使用變更資料擷取功能串流資料表更新
BigQuery 變更資料擷取 (CDC) 功能會處理串流變更,並將這些變更套用至現有資料,藉此更新 BigQuery 資料表。這項同步作業是透過 upsert 和刪除列作業完成,這些作業會由 BigQuery Storage Write API 即時串流,因此請先熟悉這項 API 再繼續操作。
事前準備
授予身分與存取權管理 (IAM) 角色,讓使用者具備執行本文中各項工作所需的權限,並確保工作流程符合各項必要條件。
所需權限
如要取得使用 Storage Write API 的必要權限,請要求管理員授予您 BigQuery 資料編輯者 (roles/bigquery.dataEditor) IAM 角色。如要進一步瞭解如何授予角色,請參閱「管理專案、資料夾和機構的存取權」。
這個預先定義的角色包含 bigquery.tables.updateData權限,這是使用 Storage Write API 的必要條件。
如要進一步瞭解 BigQuery 中的 IAM 角色和權限,請參閱「IAM 簡介」。
必要條件
如要使用 BigQuery CDC,工作流程必須符合下列條件:
- 您必須在預設串流中使用 Storage Write API。
- 您必須使用 protobuf 格式做為擷取格式。系統不支援 Apache Arrow 格式。
- 您必須在 BigQuery 中為目的地資料表宣告主鍵。系統支援最多 16 欄的複合式主鍵。
- 必須有足夠的 BigQuery 運算資源,才能執行 CDC 資料列作業。請注意,如果 CDC 資料列修改作業失敗,您可能會無意間保留原本要刪除的資料。詳情請參閱刪除資料注意事項。
指定現有記錄的變更
在 BigQuery CDC 中,虛擬資料欄 _CHANGE_TYPE 會指出要為每一列處理的變更類型。如要使用 CDC,請在使用 Storage Write API 串流列修改項目時設定 _CHANGE_TYPE。偽資料欄 _CHANGE_TYPE 僅接受 UPSERT 和 DELETE 值。當 Storage Write API 以這種方式將資料列修改串流至資料表時,該資料表會視為已啟用 CDC。
包含 UPSERT 和 DELETE 值的範例
請參考 BigQuery 中的下表:
| ID | 名稱 | 薪資 |
|---|---|---|
| 100 | Charlie | 2000 |
| 101 | Tal | 3000 |
| 102 | Lee | 5000 |
Storage Write API 會串流下列資料列修改內容:
| ID | 名稱 | 薪資 | _CHANGE_TYPE |
|---|---|---|---|
| 100 | 刪除 | ||
| 101 | Tal | 8000 | UPSERT |
| 105 | Izumi | 6000 | UPSERT |
更新後的表格如下所示:
| ID | 名稱 | 薪資 |
|---|---|---|
| 101 | Tal | 8000 |
| 102 | Lee | 5000 |
| 105 | Izumi | 6000 |
管理資料表過時狀態
根據預設,每次執行查詢時,BigQuery 都會傳回最新的結果。查詢啟用 CDC 的資料表時,為提供最新結果,BigQuery 必須套用查詢開始時間前串流的每個資料列修改內容,確保查詢的是最新版本的資料表。在查詢執行階段套用這些列修改項目,會增加查詢延遲和費用。不過,如果您不需要完全最新的查詢結果,可以在資料表上設定 max_staleness 選項,藉此降低查詢費用和延遲時間。設定這個選項後,BigQuery 會在 max_staleness 值定義的時間間隔內,至少套用一次資料列修改內容,讓您不必等待更新套用完畢,即可執行查詢,但資料可能會有些許過時。
如果資訊主頁和報表不需要最新資料,這項行為就特別實用。此外,您也可以更頻繁地讓 BigQuery 套用資料列修改,進一步控管成本。
查詢已設定 max_staleness 選項的資料表
查詢已設定 max_staleness 選項的資料表時,BigQuery 會根據 max_staleness 的值和上次套用作業發生的時間 (以資料表的 upsert_stream_apply_watermark 時間戳記表示),傳回結果。
請參考以下範例,其中資料表的 max_staleness 選項設為 10 分鐘,而最近一次套用作業發生在 T20:
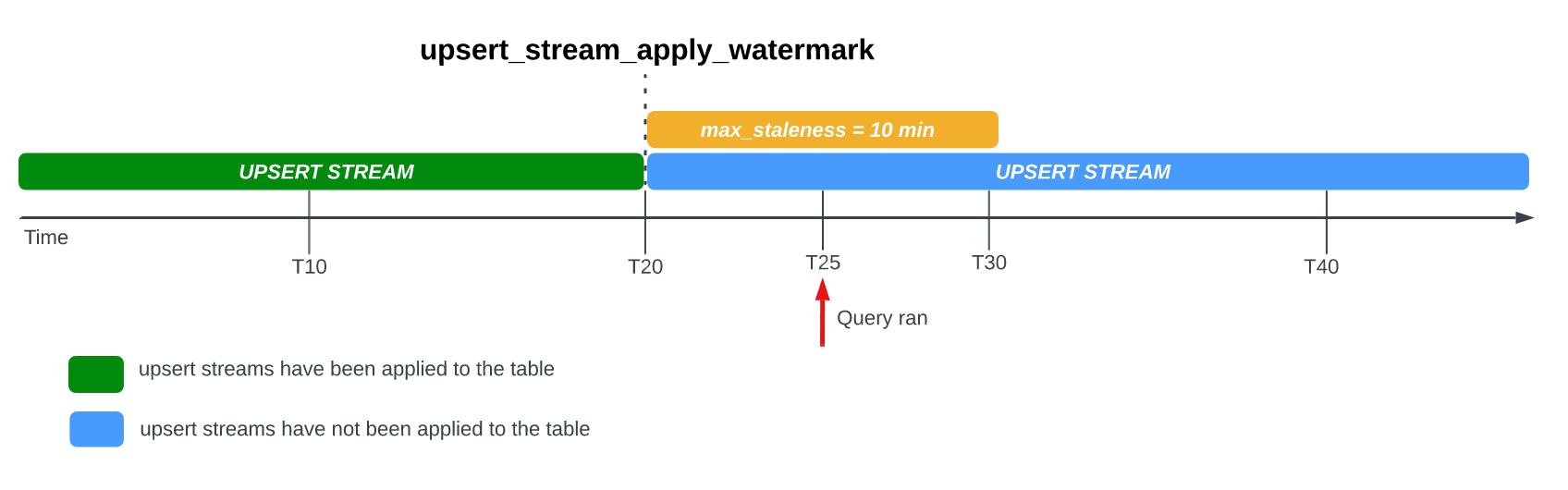
如果您在 T25 查詢資料表,資料表的目前版本會過時 5 分鐘,這少於 max_staleness 間隔的 10 分鐘。在本例中,BigQuery 會傳回 T20 的資料表版本,也就是說,傳回的資料也會過時 5 分鐘。
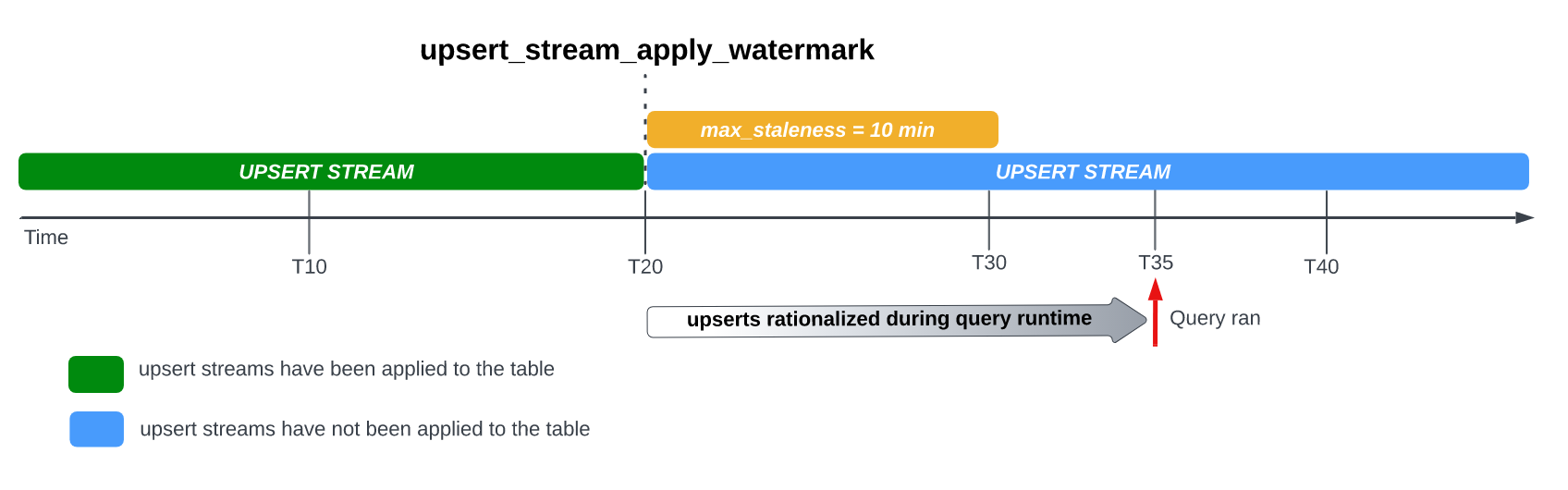
在資料表上設定 max_staleness 選項後,BigQuery 會在 max_staleness 間隔內至少套用一次待處理的資料列修改。不過在某些情況下,BigQuery 可能無法在間隔內完成套用這些待處理的資料列修改作業。
舉例來說,如果您在 T35 查詢資料表,但套用待處理資料列修改的程序尚未完成,則資料表的目前版本會過時 15 分鐘,大於 10 分鐘的 max_staleness 間隔。在本例中,BigQuery 會在查詢執行期間,將 T20 到 T35 之間的所有資料列修改套用至目前查詢,也就是說,查詢的資料完全是最新狀態,但會增加一些查詢延遲時間。這項作業會視為執行階段合併作業。
建議的 table max_staleness 值
表格的 max_staleness 值通常應為下列兩個值中較高的值:
- 工作流程可容許的資料過時程度上限。
- 將插入/更新的變更套用至資料表所需時間的兩倍,再加上一些額外緩衝時間。
如要計算將 upserted 變更套用至現有資料表所需的時間,請使用下列 SQL 查詢判斷背景套用工作的第 95 個百分位數持續時間,再加上七分鐘的緩衝時間,以利 BigQuery 寫入最佳化儲存空間 (串流緩衝區) 轉換。
SELECT project_id, destination_table.dataset_id, destination_table.table_id, APPROX_QUANTILES((TIMESTAMP_DIFF(end_time, creation_time,MILLISECOND)/1000), 100)[OFFSET(95)] AS p95_background_apply_duration_in_seconds, CEILING(APPROX_QUANTILES((TIMESTAMP_DIFF(end_time, creation_time,MILLISECOND)/1000), 100)[OFFSET(95)]*2/60)+7 AS recommended_max_staleness_with_buffer_in_minutes FROM `region-REGION`.INFORMATION_SCHEMA.JOBS AS job WHERE project_id = 'PROJECT_ID' AND DATE(creation_time) BETWEEN DATE_SUB(CURRENT_DATE(), INTERVAL 7 DAY) AND CURRENT_DATE() AND job_id LIKE "%cdc_background%" GROUP BY 1,2,3;
更改下列內容:
REGION:專案所在的區域名稱。例如:us。PROJECT_ID:包含 BigQuery 資料表的專案 ID,這些資料表會由 BigQuery CDC 修改。
背景套用作業的持續時間會受到多項因素影響,包括在過時間隔內發布的 CDC 作業數量和複雜度、資料表大小,以及 BigQuery 資源可用性。如要進一步瞭解資源可用性,請參閱「調整和監控 BACKGROUND 預留項目」。
使用 max_staleness 選項建立表格
如要使用 max_staleness 選項建立資料表,請使用 CREATE TABLE 陳述式。以下範例會建立資料表 employees,並將 max_staleness 限制設為 10 分鐘:
CREATE TABLE employees ( id INT64 PRIMARY KEY NOT ENFORCED, name STRING) CLUSTER BY id OPTIONS ( max_staleness = INTERVAL 10 MINUTE);
修改現有資料表的 max_staleness 選項
如要在現有資料表中新增或修改 max_staleness 限制,請使用 ALTER TABLE 陳述式。以下範例會將 employees 資料表的 max_staleness 限制變更為 15 分鐘:
ALTER TABLE employees SET OPTIONS ( max_staleness = INTERVAL 15 MINUTE);
判斷表格的目前 max_staleness 值
如要判斷資料表的目前 max_staleness 值,請查詢 INFORMATION_SCHEMA.TABLE_OPTIONS 檢視區塊。以下範例會檢查資料表 mytable 的目前 max_staleness 值:
SELECT option_name, option_value FROM DATASET_NAME.INFORMATION_SCHEMA.TABLE_OPTIONS WHERE option_name = 'max_staleness' AND table_name = 'TABLE_NAME';
更改下列內容:
DATASET_NAME:啟用 CDC 的資料表所在資料集名稱。TABLE_NAME:已啟用 CDC 的資料表名稱。
結果顯示 max_staleness 的值為 10 分鐘:
+---------------------+--------------+ | Row | option_name | option_value | +---------------------+--------------+ | 1 | max_staleness | 0-0 0 0:10:0 | +---------------------+--------------+
監控資料表 upsert 作業進度
如要監控表格狀態,並查看上次套用資料列修改的時間,請查詢 INFORMATION_SCHEMA.TABLES 檢視區塊,取得 upsert_stream_apply_watermark 時間戳記。
以下範例會檢查資料表 mytable 的 upsert_stream_apply_watermark 值:
SELECT upsert_stream_apply_watermark FROM DATASET_NAME.INFORMATION_SCHEMA.TABLES WHERE table_name = 'TABLE_NAME';
更改下列內容:
DATASET_NAME:啟用 CDC 的資料表所在資料集名稱。TABLE_NAME:已啟用 CDC 的資料表名稱。
結果會類似如下:
[{
"upsert_stream_apply_watermark": "2022-09-15T04:17:19.909Z"
}]
bigquery-adminbot@system.gserviceaccount.com 服務帳戶會執行 upsert 作業,並顯示在含有已啟用 CDC 資料表的專案工作記錄中。
管理自訂排序
將 upsert 串流至 BigQuery 時,系統會根據記錄擷取至 BigQuery 的 BigQuery 系統時間,決定具有相同主鍵的記錄排序方式。換句話說,系統會優先處理最近擷取且具有最新時間戳記的記錄,而非先前擷取且具有較舊時間戳記的記錄。在某些情況下,這可能不夠充分,例如在極短的時間範圍內,對相同主鍵進行非常頻繁的 upsert,或無法保證 upsert 順序。在這些情況下,可能需要使用者提供的排序鍵。
如要設定使用者提供的排序鍵,請使用虛擬資料欄 _CHANGE_SEQUENCE_NUMBER,指出 BigQuery 應套用記錄的順序,依據是兩個相符記錄之間較大的 _CHANGE_SEQUENCE_NUMBER,且這兩個記錄具有相同的主鍵。虛擬資料欄 _CHANGE_SEQUENCE_NUMBER 為選填資料欄,且只接受固定格式 STRING 的值。
_CHANGE_SEQUENCE_NUMBER 格式
虛擬資料欄 _CHANGE_SEQUENCE_NUMBER 只接受 STRING 值,且必須採用固定格式。這個固定格式使用以十六進位制寫入的 STRING 值,並以斜線 / 分隔成多個區段。每個區段最多可使用 16 個十六進位字元表示,且每個 _CHANGE_SEQUENCE_NUMBER 最多可有四個區段。「_CHANGE_SEQUENCE_NUMBER」支援的值介於「0/0/0/0」和「FFFFFFFFFFFFFFFF/FFFFFFFFFFFFFFFF/FFFFFFFFFFFFFFFF/FFFFFFFFFFFFFFFF」之間。_CHANGE_SEQUENCE_NUMBER 值支援大小寫字元。
如要表示基本排序鍵,可以使用單一區段。舉例來說,如要僅根據應用程式伺服器的記錄處理時間戳記排序金鑰,可以使用一個區段:'2024-04-30 11:19:44 UTC',方法是將時間戳記轉換為自 Epoch 以來的毫秒數,然後以十六進位表示,也就是 '18F2EBB6480'。將資料轉換為十六進位的邏輯,是由使用 Storage Write API 將寫入作業發送至 BigQuery 的用戶端負責。
支援多個區段可讓您將多個處理邏輯值合併為一個鍵,以因應更複雜的用途。舉例來說,如要根據應用程式伺服器的記錄處理時間戳記、記錄序號和記錄狀態排序金鑰,可以使用三個區段:'2024-04-30 11:19:44 UTC' / '123' / 'complete',每個區段都以十六進位表示。區段的排序是處理邏輯排名的重要考量。BigQuery 會先比較第一個區段,然後只在先前的區段相等時,才比較下一個區段。_CHANGE_SEQUENCE_NUMBER
BigQuery 會比較兩個以上的 _CHANGE_SEQUENCE_NUMBER 欄位 (視為不帶正負號的數值),藉此執行排序作業。_CHANGE_SEQUENCE_NUMBER
請參考以下_CHANGE_SEQUENCE_NUMBER比較範例和優先順序結果:
範例 1:
- 記錄 #1:
_CHANGE_SEQUENCE_NUMBER= '77' - 記錄 #2:
_CHANGE_SEQUENCE_NUMBER= '7B'
結果:記錄 #2 視為最新記錄,因為「7B」>「77」(即「123」>「119」)
- 記錄 #1:
範例 2:
- 記錄 #1:
_CHANGE_SEQUENCE_NUMBER= 'FFF/B' - 記錄 #2:
_CHANGE_SEQUENCE_NUMBER= 'FFF/ABC'
結果:記錄 #2 視為最新記錄,因為「FFF/ABC」>「FFF/B」(即「4095/2748」>「4095/11」)
- 記錄 #1:
範例 3:
- 記錄 #1:
_CHANGE_SEQUENCE_NUMBER= 'BA/FFFFFFFF' - 記錄 #2:
_CHANGE_SEQUENCE_NUMBER= 'ABC'
結果:記錄 #2 視為最新記錄,因為「ABC」>「BA/FFFFFFFF」 (即「2748」>「186/4294967295」)
- 記錄 #1:
範例 4:
- 記錄 #1:
_CHANGE_SEQUENCE_NUMBER= 'FFF/ABC' - 記錄 #2:
_CHANGE_SEQUENCE_NUMBER= 'ABC'
結果:記錄 #1 視為最新記錄,因為「FFF/ABC」>「ABC」(即「4095/2748」>「2748」)
- 記錄 #1:
如果兩個 _CHANGE_SEQUENCE_NUMBER 值相同,則系統會優先處理 BigQuery 系統最新擷取的記錄,而非先前擷取的記錄。
如果表格使用自訂排序,請務必提供 _CHANGE_SEQUENCE_NUMBER 值。如果寫入要求未指定 _CHANGE_SEQUENCE_NUMBER 值,導致資料列中同時有 _CHANGE_SEQUENCE_NUMBER 值和沒有 _CHANGE_SEQUENCE_NUMBER 值,排序順序就會無法預測。
設定 BigQuery 預留項目,以搭配 CDC 使用
您可以使用 BigQuery 預留項目,為 CDC 資料列修改作業分配專用的 BigQuery 運算資源。預留項目可讓您設定執行這些作業的費用上限。如果工作流程經常對大型資料表執行 CDC 作業,這個方法就特別實用,否則每次執行作業時處理的位元組數較多,會導致隨選費用偏高。
在 max_staleness 間隔內套用待處理資料列修改的 BigQuery CDC 工作會視為背景工作,並使用BACKGROUND 指派類型,而非 QUERY 指派類型。相較之下,如果查詢不在 max_staleness 間隔內,且需要在查詢執行階段套用資料列修改,則會使用QUERY 指派類型。如果資料表沒有 max_staleness 設定,或是 max_staleness 設定為 0,也會使用 QUERY 指派類型。
如果執行 BigQuery CDC 背景工作時未指派 BACKGROUND,則會採用以量計價方案。為 BigQuery CDC 設計工作負載管理策略時,請務必考量這點。
如要設定 BigQuery 預留項目以搭配 CDC 使用,請先在 BigQuery 資料表所在的區域設定預留項目。如需保留項目大小的相關指引,請參閱「調整及監控 BACKGROUND 保留項目大小」。建立預留項目後,請將 BigQuery 專案指派給預留項目,然後執行下列 CREATE ASSIGNMENT 陳述式,將 job_type 選項設為 BACKGROUND:
CREATE ASSIGNMENT `ADMIN_PROJECT_ID.region-REGION.RESERVATION_NAME.ASSIGNMENT_ID` OPTIONS ( assignee = 'projects/PROJECT_ID', job_type = 'BACKGROUND');
更改下列內容:
ADMIN_PROJECT_ID:擁有預留資源的管理專案 ID。REGION:專案所在的區域名稱。例如:us。RESERVATION_NAME:預訂名稱。ASSIGNMENT_ID:指派作業的 ID。ID 在專案和位置中不得重複,開頭和結尾須為小寫英文字母或數字,且只能包含小寫英文字母、數字和破折號。PROJECT_ID:包含 BigQuery 資料表的專案 ID,這些資料表會由 BigQuery CDC 修改。這項專案已指派給預留項目。
調整及監控 BACKGROUND 預留項目大小
預留項目會決定可用的運算資源量,以執行 BigQuery 運算作業。預留項目大小不足可能會增加 CDC 資料列修改作業的處理時間。如要準確估算預訂大小,請查詢 INFORMATION_SCHEMA.JOBS_TIMELINE 檢視區塊,監控執行 CDC 作業的專案歷來消耗的時段:
SELECT period_start, SUM(period_slot_ms) / (1000 * 60) AS slots_used FROM region-REGION.INFORMATION_SCHEMA.JOBS_TIMELINE_BY_PROJECT WHERE DATE(job_creation_time) BETWEEN DATE_SUB(CURRENT_DATE(), INTERVAL 7 DAY) AND CURRENT_DATE() AND job_id LIKE '%cdc_background%' GROUP BY period_start ORDER BY period_start DESC;
將 REGION 替換為專案所在的區域名稱。例如:us。
刪除資料的注意事項
- BigQuery CDC 作業會使用 BigQuery 運算資源。如果 CDC 作業設定為使用隨選計費,系統會定期使用內部 BigQuery 資源執行 CDC 作業。如果 CDC 作業設定了
BACKGROUND預留,CDC 作業就會改為受限於設定預留的資源可用性。如果設定的預留空間沒有足夠資源,處理 CDC 作業 (包括刪除作業) 的時間可能會比預期長。 - 只有在
upsert_stream_apply_watermark時間戳記晚於 Storage Write API 串流作業的時間戳記時,系統才會將 CDCDELETE作業視為已套用。如要進一步瞭解upsert_stream_apply_watermark時間戳記,請參閱「監控資料表 upsert 作業進度」。 - 如要套用順序有誤的 CDC
DELETE作業,BigQuery 會保留刪除作業兩天。在這段期間內,系統會儲存資料表DELETE作業,然後才開始進行標準的Google Cloud 資料刪除程序。刪除保留期限內的DELETE作業會採用標準的 BigQuery 儲存空間定價。
限制
- BigQuery CDC 不會強制執行鍵,因此主鍵必須是唯一的。
- 主要索引鍵不得超過 16 個資料欄。
- 啟用 CDC 的資料表不得有超過 2,000 個頂層資料欄 (由資料表的結構定義)。
- 啟用 CDC 的資料表不支援下列項目:
- 變異資料操縱語言 (DML) 陳述式,例如
DELETE、UPDATE和MERGE - 查詢萬用字元資料表
- 搜尋索引
- 變異資料操縱語言 (DML) 陳述式,例如
- 如果資料表的
max_staleness值過低,導致 CDC 啟用的資料表執行執行階段合併工作,則無法支援下列項目: - 對啟用 CDC 的資料表執行 BigQuery 匯出作業時,系統不會匯出背景工作尚未套用的近期串流資料列修改。如要匯出完整資料表,請使用
EXPORT DATA陳述式。 - 如果查詢在分區資料表上觸發執行階段合併,則無論查詢是否僅限於部分分區,系統都會掃描整個資料表。
- 如果您使用標準版,則無法預訂
BACKGROUND,因此套用待處理的資料列修改時,會採用以量計價模式。不過,無論您使用哪個版本,都可以查詢已啟用 CDC 的資料表。 - 執行資料表讀取作業時,虛擬資料欄
_CHANGE_TYPE和_CHANGE_SEQUENCE_NUMBER不是可查詢的資料欄。 - 系統不支援在同一個連線中,將含有
UPSERT或DELETE_CHANGE_TYPE值的資料列,與含有INSERT或未指定_CHANGE_TYPE值的資料列混合,否則會導致下列驗證錯誤:The given value is not a valid CHANGE_TYPE。
BigQuery CDC 定價
BigQuery CDC 使用 Storage Write API 擷取資料、使用 BigQuery 儲存空間儲存資料,以及使用 BigQuery 運算資源執行資料列修改作業,這些都會產生費用。如需價格資訊,請參閱 BigQuery 定價。
預估 BigQuery CDC 費用
除了一般 BigQuery 費用估算最佳做法,估算 BigQuery CDC 的費用對於資料量龐大、max_staleness 設定較低或資料經常變更的工作流程來說,可能相當重要。
BigQuery 資料擷取定價和 BigQuery 儲存定價是根據您擷取及儲存的資料量 (包括虛擬資料欄) 直接計算。不過,BigQuery 運算價格較難預估,因為這與執行 BigQuery CDC 工作所用的運算資源耗用量有關。
BigQuery CDC 工作分為三類:
- 背景套用工作:這類工作會在背景執行,執行間隔由資料表的
max_staleness值定義。這些工作會將最近串流的資料列修改套用至已啟用 CDC 的資料表。 - 查詢工作:在
max_staleness視窗中執行的 GoogleSQL 查詢,且只會從 CDC 基準資料表讀取資料。 - 執行階段合併工作:由在
max_staleness視窗外執行的臨時 GoogleSQL 查詢觸發的工作。這些工作必須在查詢執行階段,即時合併 CDC 基準資料表和最近串流的資料列修改內容。
只有查詢作業會運用 BigQuery 分割功能。背景套用作業和執行階段合併作業無法使用分割,因為在套用最近串流的資料列修改時,無法保證最近串流的 upsert 會套用至哪個資料表分割區。換句話說,在背景套用工作和執行階段合併工作期間,系統會讀取完整基準資料表。基於相同原因,只有查詢工作能從 BigQuery 叢集資料欄的篩選器獲益。瞭解執行 CDC 作業時讀取的資料量,有助於估算總費用。
如果從資料表基準讀取的資料量很高,請考慮使用 BigQuery 容量定價模式,這種模式的費用與處理的資料量無關。
BigQuery CDC 費用最佳做法
除了一般 BigQuery 費用最佳做法,您也可以使用下列技術,盡量降低 BigQuery CDC 作業的費用:
- 除非必要,否則請避免將表格的
max_staleness選項設為非常低的值。max_staleness值可能會增加背景套用作業和執行階段合併作業的發生次數,這類作業的費用較高,速度也比查詢作業慢。如需詳細指引,請參閱「建議的表格max_staleness值」。 - 請考慮設定 BigQuery 預留項目,以搭配 CDC 資料表使用。否則,背景套用工作和執行階段合併工作會採用以量計價,由於資料處理量較大,因此費用可能較高。如需更多詳細資料,請參閱 BigQuery 預留項目,並按照如何調整及監控
BACKGROUND預留項目大小的指南操作,以便搭配 BigQuery CDC 使用。
後續步驟
- 瞭解如何實作 Storage Write API 預設串流。
- 瞭解Storage Write API 的最佳做法。
- 瞭解如何使用 Datastream 將交易資料庫複製到 BigQuery,並搭配 BigQuery CDC。