将 Amazon S3 数据加载到 BigQuery 中
您可以使用 BigQuery Data Transfer Service for Amazon S3 连接器将数据从 Amazon S3 加载到 BigQuery。借助 BigQuery Data Transfer Service,您可以安排周期性转移作业,将最新数据从 Amazon S3 添加到 BigQuery。
准备工作
在创建 Amazon S3 数据转移作业之前,请执行以下操作:
- 确认您已完成启用 BigQuery Data Transfer Service 所需的所有操作。
- 创建 BigQuery 数据集来存储数据。
- 为数据转移作业创建目标表并指定架构定义。目标表必须遵循表命名规则。目标表名称也支持使用参数。
- 检索 Amazon S3 URI、访问密钥 ID 和私有访问密钥。 如需了解如何管理访问密钥,请参阅 AWS 文档。
- 如果您要设置 Pub/Sub 的转移作业运行通知,必须拥有
pubsub.topics.setIamPolicy权限。如果您只想设置电子邮件通知,则无需 Pub/Sub 权限。如需了解详情,请参阅 BigQuery Data Transfer Service 运行通知。
限制
Amazon S3 数据转移作业受到以下限制:
- 无法参数化 Amazon S3 URI 的存储桶部分。
- 如果将写入处置方式参数设置为
WRITE_TRUNCATE,则从 Amazon S3 执行的数据转移作业会在每次运行期间将所有匹配的文件转移到 Google Cloud 。这可能会产生额外的 Amazon S3 出站数据转移费用。如需详细了解在运行期间转移哪些文件,请参阅前缀匹配与通配符匹配的影响。 - 不支持从 AWS GovCloud (
us-gov) 区域的数据转移。 - 不支持到 BigQuery Omni 位置的数据转移。
可能还存在其他限制,具体取决于 Amazon S3 源数据的格式。如需了解详情,请参阅:
周期性数据转移作业之间的最短间隔时间为 1 小时。周期性数据转移作业的默认间隔时间为 24 小时。
所需权限
确保您已授予以下权限。
所需 BigQuery 角色
如需获得创建 BigQuery Data Transfer Service 数据转移作业所需的权限,请让您的管理员为您授予项目的 BigQuery Admin (roles/bigquery.admin) IAM 角色。
如需详细了解如何授予角色,请参阅管理对项目、文件夹和组织的访问权限。
此预定义角色可提供创建 BigQuery Data Transfer Service 数据转移作业所需的权限。如需查看所需的确切权限,请展开所需权限部分:
所需权限
创建 BigQuery Data Transfer Service 数据转移作业需要以下权限:
-
BigQuery Data Transfer Service 权限:
-
bigquery.transfers.update -
bigquery.transfers.get
-
-
BigQuery 权限:
-
bigquery.datasets.get -
bigquery.datasets.getIamPolicy -
bigquery.datasets.update -
bigquery.datasets.setIamPolicy -
bigquery.jobs.create
-
如需了解详情,请参阅授予 bigquery.admin 访问权限。
所需的 Amazon S3 角色
请参阅 Amazon S3 的相关文档,以确保您已配置启用数据转移作业所需的所有权限。Amazon S3 源数据必须至少应用 AWS 托管政策 AmazonS3ReadOnlyAccess。
设置 Amazon S3 数据转移作业
要创建 Amazon S3 数据转移作业,请执行以下操作:
控制台
前往 Google Cloud 控制台中的“数据转移”页面。
点击 创建转移作业。
在创建转移作业页面上:
在来源类型部分的来源中,选择 Amazon S3。

在转移配置名称部分的显示名中,输入转移作业的名称,例如
My Transfer。转移作业名称可以是任何可让您在需要修改转移作业时识别该转移作业的名称。
在时间表选项部分中,执行以下操作:
选择重复频率。如果您选择小时、天、周或月,则还必须指定频率。您还可以选择自定义以创建更具体的重复频率。如果您选择按需,则只有当您手动触发转移作业时,此数据转移作业才会运行。
如果适用,请选择立即开始或在设置的时间开始,并提供开始日期和运行时间。
在目标设置部分的目标数据集字段中,选择您创建用来存储数据的数据集。
在数据源详细信息部分,执行以下操作:
- 在目标表部分,输入您创建用来在 BigQuery 中存储数据的表的名称。目标表名称支持使用参数。
- 在 Amazon S3 URI 部分,采用
s3://mybucket/myfolder/...格式输入 URI。URI 也支持使用参数。 - 在 Access key ID 部分,输入访问密钥 ID。
- 在私有访问密钥 部分,输入私有访问密钥。
- 在文件格式字段中,选择数据格式(以换行符分隔的 JSON、CSV、Avro、Parquet 或 ORC)。
- 在写入处置方式部分,选择以下选项之一:
WRITE_APPEND,以采用增量方式将新数据附加到现有目标表。WRITE_APPEND是写入偏好设置的默认值。WRITE_TRUNCATE,以在每次数据转移作业运行期间覆盖目标表中的数据。
如需详细了解 BigQuery Data Transfer Service 如何使用
WRITE_APPEND或WRITE_TRUNCATE注入数据,请参阅 Amazon S3 转移作业的数据注入。如需详细了解writeDisposition字段,请参阅JobConfigurationLoad。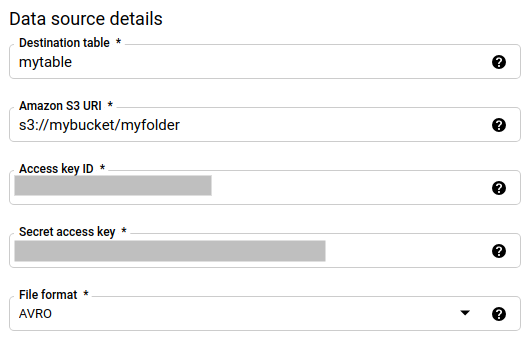
在转移作业 - 所有格式部分中:
- 在允许的错误数部分,输入一个代表可以忽略的错误记录数上限的整数值。
- (可选)在小数目标类型 (Decimal target types) 部分,输入一个源小数值可转换为的可能 SQL 数据类型的英文逗号分隔列表。选择用于转换的 SQL 数据类型取决于以下条件:
- 选择用于转换的数据类型将是以下列表中第一个支持源数据的精度和标度的数据类型(按顺序):NUMERIC、BIGNUMERIC 和 STRING。
- 如果列出的数据类型均不支持精度和比例,则系统会选择支持指定列表中最宽泛的范围的数据类型。如果在读取源数据时值超出支持的范围,将抛出错误。
- 数据类型 STRING 支持所有精度和比例值。
- 如果将此字段留空,对于 ORC,数据类型默认为“NUMERIC,STRING”,对于其他文件格式,数据类型默认为“NUMERIC”。
- 此字段不能包含重复的数据类型。
- 系统会忽略您在此字段中列出的数据类型的顺序。

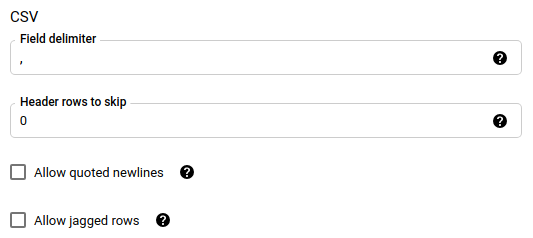
如果您选择了 CSV 或 JSON 作为文件格式,请在 JSON、CSV 部分中,选中忽略未知值以接受包含与架构不匹配的值所在的行。未知值会被忽略。对于 CSV 文件,此选项会忽略行尾的额外值。

如果您选择了 CSV 作为文件格式,请在 CSV 部分中输入用于加载数据的任何其他 CSV 选项。
在服务账号菜单中,从与您的Google Cloud 项目关联的服务账号中选择一个服务账号。您可以将服务账号与数据转移作业相关联,而不是使用用户凭据。如需详细了解如何将服务账号用于数据转移,请参阅使用服务账号。
(可选)在通知选项部分,执行以下操作:
点击保存。
bq
输入 bq mk 命令并提供转移作业创建标志 --transfer_config。
bq mk \ --transfer_config \ --project_id=project_id \ --data_source=data_source \ --display_name=name \ --target_dataset=dataset \ --service_account_name=service_account \ --params='parameters'
其中:
- project_id:可选。您的 Google Cloud 项目 ID。如果未提供
--project_id来指定具体项目,则系统会使用默认项目。 - data_source:必填。数据源 -
amazon_s3。 - display_name:必填。数据转移作业配置的显示名称。转移作业名称可以是任何可让您在需要修改转移作业时识别该转移作业的名称。
- dataset:必填。数据数据转移作业配置的目标数据集。
- service_account:用于对数据转移作业进行身份验证的服务账号名称。该服务账号应属于用于创建数据转移作业的同一
project_id,并且应拥有所有所需的权限。 parameters:必填。所创建转移作业配置的参数(采用 JSON 格式)。例如
--params='{"param":"param_value"}'。以下是 Amazon S3 转移作业的参数:- destination_table_name_template:必填。目标表的名称。
data_path:必填。Amazon S3 URI,格式如下:
s3://mybucket/myfolder/...URI 也支持使用参数。
access_key_id:必填。您的访问密钥 ID。
secret_access_key:必填。您的私有访问密钥。
file_format:可选。表示要转移的文件类型:
CSV、JSON、AVRO、PARQUET或ORC。默认值为CSV。write_disposition:可选。
WRITE_APPEND仅转移自上次成功运行以来修改的文件。WRITE_TRUNCATE会转移所有匹配的文件,包括在上次运行中转移的文件。默认值为WRITE_APPEND。max_bad_records:可选。允许的错误记录数。默认值为
0。decimal_target_types:可选。一个源小数值可转换为的可能 SQL 数据类型的英文逗号分隔列表。如果未提供此字段,则对于 ORC,数据类型默认为“NUMERIC,STRING”,对于其他文件格式,数据类型默认为“NUMERIC”。
ignore_unknown_values:可选;如果 file_format 不是
JSON或CSV,则此参数会被忽略。是否忽略数据中的未知值。field_delimiter:可选;仅在
file_format为CSV时适用。用于分隔字段的字符。默认值为英文逗号。skip_leading_rows:可选;仅在 file_format 为
CSV时适用。表示您不想导入的标题行数。默认值为0。allow_quoted_newlines:可选;仅在 file_format 为
CSV时适用。表示是否允许在引用字段中使用换行符。allow_jagged_rows:可选;仅在 file_format 为
CSV时适用。表示是否接受末尾处缺少可选列的行。系统将填入 NULL 来代替缺少的值。
例如,以下命令使用 data_path 值 s3://mybucket/myfile/*.csv、目标数据集 mydataset 和 file_format CSV 创建名为 My Transfer 的 Amazon S3 数据转移作业。此示例包含与 CSV file_format 关联的可选参数的非默认值。
该数据转移作业将在默认项目中创建:
bq mk --transfer_config \
--target_dataset=mydataset \
--display_name='My Transfer' \
--params='{"data_path":"s3://mybucket/myfile/*.csv",
"destination_table_name_template":"MyTable",
"file_format":"CSV",
"write_disposition":"WRITE_APPEND",
"max_bad_records":"1",
"ignore_unknown_values":"true",
"field_delimiter":"|",
"skip_leading_rows":"1",
"allow_quoted_newlines":"true",
"allow_jagged_rows":"false"}' \
--data_source=amazon_s3
运行命令后,您会收到如下消息:
[URL omitted] Please copy and paste the above URL into your web browser and
follow the instructions to retrieve an authentication code.
请按照说明操作,并将身份验证代码粘贴到命令行中。
API
使用 projects.locations.transferConfigs.create 方法并提供一个 TransferConfig 资源实例。
Java
试用此示例之前,请按照 BigQuery 快速入门:使用客户端库中的 Java 设置说明进行操作。 如需了解详情,请参阅 BigQuery Java API 参考文档。
如需向 BigQuery 进行身份验证,请设置应用默认凭证。如需了解详情,请参阅为客户端库设置身份验证。
前缀匹配与通配符匹配的影响
Amazon S3 API 支持前缀匹配,但不支持通配符匹配。与某个前缀匹配的所有 Amazon S3 文件都将转移到 Google Cloud中。但是,只有与转移作业配置中的 Amazon S3 URI 匹配的文件才会实际加载到 BigQuery 中。这可能会导致一些未加载到 BigQuery 中的转移文件产生额外的 Amazon S3 出站数据转移费用。
例如,假设有以下数据路径:
s3://bucket/folder/*/subfolder/*.csv
并且源位置有以下文件:
s3://bucket/folder/any/subfolder/file1.csv
s3://bucket/folder/file2.csv
这将导致前缀为 s3://bucket/folder/ 的所有 Amazon S3 文件都会转移到 Google Cloud。在本示例中,file1.csv 和 file2.csv 都将被转移。
但是,只有与 s3://bucket/folder/*/subfolder/*.csv 匹配的文件才会实际加载到 BigQuery 中。在本示例中,只有 file1.csv 才会加载到 BigQuery 中。
排查转移作业设置问题
如果您在设置数据转移作业时遇到问题,请参阅 Amazon S3 转移作业问题。
后续步骤
- 如需简要了解 Amazon S3 数据转移作业,请参阅 Amazon S3 转移作业概览
- 如需大致了解 BigQuery Data Transfer Service,请参阅 BigQuery Data Transfer Service 简介。
- 如需了解如何使用数据转移作业,包括获取有关转移作业配置的信息、列出转移作业配置以及查看转移作业的运行历史记录,请参阅使用转移作业。
- 了解如何通过跨云操作加载数据。