Penilaian migrasi
Dengan penilaian migrasi BigQuery, Anda dapat merencanakan dan meninjau migrasi data warehouse yang ada ke BigQuery. Anda dapat menjalankan penilaian migrasi BigQuery untuk membuat laporan guna menilai biaya penyimpanan data di BigQuery, melihat cara BigQuery mengoptimalkan workload yang ada demi menghemat biaya, dan menyiapkan rencana migrasi yang menguraikan waktu dan upaya yang diperlukan untuk menyelesaikan migrasi data warehouse Anda ke BigQuery.
Dokumen ini menjelaskan cara menggunakan penilaian migrasi BigQuery dan berbagai cara untuk meninjau hasil penilaian. Dokumen ini ditujukan bagi pengguna yang sudah memahami konsolGoogle Cloud dan penerjemah SQL batch.
Sebelum memulai
Untuk menyiapkan dan menjalankan penilaian migrasi BigQuery, ikuti langkah-langkah berikut:
Ekstrak metadata dan log kueri dari data warehouse Anda menggunakan alat
dwh-migration-dumper.Upload metadata dan log kueri Anda ke bucket Cloud Storage.
Opsional: Buat kueri hasil penilaian untuk menemukan informasi penilaian yang terperinci atau spesifik.
Mengekstrak metadata dan log kueri dari data warehouse Anda
Metadata dan log kueri diperlukan untuk menyiapkan penilaian dengan rekomendasi.
Untuk mengekstrak metadata dan log kueri yang diperlukan untuk menjalankan penilaian, pilih data warehouse Anda:
Teradata
Persyaratan
- Mesin yang terhubung ke data warehouse Teradata sumber Anda (Teradata 15 dan yang lebih baru didukung)
- A Google Cloud kun dengan bucket Cloud Storage untuk menyimpan data
- Set data BigQuery kosong untuk menyimpan hasilnya
- Izin baca pada set data untuk melihat hasilnya
- Direkomendasikan: Hak akses tingkat administrator ke database sumber saat menggunakan alat ekstraksi untuk mengakses tabel sistem
Persyaratan: Aktifkan logging
Alat dwh-migration-dumper mengekstrak tiga jenis log: log kueri, log utilitas, dan log penggunaan resource. Anda harus mengaktifkan logging untuk jenis log berikut guna melihat insight yang lebih menyeluruh:
- Log kueri: Diekstrak dari tabel virtual
dbc.QryLogVdan dari tabeldbc.DBQLSqlTbl. Aktifkan logging dengan menentukan opsiWITH SQL. - Log utilitas: Diekstrak dari tabel
dbc.DBQLUtilityTbl. Aktifkan logging dengan menentukan opsiWITH UTILITYINFO. - Log penggunaan resource: Diekstrak dari tabel
dbc.ResUsageScpudandbc.ResUsageSpma. Aktifkan logging RSS untuk kedua tabel ini.
Menjalankan alat dwh-migration-dumper
Download alat dwh-migration-dumper.
Download file
SHA256SUMS.txt
dan jalankan perintah berikut untuk memverifikasi kebenaran zip:
Bash
sha256sum --check SHA256SUMS.txt
Windows PowerShell
(Get-FileHash RELEASE_ZIP_FILENAME).Hash -eq ((Get-Content SHA256SUMS.txt) -Split " ")[0]
Ganti RELEASE_ZIP_FILENAME dengan
nama file zip yang didownload dari rilis alat ekstraksi command line dwh-migration-dumper, misalnya, dwh-migration-tools-v1.0.52.zip
Hasil True mengonfirmasi keberhasilan verifikasi checksum.
Hasil False menunjukkan error verifikasi. Pastikan file checksum dan ZIP didownload dari versi rilis yang sama dan ditempatkan di direktori yang sama.
Untuk mengetahui detail tentang cara menyiapkan dan menggunakan alat ekstraksi, lihat Membuat metadata untuk terjemahan dan penilaian.
Gunakan alat ekstraksi untuk mengekstrak log dan metadata dari data warehouse Teradata Anda sebagai dua file ZIP. Jalankan perintah berikut pada mesin yang memiliki akses ke data warehouse sumber untuk membuat file.
Buat file zip metadata:
dwh-migration-dumper \ --connector teradata \ --database DATABASES \ --driver path/terajdbc4.jar \ --host HOST \ --assessment \ --user USER \ --password PASSWORD
Catatan: Flag --database bersifat opsional untuk konektor
teradata. Jika tidak ada, metadata untuk semua database akan diekstrak. Flag ini hanya valid untuk konektor teradata
dan tidak dapat digunakan dengan teradata-logs.
Buat file ZIP yang berisi log kueri:
dwh-migration-dumper \ --connector teradata-logs \ --driver path/terajdbc4.jar \ --host HOST \ --assessment \ --user USER \ --password PASSWORD
Catatan: Flag --database tidak digunakan saat mengekstrak log kueri dengan konektor teradata-logs. Log kueri selalu diekstrak untuk semua database.
Ganti kode berikut:
PATH: jalur absolut atau relatif ke file JAR driver yang akan digunakan untuk koneksi iniVERSION: versi driver AndaHOST: alamat hostUSER: nama pengguna yang akan digunakan untuk koneksi databaseDATABASES: (Opsional) daftar nama database yang dipisahkan koma yang akan diekstrak. Jika tidak diberikan, semua database akan diekstrak.PASSWORD: (Opsional) sandi yang akan digunakan untuk koneksi database. Jika dibiarkan kosong, pengguna akan diminta memasukkan sandi mereka.
Secara default, log kueri diekstrak dari tabel virtual dbc.QryLogV dan dari tabel dbc.DBQLSqlTbl. Jika perlu mengekstrak log kueri dari lokasi alternatif, Anda dapat menentukan nama tabel atau tabel virtual menggunakan flag -Dteradata-logs.query-logs-table dan -Dteradata-logs.sql-logs-table.
Secara default, log utilitas diekstrak dari tabel dbc.DBQLUtilityTbl. Jika perlu mengekstrak log utilitas dari lokasi alternatif, Anda dapat menentukan nama tabel menggunakan flag -Dteradata-logs.utility-logs-table.
Secara default, log penggunaan resource diekstrak dari tabel dbc.ResUsageScpu dan dbc.ResUsageSpma. Jika perlu mengekstrak log penggunaan resource dari lokasi alternatif, Anda dapat menentukan nama tabel menggunakan flag -Dteradata-logs.res-usage-scpu-table dan -Dteradata-logs.res-usage-spma-table.
Contoh:
Bash
dwh-migration-dumper \ --connector teradata-logs \ --driver path/terajdbc4.jar \ --host HOST \ --assessment \ --user USER \ --password PASSWORD \ -Dteradata-logs.query-logs-table=pdcrdata.QryLogV_hst \ -Dteradata-logs.sql-logs-table=pdcrdata.DBQLSqlTbl_hst \ -Dteradata-logs.log-date-column=LogDate \ -Dteradata-logs.utility-logs-table=pdcrdata.DBQLUtilityTbl_hst \ -Dteradata-logs.res-usage-scpu-table=pdcrdata.ResUsageScpu_hst \ -Dteradata-logs.res-usage-spma-table=pdcrdata.ResUsageSpma_hst
Windows PowerShell
dwh-migration-dumper ` --connector teradata-logs ` --driver path\terajdbc4.jar ` --host HOST ` --assessment ` --user USER ` --password PASSWORD ` "-Dteradata-logs.query-logs-table=pdcrdata.QryLogV_hst" ` "-Dteradata-logs.sql-logs-table=pdcrdata.DBQLSqlTbl_hst" ` "-Dteradata-logs.log-date-column=LogDate" ` "-Dteradata-logs.utility-logs-table=pdcrdata.DBQLUtilityTbl_hst" ` "-Dteradata-logs.res-usage-scpu-table=pdcrdata.ResUsageScpu_hst" ` "-Dteradata-logs.res-usage-spma-table=pdcrdata.ResUsageSpma_hst"
Secara default, alat dwh-migration-dumper mengekstrak log kueri sepanjang tujuh hari terakhir.
Google merekomendasikan agar Anda menyediakan log kueri minimal dua minggu agar dapat melihat insight yang lebih menyeluruh. Anda dapat menentukan rentang waktu kustom menggunakan flag --query-log-start dan --query-log-end. Contoh:
dwh-migration-dumper \ --connector teradata-logs \ --driver path/terajdbc4.jar \ --host HOST \ --assessment \ --user USER \ --password PASSWORD \ --query-log-start "2023-01-01 00:00:00" \ --query-log-end "2023-01-15 00:00:00"
Anda juga dapat membuat beberapa file ZIP yang berisi log kueri yang mencakup periode yang berbeda dan memberikan semuanya untuk penilaian.
Redshift
Persyaratan
- Mesin yang terhubung ke data warehouse Amazon Redshift sumber Anda
- A Google Cloud kun dengan bucket Cloud Storage untuk menyimpan data
- Set data BigQuery kosong untuk menyimpan hasilnya
- Izin baca pada set data untuk melihat hasilnya
- Direkomendasikan: Akses pengguna super ke database saat menggunakan alat ekstraksi untuk mengakses tabel sistem
Menjalankan alat dwh-migration-dumper
Download alat ekstraksi command line dwh-migration-dumper.
Download file
SHA256SUMS.txt
dan jalankan perintah berikut untuk memverifikasi kebenaran zip:
Bash
sha256sum --check SHA256SUMS.txt
Windows PowerShell
(Get-FileHash RELEASE_ZIP_FILENAME).Hash -eq ((Get-Content SHA256SUMS.txt) -Split " ")[0]
Ganti RELEASE_ZIP_FILENAME dengan
nama file zip yang didownload dari rilis alat ekstraksi command line dwh-migration-dumper, misalnya, dwh-migration-tools-v1.0.52.zip
Hasil True mengonfirmasi keberhasilan verifikasi checksum.
Hasil False menunjukkan error verifikasi. Pastikan file checksum dan ZIP didownload dari versi rilis yang sama dan ditempatkan di direktori yang sama.
Untuk mengetahui detail cara menggunakan alat dwh-migration-dumper, lihat halaman membuat metadata.
Gunakan alat dwh-migration-dumper untuk mengekstrak log dan metadata dari data warehouse Amazon Redshift sebagai dua file ZIP.
Jalankan perintah berikut pada mesin yang memiliki akses ke data warehouse sumber untuk membuat file.
Buat file zip metadata:
dwh-migration-dumper \ --connector redshift \ --database DATABASE \ --driver PATH/redshift-jdbc42-VERSION.jar \ --host host.region.redshift.amazonaws.com \ --assessment \ --user USER \ --iam-profile IAM_PROFILE_NAME
Buat file ZIP yang berisi log kueri:
dwh-migration-dumper \ --connector redshift-raw-logs \ --database DATABASE \ --driver PATH/redshift-jdbc42-VERSION.jar \ --host host.region.redshift.amazonaws.com \ --assessment \ --user USER \ --iam-profile IAM_PROFILE_NAME
Ganti kode berikut:
DATABASE: nama database yang akan dihubungkanPATH: jalur absolut atau relatif ke file JAR driver yang akan digunakan untuk koneksi iniVERSION: versi driver AndaUSER: nama pengguna yang akan digunakan untuk koneksi databaseIAM_PROFILE_NAME: the Amazon Redshift IAM profile name. Diperlukan untuk autentikasi Amazon Redshift dan untuk akses AWS API. Untuk mendapatkan deskripsi cluster Amazon Redshift, gunakan AWS API.
Secara default, Amazon Redshift menyimpan log kueri sepanjang tiga hingga lima hari.
Secara default, alat dwh-migration-dumper mengekstrak log kueri sepanjang tujuh hari terakhir.
Google merekomendasikan agar Anda menyediakan log kueri minimal sepanjang dua minggu agar dapat melihat insight yang lebih menyeluruh. Anda mungkin perlu menjalankan alat ekstraksi beberapa kali selama dua minggu untuk mendapatkan hasil terbaik. Anda dapat menentukan rentang kustom menggunakan flag --query-log-start dan --query-log-end.
Contoh:
dwh-migration-dumper \ --connector redshift-raw-logs \ --database DATABASE \ --driver PATH/redshift-jdbc42-VERSION.jar \ --host host.region.redshift.amazonaws.com \ --assessment \ --user USER \ --iam-profile IAM_PROFILE_NAME \ --query-log-start "2023-01-01 00:00:00" \ --query-log-end "2023-01-02 00:00:00"
Anda juga dapat membuat beberapa file ZIP yang berisi log kueri yang mencakup periode yang berbeda dan memberikan semuanya untuk penilaian.
Redshift Serverless
Persyaratan
- Mesin yang terhubung ke data warehouse Amazon Redshift Serverless sumber Anda
- A Google Cloud kun dengan bucket Cloud Storage untuk menyimpan data
- Set data BigQuery kosong untuk menyimpan hasilnya
- Izin baca pada set data untuk melihat hasilnya
- Direkomendasikan: Akses pengguna super ke database saat menggunakan alat ekstraksi untuk mengakses tabel sistem
Menjalankan alat dwh-migration-dumper
Download alat ekstraksi command line dwh-migration-dumper.
Untuk mengetahui detail cara menggunakan alat dwh-migration-dumper, lihat halaman Membuat metadata.
Gunakan alat dwh-migration-dumper untuk mengekstrak log penggunaan dan metadata dari namespace Amazon Redshift Serverless Anda sebagai dua file ZIP. Jalankan perintah berikut di komputer yang memiliki akses ke data warehouse sumber untuk membuat file.
Buat file zip metadata:
dwh-migration-dumper \ --connector redshift \ --database DATABASE \ --driver PATH/redshift-jdbc42-VERSION.jar \ --host host.region.redshift-serverless.amazonaws.com \ --assessment \ --user USER \ --iam-profile IAM_PROFILE_NAME
Buat file ZIP yang berisi log kueri:
dwh-migration-dumper \ --connector redshift-serverless-logs \ --database DATABASE \ --driver PATH/redshift-jdbc42-VERSION.jar \ --host host.region.redshift-serverless.amazonaws.com \ --assessment \ --user USER \ --iam-profile IAM_PROFILE_NAME
Ganti kode berikut:
DATABASE: nama database yang akan dihubungkanPATH: jalur absolut atau relatif ke file JAR driver yang akan digunakan untuk koneksi iniVERSION: versi driver AndaUSER: nama pengguna yang akan digunakan untuk koneksi databaseIAM_PROFILE_NAME: the Amazon Redshift IAM profile name. Diperlukan untuk autentikasi Amazon Redshift dan untuk akses AWS API. Untuk mendapatkan deskripsi cluster Amazon Redshift, gunakan AWS API.
Amazon Redshift Serverless menyimpan log penggunaan selama tujuh hari. Jika rentang yang lebih luas diperlukan, Google merekomendasikan untuk mengekstrak data beberapa kali selama jangka waktu yang lebih lama.
Snowflake
Persyaratan
Anda harus memenuhi persyaratan berikut untuk mengekstrak metadata dan log kueri dari Snowflake:
- Mesin yang dapat terhubung ke instance Snowflake Anda.
- Akun Google Cloud dengan bucket Cloud Storage untuk menyimpan data.
- Set data BigQuery kosong untuk menyimpan hasilnya. Atau, Anda dapat membuat set data BigQuery saat Anda membuat tugas penilaian menggunakan UI konsol Google Cloud .
- Pengguna Snowflake dengan akses
IMPORTED PRIVILEGESpada databaseSnowflake. Sebaiknya buat penggunaSERVICEdengan autentikasi berbasis pasangan kunci. Cara ini memberikan metode yang aman untuk mengakses platform data Snowflake tanpa perlu membuat token MFA.- Untuk membuat pengguna layanan baru, ikuti panduan resmi Snowflake. Anda harus membuat pasangan kunci RSA dan menetapkan kunci publik ke pengguna Snowflake.
- Pengguna layanan harus memiliki peran
ACCOUNTADMIN, atau diberi peran dengan hak istimewaIMPORTED PRIVILEGESpada databaseSnowflakeoleh administrator akun. - Selain autentikasi pasangan kunci, Anda dapat menggunakan autentikasi berbasis sandi. Namun, mulai Agustus 2025, Snowflake akan menerapkan MFA pada semua pengguna berbasis sandi. Anda harus menyetujui notifikasi push MFA saat menggunakan alat ekstraksi kami.
Menjalankan alat dwh-migration-dumper
Download alat ekstraksi command line dwh-migration-dumper.
Download file
SHA256SUMS.txt
dan jalankan perintah berikut untuk memverifikasi kebenaran zip:
Bash
sha256sum --check SHA256SUMS.txt
Windows PowerShell
(Get-FileHash RELEASE_ZIP_FILENAME).Hash -eq ((Get-Content SHA256SUMS.txt) -Split " ")[0]
Ganti RELEASE_ZIP_FILENAME dengan
nama file zip yang didownload dari rilis alat ekstraksi command line dwh-migration-dumper, misalnya, dwh-migration-tools-v1.0.52.zip
Hasil True mengonfirmasi keberhasilan verifikasi checksum.
Hasil False menunjukkan error verifikasi. Pastikan file checksum dan ZIP didownload dari versi rilis yang sama dan ditempatkan di direktori yang sama.
Untuk mengetahui detail cara menggunakan alat dwh-migration-dumper, lihat halaman membuat metadata.
Gunakan alat dwh-migration-dumper untuk mengekstrak log dan metadata dari data warehouse Snowflake sebagai dua file ZIP. Jalankan perintah berikut di komputer yang memiliki akses ke data warehouse sumber untuk membuat file.
Buat file zip metadata:
dwh-migration-dumper \ --connector snowflake \ --host HOST_NAME \ --user USER_NAME \ --role ROLE_NAME \ --warehouse WAREHOUSE \ --assessment \ --private-key-file PRIVATE_KEY_PATH \ --private-key-password PRIVATE_KEY_PASSWORD
Buat file ZIP yang berisi log kueri:
dwh-migration-dumper \ --connector snowflake-logs \ --host HOST_NAME \ --user USER_NAME \ --role ROLE_NAME \ --warehouse WAREHOUSE \ --query-log-start STARTING_DATE \ --query-log-end ENDING_DATE \ --assessment \ --private-key-file PRIVATE_KEY_PATH \ --private-key-password PRIVATE_KEY_PASSWORD
Ganti kode berikut:
HOST_NAME: nama host instance Snowflake Anda.USER_NAME: nama pengguna yang akan digunakan untuk koneksi database, dengan pengguna harus memiliki izin akses seperti yang dijelaskan dalam bagian persyaratan.PRIVATE_KEY_PATH: jalur ke kunci pribadi RSA yang digunakan untuk autentikasi.PRIVATE_KEY_PASSWORD: (Opsional) sandi yang digunakan saat membuat kunci pribadi RSA. Hal ini diperlukan hanya jika kunci pribadi dienkripsi.ROLE_NAME: (Opsional) peran pengguna saat menjalankan alatdwh-migration-dumper—misalnya,ACCOUNTADMIN.WAREHOUSE: gudang yang digunakan untuk menjalankan operasi dumping. Jika memiliki beberapa gudang virtual, Anda dapat menentukan gudang mana pun untuk menjalankan kueri ini. Menjalankan kueri ini dengan izin akses yang dijelaskan di bagian persyaratan akan mengekstrak semua artefak gudang di akun ini.STARTING_DATE: (Opsional) digunakan untuk menunjukkan tanggal mulai dalam rentang tanggal log kueri, yang ditulis dalam formatYYYY-MM-DD.ENDING_DATE: (Opsional) digunakan untuk menunjukkan tanggal berakhir dalam rentang tanggal log kueri, ditulis dalam formatYYYY-MM-DD.
Anda juga dapat membuat beberapa file ZIP yang berisi log kueri yang mencakup periode yang tidak tumpang-tindih dan memberikan semuanya untuk penilaian.
Oracle
Untuk meminta masukan atau dukungan terkait fitur ini, kirim email ke bq-edw-migration-support@google.com.
Persyaratan
Anda harus memenuhi persyaratan berikut untuk mengekstrak metadata dan log kueri dari Oracle:
- Database Oracle Anda harus versi 11g R1 atau yang lebih baru.
- Mesin yang dapat terhubung ke instance Oracle Anda.
- Java 8 atau yang lebih baru.
- Akun Google Cloud dengan bucket Cloud Storage untuk menyimpan data.
- Set data BigQuery kosong untuk menyimpan hasilnya. Atau, Anda dapat membuat set data BigQuery saat Anda membuat tugas penilaian menggunakan UI konsol Google Cloud .
- Pengguna umum Oracle dengan hak istimewa SYSDBA.
Menjalankan alat dwh-migration-dumper
Download alat ekstraksi command line dwh-migration-dumper.
Download
file SHA256SUMS.txt
dan jalankan perintah berikut untuk memverifikasi kebenaran zip:
sha256sum --check SHA256SUMS.txt
Untuk mengetahui detail cara menggunakan alat dwh-migration-dumper, lihat halaman membuat metadata.
Gunakan alat dwh-migration-dumper untuk mengekstrak metadata dan statistik performa ke file ZIP. Secara default, statistik diekstrak dari AWR Oracle yang memerlukan Oracle Tuning and Diagnostics Pack. Jika data ini tidak tersedia, dwh-migration-dumper akan menggunakan STATSPACK.
Untuk database multitenan, alat dwh-migration-dumper harus dijalankan
di penampung root. Menjalankannya di salah satu database yang dapat di-plug akan menyebabkan statistik performa dan metadata tentang database yang dapat di-plug lainnya tidak ada.
Buat file zip metadata:
dwh-migration-dumper \ --connector oracle-stats \ --host HOST_NAME \ --port PORT \ --oracle-service SERVICE_NAME \ --assessment \ --driver JDBC_DRIVER_PATH \ --user USER_NAME \ --password
Ganti kode berikut:
HOST_NAME: nama host instance Oracle Anda.PORT: nomor port koneksi. Nilai defaultnya adalah 1521.SERVICE_NAME: nama layanan Oracle yang akan digunakan untuk koneksi.JDBC_DRIVER_PATH: jalur absolut atau relatif ke file JAR driver. Anda dapat mendownload file ini dari halaman download driver JDBC Oracle. Anda harus memilih versi driver yang kompatibel dengan versi database Anda.USER_NAME: nama pengguna yang digunakan untuk terhubung ke instance Oracle Anda. Pengguna harus memiliki izin akses seperti yang dijelaskan di bagian persyaratan.
Hadoop / Cloudera
Untuk meminta masukan atau dukungan terkait fitur ini, kirim email ke bq-edw-migration-support@google.com.
Persyaratan
Anda harus memiliki hal berikut untuk mengekstrak metadata dari Cloudera:
- Mesin yang dapat terhubung ke Cloudera Manager API.
- Akun Google Cloud dengan bucket Cloud Storage untuk menyimpan data.
- Set data BigQuery kosong untuk menyimpan hasilnya. Atau, Anda dapat membuat set data BigQuery saat membuat tugas penilaian.
Menjalankan alat dwh-migration-dumper
Download
SHA256SUMS.txtfile.Di lingkungan command line Anda, verifikasi kebenaran ZIP:
sha256sum --check SHA256SUMS.txt
Untuk mengetahui detail tentang cara menggunakan alat
dwh-migration-dumper, lihat Membuat metadata untuk terjemahan dan penilaian.Gunakan alat
dwh-migration-dumperuntuk mengekstrak metadata dan statistik performa ke file ZIP:dwh-migration-dumper \ --connector cloudera-manager \ --user USER_NAME \ --password PASSWORD \ --url URL_PATH \ --yarn-application-types "APP_TYPES" \ --pagination-page-size PAGE_SIZE \ --start-date START_DATE \ --end-date END_DATE \ --assessment
Ganti kode berikut:
USER_NAME: nama pengguna yang akan terhubung ke instance Cloudera Manager Anda.PASSWORD: sandi untuk instance Cloudera Manager Anda.URL_PATH: jalur URL ke Cloudera Manager API, misalnya,https://localhost:7183/api/v55/.APP_TYPES(opsional): jenis aplikasi YARN yang dipisahkan koma yang di-dump dari cluster. Nilai defaultnya adalahMAPREDUCE,SPARK,Oozie Launcher.PAGE_SIZE(opsional): jumlah data per respons Cloudera. Nilai defaultnya adalah1000.START_DATE(opsional): tanggal mulai untuk dump histori Anda dalam format ISO 8601, misalnya2025-05-29. Nilai defaultnya adalah 90 hari sebelum tanggal saat ini.END_DATE(opsional): tanggal berakhir untuk dump histori Anda dalam format ISO 8601, misalnya2025-05-30. Nilai defaultnya adalah tanggal saat ini.
Menggunakan Oozie di cluster Cloudera
Jika menggunakan Oozie di cluster Cloudera, Anda dapat membuang histori tugas Oozie dengan konektor Oozie. Anda dapat menggunakan Oozie dengan autentikasi Kerberos atau autentikasi dasar.
Untuk autentikasi Kerberos, jalankan perintah berikut:
kinit dwh-migration-dumper \ --connector oozie \ --url URL_PATH \ --assessment
Ganti kode berikut:
URL_PATH(opsional): jalur URL server Oozie. Jika Anda tidak menentukan jalur URL, jalur tersebut akan diambil dari variabel lingkunganOOZIE_URL.
Untuk autentikasi dasar, jalankan perintah berikut:
dwh-migration-dumper \ --connector oozie \ --user USER_NAME \ --password PASSWORD \ --url URL_PATH \ --assessment
Ganti kode berikut:
USER_NAME: nama pengguna Oozie.PASSWORD: sandi pengguna.URL_PATH(opsional): jalur URL server Oozie. Jika Anda tidak menentukan jalur URL, jalur tersebut akan diambil dari variabel lingkunganOOZIE_URL.
Menggunakan Airflow di cluster Cloudera
Jika menggunakan Airflow di cluster Cloudera, Anda dapat mengekspor histori DAG dengan konektor Airflow:
dwh-migration-dumper \ --connector airflow \ --user USER_NAME \ --password PASSWORD \ --url URL \ --driver "DRIVER_PATH" \ --start-date START_DATE \ --end-date END_DATE \ --assessment
Ganti kode berikut:
USER_NAME: nama pengguna AirflowPASSWORD: sandi penggunaURL: string JDBC ke database AirflowDRIVER_PATH: jalur ke driver JDBCSTART_DATE(opsional): tanggal mulai untuk dump histori Anda dalam format ISO 8601END_DATE(opsional): tanggal berakhir untuk dump histori Anda dalam format ISO 8601
Menggunakan Hive di cluster Cloudera
Untuk menggunakan konektor Hive, lihat tab Apache Hive.
Apache Hive
Persyaratan
- Mesin yang terhubung ke data warehouse Apache Hive sumber Anda (Penilaian migrasi BigQuery mendukung Hive di Tez dan MapReduce, serta mendukung versi Apache Hive antara 2.2 dan 3.1, inklusif)
- A Google Cloud kun dengan bucket Cloud Storage untuk menyimpan data
- Set data BigQuery kosong untuk menyimpan hasilnya
- Izin baca pada set data untuk melihat hasilnya
- Akses ke data warehouse Apache Hive sumber Anda untuk mengonfigurasi ekstraksi log kueri
- Statistik tabel, partisi, dan kolom yang terbaru
Penilaian migrasi BigQuery menggunakan statistik tabel, partisi, dan kolom untuk lebih memahami data warehouse Apache Hive Anda dan memberikan insight yang menyeluruh. Jika setelan konfigurasi hive.stats.autogather disetel ke false di gudang data Apache Hive sumber Anda, Google merekomendasikan untuk mengaktifkannya atau memperbarui statistik secara manual sebelum menjalankan alat dwh-migration-dumper.
Menjalankan alat dwh-migration-dumper
Download alat ekstraksi command line dwh-migration-dumper.
Download file
SHA256SUMS.txt
dan jalankan perintah berikut untuk memverifikasi kebenaran zip:
Bash
sha256sum --check SHA256SUMS.txt
Windows PowerShell
(Get-FileHash RELEASE_ZIP_FILENAME).Hash -eq ((Get-Content SHA256SUMS.txt) -Split " ")[0]
Ganti RELEASE_ZIP_FILENAME dengan
nama file zip yang didownload dari rilis alat ekstraksi command line dwh-migration-dumper, misalnya, dwh-migration-tools-v1.0.52.zip
Hasil True mengonfirmasi keberhasilan verifikasi checksum.
Hasil False menunjukkan error verifikasi. Pastikan file checksum dan ZIP didownload dari versi rilis yang sama dan ditempatkan di direktori yang sama.
Untuk mengetahui detail tentang cara menggunakan alat dwh-migration-dumper, lihat Membuat metadata untuk terjemahan dan penilaian.
Gunakan alat dwh-migration-dumper untuk membuat metadata dari data warehouse Hive Anda sebagai file ZIP.
Tanpa Autentikasi
Untuk membuat file ZIP metadata, jalankan perintah berikut di mesin yang memiliki akses ke data warehouse sumber:
dwh-migration-dumper \ --connector hiveql \ --database DATABASES \ --host hive.cluster.host \ --port 9083 \ --assessment
Dengan Autentikasi Kerberos
Untuk melakukan autentikasi ke metastore, login sebagai pengguna yang memiliki akses ke metastore Apache Hive dan buat tiket Kerberos. Kemudian, buat file zip metadata dengan perintah berikut:
JAVA_OPTS="-Djavax.security.auth.useSubjectCredsOnly=false" \ dwh-migration-dumper \ --connector hiveql \ --database DATABASES \ --host hive.cluster.host \ --port 9083 \ --hive-kerberos-url PRINCIPAL/HOST \ -Dhiveql.rpc.protection=hadoop.rpc.protection \ --assessment
Ganti kode berikut:
DATABASES: daftar nama database yang dipisahkan koma yang akan diekstrak. Jika tidak diberikan, semua database akan diekstrak.PRINCIPAL: entity utama kerberos yang tiketnya dikeluarkanHOST: nama host kerberos yang tiketnya dikeluarkan untukhadoop.rpc.protection: Quality of Protection (QOP) tingkat konfigurasi Simple Authentication and Security Layer (SASL), sama dengan nilai parameterhadoop.rpc.protectiondi dalam file/etc/hadoop/conf/core-site.xml, dengan salah satu nilai berikut:authenticationintegrityprivacy
Mengekstrak log kueri dengan hook logging hadoop-migration-assessment
Untuk mengekstrak log kueri, ikuti langkah-langkah berikut:
- Upload
hadoop-migration-assessmenthook logging. - Konfigurasi properti hook logging.
- Verifikasi hook logging.
Mengupload hook logging hadoop-migration-assessment
Download hook logging ekstraksi log kueri
hadoop-migration-assessmentyang berisi file JAR hook logging Hive.Ekstrak file JAR.
Jika Anda perlu mengaudit alat untuk memastikannya memenuhi persyaratan kepatuhan, tinjau kode sumber dari repositori GitHub hook logging
hadoop-migration-assessment, dan kompilasi biner Anda sendiri.Salin file JAR ke dalam folder library tambahan di semua cluster tempat Anda berencana mengaktifkan logging kueri. Bergantung pada vendor Anda, Anda perlu menemukan folder library tambahan di setelan cluster dan mentransfer file JAR ke folder library tambahan di cluster Hive.
Siapkan properti konfigurasi untuk hook logging
hadoop-migration-assessment. Bergantung pada vendor Hadoop Anda, Anda harus menggunakan konsol UI untuk mengedit setelan cluster. Ubah file/etc/hive/conf/hive-site.xmlatau terapkan konfigurasi dengan pengelola konfigurasi.
Mengonfigurasi properti
Jika Anda sudah memiliki nilai lain untuk kunci konfigurasi berikut, tambahkan setelan menggunakan koma (,). Untuk menyiapkan hook logging hadoop-migration-assessment, setelan konfigurasi berikut diperlukan:
hive.exec.failure.hooks:com.google.cloud.bigquery.dwhassessment.hooks.MigrationAssessmentLoggingHookhive.exec.post.hooks:com.google.cloud.bigquery.dwhassessment.hooks.MigrationAssessmentLoggingHookhive.exec.pre.hooks:com.google.cloud.bigquery.dwhassessment.hooks.MigrationAssessmentLoggingHookhive.aux.jars.path: sertakan jalur ke file JAR hook logging, misalnyafile://./HiveMigrationAssessmentQueryLogsHooks_deploy.jar dwhassessment.hook.base-directory: jalur ke folder output log kueri. Contoh,hdfs://tmp/logs/.Anda juga dapat menyetel konfigurasi opsional berikut:
dwhassessment.hook.queue.capacity: kapasitas antrean untuk thread logging peristiwa kueri. Nilai defaultnya adalah64.dwhassessment.hook.rollover-interval: frekuensi saat penggantian file harus dilakukan. Contoh,600s. Nilai default-nya adalah 3.600 detik (1 jam).dwhassessment.hook.rollover-eligibility-check-interval: frekuensi pemicuan pemeriksaan kelayakan penggantian file di latar belakang. Contoh,600s. Nilai default-nya adalah 600 detik (10 menit).
Memverifikasi hook logging
Setelah Anda memulai ulang proses hive-server2, jalankan kueri pengujian
dan analisis log debug Anda. Anda dapat melihat pesan berikut:
Logger successfully started, waiting for query events. Log directory is '[dwhassessment.hook.base-directory value]'; rollover interval is '60' minutes; rollover eligibility check is '10' minutes
Hook logging membuat subfolder yang dipartisi menurut tanggal di
folder yang dikonfigurasi. File Avro dengan peristiwa kueri muncul di folder tersebut setelah interval dwhassessment.hook.rollover-interval
atau penghentian proses hive-server2. Anda dapat mencari pesan serupa di log debug untuk melihat status operasi penggantian:
Updated rollover time for logger ID 'my_logger_id' to '2023-12-25T10:15:30'
Performed rollover check for logger ID 'my_logger_id'. Expected rollover time is '2023-12-25T10:15:30'
Pergantian terjadi pada interval yang ditentukan atau saat hari berubah. Saat tanggal berubah, hook logging juga membuat subfolder baru untuk tanggal tersebut.
Google merekomendasikan agar Anda menyediakan log kueri minimal dua minggu agar dapat melihat insight yang lebih menyeluruh.
Anda juga dapat membuat folder yang berisi log kueri dari berbagai cluster Hive dan memberikan semuanya untuk satu penilaian.
Informatica
Untuk meminta masukan atau dukungan terkait fitur ini, kirim email ke bq-edw-migration-support@google.com.
Persyaratan
- Akses ke klien Informatica PowerCenter Repository Manager
- Akun Google Cloud dengan bucket Cloud Storage untuk menyimpan data.
- Set data BigQuery kosong untuk menyimpan hasilnya. Atau, Anda dapat membuat set data BigQuery saat membuat tugas penilaian menggunakan konsol Google Cloud .
Persyaratan: Mengekspor file objek
Anda dapat menggunakan GUI Informatica PowerCenter Repository Manager untuk mengekspor file objek. Untuk mengetahui informasi, lihat Langkah-Langkah untuk Mengekspor Objek
Atau, Anda juga dapat menjalankan perintah pmrep untuk mengekspor file objek
dengan langkah-langkah berikut:
- Jalankan perintah
pmrep connectuntuk terhubung ke repositori:
pmrep connect -r `REPOSITORY_NAME` -d `DOMAIN_NAME` -n `USERNAME` -x `PASSWORD`
Ganti kode berikut:
REPOSITORY_NAME: nama repositori yang ingin Anda hubungkanDOMAIN_NAME: nama domain untuk repositoriUSERNAME: nama pengguna untuk terhubung ke repositoriPASSWORD: sandi nama pengguna
- Setelah terhubung ke repositori, gunakan perintah
pmrep objectexportuntuk mengekspor objek yang diperlukan:
pmrep objectexport -n `OBJECT_NAME` -o `OBJECT_TYPE` -f `FOLDER_NAME` -u `OUTPUT_FILE_NAME.xml`
Ganti kode berikut:
OBJECT_NAME: nama objek tertentu yang akan dieksporOBJECT_TYPE: jenis objek dari objek yang ditentukanFOLDER_NAME: nama folder yang berisi objek yang akan dieksporOUTPUT_FILE_NAME: nama file XML yang akan berisi informasi objek
Mengupload metadata dan log kueri ke Cloud Storage
Setelah mengekstrak metadata dan log kueri dari data warehouse, Anda dapat mengupload file ke bucket Cloud Storage untuk melanjutkan penilaian migrasi.
Teradata
Upload metadata dan satu atau beberapa file ZIP yang berisi log kueri ke bucket Cloud Storage Anda. Untuk mengetahui informasi selengkapnya tentang cara membuat bucket dan mengupload file ke Cloud Storage, lihat Membuat bucket dan Mengupload objek dari sistem file. Batas untuk total ukuran semua file yang tidak dikompresi di dalam file zip metadata adalah 50 GB.
Entri di semua file ZIP yang berisi log kueri dibagi menjadi hal berikut:
- File histori kueri dengan awalan
query_history_. - File deret waktu dengan awalan
utility_logs_,dbc.ResUsageScpu_, dandbc.ResUsageSpma_.
Batas total ukuran semua file histori kueri yang tidak dikompresi adalah 5 TB. Batas total ukuran yang tidak dikompresi dari semua file deret waktu adalah 1 TB.
Jika log kueri diarsipkan di database yang berbeda, lihat deskripsi flag -Dteradata-logs.query-logs-table dan -Dteradata-logs.sql-logs-table sebelumnya di bagian ini, yang menjelaskan cara memberikan lokasi alternatif untuk log kueri.
Redshift
Upload metadata dan satu atau beberapa file ZIP yang berisi log kueri ke bucket Cloud Storage Anda. Untuk mengetahui informasi selengkapnya tentang cara membuat bucket dan mengupload file ke Cloud Storage, lihat Membuat bucket dan Mengupload objek dari sistem file. Batas untuk total ukuran semua file yang tidak dikompresi di dalam file zip metadata adalah 50 GB.
Entri di semua file ZIP yang berisi log kueri dibagi menjadi hal berikut:
- File histori kueri dengan awalan
querytext_danddltext_. - File deret waktu dengan awalan
query_queue_info_,wlm_query_, danquerymetrics_.
Batas total ukuran semua file histori kueri yang tidak dikompresi adalah 5 TB. Batas total ukuran yang tidak dikompresi dari semua file deret waktu adalah 1 TB.
Redshift Serverless
Upload metadata dan satu atau beberapa file ZIP yang berisi log kueri ke bucket Cloud Storage Anda. Untuk mengetahui informasi selengkapnya tentang cara membuat bucket dan mengupload file ke Cloud Storage, lihat Membuat bucket dan Mengupload objek dari sistem file.
Snowflake
Upload metadata dan file ZIP yang berisi log kueri dan histori penggunaan ke bucket Cloud Storage Anda. Saat mengupload file ini ke Cloud Storage, persyaratan berikut harus dipenuhi:
- Total ukuran semua file yang tidak dikompresi di dalam file zip metadata harus kurang dari 50 GB.
- File ZIP metadata dan file ZIP yang berisi log kueri harus diupload ke folder Cloud Storage. Jika Anda memiliki beberapa file ZIP yang berisi log kueri yang tidak tumpang-tindih, Anda dapat mengupload semuanya.
- Anda harus mengupload semua file ke folder Cloud Storage yang sama.
- Anda harus mengupload semua file ZIP metadata dan log kueri persis seperti yang dihasilkan oleh alat
dwh-migration-dumper. Jangan mengekstrak, menggabungkan, atau memodifikasinya dengan cara lain. - Total ukuran semua file histori kueri yang tidak dikompresi harus kurang dari 5 TB.
Untuk mengetahui informasi selengkapnya tentang membuat bucket dan mengupload file ke Cloud Storage, lihat Membuat bucket dan Mengupload objek dari sistem file.
Oracle
Untuk meminta masukan atau dukungan terkait fitur ini, kirim email ke bq-edw-migration-support@google.com.
Upload file zip yang berisi metadata dan statistik performa ke bucket Cloud Storage. Secara default, nama file untuk file zip adalah
dwh-migration-oracle-stats.zip, tetapi Anda dapat menyesuaikannya dengan menentukannya
di flag --output. Batas untuk total ukuran semua file yang tidak dikompresi di dalam file ZIP adalah 50 GB.
Untuk mengetahui informasi selengkapnya tentang membuat bucket dan mengupload file ke Cloud Storage, lihat Membuat bucket dan Mengupload objek dari sistem file.
Hadoop / Cloudera
Untuk meminta masukan atau dukungan terkait fitur ini, kirim email ke bq-edw-migration-support@google.com.
Upload file zip yang berisi metadata dan statistik performa ke bucket Cloud Storage. Secara default, nama file untuk file zip adalah
dwh-migration-cloudera-manager-RUN_DATE.zip (misalnya
dwh-migration-cloudera-manager-20250312T145808.zip), tetapi Anda dapat
menyesuaikannya dengan tanda --output. Batas total ukuran semua file yang tidak dikompresi di dalam file ZIP adalah 50 GB.
Untuk mengetahui informasi selengkapnya tentang membuat bucket dan mengupload file ke Cloud Storage, lihat Membuat bucket dan Mengupload objek dari sistem file.
Apache Hive
Upload metadata dan folder yang berisi log kueri dari satu atau beberapa cluster Hive ke bucket Cloud Storage. Untuk mengetahui informasi selengkapnya tentang membuat bucket dan mengupload file ke Cloud Storage, lihat Membuat bucket dan Mengupload objek dari sistem file.
Batas untuk total ukuran semua file yang tidak dikompresi di dalam file zip metadata adalah 50 GB.
Anda dapat menggunakan konektor Cloud Storage untuk menyalin log kueri langsung ke folder Cloud Storage. Folder yang berisi subfolder dengan log kueri harus diupload ke folder Cloud Storage yang sama, tempat file ZIP metadata diupload.
Folder log kueri memiliki file histori kueri dengan awalan dwhassessment_. Batas total ukuran semua file histori kueri yang tidak dikompresi adalah 5 TB.
Informatica
Untuk meminta masukan atau dukungan terkait fitur ini, kirim email ke bq-edw-migration-support@google.com.
Upload file zip yang berisi objek repositori XML Informatica ke bucket Cloud Storage. File ZIP ini juga harus menyertakan
file compilerworks-metadata.yaml yang berisi hal berikut:
product: arguments: "ConnectorArguments{connector=informatica, assessment=true}"
Batas untuk total ukuran semua file yang tidak dikompresi di dalam file ZIP adalah 50 GB.
Untuk mengetahui informasi selengkapnya tentang membuat bucket dan mengupload file ke Cloud Storage, lihat Membuat bucket dan Mengupload objek dari sistem file.
Menjalankan penilaian migrasi BigQuery
Ikuti langkah-langkah berikut untuk menjalankan penilaian migrasi BigQuery. Langkah-langkah ini mengasumsikan bahwa Anda telah mengupload file metadata ke dalam bucket Cloud Storage, seperti yang dijelaskan di bagian sebelumnya.
Izin yang diperlukan
Untuk mengaktifkan BigQuery Migration Service, Anda memerlukan izin Identity and Access Management (IAM) berikut:
resourcemanager.projects.getresourcemanager.projects.updateserviceusage.services.enableserviceusage.services.get
Untuk mengakses dan menggunakan BigQuery Migration Service, Anda memerlukan izin berikut pada project:
bigquerymigration.workflows.createbigquerymigration.workflows.getbigquerymigration.workflows.listbigquerymigration.workflows.deletebigquerymigration.subtasks.getbigquerymigration.subtasks.list
Untuk menjalankan BigQuery Migration Service, Anda memerlukan izin tambahan berikut.
Izin untuk mengakses bucket Cloud Storage untuk file input dan output:
storage.objects.getdi bucket Cloud Storage sumberstorage.objects.listdi bucket Cloud Storage sumberstorage.objects.createdi bucket Cloud Storage tujuanstorage.objects.deletedi bucket Cloud Storage tujuanstorage.objects.updatedi bucket Cloud Storage tujuanstorage.buckets.getstorage.buckets.list
Izin untuk membaca dan memperbarui set data BigQuery tempat BigQuery Migration Service menulis hasilnya:
bigquery.datasets.updatebigquery.datasets.getbigquery.datasets.createbigquery.datasets.deletebigquery.jobs.createbigquery.jobs.deletebigquery.jobs.listbigquery.jobs.updatebigquery.tables.createbigquery.tables.getbigquery.tables.getDatabigquery.tables.listbigquery.tables.updateData
Untuk membagikan laporan Looker Studio kepada pengguna, Anda harus memberikan peran berikut:
roles/bigquery.dataViewerroles/bigquery.jobUser
Untuk menyesuaikan dokumen ini agar menggunakan project dan pengguna Anda sendiri dalam perintah, edit variabel berikut:
PROJECT,
USER_EMAIL.
Buat peran khusus dengan izin yang diperlukan untuk menggunakan penilaian migrasi BigQuery:
gcloud iam roles create BQMSrole \ --project=PROJECT \ --title=BQMSrole \ --permissions=bigquerymigration.subtasks.get,bigquerymigration.subtasks.list,bigquerymigration.workflows.create,bigquerymigration.workflows.get,bigquerymigration.workflows.list,bigquerymigration.workflows.delete,resourcemanager.projects.update,resourcemanager.projects.get,serviceusage.services.enable,serviceusage.services.get,storage.objects.get,storage.objects.list,storage.objects.create,storage.objects.delete,storage.objects.update,bigquery.datasets.get,bigquery.datasets.update,bigquery.datasets.create,bigquery.datasets.delete,bigquery.tables.get,bigquery.tables.create,bigquery.tables.updateData,bigquery.tables.getData,bigquery.tables.list,bigquery.jobs.create,bigquery.jobs.update,bigquery.jobs.list,bigquery.jobs.delete,storage.buckets.list,storage.buckets.get
Memberikan peran khusus BQMSrole kepada pengguna:
gcloud projects add-iam-policy-binding \ PROJECT \ --member=user:USER_EMAIL \ --role=projects/PROJECT/roles/BQMSrole
Berikan peran yang diperlukan kepada pengguna yang ingin Anda ajak berbagi laporan:
gcloud projects add-iam-policy-binding \ PROJECT \ --member=user:USER_EMAIL \ --role=roles/bigquery.dataViewer gcloud projects add-iam-policy-binding \ PROJECT \ --member=user:USER_EMAIL \ --role=roles/bigquery.jobUser
Lokasi yang didukung
Fitur penilaian migrasi BigQuery didukung di dua jenis lokasi:
Region adalah lokasi geografis spesifik, seperti London.
Multi-region adalah area geografis yang luas, seperti Amerika Serikat, yang berisi dua atau beberapa region. Lokasi multi-region dapat menyediakan kuota yang lebih besar daripada satu region.
Untuk mengetahui informasi selengkapnya tentang region dan zona, lihat Geografi dan region.
Region
Tabel berikut mencantumkan region di Amerika tempat penilaian migrasi BigQuery tersedia.| Deskripsi region | Nama region | Detail |
|---|---|---|
| Columbus, Ohio | us-east5 |
|
| Dallas | us-south1 |
|
| Iowa | us-central1 |
|
| South Carolina | us-east1 |
|
| Northern Virginia | us-east4 |
|
| Oregon | us-west1 |
|
| Los Angeles | us-west2 |
|
| Salt Lake City | us-west3 |
| Deskripsi region | Nama region | Detail |
|---|---|---|
| Singapura | asia-southeast1 |
|
| Tokyo | asia-northeast1 |
| Deskripsi region | Nama region | Detail |
|---|---|---|
| Belgia | europe-west1 |
|
| Finlandia | europe-north1 |
|
| Frankfurt | europe-west3 |
|
| London | europe-west2 |
|
| Madrid | europe-southwest1 |
|
| Belanda | europe-west4 |
|
| Paris | europe-west9 |
|
| Turin | europe-west12 |
|
| Warsawa | europe-central2 |
|
| Zürich | europe-west6 |
|
Multi-region
Tabel berikut mencantumkan multi-region tempat penilaian migrasi BigQuery tersedia.| Deskripsi multi-region | Nama multi-region |
|---|---|
| Pusat data di negara anggota Uni Eropa | EU |
| Pusat data di Amerika Serikat | US |
Sebelum memulai
Sebelum menjalankan penilaian, Anda harus mengaktifkan BigQuery Migration API dan membuat set data BigQuery untuk menyimpan hasil penilaian.
Mengaktifkan BigQuery Migration API
Aktifkan BigQuery Migration API sebagai berikut:
Di konsol Google Cloud , buka halaman BigQuery Migration API.
Klik Enable.
Membuat set data untuk hasil penilaian
Penilaian migrasi BigQuery menulis hasil penilaian ke tabel di BigQuery. Sebelum memulai, buat set data untuk menyimpan tabel-tabel ini. Saat membagikan laporan Looker Studio, Anda juga harus memberikan izin kepada pengguna untuk membaca set data ini. Untuk mengetahui informasi selengkapnya, lihat Membuat laporan dapat dibaca oleh pengguna.
Menjalankan penilaian migrasi
Konsol
Di konsol Google Cloud , buka halaman BigQuery.
Di menu navigasi, klik Penilaian.
Klik Start Assessment.
Isi dialog konfigurasi penilaian.
- Untuk Display name, masukkan nama yang dapat berisi huruf, angka, atau garis bawah. Nama ini hanya untuk tujuan tampilan dan tidak harus unik.
Dalam daftar Data location, pilih lokasi untuk tugas penilaian. Tugas penilaian harus berada di lokasi yang sama dengan bucket Cloud Storage input file yang diekstrak dan set data BigQuery output Anda. Namun, jika bucket Cloud Storage atau set data BigQuery berada di multi-region, maka tugas penilaian harus berada di salah satu region dalam multi-region ini.
Jika lokasi penilaian adalah multi-region
USatauEU, maka lokasi bucket Cloud Storage dan lokasi set data BigQuery harus berada di multi-region yang sama atau di lokasi di dalam multi-region ini. Untuk mengetahui informasi selengkapnya tentang batasan lokasi, lihat Pertimbangan Lokasi Data Pemuatan BigQuery.Untuk Assessment data source, pilih data warehouse Anda.
Untuk Path to input files, masukkan jalur ke bucket Cloud Storage yang berisi file yang diekstrak.
Untuk memilih cara hasil penilaian Anda disimpan, lakukan salah satu opsi berikut:
- Biarkan kotak centang Buat set data BigQuery baru secara otomatis tetap dicentang agar set data BigQuery dibuat secara otomatis. Nama set data dibuat secara otomatis.
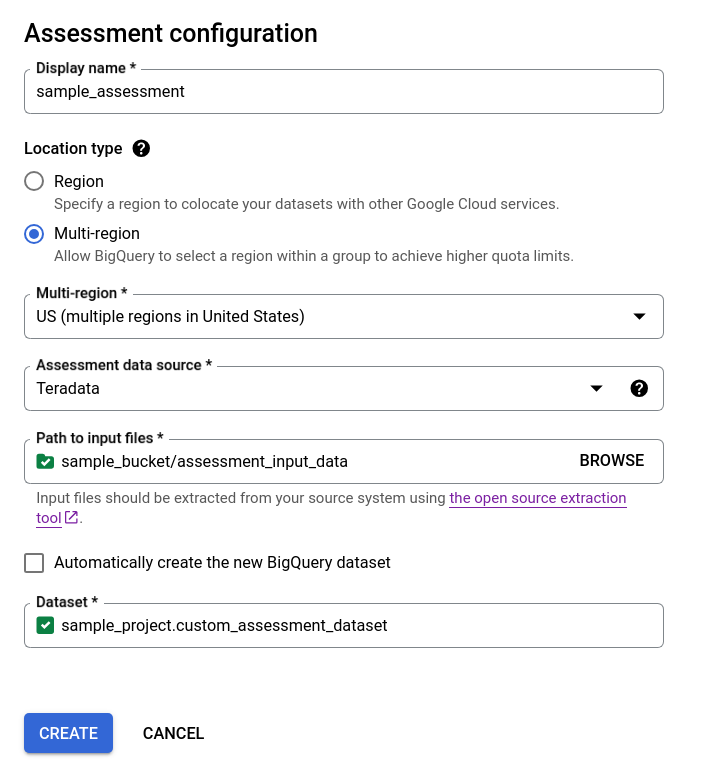
- Hapus centang pada kotak Buat set data BigQuery baru secara otomatis, lalu pilih set data BigQuery kosong yang ada menggunakan format
projectId.datasetId, atau buat nama set data baru. Pada opsi ini, Anda dapat memilih nama set data BigQuery.
Opsi 1 - pembuatan set data BigQuery otomatis (default)
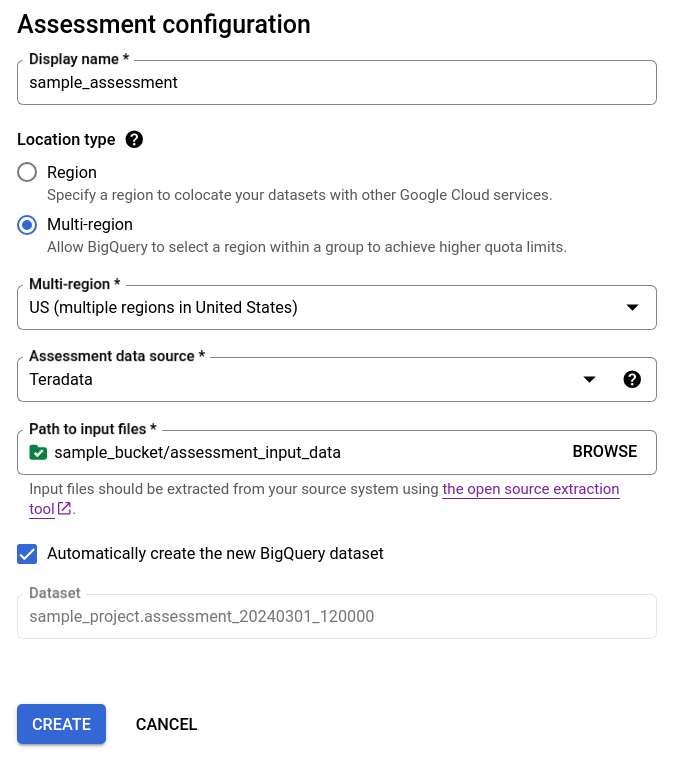
Opsi 2 - pembuatan set data BigQuery secara manual:
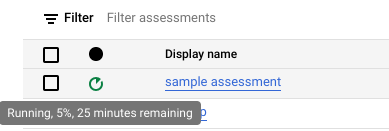
Klik Buat. Anda dapat melihat status tugas di daftar tugas penilaian.
Saat penilaian berjalan, Anda dapat memeriksa progres dan perkiraan waktu penyelesaiannya di tooltip ikon status.
Saat penilaian berjalan, Anda dapat mengklik link Lihat laporan di daftar tugas penilaian untuk melihat laporan penilaian dengan data parsial di Looker Studio. Link Lihat laporan mungkin memerlukan waktu beberapa saat untuk muncul saat penilaian sedang berjalan. Laporan akan terbuka di tab baru.
Laporan diperbarui dengan data baru saat diproses. Muat ulang tab dengan laporan atau klik Lihat laporan lagi untuk melihat laporan yang diperbarui.
Setelah penilaian selesai, klik Lihat laporan untuk melihat laporan penilaian lengkap di Looker Studio. Laporan akan terbuka di tab baru.
API
Panggil metode create dengan alur kerja yang ditentukan.
Kemudian, panggil metode start untuk memulai alur kerja penilaian.
Penilaian ini membuat tabel-tabel dalam set data BigQuery yang telah Anda buat sebelumnya. Anda dapat membuat kueri untuk mengetahui informasi tentang tabel dan kueri yang digunakan di data warehouse yang ada. Untuk informasi tentang file output terjemahan, lihat Penerjemah SQL Batch.
Hasil penilaian gabungan yang dapat dibagikan
Untuk penilaian Amazon Redshift, Teradata, dan Snowflake, selain set data BigQuery yang dibuat sebelumnya, alur kerja akan membuat set data ringan lain dengan nama yang sama, ditambah dengan akhiran _shareableRedactedAggregate. Set data ini berisi data yang sangat diagregasi yang berasal dari set data output, dan tidak berisi informasi identitas pribadi (PII).
Untuk menemukan, memeriksa, dan membagikan set data secara aman kepada pengguna lain, lihat Mengirim kueri ke tabel output penilaian migrasi.
Fitur ini aktif secara default, tetapi Anda dapat menonaktifkannya menggunakan API publik.
Detail penilaian
Untuk melihat halaman detail Penilaian, klik nama tampilan dalam daftar tugas penilaian.

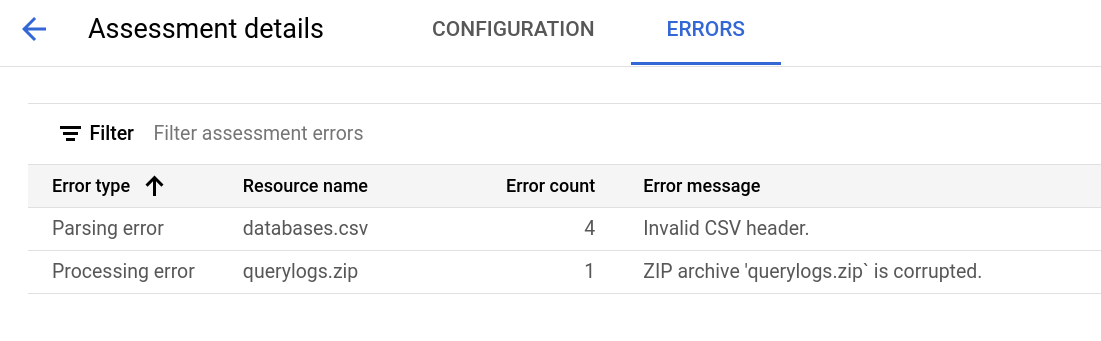
Halaman detail penilaian berisi tab Konfigurasi, tempat Anda dapat melihat informasi selengkapnya tentang tugas penilaian, dan tab Error, tempat Anda dapat meninjau error apa pun yang terjadi selama pemrosesan penilaian.
Lihat tab Konfigurasi untuk melihat properti penilaian.
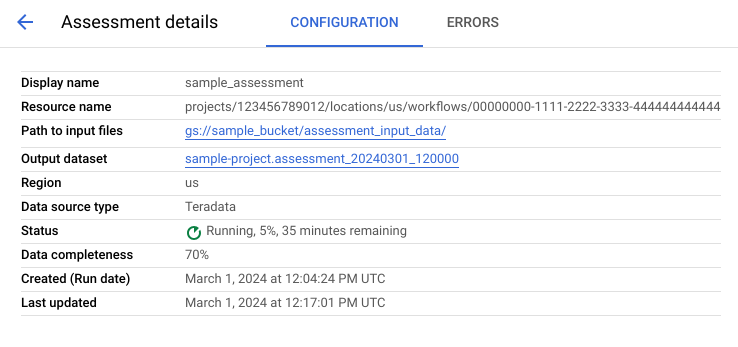
Lihat tab Error untuk melihat error yang terjadi selama pemrosesan penilaian.
Meninjau dan membagikan laporan Looker Studio
Setelah tugas penilaian selesai, Anda dapat membuat dan membagikan laporan Looker Studio tentang hasil.
Meninjau laporan
Klik link Lihat laporan yang tercantum di samping masing-masing tugas penilaian. Laporan Looker Studio akan terbuka di tab baru, dalam mode pratinjau. Anda dapat menggunakan mode pratinjau untuk meninjau isi laporan sebelum membagikannya lebih lanjut.
Laporan ini terlihat mirip dengan screenshot berikut:
Untuk melihat tabel virtual yang terdapat dalam laporan, pilih data warehouse Anda:
Teradata
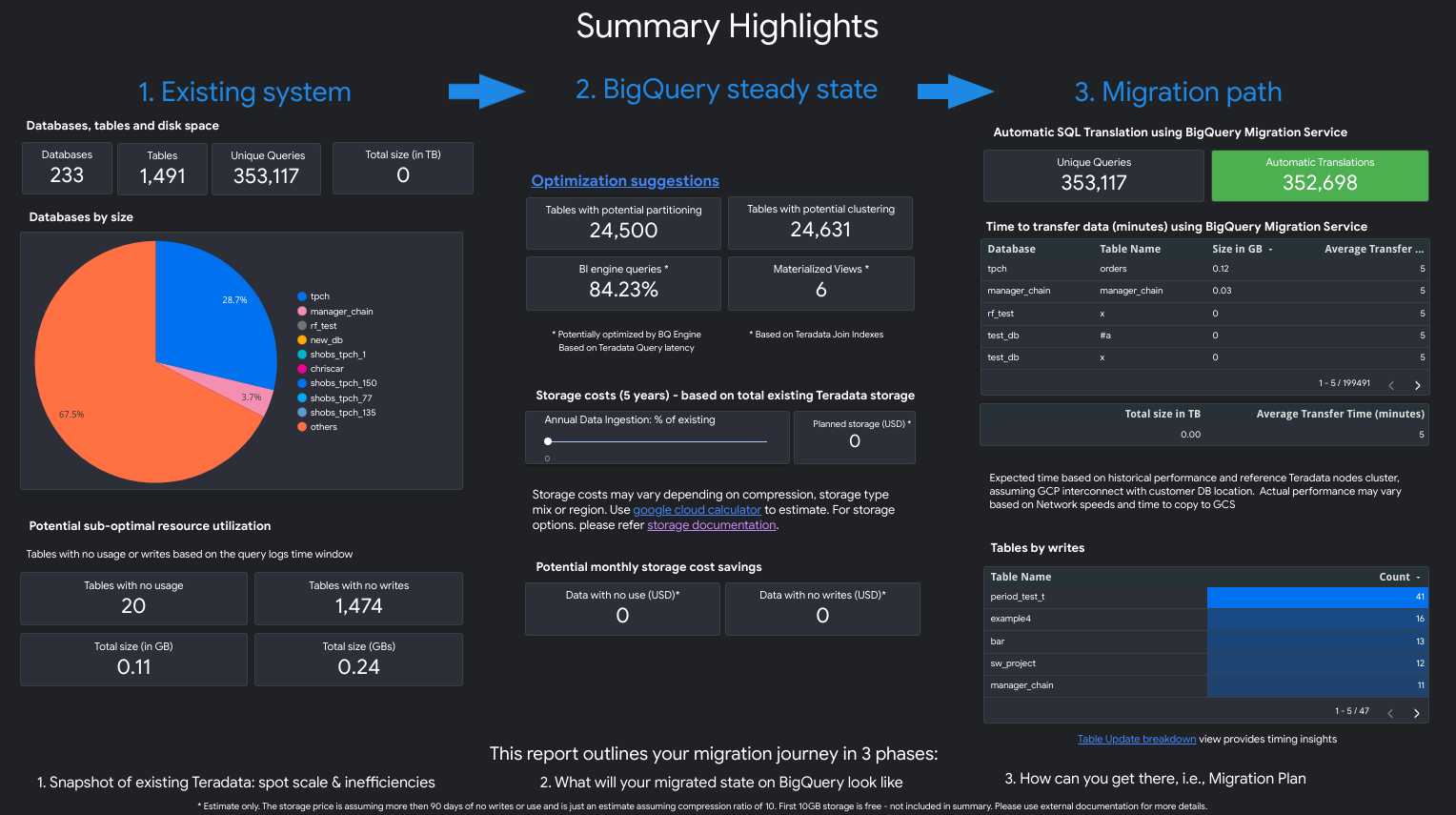
Laporan ini adalah narasi tiga bagian yang diawali dengan halaman highlight ringkasan. Halaman tersebut berisi bagian-bagian berikut:
- Sistem yang ada. Bagian ini adalah snapshot dari sistem dan penggunaan Teradata yang ada, termasuk jumlah database, skema, tabel, dan ukuran total dalam TB. Bagian ini juga mencantumkan skema berdasarkan ukuran dan mengarah ke potensi pemanfaatan resource yang kurang optimal (tabel tanpa penulisan atau beberapa pembacaan).
- Transformasi status stabil BigQuery (saran). Bagian ini menunjukkan tampilan sistem di BigQuery setelah migrasi. Bagian ini mencakup saran untuk mengoptimalkan workload di BigQuery (dan menghindari pemborosan).
- Rencana migrasi. Bagian ini memberikan informasi tentang upaya migrasi itu sendiri—misalnya, beralih dari sistem yang ada ke status stabil BigQuery. Bagian ini berisi jumlah kueri yang diterjemahkan secara otomatis dan perkiraan waktu untuk memindahkan setiap tabel ke BigQuery.
Detail setiap bagian meliputi hal-hal berikut:
Sistem yang ada
- Komputasi & Kueri
- Pemakaian CPU:
- Peta panas pemakaian CPU rata-rata per jam (tabel virtual penggunaan resource sistem secara keseluruhan)
- Kueri berdasarkan jam dan hari dengan pemakaian CPU
- Kueri menurut jenis (baca/tulis) dengan pemakaian CPU
- Aplikasi dengan pemakaian CPU
- Overlay penggunaan CPU per jam dengan performa kueri per jam rata-rata dan performa aplikasi per jam rata-rata
- Histogram kueri menurut jenis dan durasi kueri
- Tabel virtual detail aplikasi (aplikasi, pengguna, kueri unik, pelaporan versus perincian ETL)
- Pemakaian CPU:
- Ringkasan Penyimpanan
- Database menurut volume, tabel virtual, dan rasio akses
- Tabel dengan rasio akses berdasarkan pengguna, kueri, penulisan, dan pembuatan tabel sementara
- Aplikasi: Rasio akses dan alamat IP
Transformasi status stabil BigQuery (saran)
- Indeks join yang dikonversi ke tampilan terwujud
- Mengelompokkan dan mempartisi kandidat berdasarkan metadata dan penggunaan
- Kueri berlatensi rendah yang diidentifikasi sebagai kandidat untuk BigQuery BI Engine
- Kolom yang dikonfigurasi dengan nilai default yang menggunakan fitur deskripsi kolom untuk menyimpan nilai default
- Indeks unik di Teradata (untuk mencegah baris dengan kunci non-unik dalam tabel) menggunakan tabel staging dan pernyataan
MERGEuntuk menyisipkan hanya kumpulan data unik ke dalam tabel target, kemudian menghapus duplikat - Kueri dan skema yang tersisa diterjemahkan apa adanya
Rencana migrasi
- Tabel virtual mendetail dengan kueri yang diterjemahkan secara otomatis
- Jumlah total kueri dengan kemampuan untuk memfilter menurut pengguna, aplikasi, tabel yang terpengaruh, tabel yang dikueri, dan jenis kueri
- Bucket kueri dengan pola serupa yang dikelompokkan dan ditampilkan bersama, sehingga pengguna dapat melihat filosofi terjemahan berdasarkan jenis kueri
- Kueri yang memerlukan intervensi manusia
- Kueri dengan pelanggaran struktur leksikal BigQuery
- Fungsi dan prosedur yang ditentukan pengguna
- Kata kunci yang dicadangkan untuk BigQuery
- Jadwal tabel berdasarkan operasi tulis dan baca (untuk mengelompokkannya dalam rangka pemindahan)
- Migrasi data dengan BigQuery Data Transfer Service: Perkiraan waktu untuk bermigrasi menurut tabel
Bagian Sistem yang Ada berisi tabel virtual berikut:
- Ringkasan Sistem
- Tabel virtual Ringkasan Sistem menyediakan metrik volume tingkat tinggi dari komponen utama dalam sistem yang ada selama jangka waktu tertentu. Linimasa yang dievaluasi bergantung pada log yang dianalisis oleh penilaian migrasi BigQuery. Tabel virtual ini memberi Anda insight singkat tentang pemakaian data warehouse sumber, yang dapat Anda gunakan untuk perencanaan migrasi.
- Volume Tabel
- Tabel virtual Volume Tabel menyediakan statistik tentang tabel dan database terbesar yang ditemukan oleh penilaian migrasi BigQuery. Karena tabel besar mungkin memerlukan waktu lebih lama untuk diekstrak dari sistem data warehouse sumber, tabel virtual ini dapat membantu dalam perencanaan dan pengurutan migrasi.
- Penggunaan Tabel
- Tabel virtual Penggunaan Tabel menyediakan statistik tentang tabel mana yang banyak digunakan dalam sistem data warehouse sumber. Tabel yang banyak digunakan dapat membantu Anda memahami tabel mana yang mungkin memiliki banyak dependensi dan memerlukan perencanaan tambahan selama proses migrasi.
- Aplikasi
- Tabel virtual Penggunaan Aplikasi dan tabel virtual Pola Aplikasi menyediakan statistik tentang aplikasi yang ditemukan selama pemrosesan log. Dengan tabel-tabel virtual ini, pengguna dapat memahami penggunaan aplikasi tertentu dari waktu ke waktu dan dampaknya terhadap penggunaan resource. Selama migrasi, penting untuk memvisualisasikan penyerapan dan pemakaian data untuk mendapatkan pemahaman yang lebih baik tentang dependensi data warehouse, serta menganalisis dampak pemindahan berbagai aplikasi dependen secara bersamaan. Tabel Alamat IP dapat berguna untuk menemukan aplikasi yang tepat menggunakan data warehouse melalui koneksi JDBC.
- Kueri
- Tabel virtual Kueri memberikan perincian jenis pernyataan SQL yang dijalankan dan statistik penggunaannya. Anda dapat menggunakan histogram Jenis dan Waktu Kueri untuk mengidentifikasi periode penggunaan sistem yang rendah dan waktu optimal untuk mentransfer data. Anda juga dapat menggunakan tabel virtual ini untuk mengidentifikasi kueri yang sering dieksekusi dan pengguna yang memanggil eksekusi tersebut.
- Database
- Tabel virtual Database menyediakan metrik terkait ukuran, tabel, tabel virtual, dan prosedur yang ditentukan dalam sistem data warehouse sumber. Tabel virtual ini dapat memberikan insight tentang volume objek yang perlu Anda migrasikan.
- Pengaitan Database
- Tabel virtual Pengaitan Database memberikan tabel virtual tingkat tinggi tentang database dan tabel yang diakses bersama dalam satu kueri. Tabel virtual ini dapat menunjukkan tabel dan database yang sering dirujuk dan apa yang dapat Anda gunakan untuk perencanaan migrasi.
Bagian status stabil BigQuery berisi tabel virtual berikut:
- Tabel Tanpa Penggunaan
- Tabel virtual tentang Tabel Tanpa Penggunaan menampilkan tabel-tabel yang menurut penilaian migrasi BigQuery tidak memiliki penggunaan apa pun selama periode log yang dianalisis. Kurangnya penggunaan mungkin menunjukkan bahwa Anda tidak perlu mentransfer tabel tersebut ke BigQuery selama migrasi atau bahwa biaya penyimpanan data di BigQuery bisa lebih rendah. Anda harus memvalidasi daftar tabel yang tidak digunakan karena tabel tersebut bisa jadi memiliki penggunaan di luar periode log, misalnya tabel yang hanya digunakan sekali setiap tiga atau enam bulan.
- Tabel Tanpa Penulisan
- Tabel virtual tentang Tabel Tanpa Penulisan menampilkan tabel-tabel yang menurut penilaian migrasi BigQuery tidak memiliki update apa pun selama periode log yang dianalisis. Kurangnya operasi tulis dapat mengindikasikan di mana Anda dapat menurunkan biaya penyimpanan di BigQuery.
- Kueri Berlatensi Rendah
- Tabel virtual Kueri Berlatensi Rendah menampilkan distribusi runtime kueri berdasarkan data log yang dianalisis. Jika diagram distribusi durasi kueri menampilkan sejumlah besar kueri dengan runtime < 1 detik, pertimbangkan untuk mengaktifkan BigQuery BI Engine guna mempercepat BI dan workload berlatensi rendah lainnya.
- Tampilan Terwujud
- Tampilan Terwujud memberikan saran pengoptimalan lebih lanjut untuk meningkatkan performa di BigQuery.
- Pengelompokan dan Partisi
Tabel virtual Partisi dan Pengelompokan menampilkan tabel-tabel yang akan mendapatkan manfaat dari partisi, pengelompokan, atau keduanya.
Saran Metadata didapatkan dengan menganalisis skema data warehouse sumber (seperti Partisi dan Kunci Utama dalam tabel sumber) dan menemukan BigQuery terdekat yang setara untuk mencapai karakteristik pengoptimalan yang serupa.
Saran Workload dicapai dengan menganalisis log kueri sumber. Rekomendasi ditentukan dengan menganalisis workload, terutama klausa
WHEREatauJOINdalam log kueri yang dianalisis.- Rekomendasi Pengelompokan
Tabel virtual Partisi menampilkan tabel-tabel yang mungkin memiliki lebih dari 10.000 partisi, berdasarkan definisi batasan partisinya. Tabel-tabel tersebut cenderung menjadi kandidat yang baik untuk pengelompokan BigQuery, yang memungkinkan partisi tabel terperinci.
- Batasan Unik
Tabel virtual Batasan Unik menampilkan tabel-tabel
SETdan indeks unik yang ditentukan dalam data warehouse sumber. Di BigQuery, sebaiknya gunakan tabel staging dan pernyataanMERGEuntuk hanya menyisipkan kumpulan data unik ke dalam tabel target. Gunakan konten tabel virtual ini untuk membantu menentukan tabel mana yang mungkin perlu Anda sesuaikan ETLnya selama migrasi.- Nilai Default / Batasan Pemeriksaan
Tabel virtual ini menunjukkan tabel yang menggunakan batasan pemeriksaan untuk menetapkan nilai kolom default. Di BigQuery, lihat bagian Menentukan nilai kolom default.
Bagian Jalur migrasi laporan berisi tabel virtual berikut:
- Terjemahan SQL
- Tabel virtual Terjemahan SQL mencantumkan jumlah dan detail kueri yang secara otomatis dikonversi oleh penilaian migrasi BigQuery dan tidak memerlukan intervensi manual. Terjemahan SQL Otomatis biasanya mencapai tingkat terjemahan yang tinggi jika metadata diberikan. Tabel virtual ini bersifat interaktif dan memungkinkan analisis kueri umum serta bagaimana kueri tersebut diterjemahkan.
- Upaya Offline
- Tabel virtual Upaya Offline merekam area yang memerlukan intervensi manual, termasuk UDF spesifik serta potensi pelanggaran struktur leksikal dan sintaksis untuk tabel atau kolom.
- Kata Kunci yang Dicadangkan untuk BigQuery
- Tabel virtual Kata Kunci yang Dicadangkan untuk BigQuery menampilkan penggunaan kata kunci yang terdeteksi memiliki arti khusus dalam bahasa GoogleSQL, dan tidak dapat digunakan sebagai ID kecuali jika diapit oleh tanda kutip terbalik (
`). - Jadwal Pembaruan Tabel
- Tabel virtual Jadwal Pembaruan Tabel menampilkan waktu dan seberapa sering tabel diperbarui untuk membantu Anda merencanakan cara dan waktu memindahkannya.
- Migrasi Data ke BigQuery
- Tabel virtual Migrasi Data ke BigQuery menguraikan jalur migrasi dengan perkiraan waktu untuk memigrasikan data Anda menggunakan BigQuery Data Transfer Service. Untuk mengetahui informasi selengkapnya, baca Panduan BigQuery Data Transfer Service untuk Teradata.
Bagian Lampiran berisi tabel virtual berikut:
- Kepekaan Huruf Besar/Kecil
- Tabel virtual Kepekaan Huruf Besar/Kecil menampilkan tabel di data warehouse sumber yang dikonfigurasi untuk melakukan perbandingan yang tidak peka huruf besar/kecil. Secara default, perbandingan string di BigQuery peka huruf besar/kecil. Untuk mengetahui informasi selengkapnya, lihat Kolasi.
Redshift
- Sorotan Migrasi
- Tabel virtual Sorotan Migrasi memberikan ringkasan eksekutif terkait tiga bagian laporan:
- Panel Sistem yang Ada menyediakan informasi tentang jumlah database, skema, tabel, dan ukuran total Redshift System yang ada. Tabel ini juga mencantumkan skema berdasarkan ukuran dan potensi pemanfaatan resource yang kurang optimal. Anda dapat menggunakan informasi ini untuk mengoptimalkan data dengan menghapus, mempartisi, atau mengelompokkan tabel.
- Panel Status Stabil BigQuery memberikan informasi tentang tampilan data Anda setelah migrasi di BigQuery, termasuk jumlah kueri yang dapat diterjemahkan secara otomatis menggunakan BigQuery Migration Service. Bagian ini juga menampilkan biaya penyimpanan data di BigQuery berdasarkan tingkat penyerapan data tahunan Anda, beserta saran pengoptimalan untuk tabel, penyediaan, dan ruang.
- Panel Jalur Migrasi memberikan informasi tentang upaya migrasi itu sendiri. Untuk setiap tabel, panel ini menampilkan perkiraan waktu migrasi, jumlah baris dalam tabel, dan ukurannya.
Bagian Sistem yang Ada berisi tabel virtual berikut:
- Kueri berdasarkan Jenis dan Jadwal
- Tabel virtual Kueri berdasarkan Jenis dan Jadwal mengategorikan kueri Anda ke dalam ETL/Tulis dan Pelaporan/Agregasi. Dengan melihat kombinasi kueri dari waktu ke waktu, Anda dapat memahami pola penggunaan yang ada, dan mengidentifikasi ledakan serta potensi penyediaan yang berlebihan yang dapat memengaruhi biaya dan performa.
- Antrean Kueri
- Tabel virtual Antrean Kueri memberikan detail tambahan tentang muatan sistem, termasuk volume kueri, campuran, dan dampak performa apa pun akibat antrean, seperti resource yang tidak mencukupi.
- Kueri dan Penskalaan WLM
- Tabel virtual Kueri dan Penskalaan WLM mengidentifikasi penskalaan konkurensi sebagai kompleksitas konfigurasi dan biaya tambahan. Tabel virtual ini menunjukkan cara sistem Redshift merutekan kueri berdasarkan aturan yang Anda tentukan, dan dampak performa akibat antrean, penskalaan konkurensi, dan kueri yang dikeluarkan.
- Mengantre dan Menunggu
- Tabel virtual Antrean dan Menunggu adalah analisis yang lebih mendalam tentang waktu tunggu dan antrean untuk kueri dari waktu ke waktu.
- Kelas dan Performa WLM
- Tabel virtual Kelas dan Performa WLM menyediakan cara opsional untuk memetakan aturan Anda ke BigQuery. Namun, sebaiknya izinkan BigQuery merutekan kueri Anda secara otomatis.
- Insight volume Tabel & Kueri
- Tabel virtual Insight volume Tabel & Kueri mencantumkan daftar kueri berdasarkan ukuran, frekuensi, dan pengguna teratas. Hal ini membantu Anda mengategorikan sumber beban pada sistem dan merencanakan cara memigrasikan workload.
- Database dan Skema
- Tabel virtual Database dan Skema menyediakan metrik terkait ukuran, tabel, tabel virtual, dan prosedur yang ditentukan dalam sistem data warehouse sumber. Tabel virtual ini memberikan insight tentang volume objek yang perlu dimigrasikan.
- Volume Tabel
- Tabel virtual Volume Tabel menyediakan statistik tentang tabel dan database terbesar, yang menunjukkan cara mereka diakses. Karena tabel besar mungkin memerlukan waktu lebih lama untuk diekstrak dari sistem data warehouse sumber, tabel virtual ini membantu Anda dalam perencanaan dan pengurutan migrasi.
- Penggunaan Tabel
- Tabel virtual Penggunaan Tabel menyediakan statistik tentang tabel mana yang banyak digunakan dalam sistem data warehouse sumber. Tabel yang banyak digunakan dapat dimanfaatkan untuk memahami tabel yang mungkin memiliki banyak dependensi dan memperoleh perencanaan tambahan selama proses migrasi.
- Importir & Eksportir
- Tampilan Pengimpor & Pengekspor memberikan informasi tentang data dan pengguna yang terlibat dalam impor data (menggunakan kueri
COPY) dan ekspor data (menggunakan kueriUNLOAD). Tampilan ini membantu mengidentifikasi lapisan penyiapan dan proses terkait penyerapan dan ekspor. - Pemanfaatan Cluster
- Tampilan Penggunaan Cluster memberikan informasi umum tentang semua cluster yang tersedia dan menampilkan penggunaan CPU untuk setiap cluster. Tampilan ini dapat membantu Anda memahami cadangan kapasitas sistem.
Bagian status stabil BigQuery berisi tabel virtual berikut:
- Pengelompokan & Partisi
Tabel virtual Partisi dan Pengelompokan menampilkan tabel-tabel yang akan mendapatkan manfaat dari partisi, pengelompokan, atau keduanya.
Saran Metadata didapatkan dengan menganalisis skema data warehouse sumber (seperti Kunci Pengurutan dan Kunci Distribusi dalam tabel sumber) dan menemukan BigQuery terdekat yang setara untuk mencapai karakteristik pengoptimalan yang serupa.
Saran Workload dicapai dengan menganalisis log kueri sumber. Rekomendasi ditentukan dengan menganalisis workload, terutama klausa
WHEREatauJOINdalam log kueri yang dianalisis.Di bagian bawah halaman, ada pernyataan buat tabel yang diterjemahkan dengan semua pengoptimalan yang diberikan. Semua pernyataan DDL yang diterjemahkan juga dapat diekstrak dari set data. Pernyataan DDL yang diterjemahkan disimpan dalam tabel
SchemaConversiondi kolomCreateTableDDL.Rekomendasi dalam laporan hanya diberikan untuk tabel yang lebih besar dari 1 GB karena tabel kecil tidak akan mendapatkan manfaat dari pengelompokan dan partisi. Namun, DDL untuk semua tabel (termasuk tabel yang lebih kecil dari 1 GB) tersedia di tabel
SchemaConversion.- Tabel Tanpa Penggunaan
Tabel virtual tentang Tabel Tanpa Penggunaan menampilkan tabel yang menurut penilaian migrasi BigQuery tidak memiliki penggunaan apa pun selama periode log yang dianalisis. Kurangnya penggunaan mungkin menunjukkan bahwa Anda tidak perlu mentransfer tabel tersebut ke BigQuery selama migrasi atau bahwa biaya penyimpanan data di BigQuery bisa lebih rendah (ditagih sebagai Penyimpanan jangka panjang). Sebaiknya validasi daftar tabel yang tidak digunakan karena tabel tersebut dapat memiliki penggunaan di luar periode log, seperti tabel yang hanya digunakan sekali setiap tiga atau enam bulan.
- Tabel Tanpa Penulisan
Tabel virtual tentang Tabel Tanpa Penulisan menampilkan tabel yang menurut penilaian migrasi BigQuery tidak memiliki update apa pun selama periode log yang dianalisis. Kurangnya operasi tulis dapat mengindikasikan di mana Anda dapat menurunkan biaya penyimpanan di BigQuery (ditagih sebagai Penyimpanan jangka panjang).
- BigQuery BI Engine dan Tampilan Terwujud
BigQuery BI Engine dan Tampilan Terwujud memberikan saran pengoptimalan lebih lanjut untuk meningkatkan performa di BigQuery.
Bagian Jalur migrasi berisi tabel virtual berikut:
- Terjemahan SQL
- Tabel virtual Terjemahan SQL mencantumkan jumlah dan detail kueri yang secara otomatis dikonversi oleh penilaian migrasi BigQuery dan tidak memerlukan intervensi manual. Terjemahan SQL Otomatis biasanya mencapai tingkat terjemahan yang tinggi jika metadata diberikan.
- Upaya Offline Terjemahan SQL
- Tabel virtual Upaya Offline Terjemahan SQL mencatat area yang memerlukan intervensi manual, termasuk UDF dan kueri tertentu dengan potensi ambiguitas terjemahan.
- Dukungan Penambahan Tabel Alter
- Tampilan Dukungan Penambahan Tabel Alter menampilkan detail tentang konstruksi SQL Redshift umum yang tidak memiliki padanan langsung di BigQuery.
- Dukungan Perintah Salin
- Tampilan Dukungan Perintah Salin menampilkan detail tentang konstruksi SQL Redshift umum yang tidak memiliki padanan langsung di BigQuery.
- Peringatan SQL
- Tampilan Peringatan SQL mencatat area yang berhasil diterjemahkan, tetapi memerlukan peninjauan.
- Pelanggaran Struktur & Sintaksis Leksikal
- Tampilan Pelanggaran Struktur & Sintaksis Leksikal menampilkan nama kolom, tabel, fungsi, dan prosedur yang melanggar sintaksis BigQuery.
- Kata Kunci yang Dicadangkan untuk BigQuery
- Tabel virtual Kata Kunci yang Dicadangkan untuk BigQuery menampilkan penggunaan kata kunci yang terdeteksi memiliki arti khusus dalam bahasa GoogleSQL, dan tidak dapat digunakan sebagai ID kecuali jika diapit oleh tanda kutip terbalik (
`). - Pengaitan Skema
- Tabel virtual Pengaitan Skema memberikan tabel virtual tingkat tinggi tentang database, skema, dan tabel yang diakses bersama dalam satu kueri. Tabel virtual ini dapat menunjukkan tabel, skema, dan database yang sering dirujuk dan apa yang dapat Anda gunakan untuk perencanaan migrasi.
- Jadwal Pembaruan Tabel
- Tabel virtual Jadwal Pembaruan Tabel menampilkan waktu dan seberapa sering tabel diperbarui untuk membantu Anda merencanakan cara dan waktu memindahkannya.
- Skala Tabel
- Tabel virtual Skala Tabel mencantumkan tabel Anda dengan kolom terbanyak.
- Migrasi Data ke BigQuery
- Tabel virtual Migrasi Data ke BigQuery menguraikan jalur migrasi dengan perkiraan waktu untuk memigrasikan data Anda menggunakan BigQuery Migration Service Data Transfer Service. Untuk mengetahui informasi selengkapnya, lihat Panduan BigQuery Data Transfer Service untuk Redshift.
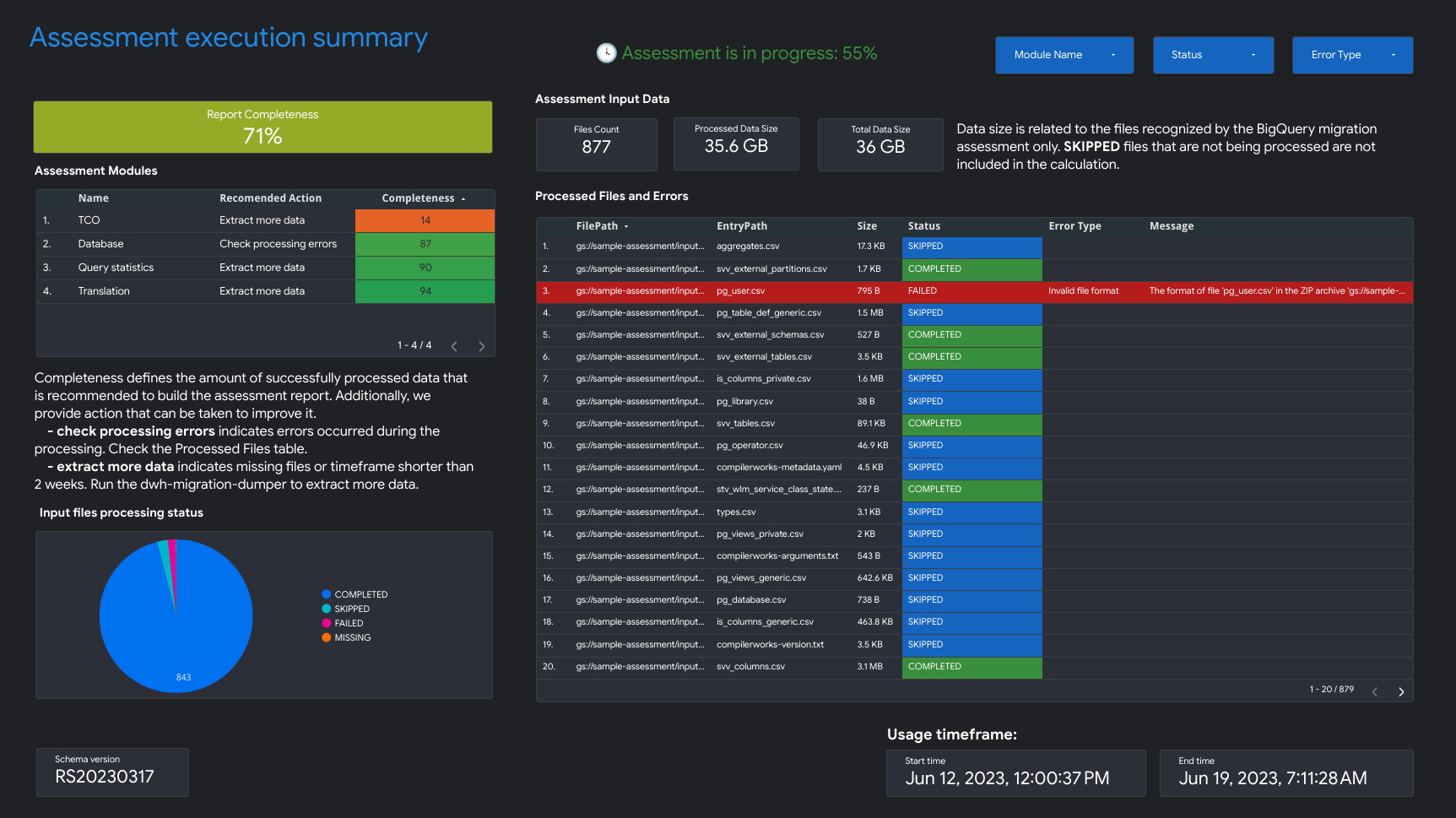
- Ringkasan eksekusi penilaian
Ringkasan eksekusi Penilaian berisi kelengkapan laporan, progres penilaian yang sedang berlangsung, dan status file yang diproses dan error.
Kelengkapan laporan menunjukkan persentase data yang berhasil diproses yang direkomendasikan untuk menampilkan insight yang bermakna dalam laporan penilaian. Jika data untuk bagian tertentu dalam laporan tidak ada, informasi ini akan tercantum dalam tabel Modul Penilaian di bagian indikator Kelengkapan Laporan.
Metrik progres menunjukkan persentase data yang telah diproses sejauh ini beserta perkiraan waktu yang tersisa untuk memproses semua data. Setelah pemrosesan selesai, metrik progres tidak ditampilkan.
Redshift Serverless
- Sorotan Migrasi
- Halaman laporan ini menampilkan ringkasan database Serverless Amazon Redshift yang ada, termasuk ukuran dan jumlah tabel. Selain itu, alat ini memberikan perkiraan tingkat tinggi Nilai Kontrak Tahunan (ACV)—biaya komputasi dan penyimpanan di BigQuery. Tabel virtual Sorotan Migrasi memberikan ringkasan eksekutif terkait tiga bagian laporan.
Bagian Sistem yang Ada memiliki tampilan berikut:
- Database dan Skema
- Memberikan perincian ukuran total penyimpanan dalam GB untuk setiap database, skema, atau tabel.
- Database dan Skema Eksternal
- Memberikan perincian ukuran total penyimpanan dalam GB untuk setiap database, skema, atau tabel eksternal.
- Pemanfaatan Sistem
- Memberikan informasi umum tentang penggunaan sistem historis. Tampilan ini menampilkan penggunaan historis RPU (Unit Pemrosesan Amazon Redshift) dan konsumsi penyimpanan harian. Tampilan ini dapat membantu Anda memahami cadangan kapasitas sistem.
Bagian Status Stabil BigQuery memberikan informasi tentang tampilan data Anda setelah migrasi di BigQuery, termasuk jumlah kueri yang dapat diterjemahkan secara otomatis menggunakan BigQuery Migration Service. Bagian ini juga menampilkan biaya penyimpanan data di BigQuery berdasarkan tingkat penyerapan data tahunan Anda, beserta saran pengoptimalan untuk tabel, penyediaan, dan ruang. Bagian Status Stabil memiliki tampilan berikut:
- Harga Amazon Redshift Serverless versus BigQuery
- Memberikan perbandingan model harga Amazon Redshift Serverless dan BigQuery untuk membantu Anda memahami manfaat dan potensi penghematan biaya setelah Anda bermigrasi ke BigQuery.
- Biaya Komputasi BigQuery (TCO)
- Memungkinkan Anda memperkirakan biaya komputasi di BigQuery. Ada empat input manual dalam kalkulator: Edisi BigQuery, Region, Periode komitmen, dan Baseline. Secara default, kalkulator memberikan komitmen dasar yang optimal dan hemat biaya yang dapat Anda ganti secara manual.
- Total Biaya Kepemilikan
- Memungkinkan Anda memperkirakan Nilai Kontrak Tahunan (ACV)—biaya komputasi dan penyimpanan di BigQuery. Kalkulator ini juga memungkinkan Anda menghitung biaya penyimpanan, yang bervariasi untuk penyimpanan aktif dan penyimpanan jangka panjang, bergantung pada modifikasi tabel selama jangka waktu yang dianalisis. Untuk mengetahui informasi selengkapnya, lihat Harga penyimpanan.
Bagian Lampiran berisi tampilan ini:
- Ringkasan Eksekusi Penilaian
- Memberikan detail eksekusi penilaian termasuk daftar file yang diproses, error, dan kelengkapan laporan. Anda dapat menggunakan halaman ini untuk menyelidiki data yang tidak ada dalam laporan dan untuk lebih memahami kelengkapan laporan.
Snowflake
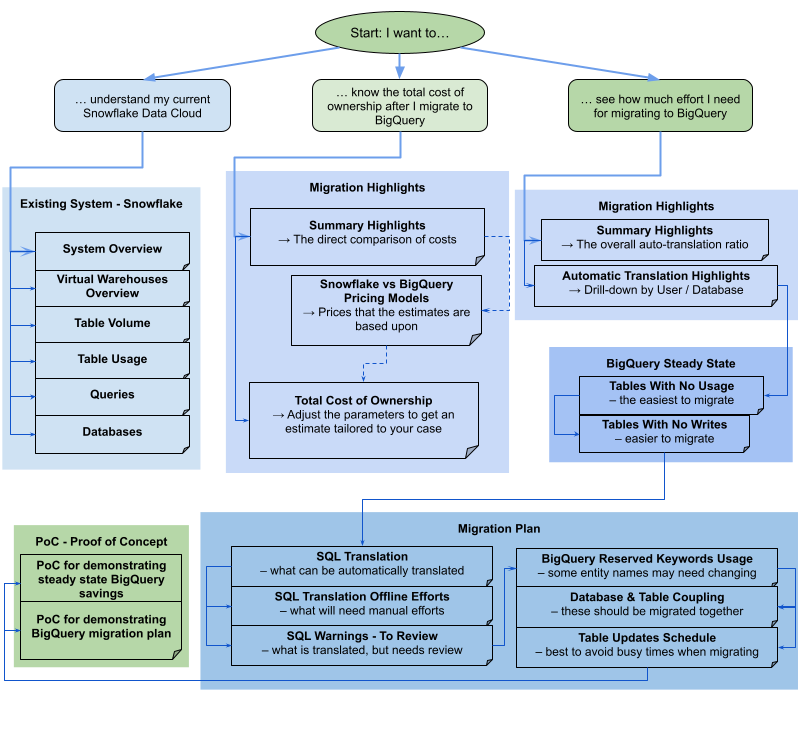
Laporan ini terdiri dari berbagai bagian yang dapat digunakan secara terpisah atau bersama-sama. Diagram berikut mengatur bagian-bagian ini ke dalam tiga sasaran umum pengguna untuk membantu Anda menilai kebutuhan migrasi:
Tampilan Sorotan Migrasi
Bagian Sorotan Migrasi berisi tabel virtual berikut:
- Model Harga Snowflake versus BigQuery
- Daftar harga dengan berbagai tingkat/edisi. Juga mencakup ilustrasi tentang cara penskalaan otomatis BigQuery dapat membantu menghemat lebih banyak biaya dibandingkan dengan Snowflake.
- Total Biaya Kepemilikan
- Tabel interaktif, yang memungkinkan pengguna menentukan: Edisi BigQuery, komitmen, komitmen slot dasar, persentase penyimpanan aktif, dan persentase data yang dimuat atau diubah. Membantu memperkirakan biaya untuk casing kustom dengan lebih baik.
- Sorotan Terjemahan Otomatis
- Rasio terjemahan gabungan, dikelompokkan menurut pengguna atau database, diurutkan secara menaik atau menurun. Juga mencakup pesan error paling umum untuk terjemahan otomatis yang gagal.
Tampilan Sistem yang ada
Bagian Sistem yang Ada berisi tabel virtual berikut:
- Ringkasan Sistem
- Tabel virtual Ringkasan Sistem menyediakan metrik volume tingkat tinggi dari komponen utama dalam sistem yang ada selama jangka waktu tertentu. Linimasa yang dievaluasi bergantung pada log yang dianalisis oleh penilaian migrasi BigQuery. Tabel virtual ini memberi Anda insight singkat tentang pemakaian data warehouse sumber, yang dapat Anda gunakan untuk perencanaan migrasi.
- Ringkasan Warehouse Virtual
- Menampilkan biaya Snowflake menurut warehouse, serta penskalaan ulang berbasis node selama periode tersebut.
- Volume Tabel
- Tabel virtual Volume Tabel menyediakan statistik tentang tabel dan database terbesar yang ditemukan oleh penilaian migrasi BigQuery. Karena tabel besar mungkin memerlukan waktu lebih lama untuk diekstrak dari sistem data warehouse sumber, tabel virtual ini dapat membantu dalam perencanaan dan pengurutan migrasi.
- Penggunaan Tabel
- Tabel virtual Penggunaan Tabel menyediakan statistik tentang tabel mana yang banyak digunakan dalam sistem data warehouse sumber. Tabel yang banyak digunakan dapat membantu Anda memahami tabel mana yang mungkin memiliki banyak dependensi dan memerlukan perencanaan tambahan selama proses migrasi.
- Kueri
- Tabel virtual Kueri memberikan perincian jenis pernyataan SQL yang dijalankan dan statistik penggunaannya. Anda dapat menggunakan histogram Jenis dan Waktu Kueri untuk mengidentifikasi periode penggunaan sistem yang rendah dan waktu optimal untuk mentransfer data. Anda juga dapat menggunakan tampilan ini untuk mengidentifikasi kueri yang sering dieksekusi dan pengguna yang memanggil eksekusi tersebut.
- Database
- Tabel virtual Database menyediakan metrik terkait ukuran, tabel, tabel virtual, dan prosedur yang ditentukan dalam sistem data warehouse sumber. Tampilan ini memberikan insight tentang volume objek yang perlu Anda migrasikan.
Tampilan status stabil BigQuery
Bagian status stabil BigQuery berisi tabel virtual berikut:
- Tabel Tanpa Penggunaan
- Tabel virtual tentang Tabel Tanpa Penggunaan menampilkan tabel-tabel yang menurut penilaian migrasi BigQuery tidak memiliki penggunaan apa pun selama periode log yang dianalisis. Hal ini dapat menunjukkan tabel mana yang mungkin tidak perlu ditransfer ke BigQuery selama migrasi atau bahwa biaya penyimpanan data di BigQuery bisa lebih rendah. Anda harus memvalidasi daftar tabel yang tidak digunakan karena tabel tersebut dapat memiliki penggunaan di luar periode log yang dianalisis, seperti tabel yang hanya digunakan sekali per kuartal atau semester.
- Tabel Tanpa Penulisan
- Tabel virtual tentang Tabel Tanpa Penulisan menampilkan tabel-tabel yang menurut penilaian migrasi BigQuery tidak memiliki update apa pun selama periode log yang dianalisis. Hal ini dapat menunjukkan bahwa biaya penyimpanan data di BigQuery bisa lebih rendah.
Tampilan Rencana Migrasi
Bagian Rencana Migrasi laporan berisi tabel virtual berikut:
- Terjemahan SQL
- Tabel virtual Terjemahan SQL mencantumkan jumlah dan detail kueri yang secara otomatis dikonversi oleh penilaian migrasi BigQuery dan tidak memerlukan intervensi manual. Terjemahan SQL Otomatis biasanya mencapai tingkat terjemahan yang tinggi jika metadata diberikan. Tabel virtual ini bersifat interaktif dan memungkinkan analisis kueri umum serta bagaimana kueri tersebut diterjemahkan.
- Upaya Offline Terjemahan SQL
- Tabel virtual Upaya Offline merekam area yang memerlukan intervensi manual, termasuk UDF spesifik serta potensi pelanggaran struktur leksikal dan sintaksis untuk tabel atau kolom.
- Peringatan SQL - Untuk Ditinjau
- Tampilan Peringatan untuk Ditinjau mencatat area yang sebagian besar sudah diterjemahkan, tetapi memerlukan pemeriksaan manual.
- Kata Kunci yang Dicadangkan untuk BigQuery
- Tabel virtual Kata Kunci yang Dicadangkan untuk BigQuery menampilkan penggunaan kata kunci yang terdeteksi memiliki arti khusus dalam bahasa GoogleSQL, dan tidak dapat digunakan sebagai ID kecuali jika diapit oleh tanda kutip terbalik (
`). - Pengaitan Database dan Tabel
- Tabel virtual Pengaitan Database memberikan tabel virtual tingkat tinggi tentang database dan tabel yang diakses bersama dalam satu kueri. Tabel virtual ini dapat menunjukkan tabel dan database yang sering dirujuk dan apa yang dapat digunakan untuk perencanaan migrasi.
- Jadwal Pembaruan Tabel
- Tabel virtual Jadwal Pembaruan Tabel menampilkan waktu dan seberapa sering tabel diperbarui untuk membantu Anda merencanakan cara dan waktu memindahkannya.
Penayangan Bukti Konsep
Bagian PoC (bukti konsep) berisi tabel virtual berikut:
- PoC untuk menunjukkan penghematan BigQuery dalam keadaan stabil
- Mencakup kueri yang paling sering, kueri yang membaca data paling banyak, kueri paling lambat, dan tabel yang terpengaruh oleh kueri yang disebutkan di atas.
- PoC untuk mendemonstrasikan rencana migrasi BigQuery
- Menunjukkan cara BigQuery menerjemahkan kueri yang paling kompleks dan tabel yang terpengaruh.
Oracle
Untuk meminta masukan atau dukungan terkait fitur ini, kirim email ke bq-edw-migration-support@google.com.
Sorotan Migrasi
Bagian Sorotan Migrasi berisi tabel virtual berikut:
- Sistem yang ada: snapshot sistem dan penggunaan Oracle yang ada, termasuk jumlah database, skema, tabel, dan ukuran total dalam GB. Laporan ini juga memberikan ringkasan klasifikasi beban kerja untuk setiap database guna membantu Anda memutuskan apakah BigQuery adalah target migrasi yang tepat.
- Kompatibilitas: memberikan informasi tentang upaya migrasi itu sendiri. Untuk setiap database yang dianalisis, panel ini menampilkan perkiraan waktu migrasi dan jumlah objek database yang dapat dimigrasikan secara otomatis dengan alat yang disediakan Google.
- Status stabil BigQuery: berisi informasi tentang tampilan data Anda setelah migrasi di BigQuery, termasuk biaya penyimpanan data Anda di BigQuery berdasarkan rasio penyerapan data tahunan dan estimasi biaya komputasi. Selain itu, alat ini memberikan insight tentang tabel yang kurang dimanfaatkan.
Sistem yang Ada
Bagian Sistem yang Ada berisi tabel virtual berikut:
- Karakteristik Workload: menjelaskan jenis workload untuk setiap database berdasarkan metrik performa yang dianalisis. Setiap database diklasifikasikan sebagai OLAP, Campuran, atau OLTP. Informasi ini dapat membantu Anda membuat keputusan tentang database mana yang dapat dimigrasikan ke BigQuery.
- Database dan Skema: memberikan perincian ukuran penyimpanan total dalam GB untuk setiap database, skema, atau tabel. Selain itu, Anda dapat menggunakan tampilan ini untuk mengidentifikasi tampilan terwujud dan tabel eksternal.
- Fitur dan Link Database: menampilkan daftar fitur Oracle yang digunakan dalam database Anda, beserta fitur atau layanan BigQuery yang setara yang dapat digunakan setelah migrasi. Selain itu, Anda dapat menjelajahi Link Database untuk lebih memahami koneksi antar-database.
- Koneksi Database: memberikan insight tentang sesi database yang dimulai oleh pengguna atau aplikasi. Menganalisis data ini dapat membantu Anda mengidentifikasi aplikasi eksternal yang mungkin memerlukan upaya tambahan selama migrasi.
- Jenis Kueri: memberikan perincian jenis pernyataan SQL yang dijalankan dan statistik penggunaannya. Anda dapat menggunakan histogram per jam dari Eksekusi Kueri atau Waktu CPU Kueri untuk mengidentifikasi periode penggunaan sistem yang rendah dan waktu optimal untuk mentransfer data.
- Kode Sumber PL/SQL: memberikan insight tentang objek PL/SQL, seperti fungsi atau prosedur, dan ukurannya untuk setiap database dan skema. Selain itu, histogram eksekusi per jam dapat digunakan untuk mengidentifikasi jam sibuk dengan eksekusi PL/SQL terbanyak.
- Penggunaan Sistem: memberikan informasi umum tentang penggunaan sistem historis. Tampilan ini menampilkan penggunaan CPU per jam dan konsumsi penyimpanan harian. Tampilan ini dapat membantu memahami cadangan kapasitas sistem.
Status Stabil BigQuery
Bagian Status Stabil BigQuery berisi tampilan berikut:
- Harga Exadata versus BigQuery: memberikan perbandingan umum model harga Exadata dan BigQuery untuk membantu Anda memahami manfaat dan potensi penghematan biaya setelah migrasi ke BigQuery.
- Baca/Tulis Database BigQuery: memberikan insight tentang operasi disk fisik database. Menganalisis data ini dapat membantu Anda menemukan waktu terbaik untuk melakukan migrasi data dari Oracle ke BigQuery.
- Biaya Komputasi BigQuery: memungkinkan Anda memperkirakan biaya komputasi di BigQuery. Ada empat input manual dalam kalkulator: Edisi BigQuery, Region, Periode komitmen, dan Dasar. Secara default, kalkulator memberikan komitmen dasar yang optimal dan hemat biaya yang dapat Anda ganti secara manual. Nilai Jam Slot Penskalaan Otomatis Tahunan memberikan jumlah jam slot yang digunakan di luar komitmen. Nilai ini dihitung menggunakan pemanfaatan sistem. Penjelasan visual tentang hubungan antara garis dasar, penskalaan otomatis, dan pemanfaatan disediakan di bagian akhir halaman. Setiap estimasi menunjukkan kemungkinan jumlah dan rentang estimasi.
- Total Biaya Kepemilikan (TCO): memungkinkan Anda memperkirakan Nilai Kontrak Tahunan (ACV) - biaya komputasi dan penyimpanan di BigQuery. Kalkulator ini juga memungkinkan Anda menghitung biaya penyimpanan. Kalkulator ini juga memungkinkan Anda menghitung biaya penyimpanan, yang bervariasi untuk penyimpanan aktif dan penyimpanan jangka panjang, bergantung pada modifikasi tabel selama jangka waktu yang dianalisis. Untuk mengetahui informasi selengkapnya tentang harga penyimpanan, lihat Harga penyimpanan.
- Tabel yang Kurang Dimanfaatkan: memberikan informasi tentang tabel hanya baca dan yang tidak digunakan berdasarkan metrik penggunaan dari periode waktu yang dianalisis. Kurangnya penggunaan mungkin menunjukkan bahwa Anda tidak perlu mentransfer tabel ke BigQuery selama migrasi atau bahwa biaya penyimpanan data di BigQuery bisa lebih rendah (ditagih sebagai penyimpanan jangka panjang). Sebaiknya validasi daftar tabel yang tidak digunakan jika tabel tersebut memiliki penggunaan di luar periode waktu yang dianalisis.
Petunjuk Migrasi
Bagian Petunjuk Migrasi berisi tabel virtual berikut:
- Kompatibilitas Objek Database: memberikan ringkasan kompatibilitas objek database dengan BigQuery, termasuk jumlah objek yang dapat dimigrasikan secara otomatis dengan alat yang disediakan Google atau memerlukan tindakan manual. Informasi ini ditampilkan untuk setiap database, skema, dan jenis objek database.
- Upaya Migrasi Objek Database: menampilkan perkiraan upaya migrasi dalam jam untuk setiap database, skema, atau jenis objek database. Selain itu, bagian ini menunjukkan persentase objek kecil, sedang, dan besar berdasarkan upaya migrasi.
- Upaya Migrasi Skema Database: memberikan daftar semua jenis objek database yang terdeteksi, jumlahnya, kompatibilitas dengan BigQuery, dan perkiraan upaya migrasi dalam jam.
- Detail Upaya Migrasi Skema Database: memberikan insight yang lebih mendalam tentang upaya migrasi skema database, termasuk informasi untuk setiap objek tunggal.
Penayangan Bukti Konsep
Bagian Tampilan Bukti Konsep berisi tampilan berikut:
- Migrasi bukti konsep: menampilkan daftar database yang disarankan dengan upaya migrasi terendah yang merupakan kandidat yang baik untuk migrasi awal. Selain itu, laporan ini menunjukkan kueri teratas yang dapat membantu mendemonstrasikan penghematan waktu dan biaya, serta nilai BigQuery menggunakan bukti konsep.
Lampiran
Bagian Lampiran berisi tabel virtual berikut:
- Ringkasan Eksekusi Penilaian: memberikan detail eksekusi penilaian, termasuk daftar file yang diproses, error, dan kelengkapan laporan. Anda dapat menggunakan halaman ini untuk menyelidiki data yang tidak ada dalam laporan dan lebih memahami kelengkapan laporan secara keseluruhan.
Apache Hive
Laporan yang terdiri dari narasi tiga bagian ini diawali dengan halaman highlight ringkasan yang mencakup bagian berikut:
Sistem yang Ada - Apache Hive. Bagian ini terdiri dari snapshot sistem dan penggunaan Apache Hive yang ada, termasuk jumlah database, tabel, ukuran totalnya dalam GB, dan jumlah log kueri yang diproses. Bagian ini juga mencantumkan database berdasarkan ukuran dan menunjukkan potensi pemanfaatan resource yang kurang optimal (tabel tanpa penulisan atau beberapa pembacaan) dan penyediaan. Detail bagian ini mencakup hal-hal berikut:
- Komputasi dan kueri
- Pemakaian CPU:
- Kueri berdasarkan jam dan hari dengan pemakaian CPU
- Kueri menurut jenis (baca/tulis)
- Antrean dan aplikasi
- Overlay penggunaan CPU per jam dengan performa kueri per jam rata-rata dan performa aplikasi per jam rata-rata
- Histogram kueri menurut jenis dan durasi kueri
- Halaman mengantre dan menunggu
- Tampilan detail antrean (antrean, pengguna, kueri unik, pelaporan versus perincian ETL, menurut metrik)
- Pemakaian CPU:
- Ringkasan penyimpanan
- Database menurut volume, tabel virtual, dan rasio akses
- Tabel dengan rasio akses berdasarkan pengguna, kueri, penulisan, dan pembuatan tabel sementara
- Antrean dan aplikasi: Rasio akses dan alamat IP klien
- Komputasi dan kueri
Status Stabil BigQuery. Bagian ini menunjukkan tampilan sistem di BigQuery setelah migrasi. Bagian ini mencakup saran untuk mengoptimalkan workload di BigQuery (dan menghindari pemborosan). Detail bagian ini meliputi hal-hal berikut:
- Tabel yang diidentifikasi sebagai kandidat untuk tampilan terwujud.
- Mengelompokkan dan mempartisi kandidat berdasarkan metadata dan penggunaan.
- Kueri berlatensi rendah yang diidentifikasi sebagai kandidat untuk BigQuery BI Engine.
- Tabel tanpa penggunaan baca atau tulis.
- Tabel berpartisi dengan kemiringan data.
Rencana Migrasi. Bagian ini memberikan informasi tentang upaya migrasi itu sendiri. Misalnya, beralih dari sistem yang ada ke status stabil BigQuery. Bagian ini berisi target penyimpanan yang diidentifikasi untuk setiap tabel, tabel yang diidentifikasi sebagai penting untuk migrasi, dan jumlah kueri yang diterjemahkan secara otomatis. Detail bagian ini meliputi hal-hal berikut:
- Tabel virtual mendetail dengan kueri yang diterjemahkan secara otomatis
- Jumlah total kueri dengan kemampuan untuk memfilter menurut pengguna, aplikasi, tabel yang terpengaruh, tabel yang dikueri, dan jenis kueri.
- Bucket kueri dengan pola serupa dikelompokkan, sehingga pengguna dapat melihat filosofi terjemahan berdasarkan jenis kueri.
- Kueri yang memerlukan intervensi manusia
- Kueri dengan pelanggaran struktur leksikal BigQuery
- Fungsi dan prosedur yang ditentukan pengguna
- Kata kunci yang dicadangkan untuk BigQuery
- Kueri yang memerlukan peninjauan
- Jadwal tabel berdasarkan operasi tulis dan baca (untuk mengelompokkannya dalam rangka pemindahan)
- Target penyimpanan yang diidentifikasi untuk tabel eksternal dan terkelola
- Tabel virtual mendetail dengan kueri yang diterjemahkan secara otomatis
Bagian Sistem yang Ada - Hive berisi tampilan berikut:
- Ringkasan Sistem
- Tampilan ini menyediakan metrik volume tingkat tinggi dari komponen utama dalam sistem yang ada selama jangka waktu tertentu. Linimasa yang dievaluasi bergantung pada log yang dianalisis oleh penilaian migrasi BigQuery. Tabel virtual ini memberi Anda insight singkat tentang pemakaian data warehouse sumber, yang dapat Anda gunakan untuk perencanaan migrasi.
- Volume Tabel
- Tampilan ini memberikan statistik tentang tabel dan database terbesar yang ditemukan oleh penilaian migrasi BigQuery. Karena tabel besar mungkin memerlukan waktu lebih lama untuk diekstrak dari sistem data warehouse sumber, tabel virtual ini dapat membantu dalam perencanaan dan pengurutan migrasi.
- Penggunaan Tabel
- Tabel virtual ini menyediakan statistik tentang tabel mana yang banyak digunakan dalam sistem data warehouse sumber. Tabel yang banyak digunakan dapat membantu Anda memahami tabel mana yang mungkin memiliki banyak dependensi dan memerlukan perencanaan tambahan selama proses migrasi.
- Penggunaan Antrean
- Tampilan ini memberikan statistik tentang penggunaan antrean YARN yang ditemukan selama pemrosesan log. Dengan tampilan ini, pengguna dapat memahami penggunaan antrean dan aplikasi tertentu dari waktu ke waktu serta dampaknya terhadap penggunaan resource. Tampilan ini juga membantu mengidentifikasi dan memprioritaskan beban kerja untuk migrasi. Selama migrasi, penting untuk memvisualisasikan penyerapan dan pemakaian data untuk mendapatkan pemahaman yang lebih baik tentang dependensi data warehouse, serta menganalisis dampak pemindahan berbagai aplikasi dependen secara bersamaan. Tabel alamat IP dapat berguna untuk menemukan aplikasi yang tepat menggunakan data warehouse melalui koneksi JDBC.
- Metrik Antrean
- Tampilan ini memberikan perincian berbagai metrik di antrean YARN yang ditemukan selama pemrosesan log. Tampilan ini memungkinkan pengguna memahami pola penggunaan dalam antrean tertentu dan dampaknya terhadap migrasi. Anda juga dapat menggunakan tampilan ini untuk mengidentifikasi koneksi antara tabel yang diakses dalam kueri dan antrean tempat kueri dijalankan.
- Mengantre dan Menunggu
- Tabel virtual ini memberikan insight tentang waktu antrean kueri di data warehouse sumber. Waktu antrean menunjukkan penurunan performa karena kurangnya penyediaan, dan penyediaan tambahan memerlukan peningkatan biaya hardware dan pemeliharaan.
- Kueri
- Tampilan ini memberikan perincian jenis pernyataan SQL yang dijalankan dan statistik penggunaannya. Anda dapat menggunakan histogram Jenis dan Waktu Kueri untuk mengidentifikasi periode penggunaan sistem yang rendah dan waktu optimal untuk mentransfer data. Anda juga dapat menggunakan tampilan ini untuk mengidentifikasi mesin eksekusi Hive yang paling banyak digunakan dan kueri yang sering dieksekusi beserta detail pengguna.
- Database
- Tabel virtual ini menyediakan metrik terkait ukuran, tabel, tabel virtual, dan prosedur yang ditentukan dalam sistem data warehouse sumber. Tabel virtual ini dapat memberikan insight tentang volume objek yang perlu Anda migrasikan.
- Pengaitan Database & Tabel
- Tabel virtual ini memberikan tabel virtual tingkat tinggi tentang database dan tabel yang diakses bersama dalam satu kueri. Tabel virtual ini dapat menunjukkan tabel dan database yang sering dirujuk dan apa yang dapat Anda gunakan untuk perencanaan migrasi.
Bagian Status Stabil BigQuery berisi tampilan berikut:
- Tabel Tanpa Penggunaan
- Tabel virtual tentang Tabel Tanpa Penggunaan menampilkan tabel-tabel yang menurut penilaian migrasi BigQuery tidak memiliki penggunaan apa pun selama periode log yang dianalisis. Kurangnya penggunaan mungkin menunjukkan bahwa Anda tidak perlu mentransfer tabel tersebut ke BigQuery selama migrasi atau bahwa biaya penyimpanan data di BigQuery bisa lebih rendah. Anda harus memvalidasi daftar tabel yang tidak digunakan karena tabel tersebut bisa jadi memiliki penggunaan di luar periode log, misalnya tabel yang hanya digunakan sekali setiap tiga atau enam bulan.
- Tabel Tanpa Penulisan
- Tabel virtual tentang Tabel Tanpa Penulisan menampilkan tabel-tabel yang menurut penilaian migrasi BigQuery tidak memiliki update apa pun selama periode log yang dianalisis. Kurangnya operasi tulis dapat mengindikasikan di mana Anda dapat menurunkan biaya penyimpanan di BigQuery.
- Rekomendasi Pengelompokan dan Partisi
Tabel virtual ini menampilkan tabel-tabel yang akan mendapatkan manfaat dari partisi, pengelompokan, atau keduanya.
Saran Metadata didapatkan dengan menganalisis skema data warehouse sumber (seperti Partisi dan Kunci Utama dalam tabel sumber) dan menemukan BigQuery terdekat yang setara untuk mencapai karakteristik pengoptimalan yang serupa.
Saran Workload dicapai dengan menganalisis log kueri sumber. Rekomendasi ditentukan dengan menganalisis workload, terutama klausa
WHEREatauJOINdalam log kueri yang dianalisis.- Partisi dikonversi menjadi Cluster
Tampilan ini menampilkan tabel yang memiliki lebih dari 10.000 partisi, berdasarkan definisi batasan partisinya. Tabel-tabel tersebut cenderung menjadi kandidat yang baik untuk pengelompokan BigQuery, yang memungkinkan partisi tabel terperinci.
- Partisi miring
Tampilan Partisi Miring menampilkan tabel yang didasarkan pada analisis metadata dan memiliki kemiringan data pada satu atau beberapa partisi. Tabel ini merupakan kandidat yang baik untuk perubahan skema, karena kueri pada partisi miring mungkin tidak berperforma baik.
- BI Engine dan Tampilan Terwujud
Tabel virtual Kueri Berlatensi Rendah dan Tampilan Terwujud menampilkan distribusi runtime kueri berdasarkan data log yang dianalisis dan saran pengoptimalan lebih lanjut untuk meningkatkan performa di BigQuery. Jika diagram distribusi durasi kueri menampilkan sejumlah besar kueri dengan runtime kurang dari 1 detik, pertimbangkan untuk mengaktifkan BI Engine guna mempercepat BI dan workload berlatensi rendah lainnya.
Bagian Rencana Migrasi laporan berisi tabel virtual berikut:
- Terjemahan SQL
- Tabel virtual Terjemahan SQL mencantumkan jumlah dan detail kueri yang secara otomatis dikonversi oleh penilaian migrasi BigQuery dan tidak memerlukan intervensi manual. Terjemahan SQL Otomatis biasanya mencapai tingkat terjemahan yang tinggi jika metadata diberikan. Tabel virtual ini bersifat interaktif dan memungkinkan analisis kueri umum serta bagaimana kueri tersebut diterjemahkan.
- Upaya Offline Terjemahan SQL
- Tabel virtual Upaya Offline merekam area yang memerlukan intervensi manual, termasuk UDF spesifik serta potensi pelanggaran struktur leksikal dan sintaksis untuk tabel atau kolom.
- Peringatan SQL
- Tampilan Peringatan SQL mencatat area yang berhasil diterjemahkan, tetapi memerlukan peninjauan.
- Kata Kunci yang Dicadangkan untuk BigQuery
- Tabel virtual Kata Kunci yang Dicadangkan untuk BigQuery menampilkan penggunaan kata kunci yang terdeteksi memiliki arti khusus dalam bahasa GoogleSQL.
Kata kunci ini tidak dapat digunakan sebagai ID kecuali jika diapit oleh karakter kutip terbalik (
`). - Jadwal Pembaruan Tabel
- Tabel virtual Jadwal Pembaruan Tabel menampilkan waktu dan seberapa sering tabel diperbarui untuk membantu Anda merencanakan cara dan waktu memindahkannya.
- Tabel Eksternal BigLake
- Tampilan Tabel Eksternal BigLake menguraikan tabel yang diidentifikasi sebagai target migrasi ke BigLake, bukan BigQuery.
Bagian Lampiran laporan berisi tabel virtual berikut:
- Analisis Upaya Offline Terjemahan SQL Mendetail
- Tampilan Analisis Upaya Offline Mendetail memberikan insight tambahan tentang area SQL yang memerlukan intervensi manual.
- Analisis Peringatan SQL Terperinci
- Tampilan Analisis Peringatan Mendetail memberikan insight tambahan tentang area SQL yang berhasil diterjemahkan, tetapi memerlukan peninjauan.
Bagikan laporannya
Laporan Looker Studio adalah dasbor frontend untuk penilaian migrasi. Hal ini bergantung pada izin akses set data pokok. Untuk membagikan laporan, penerima harus memiliki akses ke laporan Looker Studio itu sendiri dan set data BigQuery yang berisi hasil penilaian.
Saat membuka laporan dari konsol Google Cloud , Anda akan melihat laporan dalam mode pratinjau. Untuk membuat dan membagikan laporan kepada pengguna lain, lakukan langkah-langkah berikut:
- Klik Edit and share. Looker Studio akan meminta Anda untuk melampirkan konektor Looker Studio yang baru dibuat ke laporan baru.
- Klik Add to report. Laporan menerima ID laporan individual, yang dapat Anda gunakan untuk mengakses laporan.
- Untuk membagikan laporan Looker Studio kepada pengguna lain, ikuti langkah-langkah yang diberikan dalam artikel Membagikan laporan kepada audiens dan editor.
- Beri pengguna izin untuk melihat set data BigQuery yang digunakan untuk menjalankan tugas penilaian. Untuk mengetahui informasi selengkapnya, lihat Memberikan akses ke set data.
Membuat kueri tabel output penilaian migrasi
Meskipun laporan Looker Studio adalah cara paling mudah untuk melihat hasil penilaian, Anda juga dapat melihat dan mengkueri data pokok dalam set data BigQuery.
Contoh kueri
Contoh berikut mendapatkan jumlah total kueri unik, jumlah kueri yang gagal diterjemahkan, dan persentase kueri unik yang gagal diterjemahkan.
SELECT QueryCount.v AS QueryCount, ErrorCount.v as ErrorCount, (ErrorCount.v * 100) / QueryCount.v AS FailurePercentage FROM ( SELECT COUNT(*) AS v FROM `your_project.your_dataset.TranslationErrors` WHERE Severity = "ERROR" ) AS ErrorCount, ( SELECT COUNT(DISTINCT(QueryHash)) AS v FROM `your_project.your_dataset.Queries` ) AS QueryCount;
Membagikan set data Anda kepada pengguna di project lain
Setelah memeriksa set data, jika Anda ingin membagikannya kepada pengguna yang tidak ada di project Anda, Anda dapat melakukannya dengan menggunakan alur kerja penayang berbagi BigQuery (sebelumnya Analytics Hub).
Di konsol Google Cloud , buka halaman BigQuery.
Klik set data untuk melihat detailnya.
Klik Berbagi > Publikasikan sebagai listingan.
Dalam dialog yang terbuka, buat listingan seperti yang diminta.
Jika Anda sudah memiliki pertukaran data, lewati langkah 5.
Buat pertukaran data dan tetapkan izin. Untuk mengizinkan pengguna melihat listingan Anda di bursa ini, tambahkan pengguna tersebut ke daftar Pelanggan.
Masukkan detail listingan.
Nama tampilan adalah nama listingan ini dan wajib diisi; kolom lainnya bersifat opsional.
Klik Publikasikan.
Listingan pribadi dibuat.
Untuk listingan Anda, pilih Tindakan lainnya di bagian Tindakan.
Klik Salin link berbagi.
Anda dapat membagikan link kepada pengguna yang memiliki akses langganan ke bursa atau listingan Anda.
Schemata tabel penilaian
Untuk melihat tabel dan schemata-nya yang ditulis oleh penilaian migrasi BigQuery ke BigQuery, pilih data warehouse Anda:
Teradata
AllRIChildren
Tabel ini memberikan informasi integritas referensial dari turunan tabel.
| Kolom | Jenis | Deskripsi |
|---|---|---|
IndexId |
INTEGER |
Nomor indeks referensi. |
IndexName |
STRING |
Nama indeks. |
ChildDB |
STRING |
Nama database yang mereferensikan, dikonversi menjadi huruf kecil. |
ChildDBOriginal |
STRING |
Nama database yang mereferensikan dengan huruf tidak diubah |
ChildTable |
STRING |
Nama tabel yang mereferensikan, dikonversi menjadi huruf kecil. |
ChildTableOriginal |
STRING |
Nama tabel yang mereferensikan dengan huruf yang dipertahankan. |
ChildKeyColumn |
STRING |
Nama kolom dalam kunci yang mereferensikan, dikonversi menjadi huruf kecil. |
ChildKeyColumnOriginal |
STRING |
Nama kolom dalam kunci yang mereferensikan dengan huruf tidak diubah. |
ParentDB |
STRING |
Nama database yang direferensikan, dikonversi menjadi huruf kecil. |
ParentDBOriginal |
STRING |
Nama database yang direferensikan dengan huruf tidak diubah. |
ParentTable |
STRING |
Nama tabel yang direferensikan, dikonversi menjadi huruf kecil. |
ParentTableOriginal |
STRING |
Nama tabel yang direferensikan dengan huruf tidak diubah. |
ParentKeyColumn |
STRING |
Nama kolom dalam kunci yang direferensikan, dikonversi menjadi huruf kecil. |
ParentKeyColumnOriginal |
STRING |
Nama kolom dalam kunci yang direferensikan dengan huruf tidak diubah. |
AllRIParents
Tabel ini memberikan informasi integritas referensial dari induk tabel.
| Kolom | Jenis | Deskripsi |
|---|---|---|
IndexId |
INTEGER |
Nomor indeks referensi. |
IndexName |
STRING |
Nama indeks. |
ChildDB |
STRING |
Nama database yang mereferensikan, dikonversi menjadi huruf kecil. |
ChildDBOriginal |
STRING |
Nama database yang mereferensikan dengan huruf tidak diubah |
ChildTable |
STRING |
Nama tabel yang mereferensikan, dikonversi menjadi huruf kecil. |
ChildTableOriginal |
STRING |
Nama tabel yang mereferensikan dengan huruf yang dipertahankan. |
ChildKeyColumn |
STRING |
Nama kolom dalam kunci yang mereferensikan, dikonversi menjadi huruf kecil. |
ChildKeyColumnOriginal |
STRING |
Nama kolom dalam kunci yang mereferensikan dengan huruf tidak diubah. |
ParentDB |
STRING |
Nama database yang direferensikan, dikonversi menjadi huruf kecil. |
ParentDBOriginal |
STRING |
Nama database yang direferensikan dengan huruf tidak diubah. |
ParentTable |
STRING |
Nama tabel yang direferensikan, dikonversi menjadi huruf kecil. |
ParentTableOriginal |
STRING |
Nama tabel yang direferensikan dengan huruf tidak diubah. |
ParentKeyColumn |
STRING |
Nama kolom dalam kunci yang direferensikan, dikonversi menjadi huruf kecil. |
ParentKeyColumnOriginal |
STRING |
Nama kolom dalam kunci yang direferensikan dengan huruf tidak diubah. |
Columns
Tabel ini memberikan informasi tentang kolom.
| Kolom | Jenis | Deskripsi |
|---|---|---|
DatabaseName |
STRING |
Nama database, dikonversi menjadi huruf kecil. |
DatabaseNameOriginal |
STRING |
Nama database dengan huruf tidak diubah. |
TableName |
STRING |
Nama tabel, dikonversi menjadi huruf kecil. |
TableNameOriginal |
STRING |
Nama tabel dengan huruf tidak diubah. |
ColumnName |
STRING |
Nama kolom, dikonversi menjadi huruf kecil. |
ColumnNameOriginal |
STRING |
Nama kolom dengan huruf tidak diubah. |
ColumnType |
STRING |
Jenis kolom BigQuery, seperti STRING. |
OriginalColumnType |
STRING |
Jenis kolom asli, seperti VARCHAR. |
ColumnLength |
INTEGER |
Jumlah maksimal byte kolom, misalnya 30 untuk VARCHAR(30). |
DefaultValue |
STRING |
Nilai default, jika ada. |
Nullable |
BOOLEAN |
Apakah kolom nullable. |
DiskSpace
Tabel ini memberikan informasi tentang penggunaan diskspace untuk setiap database.
| Kolom | Jenis | Deskripsi |
|---|---|---|
DatabaseName |
STRING |
Nama database, dikonversi menjadi huruf kecil. |
DatabaseNameOriginal |
STRING |
Nama database dengan huruf tidak diubah. |
MaxPerm |
INTEGER |
Jumlah byte maksimum yang dialokasikan ke ruang permanen. |
MaxSpool |
INTEGER |
Jumlah byte maksimum yang dialokasikan ke ruang spool. |
MaxTemp |
INTEGER |
Jumlah byte maksimum yang dialokasikan ke ruang sementara. |
CurrentPerm |
INTEGER |
Jumlah byte yang dialokasikan ke ruang permanen. |
CurrentSpool |
INTEGER |
Jumlah byte yang dialokasikan ke ruang spool. |
CurrentTemp |
INTEGER |
Jumlah byte yang dialokasikan ke ruang sementara. |
PeakPerm |
INTEGER |
Jumlah maksimum byte yang digunakan sejak reset terakhir untuk ruang permanen. |
PeakSpool |
INTEGER |
Jumlah maksimum byte yang digunakan sejak reset terakhir untuk ruang spool. |
PeakPersistentSpool |
INTEGER |
Jumlah maksimum byte yang digunakan sejak reset terakhir untuk ruang persisten. |
PeakTemp |
INTEGER |
Jumlah maksimum byte yang digunakan sejak reset terakhir untuk ruang sementara. |
MaxProfileSpool |
INTEGER |
Batas ruang spool untuk pengguna. |
MaxProfileTemp |
INTEGER |
Batas ruang sementara bagi pengguna. |
AllocatedPerm |
INTEGER |
Alokasi ruang permanen saat ini. |
AllocatedSpool |
INTEGER |
Alokasi ruang spool saat ini. |
AllocatedTemp |
INTEGER |
Alokasi ruang sementara saat ini. |
Functions
Tabel ini memberikan informasi tentang fungsi.
| Kolom | Jenis | Deskripsi |
|---|---|---|
DatabaseName |
STRING |
Nama database, dikonversi menjadi huruf kecil. |
DatabaseNameOriginal |
STRING |
Nama database dengan huruf tidak diubah. |
FunctionName |
STRING |
Nama fungsi. |
LanguageName |
STRING |
Nama bahasa. |
Indices
Tabel ini memberikan informasi tentang indeks.
| Kolom | Jenis | Deskripsi |
|---|---|---|
DatabaseName |
STRING |
Nama database, dikonversi menjadi huruf kecil. |
DatabaseNameOriginal |
STRING |
Nama database dengan huruf tidak diubah. |
TableName |
STRING |
Nama tabel, dikonversi menjadi huruf kecil. |
TableNameOriginal |
STRING |
Nama tabel dengan huruf tidak diubah. |
IndexName |
STRING |
Nama indeks. |
ColumnName |
STRING |
Nama kolom, dikonversi menjadi huruf kecil. |
ColumnNameOriginal |
STRING |
Nama kolom dengan huruf tidak diubah. |
OrdinalPosition |
INTEGER |
Posisi kolom. |
UniqueFlag |
BOOLEAN |
Menunjukkan apakah indeks memberlakukan keunikan. |
Queries
Tabel ini memberikan informasi tentang kueri yang diekstrak.
| Kolom | Jenis | Deskripsi |
|---|---|---|
QueryHash |
STRING |
Hash kueri. |
QueryText |
STRING |
Teks kueri. |
QueryLogs
Tabel ini berisi beberapa statistik eksekusi tentang kueri yang diekstrak.
| Kolom | Jenis | Deskripsi |
|---|---|---|
QueryText |
STRING |
Teks kueri. |
QueryHash |
STRING |
Hash kueri. |
QueryId |
STRING |
ID kueri. |
QueryType |
STRING |
Jenis kueri, baik Query maupun DDL. |
UserId |
BYTES |
ID pengguna yang menjalankan kueri. |
UserName |
STRING |
Nama pengguna yang menjalankan kueri. |
StartTime |
TIMESTAMP |
Stempel waktu saat kueri dikirim. |
Duration |
STRING |
Durasi kueri dalam milidetik. |
AppId |
STRING |
ID aplikasi yang menjalankan kueri. |
ProxyUser |
STRING |
Pengguna proxy saat digunakan melalui tingkat menengah. |
ProxyRole |
STRING |
Peran proxy saat digunakan melalui tingkat menengah. |
QueryTypeStatistics
Tabel ini memberikan statistik tentang jenis kueri.
| Kolom | Jenis | Deskripsi |
|---|---|---|
QueryHash |
STRING |
Hash kueri. |
QueryType |
STRING |
Jenis kueri. |
UpdatedTable |
STRING |
Tabel yang diperbarui oleh kueri jika ada. |
QueriedTables |
ARRAY<STRING> |
Daftar tabel yang telah dikueri. |
ResUsageScpu
Tabel ini memberikan informasi tentang penggunaan resource CPU.
| Kolom | Jenis | Deskripsi |
|---|---|---|
EventTime |
TIMESTAMP |
Waktu peristiwa terjadi. |
NodeId |
INTEGER |
ID Node |
CabinetId |
INTEGER |
Nomor lemari fisik node. |
ModuleId |
INTEGER |
Nomor modul fisik node. |
NodeType |
STRING |
Jenis node. |
CpuId |
INTEGER |
ID CPU dalam node ini. |
MeasurementPeriod |
INTEGER |
Periode pengukuran yang dinyatakan dalam sentidetik. |
SummaryFlag |
STRING |
S - baris ringkasan, N - baris non-ringkasan |
CpuFrequency |
FLOAT |
Frekuensi CPU dalam MHz. |
CpuIdle |
FLOAT |
Waktu CPU tidak ada aktivitas dinyatakan dalam sentidetik. |
CpuIoWait |
FLOAT |
Waktu CPU menunggu I/O yang dinyatakan dalam sentidetik. |
CpuUServ |
FLOAT |
Waktu CPU mengeksekusi kode pengguna yang dinyatakan dalam sentidetik. |
CpuUExec |
FLOAT |
Waktu CPU mengeksekusi kode layanan yang dinyatakan dalam sentidetik. |
Roles
Tabel ini memberikan informasi tentang peran.
| Kolom | Jenis | Deskripsi |
|---|---|---|
RoleName |
STRING |
Nama peran. |
Grantor |
STRING |
Nama database yang memberikan peran tersebut. |
Grantee |
STRING |
Pengguna yang diberi peran. |
WhenGranted |
TIMESTAMP |
Saat peran diberikan. |
WithAdmin |
BOOLEAN |
Adalah Admin Option yang ditetapkan untuk peran yang diberikan. |
SchemaConversion
Tabel ini memberikan informasi tentang konversi skema yang terkait dengan pengelompokan dan partisi.
| Nama Kolom | Jenis Kolom | Deskripsi |
|---|---|---|
DatabaseName |
STRING |
Nama database sumber yang menjadi alasan saran dibuat. Database dipetakan ke set data di BigQuery. |
TableName |
STRING |
Nama tabel yang menjadi alasan saran dibuat. |
PartitioningColumnName |
STRING |
Nama kolom partisi yang disarankan di BigQuery. |
ClusteringColumnNames |
ARRAY |
Nama kolom pengelompokan yang disarankan di BigQuery. |
CreateTableDDL |
STRING |
CREATE TABLE statement untuk membuat tabel di BigQuery. |
TableInfo
Tabel ini memberikan informasi tentang tabel.
| Kolom | Jenis | Deskripsi |
|---|---|---|
DatabaseName |
STRING |
Nama database, dikonversi menjadi huruf kecil. |
DatabaseNameOriginal |
STRING |
Nama database dengan huruf tidak diubah. |
TableName |
STRING |
Nama tabel, dikonversi menjadi huruf kecil. |
TableNameOriginal |
STRING |
Nama tabel dengan huruf tidak diubah. |
LastAccessTimestamp |
TIMESTAMP |
Terakhir kali tabel diakses. |
LastAlterTimestamp |
TIMESTAMP |
Terakhir kali tabel diubah. |
TableKind |
STRING |
Jenis tabel. |
TableRelations
Tabel ini memberikan informasi tentang tabel.
| Kolom | Jenis | Deskripsi |
|---|---|---|
QueryHash |
STRING |
Hash kueri yang membuat relasi. |
DatabaseName1 |
STRING |
Nama database pertama. |
TableName1 |
STRING |
Nama tabel pertama. |
DatabaseName2 |
STRING |
Nama database kedua. |
TableName2 |
STRING |
Nama tabel kedua. |
Relation |
STRING |
Jenis hubungan antara kedua tabel. |
TableSizes
Tabel ini memberikan informasi tentang ukuran tabel.
| Kolom | Jenis | Deskripsi |
|---|---|---|
DatabaseName |
STRING |
Nama database, dikonversi menjadi huruf kecil. |
DatabaseNameOriginal |
STRING |
Nama database dengan huruf tidak diubah. |
TableName |
STRING |
Nama tabel, dikonversi menjadi huruf kecil. |
TableNameOriginal |
STRING |
Nama tabel dengan huruf tidak diubah. |
TableSizeInBytes |
INTEGER |
Ukuran tabel dalam byte. |
Users
Tabel ini memberikan informasi tentang pengguna.
| Kolom | Jenis | Deskripsi |
|---|---|---|
UserName |
STRING |
Nama pengguna. |
CreatorName |
STRING |
Nama entitas yang membuat pengguna ini. |
CreateTimestamp |
TIMESTAMP |
Stempel waktu saat pengguna ini dibuat. |
LastAccessTimestamp |
TIMESTAMP |
Stempel waktu saat pengguna ini terakhir kali mengakses database. |
Redshift
Columns
Tabel Columns berasal dari salah satu tabel berikut:
SVV_COLUMNS,
INFORMATION_SCHEMA.COLUMNS
atau
PG_TABLE_DEF,
yang diurutkan berdasarkan prioritas. Alat ini akan mencoba memuat data dari tabel prioritas tertinggi terlebih dahulu. Jika gagal, metode ini akan mencoba memuat data dari tabel dengan prioritas tertinggi berikutnya. Lihat dokumentasi Amazon Redshift atau PostgreSQL untuk mengetahui detail selengkapnya tentang skema dan penggunaannya.
| Kolom | Jenis | Deskripsi |
|---|---|---|
DatabaseName |
STRING |
Nama database. |
SchemaName |
STRING |
Nama skema. |
TableName |
STRING |
Nama tabel. |
ColumnName |
STRING |
Nama kolom. |
DefaultValue |
STRING |
Nilai default, jika tersedia. |
Nullable |
BOOLEAN |
Apakah kolom dapat memiliki nilai null atau tidak. |
ColumnType |
STRING |
Jenis kolom, seperti VARCHAR. |
ColumnLength |
INTEGER |
Ukuran kolom, misalnya 30 untuk VARCHAR(30). |
CreateAndDropStatistic
Tabel ini memberikan informasi tentang pembuatan dan penghapusan tabel.
| Kolom | Jenis | Deskripsi |
|---|---|---|
QueryHash |
STRING |
Hash kueri. |
DefaultDatabase |
STRING |
Database default. |
EntityType |
STRING |
Jenis entity—misalnya, TABLE. |
EntityName |
STRING |
Nama entity. |
Operation |
STRING |
Operasinya: CREATE atau DROP. |
Databases
Tabel ini berasal dari tabel PG_DATABASE_INFO dari Amazon Redshift secara langsung. Nama kolom asli dari tabel PG disertakan dengan deskripsi. Lihat dokumentasi Amazon Redshift dan PostgreSQL untuk mengetahui detail selengkapnya tentang skema dan penggunaannya.
| Kolom | Jenis | Deskripsi |
|---|---|---|
DatabaseName |
STRING |
Nama database. Nama sumber: datname |
Owner |
STRING |
Pemilik database. Misalnya, pengguna yang membuat database. Nama sumber: datdba |
ExternalColumns
Tabel ini berisi informasi dari tabel SVV_EXTERNAL_COLUMNS dari Amazon Redshift secara langsung. Lihat dokumentasi Amazon Redshift untuk mengetahui detail selengkapnya tentang skema dan penggunaannya.
| Kolom | Jenis | Deskripsi |
|---|---|---|
SchemaName |
STRING |
Nama skema eksternal. |
TableName |
STRING |
Nama tabel eksternal. |
ColumnName |
STRING |
Nama kolom eksternal. |
ColumnType |
STRING |
Jenis kolom. |
Nullable |
BOOLEAN |
Apakah kolom dapat memiliki nilai null atau tidak. |
ExternalDatabases
Tabel ini berisi informasi dari tabel SVV_EXTERNAL_DATABASES dari Amazon Redshift secara langsung. Lihat dokumentasi Amazon Redshift untuk mengetahui detail selengkapnya tentang skema dan penggunaannya.
| Kolom | Jenis | Deskripsi |
|---|---|---|
DatabaseName |
STRING |
Nama database eksternal. |
Location |
STRING |
Lokasi database. |
ExternalPartitions
Tabel ini berisi informasi dari tabel SVV_EXTERNAL_PARTITIONS dari Amazon Redshift secara langsung. Lihat dokumentasi Amazon Redshift untuk mengetahui detail selengkapnya tentang skema dan penggunaannya.
| Kolom | Jenis | Deskripsi |
|---|---|---|
SchemaName |
STRING |
Nama skema eksternal. |
TableName |
STRING |
Nama tabel eksternal. |
Location |
STRING |
Lokasi partisi. Ukuran kolom dibatasi hingga 128 karakter. Nilai yang lebih panjang akan terpotong. |
ExternalSchemas
Tabel ini berisi informasi dari tabel SVV_EXTERNAL_SCHEMAS langsung dari Amazon Redshift. Lihat dokumentasi Amazon Redshift untuk mengetahui detail selengkapnya tentang skema dan penggunaannya.
| Kolom | Jenis | Deskripsi |
|---|---|---|
SchemaName |
STRING |
Nama skema eksternal. |
DatabaseName |
STRING |
Nama database eksternal. |
ExternalTables
Tabel ini berisi informasi dari tabel SVV_EXTERNAL_TABLES langsung dari Amazon Redshift. Lihat dokumentasi Amazon Redshift untuk mengetahui detail selengkapnya tentang skema dan penggunaannya.
| Kolom | Jenis | Deskripsi |
|---|---|---|
SchemaName |
STRING |
Nama skema eksternal. |
TableName |
STRING |
Nama tabel eksternal. |
Functions
Tabel ini berisi informasi dari tabel PG_PROC dari Amazon Redshift secara langsung. Lihat dokumentasi Amazon Redshift dan PostgreSQL untuk mengetahui detail selengkapnya tentang skema dan penggunaannya.
| Kolom | Jenis | Deskripsi |
|---|---|---|
SchemaName |
STRING |
Nama skema. |
FunctionName |
STRING |
Nama fungsi. |
LanguageName |
STRING |
Bahasa implementasi atau antarmuka panggilan dari fungsi ini. |
Queries
Tabel ini dibuat menggunakan informasi dari tabel QueryLogs. Tidak seperti tabel QueryLogs, setiap baris dalam tabel Queries hanya berisi satu pernyataan kueri yang disimpan di kolom QueryText. Tabel ini menyediakan data sumber untuk menghasilkan tabel Statistik dan output terjemahan.
| Kolom | Jenis | Deskripsi |
|---|---|---|
QueryText |
STRING |
Teks kueri. |
QueryHash |
STRING |
Hash kueri. |
QueryLogs
Tabel ini memberikan informasi tentang eksekusi kueri.
| Kolom | Jenis | Deskripsi |
|---|---|---|
QueryText |
STRING |
Teks kueri. |
QueryHash |
STRING |
Hash kueri. |
QueryID |
STRING |
ID kueri. |
UserID |
STRING |
ID pengguna. |
StartTime |
TIMESTAMP |
Waktu mulai. |
Duration |
INTEGER |
Durasi dalam milidetik. |
QueryTypeStatistics
| Kolom | Jenis | Deskripsi |
|---|---|---|
QueryHash |
STRING |
Hash kueri. |
DefaultDatabase |
STRING |
Database default. |
QueryType |
STRING |
Jenis kueri. |
UpdatedTable |
STRING |
Tabel yang diperbarui. |
QueriedTables |
ARRAY<STRING> |
Tabel yang dikueri. |
TableInfo
Tabel ini berisi informasi yang diekstrak dari tabel SVV_TABLE_INFO di Amazon Redshift.
| Kolom | Jenis | Deskripsi |
|---|---|---|
DatabaseName |
STRING |
Nama database. |
SchemaName |
STRING |
Nama skema. |
TableId |
INTEGER |
ID tabel. |
TableName |
STRING |
Nama tabel. |
SortKey1 |
STRING |
Kolom pertama dalam kunci pengurutan. |
SortKeyNum |
INTEGER |
Jumlah kolom yang ditentukan sebagai kunci pengurutan. |
MaxVarchar |
INTEGER |
Ukuran kolom terbesar yang menggunakan jenis data VARCHAR. |
Size |
INTEGER |
Ukuran tabel, dalam blok data 1 MB. |
TblRows |
INTEGER |
Jumlah total baris dalam tabel. |
TableRelations
| Kolom | Jenis | Deskripsi |
|---|---|---|
QueryHash |
STRING |
Hash kueri yang membentuk relasi (Misalnya, kueri JOIN). |
DefaultDatabase |
STRING |
Database default. |
TableName1 |
STRING |
Tabel pertama dalam hubungan. |
TableName2 |
STRING |
Tabel kedua dalam hubungan. |
Relation |
STRING |
Jenis hubungan. Mengambil salah satu nilai berikut:
COMMA_JOIN, CROSS_JOIN,
FULL_OUTER_JOIN, INNER_JOIN,
LEFT_OUTER_JOIN,
RIGHT_OUTER_JOIN, CREATED_FROM, atau
INSERT_INTO. |
Count |
INTEGER |
Seberapa sering hubungan ini diamati. |
TableSizes
Tabel ini memberikan informasi tentang ukuran tabel.
| Kolom | Jenis | Deskripsi |
|---|---|---|
DatabaseName |
STRING |
Nama database. |
SchemaName |
STRING |
Nama skema. |
TableName |
STRING |
Nama tabel. |
TableSizeInBytes |
INTEGER |
Ukuran tabel dalam byte. |
Tables
Tabel ini berisi informasi yang diekstrak dari tabel SVV_TABLES di Amazon Redshift. Lihat dokumentasi Amazon Redshift untuk mengetahui detail selengkapnya tentang skema dan penggunaannya.
| Kolom | Jenis | Deskripsi |
|---|---|---|
DatabaseName |
STRING |
Nama database. |
SchemaName |
STRING |
Nama skema. |
TableName |
STRING |
Nama tabel. |
TableType |
STRING |
Jenis tabel. |
TranslatedQueries
Tabel ini menyediakan terjemahan kueri.
| Kolom | Jenis | Deskripsi |
|---|---|---|
QueryHash |
STRING |
Hash kueri. |
TranslatedQueryText |
STRING |
Hasil terjemahan dari dialek sumber ke GoogleSQL. |
TranslationErrors
Tabel ini memberikan informasi tentang error terjemahan kueri.
| Kolom | Jenis | Deskripsi |
|---|---|---|
QueryHash |
STRING |
Hash kueri. |
Severity |
STRING |
Tingkat keparahan error, seperti ERROR. |
Category |
STRING |
Kategori error, seperti
AttributeNotFound. |
Message |
STRING |
Pesan dengan detail tentang error. |
LocationOffset |
INTEGER |
Posisi karakter lokasi error. |
LocationLine |
INTEGER |
Nomor baris error. |
LocationColumn |
INTEGER |
Nomor kolom error. |
LocationLength |
INTEGER |
Panjang karakter lokasi error. |
UserTableRelations
| Kolom | Jenis | Deskripsi |
|---|---|---|
UserID |
STRING |
ID pengguna. |
TableName |
STRING |
Nama tabel. |
Relation |
STRING |
Hubungan. |
Count |
INTEGER |
Jumlah. |
Users
Tabel ini berisi informasi yang diekstrak dari tabel PG_USER di Amazon Redshift. Lihat dokumentasi PostgreSQL untuk mengetahui detail selengkapnya tentang skema dan penggunaannya.
| Kolom | Jenis | Deskripsi | |
|---|---|---|---|
UserName |
STRING |
Nama pengguna. | |
UserId |
STRING |
ID pengguna. |
Snowflake
Warehouses
| Kolom | Jenis | Deskripsi | Kehadiran |
|---|---|---|---|
WarehouseName |
STRING |
Nama gudang. | Selalu |
State |
STRING |
Status gudang. Nilai yang mungkin: STARTED, SUSPENDED, RESIZING. |
Selalu |
Type |
STRING |
Jenis gudang. Nilai yang mungkin: STANDARD, SNOWPARK-OPTIMIZED. |
Selalu |
Size |
STRING |
Ukuran gudang. Nilai yang mungkin: X-Small, Small, Medium, Large, X-Large, 2X-Large ... 6X-Large. |
Selalu |
Databases
| Kolom | Jenis | Deskripsi | Kehadiran |
|---|---|---|---|
DatabaseNameOriginal |
STRING |
Nama database, dengan huruf tidak diubah. | Selalu |
DatabaseName |
STRING |
Nama database, dikonversi menjadi huruf kecil. | Selalu |
Schemata
| Kolom | Jenis | Deskripsi | Kehadiran |
|---|---|---|---|
DatabaseNameOriginal |
STRING |
Nama database tempat skema berada, dengan huruf tidak diubah. | Selalu |
DatabaseName |
STRING |
Nama database tempat skema berada, dikonversi menjadi huruf kecil. | Selalu |
SchemaNameOriginal |
STRING |
Nama skema, dengan huruf tidak diubah. | Selalu |
SchemaName |
STRING |
Nama skema, dikonversi menjadi huruf kecil. | Selalu |
Tables
| Kolom | Jenis | Deskripsi | Kehadiran |
|---|---|---|---|
DatabaseNameOriginal |
STRING |
Nama database tempat tabel berada, dengan huruf tidak diubah. | Selalu |
DatabaseName |
STRING |
Nama database tempat tabel berada, dikonversi menjadi huruf kecil. | Selalu |
SchemaNameOriginal |
STRING |
Nama skema tempat tabel berada, dengan huruf tidak diubah. | Selalu |
SchemaName |
STRING |
Nama skema tempat tabel berada, dikonversi menjadi huruf kecil. | Selalu |
TableNameOriginal |
STRING |
Nama tabel, dengan huruf tidak diubah. | Selalu |
TableName |
STRING |
Nama tabel, dikonversi menjadi huruf kecil. | Selalu |
TableType |
STRING |
Jenis tabel (Tampilan / Tampilan Terwujud / Tabel Dasar). | Selalu |
RowCount |
BIGNUMERIC |
Jumlah baris dalam tabel. | Selalu |
Columns
| Kolom | Jenis | Deskripsi | Kehadiran |
|---|---|---|---|
DatabaseName |
STRING |
Nama database, dikonversi menjadi huruf kecil. | Selalu |
DatabaseNameOriginal |
STRING |
Nama database, dengan huruf tidak diubah. | Selalu |
SchemaName |
STRING |
Nama skema, dikonversi menjadi huruf kecil. | Selalu |
SchemaNameOriginal |
STRING |
Nama skema, dengan huruf tidak diubah. | Selalu |
TableName |
STRING |
Nama tabel, dikonversi menjadi huruf kecil. | Selalu |
TableNameOriginal |
STRING |
Nama tabel dengan huruf tidak diubah. | Selalu |
ColumnName |
STRING |
Nama kolom, dikonversi menjadi huruf kecil. | Selalu |
ColumnNameOriginal |
STRING |
Nama kolom dengan huruf tidak diubah. | Selalu |
ColumnType |
STRING |
Jenis kolom. | Selalu |
CreateAndDropStatistics
| Kolom | Jenis | Deskripsi | Kehadiran |
|---|---|---|---|
QueryHash |
STRING |
Hash kueri. | Selalu |
DefaultDatabase |
STRING |
Database default. | Selalu |
EntityType |
STRING |
Jenis entity—misalnya, TABLE. |
Selalu |
EntityName |
STRING |
Nama entity. | Selalu |
Operation |
STRING |
Operasi: CREATE atau DROP. |
Selalu |
Queries
| Kolom | Jenis | Deskripsi | Kehadiran |
|---|---|---|---|
QueryText |
STRING |
Teks kueri. | Selalu |
QueryHash |
STRING |
Hash kueri. | Selalu |
QueryLogs
| Kolom | Jenis | Deskripsi | Kehadiran |
|---|---|---|---|
QueryText |
STRING |
Teks kueri. | Selalu |
QueryHash |
STRING |
Hash kueri. | Selalu |
QueryID |
STRING |
ID kueri. | Selalu |
UserID |
STRING |
ID pengguna. | Selalu |
StartTime |
TIMESTAMP |
Waktu mulai. | Selalu |
Duration |
INTEGER |
Durasi dalam milidetik. | Selalu |
QueryTypeStatistics
| Kolom | Jenis | Deskripsi | Kehadiran |
|---|---|---|---|
QueryHash |
STRING |
Hash kueri. | Selalu |
DefaultDatabase |
STRING |
Database default. | Selalu |
QueryType |
STRING |
Jenis kueri. | Selalu |
UpdatedTable |
STRING |
Tabel yang diperbarui. | Selalu |
QueriedTables |
REPEATED STRING |
Tabel yang dikueri. | Selalu |
TableRelations
| Kolom | Jenis | Deskripsi | Kehadiran |
|---|---|---|---|
QueryHash |
STRING |
Hash kueri yang membuat relasi (misalnya, kueri JOIN). |
Selalu |
DefaultDatabase |
STRING |
Database default. | Selalu |
TableName1 |
STRING |
Tabel pertama dalam hubungan. | Selalu |
TableName2 |
STRING |
Tabel kedua dalam hubungan. | Selalu |
Relation |
STRING |
Jenis hubungan. | Selalu |
Count |
INTEGER |
Seberapa sering hubungan ini diamati. | Selalu |
TranslatedQueries
| Kolom | Jenis | Deskripsi | Kehadiran |
|---|---|---|---|
QueryHash |
STRING |
Hash kueri. | Selalu |
TranslatedQueryText |
STRING |
Hasil terjemahan dari dialek sumber ke BigQuery SQL. | Selalu |
TranslationErrors
| Kolom | Jenis | Deskripsi | Kehadiran |
|---|---|---|---|
QueryHash |
STRING |
Hash kueri. | Selalu |
Severity |
STRING |
Tingkat keparahan error—misalnya, ERROR. |
Selalu |
Category |
STRING |
Kategori error—misalnya, AttributeNotFound. |
Selalu |
Message |
STRING |
Pesan dengan detail tentang error. | Selalu |
LocationOffset |
INTEGER |
Posisi karakter lokasi error. | Selalu |
LocationLine |
INTEGER |
Nomor baris error. | Selalu |
LocationColumn |
INTEGER |
Nomor kolom error. | Selalu |
LocationLength |
INTEGER |
Panjang karakter lokasi error. | Selalu |
UserTableRelations
| Kolom | Jenis | Deskripsi | Kehadiran |
|---|---|---|---|
UserID |
STRING |
ID Pengguna. | Selalu |
TableName |
STRING |
Nama tabel. | Selalu |
Relation |
STRING |
Hubungan. | Selalu |
Count |
INTEGER |
Jumlah. | Selalu |
Apache Hive
Columns
Tabel ini memberikan informasi tentang kolom:
| Kolom | Jenis | Deskripsi |
|---|---|---|
DatabaseName |
STRING |
Nama database dengan huruf tidak diubah. |
TableName |
STRING |
Nama tabel dengan huruf tidak diubah. |
ColumnName |
STRING |
Nama kolom dengan huruf tidak diubah. |
ColumnType |
STRING |
Jenis kolom BigQuery, seperti STRING. |
OriginalColumnType |
STRING |
Jenis kolom asli, seperti VARCHAR. |
CreateAndDropStatistic
Tabel ini memberikan informasi tentang pembuatan dan penghapusan tabel:
| Kolom | Jenis | Deskripsi |
|---|---|---|
QueryHash |
STRING |
Hash kueri. |
DefaultDatabase |
STRING |
Database default. |
EntityType |
STRING |
Jenis entity, misalnya, TABLE. |
EntityName |
STRING |
Nama entity. |
Operation |
STRING |
Operasi yang dilakukan pada tabel (CREATE atau DROP). |
Databases
Tabel ini memberikan informasi tentang database:
| Kolom | Jenis | Deskripsi |
|---|---|---|
DatabaseName |
STRING |
Nama database dengan huruf tidak diubah. |
Owner |
STRING |
Pemilik database. Misalnya, pengguna yang membuat database. |
Location |
STRING |
Lokasi database dalam sistem file. |
Functions
Tabel ini memberikan informasi tentang fungsi:
| Kolom | Jenis | Deskripsi |
|---|---|---|
DatabaseName |
STRING |
Nama database dengan huruf tidak diubah. |
FunctionName |
STRING |
Nama fungsi. |
LanguageName |
STRING |
Nama bahasa. |
ClassName |
STRING |
Nama class fungsi. |
ObjectReferences
Tabel ini memberikan informasi tentang objek yang dirujuk dalam kueri:
| Kolom | Jenis | Deskripsi |
|---|---|---|
QueryHash |
STRING |
Hash kueri. |
DefaultDatabase |
STRING |
Database default. |
Clause |
STRING |
Klausul tempat objek muncul. Misalnya, SELECT. |
ObjectName |
STRING |
Nama objek. |
Type |
STRING |
Jenis objek. |
Subtype |
STRING |
Subjenis objek. |
PartitionKeys
Tabel ini memberikan informasi tentang kunci partisi:
| Kolom | Jenis | Deskripsi |
|---|---|---|
DatabaseName |
STRING |
Nama database dengan huruf tidak diubah. |
TableName |
STRING |
Nama tabel dengan huruf tidak diubah. |
ColumnName |
STRING |
Nama kolom dengan huruf tidak diubah. |
ColumnType |
STRING |
Jenis kolom BigQuery, seperti STRING. |
Partitions
Tabel ini memberikan informasi tentang partisi tabel:
| Kolom | Jenis | Deskripsi |
|---|---|---|
DatabaseName |
STRING |
Nama database dengan huruf tidak diubah. |
TableName |
STRING |
Nama tabel dengan huruf tidak diubah. |
PartitionName |
STRING |
Nama partisi. |
CreateTimestamp |
TIMESTAMP |
Stempel waktu saat partisi ini dibuat. |
LastAccessTimestamp |
TIMESTAMP |
Stempel waktu saat partisi ini terakhir kali diakses. |
LastDdlTimestamp |
TIMESTAMP |
Stempel waktu saat partisi ini terakhir diubah. |
TotalSize |
INTEGER |
Ukuran partisi yang dikompresi dalam byte. |
Queries
Tabel ini dibuat menggunakan informasi dari tabel QueryLogs. Tidak seperti tabel QueryLogs, setiap baris dalam tabel Queries hanya berisi satu pernyataan kueri yang disimpan di kolom QueryText. Tabel ini menyediakan data sumber untuk menghasilkan tabel Statistik dan output terjemahan:
| Kolom | Jenis | Deskripsi |
|---|---|---|
QueryHash |
STRING |
Hash kueri. |
QueryText |
STRING |
Teks kueri. |
QueryLogs
Tabel ini berisi beberapa statistik eksekusi tentang kueri yang diekstrak:
| Kolom | Jenis | Deskripsi |
|---|---|---|
QueryText |
STRING |
Teks kueri. |
QueryHash |
STRING |
Hash kueri. |
QueryId |
STRING |
ID kueri. |
QueryType |
STRING |
Jenis kueri, Query atau DDL. |
UserName |
STRING |
Nama pengguna yang menjalankan kueri. |
StartTime |
TIMESTAMP |
Stempel waktu saat kueri dikirim. |
Duration |
STRING |
Durasi kueri dalam milidetik. |
QueryTypeStatistics
Tabel ini memberikan statistik tentang jenis kueri:
| Kolom | Jenis | Deskripsi |
|---|---|---|
QueryHash |
STRING |
Hash kueri. |
QueryType |
STRING |
Jenis kueri. |
UpdatedTable |
STRING |
Tabel yang diperbarui oleh kueri, jika ada. |
QueriedTables |
ARRAY<STRING> |
Daftar tabel yang telah dikueri. |
QueryTypes
Tabel ini memberikan statistik tentang jenis kueri:
| Kolom | Jenis | Deskripsi |
|---|---|---|
QueryHash |
STRING |
Hash kueri. |
Category |
STRING |
Kategori kueri. |
Type |
STRING |
Jenis kueri. |
Subtype |
STRING |
Subjenis kueri. |
SchemaConversion
Tabel ini memberikan informasi tentang konversi skema yang terkait dengan pengelompokan dan partisi:
| Nama Kolom | Jenis Kolom | Deskripsi |
|---|---|---|
DatabaseName |
STRING |
Nama database sumber yang menjadi alasan saran dibuat. Database dipetakan ke set data di BigQuery. |
TableName |
STRING |
Nama tabel yang menjadi alasan saran dibuat. |
PartitioningColumnName |
STRING |
Nama kolom partisi yang disarankan di BigQuery. |
ClusteringColumnNames |
ARRAY |
Nama kolom pengelompokan yang disarankan di BigQuery. |
CreateTableDDL |
STRING |
CREATE TABLE statement untuk membuat tabel di BigQuery. |
TableRelations
Tabel ini memberikan informasi tentang tabel:
| Kolom | Jenis | Deskripsi |
|---|---|---|
QueryHash |
STRING |
Hash kueri yang membuat relasi. |
DatabaseName1 |
STRING |
Nama database pertama. |
TableName1 |
STRING |
Nama tabel pertama. |
DatabaseName2 |
STRING |
Nama database kedua. |
TableName2 |
STRING |
Nama tabel kedua. |
Relation |
STRING |
Jenis hubungan antara kedua tabel. |
TableSizes
Tabel ini memberikan informasi tentang ukuran tabel:
| Kolom | Jenis | Deskripsi |
|---|---|---|
DatabaseName |
STRING |
Nama database dengan huruf tidak diubah. |
TableName |
STRING |
Nama tabel dengan huruf tidak diubah. |
TotalSize |
INTEGER |
Ukuran tabel dalam byte. |
Tables
Tabel ini memberikan informasi tentang tabel:
| Kolom | Jenis | Deskripsi |
|---|---|---|
DatabaseName |
STRING |
Nama database dengan huruf tidak diubah. |
TableName |
STRING |
Nama tabel dengan huruf tidak diubah. |
Type |
STRING |
Jenis tabel. |
TranslatedQueries
Tabel ini menyediakan terjemahan kueri:
| Kolom | Jenis | Deskripsi |
|---|---|---|
QueryHash |
STRING |
Hash kueri. |
TranslatedQueryText |
STRING |
Hasil terjemahan dari dialek sumber ke GoogleSQL. |
TranslationErrors
Tabel ini memberikan informasi tentang error terjemahan kueri:
| Kolom | Jenis | Deskripsi |
|---|---|---|
QueryHash |
STRING |
Hash kueri. |
Severity |
STRING |
Tingkat keparahan error, seperti ERROR. |
Category |
STRING |
Kategori error, seperti
AttributeNotFound. |
Message |
STRING |
Pesan dengan detail tentang error. |
LocationOffset |
INTEGER |
Posisi karakter lokasi error. |
LocationLine |
INTEGER |
Nomor baris error. |
LocationColumn |
INTEGER |
Nomor kolom error. |
LocationLength |
INTEGER |
Panjang karakter lokasi error. |
UserTableRelations
| Kolom | Jenis | Deskripsi |
|---|---|---|
UserID |
STRING |
ID pengguna. |
TableName |
STRING |
Nama tabel. |
Relation |
STRING |
Hubungan. |
Count |
INTEGER |
Jumlah. |
Pemecahan masalah
Bagian ini menjelaskan beberapa masalah umum dan teknik pemecahan masalah untuk memigrasikan data warehouse Anda ke BigQuery.
Error alat dwh-migration-dumper
Untuk memecahkan masalah error dan peringatan dalam output terminal alat dwh-migration-dumper yang terjadi selama ekstraksi metadata atau log kueri, lihat pemecahan masalah pembuatan metadata.
Error migrasi Hive
Bagian ini menjelaskan masalah umum yang mungkin Anda alami saat berencana memigrasikan data warehouse dari Hive ke BigQuery.
Hook logging menulis pesan log debug di log
hive-server2 Anda. Jika Anda mengalami masalah, tinjau log debug hook logging, yang berisi string MigrationAssessmentLoggingHook.
Menangani error ClassNotFoundException
Error ini mungkin disebabkan oleh salah penempatan file JAR hook logging. Pastikan Anda telah menambahkan file JAR ke folder auxlib di cluster Hive. Atau, Anda dapat menentukan jalur lengkap ke
file JAR di properti hive.aux.jars.path, misalnya,
file://.
Subfolder tidak muncul di folder yang dikonfigurasi
Masalah ini mungkin disebabkan oleh kesalahan konfigurasi atau masalah selama inisialisasi hook logging.
Telusuri pesan hook logging hive-server2debug log Anda berikut:
Unable to initialize logger, logging disabled
Log dir configuration key 'dwhassessment.hook.base-directory' is not set, logging disabled.
Error while trying to set permission
Tinjau detail masalah dan lihat apakah ada hal yang perlu diperbaiki untuk mengatasi masalah tersebut.
File tidak muncul di folder
Masalah ini mungkin disebabkan oleh masalah yang terjadi selama pemrosesan peristiwa atau saat menulis ke file.
Telusuri pesan hook logging berikut di log debug hive-server2:
Failed to close writer for file
Got exception while processing event
Error writing record for query
Tinjau detail masalah dan lihat apakah ada hal yang perlu diperbaiki untuk mengatasi masalah tersebut.
Beberapa peristiwa kueri tidak tercatat
Masalah ini mungkin disebabkan oleh overflow antrean thread hook logging.
Telusuri pesan hook logging berikut di log debug hive-server2:
Writer queue is full. Ignoring event
Jika ada pesan tersebut, pertimbangkan untuk meningkatkan parameter
dwhassessment.hook.queue.capacity.
Langkah berikutnya
Untuk informasi selengkapnya tentang alat dwh-migration-dumper, lihat dwh-migration-tools.
Anda juga dapat mempelajari lebih lanjut langkah-langkah berikut dalam migrasi data warehouse:
- Ringkasan migrasi
- Ringkasan skema dan transfer data
- Data pipelines
- Terjemahan batch SQL
- Terjemahan SQL interaktif
- Tata kelola dan keamanan data
- Alat validasi data