Migration assessment
The BigQuery migration assessment lets you plan and review the migration of your existing data warehouse into BigQuery. You can run the BigQuery migration assessment to generate a report to assess the cost to store your data in BigQuery, to see how BigQuery can optimize your existing workload for cost savings, and to prepare a migration plan that outlines the time and effort required to complete your data warehouse migration to BigQuery.
This document describes how to use the BigQuery migration assessment and the different ways you can review the assessment results. This document is intended for users who are familiar with the Google Cloud console and the batch SQL translator.
Before you begin
To prepare and run a BigQuery migration assessment, follow these steps:
Extract metadata and query logs from your data warehouse using the
dwh-migration-dumpertool.Upload your metadata and query logs to your Cloud Storage bucket.
Optional: Query the assessment results to find detailed or specific assessment information.
Extract metadata and query logs from your data warehouse
Both metadata and query logs are needed for preparing the assessment with recommendations.
To extract the metadata and query logs necessary to run the assessment, select your data warehouse:
Teradata
Requirements
- A machine connected to your source Teradata data warehouse (Teradata 15 and later are supported)
- A Google Cloud account with a Cloud Storage bucket to store the data
- An empty BigQuery dataset to store the results
- Read permissions on the dataset to view the results
- Recommended: Administrator-level access rights to the source database when using the extraction tool to access system tables
Requirement: Enable logging
The dwh-migration-dumper tool extracts three types of logs: query logs, utility
logs, and resource usage logs. You need to enable logging for the following
types of logs to view more thorough insights:
- Query logs: Extracted from the view
dbc.QryLogVand from the tabledbc.DBQLSqlTbl. Enable logging by specifying theWITH SQLoption. - Utility logs: Extracted from the table
dbc.DBQLUtilityTbl. Enable logging by specifying theWITH UTILITYINFOoption. - Resource usage logs: Extracted from the tables
dbc.ResUsageScpuanddbc.ResUsageSpma. Enable RSS logging for these two tables.
Run the dwh-migration-dumper tool
Download the dwh-migration-dumper tool.
Download the
SHA256SUMS.txt file
and run the following command to verify zip correctness:
Bash
sha256sum --check SHA256SUMS.txt
Windows PowerShell
(Get-FileHash RELEASE_ZIP_FILENAME).Hash -eq ((Get-Content SHA256SUMS.txt) -Split " ")[0]
Replace the RELEASE_ZIP_FILENAME with the
downloaded zip filename of the dwh-migration-dumper command-line extraction tool release—for
example, dwh-migration-tools-v1.0.52.zip
The True result confirms successful checksum verification.
The False result indicates verification error. Make sure the checksum
and zip files are downloaded from the same release version and placed in
the same directory.
For details about how to set up and use the extraction tool, see Generate metadata for translation and assessment.
Use the extraction tool to extract logs and metadata from your Teradata data warehouse as two zip files. Run the following commands on a machine with access to the source data warehouse to generate the files.
Generate the metadata zip file:
dwh-migration-dumper \ --connector teradata \ --database DATABASES \ --driver path/terajdbc4.jar \ --host HOST \ --assessment \ --user USER \ --password PASSWORD
Note: The --database flag is optional for the
teradata connector. If omitted, then the metadata for all of the databases is extracted. This flag is only valid for the teradata
connector and can't be used with teradata-logs.
Generate the zip file containing query logs:
dwh-migration-dumper \ --connector teradata-logs \ --driver path/terajdbc4.jar \ --host HOST \ --assessment \ --user USER \ --password PASSWORD
Note: The --database flag isn't used when extracting
query logs with the teradata-logs connector. Query logs are
always extracted for all databases.
Replace the following:
PATH: the absolute or relative path to the driver JAR file to use for this connectionVERSION: the version of your driverHOST: the host addressUSER: the username to use for the database connectionDATABASES: (Optional) the comma-separated list of database names to extract. If not provided, all databases are extracted.PASSWORD: (Optional) the password to use for the database connection. If left empty, the user is prompted for their password.
By default, the query logs are extracted
from the view dbc.QryLogV and from the table dbc.DBQLSqlTbl. If you need
to extract the query logs from an alternative location, you can
specify the names of the tables or views by using the
-Dteradata-logs.query-logs-table and -Dteradata-logs.sql-logs-table
flags.
By default, the utility logs are extracted from the table
dbc.DBQLUtilityTbl. If you need to extract the utility logs from an
alternative location, you can specify the name of the table using the
-Dteradata-logs.utility-logs-table flag.
By default, the resource usage logs are extracted from the tables
dbc.ResUsageScpu and dbc.ResUsageSpma. If you need to extract the
resource usage logs from an alternative location, you can specify the names
of the tables using the -Dteradata-logs.res-usage-scpu-table and
-Dteradata-logs.res-usage-spma-table flags.
For example:
Bash
dwh-migration-dumper \ --connector teradata-logs \ --driver path/terajdbc4.jar \ --host HOST \ --assessment \ --user USER \ --password PASSWORD \ -Dteradata-logs.query-logs-table=pdcrdata.QryLogV_hst \ -Dteradata-logs.sql-logs-table=pdcrdata.DBQLSqlTbl_hst \ -Dteradata-logs.log-date-column=LogDate \ -Dteradata-logs.utility-logs-table=pdcrdata.DBQLUtilityTbl_hst \ -Dteradata-logs.res-usage-scpu-table=pdcrdata.ResUsageScpu_hst \ -Dteradata-logs.res-usage-spma-table=pdcrdata.ResUsageSpma_hst
Windows PowerShell
dwh-migration-dumper ` --connector teradata-logs ` --driver path\terajdbc4.jar ` --host HOST ` --assessment ` --user USER ` --password PASSWORD ` "-Dteradata-logs.query-logs-table=pdcrdata.QryLogV_hst" ` "-Dteradata-logs.sql-logs-table=pdcrdata.DBQLSqlTbl_hst" ` "-Dteradata-logs.log-date-column=LogDate" ` "-Dteradata-logs.utility-logs-table=pdcrdata.DBQLUtilityTbl_hst" ` "-Dteradata-logs.res-usage-scpu-table=pdcrdata.ResUsageScpu_hst" ` "-Dteradata-logs.res-usage-spma-table=pdcrdata.ResUsageSpma_hst"
By default, the dwh-migration-dumper tool extracts the last seven days of
query logs.
Google recommends that you provide at least two weeks of query logs to be
able to view more thorough insights. You can specify a custom time range by
using the --query-log-start and --query-log-end flags. For example:
dwh-migration-dumper \ --connector teradata-logs \ --driver path/terajdbc4.jar \ --host HOST \ --assessment \ --user USER \ --password PASSWORD \ --query-log-start "2023-01-01 00:00:00" \ --query-log-end "2023-01-15 00:00:00"
You can also generate multiple zip files containing query logs covering different periods and provide all of them for assessment.
Redshift
Requirements
- A machine connected to your source Amazon Redshift data warehouse
- A Google Cloud account with a Cloud Storage bucket to store the data
- An empty BigQuery dataset to store the results
- Read permissions on the dataset to view the results
- Recommended: Super user access to the database when using the extraction tool to access system tables
Run the dwh-migration-dumper tool
Download the dwh-migration-dumper command-line extraction tool.
Download the
SHA256SUMS.txt file
and run the following command to verify zip correctness:
Bash
sha256sum --check SHA256SUMS.txt
Windows PowerShell
(Get-FileHash RELEASE_ZIP_FILENAME).Hash -eq ((Get-Content SHA256SUMS.txt) -Split " ")[0]
Replace the RELEASE_ZIP_FILENAME with the
downloaded zip filename of the dwh-migration-dumper command-line extraction tool release—for
example, dwh-migration-tools-v1.0.52.zip
The True result confirms successful checksum verification.
The False result indicates verification error. Make sure the checksum
and zip files are downloaded from the same release version and placed in
the same directory.
For details about how to use the dwh-migration-dumper tool,
see the
generate metadata
page.
Use the dwh-migration-dumper tool to extract logs and metadata from your
Amazon Redshift data warehouse as two zip files.
Run the following commands on a machine with access to the source
data warehouse to generate the files.
Generate the metadata zip file:
dwh-migration-dumper \ --connector redshift \ --database DATABASE \ --driver PATH/redshift-jdbc42-VERSION.jar \ --host host.region.redshift.amazonaws.com \ --assessment \ --user USER \ --iam-profile IAM_PROFILE_NAME
Generate the zip file containing query logs:
dwh-migration-dumper \ --connector redshift-raw-logs \ --database DATABASE \ --driver PATH/redshift-jdbc42-VERSION.jar \ --host host.region.redshift.amazonaws.com \ --assessment \ --user USER \ --iam-profile IAM_PROFILE_NAME
Replace the following:
DATABASE: the name of the database to connect toPATH: the absolute or relative path to the driver JAR file to use for this connectionVERSION: the version of your driverUSER: the username to use for the database connectionIAM_PROFILE_NAME: the Amazon Redshift IAM profile name. Required for Amazon Redshift authentication and for AWS API access. To get the description of Amazon Redshift clusters, use the AWS API.
By default, Amazon Redshift stores three to five days of query logs.
By default, the dwh-migration-dumper tool extracts the last seven days of query
logs.
Google recommends that you provide at least two weeks of query logs to be
able
to view more thorough insights. You might need to run the
extraction tool a few times
over the course of two weeks to get the best results. You can specify a custom
range by using the --query-log-start and --query-log-end flags.
For example:
dwh-migration-dumper \ --connector redshift-raw-logs \ --database DATABASE \ --driver PATH/redshift-jdbc42-VERSION.jar \ --host host.region.redshift.amazonaws.com \ --assessment \ --user USER \ --iam-profile IAM_PROFILE_NAME \ --query-log-start "2023-01-01 00:00:00" \ --query-log-end "2023-01-02 00:00:00"
You can also generate multiple zip files containing query logs covering different periods and provide all of them for assessment.
Redshift Serverless
Requirements
- A machine connected to your source Amazon Redshift Serverless data warehouse
- A Google Cloud account with a Cloud Storage bucket to store the data
- An empty BigQuery dataset to store the results
- Read permissions on the dataset to view the results
- Recommended: Super user access to the database when using the extraction tool to access system tables
Run the dwh-migration-dumper tool
Download the dwh-migration-dumper command-line extraction tool.
For details about how to use the dwh-migration-dumper tool, see the
Generate metadata page.
Use the dwh-migration-dumper tool to extract usage logs and metadata from
your Amazon Redshift Serverless namespace as two zip files. Run the following
commands on a machine with access to the source data warehouse to generate
the files.
Generate the metadata zip file:
dwh-migration-dumper \ --connector redshift \ --database DATABASE \ --driver PATH/redshift-jdbc42-VERSION.jar \ --host host.region.redshift-serverless.amazonaws.com \ --assessment \ --user USER \ --iam-profile IAM_PROFILE_NAME
Generate the zip file containing query logs:
dwh-migration-dumper \ --connector redshift-serverless-logs \ --database DATABASE \ --driver PATH/redshift-jdbc42-VERSION.jar \ --host host.region.redshift-serverless.amazonaws.com \ --assessment \ --user USER \ --iam-profile IAM_PROFILE_NAME
Replace the following:
DATABASE: the name of the database to connect toPATH: the absolute or relative path to the driver JAR file to use for this connectionVERSION: the version of your driverUSER: the username to use for the database connectionIAM_PROFILE_NAME: the Amazon Redshift IAM profile name. Required for Amazon Redshift authentication and for AWS API access. To get the description of Amazon Redshift clusters, use the AWS API.
Amazon Redshift Serverless stores usage logs for seven days. If a wider range is required, Google recommends extracting data multiple times over a longer period.
Snowflake
Requirements
You must meet the following requirements in order to extract metadata and query logs from Snowflake:
- A machine that can connect to your Snowflake instance(s).
- A Google Cloud account with a Cloud Storage bucket to store the data.
- An empty BigQuery dataset to store the results. Alternatively, you can create a BigQuery dataset when you create the assessment job using the Google Cloud console UI.
- Snowflake user with
IMPORTED PRIVILEGESaccess on the databaseSnowflake. We recommend creating aSERVICEuser with a key-pair based authentication. This provides the secure method for accessing Snowflake data platform without a need to generate MFA tokens.- To create a new service user follow the official Snowflake guide. You will have to generate the RSA key-pair and assign public key to the Snowflake user.
- Service user should have the
ACCOUNTADMINrole, or be granted a role with theIMPORTED PRIVILEGESprivileges on the databaseSnowflakeby an account administrator. - Alternatively to key-pair authentication, you can use the password-based authentication. However, starting from August 2025, Snowflake enforces MFA on all password-based users. This requires you to approve the MFA push notification when using our extraction tool.
Run the dwh-migration-dumper tool
Download the dwh-migration-dumper command-line extraction tool.
Download the
SHA256SUMS.txt file
and run the following command to verify zip correctness:
Bash
sha256sum --check SHA256SUMS.txt
Windows PowerShell
(Get-FileHash RELEASE_ZIP_FILENAME).Hash -eq ((Get-Content SHA256SUMS.txt) -Split " ")[0]
Replace the RELEASE_ZIP_FILENAME with the
downloaded zip filename of the dwh-migration-dumper command-line extraction tool release—for
example, dwh-migration-tools-v1.0.52.zip
The True result confirms successful checksum verification.
The False result indicates verification error. Make sure the checksum
and zip files are downloaded from the same release version and placed in
the same directory.
For details about how to use the dwh-migration-dumper tool,
see the
generate metadata
page.
Use the dwh-migration-dumper tool to extract logs and metadata from your
Snowflake data warehouse as two zip files. Run the following
commands on a machine with access to the source data warehouse to generate
the files.
Generate the metadata zip file:
dwh-migration-dumper \ --connector snowflake \ --host HOST_NAME \ --user USER_NAME \ --role ROLE_NAME \ --warehouse WAREHOUSE \ --assessment \ --private-key-file PRIVATE_KEY_PATH \ --private-key-password PRIVATE_KEY_PASSWORD
Generate the zip file containing query logs:
dwh-migration-dumper \ --connector snowflake-logs \ --host HOST_NAME \ --user USER_NAME \ --role ROLE_NAME \ --warehouse WAREHOUSE \ --query-log-start STARTING_DATE \ --query-log-end ENDING_DATE \ --assessment \ --private-key-file PRIVATE_KEY_PATH \ --private-key-password PRIVATE_KEY_PASSWORD
Replace the following:
HOST_NAME: the hostname of your Snowflake instance.USER_NAME: the username to use for the database connection, where the user must have the access permissions as detailed in the requirements section.PRIVATE_KEY_PATH: the path to the RSA private key used for authentication.PRIVATE_KEY_PASSWORD: (Optional) the password that was used when creating the RSA private key. It is required only if private key is encrypted.ROLE_NAME: (Optional) the user role when running thedwh-migration-dumpertool—for example,ACCOUNTADMIN.WAREHOUSE: the warehouse used to execute the dumping operations. If you have multiple virtual warehouses, you can specify any warehouse to execute this query. Running this query with the access permissions detailed in the requirements section extracts all warehouse artefacts in this account.STARTING_DATE: (Optional) used to indicate the start date in a date range of query logs, written in the formatYYYY-MM-DD.ENDING_DATE: (Optional) used to indicate the end date in a date range of query logs, written in the formatYYYY-MM-DD.
You can also generate multiple zip files containing query logs covering non-overlapping periods and provide all of them for assessment.
Oracle
To request feedback or support for this feature, send an email to bq-edw-migration-support@google.com.
Requirements
You must meet the following requirements in order to extract metadata and query logs from Oracle:
- Your Oracle database must be version 11g R1 or higher.
- A machine that can connect to your Oracle instance(s).
- Java 8 or higher.
- A Google Cloud account with a Cloud Storage bucket to store the data.
- An empty BigQuery dataset to store the results. Alternatively, you can create a BigQuery dataset when you create the assessment job using the Google Cloud console UI.
- An Oracle common user with SYSDBA privileges.
Run the dwh-migration-dumper tool
Download the dwh-migration-dumper command-line extraction tool.
Download the
SHA256SUMS.txt file
and run the following command to verify zip correctness:
sha256sum --check SHA256SUMS.txt
For details about how to use the dwh-migration-dumper tool,
see the
generate metadata
page.
Use the dwh-migration-dumper tool to extract metadata and performance
statistics to the zip file. By default, statistics are extracted from the
Oracle AWR that requires the Oracle Tuning and Diagnostics
Pack. If this data is not available, dwh-migration-dumper uses STATSPACK
instead.
For multitenant databases, the dwh-migration-dumper tool must be executed
in the root container. Running it in one of the pluggable databases results
in missing performance statistics and metadata about other pluggable
databases.
Generate the metadata zip file:
dwh-migration-dumper \ --connector oracle-stats \ --host HOST_NAME \ --port PORT \ --oracle-service SERVICE_NAME \ --assessment \ --driver JDBC_DRIVER_PATH \ --user USER_NAME \ --password
Replace the following:
HOST_NAME: the hostname of your Oracle instance.PORT: the connection port number. The default value is 1521.SERVICE_NAME: the Oracle service name to use for the connection.JDBC_DRIVER_PATH: the absolute or relative path to the driver JAR file. You can download this file from the Oracle JDBC driver downloads page. You should select the driver version that is compatible with your database version.USER_NAME: name of the user used to connect to your Oracle instance. The user must have the access permissions as detailed in the requirements section.
Hadoop / Cloudera
To request feedback or support for this feature, send an email to bq-edw-migration-support@google.com.
Requirements
You must have the following to extract metadata from Cloudera:
- A machine that can connect to the Cloudera Manager API.
- A Google Cloud account with a Cloud Storage bucket to store the data.
- An empty BigQuery dataset to store the results. Alternatively, you can create a BigQuery dataset when you create the assessment job.
Run the dwh-migration-dumper tool
Download the
dwh-migration-dumpercommand-line extraction tool.Download the
SHA256SUMS.txtfile.In your command-line environment, verify zip correctness:
sha256sum --check SHA256SUMS.txt
For details about how to use the
dwh-migration-dumpertool, see Generate metadata for translation and assessment.Use the
dwh-migration-dumpertool to extract metadata and performance statistics to the zip file:dwh-migration-dumper \ --connector cloudera-manager \ --user USER_NAME \ --password PASSWORD \ --url URL_PATH \ --yarn-application-types "APP_TYPES" \ --pagination-page-size PAGE_SIZE \ --start-date START_DATE \ --end-date END_DATE \ --assessment
Replace the following:
USER_NAME: the name of the user to connect to your Cloudera Manager instance.PASSWORD: the password for your Cloudera Manager instance.URL_PATH: the URL path to the Cloudera Manager API, for example,https://localhost:7183/api/v55/.APP_TYPES(optional): the comma-separated YARN application types that are dumped from the cluster. The default value isMAPREDUCE,SPARK,Oozie Launcher.PAGE_SIZE(optional): the number of records per Cloudera response. The default value is1000.START_DATE(optional): the start date for your history dump in ISO 8601 format, for example2025-05-29. The default value is 90 days before the current date.END_DATE(optional): the end date for your history dump in ISO 8601 format, for example2025-05-30. The default value is the current date.
Use Oozie in your Cloudera cluster
If you use Oozie in your Cloudera cluster, you can dump Oozie job history with the Oozie connector. You can use Oozie with Kerberos authentication or basic authentication.
For Kerberos authentication, run the following:
kinit dwh-migration-dumper \ --connector oozie \ --url URL_PATH \ --assessment
Replace the following:
URL_PATH(optional): the Oozie server URL path. If you don't specify the URL path, it's taken from theOOZIE_URLenvironment variable.
For basic authentication, run the following:
dwh-migration-dumper \ --connector oozie \ --user USER_NAME \ --password PASSWORD \ --url URL_PATH \ --assessment
Replace the following:
USER_NAME: the name of the Oozie user.PASSWORD: the user password.URL_PATH(optional): the Oozie server URL path. If you don't specify the URL path, it's taken from theOOZIE_URLenvironment variable.
Use Airflow in your Cloudera cluster
If you use Airflow in your Cloudera cluster, you can dump DAGs history with the Airflow connector:
dwh-migration-dumper \ --connector airflow \ --user USER_NAME \ --password PASSWORD \ --url URL \ --driver "DRIVER_PATH" \ --start-date START_DATE \ --end-date END_DATE \ --assessment
Replace the following:
USER_NAME: the name of the Airflow userPASSWORD: the user passwordURL: the JDBC string to the Airflow databaseDRIVER_PATH: the path to the JDBC driverSTART_DATE(optional): the start date for your history dump in ISO 8601 formatEND_DATE(optional): the end date for your history dump in ISO 8601 format
Use Hive in your Cloudera cluster
To use the Hive connector, see the Apache Hive tab.
Apache Hive
Requirements
- A machine connected to your source Apache Hive data warehouse (BigQuery migration assessment supports Hive on Tez and MapReduce, and supports Apache Hive versions between 2.2 and 3.1, inclusively)
- A Google Cloud account with a Cloud Storage bucket to store the data
- An empty BigQuery dataset to store the results
- Read permissions on the dataset to view the results
- Access to your source Apache Hive data warehouse to configure query logs extraction
- Up to date tables, partitions, and columns statistics
The BigQuery migration assessment uses tables, partitions, and columns statistics to
understand your Apache Hive data warehouse better and provide
thorough insights. If the hive.stats.autogather configuration
setting is set to false in your source Apache Hive data warehouse,
Google recommends enabling it or updating statistics manually before
running the dwh-migration-dumper tool.
Run the dwh-migration-dumper tool
Download the dwh-migration-dumper command-line extraction tool.
Download the
SHA256SUMS.txt file
and run the following command to verify zip correctness:
Bash
sha256sum --check SHA256SUMS.txt
Windows PowerShell
(Get-FileHash RELEASE_ZIP_FILENAME).Hash -eq ((Get-Content SHA256SUMS.txt) -Split " ")[0]
Replace the RELEASE_ZIP_FILENAME with the
downloaded zip filename of the dwh-migration-dumper command-line extraction tool release—for
example, dwh-migration-tools-v1.0.52.zip
The True result confirms successful checksum verification.
The False result indicates verification error. Make sure the checksum
and zip files are downloaded from the same release version and placed in
the same directory.
For details about how to use the dwh-migration-dumper tool, see
Generate metadata for translation and assessment.
Use the dwh-migration-dumper tool to generate metadata from your
Hive data warehouse as a zip file.
Without Authentication
To generate the metadata zip file, run the following command on a machine that has access to the source data warehouse:
dwh-migration-dumper \ --connector hiveql \ --database DATABASES \ --host hive.cluster.host \ --port 9083 \ --assessment
With Kerberos Authentication
To authenticate to the metastore, sign in as a user that has access to the Apache Hive metastore and generate a Kerberos ticket. Then, generate the metadata zip file with the following command:
JAVA_OPTS="-Djavax.security.auth.useSubjectCredsOnly=false" \ dwh-migration-dumper \ --connector hiveql \ --database DATABASES \ --host hive.cluster.host \ --port 9083 \ --hive-kerberos-url PRINCIPAL/HOST \ -Dhiveql.rpc.protection=hadoop.rpc.protection \ --assessment
Replace the following:
DATABASES: the comma-separated list of database names to extract. If not provided, all databases are extracted.PRINCIPAL: the kerberos principal that the ticket is issued toHOST: the kerberos hostname that the ticket is issued tohadoop.rpc.protection: the Quality of Protection (QOP) of the Simple Authentication and Security Layer (SASL) configuration level, equal to the value ofhadoop.rpc.protectionparameter inside the/etc/hadoop/conf/core-site.xmlfile, with one of the following values:authenticationintegrityprivacy
Extract query logs with the hadoop-migration-assessment logging hook
To extract query logs, follow these steps:
- Upload the
hadoop-migration-assessmentlogging hook. - Configure the logging hook properties.
- Verify the logging hook.
Upload the hadoop-migration-assessment logging hook
Download the
hadoop-migration-assessmentquery logs extraction logging hook that contains the Hive logging hook JAR file.Extract the JAR file.
If you need to audit the tool to ensure that it meets compliance requirements, review the source code from the
hadoop-migration-assessmentlogging hook GitHub repository, and compile your own binary.Copy the JAR file into the auxiliary library folder on all clusters where you plan to enable the query logging. Depending on your vendor, you need to locate the auxiliary library folder in cluster settings and transfer the JAR file to the auxiliary library folder on the Hive cluster.
Set up configuration properties for
hadoop-migration-assessmentlogging hook. Depending on your Hadoop vendor, you need to use the UI console to edit cluster settings. Modify the/etc/hive/conf/hive-site.xmlfile or apply the configuration with the configuration manager.
Configure properties
If you already have other values for the following
configuration keys, append the settings using a comma (,).
To set up hadoop-migration-assessment logging hook, the following configuration
settings are required:
hive.exec.failure.hooks:com.google.cloud.bigquery.dwhassessment.hooks.MigrationAssessmentLoggingHookhive.exec.post.hooks:com.google.cloud.bigquery.dwhassessment.hooks.MigrationAssessmentLoggingHookhive.exec.pre.hooks:com.google.cloud.bigquery.dwhassessment.hooks.MigrationAssessmentLoggingHookhive.aux.jars.path: include the path to the logging hook JAR file, for examplefile://./HiveMigrationAssessmentQueryLogsHooks_deploy.jar dwhassessment.hook.base-directory: path to the query logs output folder. For example,hdfs://tmp/logs/.You can also set the following optional configurations:
dwhassessment.hook.queue.capacity: the queue capacity for the query events logging threads. The default value is64.dwhassessment.hook.rollover-interval: the frequency at which the file rollover must be performed. For example,600s. The default value is 3600 seconds (1 hour).dwhassessment.hook.rollover-eligibility-check-interval: the frequency at which the file rollover eligibility check is triggered in the background. For example,600s. The default value is 600 seconds (10 minutes).
Verify the logging hook
After you restart the hive-server2 process, run a test query
and analyze your debug logs. You can see the following message:
Logger successfully started, waiting for query events. Log directory is '[dwhassessment.hook.base-directory value]'; rollover interval is '60' minutes; rollover eligibility check is '10' minutes
The logging hook creates a date-partitioned subfolder in
the configured folder. The Avro file with query events appears in that
folder after the dwhassessment.hook.rollover-interval interval
or hive-server2 process termination. You can look for similar
messages in your debug logs to see the status of the rollover operation:
Updated rollover time for logger ID 'my_logger_id' to '2023-12-25T10:15:30'
Performed rollover check for logger ID 'my_logger_id'. Expected rollover time is '2023-12-25T10:15:30'
Rollover happens at the specified intervals or when the day changes. When the date changes, the logging hook also creates a new subfolder for that date.
Google recommends that you provide at least two weeks of query logs to be able to view more thorough insights.
You can also generate folders containing query logs from different Hive clusters and provide all of them for a single assessment.
Informatica
To request feedback or support for this feature, send an email to bq-edw-migration-support@google.com.
Requirements
- Access to Informatica PowerCenter Repository Manager client
- A Google Cloud account with a Cloud Storage bucket to store the data.
- An empty BigQuery dataset to store the results. Alternatively, you can create a BigQuery dataset when you create the assessment job using the Google Cloud console.
Requirement: Export object files
You can use the Informatica PowerCenter Repository Manager GUI to export your object files. For information, see Steps to Export Objects
Alternatively, you can also run the pmrep command to export your object
files with the following steps:
- Run the
pmrep connectcommand to connect to the repository:
pmrep connect -r `REPOSITORY_NAME` -d `DOMAIN_NAME` -n `USERNAME` -x `PASSWORD`
Replace the following:
REPOSITORY_NAME: name of the repository you want to connect toDOMAIN_NAME: name of the domain for the repositoryUSERNAME: username to connect to the repositoryPASSWORD: password of the username
- Once connected to the repository, use the
pmrep objectexportcommand to export the required objects:
pmrep objectexport -n `OBJECT_NAME` -o `OBJECT_TYPE` -f `FOLDER_NAME` -u `OUTPUT_FILE_NAME.xml`
Replace the following:
OBJECT_NAME: name of a specific object to exportOBJECT_TYPE: object type of the specified objectFOLDER_NAME: name of the folder containing the object to exportOUTPUT_FILE_NAME: name of the XML file to contain the object information
Upload metadata and query logs to Cloud Storage
Once you have extracted the metadata and query logs from your data warehouse, you can upload the files to a Cloud Storage bucket to proceed with the migration assessment.
Teradata
Upload the metadata and one or more zip files containing query logs to your Cloud Storage bucket. For more information about creating buckets and uploading files to Cloud Storage, see Create buckets and Upload objects from a filesystem. The limit for the total uncompressed size of all the files inside the metadata zip file is 50 GB.
The entries in all the zip files containing query logs are divided into the following:
- Query history files with the
query_history_prefix. - Time series files with the
utility_logs_,dbc.ResUsageScpu_, anddbc.ResUsageSpma_prefixes.
The limit for the total uncompressed size of all the query history files is 5 TB. The limit for the total uncompressed size of all the time series files is 1 TB.
In case the query logs are archived in a different database, see
the description of the -Dteradata-logs.query-logs-table and
-Dteradata-logs.sql-logs-table flags earlier in this section, which explains
how to provide an alternative location for the query logs.
Redshift
Upload the metadata and one or more zip files containing query logs to your Cloud Storage bucket. For more information about creating buckets and uploading files to Cloud Storage, see Create buckets and Upload objects from a filesystem. The limit for the total uncompressed size of all the files inside the metadata zip file is 50 GB.
The entries in all the zip files containing query logs are divided into the following:
- Query history files with the
querytext_andddltext_prefixes. - Time series files with the
query_queue_info_,wlm_query_, andquerymetrics_prefixes.
The limit for the total uncompressed size of all the query history files is 5 TB. The limit for the total uncompressed size of all the time series files is 1 TB.
Redshift Serverless
Upload the metadata and one or more zip files containing query logs to your Cloud Storage bucket. For more information about creating buckets and uploading files to Cloud Storage, see Create buckets and Upload objects from a filesystem.
Snowflake
Upload the metadata and the zip file(s) containing query logs and usage histories to your Cloud Storage bucket. When uploading these files to Cloud Storage, the following requirements must be met:
- The total uncompressed size of all the files inside the metadata zip file must be less than 50 GB.
- The metadata zip file and the zip file containing query logs must be uploaded to a Cloud Storage folder. If you have multiple zip files containing non-overlapping query logs, you can upload all of them.
- You must upload all the files to the same Cloud Storage folder.
- You must upload all of the metadata and query logs zip files exactly as
they are output by
dwh-migration-dumpertool. Don't extract, combine, or otherwise modify them. - The total uncompressed size of all the query history files must be less than 5 TB.
For more information about creating buckets and uploading files to Cloud Storage, see Create buckets and Upload objects from a filesystem.
Oracle
To request feedback or support for this feature, send email to bq-edw-migration-support@google.com.
Upload the zip file containing metadata and performance statistics to a
Cloud Storage bucket. By default, the filename for the zip file is
dwh-migration-oracle-stats.zip, but you can customize this by specifying it
in the --output flag. The limit for the total uncompressed size of all the
files inside the zip file is 50 GB.
For more information about creating buckets and uploading files to Cloud Storage, see Create buckets and Upload objects from a filesystem.
Hadoop / Cloudera
To request feedback or support for this feature, send email to bq-edw-migration-support@google.com.
Upload the zip file containing metadata and performance statistics to a
Cloud Storage bucket. By default, the filename for the zip file is
dwh-migration-cloudera-manager-RUN_DATE.zip (for
example dwh-migration-cloudera-manager-20250312T145808.zip), but you can
customize it with the --output flag. The limit for the total uncompressed
size of all files inside the zip file is 50 GB.
For more information about creating buckets and uploading files to Cloud Storage, see Create a bucket and Upload objects from a file system.
Apache Hive
Upload the metadata and folders containing query logs from one or multiple Hive clusters to your Cloud Storage bucket. For more information about creating buckets and uploading files to Cloud Storage, see Create buckets and Upload objects from a filesystem.
The limit for the total uncompressed size of all the files inside the metadata zip file is 50 GB.
You can use Cloud Storage connector to copy query logs directly to the Cloud Storage folder. The folders containing subfolders with query logs must be uploaded to the same Cloud Storage folder, where the metadata zip file is uploaded.
Query logs folders have query history files with the dwhassessment_
prefix. The limit for the total uncompressed size of all the query history
files is 5 TB.
Informatica
To request feedback or support for this feature, send email to bq-edw-migration-support@google.com.
Upload a zip file containing your Informatica XML repository objects to a
Cloud Storage bucket. This zip file must also include a
compilerworks-metadata.yaml file that contains the following:
product: arguments: "ConnectorArguments{connector=informatica, assessment=true}"
The limit for the total uncompressed size of all files inside the zip file is 50 GB.
For more information about creating buckets and uploading files to Cloud Storage, see Create buckets and Upload objects from a filesystem.
Run a BigQuery migration assessment
Follow these steps to run the BigQuery migration assessment. These steps assume you have uploaded the metadata files into a Cloud Storage bucket, as described in the previous section.
Required permissions
To enable the BigQuery Migration Service, you need the following Identity and Access Management (IAM) permissions:
resourcemanager.projects.getresourcemanager.projects.updateserviceusage.services.enableserviceusage.services.get
To access and use the BigQuery Migration Service, you need the following permissions on the project:
bigquerymigration.workflows.createbigquerymigration.workflows.getbigquerymigration.workflows.listbigquerymigration.workflows.deletebigquerymigration.subtasks.getbigquerymigration.subtasks.list
To run the BigQuery Migration Service, you need the following additional permissions.
Permission to access the Cloud Storage buckets for input and output files:
storage.objects.geton the source Cloud Storage bucketstorage.objects.liston the source Cloud Storage bucketstorage.objects.createon the destination Cloud Storage bucketstorage.objects.deleteon the destination Cloud Storage bucketstorage.objects.updateon the destination Cloud Storage bucketstorage.buckets.getstorage.buckets.list
Permission to read and update the BigQuery dataset where the BigQuery Migration Service writes the results:
bigquery.datasets.updatebigquery.datasets.getbigquery.datasets.createbigquery.datasets.deletebigquery.jobs.createbigquery.jobs.deletebigquery.jobs.listbigquery.jobs.updatebigquery.tables.createbigquery.tables.getbigquery.tables.getDatabigquery.tables.listbigquery.tables.updateData
To share the Looker Studio report with a user, you need to grant the following roles:
roles/bigquery.dataViewerroles/bigquery.jobUser
To customize this document to use your own project and user in the commands, edit these variables:
PROJECT,
USER_EMAIL.
Create a custom role with the permissions needed to use the BigQuery migration assessment:
gcloud iam roles create BQMSrole \ --project=PROJECT \ --title=BQMSrole \ --permissions=bigquerymigration.subtasks.get,bigquerymigration.subtasks.list,bigquerymigration.workflows.create,bigquerymigration.workflows.get,bigquerymigration.workflows.list,bigquerymigration.workflows.delete,resourcemanager.projects.update,resourcemanager.projects.get,serviceusage.services.enable,serviceusage.services.get,storage.objects.get,storage.objects.list,storage.objects.create,storage.objects.delete,storage.objects.update,bigquery.datasets.get,bigquery.datasets.update,bigquery.datasets.create,bigquery.datasets.delete,bigquery.tables.get,bigquery.tables.create,bigquery.tables.updateData,bigquery.tables.getData,bigquery.tables.list,bigquery.jobs.create,bigquery.jobs.update,bigquery.jobs.list,bigquery.jobs.delete,storage.buckets.list,storage.buckets.get
Grant the custom role BQMSrole to a user:
gcloud projects add-iam-policy-binding \ PROJECT \ --member=user:USER_EMAIL \ --role=projects/PROJECT/roles/BQMSrole
Grant the required roles to a user who you want to share the report with:
gcloud projects add-iam-policy-binding \ PROJECT \ --member=user:USER_EMAIL \ --role=roles/bigquery.dataViewer gcloud projects add-iam-policy-binding \ PROJECT \ --member=user:USER_EMAIL \ --role=roles/bigquery.jobUser
Supported locations
The BigQuery migration assessment feature is supported in two types of locations:
A region is a specific geographic place, such as London.
A multi-region is a large geographic area, such as the United States, that contains two or more regions. Multi-region locations can provide larger quotas than single regions.
For more information about regions and zones, see Geography and regions.
Regions
The following table lists the regions in the Americas where BigQuery migration assessment is available.| Region description | Region name | Details |
|---|---|---|
| Columbus, Ohio | us-east5 |
|
| Dallas | us-south1 |
|
| Iowa | us-central1 |
|
| South Carolina | us-east1 |
|
| Northern Virginia | us-east4 |
|
| Oregon | us-west1 |
|
Los Angeles | us-west2 |
| Salt Lake City | us-west3 |
| Region description | Region name | Details |
|---|---|---|
| Singapore | asia-southeast1 |
|
| Tokyo | asia-northeast1 |
| Region description | Region name | Details |
|---|---|---|
| Belgium | europe-west1 |
|
| Finland | europe-north1 |
|
| Frankfurt | europe-west3 |
|
| London | europe-west2 |
|
| Madrid | europe-southwest1 |
|
| Netherlands | europe-west4 |
|
| Paris | europe-west9 |
|
| Turin | europe-west12 |
|
| Warsaw | europe-central2 |
Zürich | europe-west6 |
|
Multi-regions
The following table lists the multi-regions where BigQuery migration assessment is available.| Multi-region description | Multi-region name |
|---|---|
| Data centers within member states of the European Union | EU |
| Data centers in the United States | US |
Before you begin
Before you run the assessment, you must enable the BigQuery Migration API and create a BigQuery dataset to store the results of the assessment.
Enable the BigQuery Migration API
Enable the BigQuery Migration API as follows:
In the Google Cloud console, go to the BigQuery Migration API page.
Click Enable.
Create a dataset for the assessment results
The BigQuery migration assessment writes the assessment results to tables in BigQuery. Before you begin, create a dataset to hold these tables. When you share the Looker Studio report, you must also give users permission to read this dataset. For more information, see Make the report available to users.
Run the migration assessment
Console
In the Google Cloud console, go to the BigQuery page.
In the navigation menu, click Assessment.
Click Start Assessment.
Fill in the assessment configuration dialog.
- For Display name, enter the name which can contain letters, numbers or underscores. This name is only for display purposes and does not have to be unique.
In the Data location list, choose a location for the assessment job. The assessment job must be located in the same location as your extracted files input Cloud Storage bucket and your output BigQuery dataset. However, if Cloud Storage bucket or BigQuery dataset is located in a multi-region, then the assessment job must be in any of the regions inside this multi-region.
If assessment location is a
USorEUmulti-region, then the Cloud Storage bucket location and the BigQuery dataset location must be in the same multi-region or in the location inside this multi-region. For more information on location constraints, see BigQuery Load Data Location considerations .For Assessment data source, choose your data warehouse.
For Path to input files, enter the path to the Cloud Storage bucket that contains your extracted files.
To choose how your assessment results are stored, do one of the following options:
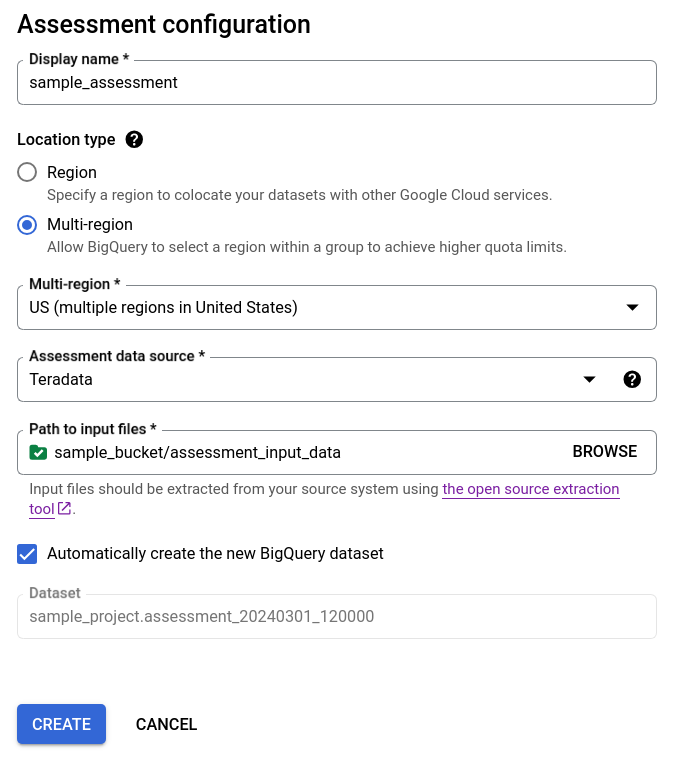
- Keep the Automatically create the new BigQuery dataset checkbox selected to have the BigQuery dataset created automatically. The name of the dataset is generated automatically.
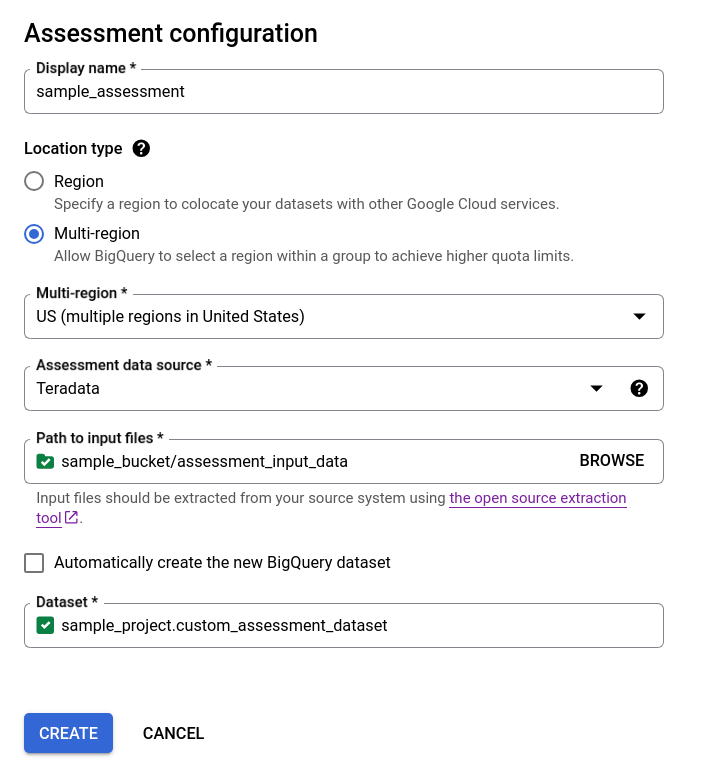
- Clear the Automatically create the new BigQuery dataset checkbox and either choose the existing empty
BigQuery dataset using the format
projectId.datasetId, or create a new dataset name. In this option you can choose the BigQuery dataset name.
Option 1 - automatic BigQuery dataset generation (default)
Option 2 - manual BigQuery dataset creation:
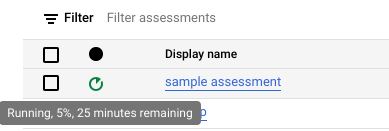
Click Create. You can see the status of the job in the assessment jobs list.
While the assessment is running, you can check its progress and estimated time to complete in the tooltip of the status icon.
While the assessment is running, you can click the View report link in the assessment jobs list to view the assessment report with partial data in Looker Studio. The View report link might take some time to appear while the assessment is running. The report opens in a new tab.
The report is updated with new data as they are processed. Refresh the tab with the report or click View report again to see the updated report.
After the assessment is complete, click View report to view the complete assessment report in Looker Studio. The report opens in a new tab.
API
Call the create
method with a defined workflow.
Then call the start
method to start the assessment workflow.
The assessment creates tables in the BigQuery dataset you created earlier. You can query these for information about the tables and queries used in your existing data warehouse. For information about the output files of the translation, see Batch SQL translator.
Shareable aggregated assessment result
For Amazon Redshift, Teradata, and Snowflake assessments, in
addition to the previously created BigQuery dataset, the workflow
creates another lightweight dataset with the same name, plus the
_shareableRedactedAggregate suffix. This dataset contains highly
aggregated data that is derived from the output dataset, and contains no
personally identifiable information (PII).
To find, inspect, and securely share the dataset with other users, see Query the migration assessment output tables.
The feature is on by default, but you can opt out using the public API.
Assessment details
To view the Assessment details page, click the display name in the assessment jobs list.

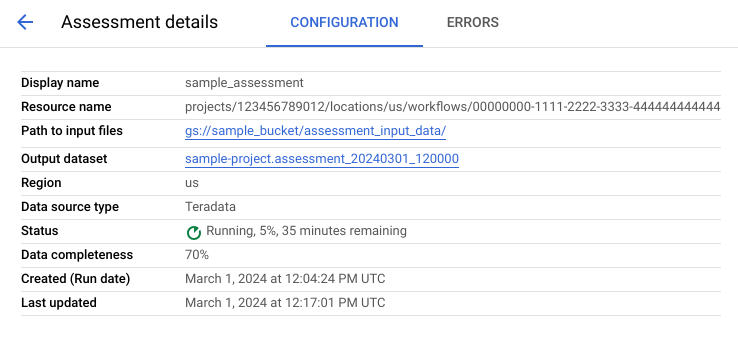
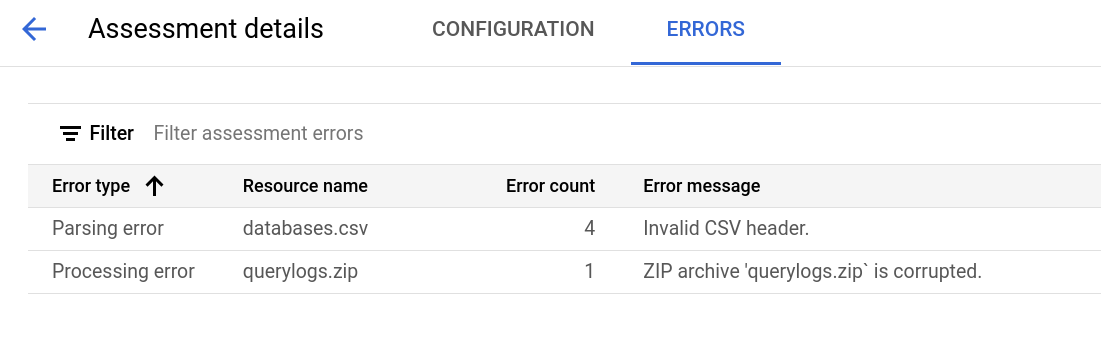
The assessment details page contains the Configuration tab, where you can view more information about an assessment job, and the Errors tab, where you can review any errors that happened during the assessment processing.
View the Configuration tab to see the properties of the assessment.
View the Errors tab to see the errors that happened during assessment processing.
Review and share the Looker Studio report
After the assessment task completes, you can create and share a Looker Studio report of the results.
Review the report
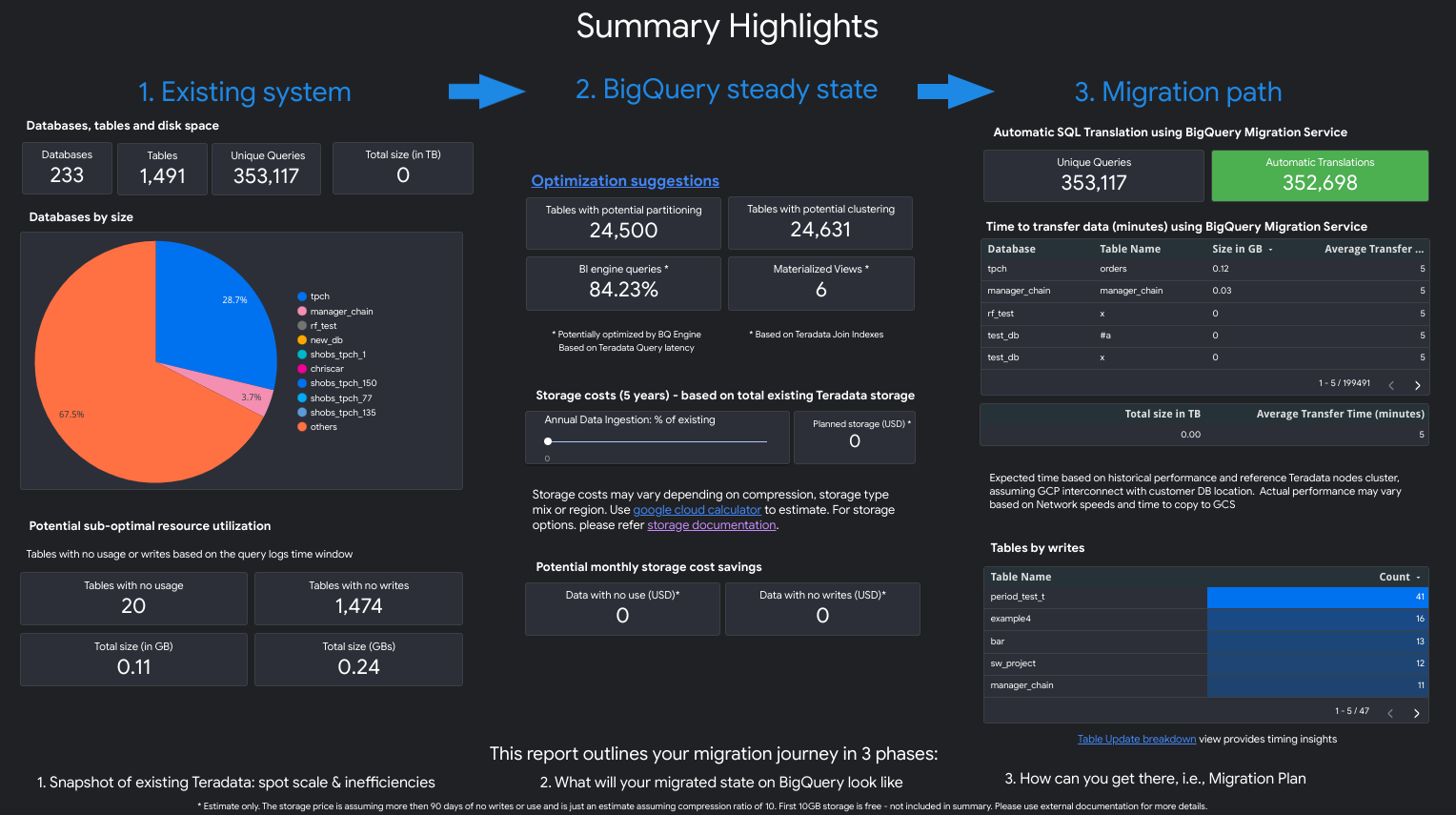
Click the View report link listed next to your individual assessment task. The Looker Studio report opens in a new tab, in a preview mode. You can use preview mode to review the content of the report before sharing it further.
The report looks similar to the following screenshot:
To see which views are contained in the report, select your data warehouse:
Teradata
The report is a three-part narrative that's prefaced by a summary highlights page. That page includes the following sections:
- Existing system. This section is a snapshot of the existing Teradata system and usage, including the number of databases, schemas, tables, and total size in TB. It also lists the schemas by size and points to potential sub-optimal resource utilization (tables with no writes or few reads).
- BigQuery steady state transformations (suggestions). This section shows what the system will look like on BigQuery after migration. It includes suggestions for optimizing workloads on BigQuery (and avoiding wastage).
- Migration plan. This section provides information about the migration effort itself—for example, getting from the existing system to the BigQuery steady state. This section includes the count of queries that were automatically translated and the expected time to move each table into BigQuery.
The details of each section include the following:
Existing system
- Compute & Queries
- CPU utilization:
- Heatmap of hourly average CPU utilization (overall system resource utilization view)
- Queries by hour and day with CPU utilization
- Queries by type (read/write) with CPU utilization
- Applications with CPU utilization
- Overlay of the hourly CPU utilization with average hourly query performance and average hourly application performance
- Queries histogram by type and query durations
- Applications details view (app, user, unique queries, reporting versus ETL breakdown)
- CPU utilization:
- Storage Overview
- Databases by volume, views, and access rates
- Tables with access rates by users, queries, writes, and temporary table creations
- Applications: Access rates and IP addresses
BigQuery steady state transformations (suggestions)
- Join indexes converted to materialized views
- Clustering and partitioning candidates based on metadata and usage
- Low latency queries identified as candidates for BigQuery BI Engine
- Columns configured with default values that use the column description feature to store default values
- Unique indexes in Teradata
(to prevent rows with non-unique keys in
a table) use staging tables and a
MERGEstatement to insert only unique records into the target tables and then discard duplicates - Remaining queries and schema translated as-is
Migration plan
- Detailed view with automatically translated queries
- Count of total queries with ability to filter by user, application, affected tables, queried tables, and query type
- Buckets of queries with similar patterns grouped and shown together so that the user is able to see the translation philosophy by query types
- Queries requiring human intervention
- Queries with BigQuery lexical structure violations
- User-defined functions and procedures
- BigQuery reserved keywords
- Tables schedules by writes and reads (to group them for moving)
- Data migration with the BigQuery Data Transfer Service: Estimated time to migrate by table
The Existing System section contains the following views:
- System Overview
- The System Overview view provides the high-level volume metrics of the key components in the existing system for a specified time period. The timeline that is evaluated depends on the logs that were analyzed by the BigQuery migration assessment. This view gives you quick insight into the source data warehouse utilization, which you can use for migration planning.
- Table Volume
- The Table Volume view provides statistics on the largest tables and databases found by the BigQuery migration assessment. Because large tables may take longer to extract from the source data warehouse system, this view can be helpful in migration planning and sequencing.
- Table Usage
- The Table Usage view provides statistics on which tables are heavily used within the source data warehouse system. Heavily used tables can help you to understand which tables might have many dependencies and require additional planning during the migration process.
- Applications
- The Applications Usage view and the Applications Patterns view provide statistics on applications found during processing of logs. These views let users understand usage of specific applications over time and the impact on resource usage. During a migration, it's important to visualize the ingestion and consumption of data to gain a better understanding of the dependencies of the data warehouse, and to analyze the impact of moving various dependent applications together. The IP Address table can be useful for pinpointing the exact application using the data warehouse over JDBC connections.
- Queries
- The Queries view gives a breakdown of the types of SQL statements executed and statistics of their usage. You can use the histogram of Query Type and Time to identify low periods of system utilization and optimal times of day to transfer data. You can also use this view to identify frequently executed queries and the users invoking those executions.
- Databases
- The Databases view provides metrics on the size, tables, views, and procedures defined in the source data warehouse system. This view can give insight into the volume of objects that you need to migrate.
- Database Coupling
- The Database Coupling view provides a high-level view on databases and tables that are accessed together in a single query. This view can show what tables and databases are referenced often and what you can use for migration planning.
The BigQuery steady state section contains the following views:
- Tables With No Usage
- The Tables With No Usage view displays tables in which the BigQuery migration assessment couldn't find any usage during the logs period that was analyzed. A lack of usage might indicate that you don't need to transfer that table to BigQuery during migration or that the costs of storing data in BigQuery could be lower. You should validate the list of unused tables because they could have usage outside of the logs period, such as a table that is only used once every three or six months.
- Tables With No Writes
- The Tables With No Writes view displays tables in which the BigQuery migration assessment couldn't find any updates during the logs period that was analyzed. A lack of writes can indicate where you might lower your storage costs in BigQuery.
- Low-Latency Queries
- The Low-Latency Queries view displays a distribution of query runtimes based on the log data analyzed. If the query duration distribution chart displays a large number of queries with < 1 second in runtime, consider enabling BigQuery BI Engine to accelerate BI and other low-latency workloads.
- Materialized Views
- The Materialized View provides further optimization suggestions to boost performance on BigQuery.
- Clustering and Partitioning
The Partitioning and Clustering view displays tables that would benefit from partitioning, clustering, or both.
The Metadata suggestions are achieved by analyzing the source data warehouse schema (like Partitioning and Primary Key in the source table) and finding the closest BigQuery equivalent to achieve similar optimization characteristics.
The Workload suggestions are achieved by analyzing the source query logs. The recommendation is determined by analyzing the workloads, especially
WHEREorJOINclauses in the analyzed query logs.- Clustering Recommendation
The Partitioning view displays tables which might have greater than 10,000 partitions, based on their partitioning constraint definition. These tables tend to be good candidates for BigQuery clustering, which enables fine-grained table partitions.
- Unique Constraints
The Unique Constraints view displays both
SETtables and unique indexes defined within the source data warehouse. In BigQuery, it's recommended to use staging tables and aMERGEstatement to insert only unique records into a target table. Use the contents of this view to help determine which tables you might need to adjust ETL for during the migration.- Default Values / Check Constraints
This view shows tables that use check constraints to set default column values. In BigQuery, see Specify default column values.
The Migration path section of the report contains the following views:
- SQL Translation
- The SQL Translation view lists the count and details of queries that were automatically converted by BigQuery migration assessment and don't need manual intervention. Automated SQL Translation typically achieves high translation rates if metadata is provided. This view is interactive and allows analysis of common queries and how these are translated.
- Offline Effort
- The Offline Effort view captures the areas that need manual intervention, including specific UDFs and potential lexical structure and syntax violations for tables or columns.
- BigQuery Reserved Keywords
- The BigQuery Reserved Keywords view displays detected usage
of keywords that have special meaning in the GoogleSQL language,
and cannot be used as identifiers unless enclosed by backtick (
`) characters. - Table Updates Schedule
- The Table Updates Schedule view shows when and how frequently tables are updated to help you plan how and when to move them.
- Data Migration to BigQuery
- The Data Migration to BigQuery view outlines the migration path with the expected time to migrate your data using the BigQuery Data Transfer Service. For more information, see the BigQuery Data Transfer Service for Teradata guide.
The Appendix section contains the following views:
- Case Sensitivity
- The Case Sensitivity view shows tables in the source data warehouse that are configured to perform case-insensitive comparisons. By default, string comparisons in BigQuery are case-sensitive. For more information, see Collation.
Redshift
- Migration Highlights
- The Migration Highlights view provides an executive summary of the three sections of the report:
- The Existing System panel provides information on the number of databases, schemas, tables, and the total size of the existing Redshift System. It also lists the schemas by size and potential sub-optimal resource utilization. You can use this information to optimize your data by removing, partitioning, or clustering your tables.
- The BigQuery Steady State panel provides information on what your data will look like post-migration on BigQuery, including the number of queries that can be automatically translated using BigQuery Migration Service. This section also shows the costs of storing your data in BigQuery based on your annual data ingestion rate, along with optimization suggestions for tables, provisioning, and space.
- The Migration Path panel provides information on the migration effort itself. For each table it shows the expected time to migrate, the number of rows in the table, and its size.
The Existing System section contains the following views:
- Queries by Type and Schedule
- The Queries by Type and Schedule view categorizes your queries into ETL/Write and Reporting/Aggregation. Seeing your query mix over time helps you understand your existing usage patterns, and identify burstiness and potential over-provisioning that can impact cost and performance.
- Query Queuing
- The Query Queuing view provides additional details on system load including query volume, mix, and any performance impacts due to queuing, such as insufficient resources.
- Queries and WLM Scaling
- The Queries and WLM Scaling view identifies concurrency scaling as an added cost and configuration complexity. It shows how your Redshift system routes queries based on the rules you specified, and performance impacts due to queuing, concurrency scaling, and evicted queries.
- Queuing and Waiting
- The Queuing and Waiting view is a deeper look into queue and wait times for queries over time.
- WLM Classes and Performance
- The WLM Classes and Performance view provides an optional way to map your rules to BigQuery. However, we recommend you let BigQuery automatically route your queries.
- Query & Table volume insights
- The Query & Table volume insights view lists queries by size, frequency, and top users. This helps you categorize the sources of load on the system and plan how to migrate your workloads.
- Databases and Schemas
- The Databases and Schemas view provides metrics on the size, tables, views, and procedures defined in the source data warehouse system. This provides insight into the volume of objects which need to be migrated.
- Table Volume
- The Table Volume view provides statistics on the largest tables and databases, showing how they are accessed. Because large tables may take longer to extract from the source data warehouse system, this view helps you with migration planning and sequencing.
- Table Usage
- The Table Usage view provides statistics on which tables are heavily used within the source data warehouse system. Heavily used tables can be leveraged to understand tables which might have many dependencies and warrant additional planning during the migration process.
- Importers & Exporters
- The Importers & Exporters view provides information on data and users
involved in data import (using
COPYqueries) and data export (usingUNLOADqueries). This view helps to identify staging layer and processes related to ingestion and exports. - Cluster Utilization
- The Cluster Utilization view provides general information about all available clusters and displays CPU utilization for each cluster. This view can help you understand system capacity reserve.
The BigQuery steady state section contains the following views:
- Clustering & Partitioning
The Partitioning and Clustering view displays tables that would benefit from partitioning, clustering, or both.
The Metadata suggestions are achieved by analyzing the source data warehouse schema (like Sort Key and Dist Key in the source table) and finding the closest BigQuery equivalent to achieve similar optimization characteristics.
The Workload suggestions are achieved by analyzing the source query logs. The recommendation is determined by analyzing the workloads, especially
WHEREorJOINclauses in the analyzed query logs.At the bottom of the page, there is a translated create table statement with all optimizations provided. All translated DDL statements can be also extracted from the dataset. Translated DDL statements are stored in
SchemaConversiontable inCreateTableDDLcolumn.The recommendations in the report are provided only for tables larger than 1 GB because small tables won't benefit from clustering and partitioning. However, DDL for all tables (including tables smaller than 1GB) are available in
SchemaConversiontable.- Tables With No Usage
The Tables With No Usage view displays tables where the BigQuery migration assessment did not identify any usage during the analyzed logs period. A lack of usage might indicate that you don't need to transfer that table to BigQuery during migration or that the costs of storing data in BigQuery could be lower (billed as Long-term storage). We recommend validating the list of unused tables because they could have usage outside of the logs period, such as a table that is only used once every three or six months.
- Tables With No Writes
The Tables With No Writes view displays tables where the BigQuery migration assessment did not identify any updates during the analyzed logs period. A lack of writes can indicate where you might lower your storage costs in BigQuery (billed as Long-term storage).
- BigQuery BI Engine and Materialized Views
The BigQuery BI Engine and Materialized Views provides further optimization suggestions to boost performance on BigQuery.
The Migration path section contains the following views:
- SQL Translation
- The SQL Translation view lists the count and details of queries that were automatically converted by BigQuery migration assessment and don't need manual intervention. Automated SQL Translation typically achieves high translation rates if metadata is provided.
- SQL Translation Offline Effort
- The SQL Translation Offline Effort view captures the areas that need manual intervention, including specific UDFs and queries with potential translation ambiguities.
- Alter Table Append Support
- The Alter Table Append Support view shows details about common Redshift SQL constructs that don't have a direct BigQuery counterpart.
- Copy Command Support
- The Copy Command Support view shows details about common Redshift SQL constructs that don't have a direct BigQuery counterpart.
- SQL Warnings
- The SQL Warnings view captures areas that are successfully translated, but require a review.
- Lexical Structure & Syntax Violations
- The Lexical Structure & Syntax Violations view displays names of columns, tables, functions, and procedures that violate BigQuery syntax.
- BigQuery Reserved Keywords
- The BigQuery Reserved Keywords view displays detected usage
of keywords that have special meaning in the GoogleSQL language,
and cannot be used as identifiers unless enclosed by backtick (
`) characters. - Schema Coupling
- The Schema Coupling view provides a high-level view on databases, schemas, and tables that are accessed together in a single query. This view can show what tables, schemas, and databases are referenced often and what you can use for migration planning.
- Table Updates Schedule
- The Table Updates Schedule view shows how when and how frequently tables are updated to help you plan how and when to move them.
- Table Scale
- The Table Scale view lists your tables with the most columns.
- Data Migration to BigQuery
- The Data Migration to BigQuery view outlines the migration path with the expected time to migrate your data using the BigQuery Migration Service Data Transfer Service. For more information, see the BigQuery Data Transfer Service for Redshift guide.
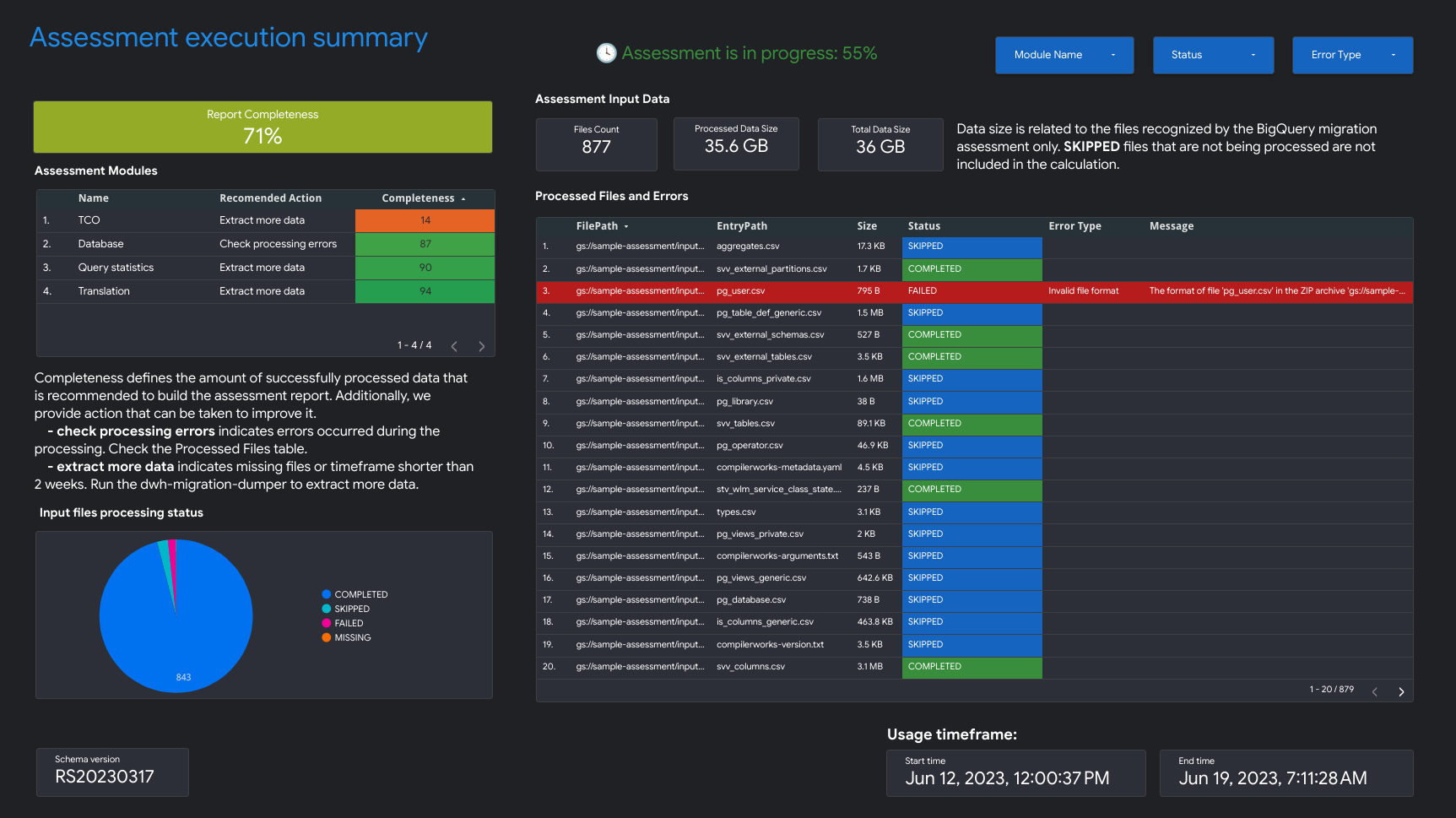
- Assessment execution summary
The Assessment execution summary contains the report completeness, the progress of the on-going assessment, and the status of processed files and errors.
Report completeness represents the percentage of successfully processed data that is recommended to display meaningful insights in the assessment report. If the data for a particular section of the report is missing, this information is listed in the Assessment Modules table under the Report Completeness indicator.
The progress metric indicates the percentage of the data processed so far along with the estimate of the remaining time to process all of the data. After the processing is complete, the progress metric is not displayed.
Redshift Serverless
- Migration Highlights
- This report page shows the summary of existing Amazon Redshift Serverless databases including the size and number of tables. Additionally, it provides the high level estimate of the Annual Contract Value (ACV)—the cost of compute and storage in BigQuery. The Migration Highlights view provides an executive summary of the three sections of the report.
The Existing System section has the following views:
- Databases and Schemas
- Provides a breakdown of total storage size in GB for each database, schema, or table.
- External Databases and Schemas
- Provides a breakdown of total storage size in GB for each external database, schema, or table.
- System Utilization
- Provides general information about the historical system utilization. This view displays the historical usage of RPU (Amazon Redshift Processing Units) and daily storage consumption. This view can help you understand the system capacity reserve.
The BigQuery Steady State section provides information on what your data will look like post-migration on BigQuery, including the number of queries that can be automatically translated using BigQuery Migration Service. This section also shows the costs of storing your data in BigQuery based on your annual data ingestion rate, along with optimization suggestions for tables, provisioning, and space. The Steady State section has the following views:
- Amazon Redshift Serverless versus BigQuery pricing
- Provides a comparison of Amazon Redshift Serverless and BigQuery pricing models to help you understand the benefits and potential cost savings after you migrate to BigQuery.
- BigQuery Compute Cost (TCO)
- Lets you estimate the cost of compute in BigQuery. There are four manual inputs in the calculator: BigQuery Edition, Region, Commitment period, and Baseline. By default, the calculator provides optimal, cost-effective baseline commitments that you can manually override.
- Total Cost of Ownership
- Lets you estimate the Annual Contract Value (ACV)—the cost of compute and storage in BigQuery. The calculator also lets you calculate the storage cost, which varies for active storage and long-term storage, depending on the table modifications during the analyzed time period. For more information, see Storage pricing.
The Appendix section contains this view:
- Assessment Execution Summary
- Provides the assessment execution details including the list of processed files, errors and report completeness. You can use this page to investigate missing data in the report and to better understand the report's completeness.
Snowflake
The report consists of different sections that can be used either separately or together. The following diagram organizes these sections into three common user goals to help you assess your migration needs:
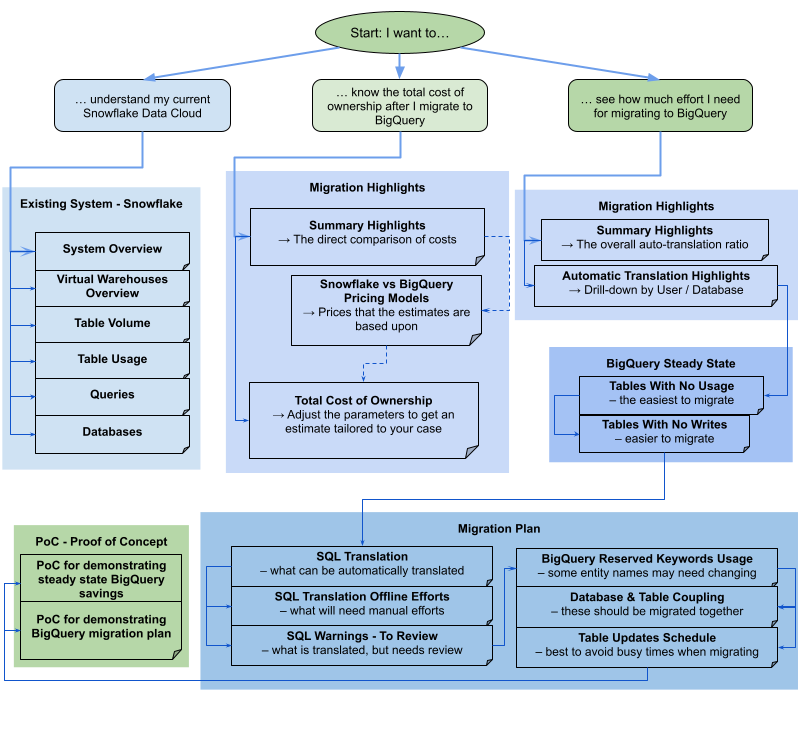
Migration Highlights views
The Migration Highlights section contains the following views:
- Snowflake versus BigQuery Pricing Models
- Listing of the pricings with different tiers/editions. Also includes an illustration of how BigQuery autoscaling can help save more cost compared to that of Snowflake.
- Total Cost of Ownership
- Interactive table, allowing the user to define: BigQuery Edition, commitment, baseline slot commitment, percentage of active storage, and percentage of data loaded or changed. Helps better estimate the cost for custom cases.
- Automatic Translation Highlights
- Aggregated translation ratio, grouped by either user or database, ordered ascending or descending. Also includes the most common error message for failed auto translation.
Existing System views
The Existing System section contains the following views:
- System Overview
- The System Overview view provides the high-level volume metrics of the key components in the existing system for a specified time period. The timeline that is evaluated depends on the logs that were analyzed by the BigQuery migration assessment. This view gives you quick insight into the source data warehouse utilization, which you can use for migration planning.
- Virtual Warehouses Overview
- Shows the Snowflake cost by warehouse, as well as the node-based rescaling over the period.
- Table Volume
- The Table Volume view provides statistics on the largest tables and databases found by the BigQuery migration assessment. Because large tables may take longer to extract from the source data warehouse system, this view can be helpful in migration planning and sequencing.
- Table Usage
- The Table Usage view provides statistics on which tables are heavily used within the source data warehouse system. Heavily used tables can help you to understand which tables might have many dependencies and require additional planning during the migration process.
- Queries
- The Queries view gives a breakdown of the types of SQL statements executed and statistics of their usage. You can use the histogram of Query Type and Time to identify low periods of system utilization and optimal times of day to transfer data. You can also use this view to identify frequently executed queries and the users invoking those executions.
- Databases
- The Databases view provides metrics on the size, tables, views, and procedures defined in the source data warehouse system. This view provides insight into the volume of objects that you need to migrate.
BigQuery steady state views
The BigQuery steady state section contains the following views:
- Tables With No Usage
- The Tables With No Usage view displays tables in which the BigQuery migration assessment couldn't find any usage during the logs period that was analyzed. This can indicate which tables might not need to be transferred to BigQuery during migration or that the costs of storing data in BigQuery could be lower. You must validate the list of unused tables since they could have usage outside of the logs period analyzed, such as a table which is only used once per quarter or half.
- Tables With No Writes
- The Tables With No Writes view displays tables in which the BigQuery migration assessment couldn't find any updates during the logs period that was analyzed. This can indicate that the costs of storing data in BigQuery could be lower.
Migration Plan views
The Migration Plan section of the report contains the following views:
- SQL Translation
- The SQL Translation view lists the count and details of queries that were automatically converted by BigQuery migration assessment and don't need manual intervention. Automated SQL Translation typically achieves high translation rates if metadata is provided. This view is interactive and allows analysis of common queries and how these are translated.
- SQL Translation Offline Effort
- The Offline Effort view captures the areas that need manual intervention, including specific UDFs and potential lexical structure and syntax violations for tables or columns.
- SQL Warnings - To Review
- The Warnings To Review view captures the areas that are mostly translated but requires some human inspection.
- BigQuery Reserved Keywords
- The BigQuery Reserved Keywords view displays detected usage
of keywords that have special meaning in the GoogleSQL language,
and cannot be used as identifiers unless enclosed by backtick (
`) characters. - Database and Table Coupling
- The Database Coupling view provides a high-level view on databases and tables that are accessed together in a single query. This view can show what tables and databases are often referenced and what can be used for migration planning.
- Table Updates Schedule
- The Table Updates Schedule view shows when and how frequently tables are updated to help you plan how and when to move them.
Proof of Concept views
The PoC (proof of concept) section contains the following views:
- PoC for demonstrating steady state BigQuery savings
- Includes the most frequent queries, the queries reading the most data, the slowest queries, and the tables impacted by these aforementioned queries.
- PoC for demonstrating BigQuery migration plan
- Showcases how BigQuery translate the most complex queries and the tables they impact.
Oracle
To request feedback or support for this feature, send email to bq-edw-migration-support@google.com.
Migration Highlights
The Migration Highlights section contains the following views:
- Existing system: a snapshot of the existing Oracle system and usage, including the number of databases, schemas, tables, and total size in GB. It also provides the workload classification summary for each database to help you decide if BigQuery is the right migration target.
- Compatibility: provides information about the migration effort itself. For each analyzed database it shows the expected time to migrate and the number of database objects that can be migrated automatically with Google provided tools.
- BigQuery steady state: contains information on what your data will look like post-migration on BigQuery, including the costs of storing your data in BigQuery based on your annual data ingestion rate and the compute cost estimation. In addition, it provides insights into any underutilized tables.
Existing System
The Existing System section contains the following views:
- Workloads Characteristic: describes the workload type for each database based on the analyzed performance metrics. Each database is classified as OLAP, Mixed, or OLTP. This information can help you to make a decision on which databases can be migrated to BigQuery.
- Databases and Schemas: provides a breakdown of total storage size in GB for each database, schema, or table. In addition you can use this view to identify materialized views and external tables.
- Database Features and Links: shows the list of Oracle features used in your database, together with the BigQuery equivalent features or services that can be used after the migration. In addition, you can explore the Database Links to better understand connections between the databases.
- Database Connections: provides insight into the database sessions started by the user or application. Analyzing this data can help you identify external applications that may require additional effort during the migration.
- Query Types: provides a breakdown of the types of SQL statements executed and statistics of their usage. You can use the hourly histogram of Query Executions or Query CPU Time to identify low periods of system utilization and optimal times of day to transfer data.
- PL/SQL Source Code: provides insight into the PL/SQL objects, like functions or procedures, and their size for each database and schema. In addition, the hourly executions histogram can be used to identify peak hours with most PL/SQL executions.
- System Utilization: provides general information about the historical system utilization. This view displays the hourly usage of CPU and daily storage consumption. This view can help to understand the system capacity reserve.
BigQuery Steady State
The BigQuery Steady State section contains the following views:
- Exadata versus BigQuery pricing: provides the general comparison of Exadata and BigQuery pricing models to help you understand the benefits and potential cost savings after the migration to BigQuery.
- BigQuery Database Read/Writes: provides insights about the database's physical disk operations. Analyzing this data can help you find the best time to perform data migration from Oracle to BigQuery.
- BigQuery Compute Cost: lets you estimate the cost of compute in BigQuery. There are four manual inputs in the calculator: BigQuery Edition, Region, Commitment period, and Baseline. By default, the calculator provides optimal, cost-effective baseline commitment that you can manually override. The Annual Autoscaling Slot Hours value provides the number of slot hours used outside of commitment. This value is calculated using system utilization. The visual explanation of relationships between the baseline, autoscaling, and utilization is provided at the end of the page. Each estimation shows the probable number and an estimation range.
- Total Cost of Ownership (TCO): lets you estimate the Annual Contract Value (ACV) - the cost of compute and storage in BigQuery. The calculator also lets you calculate the storage cost. The calculator also lets you calculate the storage cost, which varies for active storage and long-term storage, depending on the table modifications during the analyzed time period. For more information about storage pricing, see Storage pricing.
- Underutilized Tables: provides information about unused and read-only tables based on the usage metrics from the analyzed time period. A lack of usage might indicate that you don't need to transfer the table to BigQuery during a migration or that the costs of storing data in BigQuery could be lower (billed as long-term storage). We recommend that you validate the list of unused tables in case they have usage outside of the analyzed time period.
Migration Hints
The Migration Hints section contains the following views:
- Database Objects Compatibility: provides the overview of database objects compatibility with BigQuery, including the number of objects that can be automatically migrated with Google provided tools or require manual action. This information is shown for each database, schemma, and database object type.
- Database Objects Migration Effort: shows the estimate of migration effort in hours for each database, schema, or database object type. In addition it shows the percentage of small, medium, and large objects based on the migration effort.
- Database Schema Migration Effort: provides the list of all detected database object types, their number, compatibility with BigQuery and the estimated migration effort in hours.
- Database Schema Migration Effort Detailed: provides more deep dive insight into the database schema migration effort, including the information for each single object.
Proof of Concept views
The Proof of Concept views section contains the following views:
- Proof of concept migration: shows the suggested list of databases with the lowest migration effort that are good candidates for initial migration. In addition, it shows the top queries that can help to demonstrate the time and cost savings, and value of BigQuery using a proof of concept.
Appendix
The Appendix section contains the following views:
- Assessment Execution Summary: provides the assessment execution details including the list of processed files, errors, and report completeness. You can use this page to investigate missing data in the report and better understand the overall report completeness.
Apache Hive
The report consisting of a three-part narrative is prefaced by a summary highlights page that includes the following sections:
Existing System - Apache Hive. This section consists of a snapshot of the existing Apache Hive system and usage including the number of databases, tables, their total size in GB, and the number of query logs processed. This section also lists the databases by size and points to potential sub-optimal resource utilization (tables with no writes or few reads) and provisioning. The details of this section include the following:
- Compute and queries
- CPU utilization:
- Queries by hour and day with CPU utilization
- Queries by type (read/write)
- Queues and applications
- Overlay of the hourly CPU utilization with average hourly query performance and average hourly application performance
- Queries histogram by type and query durations
- Queueing and waiting page
- Queues detailed view (queue, user, unique queries, reporting versus ETL breakdown, by metrics)
- CPU utilization:
- Storage overview
- Databases by volume, views, and access rates
- Tables with access rates by users, queries, writes, and temporary table creations
- Queues and applications: Access rates and client IP addresses
- Compute and queries
BigQuery Steady State. This section shows what the system will look like on BigQuery after migration. It includes suggestions for optimizing workloads on BigQuery (and avoiding wastage). The details of this section include the following:
- Tables identified as candidates for materialized views.
- Clustering and partitioning candidates based on metadata and usage.
- Low-latency queries identified as candidates for BigQuery BI Engine.
- Tables without read or write usage.
- Partitioned tables with the data skew.
Migration Plan. This section provides information about the migration effort itself. For example, getting from the existing system to the BigQuery steady state. This section contains identified storage targets for each table, tables identified as significant for migration, and the count of queries that were automatically translated. The details of this section include the following:
- Detailed view with automatically translated queries
- Count of total queries with ability to filter by user, application, affected tables, queried tables, and query type.
- Query buckets with similar patterns grouped together, enabling users to see the translation philosophy by query types.
- Queries requiring human intervention
- Queries with BigQuery lexical structure violations
- User-defined functions and procedures
- BigQuery reserved keywords
- Query requiring review
- Tables schedules by writes and reads (to group them for moving)
- Identified storage target for external and managed tables
- Detailed view with automatically translated queries
The Existing System - Hive section contains the following views:
- System Overview
- This view provides the high-level volume metrics of the key components in the existing system for a specified time period. The timeline that is evaluated depends on the logs that were analyzed by the BigQuery migration assessment. This view gives you quick insight into the source data warehouse utilization, which you can use for migration planning.
- Table Volume
- This view provides statistics on the largest tables and databases found by the BigQuery migration assessment. Because large tables may take longer to extract from the source data warehouse system, this view can be helpful in migration planning and sequencing.
- Table Usage
- This view provides statistics on which tables are heavily used within the source data warehouse system. Heavily used tables can help you to understand which tables might have many dependencies and require additional planning during the migration process.
- Queues Utilization
- This view provides statistics on YARN queues usage found during processing of logs. These views let users understand usage of specific queues and applications over time and the impact on resource usage. These views also help identify and prioritize workloads for migration. During a migration, it's important to visualize the ingestion and consumption of data to gain a better understanding of the dependencies of the data warehouse, and to analyze the impact of moving various dependent applications together. The IP address table can be useful for pinpointing the exact application using the data warehouse over JDBC connections.
- Queues Metrics
- This view provides a breakdown of the different metrics on YARN queues found during processing of logs. This view lets users to understand patterns of usage in specific queues and impact on migration. You can also use this view to identify connections between tables accessed in queries and queues where the query was executed.
- Queuing and Waiting
- This view provides an insight on the query queuing time in the source data warehouse. Queuing times indicate performance degradation due to under provisioning, and additional provisioning requires increased hardware and maintenance costs.
- Queries
- This view gives a breakdown of the types of SQL statements executed and statistics of their usage. You can use the histogram of Query Type and Time to identify low periods of system utilization and optimal times of day to transfer data. You can also use this view to identify most-used Hive execution engines and frequently executed queries along with the user details.
- Databases
- This view provides metrics on the size, tables, views, and procedures defined in the source data warehouse system. This view can give insight into the volume of objects that you need to migrate.
- Database & Table Coupling
- This view provides a high-level view on databases and tables that are accessed together in a single query. This view can show what tables and databases are referenced often and what you can use for migration planning.
The BigQuery Steady State section contains the following views:
- Tables With No Usage
- The Tables With No Usage view displays tables in which the BigQuery migration assessment couldn't find any usage during the logs period that was analyzed. A lack of usage might indicate that you don't need to transfer that table to BigQuery during migration or that the costs of storing data in BigQuery could be lower. You must validate the list of unused tables because they could have usage outside of the logs period, such as a table that is only used once every three or six months.
- Tables With No Writes
- The Tables With No Writes view displays tables in which the BigQuery migration assessment couldn't find any updates during the logs period that was analyzed. A lack of writes can indicate where you might lower your storage costs in BigQuery.
- Clustering and Partitioning Recommendations
This view displays tables that would benefit from partitioning, clustering, or both.
The Metadata suggestions are achieved by analyzing the source data warehouse schema (like Partitioning and Primary Key in the source table) and finding the closest BigQuery equivalent to achieve similar optimization characteristics.
The Workload suggestions are achieved by analyzing the source query logs. The recommendation is determined by analyzing the workloads, especially
WHEREorJOINclauses in the analyzed query logs.- Partitions converted to Clusters
This view displays tables that have more than 10,000 partitions, based on their partitioning constraint definition. These tables tend to be good candidates for BigQuery clustering, which enables fine-grained table partitions.
- Skewed partitions
The Skewed Partitions view displays tables that are based on the metadata analysis and have data skew on one or several partitions. These tables are good candidates for schema change, as queries on skewed partitions might not perform well.
- BI Engine and Materialized Views
The Low-Latency Queries and Materialized Views view displays a distribution of query runtimes based on the log data analyzed and a further optimization suggestions to boost performance on BigQuery. If the query duration distribution chart displays a large number of queries with runtime less than 1 second, consider enabling BI Engine to accelerate BI and other low-latency workloads.
The Migration Plan section of the report contains the following views:
- SQL Translation
- The SQL Translation view lists the count and details of queries that were automatically converted by BigQuery migration assessment and don't need manual intervention. Automated SQL Translation typically achieves high translation rates if metadata is provided. This view is interactive and allows analysis of common queries and how these are translated.
- SQL Translation Offline Effort
- The Offline Effort view captures the areas that need manual intervention, including specific UDFs and potential lexical structure and syntax violations for tables or columns.
- SQL Warnings
- The SQL Warnings view captures areas that are successfully translated, but require a review.
- BigQuery Reserved Keywords
- The BigQuery Reserved Keywords view displays detected usage
of keywords that have special meaning in the GoogleSQL language.
These keywords can't be used as identifiers unless enclosed by
backtick (
`) characters. - Table Updates Schedule
- The Table Updates Schedule view shows when and how frequently tables are updated to help you plan how and when to move them.
- BigLake External Tables
- The BigLake External Tables view outlines tables that are identified as targets to migration to BigLake instead of BigQuery.
The Appendix section of the report contains the following views:
- Detailed SQL Translation Offline Effort Analysis
- The Detailed Offline Effort Analysis view provides an additional insight of the SQL areas that need manual intervention.
- Detailed SQL Warnings Analysis
- The Detailed Warnings Analysis view provides an additional insight of the SQL areas that are successfully translated, but require a review.
Share the report
The Looker Studio report is a frontend dashboard for the migration assessment. It relies on the underlying dataset access permissions. To share the report, the recipient must have access to both the Looker Studio report itself and the BigQuery dataset that contains the assessment results.
When you open the report from the Google Cloud console, you are viewing the report in the preview mode. To create and share the report with other users, perform the following steps:
- Click Edit and share. Looker Studio prompts you to attach newly created Looker Studio connectors to the new report.
- Click Add to report. The report receives an individual report ID, which you can use to access the report.
- To share the Looker Studio report with other users, follow the steps given in Share reports with viewers and editors.
- Grant the users permission to view the BigQuery dataset that was used to run the assessment task. For more information, see Granting access to a dataset.
Query the migration assessment output tables
Although the Looker Studio reports are the most convenient way to view the assessment results, you can also view and query the underlying data in the BigQuery dataset.
Example query
The following example gets the total number of unique queries, the number of queries that failed translation, and the percentage of unique queries that failed translation.
SELECT QueryCount.v AS QueryCount, ErrorCount.v as ErrorCount, (ErrorCount.v * 100) / QueryCount.v AS FailurePercentage FROM ( SELECT COUNT(*) AS v FROM `your_project.your_dataset.TranslationErrors` WHERE Severity = "ERROR" ) AS ErrorCount, ( SELECT COUNT(DISTINCT(QueryHash)) AS v FROM `your_project.your_dataset.Queries` ) AS QueryCount;
Share your dataset with users in other projects
After inspecting the dataset, if you would like to share it with a user that is not in your project, you can do so by utilizing the publisher workflow of BigQuery sharing (formerly Analytics Hub).
In the Google Cloud console, go to the BigQuery page.
Click the dataset to view its details.
Click Sharing > Publish as listing.
In the dialog that opens, create a listing as prompted.
If you already have a data exchange, skip step 5.
Create a data exchange and set permissions. To allow a user to view your listings in this exchange, add them to the Subscribers list.
Enter the listing details.
Display name is the name of this listing and is required; other fields are optional.
Click Publish.
A private listing is created.
For your listing, select More actions under Actions.
Click Copy share link.
You can share the link with users that have subscription access to your exchange or listing.
Assessment tables schemata
To see the tables and their schemata that the BigQuery migration assessment writes to BigQuery, select your data warehouse:
Teradata
AllRIChildren
This table provides the referential integrity information of the table children.
| Column | Type | Description |
|---|---|---|
IndexId |
INTEGER |
The reference index number. |
IndexName |
STRING |
The name of the index. |
ChildDB |
STRING |
The name of the referencing database, converted to lowercase. |
ChildDBOriginal |
STRING |
The name of the referencing database with the case preserved. |
ChildTable |
STRING |
The name of the referencing table, converted to lowercase. |
ChildTableOriginal |
STRING |
The name of the referencing table with the case preserved. |
ChildKeyColumn |
STRING |
The name of a column in the referencing key, converted to lowercase. |
ChildKeyColumnOriginal |
STRING |
The name of a column in the referencing key with the case preserved. |
ParentDB |
STRING |
The name of the referenced database, converted to lowercase. |
ParentDBOriginal |
STRING |
The name of the referenced database with the case preserved. |
ParentTable |
STRING |
The name of the referenced table, converted to lowercase. |
ParentTableOriginal |
STRING |
The name of the referenced table with the case preserved. |
ParentKeyColumn |
STRING |
The name of the column in a referenced key, converted to lowercase. |
ParentKeyColumnOriginal |
STRING |
The name of the column in a referenced key with the case preserved. |
AllRIParents
This table provides the referential integrity information of the table parents.
| Column | Type | Description |
|---|---|---|
IndexId |
INTEGER |
The reference index number. |
IndexName |
STRING |
The name of the index. |
ChildDB |
STRING |
The name of the referencing database, converted to lowercase. |
ChildDBOriginal |
STRING |
The name of the referencing database with the case preserved. |
ChildTable |
STRING |
The name of the referencing table, converted to lowercase. |
ChildTableOriginal |
STRING |
The name of the referencing table with the case preserved. |
ChildKeyColumn |
STRING |
The name of a column in the referencing key, converted to lowercase. |
ChildKeyColumnOriginal |
STRING |
The name of a column in the referencing key with the case preserved. |
ParentDB |
STRING |
The name of the referenced database, converted to lowercase. |
ParentDBOriginal |
STRING |
The name of the referenced database with the case preserved. |
ParentTable |
STRING |
The name of the referenced table, converted to lowercase. |
ParentTableOriginal |
STRING |
The name of the referenced table with the case preserved. |
ParentKeyColumn |
STRING |
The name of the column in a referenced key, converted to lowercase. |
ParentKeyColumnOriginal |
STRING |
The name of the column in a referenced key with the case preserved. |
Columns
This table provides information about the columns.
| Column | Type | Description |
|---|---|---|
DatabaseName |
STRING |
The name of the database, converted to lowercase. |
DatabaseNameOriginal |
STRING |
The name of the database with the case preserved. |
TableName |
STRING |
The name of the table, converted to lowercase. |
TableNameOriginal |
STRING |
The name of the table with the case preserved. |
ColumnName |
STRING |
The name of the column, converted to lowercase. |
ColumnNameOriginal |
STRING |
The name of the column with the case preserved. |
ColumnType |
STRING |
The BigQuery type of the column, such as STRING. |
OriginalColumnType |
STRING |
The original type of the column, such as VARCHAR. |
ColumnLength |
INTEGER |
The maximal number of bytes of the column, such as 30 for VARCHAR(30). |
DefaultValue |
STRING |
The default value, if it exists. |
Nullable |
BOOLEAN |
Whether the column is nullable. |
DiskSpace
This table provides information about the diskspace usage for each database.
| Column | Type | Description |
|---|---|---|
DatabaseName |
STRING |
The name of the database, converted to lowercase. |
DatabaseNameOriginal |
STRING |
The name of the database with the case preserved. |
MaxPerm |
INTEGER |
The maximum number of bytes allocated to the permanent space. |
MaxSpool |
INTEGER |
The maximum number of bytes allocated to the spool space. |
MaxTemp |
INTEGER |
The maximum number of bytes allocated to the temporary space. |
CurrentPerm |
INTEGER |
The number of bytes allocated to the permanent space. |
CurrentSpool |
INTEGER |
The number of bytes allocated to the spool space. |
CurrentTemp |
INTEGER |
The number of bytes allocated to the temporary space. |
PeakPerm |
INTEGER |
Peak number of bytes used since the last reset for the permanent space. |
PeakSpool |
INTEGER |
Peak number of bytes used since the last reset for the spool space. |
PeakPersistentSpool |
INTEGER |
Peak number of bytes used since the last reset for the persistent space. |
PeakTemp |
INTEGER |
Peak number of bytes used since the last reset for the temporary space. |
MaxProfileSpool |
INTEGER |
The limit for spool space for the user. |
MaxProfileTemp |
INTEGER |
The limit for temporary space for the user. |
AllocatedPerm |
INTEGER |
Current allocation of permanent space. |
AllocatedSpool |
INTEGER |
Current allocation of spool space. |
AllocatedTemp |
INTEGER |
Current allocation of temporary space. |
Functions
This table provides information about the functions.
| Column | Type | Description |
|---|---|---|
DatabaseName |
STRING |
The name of the database, converted to lowercase. |
DatabaseNameOriginal |
STRING |
The name of the database with the case preserved. |
FunctionName |
STRING |
The name of the function. |
LanguageName |
STRING |
The name of the language. |
Indices
This table provides information about the indexes.
| Column | Type | Description |
|---|---|---|
DatabaseName |
STRING |
The name of the database, converted to lowercase. |
DatabaseNameOriginal |
STRING |
The name of the database with the case preserved. |
TableName |
STRING |
The name of the table, converted to lowercase. |
TableNameOriginal |
STRING |
The name of the table with the case preserved. |
IndexName |
STRING |
The name of the index. |
ColumnName |
STRING |
The name of the column, converted to lowercase. |
ColumnNameOriginal |
STRING |
The name of the column with the case preserved. |
OrdinalPosition |
INTEGER |
The position of the column. |
UniqueFlag |
BOOLEAN |
Indicates whether the index enforces uniqueness. |
Queries
This table provides information about the extracted queries.
| Column | Type | Description |
|---|---|---|
QueryHash |
STRING |
The hash of the query. |
QueryText |
STRING |
The text of the query. |
QueryLogs
This table provides some execution statistics about the extracted queries.
| Column | Type | Description |
|---|---|---|
QueryText |
STRING |
The text of the query. |
QueryHash |
STRING |
The hash of the query. |
QueryId |
STRING |
The ID of the query. |
QueryType |
STRING |
The type of the query, either Query or DDL. |
UserId |
BYTES |
The ID of the user who executed the query. |
UserName |
STRING |
The name of the user who executed the query. |
StartTime |
TIMESTAMP |
Timestamp when the query was submitted. |
Duration |
STRING |
Duration of the query in milliseconds. |
AppId |
STRING |
The ID of the application that executed the query. |
ProxyUser |
STRING |
The proxy user when used through a middle tier. |
ProxyRole |
STRING |
The proxy role when used through a middle tier. |
QueryTypeStatistics
This table provides statistics on types of queries.
| Column | Type | Description |
|---|---|---|
QueryHash |
STRING |
The hash of the query. |
QueryType |
STRING |
The type of the query. |
UpdatedTable |
STRING |
The table that was updated by the query if any. |
QueriedTables |
ARRAY<STRING> |
A list of the tables that were queried. |
ResUsageScpu
This table provides information about CPU resource usage.
| Column | Type | Description |
|---|---|---|
EventTime |
TIMESTAMP |
The time of the event. |
NodeId |
INTEGER |
Node ID |
CabinetId |
INTEGER |
The physical cabinet number of the node. |
ModuleId |
INTEGER |
The physical module number of the node. |
NodeType |
STRING |
Type of node. |
CpuId |
INTEGER |
ID of CPU within this node. |
MeasurementPeriod |
INTEGER |
The period of the measurement expressed in centiseconds. |
SummaryFlag |
STRING |
S - summary row, N - non-summary row |
CpuFrequency |
FLOAT |
CPU frequency in MHz. |
CpuIdle |
FLOAT |
The time CPU is idle expressed in centiseconds. |
CpuIoWait |
FLOAT |
The time CPU is waiting for I/O expressed in centiseconds. |
CpuUServ |
FLOAT |
The time CPU is executing user code expressed in centiseconds. |
CpuUExec |
FLOAT |
The time CPU is executing service code expressed in centiseconds. |
Roles
This table provides information about roles.
| Column | Type | Description |
|---|---|---|
RoleName |
STRING |
The name of the role. |
Grantor |
STRING |
The database name that granted the role. |
Grantee |
STRING |
The user who is granted the role. |
WhenGranted |
TIMESTAMP |
When the role was granted. |
WithAdmin |
BOOLEAN |
Is Admin Option set for the granted role. |
SchemaConversion
This table provides information on schema conversions that are related to clustering and partitioning.
| Column Name | Column Type | Description |
|---|---|---|
DatabaseName |
STRING |
The name of the source database for which the suggestion is made. A database maps to a dataset in BigQuery. |
TableName |
STRING |
The name of the table for which the suggestion is made. |
PartitioningColumnName |
STRING |
The name of the suggested partitioning column in BigQuery. |
ClusteringColumnNames |
ARRAY |
The names of the suggested clustering columns in BigQuery. |
CreateTableDDL |
STRING |
The CREATE TABLE statement
to create the table in BigQuery. |
TableInfo
This table provides information about tables.
| Column | Type | Description |
|---|---|---|
DatabaseName |
STRING |
The name of the database, converted to lowercase. |
DatabaseNameOriginal |
STRING |
The name of the database with the case preserved. |
TableName |
STRING |
The name of the table, converted to lowercase. |
TableNameOriginal |
STRING |
The name of the table with the case preserved. |
LastAccessTimestamp |
TIMESTAMP |
The last time the table was accessed. |
LastAlterTimestamp |
TIMESTAMP |
The last time the table was altered. |
TableKind |
STRING |
The type of table. |
TableRelations
This table provides information about tables.
| Column | Type | Description |
|---|---|---|
QueryHash |
STRING |
The hash of the query that established the relation. |
DatabaseName1 |
STRING |
The name of the first database. |
TableName1 |
STRING |
The name of the first table. |
DatabaseName2 |
STRING |
The name of the second database. |
TableName2 |
STRING |
The name of the second table. |
Relation |
STRING |
The type of relationship between the two tables. |
TableSizes
This table provides information about sizes of tables.
| Column | Type | Description |
|---|---|---|
DatabaseName |
STRING |
The name of the database, converted to lowercase. |
DatabaseNameOriginal |
STRING |
The name of the database with the case preserved. |
TableName |
STRING |
The name of the table, converted to lowercase. |
TableNameOriginal |
STRING |
The name of the table with the case preserved. |
TableSizeInBytes |
INTEGER |
The size of the table in bytes. |
Users
This table provides information about users.
| Column | Type | Description |
|---|---|---|
UserName |
STRING |
The name of the user. |
CreatorName |
STRING |
The name of the entity that created this user. |
CreateTimestamp |
TIMESTAMP |
The timestamp of when this user was created. |
LastAccessTimestamp |
TIMESTAMP |
The timestamp of when this user last accessed a database. |
Redshift
Columns
The Columns table comes from one of the following tables:
SVV_COLUMNS,
INFORMATION_SCHEMA.COLUMNS
or
PG_TABLE_DEF,
ordered by priority. The tool attempts to load data from the highest
priority table first. If this fails, then it attempts to load data from the
next highest priority table. Refer to the Amazon Redshift or
PostgreSQL documentation for more details about the schema and
usage.
| Column | Type | Description |
|---|---|---|
DatabaseName |
STRING |
The name of the database. |
SchemaName |
STRING |
The name of the schema. |
TableName |
STRING |
The name of the table. |
ColumnName |
STRING |
The name of the column. |
DefaultValue |
STRING |
The default value, if available. |
Nullable |
BOOLEAN |
Whether or not a column may have a null value. |
ColumnType |
STRING |
The type of the column, such as VARCHAR. |
ColumnLength |
INTEGER |
The size of the column, such as 30 for a
VARCHAR(30). |
CreateAndDropStatistic
This table provides information on the creation and deletion of tables.
| Column | Type | Description |
|---|---|---|
QueryHash |
STRING |
The hash of the query. |
DefaultDatabase |
STRING |
The default database. |
EntityType |
STRING |
The type of the entity—for example, TABLE. |
EntityName |
STRING |
The name of the entity. |
Operation |
STRING |
The operation: either CREATE or DROP. |
Databases
This table comes from the PG_DATABASE_INFO table from Amazon Redshift directly. The original field names from the PG table are included with the descriptions. Refer to the Amazon Redshift and PostgreSQL documentation for more details about the schema and usage.
| Column | Type | Description |
|---|---|---|
DatabaseName |
STRING |
The name of the database. Source name: datname |
Owner |
STRING |
The owner of the database. For example, the user who created the database. Source name: datdba |
ExternalColumns
This table contains information from the SVV_EXTERNAL_COLUMNS table from Amazon Redshift directly. Refer to the Amazon Redshift documentation for more details about the schema and usage.
| Column | Type | Description |
|---|---|---|
SchemaName |
STRING |
The external schema name. |
TableName |
STRING |
The external table name. |
ColumnName |
STRING |
The external column name. |
ColumnType |
STRING |
The type of the column. |
Nullable |
BOOLEAN |
Whether or not a column may have a null value. |
ExternalDatabases
This table contains information from the SVV_EXTERNAL_DATABASES table from Amazon Redshift directly. Refer to the Amazon Redshift documentation for more details about the schema and usage.
| Column | Type | Description |
|---|---|---|
DatabaseName |
STRING |
The external database name. |
Location |
STRING |
The location of the database. |
ExternalPartitions
This table contains information from the SVV_EXTERNAL_PARTITIONS table from Amazon Redshift directly. Refer to the Amazon Redshift documentation for more details about the schema and usage.
| Column | Type | Description |
|---|---|---|
SchemaName |
STRING |
The external schema name. |
TableName |
STRING |
The external table name. |
Location |
STRING |
The location of the partition. The column size is limited to 128 characters. Longer values are truncated. |
ExternalSchemas
This table contains information from the SVV_EXTERNAL_SCHEMAS table from Amazon Redshift directly. Refer to the Amazon Redshift documentation for more details about the schema and usage.
| Column | Type | Description |
|---|---|---|
SchemaName |
STRING |
The external schema name. |
DatabaseName |
STRING |
The external database name. |
ExternalTables
This table contains information from the SVV_EXTERNAL_TABLES table from Amazon Redshift directly. Refer to the Amazon Redshift documentation for more details about the schema and usage.
| Column | Type | Description |
|---|---|---|
SchemaName |
STRING |
The external schema name. |
TableName |
STRING |
The external table name. |
Functions
This table contains information from the PG_PROC table from Amazon Redshift directly. Refer to the Amazon Redshift and PostgreSQL documentation for more details about the schema and usage.
| Column | Type | Description |
|---|---|---|
SchemaName |
STRING |
The name of the schema. |
FunctionName |
STRING |
The name of the function. |
LanguageName |
STRING |
The implementation language or call interface of this function. |
Queries
This table is generated using the information from the QueryLogs table. Unlike
the QueryLogs table, every row in the Queries table contains only one query
statement stored in the QueryText column. This table provides the source data
to generate the Statistics tables and translation outputs.
| Column | Type | Description |
|---|---|---|
QueryText |
STRING |
The text of the query. |
QueryHash |
STRING |
The hash of the query. |
QueryLogs
This table provides information on query execution.
| Column | Type | Description |
|---|---|---|
QueryText |
STRING |
The text of the query. |
QueryHash |
STRING |
The hash of the query. |
QueryID |
STRING |
The ID of the query. |
UserID |
STRING |
The ID of the user. |
StartTime |
TIMESTAMP |
The start time. |
Duration |
INTEGER |
Duration in milliseconds. |
QueryTypeStatistics
| Column | Type | Description |
|---|---|---|
QueryHash |
STRING |
The hash of the query. |
DefaultDatabase |
STRING |
The default database. |
QueryType |
STRING |
The type of the query. |
UpdatedTable |
STRING |
The updated table. |
QueriedTables |
ARRAY<STRING> |
The queried tables. |
TableInfo
This table contains information extracted from the SVV_TABLE_INFO table in Amazon Redshift.
| Column | Type | Description |
|---|---|---|
DatabaseName |
STRING |
The name of the database. |
SchemaName |
STRING |
The name of the schema. |
TableId |
INTEGER |
The table ID. |
TableName |
STRING |
The name of the table. |
SortKey1 |
STRING |
First column in the sort key. |
SortKeyNum |
INTEGER |
Number of columns defined as sort keys. |
MaxVarchar |
INTEGER |
Size of the largest column that uses a VARCHAR
data type. |
Size |
INTEGER |
Size of the table, in 1-MB data blocks. |
TblRows |
INTEGER |
Total number of rows in the table. |
TableRelations
| Column | Type | Description |
|---|---|---|
QueryHash |
STRING |
The hash of the query that established the relation (For example, a JOIN query). |
DefaultDatabase |
STRING |
The default database. |
TableName1 |
STRING |
The first table of the relationship. |
TableName2 |
STRING |
The second table of the relationship. |
Relation |
STRING |
The kind of relation. Takes one of the following values:
COMMA_JOIN, CROSS_JOIN,
FULL_OUTER_JOIN, INNER_JOIN,
LEFT_OUTER_JOIN,
RIGHT_OUTER_JOIN, CREATED_FROM, or
INSERT_INTO. |
Count |
INTEGER |
How often this relationship was observed. |
TableSizes
This table provides information on tables sizes.
| Column | Type | Description |
|---|---|---|
DatabaseName |
STRING |
The name of the database. |
SchemaName |
STRING |
The name of the schema. |
TableName |
STRING |
The name of the table. |
TableSizeInBytes |
INTEGER |
The size of the table in bytes. |
Tables
This table contains information extracted from the SVV_TABLES table in Amazon Redshift. Refer to the Amazon Redshift documentation for more details about the schema and usage.
| Column | Type | Description |
|---|---|---|
DatabaseName |
STRING |
The name of the database. |
SchemaName |
STRING |
The name of the schema. |
TableName |
STRING |
The name of the table. |
TableType |
STRING |
The type of table. |
TranslatedQueries
This table provides query translations.
| Column | Type | Description |
|---|---|---|
QueryHash |
STRING |
The hash of the query. |
TranslatedQueryText |
STRING |
Result of translation from the source dialect to GoogleSQL. |
TranslationErrors
This table provides information about query translation errors.
| Column | Type | Description |
|---|---|---|
QueryHash |
STRING |
The hash of the query. |
Severity |
STRING |
The severity of the error, such as ERROR. |
Category |
STRING |
The category of the error, such as
AttributeNotFound. |
Message |
STRING |
The message with the details about the error. |
LocationOffset |
INTEGER |
The character position of the location of the error. |
LocationLine |
INTEGER |
The line number of the error. |
LocationColumn |
INTEGER |
The column number of the error. |
LocationLength |
INTEGER |
The character length of the location of the error. |
UserTableRelations
| Column | Type | Description |
|---|---|---|
UserID |
STRING |
The user ID. |
TableName |
STRING |
The name of the table. |
Relation |
STRING |
The relation. |
Count |
INTEGER |
The count. |
Users
This table contains information extracted from the PG_USER table in Amazon Redshift. Refer to the PostgreSQL documentation for more details about the schema and usage.
| Column | Type | Description | |
|---|---|---|---|
UserName |
STRING |
The name of the user. | |
UserId |
STRING |
The user ID. |
Snowflake
Warehouses
| Column | Type | Description | Presence |
|---|---|---|---|
WarehouseName |
STRING |
The name of the warehouse. | Always |
State |
STRING |
The state of the warehouse. Possible values: STARTED, SUSPENDED, RESIZING. |
Always |
Type |
STRING |
Warehouse type. Possible values: STANDARD, SNOWPARK-OPTIMIZED. |
Always |
Size |
STRING |
Size of the warehouse. Possible values: X-Small, Small, Medium, Large, X-Large, 2X-Large ... 6X-Large. |
Always |
Databases
| Column | Type | Description | Presence |
|---|---|---|---|
DatabaseNameOriginal |
STRING |
The name of the database, with the case preserved. | Always |
DatabaseName |
STRING |
The name of the database, converted to lowercase. | Always |
Schemata
| Column | Type | Description | Presence |
|---|---|---|---|
DatabaseNameOriginal |
STRING |
The name of the database that the schema belongs to, with the case preserved. | Always |
DatabaseName |
STRING |
The name of the database that the schema belongs to, converted to lowercase. | Always |
SchemaNameOriginal |
STRING |
The name of the schema, with the case preserved. | Always |
SchemaName |
STRING |
The name of the schema, converted to lowercase. | Always |
Tables
| Column | Type | Description | Presence |
|---|---|---|---|
DatabaseNameOriginal |
STRING |
The name of the database that the table belongs to, with the case preserved. | Always |
DatabaseName |
STRING |
The name of the database that the table belongs to, converted to lowercase. | Always |
SchemaNameOriginal |
STRING |
The name of the schema that the table belongs to, with the case preserved. | Always |
SchemaName |
STRING |
The name of the schema that the table belongs to, converted to lowercase. | Always |
TableNameOriginal |
STRING |
The name of the table, with the case preserved. | Always |
TableName |
STRING |
The name of the table, converted to lowercase. | Always |
TableType |
STRING |
Type of the table (View / Materialized View / Base Table). | Always |
RowCount |
BIGNUMERIC |
Number of rows in the table. | Always |
Columns
| Column | Type | Description | Presence |
|---|---|---|---|
DatabaseName |
STRING |
The name of the database, converted to lowercase. | Always |
DatabaseNameOriginal |
STRING |
The name of the database, with the case preserved. | Always |
SchemaName |
STRING |
The name of the schema, converted to lowercase. | Always |
SchemaNameOriginal |
STRING |
The name of the schema, with the case preserved. | Always |
TableName |
STRING |
The name of the table, converted to lowercase. | Always |
TableNameOriginal |
STRING |
The name of the table with the case preserved. | Always |
ColumnName |
STRING |
The name of the column, converted to lowercase. | Always |
ColumnNameOriginal |
STRING |
The name of the column with the case preserved. | Always |
ColumnType |
STRING |
The type of the column. | Always |
CreateAndDropStatistics
| Column | Type | Description | Presence |
|---|---|---|---|
QueryHash |
STRING |
The hash of the query. | Always |
DefaultDatabase |
STRING |
The default database. | Always |
EntityType |
STRING |
The type of the entity—for example, TABLE. |
Always |
EntityName |
STRING |
The name of the entity. | Always |
Operation |
STRING |
The operation: either CREATE or DROP. |
Always |
Queries
| Column | Type | Description | Presence |
|---|---|---|---|
QueryText |
STRING |
The text of the query. | Always |
QueryHash |
STRING |
The hash of the query. | Always |
QueryLogs
| Column | Type | Description | Presence |
|---|---|---|---|
QueryText |
STRING |
The text of the query. | Always |
QueryHash |
STRING |
The hash of the query. | Always |
QueryID |
STRING |
The ID of the query. | Always |
UserID |
STRING |
The ID of the user. | Always |
StartTime |
TIMESTAMP |
The start time. | Always |
Duration |
INTEGER |
Duration in milliseconds. | Always |
QueryTypeStatistics
| Column | Type | Description | Presence |
|---|---|---|---|
QueryHash |
STRING |
The hash of the query. | Always |
DefaultDatabase |
STRING |
The default database. | Always |
QueryType |
STRING |
The type of the query. | Always |
UpdatedTable |
STRING |
The updated table. | Always |
QueriedTables |
REPEATED STRING |
The queried tables. | Always |
TableRelations
| Column | Type | Description | Presence |
|---|---|---|---|
QueryHash |
STRING |
The hash of the query that established the relation (for example, a JOIN query). |
Always |
DefaultDatabase |
STRING |
The default database. | Always |
TableName1 |
STRING |
The first table of the relationship. | Always |
TableName2 |
STRING |
The second table of the relationship. | Always |
Relation |
STRING |
The kind of relation. | Always |
Count |
INTEGER |
How often this relationship was observed. | Always |
TranslatedQueries
| Column | Type | Description | Presence |
|---|---|---|---|
QueryHash |
STRING |
The hash of the query. | Always |
TranslatedQueryText |
STRING |
Result of translation from the source dialect to BigQuery SQL. | Always |
TranslationErrors
| Column | Type | Description | Presence |
|---|---|---|---|
QueryHash |
STRING |
The hash of the query. | Always |
Severity |
STRING |
The severity of the error—for example, ERROR. |
Always |
Category |
STRING |
The category of the error—for example, AttributeNotFound. |
Always |
Message |
STRING |
The message with the details about the error. | Always |
LocationOffset |
INTEGER |
The character position of the location of the error. | Always |
LocationLine |
INTEGER |
The line number of the error. | Always |
LocationColumn |
INTEGER |
The column number of the error. | Always |
LocationLength |
INTEGER |
The character length of the location of the error. | Always |
UserTableRelations
| Column | Type | Description | Presence |
|---|---|---|---|
UserID |
STRING |
User ID. | Always |
TableName |
STRING |
The name of the table. | Always |
Relation |
STRING |
The relation. | Always |
Count |
INTEGER |
The count. | Always |
Apache Hive
Columns
This table provides information about the columns:
| Column | Type | Description |
|---|---|---|
DatabaseName |
STRING |
The name of the database with the case preserved. |
TableName |
STRING |
The name of the table with the case preserved. |
ColumnName |
STRING |
The name of the column with the case preserved. |
ColumnType |
STRING |
The BigQuery type of the column, such as STRING. |
OriginalColumnType |
STRING |
The original type of the column, such as VARCHAR. |
CreateAndDropStatistic
This table provides information on the creation and deletion of tables:
| Column | Type | Description |
|---|---|---|
QueryHash |
STRING |
The hash of the query. |
DefaultDatabase |
STRING |
The default database. |
EntityType |
STRING |
The type of the entity, for example, TABLE. |
EntityName |
STRING |
The name of the entity. |
Operation |
STRING |
The operation performed on the table (CREATE or DROP). |
Databases
This table provides information about the databases:
| Column | Type | Description |
|---|---|---|
DatabaseName |
STRING |
The name of the database with the case preserved. |
Owner |
STRING |
The owner of the database. For example, the user who created the database. |
Location |
STRING |
Location of the database in the file system. |
Functions
This table provides information about the functions:
| Column | Type | Description |
|---|---|---|
DatabaseName |
STRING |
The name of the database with the case preserved. |
FunctionName |
STRING |
The name of the function. |
LanguageName |
STRING |
The name of the language. |
ClassName |
STRING |
The class name of the function. |
ObjectReferences
This table provides information about the objects referenced in queries:
| Column | Type | Description |
|---|---|---|
QueryHash |
STRING |
The hash of the query. |
DefaultDatabase |
STRING |
The default database. |
Clause |
STRING |
The clause where the object appears. For example, SELECT. |
ObjectName |
STRING |
The name of the object. |
Type |
STRING |
The type of the object. |
Subtype |
STRING |
The subtype of the object. |
PartitionKeys
This table provides information about the partition keys:
| Column | Type | Description |
|---|---|---|
DatabaseName |
STRING |
The name of the database with the case preserved. |
TableName |
STRING |
The name of the table with the case preserved. |
ColumnName |
STRING |
The name of the column with the case preserved. |
ColumnType |
STRING |
The BigQuery type of the column, such as STRING. |
Partitions
This table provides information about the tables partitions:
| Column | Type | Description |
|---|---|---|
DatabaseName |
STRING |
The name of the database with the case preserved. |
TableName |
STRING |
The name of the table with the case preserved. |
PartitionName |
STRING |
The name of the partition. |
CreateTimestamp |
TIMESTAMP |
The timestamp of when this partition was created. |
LastAccessTimestamp |
TIMESTAMP |
The timestamp of when this partition was last accessed. |
LastDdlTimestamp |
TIMESTAMP |
The timestamp of when this partition was last changed. |
TotalSize |
INTEGER |
The compressed size of the partition in bytes. |
Queries
This table is generated using the information from the QueryLogs table. Unlike the QueryLogs table, every row in the Queries table contains only one query statement stored in the QueryText column. This table provides the source data to generate the Statistics tables and translation outputs:
| Column | Type | Description |
|---|---|---|
QueryHash |
STRING |
The hash of the query. |
QueryText |
STRING |
The text of the query. |
QueryLogs
This table provides some execution statistics about the extracted queries:
| Column | Type | Description |
|---|---|---|
QueryText |
STRING |
The text of the query. |
QueryHash |
STRING |
The hash of the query. |
QueryId |
STRING |
The ID of the query. |
QueryType |
STRING |
The type of the query, either Query or DDL. |
UserName |
STRING |
The name of the user who executed the query. |
StartTime |
TIMESTAMP |
The timestamp when the query was submitted. |
Duration |
STRING |
The duration of the query in milliseconds. |
QueryTypeStatistics
This table provides statistics on types of queries:
| Column | Type | Description |
|---|---|---|
QueryHash |
STRING |
The hash of the query. |
QueryType |
STRING |
The type of the query. |
UpdatedTable |
STRING |
The table that was updated by the query, if any. |
QueriedTables |
ARRAY<STRING> |
A list of the tables that were queried. |
QueryTypes
This table provides statistics on types of queries:
| Column | Type | Description |
|---|---|---|
QueryHash |
STRING |
The hash of the query. |
Category |
STRING |
The category of the query. |
Type |
STRING |
The type of the query. |
Subtype |
STRING |
The subtype of the query. |
SchemaConversion
This table provides information about schema conversions that are related to clustering and partitioning:
| Column Name | Column Type | Description |
|---|---|---|
DatabaseName |
STRING |
The name of the source database for which the suggestion is made. A database maps to a dataset in BigQuery. |
TableName |
STRING |
The name of the table for which the suggestion is made. |
PartitioningColumnName |
STRING |
The name of the suggested partitioning column in BigQuery. |
ClusteringColumnNames |
ARRAY |
The names of the suggested clustering columns in BigQuery. |
CreateTableDDL |
STRING |
The CREATE TABLE statement
to create the table in BigQuery. |
TableRelations
This table provides information about tables:
| Column | Type | Description |
|---|---|---|
QueryHash |
STRING |
The hash of the query that established the relation. |
DatabaseName1 |
STRING |
The name of the first database. |
TableName1 |
STRING |
The name of the first table. |
DatabaseName2 |
STRING |
The name of the second database. |
TableName2 |
STRING |
The name of the second table. |
Relation |
STRING |
The type of relationship between the two tables. |
TableSizes
This table provides information about sizes of tables:
| Column | Type | Description |
|---|---|---|
DatabaseName |
STRING |
The name of the database with the case preserved. |
TableName |
STRING |
The name of the table with the case preserved. |
TotalSize |
INTEGER |
The size of the table in bytes. |
Tables
This table provides information about tables:
| Column | Type | Description |
|---|---|---|
DatabaseName |
STRING |
The name of the database with the case preserved. |
TableName |
STRING |
The name of the table with the case preserved. |
Type |
STRING |
The type of table. |
TranslatedQueries
This table provides query translations:
| Column | Type | Description |
|---|---|---|
QueryHash |
STRING |
The hash of the query. |
TranslatedQueryText |
STRING |
The result of translation from the source dialect to GoogleSQL. |
TranslationErrors
This table provides information about query translation errors:
| Column | Type | Description |
|---|---|---|
QueryHash |
STRING |
The hash of the query. |
Severity |
STRING |
The severity of the error, such as ERROR. |
Category |
STRING |
The category of the error, such as
AttributeNotFound. |
Message |
STRING |
The message with the details about the error. |
LocationOffset |
INTEGER |
The character position of the location of the error. |
LocationLine |
INTEGER |
The line number of the error. |
LocationColumn |
INTEGER |
The column number of the error. |
LocationLength |
INTEGER |
The character length of the location of the error. |
UserTableRelations
| Column | Type | Description |
|---|---|---|
UserID |
STRING |
The user ID. |
TableName |
STRING |
The name of the table. |
Relation |
STRING |
The relation. |
Count |
INTEGER |
The count. |
Troubleshooting
This section explains some common issues and troubleshooting techniques for migrating your data warehouse to BigQuery.
dwh-migration-dumper tool errors
To troubleshoot errors and warnings in the dwh-migration-dumper tool terminal
output that occurred during metadata or query logs extraction, see
generate metadata troubleshooting.
Hive migration errors
This section describes common issues that you might run into when you plan to migrate your data warehouse from Hive to BigQuery.
The logging hook writes debug log messages in your
hive-server2 logs. If you run into any issues, review the
logging hook debug logs, which contains the
MigrationAssessmentLoggingHook string.
Handle the ClassNotFoundException error
The error might be caused by the logging hook JAR file
misplacement. Ensure that you added the JAR file to the auxlib folder on the
Hive cluster. Alternatively, you can specify full path to
the JAR file in the hive.aux.jars.path property, for example,
file://.
Subfolders don't appear in the configured folder
This issue might be caused by the misconfiguration or problems during logging hook initialization.
Search your hive-server2 debug logs for the following
logging hook messages:
Unable to initialize logger, logging disabled
Log dir configuration key 'dwhassessment.hook.base-directory' is not set, logging disabled.
Error while trying to set permission
Review the issue details and see if there is anything that you need to correct to fix the problem.
Files don't appear in the folder
This issue might be caused by the problems encountered during an event processing or while writing to a file.
Search in your hive-server2 debug logs for the following
logging hook messages:
Failed to close writer for file
Got exception while processing event
Error writing record for query
Review the issue details and see if there is anything that you need to correct to fix the problem.
Some query events are missed
This issue might be caused by the logging hook thread queue overflow.
Search in your hive-server2 debug logs for the following
logging hook message:
Writer queue is full. Ignoring event
If there are such messages, consider increasing the
dwhassessment.hook.queue.capacity parameter.
What's next
For more information about the dwh-migration-dumper tool, see
dwh-migration-tools.
You can also learn more about the following steps in data warehouse migration:
- Migration overview
- Schema and data transfer overview
- Data pipelines
- Batch SQL translation
- Interactive SQL translation
- Data security and governance
- Data validation tool