위치 간 정책 태그 관리
이 문서에서는 BigQuery에서 열 수준 보안과 동적 데이터 마스킹을 위해 리전 위치에서 정책 태그를 관리하는 방법을 설명합니다.
BigQuery는 정책 태그를 통해 민감한 테이블 열에 세분화된 액세스 제어와 동적 데이터 마스킹을 제공하여 데이터의 유형 기반 분류를 지원합니다.
데이터 분류 체계를 만들고 데이터에 정책 태그를 적용한 후에는 여러 위치에서 정책 태그를 추가로 관리할 수 있습니다.
위치 고려사항
분류는 BigQuery 데이터 세트 및 테이블과 같은 리전별 리소스입니다. 분류를 만들 때는 분류의 리전 또는 위치를 지정합니다.
BigQuery를 사용할 수 있는 모든 리전의 테이블에 분류를 만들고 정책 태그를 적용할 수 있습니다. 그러나 분류의 정책 태그를 테이블 열에 적용하려면 분류와 테이블이 같은 리전 위치에 있어야 합니다.
다른 위치에 있는 테이블 열에 정책 태그를 적용할 수는 없지만 해당 위치에서 명시적으로 복제하여 다른 위치에 분류를 복사할 수 있습니다.
여러 위치에서 분류 사용
각 위치에서 수동으로 새 분류를 만들지 않고도 분류 및 정책 태그 정의를 추가 위치로 명시적으로 복사(또는 복제)할 수 있습니다. 분류를 복제하면 여러 위치의 열 수준 보안에 동일한 정책 태그를 사용하여 관리를 간소화할 수 있습니다.
복제하면 분류와 정책 태그가 각 위치에서 동일한 ID를 보관합니다.
분류 및 정책 태그를 다시 동기화하여 여러 위치에 통합할 수 있습니다. 분류의 명시적인 복제는 Data Catalog API 호출을 통해 실행됩니다. 복제된 분류에서 이후 동기화는 동일한 API 명령어를 사용하여 이전 분류를 덮어씁니다.
분류 동기화를 용이하게 하려면 Cloud Scheduler를 사용하여 정해진 일정 또는 수동 버튼 푸시를 통해 리전 간 분류 동기화를 주기적으로 수행할 수 있습니다. Cloud Scheduler를 사용하려면 서비스 계정을 설정해야 합니다.
새 위치에서 분류 복제
필수 권한
분류를 복제하는 사용자 인증 정보 또는 서비스 계정에는 Data Catalog 정책 태그 관리자 역할이 있어야 합니다.
BigQuery 열 수준 보안으로 액세스 제한에서 정책 태그 관리자 역할 부여에 대해 자세히 알아보세요.
BigQuery의 IAM 역할과 권한에 대한 자세한 내용은 사전 정의된 역할 및 권한을 참조하세요.
여러 위치에서 분류를 복제하려면 다음 안내를 따르세요.
API
Data Catalog API의 projects.locations.taxonomies.import 메서드를 호출하여 POST 요청과 HTTP 문자열에서 대상 프로젝트 이름과 위치를 제공합니다.
POST https://datacatalog.googleapis.com/{parent}/taxonomies:import
parent 경로 파라미터는 분류를 복사할 대상 프로젝트와 위치입니다. 예를 들면 projects/MyProject/locations/eu입니다.
복제된 분류 동기화
이미 여러 위치에 복제된 분류를 동기화하려면 새 위치에서 분류 복제에 설명된 대로 Data Catalog API 호출을 반복합니다.
또는 서비스 계정과 Cloud Scheduler를 사용하여 지정한 일정에 따라 분류를 동기화할 수 있습니다. Cloud Scheduler에서 서비스 계정을 설정하면 Google Cloud 콘솔의 Cloud Scheduler 페이지나 Google Cloud CLI를 통해 주문형(예약되지 않은) 동기화를 트리거할 수 있습니다.
Cloud Scheduler로 복제된 분류 동기화
여러 위치에서 복제된 분류를 Cloud Scheduler로 동기화하려면 서비스 계정이 필요합니다.
서비스 계정
복제 동기화에 대한 권한을 기존 서비스 계정에 부여하거나 새 서비스 계정을 만들 수 있습니다.
새 서비스 계정을 만들려면 서비스 계정 만들기를 참조하세요.
필수 권한
분류를 동기화하는 서비스 계정에는 Data Catalog 정책 태그 관리자 역할이 있어야 합니다. 자세한 내용은 정책 태그 관리자 역할 부여를 참조하세요.
Cloud Scheduler로 분류 동기화 설정
여러 위치에 복제된 분류를 Cloud Scheduler로 동기화하려면 다음 안내를 따르세요.
콘솔
먼저 동기화 작업과 해당 일정을 만듭니다.
Cloud Scheduler에서 작업 만들기의 안내를 따릅니다.
대상의 경우 인증을 사용하여 스케줄러 작업 만들기의 안내를 참조하세요.
다음으로 예약된 동기화에 필요한 인증을 추가합니다.
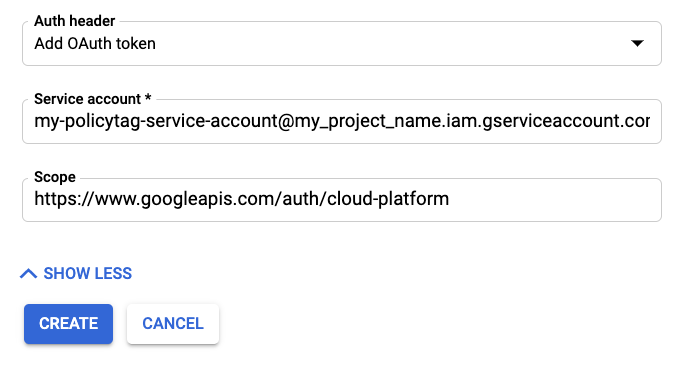
더보기를 클릭하여 인증 필드를 표시합니다.
인증 헤더에서 'OAuth 토큰 추가'를 선택합니다.
서비스 계정 정보를 추가합니다.
범위에 'https://www.googleapis.com/auth/cloud-platform'을 입력합니다.
만들기를 클릭하여 예약된 동기화를 저장합니다.
이제 작업이 올바르게 구성되었는지 테스트합니다.
작업이 생성되면 지금 실행을 클릭하여 작업이 올바르게 구성되었는지 테스트합니다. 이후 Cloud Scheduler는 지정된 일정에 따라 HTTP 요청을 트리거합니다.
gcloud
구문:
gcloud scheduler jobs create http "JOB_ID" --schedule="FREQUENCY" --uri="URI" --oath-service-account-email="CLIENT_SERVICE_ACCOUNT_EMAIL" --time-zone="TIME_ZONE" --message-body-from-file="MESSAGE_BODY"
다음을 바꿉니다.
${JOB_ID}는 작업의 이름입니다. 프로젝트 내에서 고유한 이름이어야 합니다. 작업 이름과 연결된 작업을 삭제하더라도 프로젝트에서 그 작업 이름을 다시 사용할 수 없다는 점에 유의하세요.${FREQUENCY}는 작업 실행 빈도인 작업 주기라고도 하는 일정입니다. 예: '3시간마다'. crontab 호환 문자열이라면 어떤 문자열도 여기에 제공할 수 있습니다. 또는 기존 App Engine 크론에 익숙한 개발자는 App Engine 크론 구문을 사용해도 됩니다.${URI}는 엔드포인트의 정규화된 URL입니다.--oauth-service-account-email은 토큰 유형을 정의합니다.*.googleapis.com에서 호스팅되는 Google API에는 OAuth 토큰이 필요합니다.${CLIENT_SERVICE_ACCOUNT_EMAIL}은 클라이언트 서비스 계정 이메일입니다.${MESSAGE_BODY}는 POST 요청 본문을 포함하는 파일의 경로입니다.
사용할 수 있는 다른 옵션 매개변수는 Google Cloud CLI 참조에 설명되어 있습니다.
예시:
gcloud scheduler jobs create http cross_regional_copy_to_eu_scheduler --schedule="0 0 1 * *" --uri="https://datacatalog.googleapis.com/v1/projects/my-project/locations/eu/taxonomies:import" --oauth-service-account-email="policytag-manager-service-acou@my-project.iam.gserviceaccount.com" --time-zone="America/Los_Angeles" --message-body-from-file=request_body.json
다음 단계
- 정책 태그를 사용한 열 수준 보안 개요는 BigQuery 열 수준 보안 소개를 참조하세요.
- 정책 태그를 만들고 적용하는 방법에 대한 자세한 내용은 BigQuery 열 수준 보안으로 액세스 제한을 참조하세요.
- BigQuery 열 수준 보안을 사용할 때 쓰기에 미치는 영향을 알아보려면 BigQuery 열 수준 보안이 쓰기에 미치는 영향을 참조하세요.
- 정책 태그 사용을 위한 권장사항에 대한 자세한 내용은 BigQuery에서 정책 태그 사용을 참조하세요.