Strumenti di analisi programmatica
Questo documento descrive diversi modi per scrivere ed eseguire codice per analizzare i dati gestiti in BigQuery.
Sebbene SQL sia un linguaggio di query potente, linguaggi di programmazione come Python, Java o R forniscono sintassi e un'ampia gamma di funzioni statistiche integrate che gli analisti di dati potrebbero trovare più espressive e più facili da manipolare per determinati tipi di analisi dei dati.
Allo stesso modo, mentre i fogli di lavoro sono ampiamente utilizzati, altri ambienti di programmazione come i notebook possono a volte fornire un ambiente più flessibile per eseguire analisi ed esplorazioni complesse dei dati.
Notebook Colab Enterprise
Puoi utilizzare i notebook Colab Enterprise in BigQuery per completare i flussi di lavoro di analisi e machine learning (ML) utilizzando SQL, Python e altri pacchetti e API comuni. Notebooks offrono una migliore collaborazione e gestione con le seguenti opzioni:
- Condividi i blocchi note con utenti e gruppi specifici utilizzando Identity and Access Management (IAM).
- Esamina la cronologia delle versioni del notebook.
- Ripristina o crea una ramificazione dalle versioni precedenti del blocco note.
Notebooks sono asset di codice BigQuery Studio basati su Dataform, anche se non sono visibili in Dataform. Anche le query salvate sono asset di codice. Tutti gli asset di codice vengono archiviati in una regione predefinita. L'aggiornamento della regione predefinita modifica la regione per tutti gli asset di codice creati dopo quel momento.
Le funzionalità dei notebook sono disponibili solo nella Google Cloud console.
Notebooks in BigQuery offrono i seguenti vantaggi:
- BigQuery DataFrames è integrato nei blocchi note, senza necessità di configurazione. BigQuery DataFrames è un'API Python che puoi utilizzare per analizzare i dati di BigQuery su scala utilizzando le API pandas DataFrame e scikit-learn.
- Sviluppo di codice assistito basato sull'AI generativa Gemini.
- Completamento automatico delle istruzioni SQL, come nell'editor BigQuery.
- Possibilità di salvare, condividere e gestire le versioni dei blocchi note.
- La possibilità di utilizzare matplotlib, seaborn e altre librerie popolari per visualizzare i dati in qualsiasi punto del flusso di lavoro.
- La possibilità di scrivere ed eseguire SQL in una cella che può fare riferimento alle variabili Python del notebook.
- Visualizzazione interattiva di DataFrame che supporta l'aggregazione e la personalizzazione.
Puoi iniziare a utilizzare i notebook utilizzando i modelli della galleria di notebook. Per ulteriori informazioni, vedi Creare un notebook utilizzando la galleria di notebook.
BigQuery DataFrames
BigQuery DataFrames è un insieme di librerie Python open source che ti consentono di sfruttare l'elaborazione dei dati BigQuery utilizzando API Python familiari. BigQuery DataFrames implementa le API pandas e scikit-learn trasferendo l'elaborazione a BigQuery tramite la conversione SQL. Questo design ti consente di utilizzare BigQuery per esplorare ed elaborare terabyte di dati, nonché di addestrare modelli ML, il tutto con le API Python.
BigQuery DataFrames offre i seguenti vantaggi:
- Oltre 750 API pandas e scikit-learn implementate tramite la conversione SQL trasparente in BigQuery e le API BigQuery ML.
- Esecuzione differita delle query per prestazioni migliori.
- Estensione delle trasformazioni dei dati con funzioni Python definite dall'utente per consentirti di elaborare i dati nel cloud. Queste funzioni vengono implementate automaticamente come funzioni remote di BigQuery.
- Integrazione con Vertex AI per consentirti di utilizzare i modelli Gemini per la generazione di testo.
Altre soluzioni di analisi programmatica
In BigQuery sono disponibili anche le seguenti soluzioni di analisi programmatica.
Blocchi note Jupyter
Jupyter è un'applicazione open source basata sul web per la pubblicazione di notebook che contengono codice live, descrizioni testuali e visualizzazioni. Data scientist, specialisti di machine learning e studenti utilizzano comunemente questa piattaforma per attività come la pulizia e la trasformazione dei dati, la simulazione numerica, la modellazione statistica, la visualizzazione dei dati e il machine learning.
I notebook Jupyter sono basati sul kernel IPython, una potente shell interattiva che può interagire direttamente con BigQuery utilizzando IPython Magics per BigQuery. In alternativa, puoi accedere a BigQuery anche dalle istanze dei notebook Jupyter installando una delle librerie client di BigQuery disponibili. Puoi visualizzare i dati BigQuery GIS con i blocchi note Jupyter tramite l'estensione GeoJSON. Per ulteriori dettagli sull'integrazione di BigQuery, consulta il tutorial Visualizzazione dei dati di BigQuery in un blocco note Jupyter.
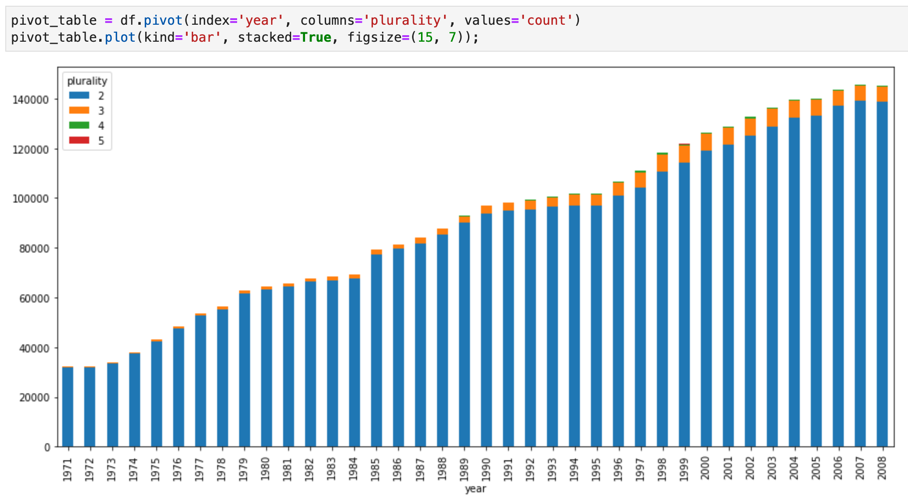
JupyterLab è un'interfaccia utente basata sul web per la gestione di documenti e attività come notebook Jupyter, editor di testo, terminali e componenti personalizzati. Con JupyterLab, puoi disporre più documenti e attività affiancati nell'area di lavoro utilizzando schede e separatori.
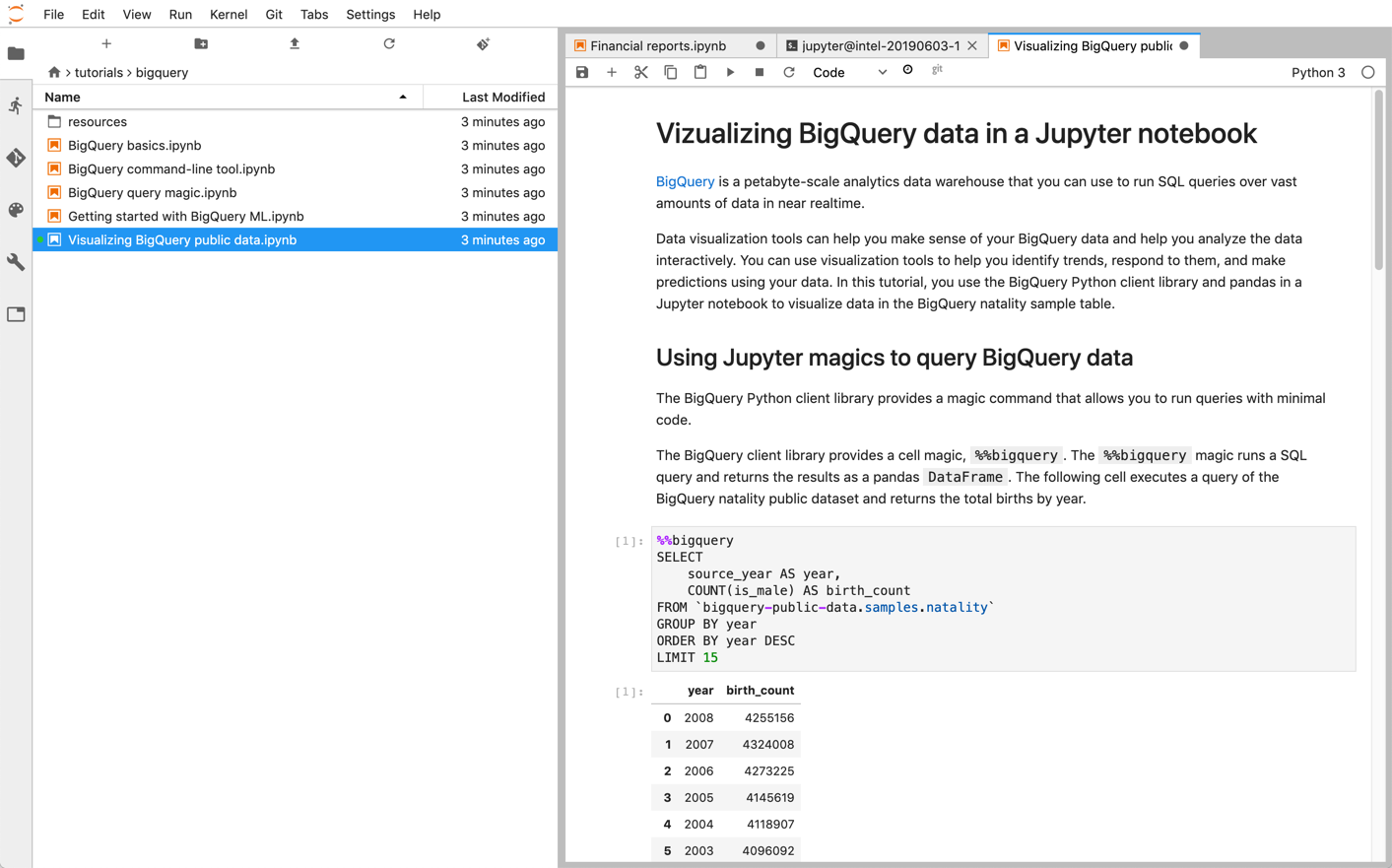
Puoi eseguire il deployment di notebook Jupyter e ambienti JupyterLab su Google Cloud utilizzando uno dei seguenti prodotti:
- Istanze Vertex AI Workbench, un servizio che offre un ambiente JupyterLab integrato in cui gli sviluppatori di machine learning e i data scientist possono utilizzare alcuni dei più recenti framework di data science e machine learning. Vertex AI Workbench è integrato con altri prodotti per i dati come BigQuery, semplificando il passaggio dall'importazione dati ai processi di pre-elaborazione ed esplorazione, fino ad arrivare all'addestramento e al deployment dei modelli. Google Cloud Per saperne di più, consulta Introduzione alle istanze di Vertex AI Workbench.
- Dataproc, un servizio completamente gestito, veloce e facile da utilizzare per eseguire i cluster Apache Spark e Apache Hadoop in modo semplice ed economico. Puoi installare i notebook Jupyter e JupyterLab su un cluster Dataproc utilizzando il componente facoltativo Jupyter. Il componente fornisce un kernel Python per eseguire il codice PySpark. Per impostazione predefinita, Dataproc configura automaticamente i blocchi note in modo che vengano salvati in Cloud Storage, rendendo gli stessi file del blocco note accessibili ad altri cluster. Quando esegui la migrazione dei notebook esistenti a Dataproc, verifica che le dipendenze dei notebook siano coperte dalle versioni di Dataproc supportate. Se devi installare software personalizzato, valuta la possibilità di creare una tua immagine Dataproc, scrivere le tue azioni di inizializzazione o specificare requisiti personalizzati per i pacchetti Python. Per iniziare, consulta il tutorial su Installazione ed esecuzione di un notebook Jupyter su un cluster Dataproc.
Apache Zeppelin
Apache Zeppelin
è un progetto open source che offre notebook basati su web per l'analisi dei dati.
Puoi eseguire il deployment di un'istanza di Apache Zeppelin su
Dataproc
installando il
componente facoltativo Zeppelin.
Per impostazione predefinita, i blocchi note vengono salvati in Cloud Storage nel bucket gestione temporanea Dataproc, specificato dall'utente o creato automaticamente al momento della creazione del cluster. Puoi modificare la posizione del blocco note
aggiungendo la proprietà zeppelin:zeppelin.notebook.gcs.dir quando crei il
cluster. Per ulteriori informazioni sull'installazione e la configurazione di Apache Zeppelin,
consulta la
guida al componente Zeppelin.
Per un esempio, vedi
Analizzare i set di dati BigQuery utilizzando l'interprete BigQuery per Apache Zeppelin.
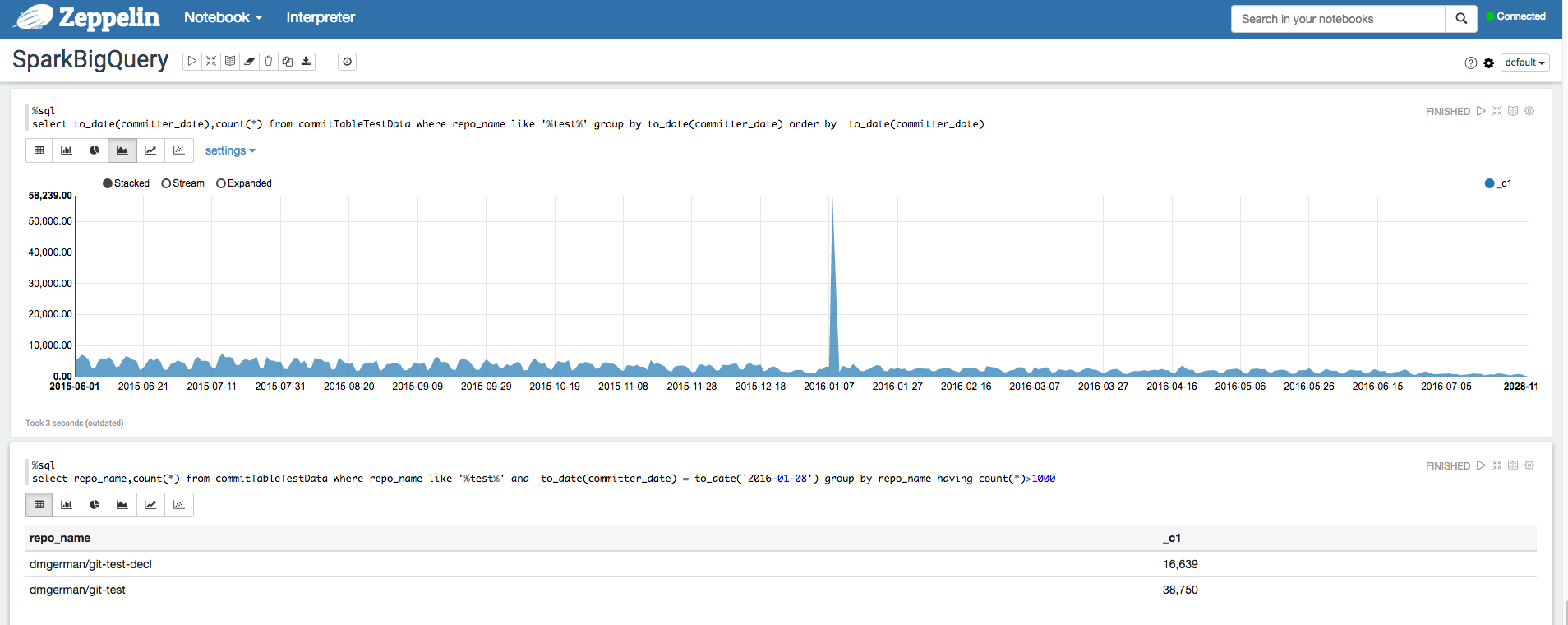
Apache Hadoop, Apache Spark e Apache Hive
Per una parte della migrazione della pipeline di analisi dei dati, potresti voler eseguire la migrazione di alcuni job Apache Hadoop, Apache Spark o Apache Hive legacy che devono elaborare direttamente i dati dal data warehouse. Ad esempio, potresti estrarre funzionalità per i tuoi carichi di lavoro di machine learning.
Dataproc consente di eseguire il deployment di cluster Hadoop e Spark completamente gestiti in modo efficiente ed economico. Dataproc si integra con i connettori BigQuery open source. Questi connettori utilizzano l'API BigQuery Storage, che trasmette i dati in parallelo direttamente da BigQuery tramite gRPC.
Quando esegui la migrazione dei tuoi carichi di lavoro Hadoop e Spark esistenti a Dataproc, puoi verificare che le dipendenze dei tuoi carichi di lavoro siano coperte dalle versioni di Dataproc supportate. Se devi installare software personalizzato, potresti prendere in considerazione la possibilità di creare una tua immagine Dataproc, scrivere le tue azioni di inizializzazione o specificare requisiti personalizzati per i pacchetti Python.
Per iniziare, consulta le guide di avvio rapido di Dataproc e gli esempi di codice del connettore BigQuery.
Apache Beam
Apache Beam è un framework open source che fornisce un ricco set di primitive per windowing e analisi delle sessioni, nonché un ecosistema di connettori di origine e sink, tra cui un connettore per BigQuery. Apache Beam consente di trasformare e arricchire i dati in modalità flusso (in tempo reale) e batch (storici) con affidabilità ed espressività garantite.
Dataflow è un servizio completamente gestito per l'esecuzione di job Apache Beam su larga scala. L'approccio serverless di Dataflow elimina i problemi di overhead operativo in quanto prestazioni, scalabilità, disponibilità, sicurezza e conformità vengono gestite automaticamente. In questo modo puoi concentrarti sulla programmazione invece che sulla gestione dei cluster di server.
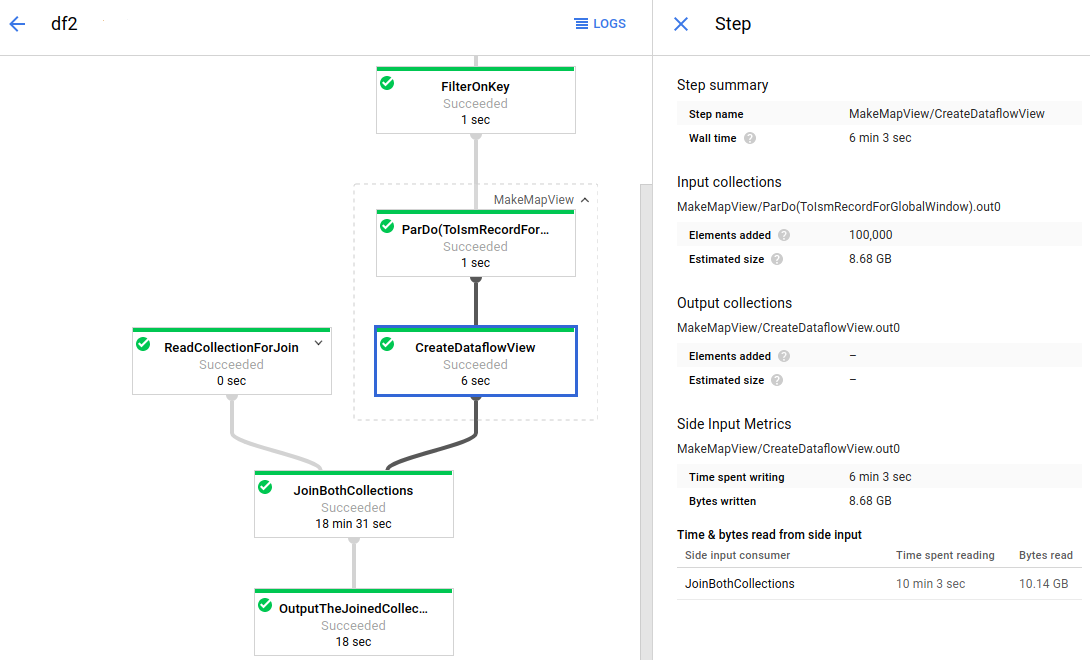
Puoi inviare job Dataflow in diversi modi, tramite l'interfaccia a riga di comando, l'SDK Java o l'SDK Python.
Se vuoi eseguire la migrazione delle query e delle pipeline di dati da altri framework ad Apache Beam e Dataflow, leggi il modello di programmazione Apache Beam e sfoglia la documentazione di Dataflow ufficiale.
Altre risorse
BigQuery offre un'ampia gamma di librerie client in più linguaggi di programmazione, come Java, Go, Python, JavaScript, PHP e Ruby. Alcuni framework di analisi dei dati, come pandas, forniscono plug-in che interagiscono direttamente con BigQuery. Per alcuni esempi pratici, consulta l'esercitazione Visualizzare i dati di BigQuery in un blocco note Jupyter.
Infine, se preferisci scrivere programmi in un ambiente shell, puoi utilizzare lo strumento a riga di comando bq.