Tutorial sulla migrazione da Teradata a BigQuery
Questo documento descrive come eseguire la migrazione da Teradata a BigQuery utilizzando dati di esempio. Fornisce una proof-of-concept che illustra la procedura di trasferimento di schema e dati da un data warehouse Teradata a BigQuery.
Obiettivi
- Genera dati sintetici e caricali su Teradata.
- Esegui la migrazione dello schema e dei dati a BigQuery utilizzando BigQuery Data Transfer Service (BQDT).
- Verifica che le query restituiscano gli stessi risultati su Teradata e BigQuery.
Costi
Questa guida rapida utilizza i seguenti componenti fatturabili di Google Cloud:
- BigQuery: Questo tutorial archivia quasi 1 GB di dati in BigQuery ed elabora meno di 2 GB quando esegui le query una volta. Nell'ambito del Google Cloud livello gratuito, BigQuery offre alcune risorse gratuitamente entro limiti specifici. Questi limiti di utilizzo gratuito sono disponibili sia durante che dopo il periodo di prova gratuita. Se superi questi limiti di utilizzo e il tuo periodo di prova gratuita è scaduto, ti verranno addebitate le tariffe previste, come indicato nella pagina Prezzi di BigQuery.
Puoi utilizzare il calcolatore prezzi per generare una stima dei costi in base all'utilizzo previsto.
Prerequisiti
- Assicurati di disporre delle autorizzazioni di scrittura ed esecuzione in una macchina che ha accesso a internet, in modo da poter scaricare ed eseguire lo strumento di generazione dei dati.
- Assicurati di poterti connettere a un database Teradata.
Assicurati che sulla macchina siano installati gli strumenti client Teradata BTEQ e FastLoad. Puoi scaricare gli strumenti client Teradata dal sito web di Teradata. Se hai bisogno di aiuto per installare questi strumenti, chiedi al tuo amministratore di sistema informazioni dettagliate su come installarli, configurarli ed eseguirli. In alternativa o in aggiunta a BTEQ, puoi procedere nel seguente modo:
- Installa uno strumento con un'interfaccia grafica come DBeaver.
- Installa il driver SQL di Teradata per Python per lo scripting delle interazioni con il database Teradata.
Assicurati che la macchina abbia la connettività di rete con Google Cloud affinché l'agente BigQuery Data Transfer Service possa comunicare con BigQuery e trasferire lo schema e i dati.
Introduzione
Questa guida rapida ti illustra una proof of concept della migrazione. Durante l'avvio rapido, generi dati sintetici e li carichi in Teradata. Poi utilizzi il BigQuery Data Transfer Service per spostare lo schema e i dati in BigQuery. Infine, esegui query su entrambi i lati per confrontare i risultati. Lo stato finale è che lo schema e i dati di Teradata vengono mappati uno a uno in BigQuery.
Questa guida rapida è pensata per amministratori, sviluppatori e professionisti dei dati in generale interessati a un'esperienza pratica con la migrazione di schema e dati utilizzando BigQuery Data Transfer Service.
Generazione dei dati
Il Transaction Processing Performance Council (TPC) è un'organizzazione non profit che pubblica specifiche di benchmarking. Queste specifiche sono diventate standard di settore de facto per l'esecuzione di benchmark correlati ai dati.
La specifica TPC-H è un benchmark incentrato sul supporto decisionale. In questa guida rapida, utilizzerai parti di questa specifica per creare le tabelle e generare dati sintetici come modello di un data warehouse reale. Sebbene la specifica sia stata creata per il benchmarking, in questa guida rapida utilizzi questo modello come parte della migrazione proof of concept, non per le attività di benchmarking.
- Sul computer a cui ti connetterai a Teradata, utilizza un browser web per scaricare l'ultima versione disponibile degli strumenti TPC-H dal sito web TPC.
- Apri un terminale dei comandi e passa alla directory in cui hai scaricato gli strumenti.
Estrai il file ZIP scaricato. Sostituisci file-name con il nome del file che hai scaricato:
unzip file-name.zip
Viene estratta una directory il cui nome include il numero di versione degli strumenti. Questa directory include il codice sorgente TPC per lo strumento di generazione dei dati DBGEN e la specifica TPC-H.
Vai alla sottodirectory
dbgen. Utilizza il nome della directory principale corrispondente alla tua versione, come nel seguente esempio:cd 2.18.0_rc2/dbgenCrea un makefile utilizzando il modello fornito:
cp makefile.suite makefileModifica il makefile con un editor di testo. Ad esempio, utilizza vi per modificare il file:
vi makefileNel makefile, modifica i valori delle seguenti variabili:
CC = gcc # TDAT -> TERADATA DATABASE = TDAT MACHINE = LINUX WORKLOAD = TPCHA seconda dell'ambiente, il compilatore C (
CC) o i valoriMACHINEpotrebbero essere diversi. Se necessario, rivolgiti all'amministratore di sistema.Salva le modifiche e chiudi il file.
Elabora il makefile:
makeGenera i dati TPC-H utilizzando lo strumento
dbgen:dbgen -vLa generazione dei dati richiede un paio di minuti. Il flag
-v(dettagliato) fa sì che il comando riporti l'avanzamento. Al termine della generazione dei dati, troverai 8 file ASCII con estensione.tblnella cartella corrente. Contengono dati sintetici delimitati da una barra verticale da caricare in ciascuna delle tabelle TPC-H.
Caricamento dei dati di esempio su Teradata
In questa sezione, caricherai i dati generati nel database Teradata.
Crea il database TPC-H
Il client Teradata, chiamato Basic Teradata Query (BTEQ), viene utilizzato per comunicare con uno o più server di database Teradata ed eseguire query SQL su questi sistemi. In questa sezione utilizzerai BTEQ per creare un nuovo database per le tabelle TPC-H.
Apri il client Teradata BTEQ:
bteqAccedi a Teradata. Sostituisci teradata-ip e teradata-user con i valori corrispondenti per il tuo ambiente.
.LOGON teradata-ip/teradata-user
Crea un database denominato
tpchcon 2 GB di spazio allocato:CREATE DATABASE tpch AS PERM=2e+09;Esci da BTEQ:
.QUIT
Caricare i dati generati
In questa sezione, creerai uno script FastLoad per creare e caricare le tabelle di esempio. Le definizioni delle tabelle sono descritte nella sezione 1.4 delle specifiche TPC-H. La sezione 1.2 contiene un diagramma entità-relazioni dell'intero schema del database.
La seguente procedura mostra come creare la tabella lineitem, che è la più grande e complessa delle tabelle TPC-H. Al termine della
tabella lineitem, ripeti questa procedura per le tabelle rimanenti.
Con un editor di testo, crea un nuovo file denominato
fastload_lineitem.fl:vi fastload_lineitem.flCopia il seguente script nel file, che si connette al database Teradata e crea una tabella denominata
lineitem.Nel comando
logon, sostituisci teradata-ip, teradata-user e teradata-pwd con i dettagli della connessione.logon teradata-ip/teradata-user,teradata-pwd; drop table tpch.lineitem; drop table tpch.error_1; drop table tpch.error_2; CREATE multiset TABLE tpch.lineitem, NO FALLBACK, NO BEFORE JOURNAL, NO AFTER JOURNAL, CHECKSUM = DEFAULT, DEFAULT MERGEBLOCKRATIO ( L_ORDERKEY INTEGER NOT NULL, L_PARTKEY INTEGER NOT NULL, L_SUPPKEY INTEGER NOT NULL, L_LINENUMBER INTEGER NOT NULL, L_QUANTITY DECIMAL(15,2) NOT NULL, L_EXTENDEDPRICE DECIMAL(15,2) NOT NULL, L_DISCOUNT DECIMAL(15,2) NOT NULL, L_TAX DECIMAL(15,2) NOT NULL, L_RETURNFLAG CHAR(1) CHARACTER SET LATIN CASESPECIFIC NOT NULL, L_LINESTATUS CHAR(1) CHARACTER SET LATIN CASESPECIFIC NOT NULL, L_SHIPDATE DATE FORMAT 'yyyy-mm-dd' NOT NULL, L_COMMITDATE DATE FORMAT 'yyyy-mm-dd' NOT NULL, L_RECEIPTDATE DATE FORMAT 'yyyy-mm-dd' NOT NULL, L_SHIPINSTRUCT CHAR(25) CHARACTER SET LATIN CASESPECIFIC NOT NULL, L_SHIPMODE CHAR(10) CHARACTER SET LATIN CASESPECIFIC NOT NULL, L_COMMENT VARCHAR(44) CHARACTER SET LATIN CASESPECIFIC NOT NULL) PRIMARY INDEX ( L_ORDERKEY ) PARTITION BY RANGE_N(L_COMMITDATE BETWEEN DATE '1992-01-01' AND DATE '1998-12-31' EACH INTERVAL '1' DAY);Lo script verifica innanzitutto che la tabella
lineiteme le tabelle degli errori temporanei non esistano e procede alla creazione della tabellalineitem.Nello stesso file, aggiungi questo codice, che carica i dati nella tabella appena creata. Compila tutti i campi della tabella nei tre blocchi (
define,insertevalues), assicurandoti di utilizzarevarcharcome tipo di dati di caricamento.begin loading tpch.lineitem errorfiles tpch.error_1, tpch.error_2; set record vartext; define in_ORDERKEY(varchar(50)), in_PARTKEY(varchar(50)), in_SUPPKEY(varchar(50)), in_LINENUMBER(varchar(50)), in_QUANTITY(varchar(50)), in_EXTENDEDPRICE(varchar(50)), in_DISCOUNT(varchar(50)), in_TAX(varchar(50)), in_RETURNFLAG(varchar(50)), in_LINESTATUS(varchar(50)), in_SHIPDATE(varchar(50)), in_COMMITDATE(varchar(50)), in_RECEIPTDATE(varchar(50)), in_SHIPINSTRUCT(varchar(50)), in_SHIPMODE(varchar(50)), in_COMMENT(varchar(50)) file = lineitem.tbl; insert into tpch.lineitem ( L_ORDERKEY, L_PARTKEY, L_SUPPKEY, L_LINENUMBER, L_QUANTITY, L_EXTENDEDPRICE, L_DISCOUNT, L_TAX, L_RETURNFLAG, L_LINESTATUS, L_SHIPDATE, L_COMMITDATE, L_RECEIPTDATE, L_SHIPINSTRUCT, L_SHIPMODE, L_COMMENT ) values ( :in_ORDERKEY, :in_PARTKEY, :in_SUPPKEY, :in_LINENUMBER, :in_QUANTITY, :in_EXTENDEDPRICE, :in_DISCOUNT, :in_TAX, :in_RETURNFLAG, :in_LINESTATUS, :in_SHIPDATE, :in_COMMITDATE, :in_RECEIPTDATE, :in_SHIPINSTRUCT, :in_SHIPMODE, :in_COMMENT ); end loading; logoff;
Lo script FastLoad carica i dati da un file nella stessa directory denominato
lineitem.tbl, che hai generato nella sezione precedente.Salva le modifiche e chiudi il file.
Esegui lo script FastLoad:
fastload < fastload_lineitem.flRipeti questa procedura per le altre tabelle TPC-H elencate nella sezione 1.4 delle specifiche TPC-H. Assicurati di modificare i passaggi per ogni tabella.
Migrazione dello schema e dei dati in BigQuery
Le istruzioni per la migrazione dello schema e dei dati in BigQuery sono riportate in un tutorial separato: Eseguire la migrazione dei dati da Teradata. In questa sezione sono inclusi i dettagli su come procedere con alcuni passaggi di questo tutorial. Una volta completati i passaggi dell'altro tutorial, torna a questo documento e continua con la sezione successiva, Verifica dei risultati della query.
Crea il set di dati BigQuery
Durante i passaggi di configurazione Google Cloud iniziali, ti viene chiesto di creare un set di dati in BigQuery per contenere le tabelle dopo la migrazione. Assegna al set di dati il nome tpch. Le query alla fine di questa guida rapida
presuppongono questo nome e non richiedono modifiche.
# Use the bq utility to create the dataset
bq mk --location=US tpch
Crea un account di servizio
Inoltre, nell'ambito dei Google Cloud passaggi di configurazione, devi creare un account di servizio Identity and Access Management (IAM). Questo account di servizio viene utilizzato per scrivere i dati in BigQuery e per archiviare i dati temporanei in Cloud Storage.
# Set the PROJECT variable
export PROJECT=$(gcloud config get-value project)
# Create a service account
gcloud iam service-accounts create tpch-transfer
Concedi al account di servizio le autorizzazioni che gli consentono di amministrare i set di dati BigQuery e l'area di gestione temporanea in Cloud Storage:
# Set TPCH_SVC_ACCOUNT = service account email
export TPCH_SVC_ACCOUNT=tpch-transfer@${PROJECT}.iam.gserviceaccount.com
# Bind the service account to the BigQuery Admin role
gcloud projects add-iam-policy-binding ${PROJECT} \
--member serviceAccount:${TPCH_SVC_ACCOUNT} \
--role roles/bigquery.admin
# Bind the service account to the Storage Admin role
gcloud projects add-iam-policy-binding ${PROJECT} \
--member serviceAccount:${TPCH_SVC_ACCOUNT} \
--role roles/storage.admin
Crea il bucket gestione temporanea Cloud Storage
Un'altra attività nella configurazione Google Cloud consiste nel creare un bucket Cloud Storage. Questo bucket viene utilizzato da BigQuery Data Transfer Service come area di gestione temporanea per i file di dati da importare in BigQuery.
# Use gcloud storage to create the bucket
gcloud storage buckets create gs://${PROJECT}-tpch --location=us-central1
Specifica i pattern dei nomi delle tabelle
Durante la configurazione di un nuovo trasferimento in BigQuery Data Transfer Service, ti viene chiesto di specificare un'espressione che indichi le tabelle da includere nel trasferimento. In questa guida rapida, includi tutte le tabelle del database tpch.
Il formato dell'espressione è database.table e il nome della tabella può essere sostituito da un carattere jolly. Poiché i caratteri jolly in Java iniziano con due punti, l'espressione per trasferire tutte le tabelle dal database tpch è la seguente:
tpch..*
Nota che ci sono due punti.
Verifica dei risultati della query
A questo punto hai creato dati di esempio, li hai caricati su Teradata e poi li hai migrati a BigQuery utilizzando BigQuery Data Transfer Service, come spiegato nel tutorial separato. In questa sezione, esegui due delle query standard TPC-H per verificare che i risultati siano gli stessi in Teradata e in BigQuery.
Esegui la query del report di riepilogo dei prezzi
La prima query è la query del report di riepilogo dei prezzi (sezione 2.4.1 della specifica TPC-H). Questa query indica il numero di articoli fatturati, spediti e restituiti a una determinata data.
Il seguente elenco mostra la query completa:
SELECT
l_returnflag,
l_linestatus,
SUM(l_quantity) AS sum_qty,
SUM(l_extendedprice) AS sum_base_price,
SUM(l_extendedprice*(1-l_discount)) AS sum_disc_price,
SUM(l_extendedprice*(1-l_discount)*(1+l_tax)) AS sum_charge,
AVG(l_quantity) AS avg_qty,
AVG(l_extendedprice) AS avg_price,
AVG(l_discount) AS avg_disc,
COUNT(*) AS count_order
FROM tpch.lineitem
WHERE l_shipdate BETWEEN '1996-01-01' AND '1996-01-10'
GROUP BY
l_returnflag,
l_linestatus
ORDER BY
l_returnflag,
l_linestatus;
Esegui la query in Teradata:
- Esegui BTEQ e connettiti a Teradata. Per maggiori dettagli, vedi Crea il database TPC-H in precedenza in questo documento.
Modifica la larghezza di visualizzazione dell'output a 500 caratteri:
.set width 500Copia la query e incollala al prompt BTEQ.
Il risultato è simile al seguente:
L_RETURNFLAG L_LINESTATUS sum_qty sum_base_price sum_disc_price sum_charge avg_qty avg_price avg_disc count_order ------------ ------------ ----------------- ----------------- ----------------- ----------------- ----------------- ----------------- ----------------- ----------- N O 629900.00 943154565.63 896323924.4600 932337245.114003 25.45 38113.41 .05 24746
Esegui la stessa query in BigQuery:
Vai alla console BigQuery:
Copia la query nell'editor di query.
Assicurati che il nome del set di dati nella riga
FROMsia corretto.Fai clic su Esegui.
Il risultato è lo stesso di quello di Teradata.
Se vuoi, puoi scegliere intervalli di tempo più ampi nella query per assicurarti che vengano scansionate tutte le righe della tabella.
Esegui la query sul volume dei fornitori locali
La seconda query di esempio è il report sulla query del volume dei fornitori locali (sezione 2.4.5 della specifica TPC-H). Per ogni paese di una regione, questa query restituisce le entrate prodotte da ogni elemento pubblicitario in cui il cliente e il fornitore si trovavano in quel paese. Questi risultati sono utili per pianificare, ad esempio, dove posizionare i centri di distribuzione.
Il seguente elenco mostra la query completa:
SELECT
n_name AS nation,
SUM(l_extendedprice * (1 - l_discount) / 1000) AS revenue
FROM
tpch.customer,
tpch.orders,
tpch.lineitem,
tpch.supplier,
tpch.nation,
tpch.region
WHERE c_custkey = o_custkey
AND l_orderkey = o_orderkey
AND l_suppkey = s_suppkey
AND c_nationkey = s_nationkey
AND s_nationkey = n_nationkey
AND n_regionkey = r_regionkey
AND r_name = 'EUROPE'
AND o_orderdate >= '1996-01-01'
AND o_orderdate < '1997-01-01'
GROUP BY
n_name
ORDER BY
revenue DESC;
Esegui la query in Teradata BTEQ e nella console BigQuery come descritto nella sezione precedente.
Questo è il risultato restituito da Teradata:
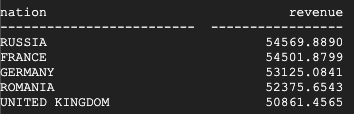
Questo è il risultato restituito da BigQuery:
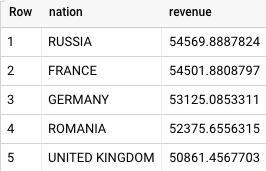
Sia Teradata che BigQuery restituiscono gli stessi risultati.
Esegui la query sulla metrica di profitto del tipo di prodotto
Il test finale per verificare la migrazione è la query sulla misura del profitto per tipo di prodotto ultimo esempio di query (sezione 2.4.9 della specifica TPC-H). Per ogni paese e ogni anno, questa query trova il profitto per tutte le parti ordinate in quell'anno. Filtra i risultati in base a una sottostringa nei nomi delle parti e a un fornitore specifico.
Il seguente elenco mostra la query completa:
SELECT
nation,
o_year,
SUM(amount) AS sum_profit
FROM (
SELECT
n_name AS nation,
EXTRACT(YEAR FROM o_orderdate) AS o_year,
(l_extendedprice * (1 - l_discount) - ps_supplycost * l_quantity)/1e+3 AS amount
FROM
tpch.part,
tpch.supplier,
tpch.lineitem,
tpch.partsupp,
tpch.orders,
tpch.nation
WHERE s_suppkey = l_suppkey
AND ps_suppkey = l_suppkey
AND ps_partkey = l_partkey
AND p_partkey = l_partkey
AND o_orderkey = l_orderkey
AND s_nationkey = n_nationkey
AND p_name like '%blue%' ) AS profit
GROUP BY
nation,
o_year
ORDER BY
nation,
o_year DESC;
Esegui la query in Teradata BTEQ e nella console BigQuery come descritto nella sezione precedente.
Questo è il risultato restituito da Teradata:
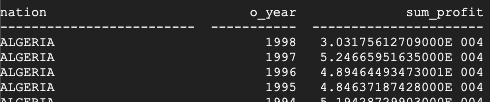
Questo è il risultato restituito da BigQuery:

Teradata e BigQuery restituiscono gli stessi risultati, anche se Teradata utilizza la notazione scientifica per la somma.
Query aggiuntive
Facoltativamente, puoi eseguire il resto delle query TPC-H definite nella sezione 2.4 delle specifiche TPC-H.
Puoi anche generare query seguendo lo standard TPC-H utilizzando lo strumento QGEN,
che si trova nella stessa directory dello strumento DBGEN. QGEN è creato utilizzando lo stesso makefile di DBGEN, quindi quando esegui make per compilare dbgen, viene prodotto anche l'eseguibile qgen.
Per ulteriori informazioni su entrambi gli strumenti e sulle relative opzioni della riga di comando, consulta il file
README per ogni strumento.
Esegui la pulizia
Per evitare che al tuo account Google Cloud vengano addebitati costi relativi alle risorse utilizzate in questo tutorial, rimuovile.
Elimina il progetto
Il modo più semplice per interrompere gli addebiti della fatturazione è eliminare il progetto creato per questo tutorial.
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
Passaggi successivi
- Ricevi istruzioni passo passo per eseguire la migrazione da Teradata a BigQuery.