BigQuery 샌드박스 사용 설정
BigQuery 샌드박스를 사용하면 BigQuery 기능을 무료로 탐색하여 BigQuery가 니즈에 적합한지 확인할 수 있습니다. BigQuery 샌드박스를 사용하면 신용카드 정보를 제공하거나 프로젝트에 결제 계정을 만들지 않고도 BigQuery를 경험할 수 있습니다. 이미 결제 계정을 만든 경우에도 무료 사용량 등급으로 BigQuery를 무료로 사용할 수 있습니다.
BigQuery 샌드박스 사용 시작
Google Cloud 콘솔에서 BigQuery 페이지로 이동합니다.
또한 브라우저에 다음 URL을 입력하면 Google Cloud 콘솔에서 BigQuery를 열 수 있습니다.
https://console.cloud.google.com/bigquery
Google Cloud 콘솔은 BigQuery 리소스를 만들어 관리하거나 SQL 쿼리를 실행할 때 사용할 수 있는 그래픽 인터페이스입니다.
Google 계정으로 인증하거나 새 계정을 만듭니다.
시작 페이지에서 다음을 수행합니다.
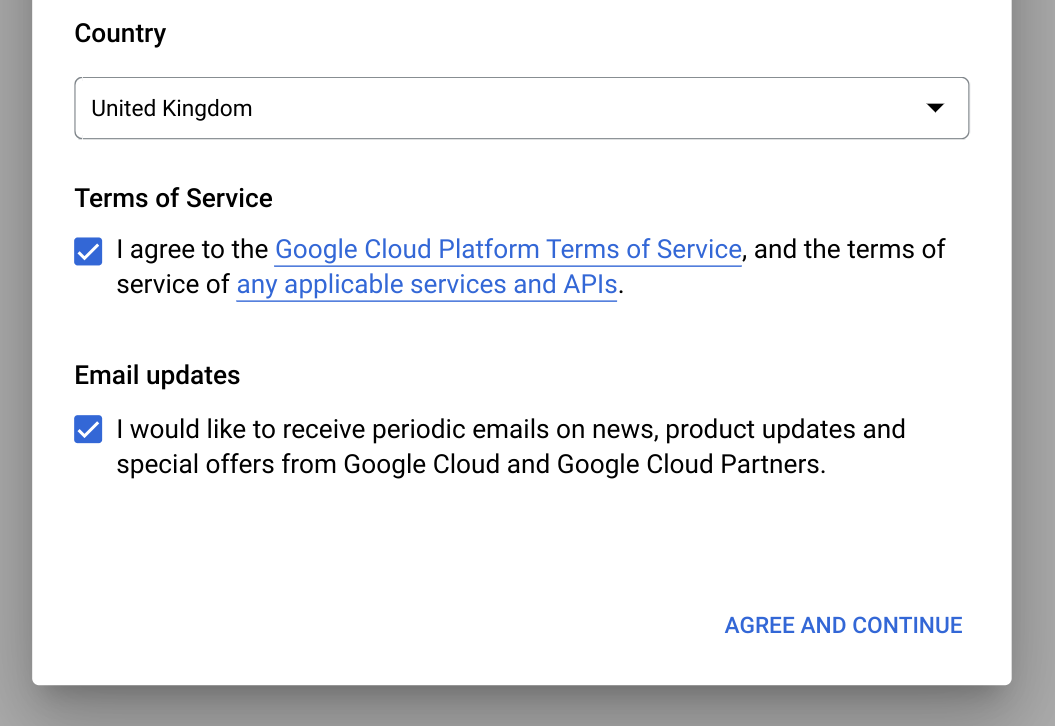
국가에서 국가를 선택합니다.
서비스 약관에서 서비스 약관에 동의하면 체크박스를 선택합니다.
선택사항: 이메일 업데이트에 대한 메시지가 표시되면 이메일 업데이트를 수신하려는 경우 체크박스를 선택합니다.
동의 및 계속하기를 클릭합니다.
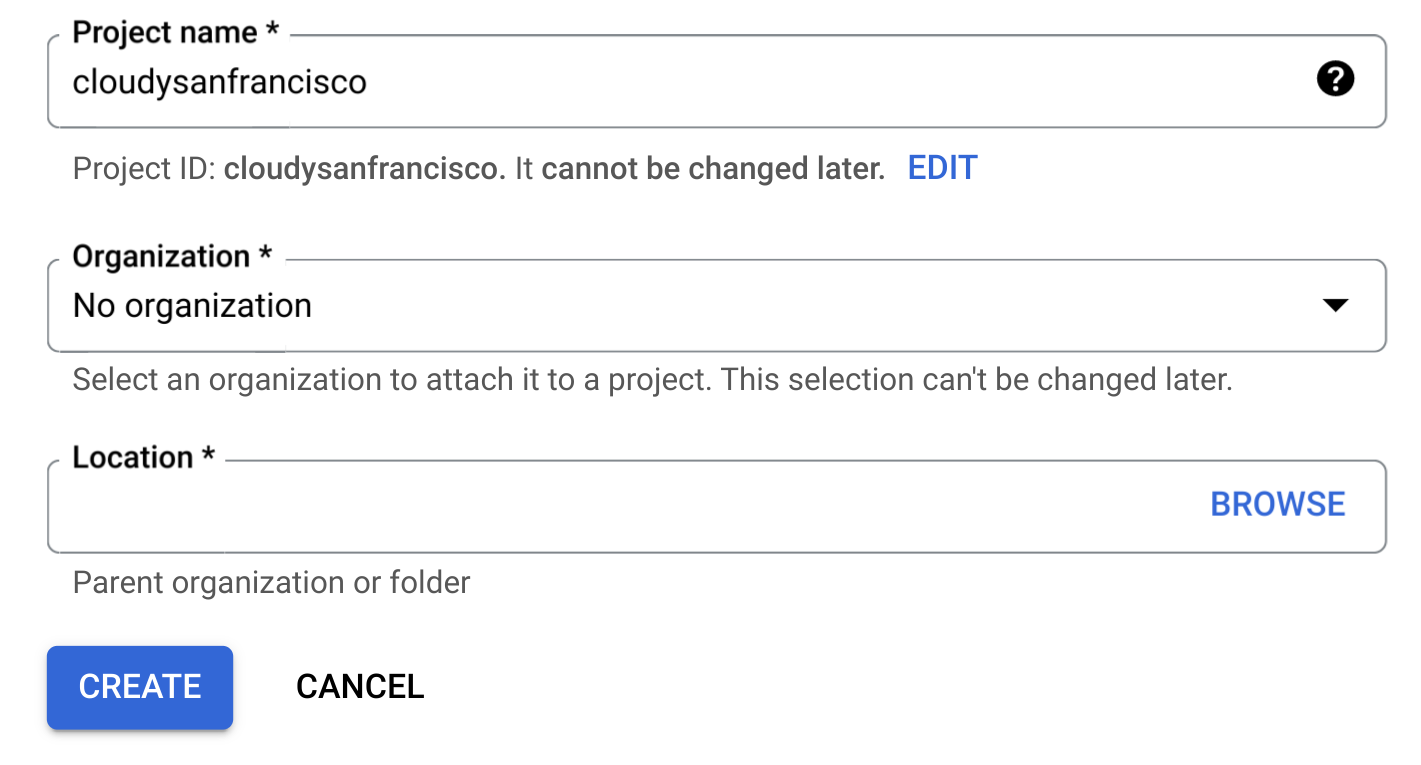
프로젝트 만들기를 클릭합니다.
새 프로젝트 페이지에서 다음을 수행합니다.
프로젝트 이름에 프로젝트 이름을 입력합니다.
조직에서 조직을 선택하거나 조직에 속해 있지 않은 경우 조직 없음을 선택합니다. 관리 계정(예: 교육 기관과 연결된 계정)은 조직을 선택해야 합니다.
위치를 선택하라는 메시지가 표시되면 찾아보기를 클릭하고 프로젝트의 위치를 선택합니다.
만들기를 클릭합니다. Google Cloud 콘솔에서 BigQuery 페이지로 다시 리디렉션됩니다.
BigQuery 샌드박스를 사용 설정했습니다. 이제 BigQuery 페이지에 BigQuery 샌드박스 알림이 표시됩니다.

이제 BigQuery 샌드박스가 사용 설정되었으므로 다음으로 Google Cloud 콘솔로 공개 데이터 세트 쿼리 빠른 시작을 진행해 보세요. 또한 많은 관리 태스크에 유용한 유사한 bq 명령줄 도구 빠른 시작이나 유사한 클라이언트 라이브러리 빠른 시작을 사용하면 Java 및 Python과 같은 프로그래밍 언어로 BigQuery를 사용할 수 있습니다.
BigQuery 샌드박스에서 업그레이드
BigQuery 샌드박스를 사용하면 제한된 BigQuery 기능을 무료로 사용해 볼 수 있습니다. 스토리지 용량을 늘리거나 더 많은 쿼리 기능을 사용할 준비가 되었다면 BigQuery 샌드박스에서 업그레이드하세요.
업그레이드하려면 다음 단계를 따르세요.
프로젝트에 결제를 사용 설정합니다.
BigQuery 버전을 살펴보고 적합한 가격 책정 모델을 결정합니다.
BigQuery 샌드박스에서 업그레이드한 후에는 테이블, 뷰, 파티션과 같은 BigQuery 리소스의 기본 만료 시간을 업데이트해야 합니다.
제한사항
BigQuery 샌드박스에는 다음 한도가 적용됩니다.
- 모든 BigQuery 할당량 및 한도가 적용됩니다.
- BigQuery 무료 등급과 동일한 무료 사용량 한도, 즉 매월 활성 스토리지 10GB와 처리된 쿼리 데이터 1TB가 제공됩니다.
- 모든 BigQuery 데이터 세트에는 기본 테이블 만료 시간이 있으며 모든 테이블, 뷰, 파티션은 60일 후에 자동으로 만료됩니다.
BigQuery 샌드박스는 다음을 비롯한 여러 BigQuery 기능을 지원하지 않습니다.
다음 단계
- Google Cloud 콘솔로 공개 데이터 세트를 쿼리하는 방법 알아보기
- bq 도구를 사용하여 공개 데이터 세트를 쿼리하는 방법 알아보기
- 클라이언트 라이브러리로 공개 데이터 세트를 쿼리하는 방법 알아보기
- 무료 사용량 등급에서 BigQuery를 무료로 사용하는 방법에 대한 자세한 내용은 무료 사용량 등급 참조하기
- BigQuery 출시 업데이트 받기
- Firebase 사용자라면 Firebase에 BigQuery 연결 참조하기