本文档提供有关 BigQuery 的差分隐私的一般信息。如需了解语法,请参阅差分隐私子句。 如需查看可与此语法搭配使用的函数列表,请参阅差分隐私聚合函数。
什么是差分隐私?
差分隐私是一种数据计算的标准,用于限制输出披露的个人信息。差分隐私通常用于共享数据并允许对用户组进行推断,同时防止有人获取具体用户的信息。
差分隐私在以下领域非常有用:
- 存在重标识的风险。
- 量化风险与分析有效性之间的折衷。
为了更好地了解差分隐私,让我们来看一个简单的示例。
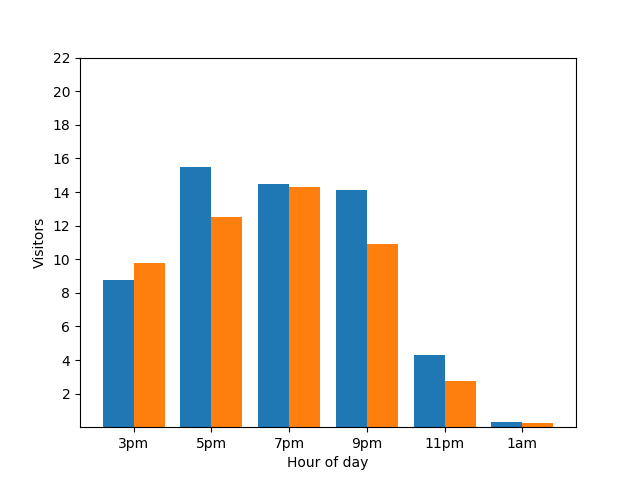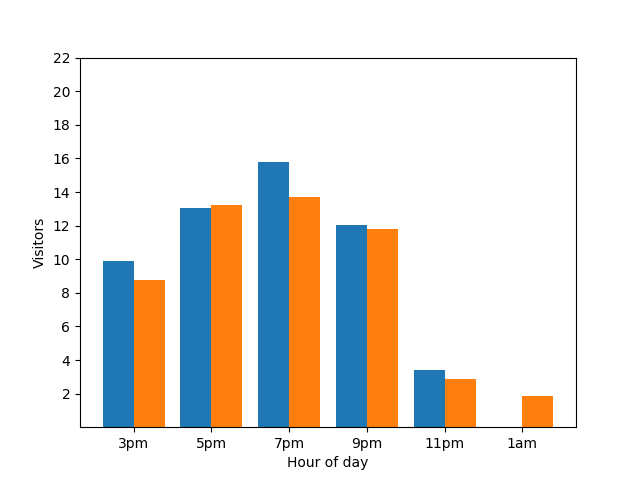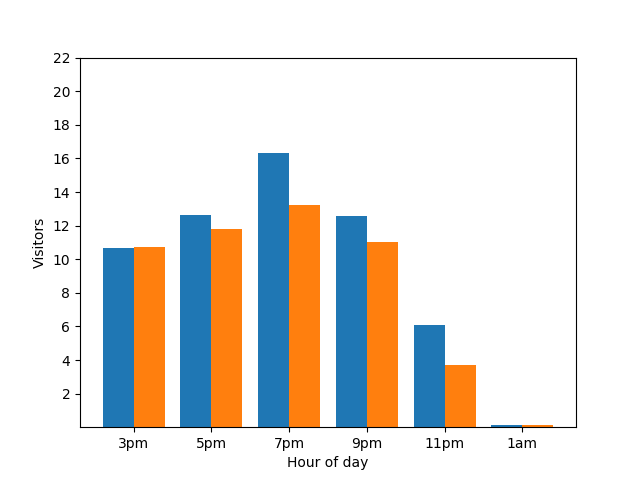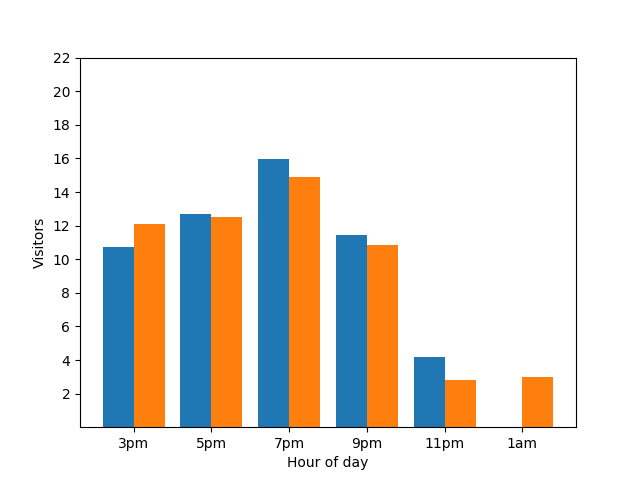
下面的条形图显示了一家小餐厅在某个晚上的繁忙程度。晚上 7 点有大量顾客光临,而凌晨 1 点餐厅空无一人:
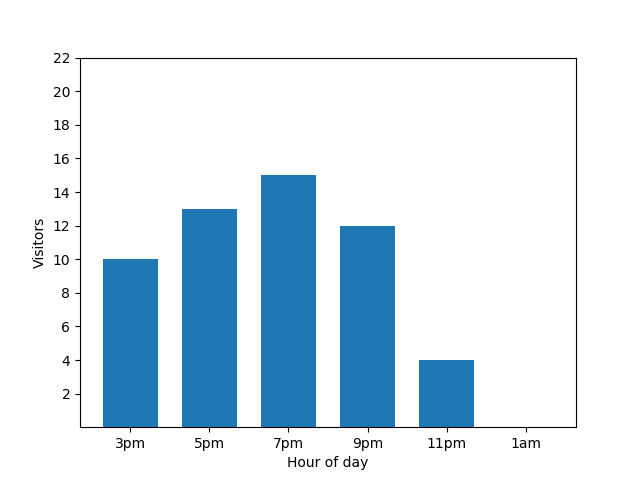
此图表看起来很实用,但它存在一个弊端。当一位新顾客光临时,条形图会立即透露这一事实。在下图中,可以明显看出有一名新顾客,并且该顾客在凌晨 1 点左右到店:
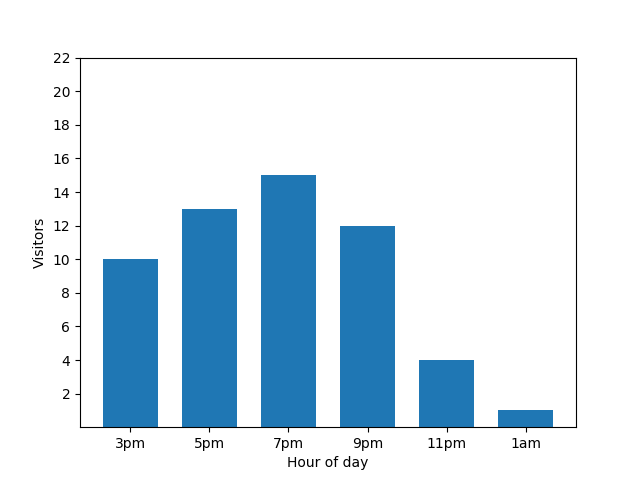
从隐私的角度来看,显示此详细信息并不好,因为匿名统计数据不应透露个人贡献。将这两个图表并排放置会更加明显:橙色条形图中多了一名在凌晨 1 点左右到店的顾客:
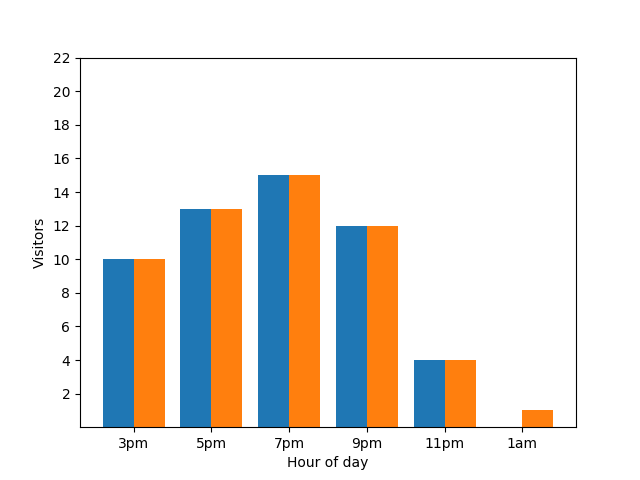
重申一遍,这是一个弊端。为避免这种隐私问题,您可以使用差分隐私向条形图添加随机噪声。在以下比较图表中,结果是匿名化的,不再透露个人贡献。
差分隐私在查询中的工作原理
差分隐私的目标是降低披露风险,即有人可以获取数据集中某个实体的相关信息。差分隐私可以在隐私保护与统计分析有效性之间取得平衡。隐私性越好,统计分析有效性越低,反之亦然。
借助 GoogleSQL for BigQuery,您可以使用差分隐私聚合来转换查询结果。执行查询时,它会执行以下操作:
- 如果使用
GROUP BY子句指定组,则计算每个组的按实体聚合值。根据max_groups_contributed差分隐私参数,限制每个实体可以贡献的组数。 - 将按实体聚合的贡献限制在限制取值范围内。如果未指定限制取值范围,则以差分隐私方式隐式计算。
- 聚合每个组的限制后按实体聚合贡献。
- 向每个组的最终聚合值添加噪声。随机噪声的范围是所有限制取值范围和隐私参数的函数。
- 计算每个组的噪声实体数量,并去除包含很少实体的组。噪声实体数量可帮助去除非确定性的组。
最终结果是一个数据集,其中每个组都有噪声聚合结果,并且去除了较小的组。
如需详细了解差分隐私及其应用场景,请参阅以下文章:
生成有效的差分隐私查询
有效的差分隐私查询必须符合以下规则:
定义隐私单元列
隐私单元是数据集中使用差分隐私进行保护的实体。实体可以是个人、公司、位置或您选择的任何列。
差分隐私查询必须包含且仅包含一个隐私单元列。隐私单元列是隐私单元的唯一标识符,可以存在于多个组中。由于支持多个组,因此隐私单元列的数据类型必须是可分组的。
您可以使用唯一标识符 privacy_unit_column 在差分隐私子句的 OPTIONS 子句中定义隐私单元列。
在以下示例中,一个隐私单元列被添加到差分隐私子句。id 表示名为 students 的表中的一个列。
SELECT WITH DIFFERENTIAL_PRIVACY
OPTIONS (epsilon=10, delta=.01, privacy_unit_column=id)
item,
COUNT(*, contribution_bounds_per_group=>(0, 100))
FROM students;
SELECT WITH DIFFERENTIAL_PRIVACY
OPTIONS (epsilon=10, delta=.01, privacy_unit_column=members.id)
item,
COUNT(*, contribution_bounds_per_group=>(0, 100))
FROM (SELECT * FROM students) AS members;
从差分隐私查询中移除噪声
请参阅“查询语法”参考文档中的移除噪声。
向差分隐私查询添加噪声
请参阅“查询语法”参考文档中的添加噪声。
限制隐私单元 ID 可以存在的组
请参阅“查询语法”参考文档中的限制隐私权单元 ID 可以存在的组。
限制
本部分介绍差分隐私的限制。
差分隐私的性能影响
差分隐私查询的执行速度比标准查询慢,因为需要执行按实体聚合,并且要应用 max_groups_contributed 限制。限制贡献范围有助于提高差分隐私查询的性能。
以下查询的性能分析结果不相同:
SELECT
WITH DIFFERENTIAL_PRIVACY OPTIONS(epsilon=1, delta=1e-10, privacy_unit_column=id)
column_a, COUNT(column_b)
FROM table_a
GROUP BY column_a;
SELECT column_a, COUNT(column_b)
FROM table_a
GROUP BY column_a;
性能差异的原因在于针对差分隐私查询执行了更精细的分组,因为还必须执行按实体聚合。
以下查询的性能分析结果应该相似,但差分隐私查询稍微慢一些:
SELECT
WITH DIFFERENTIAL_PRIVACY OPTIONS(epsilon=1, delta=1e-10, privacy_unit_column=id)
column_a, COUNT(column_b)
FROM table_a
GROUP BY column_a;
SELECT column_a, id, COUNT(column_b)
FROM table_a
GROUP BY column_a, id;
差分隐私查询执行速度较慢的原因在于隐私单元列有大量不同的值。
小型数据集的隐式边界限制
使用大型数据集计算时,隐式边界效果最佳。 如果数据集包含的隐私单元数量较少,则隐式边界可能会失败,且不返回任何结果。此外,在具有较少隐私单元的数据集上,隐式边界可能会限制大部分非离群值的取值范围,从而导致低估的聚合以及限制取值范围比添加噪声影响更大的结果。具有较少隐私单元或较少分区的数据集应使用显式而不是隐式取值范围限制。
隐私漏洞
如果分析师要进行恶意破坏,由于算术上的限制,任何差分隐私算法(包括此差分隐私算法)都存在隐私数据泄露的风险,尤其是在计算总和等基本统计信息时。
隐私保证的限制
虽然 BigQuery 差分隐私应用差分隐私算法,但不保证生成的数据集的隐私属性。
运行时错误
怀有恶意且能够编写查询或控制输入数据的分析师可能会触发私有数据的运行时错误。
浮点噪声
在使用差分隐私之前,应考虑与舍入、重复舍入和重新排序攻击相关的漏洞。当攻击者可以控制数据集的某些内容或数据集中的内容顺序时,这些漏洞尤为令人担忧。
浮点数据类型的差分隐私噪声添加受到差分隐私库中广泛低估的敏感度以及如何解决该问题中所述漏洞的影响。整数数据类型的噪声添加不受到白皮书中所述漏洞的影响。
时序攻击风险
怀有恶意的分析师可能执行足够复杂的查询,根据查询的执行时长推断输入数据。
分类错误
创建差分隐私查询假设您的数据采用众所周知且易于理解的结构。如果您对错误的标识符应用差分隐私(例如表示事务 ID 而非个人 ID 的标识符),则可能会泄露敏感数据。
如果您在理解数据方面需要帮助,请考虑使用以下服务和工具:
价格
使用差分隐私不会产生额外费用,但分析适用标准 BigQuery 价格。