Menentukan kolom bertingkat dan berulang dalam skema tabel
Halaman ini menjelaskan cara menentukan skema tabel dengan kolom bertingkat dan berulang di BigQuery. Untuk ringkasan skema tabel, lihat Menentukan skema.
Menentukan kolom bertingkat dan berulang
Untuk membuat kolom dengan data bertingkat, setel jenis data kolom ke
RECORD dalam skema. RECORD dapat diakses sebagai
jenis STRUCT
di GoogleSQL. STRUCT adalah penampung kolom yang diurutkan.
Untuk membuat kolom dengan data berulang, setel
mode kolom ke REPEATED dalam skema.
Kolom berulang dapat diakses sebagai
jenis ARRAY di
GoogleSQL.
Kolom RECORD dapat memiliki mode REPEATED, yang direpresentasikan sebagai array
jenis STRUCT. Selain itu, kolom dalam kumpulan data dapat diulang, yang
direpresentasikan sebagai STRUCT yang berisi ARRAY. Array tidak boleh berisi
array lain secara langsung. Untuk informasi selengkapnya, lihat
Mendeklarasikan jenis ARRAY.
Batasan
Skema bertingkat dan berulang tunduk pada batasan berikut:
- Skema tidak boleh berisi lebih dari 15 tingkat jenis
RECORDbertingkat. - Kolom jenis
RECORDdapat berisi jenisRECORDbertingkat, yang juga disebut kumpulan data turunan. Batas kedalaman maksimum bertingkat adalah 15 tingkat. Batas ini tidak bergantung pada apakahRECORDberbasis skalar atau array (berulang).
Jenis RECORD tidak kompatibel dengan UNION, INTERSECT, EXCEPT DISTINCT, dan SELECT DISTINCT.
Contoh skema
Contoh berikut menunjukkan contoh data bertingkat dan berulang. Tabel ini berisi informasi tentang orang. Terdiri dari kolom berikut:
idfirst_namelast_namedob(Tanggal lahir)addresses(kolom bertingkat dan berulang)addresses.status(saat ini atau sebelumnya)addresses.addressaddresses.cityaddresses.stateaddresses.zipaddresses.numberOfYears(tahun di alamat)
File data JSON akan terlihat seperti berikut. Perhatikan bahwa kolom
alamat berisi array nilai (ditunjukkan dengan [ ]). Beberapa alamat
dalam array adalah data berulang. Beberapa kolom dalam setiap alamat adalah
data bertingkat.
{"id":"1","first_name":"John","last_name":"Doe","dob":"1968-01-22","addresses":[{"status":"current","address":"123 First Avenue","city":"Seattle","state":"WA","zip":"11111","numberOfYears":"1"},{"status":"previous","address":"456 Main Street","city":"Portland","state":"OR","zip":"22222","numberOfYears":"5"}]}
{"id":"2","first_name":"Jane","last_name":"Doe","dob":"1980-10-16","addresses":[{"status":"current","address":"789 Any Avenue","city":"New York","state":"NY","zip":"33333","numberOfYears":"2"},{"status":"previous","address":"321 Main Street","city":"Hoboken","state":"NJ","zip":"44444","numberOfYears":"3"}]}
Skema untuk tabel ini terlihat seperti berikut:
[ { "name": "id", "type": "STRING", "mode": "NULLABLE" }, { "name": "first_name", "type": "STRING", "mode": "NULLABLE" }, { "name": "last_name", "type": "STRING", "mode": "NULLABLE" }, { "name": "dob", "type": "DATE", "mode": "NULLABLE" }, { "name": "addresses", "type": "RECORD", "mode": "REPEATED", "fields": [ { "name": "status", "type": "STRING", "mode": "NULLABLE" }, { "name": "address", "type": "STRING", "mode": "NULLABLE" }, { "name": "city", "type": "STRING", "mode": "NULLABLE" }, { "name": "state", "type": "STRING", "mode": "NULLABLE" }, { "name": "zip", "type": "STRING", "mode": "NULLABLE" }, { "name": "numberOfYears", "type": "STRING", "mode": "NULLABLE" } ] } ]
Menentukan kolom bertingkat dan berulang dalam contoh
Untuk membuat tabel baru dengan kolom bertingkat dan berulang sebelumnya, pilih salah satu opsi berikut:
Konsol
Tentukan kolom addresses bertingkat dan berulang:
Di Google Cloud konsol, buka halaman BigQuery.
Di panel Penjelajah, luaskan project Anda dan pilih set data.
Di panel detail, klik Buat tabel.
Di halaman Buat tabel, tentukan detail berikut:
- Untuk Sumber, di kolom Buat tabel dari, pilih Tabel kosong.
Di bagian Tujuan, tentukan kolom berikut:
- Untuk Set data, pilih set data tempat Anda ingin membuat tabel.
- Untuk Tabel, masukkan nama tabel yang ingin Anda buat.
Untuk Skema, klik Tambah kolom, lalu masukkan skema tabel berikut:
- Untuk Nama kolom, masukkan
addresses. - Untuk Jenis, pilih KUMPULAN DATA.
- Untuk Mode, pilih BERULANG.
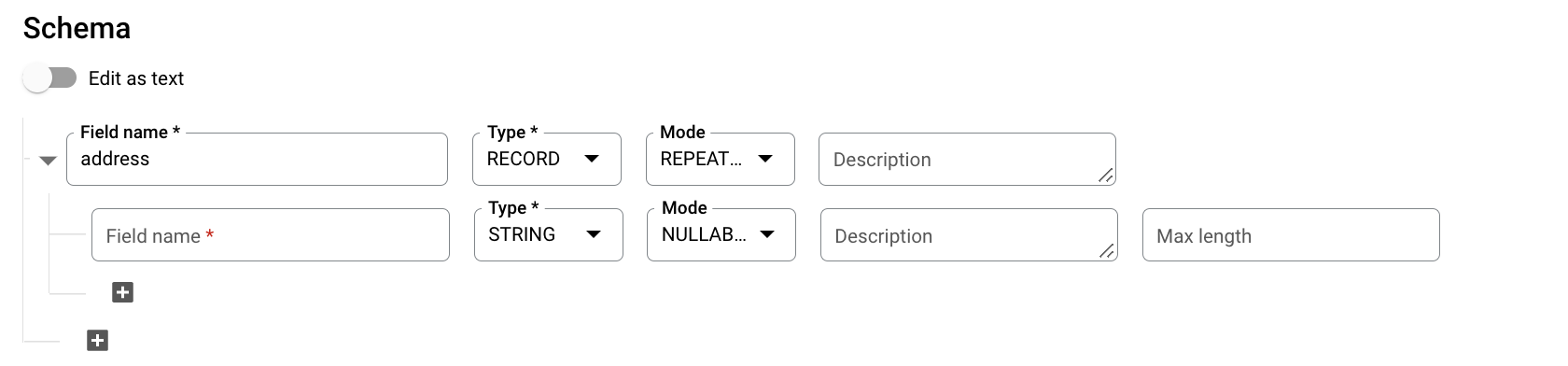
Tentukan kolom berikut untuk kolom bertingkat:
- Di kolom Nama kolom, masukkan
status. - Untuk Jenis, pilih STRING.
- Untuk Mode, biarkan nilai disetel ke NULLABLE.
Klik Tambah kolom untuk menambahkan kolom berikut:
Nama kolom Jenis Mode addressSTRINGNULLABLEcitySTRINGNULLABLEstateSTRINGNULLABLEzipSTRINGNULLABLEnumberOfYearsSTRINGNULLABLE
Atau, klik Edit sebagai teks dan tentukan skema sebagai array JSON.
- Di kolom Nama kolom, masukkan
- Untuk Nama kolom, masukkan
SQL
Gunakan
pernyataan CREATE TABLE.
Tentukan skema menggunakan
opsi
kolom:
Di Google Cloud konsol, buka halaman BigQuery.
Di editor kueri, masukkan pernyataan berikut:
CREATE TABLE IF NOT EXISTS mydataset.mytable ( id STRING, first_name STRING, last_name STRING, dob DATE, addresses ARRAY< STRUCT< status STRING, address STRING, city STRING, state STRING, zip STRING, numberOfYears STRING>> ) OPTIONS ( description = 'Example name and addresses table');
Klik Run.
Untuk mengetahui informasi selengkapnya tentang cara menjalankan kueri, lihat artikel Menjalankan kueri interaktif.
bq
Untuk menentukan kolom addresses bertingkat dan berulang dalam file skema JSON,
gunakan editor teks untuk membuat file baru. Tempel contoh definisi skema
yang ditunjukkan di atas.
Setelah membuat file skema JSON, Anda dapat menyediakannya melalui alat command line bq. Untuk mengetahui informasi selengkapnya, lihat Menggunakan file skema JSON.
Go
Sebelum mencoba contoh ini, ikuti petunjuk penyiapan Go di Panduan memulai BigQuery menggunakan library klien. Untuk mengetahui informasi selengkapnya, lihat Dokumentasi referensi BigQuery Go API.
Untuk melakukan autentikasi ke BigQuery, siapkan Kredensial Default Aplikasi. Untuk mengetahui informasi selengkapnya, lihat Menyiapkan autentikasi untuk library klien.
Java
Sebelum mencoba contoh ini, ikuti petunjuk penyiapan Java di Panduan memulai BigQuery menggunakan library klien. Untuk mengetahui informasi selengkapnya, lihat Dokumentasi referensi BigQuery Java API.
Untuk melakukan autentikasi ke BigQuery, siapkan Kredensial Default Aplikasi. Untuk mengetahui informasi selengkapnya, lihat Menyiapkan autentikasi untuk library klien.
Node.js
Sebelum mencoba contoh ini, ikuti petunjuk penyiapan Node.js di Panduan memulai BigQuery menggunakan library klien. Untuk mengetahui informasi selengkapnya, lihat Dokumentasi referensi BigQuery Node.js API.
Untuk melakukan autentikasi ke BigQuery, siapkan Kredensial Default Aplikasi. Untuk mengetahui informasi selengkapnya, lihat Menyiapkan autentikasi untuk library klien.
Python
Sebelum mencoba contoh ini, ikuti petunjuk penyiapan Python di Panduan memulai BigQuery menggunakan library klien. Untuk mengetahui informasi selengkapnya, lihat Dokumentasi referensi BigQuery Python API.
Untuk melakukan autentikasi ke BigQuery, siapkan Kredensial Default Aplikasi. Untuk mengetahui informasi selengkapnya, lihat Menyiapkan autentikasi untuk library klien.
Menyisipkan data di kolom bertingkat dalam contoh
Gunakan kueri berikut untuk menyisipkan kumpulan data bertingkat ke dalam tabel yang memiliki kolom jenis data RECORD.
Contoh 1
INSERT INTO mydataset.mytable (id, first_name, last_name, dob, addresses) values ("1","Johnny","Dawn","1969-01-22", ARRAY< STRUCT< status STRING, address STRING, city STRING, state STRING, zip STRING, numberOfYears STRING>> [("current","123 First Avenue","Seattle","WA","11111","1")])
Contoh 2
INSERT INTO mydataset.mytable (id, first_name, last_name, dob, addresses) values ("1","Johnny","Dawn","1969-01-22",[("current","123 First Avenue","Seattle","WA","11111","1")])
Mengkueri kolom bertingkat dan berulang
Untuk memilih nilai ARRAY di posisi tertentu, gunakan operator subskrip
array.
Untuk mengakses elemen dalam STRUCT, gunakan
operator titik.
Contoh berikut memilih nama depan, nama belakang, dan alamat pertama
yang tercantum di kolom addresses:
SELECT first_name, last_name, addresses[offset(0)].address FROM mydataset.mytable;
Hasilnya adalah sebagai berikut:
+------------+-----------+------------------+ | first_name | last_name | address | +------------+-----------+------------------+ | John | Doe | 123 First Avenue | | Jane | Doe | 789 Any Avenue | +------------+-----------+------------------+
Untuk mengekstrak semua elemen ARRAY, gunakan
operator UNNEST
dengan CROSS JOIN.
Contoh berikut memilih nama depan, nama belakang, alamat, dan negara bagian untuk
semua alamat yang tidak berlokasi di New York:
SELECT first_name, last_name, a.address, a.state FROM mydataset.mytable CROSS JOIN UNNEST(addresses) AS a WHERE a.state != 'NY';
Hasilnya adalah sebagai berikut:
+------------+-----------+------------------+-------+ | first_name | last_name | address | state | +------------+-----------+------------------+-------+ | John | Doe | 123 First Avenue | WA | | John | Doe | 456 Main Street | OR | | Jane | Doe | 321 Main Street | NJ | +------------+-----------+------------------+-------+
Mengubah kolom bertingkat dan berulang
Setelah menambahkan kolom bertingkat atau kolom bertingkat dan berulang ke definisi skema tabel, Anda dapat mengubah kolom seperti yang biasa dilakukan pada jenis kolom lainnya. BigQuery secara native mendukung beberapa perubahan skema seperti menambahkan kolom bertingkat baru ke data atau melonggarkan mode kolom bertingkat. Untuk mengetahui informasi selengkapnya, lihat Mengubah skema tabel.
Kapan harus menggunakan kolom bertingkat dan berulang
BigQuery akan berfungsi optimal saat data Anda didenormalisasi. Daripada mempertahankan skema relasional seperti skema bintang atau kepingan salju, lakukan denormalisasi data dan manfaatkan kolom bertingkat dan berulang. Kolom bertingkat dan berulang dapat mempertahankan hubungan tanpa dampak performa dari mempertahankan skema relasional (dinormalisasi).
Misalnya, database relasional yang digunakan untuk melacak buku perpustakaan mungkin akan menyimpan
semua informasi penulis dalam tabel terpisah. Kunci seperti author_id akan
digunakan untuk menautkan buku ke penulis.
Di BigQuery, Anda dapat mempertahankan hubungan antara buku dan penulis tanpa membuat tabel penulis terpisah. Sebagai gantinya, Anda membuat kolom penulis, dan Anda menempatkan kolom di dalamnya seperti nama depan, nama belakang, tanggal lahir penulis, dan sebagainya. Jika buku memiliki beberapa penulis, Anda dapat membuat kolom penulis bertingkat berulang.
Misalkan Anda memiliki tabel mydataset.books berikut:
+------------------+------------+-----------+ | title | author_ids | num_pages | +------------------+------------+-----------+ | Example Book One | [123, 789] | 487 | | Example Book Two | [456] | 89 | +------------------+------------+-----------+
Anda juga memiliki tabel berikut, mydataset.authors, dengan informasi
lengkap untuk setiap ID penulis:
+-----------+-------------+---------------+ | author_id | author_name | date_of_birth | +-----------+-------------+---------------+ | 123 | Alex | 01-01-1960 | | 456 | Rosario | 01-01-1970 | | 789 | Kim | 01-01-1980 | +-----------+-------------+---------------+
Jika tabelnya besar, mungkin dibutuhkan sumber daya yang intensif untuk menggabungkannya secara rutin. Bergantung pada situasi Anda, akan bermanfaat jika membuat satu tabel yang berisi semua informasi:
CREATE TABLE mydataset.denormalized_books( title STRING, authors ARRAY<STRUCT<id INT64, name STRING, date_of_birth STRING>>, num_pages INT64) AS ( SELECT title, ARRAY_AGG(STRUCT(author_id, author_name, date_of_birth)) AS authors, ANY_VALUE(num_pages) FROM mydataset.books, UNNEST(author_ids) id JOIN mydataset.authors ON id = author_id GROUP BY title );
Tabel yang dihasilkan akan terlihat seperti berikut:
+------------------+-------------------------------+-----------+
| title | authors | num_pages |
+------------------+-------------------------------+-----------+
| Example Book One | [{123, Alex, 01-01-1960}, | 487 |
| | {789, Kim, 01-01-1980}] | |
| Example Book Two | [{456, Rosario, 01-01-1970}] | 89 |
+------------------+-------------------------------+-----------+
BigQuery mendukung pemuatan data bertingkat dan berulang dari format sumber yang mendukung skema berbasis objek, seperti file JSON, file Avro, file ekspor Firestore, dan file ekspor Datastore.
Menghapus kumpulan data duplikat dalam tabel
Kueri berikut menggunakan fungsi row_number()
untuk mengidentifikasi kumpulan data duplikat yang memiliki nilai yang sama untuk
last_name dan first_name dalam contoh yang digunakan dan mengurutkannya menurut dob:
CREATE OR REPLACE TABLE mydataset.mytable AS ( SELECT * except(row_num) FROM ( SELECT *, row_number() over (partition by last_name, first_name order by dob) row_num FROM mydataset.mytable) temp_table WHERE row_num=1 )
Keamanan tabel
Untuk mengontrol akses ke tabel di BigQuery, lihat Mengontrol akses ke resource dengan IAM.
Langkah berikutnya
- Untuk menyisipkan dan memperbarui baris dengan kolom bertingkat dan berulang, lihat Sintaksis bahasa pengolahan data.