このドキュメントでは、BigQuery の差分プライバシーに関する一般的な情報を提供します。構文については、差分プライバシー句をご覧ください。この構文で使用できる関数のリストについては、差分プライベート集計関数をご覧ください。
差分プライバシーとは
差分プライバシーとは、データの計算に関する標準のことで、出力によって公開される個人情報を制限します。差分プライバシーは、データの共有や、グループに関する情報の推論を許可しながら、個人に関する情報が他者に知られることを防ぐためによく使用されます。
差分プライバシーは次の場合に有用です。
- 再識別のリスクがある場合。
- リスクと分析ユーティリティのトレードオフを定量化する場合。
差分プライバシーをより良く理解するために、簡単な例を見てみましょう。
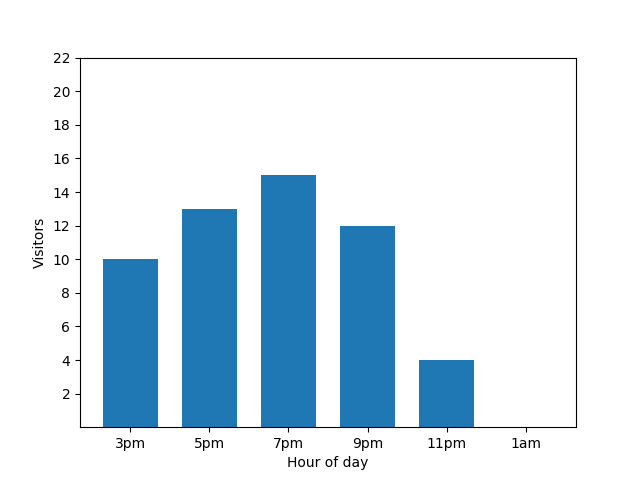
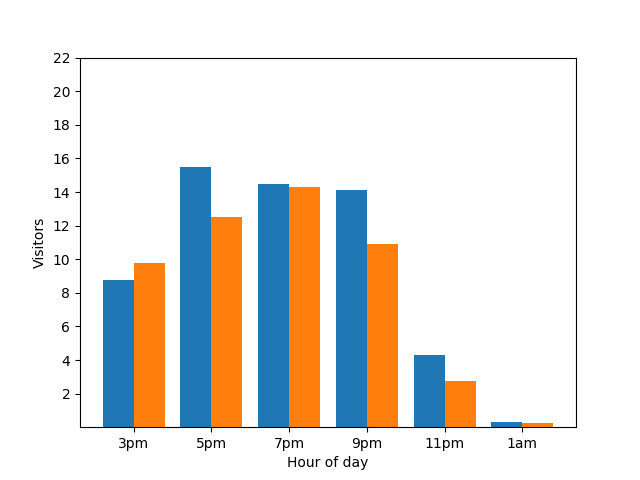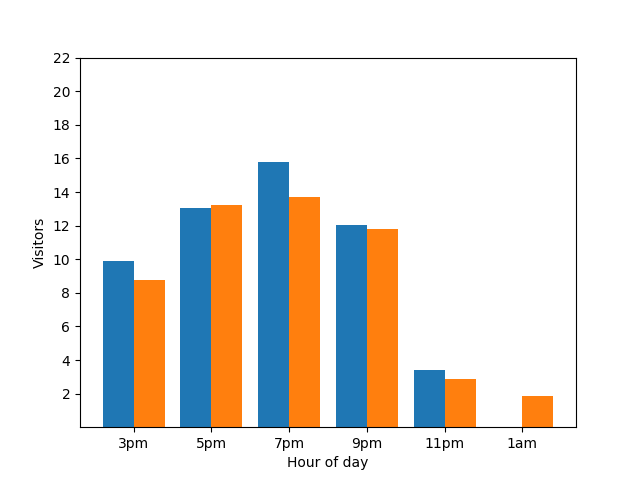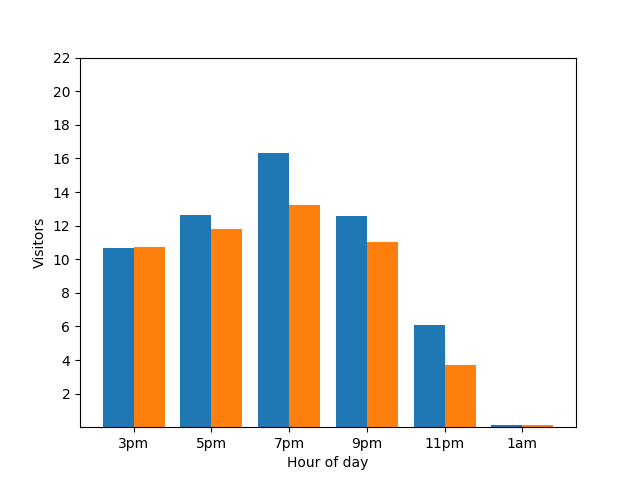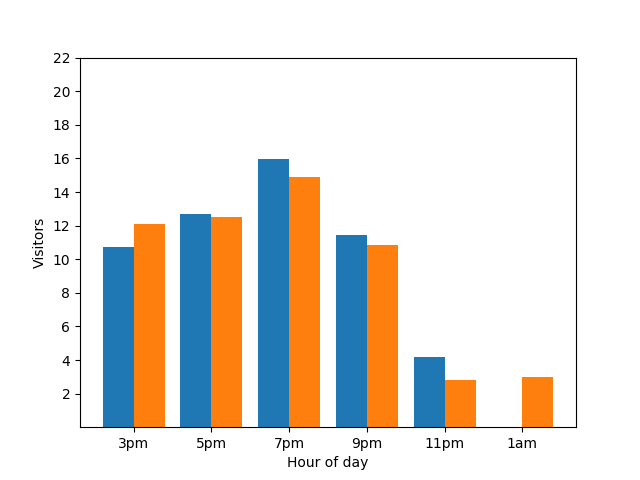
この棒グラフは、ある特定の晩の、小さなレストランの混雑状況を示しています。午後 7 時に多くの客がやってきて、午前 1 時にはレストランが完全に空になります。
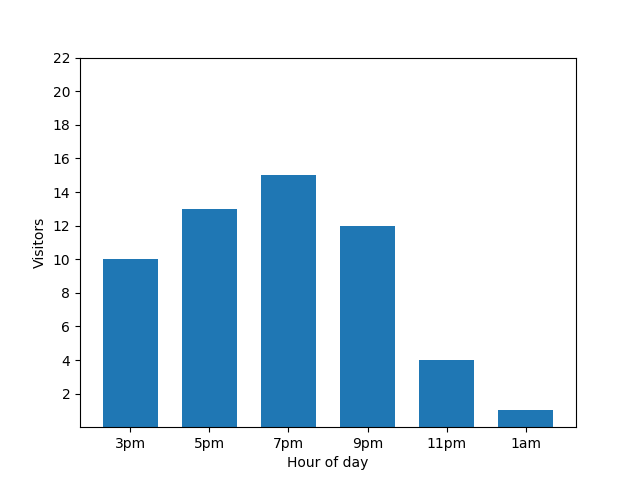
このグラフは便利そうに見えますが、欠点が 1 つあります。新たな来店があると、この事実が棒グラフですぐに明らかになることです。次のグラフでは、新しい客が来店したことと、その客が午前 1 時頃に到着したことがわかります。
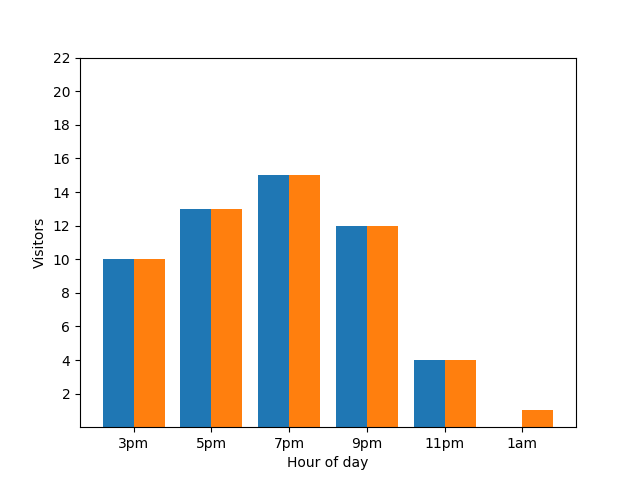
匿名化された統計で個々の行動がわかることは好ましくないため、プライバシーの観点からこの詳細の表示は適切ではありません。この 2 つのグラフを並べてみると、このことがさらに明確になります。オレンジ色の棒グラフでは、午前 1 時頃に客が 1 人増えています。
繰り返しますが、これは好ましくありません。このようなプライバシーの問題を回避するには、差分プライバシーを使用して、棒グラフにランダムなノイズを追加します。次の比較グラフでは、結果が匿名化され、個々の貢献度が公開されなくなりました。
クエリでの差分プライバシーの仕組み
差分プライバシーの目標は、開示リスク(データセット内のあるエンティティに関する情報を第三者が知ることができるリスク)を低減することです。差分プライバシーは、プライバシーを保護する必要性と、統計分析の有用性に対するニーズのバランスを取るものです。プライバシーの保護が進むと、統計分析の有用性は低下し、逆もまた然りです。
GoogleSQL for BigQuery を使用すると、クエリの結果を、差分プライベート集計で変換できます。クエリを実行すると、次の処理が行われます。
- グループが
GROUP BY句で指定されている場合は、各グループのエンティティごとの集計を計算します。max_groups_contributed差分プライバシー パラメータに基づいて、各エンティティが関与できるグループの数を制限します。 - エンティティごとの集計の貢献度をクランプして、クランプ境界内に収まるようにします。クランプ境界が指定されていない場合、差分プライベート手法で暗黙的に計算されます。
- 各グループの、クランプされたエンティティごとの集計の貢献度を集計します。
- 各グループの最終的な集計値にノイズを追加します。ランダムノイズの規模は、クランプされた境界とプライバシー パラメータの関数です。
- 各グループのノイズの多いエンティティ数を計算し、エンティティ数の少ないグループを除外します。ノイズの多いエンティティの数は、非確定的なグループの集合の排除に役立ちます。
最終結果は、各グループのノイズの多い集計結果が含まれ、小規模なグループが除外されたデータセットになります。
差分プライバシーとそのユースケースの詳細については、以下の記事をご覧ください。
- A friendly, non-technical introduction to differential privacy(英語)
- Differentially private SQL with bounded user contribution(英語)
- Wikipedia の「Differential privacy」に関するページ(英語)
有効な差分プライベート クエリを生成する
差分プライベート クエリを有効なものにするには、次のルールを満たしている必要があります。
- プライバシー ユニット列が定義されている。
SELECTリストに差分プライベート句が含まれている。- 差分プライベート句を含む
SELECTリストには、差分プライベート集計関数のみが含まれている。
プライバシー ユニット列を定義する
プライバシー ユニットとは、差分プライバシーを使用して保護されているデータセット内のエンティティのことです。エンティティは、個人、会社、場所など、任意の列に設定できます。
差分プライベート クエリには、プライバシー ユニット列を 1 つだけ含める必要があります。プライバシー ユニット列は、プライバシー ユニットの固有識別子であり、複数のグループ内に存在できます。複数のグループがサポートされているため、プライバシー ユニット列のデータ型はグループ化可能である必要があります。
プライバシー ユニット列は、固有識別子 privacy_unit_column を使用して、差分プライバシー句の OPTIONS 句で定義できます。
次の例では、プライバシー ユニット列が差分プライバシー句に追加されます。id は students というテーブルから派生した列を表します。
SELECT WITH DIFFERENTIAL_PRIVACY
OPTIONS (epsilon=10, delta=.01, privacy_unit_column=id)
item,
COUNT(*, contribution_bounds_per_group=>(0, 100))
FROM students;
SELECT WITH DIFFERENTIAL_PRIVACY
OPTIONS (epsilon=10, delta=.01, privacy_unit_column=members.id)
item,
COUNT(*, contribution_bounds_per_group=>(0, 100))
FROM (SELECT * FROM students) AS members;
差分プライベート クエリからノイズを削除する
「クエリ構文」リファレンスで、ノイズの削除をご覧ください。
差分プライベート クエリにノイズを追加する
「クエリ構文」リファレンスで、ノイズの追加をご覧ください。
プライバシー ユニット ID が存在できるグループを制限する
「クエリ構文」リファレンスで、プライバシー ユニット ID が存在するグループを制限するをご覧ください。
制限事項
このセクションでは、差分プライバシーの制限について説明します。
差分プライバシーのパフォーマンスへの影響
差分プライベート クエリは、エンティティごとの集計が行われ、max_groups_contributed の制限が適用されるため、標準クエリよりも実行速度が遅くなります。貢献度の範囲を制限することで、差分プライベート クエリのパフォーマンスを改善できます。
次の 2 つのクエリのパフォーマンス プロファイルは異なります。
SELECT
WITH DIFFERENTIAL_PRIVACY OPTIONS(epsilon=1, delta=1e-10, privacy_unit_column=id)
column_a, COUNT(column_b)
FROM table_a
GROUP BY column_a;
SELECT column_a, COUNT(column_b)
FROM table_a
GROUP BY column_a;
パフォーマンスの違いの理由は、エンティティごとの集計も実行しなければならず、差分プライベート クエリに対してさらに細かい粒度のグループ化が実行されるためです。
差分プライベート クエリのほうがやや遅くなりますが、次の 2 つのクエリのパフォーマンス プロファイルは類似しています。
SELECT
WITH DIFFERENTIAL_PRIVACY OPTIONS(epsilon=1, delta=1e-10, privacy_unit_column=id)
column_a, COUNT(column_b)
FROM table_a
GROUP BY column_a;
SELECT column_a, id, COUNT(column_b)
FROM table_a
GROUP BY column_a, id;
差分プライベート クエリの場合、プライバシー ユニット列の個別の値が多数存在するため、パフォーマンスが低下します。
小規模データセットに対する暗黙的な境界の制限
暗黙的な境界は、大規模なデータセットを使用して計算する場合に最適です。プライバシー ユニットの数が少ないデータセットでは、暗黙的な境界が失敗し、結果が返されない可能性があります。さらに、プライバシー ユニット数が少ないデータセットに対する暗黙的な境界では、外れ値以外の大部分をクランプしてしまい、集計結果が過小報告されたり、ノイズの追加よりもクランプのために結果が大きく変わったりする可能性があります。プライバシー ユニット数が少ないデータセットや、細かくパーティショニングされたデータセットでは、暗黙のクランプ処理ではなく明示的なクランプ処理を使用する必要があります。
プライバシーに関する脆弱性
この例のような差分プライバシー アルゴリズムには、アナリストが悪意を持って行動した場合、特に合計などの基本的な統計を計算するときに、演算に関する制限が理由で、個人情報が漏えいするリスクがあります。
プライバシー保証の制限
BigQuery の差分プライバシーは差分プライバシー アルゴリズムを適用しますが、作成されたデータセットのプライバシー特性を保証するものではありません。
ランタイム エラー
クエリの作成や入力データの管理を行える悪意あるアナリストのために、プライベート データのランタイム エラーが発生する可能性があります。
浮動小数点ノイズ
差分プライバシーを使用する前に、丸め、丸めの繰り返し、再順序付けによる攻撃に関連する脆弱性を考慮する必要があります。これらの脆弱性は、攻撃者がデータセットの内容の一部またはデータセット内のコンテンツの順序を制御できる場合に特に考慮する必要があります。
浮動小数点データ型に対する差分プライベートのノイズの追加は、「Widespread Underestimation of Sensitivity in Differentially Private Libraries and How to Fix It(英語)」で説明されている脆弱性の影響を受けます。整数データ型に対するノイズの追加は、このドキュメントで説明されている脆弱性の影響を受けません。
タイミング攻撃のリスク
悪意あるアナリストが複雑なクエリを実行して、クエリの実行時間に基づいて入力データについて推定する可能性があります。
誤分類
差分プライバシー クエリの作成は、データの構造がよく知られた、理解できるものであることを前提としています。たとえば、個人の ID ではなくトランザクション ID を表す識別子など、誤った識別子に差分プライバシーを適用すると、機密データが公開される可能性があります。
データを理解するのにサポートが必要な場合は、次のようなサービスとツールの使用を検討してください。
料金
差分プライバシーを使用するための追加料金はありませんが、分析のための標準の BigQuery 料金が適用されます。