分区表简介
分区表分成多个区段(称为分区),可让您更轻松地管理和查询数据。通过将大型表划分为较小的分区,可以改善查询性能;通过减少查询读取的字节数,可以控制费用。通过指定用于将表分段的分区列来对表进行分区。
如果查询对分区列的值使用符合条件的过滤条件,则 BigQuery 可以扫描与过滤条件匹配的分区并跳过其余分区。此过程称为“删减”。
在分区表中,数据存储在物理块中,而每个物理块都包含一个数据分区。每个分区表都会维护修改它的所有操作的相关排序属性的各种元数据。元数据可让 BigQuery 在查询运行之前更准确地估算查询费用。
何时使用分区
在以下情况下,请考虑对表进行分区:
- 您希望仅扫描表的一部分以改善查询性能。
- 表操作超出标准表配额,您可以将表操作的范围限定为特定的分区列值,从而增加分区表配额。
- 您希望在查询运行之前确定查询费用。在对分区表运行查询之前,BigQuery 会提供查询费用估算。通过删减分区表计算查询费用估算,然后发出查询试运行来估算查询费用。
- 您需要以下任意分区级管理功能:
在以下情况下,请考虑对表进行聚簇,而不是对表进行分区:
- 您需要比分区允许更多的粒度。
- 您的查询通常对多个列使用过滤器或聚合。
- 一列或多列中值数量的基数较大。
- 查询执行前无需严格的费用估算。
- 分区会生成每个分区的少量数据(约为 10 GB)。创建许多小型分区会增加表的元数据,并在查询表时影响元数据访问时间。
- 分区会产生大量分区,超出分区表的限制。
- 您的 DML 操作会经常修改(例如,每隔几分钟)表中的大多数分区。
在这种情况下,表聚簇可让您根据用户定义的排序属性对特定列中的数据进行聚簇,从而加快查询速度。
您还可以结合使用聚簇和表分区来实现更精细的排序。如需详细了解此方法,请参阅结合使用聚簇表和分区表。
分区类型
本部分介绍对表进行分区的不同方法。
整数范围分区
您可以按照特定 INTEGER 列中的值范围对表进行分区。如需创建整数范围分区表,请提供以下各项:
- 分区列。
- 范围分区的起始值(含边界值)。
- 范围分区的终止值(不含边界值)。
- 分区中每个范围的间隔值。
例如,假设您使用以下规范创建了一个整数范围分区:
| 参数 | 值 |
|---|---|
| 列名 | customer_id |
| start | 0 |
| end | 100 |
| interval | 10 |
表将按 customer_id 列进行范围分区,间隔值为 10。值 0 到 9 进入一个分区,值 10 到 19 进入下一个分区,以此类推,最多 99 个。此范围以外的值会进入名为 __UNPARTITIONED__ 的分区中。customer_id 为 NULL 的所有行都会进入名为 __NULL__ 的分区。
如需了解整数范围分区表,请参阅创建整数范围分区表。
时间单位列分区
您可以按照表的 DATE、TIMESTAMP 或 DATETIME 列对表进行分区。当您将数据写入表时,BigQuery 会根据列中的值自动将数据放入正确的分区。
对于 TIMESTAMP 和 DATETIME 列,分区可以具有每小时、每天、每月或每年的时间粒度。对于 DATE 列,分区可以具有每天、每月或每年的时间粒度。分区边界基于世界协调时间 (UTC)。
例如,假设您对包含 DATETIME 列的表按月分区。如果您将以下值插入表中,则行会写入以下分区:
| 列值 | 分区(每月) |
|---|---|
DATETIME("2019-01-01") |
201901 |
DATETIME("2019-01-15") |
201901 |
DATETIME("2019-04-30") |
201904 |
此外,系统会创建两个特殊分区:
__NULL__:包含分区列中具有NULL值的行。__UNPARTITIONED__:包含分区列的值早于 1960-01-01 或晚于 2159-12-31 的行。
如需了解时间单位列分区表,请参阅创建时间单位列分区表。
提取时间分区
当您创建按提取时间分区的表时,BigQuery 会根据 BigQuery 提取数据时的时间自动将行分配到分区。您可以为分区选择每小时、每天、每月或每年的时间粒度。分区边界基于世界协调时间 (UTC)。
如果使用较精细的时间粒度时,数据可能会达到每个表的分区数上限,请改用较粗的粒度。例如,您可以按月而非按日进行分区,以减少分区数量。 您还可以对分区列进行聚簇,以进一步提高性能。
注入时间分区表具有名为 _PARTITIONTIME 的伪列。此列的值是每行的提取时间,截断至分区边界(例如每小时或每天)。例如,假设您创建了一个每小时分区的注入时间分区表,并在以下时间发送数据:
| 提取时间 | _PARTITIONTIME |
分区(每小时) |
|---|---|---|
| 2021-05-07 17:22:00 | 2021-05-07 17:00:00 | 2021050717 |
| 2021-05-07 17:40:00 | 2021-05-07 17:00:00 | 2021050717 |
| 2021-05-07 18:31:00 | 2021-05-07 18:00:00 | 2021050718 |
由于本例中的表使用每小时分区,因此 _PARTITIONTIME 的值被截断到小时边界。BigQuery 使用此值来确定数据的正确分区。
您还可以将数据写入特定分区。例如,您可能需要加载历史数据或根据时区进行调整。您可以使用 0001-01-01 和 9999-12-31 之间的任何有效日期。但是,DML 语句不能引用 1970-01-01 之前或 2159-12-31 之后的日期。如需了解详情,请参阅将数据写入特定分区。
除了使用 _PARTITIONTIME,您还可以使用 _PARTITIONDATE。
_PARTITIONDATE 伪列包含与 _PARTITIONTIME 伪列中的值对应的世界协调时间 (UTC) 日期。
选择每日、每小时、每月或每年分区
按时间单位列或提取时间对表进行分区时,您可以选择分区是具有每日、每小时、每月还是每年的时间粒度。
每日分区是默认分区类型。如果您的数据分布于多个日期范围内,或者如果数据随时间不断增加,则每日分区是一个不错的选择。
如果您的表包含大量数据,且这些数据覆盖一个较短的日期范围(时间戳值通常小于六个月),请选择每小时分区。如果选择每小时分区,请确保分区数量不超出分区限制范围。
如果您的表每天包含的数据量相对较少,但覆盖的日期范围很广,请选择每月或每年分区。如果您的工作流需要频繁更新或添加覆盖较广日期范围的行(例如超过 500 个日期),我们也建议您使用此选项。在这些场景中,请对分区列使用每月或每年分区以及聚簇操作,以获得最佳性能。如需了解详情,请参阅本文档中的结合使用聚簇表和分区表。
结合使用聚簇表和分区表
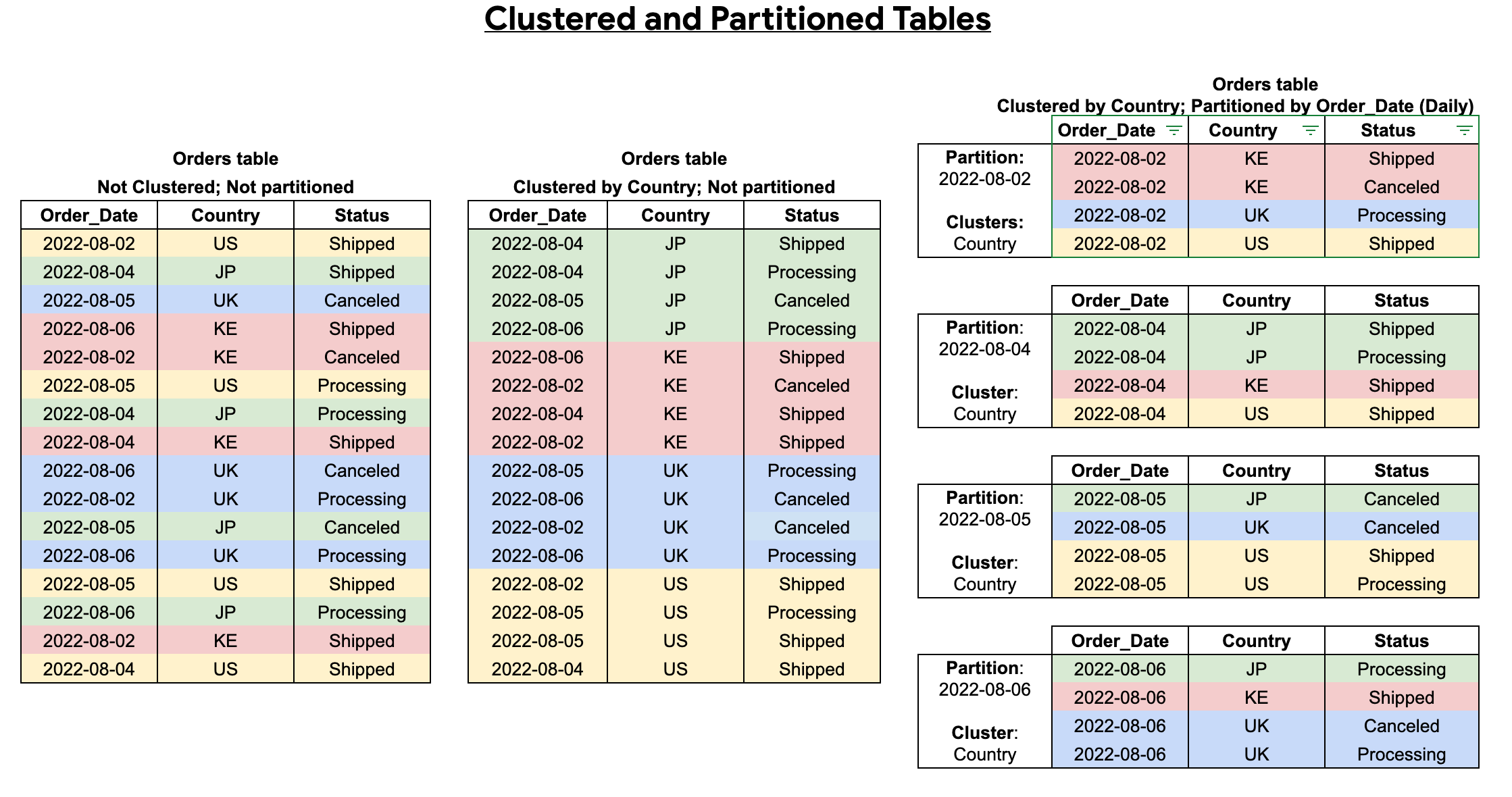
您可以结合使用表分区与表聚簇以实现精细的排序,从而进一步优化查询。
聚簇表包含根据用户定义的排序属性对数据进行排序的聚簇列。这些聚簇列中的数据会被分类为多个存储块,这些存储块根据表的大小进行自适应调整。当您运行按聚簇列过滤的查询时,BigQuery 仅根据聚簇列而不是相关表或表分区扫描相关块。在同时使用表分区和聚簇的方法中,首先将表数据分段为分区,然后按聚簇列对每个分区中的数据进行聚簇。
创建聚簇和分区的表时,您可以实现更精细的排序,如下图所示:
分区与分片的比较
表分片是使用 [PREFIX]_YYYYMMDD 等命名前缀将数据存储到多个表中的做法。
更推荐使用分区而不是表分片,因为分区表性能更佳。对于分片表,BigQuery 必须为每个表保留架构和元数据的副本。BigQuery 可能还需要分别为每个要查询的表验证权限。该做法也会增加查询开销,影响查询性能。
如果您之前创建了日期分片表,可以将其转换为注入时间分区表。如需了解详情,请参阅将日期分片表转换为提取时间分区表。
分区修饰器
通过分区修饰器,您可以引用表中的分区。例如,您可以使用分区修饰器将数据写入特定分区。
分区修饰器采用 table_name$partition_id 格式,其中 partition_id 部分的格式取决于分区类型:
| 分区类型 | 格式 | 示例 |
|---|---|---|
| 每小时 | yyyymmddhh |
my_table$2021071205 |
| 每天 | yyyymmdd |
my_table$20210712 |
| 每月 | yyyymm |
my_table$202107 |
| 每年 | yyyy |
my_table$2021 |
| 整数范围 | range_start |
my_table$40 |
浏览分区中的数据
如需浏览指定分区中的数据,请使用 bq head 命令和分区修饰器。
例如,以下命令会列出 2018-02-24 分区中 my_dataset.my_table 的前 10 行的所有字段:
bq head --max_rows=10 'my_dataset.my_table$20180224'
导出表数据
从分区表导出全部数据的方法与从非分区表导出数据的方法相同。如需了解详情,请参阅导出表数据。
如需导出单个分区中的数据,请使用 bq extract 命令并将分区修饰器附加到表名称。例如 my_table$20160201。您还可以通过将分区名称附加到表名称,导出 __NULL__ 和 __UNPARTITIONED__ 分区中的数据。例如 my_table$__NULL__ 或 my_table$__UNPARTITIONED__。
限制
分区表存在以下限制:
不能使用旧版 SQL 查询分区表,也不能将查询结果写入分区表中。
BigQuery 不支持按多列进行分区。只能根据一列对表进行分区。
您无法直接将现有的非分区表转换为分区表。分区策略是在创建表时定义的。请改为使用
CREATE TABLE语句,通过查询现有表中的数据来创建新的分区表。时间单位列分区表存在如下限制:
- 分区列必须是标量
DATE、TIMESTAMP或DATETIME列。虽然列模式可以是REQUIRED或NULLABLE,但不能是REPEATED(基于数组)。 - 此外,分区列必须是顶级字段。不能将
RECORD(STRUCT) 中的叶级字段用作分区列。
如需了解时间单位列分区表,请参阅创建时间单位列分区表。
- 分区列必须是标量
整数范围分区表存在如下限制:
- 分区列必须为
INTEGER列。虽然列模式可以是REQUIRED或NULLABLE,但不能是REPEATED(基于数组)。 - 此外,分区列必须是顶级字段。不能将
RECORD(STRUCT) 中的叶级字段用作分区列。
如需了解整数范围分区表,请参阅创建整数范围分区表。
- 分区列必须为
配额和限制
分区表在 BigQuery 中有确定的限制。
配额和限制也适用于针对分区表运行的不同类型的作业,其中包括:
如需详细了解所有配额和限制,请参阅配额和限制。
表价格
在 BigQuery 中创建和使用分区表时,您的费用取决于分区中存储的数据量以及对数据运行的查询:
很多分区表操作都是免费的,包括将数据加载到分区、复制分区,以及从分区导出数据。这些操作虽然免费,但是受 BigQuery 的配额和限制约束。如需了解所有免费操作,请参阅价格页面上的免费操作。
如需了解在 BigQuery 中控制费用的最佳实践,请参阅控制 BigQuery 费用
表安全性
分区表的访问权限控制与标准表的访问权限控制相同。如需了解详情,请参阅表访问权限控制简介。