Mit Salesforce Data Cloud-Daten in BigQuery arbeiten
Data Cloud-Nutzer können nativ in BigQuery auf ihre Data Cloud-Daten zugreifen. Sie können Data Cloud-Daten mit BigQuery Omni analysieren und cloudübergreifende Analysen mit den Daten in Google Cloudausführen. In diesem Dokument finden Sie eine Anleitung zum Zugriff auf Ihre Data Cloud-Daten und mehrere Analyseaufgaben, die Sie mit diesen Daten in BigQuery ausführen können.
Data Cloud funktioniert mit BigQuery auf der Grundlage der folgenden Architektur:
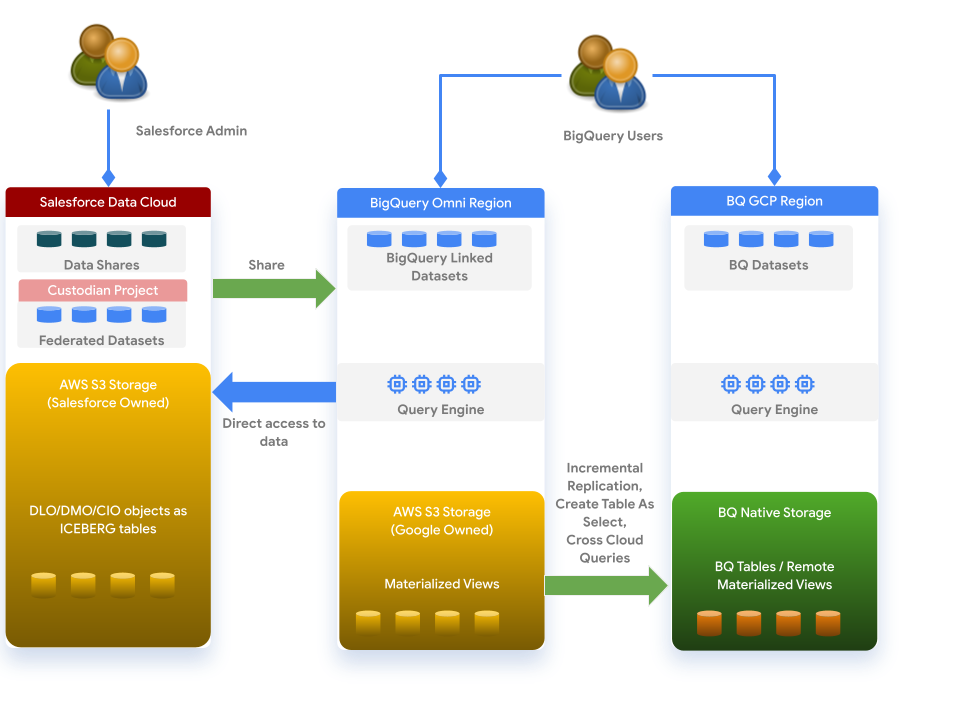
Hinweise
Bevor Sie mit Data Cloud-Daten arbeiten können, müssen Sie Data Cloud-Nutzer sein. Wenn Sie für Ihr Projekt VPC Service Controls aktiviert haben, benötigen Sie zusätzliche Berechtigungen.
Erforderliche Rollen
Folgende Rollen und Berechtigungen sind erforderlich:
- Analytics Hub Subscriber (
roles/analyticshub.subscriber) - BigQuery Administrator (
roles/bigquery.admin)
Daten aus Data Cloud teilen
In dieser Dokumentation wird gezeigt, wie Sie Daten aus Data Cloud für BigQuery freigeben: BYOL-Datenfreigaben – Zero-ETL-Integration mit BigQuery.
Data Cloud-Dataset mit BigQuery verknüpfen
Wenn Sie auf ein Data Cloud-Dataset in BigQuery zugreifen möchten, müssen Sie es zuerst mit BigQuery verknüpfen. Gehen Sie dazu so vor:
Rufen Sie in der Google Cloud Console die BigQuery-Seite auf.
Klicken Sie auf Salesforce Data Cloud.
Data Cloud-Datasets werden angezeigt. Sie können das Dataset anhand des folgenden Benennungsmusters finden:
listing_DATA_SHARE_NAME_TARGET_NAME
DATA_SHARE_NAME: Der Name der Datenfreigabe in der Data Cloud.TARGET_NAME: Der Name des BigQuery-Ziels in der Data Cloud.
Klicken Sie auf das Dataset, das Sie BigQuery hinzufügen möchten.
Klicken Sie auf Dataset in Projekt aufnehmen.
Geben Sie den Namen des verknüpften Datasets an.
Nachdem das verknüpfte Dataset erstellt wurde, können Sie es und die darin enthaltenen Tabellen untersuchen. Alle Metadaten der Tabellen werden dynamisch aus Data Cloud abgerufen. Alle Objekte im Datensatz sind Ansichten, die den Data Cloud-Objekten zugeordnet sind. BigQuery unterstützt drei Arten von Data Cloud-Objekten:
- Data Lake Objects (DLO)
- Data Model Objects (DMO)
- Objekte mit berechneten Statistiken (CIO)
Alle diese Objekte werden in BigQuery als Ansichten dargestellt. Diese Ansichten verweisen auf ausgeblendete Tabellen, die in Amazon S3 gespeichert sind.
Mit Data Cloud-Daten arbeiten
In den folgenden Beispielen wird ein Dataset namens „Northwest Trail Outfitters“ (NTO) verwendet, das in Data Cloud gehostet wird. Dieser Datensatz besteht aus drei Tabellen, die die Onlineverkäufe der NTO-Organisation darstellen:
linked_nto_john.nto_customers__dlllinked_nto_john.nto_products__dlllinked_nto_john.nto_orders__dll
Der zweite Datensatz, der in diesen Beispielen verwendet wird, sind Offline-POS-Daten. Dieser umfasst die Offlineverkäufe und besteht aus drei Tabellen:
nto_pos.customersnto_pos.productsnto_pos.orders
In den folgenden Datasets werden zusätzliche Objekte gespeichert:
aws_dataus_data
Ad-hoc-Abfragen ausführen
Mit BigQuery Omni können Sie Ad-hoc-Abfragen ausführen, um die Data Cloud-Daten über das abonnierte Dataset zu analysieren. Das folgende Beispiel zeigt eine einfache Abfrage, bei der die Tabelle „Kunden“ aus Data Cloud abgefragt wird.
SELECT name__c, age__c FROM `listing_nto_john.nto_customers__dll` WHERE age > 40 LIMIT 1000;
Cloudübergreifende Abfragen ausführen
Mit cloudübergreifenden Abfragen können Sie Tabellen in der BigQuery Omni-Region mit Tabellen in den BigQuery-Regionen verknüpfen. Weitere Informationen zu cloudübergreifenden Abfragen finden Sie in diesem Blogpost.
In diesem Beispiel rufen wir den Gesamtumsatz für einen Kunden namens john ab.
-- Get combined sales for a customer from both offline and online sales USING ( SELECT total_price FROM `listing_nto_john.nto_orders__dll` WHERE customer_name = 'john' UNION ALL SELECT total_price FROM `listing_nto_john.nto_orders__dll` WHERE customer_name = 'john' ) a SELECT SUM(total_price);
Cloudübergreifende Datenübertragung über CTAS
Sie können Create Table As Select (CTAS) verwenden, um Daten aus Data Cloud-Tabellen in der BigQuery Omni-Region in die Region US zu verschieben.
-- Move all the orders for March to the US region CREATE OR REPLACE TABLE us_data.online_orders_march AS SELECT * FROM listing_nto_john.nto_orders__dll WHERE EXTRACT(MONTH FROM order_time) = 3
Die Zieltabelle ist eine von BigQuery verwaltete Tabelle in der Region US. Diese Tabelle kann mit anderen Tabellen zusammengeführt werden. Für diesen Vorgang fallen AWS-Kosten für ausgehenden Traffic an, die von der übertragenen Datenmenge abhängen.
Nach der Verschiebung der Daten müssen Sie keine Gebühren mehr für ausgehenden Traffic für Abfragen bezahlen, die in der Tabelle online_orders_march ausgeführt werden.
Cloudübergreifende materialisierte Ansichten
Mithilfe von Cloud-übergreifenden materialisierten Ansichten (CCMV) werden Daten inkrementell aus einer BigQuery Omni-Region in eine BigQuery-Region übertragen, die keine BigQuery Omni-Region ist.
Richten Sie eine neue CCMV ein, die eine Zusammenfassung der Gesamtumsätze aus Onlinetransaktionen überträgt, und replizieren Sie diese Daten in der Region US.
Sie können über Ads Data Hub auf CCMVs zugreifen und sie mit anderen Ads Data Hub-Daten zusammenführen. CCMVs verhalten sich größtenteils wie normale verwaltete BigQuery-Tabellen.
Lokale materialisierte Ansicht erstellen
So erstellen Sie eine lokale materialisierte Ansicht:
-- Create a local materialized view that keeps track of total sales by day CREATE MATERIALIZED VIEW `aws_data.total_sales` OPTIONS (enable_refresh = true, refresh_interval_minutes = 60) AS SELECT EXTRACT(DAY FROM order_time) AS date, SUM(order_total) as sales FROM `listing_nto_john.nto_orders__dll` GROUP BY 1;
Materialisierte Ansicht autorisieren
Sie müssen materialisierte Ansichten autorisieren, um eine CCMV zu erstellen. Sie können entweder die Ansicht (aws_data.total_sales) oder das Dataset (aws_data) autorisieren. So autorisieren Sie die materialisierte Ansicht:
Rufen Sie in der Google Cloud Console die BigQuery-Seite auf.
Öffnen Sie das Quell-Dataset
listing_nto_john.Klicken Sie auf Freigabe und dann auf Datasets autorisieren.
Geben Sie den Namen des Datensatzes ein (in diesem Fall
listing_nto_john) und klicken Sie auf Ok.
Materialisierte Replikatansicht erstellen
Erstellen Sie eine neue materialisierte Replikatansicht in der Region US. Die materialisierte Ansicht wird regelmäßig repliziert, wenn sich die Quelldaten ändern, um das Replikat auf dem neuesten Stand zu halten.
-- Create a replica MV in the us region. CREATE MATERIALIZED VIEW `us_data.total_sales_replica` AS REPLICA OF `aws_data.total_sales`;
Abfrage für eine materialisierte Ansicht eines Replikats ausführen
Im folgenden Beispiel wird eine Abfrage für eine materialisierte Ansicht eines Replikats ausgeführt:
-- Find total sales for the current month for the dashboard SELECT EXTRACT(MONTH FROM CURRENT_DATE()) as month, SUM(sales) FROM us_data.total_sales_replica WHERE month = EXTRACT(MONTH FROM date) GROUP BY 1
Data Cloud-Daten mit INFORMATION_SCHEMA verwenden
Data Cloud-Datasets unterstützen BigQuery-INFORMATION_SCHEMA-Ansichten. Die Daten in den INFORMATION_SCHEMA-Ansichten werden regelmäßig aus Data Cloud synchronisiert und sind möglicherweise veraltet. In der Spalte SYNC_STATUS in den Ansichten TABLES und SCHEMATA werden die letzte abgeschlossene Synchronisierungszeit, alle Fehler, die verhindern, dass BigQuery aktuelle Daten bereitstellt, sowie alle Schritte, die zur Behebung des Fehlers erforderlich sind, angezeigt.
INFORMATION_SCHEMA-Abfragen enthalten keine Datensätze, die vor der ersten Synchronisierung erstellt wurden.
Data Cloud-Datasets unterliegen den gleichen Einschränkungen wie andere verknüpfte Datasets, z. B. sind sie nur in INFORMATION_SCHEMA in Dataset-bezogenen Abfragen zugänglich.
Nächste Schritte
Weitere Informationen zu BigQuery Omni