Tutoriel de la migration de Teradata vers BigQuery
Ce document explique comment migrer de Teradata vers BigQuery à l'aide d'exemples de données. Il fournit une démonstration de faisabilité qui vous accompagne tout au long du processus de transfert à la fois d'un schéma et de données depuis un entrepôt de données Teradata vers BigQuery.
Objectifs
- Générer des données synthétiques et les importer dans Teradata.
- Migrer le schéma et les données vers BigQuery à l'aide du service de transfert de données BigQuery (BQDT).
- Vérifier que les requêtes renvoient les mêmes résultats sur Teradata et BigQuery.
Coûts
Ce guide de démarrage rapide utilise les composants facturables suivants de Google Cloud :
- BigQuery : Ce tutoriel stocke près de 1 Go de données dans BigQuery et traite moins de 2 Go pour une seule exécution des requêtes. Dans le cadre de la version gratuite deGoogle Cloud , vous bénéficiez d'un quota de ressources gratuites avec BigQuery dans la limite des conditions fixées. Ce quota est disponible pendant et après l'essai gratuit. Si vous dépassez ces limites d'utilisation et que votre période d'essai gratuit est terminée, des frais vous seront facturés conformément au tarif figurant sur la page Tarifs de BigQuery.
Vous pouvez utiliser le simulateur de coût pour générer une estimation des coûts en fonction de l'utilisation prévue.
Prérequis
- Assurez-vous de disposer des autorisations d'écriture et d'exécution sur une machine ayant accès à Internet afin de pouvoir télécharger et exécuter l'outil de génération de données.
- Assurez-vous que vous pouvez vous connecter à une base de données Teradata.
Assurez-vous que les outils clients BTEQ et FastLoad de Teradata sont installés sur la machine. Vous pouvez vous procurer les outils clients Teradata sur le site Web de Teradata. Si vous avez besoin d'assistance pour installer ces outils, demandez à votre administrateur système de vous fournir les informations d'installation, de configuration et d'exécution. En remplacement ou en plus de BTEQ, vous pouvez également effectuer les actions suivantes :
- Installer un outil avec une interface graphique telle que DBeaver.
- Installer le pilote SQL Teradata pour Python pour créer des interactions de scripts avec la base de données Teradata.
Assurez-vous que la machine dispose d'une connectivité réseau avecGoogle Cloud pour que l'agent de service de transfert de données BigQuery puisse communiquer avec BigQuery et transférer le schéma et les données.
Présentation
Ce guide de démarrage rapide vous présente une démonstration de faisabilité de la migration. Au cours de ce guide de démarrage rapide, vous générez des données synthétiques et les chargez dans Teradata. Ensuite, vous utilisez le service de transfert de données BigQuery pour déplacer le schéma et les données dans BigQuery. Et enfin, vous exécutez les requêtes des deux côtés afin de comparer les résultats. À la fin, il faut que le schéma et les données de Teradata soient mappés exactement comme dans BigQuery.
Ce guide de démarrage rapide est destiné aux administrateurs d'entrepôts de données, aux développeurs et aux utilisateurs de données en général qui souhaitent s'exercer avec un exemple concret sur la migration de schémas et de données à l'aide du service de transfert de données BigQuery.
Générer les données
Le Transaction Processing Performance Council (TPC) est un organisme à but non lucratif qui publie des spécifications de benchmarking. Ces spécifications sont devenues de facto les normes de l'industrie pour l'exécution de tests de performances liés aux données.
La spécification TPC-H est un benchmark axé sur l'aide à la prise de décision. Dans ce guide de démarrage rapide, vous utilisez des parties de cette spécification pour créer les tables et générer des données synthétiques en tant que modèle d'entrepôt de données réel. Bien que la spécification ait été créée pour l'analyse comparative, dans ce guide de démarrage rapide, vous utilisez ce modèle dans le cadre de la démonstration de faisabilité de la migration et non pour les tâches d'analyse comparative.
- Sur l'ordinateur sur lequel vous vous connectez à Teradata, utilisez un navigateur Web pour télécharger la dernière version disponible des outils TPC-H à partir du site Web de TPC.
- Ouvrez un terminal de commande et accédez au répertoire dans lequel vous avez téléchargé les outils.
Décompressez le fichier ZIP téléchargé. Remplacez file-name par le nom du fichier que vous avez téléchargé :
unzip file-name.zip
Un répertoire dont le nom inclut le numéro de version des outils est extrait. Ce répertoire inclut le code source TPC de l'outil de génération de données DBGEN et la spécification TPC-H.
Accédez au sous-répertoire
dbgen. Utilisez le nom du répertoire parent de votre version, comme dans l'exemple suivant :cd 2.18.0_rc2/dbgenCréez un fichier makefile en utilisant le modèle fourni :
cp makefile.suite makefileModifiez le fichier makefile avec un éditeur de texte. Par exemple, utilisez "vi" pour modifier le fichier :
vi makefileDans le fichier makefile, modifiez les valeurs des variables suivantes :
CC = gcc # TDAT -> TERADATA DATABASE = TDAT MACHINE = LINUX WORKLOAD = TPCHEn fonction de votre environnement, les valeurs du compilateur C (
CC) ouMACHINEpeuvent varier. Au besoin, contactez votre administrateur système.Enregistrez les modifications et fermez le fichier.
Traitez le fichier makefile :
makeGénérez les données TPC-H à l'aide de l'outil
dbgen:dbgen -vLa génération de données prend quelques minutes. L'option
-v("verbose" : détaillé) ajoute à la commande un suivi de processus. Une fois la génération de données terminée, vous obtenez huit fichiers ASCII avec l'extension.tbldans le dossier actif. Ils contiennent des données synthétiques délimitées par des barres verticales à charger dans chacune des tables TPC-H.
Importer des échantillons de données sur Teradata
Dans cette section, vous importez les données générées dans votre base de données Teradata.
Créer la base de données TPC-H
Le client Teradata, appelé Basic Teradata Query (BTEQ) (requête Teradata de base), est utilisé pour communiquer avec un ou plusieurs serveurs de base de données Teradata et pour exécuter des requêtes SQL sur ces systèmes. Dans cette section, vous utilisez BTEQ pour créer une base de données pour les tables TPC-H.
Ouvrez le client Teradata BTEQ :
bteqConnectez-vous à Teradata. Remplacez teradata-ip et teradata-user par les valeurs correspondantes pour votre environnement.
.LOGON teradata-ip/teradata-user
Créez une base de données appelée
tpchavec 2 Go d'espace alloué :CREATE DATABASE tpch AS PERM=2e+09;Quittez BTEQ :
.QUIT
Charger les données générées
Dans cette section, vous créez un script FastLoad pour créer et charger des exemples de tables. Les définitions de tables sont décrites dans la section 1.4 de la spécification TPC-H. La section 1.2 contient un diagramme entité-relation de l'ensemble du schéma de base de données.
La procédure suivante montre comment créer la table lineitem, qui est la plus grande et la plus complexe des tables TPC-H. Lorsque vous avez terminé avec la table lineitem, répétez cette procédure pour les tables restantes.
À l'aide d'un éditeur de texte, créez un fichier nommé
fastload_lineitem.fl:vi fastload_lineitem.flCopiez le script suivant dans le fichier, qui se connecte à la base de données Teradata et crée une table nommée
lineitem.Dans la commande
logon, remplacez teradata-ip, teradata-user et teradata-pwd par vos informations de connexion.logon teradata-ip/teradata-user,teradata-pwd; drop table tpch.lineitem; drop table tpch.error_1; drop table tpch.error_2; CREATE multiset TABLE tpch.lineitem, NO FALLBACK, NO BEFORE JOURNAL, NO AFTER JOURNAL, CHECKSUM = DEFAULT, DEFAULT MERGEBLOCKRATIO ( L_ORDERKEY INTEGER NOT NULL, L_PARTKEY INTEGER NOT NULL, L_SUPPKEY INTEGER NOT NULL, L_LINENUMBER INTEGER NOT NULL, L_QUANTITY DECIMAL(15,2) NOT NULL, L_EXTENDEDPRICE DECIMAL(15,2) NOT NULL, L_DISCOUNT DECIMAL(15,2) NOT NULL, L_TAX DECIMAL(15,2) NOT NULL, L_RETURNFLAG CHAR(1) CHARACTER SET LATIN CASESPECIFIC NOT NULL, L_LINESTATUS CHAR(1) CHARACTER SET LATIN CASESPECIFIC NOT NULL, L_SHIPDATE DATE FORMAT 'yyyy-mm-dd' NOT NULL, L_COMMITDATE DATE FORMAT 'yyyy-mm-dd' NOT NULL, L_RECEIPTDATE DATE FORMAT 'yyyy-mm-dd' NOT NULL, L_SHIPINSTRUCT CHAR(25) CHARACTER SET LATIN CASESPECIFIC NOT NULL, L_SHIPMODE CHAR(10) CHARACTER SET LATIN CASESPECIFIC NOT NULL, L_COMMENT VARCHAR(44) CHARACTER SET LATIN CASESPECIFIC NOT NULL) PRIMARY INDEX ( L_ORDERKEY ) PARTITION BY RANGE_N(L_COMMITDATE BETWEEN DATE '1992-01-01' AND DATE '1998-12-31' EACH INTERVAL '1' DAY);Le script s'assure tout d'abord de l'absence de la table
lineitemet de tables d'erreur temporaires, puis crée la tablelineitem.Dans le même fichier, ajoutez le code ci-dessous, qui charge les données dans la table qui vient d'être créée. Remplissez tous les champs de la table dans les trois blocs (
define,insertetvalues), en prenant soin de spécifiervarcharcomme type de données de chargement.begin loading tpch.lineitem errorfiles tpch.error_1, tpch.error_2; set record vartext; define in_ORDERKEY(varchar(50)), in_PARTKEY(varchar(50)), in_SUPPKEY(varchar(50)), in_LINENUMBER(varchar(50)), in_QUANTITY(varchar(50)), in_EXTENDEDPRICE(varchar(50)), in_DISCOUNT(varchar(50)), in_TAX(varchar(50)), in_RETURNFLAG(varchar(50)), in_LINESTATUS(varchar(50)), in_SHIPDATE(varchar(50)), in_COMMITDATE(varchar(50)), in_RECEIPTDATE(varchar(50)), in_SHIPINSTRUCT(varchar(50)), in_SHIPMODE(varchar(50)), in_COMMENT(varchar(50)) file = lineitem.tbl; insert into tpch.lineitem ( L_ORDERKEY, L_PARTKEY, L_SUPPKEY, L_LINENUMBER, L_QUANTITY, L_EXTENDEDPRICE, L_DISCOUNT, L_TAX, L_RETURNFLAG, L_LINESTATUS, L_SHIPDATE, L_COMMITDATE, L_RECEIPTDATE, L_SHIPINSTRUCT, L_SHIPMODE, L_COMMENT ) values ( :in_ORDERKEY, :in_PARTKEY, :in_SUPPKEY, :in_LINENUMBER, :in_QUANTITY, :in_EXTENDEDPRICE, :in_DISCOUNT, :in_TAX, :in_RETURNFLAG, :in_LINESTATUS, :in_SHIPDATE, :in_COMMITDATE, :in_RECEIPTDATE, :in_SHIPINSTRUCT, :in_SHIPMODE, :in_COMMENT ); end loading; logoff;
Le script FastLoad charge les données d'un fichier appelé
lineitem.tbl, situé dans le même répertoire et que vous avez généré à la section précédente.Enregistrez les modifications et fermez le fichier.
Exécutez le script FastLoad :
fastload < fastload_lineitem.flRépétez cette procédure pour le reste des tables TPC-H répertoriées dans la section 1.4 de la spécification TPC-H. Assurez-vous que vous ajustez les étapes pour chaque table.
Migrer le schéma et les données vers BigQuery
Les instructions relatives à la migration du schéma et des données vers BigQuery se trouvent dans un autre tutoriel : Migrer des données depuis Teradata. Nous avons inclus dans cette section des détails sur la façon de procéder avec certaines étapes de ce tutoriel. Lorsque vous avez terminé les étapes de l'autre tutoriel, revenez à ce document et passez à la section suivante, Vérifier les résultats de requêtes.
Créer l'ensemble de données BigQuery
Au cours des étapes de configuration initiales de Google Cloud , vous êtes invité à créer un ensemble de données dans BigQuery pour contenir les tables après leur migration. Nommez l'ensemble de données tpch. Les requêtes à la fin de ce guide de démarrage prennent automatiquement ce nom et ne nécessitent aucune modification.
# Use the bq utility to create the dataset
bq mk --location=US tpch
Créer un compte de service
Toujours dans le cadre des étapes de configuration de Google Cloud , vous devez créer un compte de service Identity and Access Management (IAM). Ce compte de service est utilisé pour écrire les données dans BigQuery et pour stocker des données temporaires dans Cloud Storage.
# Set the PROJECT variable
export PROJECT=$(gcloud config get-value project)
# Create a service account
gcloud iam service-accounts create tpch-transfer
Accordez les autorisations au compte de service afin qu'il gère les ensembles de données BigQuery et les zones de stockage dans Cloud Storage :
# Set TPCH_SVC_ACCOUNT = service account email
export TPCH_SVC_ACCOUNT=tpch-transfer@${PROJECT}.iam.gserviceaccount.com
# Bind the service account to the BigQuery Admin role
gcloud projects add-iam-policy-binding ${PROJECT} \
--member serviceAccount:${TPCH_SVC_ACCOUNT} \
--role roles/bigquery.admin
# Bind the service account to the Storage Admin role
gcloud projects add-iam-policy-binding ${PROJECT} \
--member serviceAccount:${TPCH_SVC_ACCOUNT} \
--role roles/storage.admin
Créer le bucket de préproduction Cloud Storage
Une des étapes supplémentaires de la configuration de Google Cloud est la création d'un bucket Cloud Storage. Ce bucket est utilisé par le service de transfert de données BigQuery en tant que zone de préproduction pour les fichiers de données en vue de leur ingestion dans BigQuery.
# Use gcloud storage to create the bucket
gcloud storage buckets create gs://${PROJECT}-tpch --location=us-central1
Spécifier les modèles de noms de table
Au cours de la configuration d'un nouveau transfert dans le service de transfert de données BigQuery, vous êtes invité à spécifier une expression indiquant les tables à inclure dans le transfert. Dans ce guide de démarrage rapide, vous incluez toutes les tables de la base de données tpch.
L'expression est au format database.table, et le nom de la table peut être remplacé par un caractère générique. Puisque les caractères génériques dans Java sont précédés de deux points, l'expression pour transférer toutes les tables de la base de données tpch se présente comme suit :
tpch..*
Vous pouvez constater la présence des deux points.
Vérifier les résultats de requêtes
À ce stade, vous avec créé un échantillon de données, importé des données dans Teradata et vous les avez migrées dans BigQuery à l'aide du service de transfert de données BigQuery, comme indiqué dans l'autre tutoriel. Dans cette section, vous exécutez deux des requêtes TPC-H standards afin de vérifier que les résultats dans Teradata sont les même que dans BigQuery.
Exécuter la requête de rapport de synthèse des tarifs
La première requête est la requête de rapport de synthèse des tarifs (section 2.4.1 de la spécification TPC-H). Cette requête affiche le nombre d'éléments facturés, envoyés et renvoyés à une date précise.
La liste suivante indique la requête complète :
SELECT
l_returnflag,
l_linestatus,
SUM(l_quantity) AS sum_qty,
SUM(l_extendedprice) AS sum_base_price,
SUM(l_extendedprice*(1-l_discount)) AS sum_disc_price,
SUM(l_extendedprice*(1-l_discount)*(1+l_tax)) AS sum_charge,
AVG(l_quantity) AS avg_qty,
AVG(l_extendedprice) AS avg_price,
AVG(l_discount) AS avg_disc,
COUNT(*) AS count_order
FROM tpch.lineitem
WHERE l_shipdate BETWEEN '1996-01-01' AND '1996-01-10'
GROUP BY
l_returnflag,
l_linestatus
ORDER BY
l_returnflag,
l_linestatus;
Exécutez la requête dans Teradata :
- Exécutez BTEQ et connectez-vous à Teradata. Pour plus d'informations, consultez la section Créer la base de données TPC-H présentée plus tôt dans ce document.
Spécifiez la largeur de l'affichage du résultat sur 500 caractères :
.set width 500Copiez la requête et collez-la dans l'invite BTEQ.
Le résultat doit ressembler à ce qui suit.
L_RETURNFLAG L_LINESTATUS sum_qty sum_base_price sum_disc_price sum_charge avg_qty avg_price avg_disc count_order ------------ ------------ ----------------- ----------------- ----------------- ----------------- ----------------- ----------------- ----------------- ----------- N O 629900.00 943154565.63 896323924.4600 932337245.114003 25.45 38113.41 .05 24746
Exécutez la même requête dans BigQuery :
Accédez à la console BigQuery :
Copiez la requête dans l'éditeur de requête.
Assurez-vous que le nom de l'ensemble de données figurant sur la ligne
FROMest correct.Cliquez sur Run (Exécuter).
Le résultat est le même que celui de Teradata.
Facultatif : Vous pouvez choisir des intervalles de temps plus importants dans la requête pour vous assurer que toutes les lignes de la table aient bien été scannées.
Exécuter la requête du volume par fournisseur local
Le deuxième exemple de requête est la requête de rapport de volume par fournisseur local (section 2.4.5 de la spécification TPC-H). Pour chaque nation dans une région, cette requête affiche le revenu généré par chaque ligne où le consommateur et le fournisseur étaient dans cette nation. Ces résultats sont utiles pour la planification d'implantation de centres de distributions par exemple.
La liste suivante indique la requête complète :
SELECT
n_name AS nation,
SUM(l_extendedprice * (1 - l_discount) / 1000) AS revenue
FROM
tpch.customer,
tpch.orders,
tpch.lineitem,
tpch.supplier,
tpch.nation,
tpch.region
WHERE c_custkey = o_custkey
AND l_orderkey = o_orderkey
AND l_suppkey = s_suppkey
AND c_nationkey = s_nationkey
AND s_nationkey = n_nationkey
AND n_regionkey = r_regionkey
AND r_name = 'EUROPE'
AND o_orderdate >= '1996-01-01'
AND o_orderdate < '1997-01-01'
GROUP BY
n_name
ORDER BY
revenue DESC;
Exécutez la requête dans Teradata BTEQ et dans la console BigQuery comme décrit dans la section précédente.
Voilà le résultat dans Teradata :
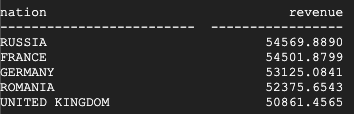
Voilà le résultat dans BigQuery :
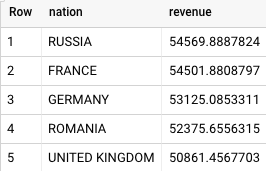
Les résultats de Teradata et de BigQuery sont les mêmes.
Exécutez la requête de mesure de profit par type de produit
La test final pour la vérification de la migration est la requête de mesure de profit par type de produit, dernière exemple de requête (section 2.4.9 dans la spécification TPC-H). Pour chaque nation et chaque année, la requête affiche les profits pour toutes les commandes de l'année. Le test filtre les résultats en sous-chaîne dans les noms d'éléments et par fournisseur.
La liste suivante indique la requête complète :
SELECT
nation,
o_year,
SUM(amount) AS sum_profit
FROM (
SELECT
n_name AS nation,
EXTRACT(YEAR FROM o_orderdate) AS o_year,
(l_extendedprice * (1 - l_discount) - ps_supplycost * l_quantity)/1e+3 AS amount
FROM
tpch.part,
tpch.supplier,
tpch.lineitem,
tpch.partsupp,
tpch.orders,
tpch.nation
WHERE s_suppkey = l_suppkey
AND ps_suppkey = l_suppkey
AND ps_partkey = l_partkey
AND p_partkey = l_partkey
AND o_orderkey = l_orderkey
AND s_nationkey = n_nationkey
AND p_name like '%blue%' ) AS profit
GROUP BY
nation,
o_year
ORDER BY
nation,
o_year DESC;
Exécutez la requête dans Teradata BTEQ et dans la console BigQuery comme décrit dans la section précédente.
Voilà le résultat dans Teradata :

Voilà le résultat dans BigQuery :

Les résultats de Teradata et de BigQuery sont les mêmes, bien que Teradata utilise la notation scientifique pour la somme.
Requêtes supplémentaires
Facultativement, vous pouvez exécuter le reste des requêtes TPC-H définies dans la section 2.4 de la spécification TPC-H.
Vous pouvez également générer des requêtes selon le standard TPC-H à l'aide de l'outil QGEN, qui se trouve dans le même répertoire que l'outil DBGEN. L'outil QGEN est conçu à l'aide du même fichier makefile que l'outil DBGEN. Cela signifie donc que lorsque vous l'exécutez pour compiler dbgen, vous produisez également l'exécutable qgen.
Pour plus d'informations sur ces deux outils et sur leurs options de ligne de commande, consultez le fichier README pour chacun de ces outils.
Nettoyage
Pour éviter que les ressources utilisées dans ce tutoriel ne soient facturées sur votre compte Google Cloud , supprimez-les.
Supprimer le projet
Le moyen le plus simple d'arrêter les frais de facturation consiste à supprimer le projet que vous avez créé dans le cadre de ce tutoriel.
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
Étapes suivantes
- Obtenez des instructions détaillées sur la Migration de Teradata vers BigQuery.