分區資料表簡介
分區資料表劃分為多個區段 (稱為分區),可讓您更容易管理和查詢資料。將大型資料表分成較小的分區,可以提高查詢效能,並且可以透過減少查詢讀取的位元組數來控制費用。您可以指定用來區隔資料表的分區欄,藉此分割資料表。
如果查詢作業對分區資料欄套用符合的篩選器,BigQuery 就能掃描符合篩選條件的分區,並略過其餘的分區。這個過程稱為「修剪」。
在分區資料表中,資料會儲存在實際區塊中,每個區塊都會保留一個資料分區。每個分區資料表都會在所有修改排序屬性的作業中,保留排序屬性的各種中繼資料。中繼資料可讓 BigQuery 在執行查詢前更準確地估算查詢費用。
使用區隔處理的時機
請考慮在下列情況下為資料表建立分區:
- 您想只掃描資料表的一部分,藉此提高查詢效能。
- 您的資料表作業超出標準資料表配額,您可以將資料表作業範圍限定為特定分區欄值,以便提高分區資料表配額。
- 您希望在執行查詢前先確定查詢費用。在對分區資料表執行查詢前,BigQuery 會提供查詢費用預估值。透過縮減分區資料表來計算查詢費用的預估值,然後發出查詢模擬測試,以便估算查詢費用。
- 您需要下列任一分區層級管理功能:
在下列情況下,建議您叢集資料表,而非分割資料表:
- 您需要的精細程度超出分區的限制。
- 查詢通常會對多個資料欄使用篩選或匯總。
- 資料欄或一組資料欄中的值數量基數過大。
- 您不需要在執行查詢前進行嚴格的費用估算。
- 分區後,每個分區的資料量都會很少 (約小於 10 GB)。建立許多小分區會增加資料表的中繼資料,並可能影響查詢資料表時的中繼資料存取時間。
- 分區後會產生大量的分區,超過分區資料表的限制。
- 您的 DML 作業經常修改資料表中的大部分分區 (例如每隔幾分鐘就修改一次)。
在這種情況下,您可以使用資料表叢集功能,根據使用者定義的排序屬性,將特定欄中的資料分組,加快查詢速度。
您也可以結合叢集和資料表分區,以便進行更精細的排序。如要進一步瞭解這種做法,請參閱「結合叢集和分區資料表」。
分區類型
本節說明分割資料表的不同方式。
整數範圍分區
您可以根據特定 INTEGER 資料欄中的值範圍,對資料表進行分區。如要建立整數範圍分區資料表,請提供:
- 分區欄。
- 範圍分區的起始值 (含)。
- 範圍分區的結束值 (不含)。
- 分區內每個範圍的間隔。
舉例來說,假設您使用下列規格建立整數範圍分區:
| 引數 | 值 |
|---|---|
| 資料欄名稱 | customer_id |
| 開始 | 0 |
| 結束 | 100 |
| interval | 10 |
資料表會依 customer_id 資料欄分區為間隔為 10 的多個範圍。0 到 9 的值會放在一個分區中,10 到 19 的值放在下一個分區中,以此類推,直到最後 99 的值放在另一個分區中。超出範圍的值會放入名為 __UNPARTITIONED__ 的分區。任何 customer_id 為 NULL 的資料列都會進入名為 __NULL__ 的分割區。
如要瞭解整數範圍分區資料表,請參閱「建立整數範圍分區資料表」。
時間單位資料欄分區
您可以在資料表中的 DATE、TIMESTAMP 或 DATETIME 資料欄上分割資料表。將資料寫入資料表時,BigQuery 會根據資料欄中的值,自動將資料放入正確的分區。
對於 TIMESTAMP 和 DATETIME 資料欄,分區的精細程度可以是每小時、每日、每月或每年。對於 DATE 欄,區隔的精細程度可以是每日、每月或每年。分區邊界以 UTC 時間為準。
舉例來說,假設您依據每月分區的 DATETIME 資料欄分割資料表。如果您將下列值插入表格,資料列會寫入下列分區:
| 列值 | 分區 (每月) |
|---|---|
DATETIME("2019-01-01") |
201901 |
DATETIME("2019-01-15") |
201901 |
DATETIME("2019-04-30") |
201904 |
此外,系統也會建立兩個特別的分區:
__NULL__:分區資料欄中值為NULL的資料列。__UNPARTITIONED__:包含分割資料欄值早於 1960-01-01 或晚於 2159-12-31 的資料列。
如要瞭解時間單位資料欄分區資料表,請參閱「建立時間單位資料欄分區資料表」一文。
擷取時間分區
建立以擷取時間分區的資料表時,BigQuery 會根據 BigQuery 擷取資料的時間,自動將資料列指派給分區。您可以為區隔設定每小時、每日、每月或每年的細目設定。分區邊界以世界標準時間為準。
如果使用較精細的時間精細度時,資料可能會達到每個資料表的分區數量上限,請改用較粗略的精細度。舉例來說,您可以按月而不是按天劃分,以減少分區數量。您也可以叢集區隔欄,進一步提升效能。
擷取時間分區資料表包含名為 _PARTITIONTIME 的虛擬資料欄。這個欄位的值是每個資料列的擷取時間,會截斷至區隔邊界 (例如每小時或每日)。舉例來說,假設您建立擷取時間分區資料表,並以每小時分區,且在下列時間傳送資料:
| 擷取時間 | _PARTITIONTIME |
分區 (按小時計費) |
|---|---|---|
| 2021-05-07 17:22:00 | 2021-05-07 17:00:00 | 2021050717 |
| 2021-05-07 17:40:00 | 2021-05-07 17:00:00 | 2021050717 |
| 2021-05-07 18:31:00 | 2021-05-07 18:00:00 | 2021050718 |
由於本範例中的資料表使用每小時分區,因此 _PARTITIONTIME 的值會截斷為小時邊界。BigQuery 會使用這個值來判斷資料的正確分區。
您也可以將資料寫入特定分區。舉例來說,您可能會想載入歷來資料或調整時區。您可以使用 0001-01-01 到 9999-12-31 之間的任何有效日期。不過,DML 陳述式無法參照 1970-01-01 之前或 2159-12-31 之後的日期。詳情請參閱「將資料寫入特定分區」。
您也可以改用 _PARTITIONDATE,而非 _PARTITIONTIME。_PARTITIONDATE 虛擬資料欄包含的世界標準時間日期,與 _PARTITIONTIME 虛擬資料欄中的值相對應。
選取每日、每小時、每月或每年的分割方式
依時間單位欄或擷取時間分區資料表時,您可以選擇分區的細目程度 (每日、每小時、每月或每年)。
每日分區是預設的分區類型。如果資料散布在廣泛的日期範圍內,或是資料會持續新增,每日分割作業就是不錯的選擇。
如果資料表的資料量很大,且涵蓋的日期範圍較短 (通常為六個月內的時間戳記值),請選擇每小時分割。如果您選擇每小時分區,請確保分區數量維持在分區限制內。
如果每個資料表的每日資料量相對較少,但日期範圍較廣,請選擇按月或按年分區。如果工作流程需要經常更新或新增跨越廣泛日期範圍 (例如超過 500 個日期) 的資料列,我們也建議使用這個選項。在這些情況下,請使用月度或年度分區,並在分區欄上進行分群,以獲得最佳效能。詳情請參閱本文中的叢集和分區資料表組合一節。
結合叢集和分區資料表
您可以將資料表分區與資料表叢集結合,以便進一步最佳化查詢,並獲得精細的排序結果。
叢集資料表包含叢集資料欄,可根據使用者定義的排序屬性排序資料。這些叢集處理資料欄中的資料會排序至儲存區塊,這些區塊的大小會根據資料表的大小進行調整。當您執行以叢集資料欄篩選的查詢時,BigQuery 只會根據叢集資料欄掃描相關區塊,而非整個資料表或資料表分區。在同時使用資料表分區和叢集的組合方法中,您會先將資料表資料分割為分區,然後再根據叢集資料欄將每個分區中的資料分群。
建立經過叢集和分區處理的資料表時,您可以獲得更精細的排序結果,如下圖所示:
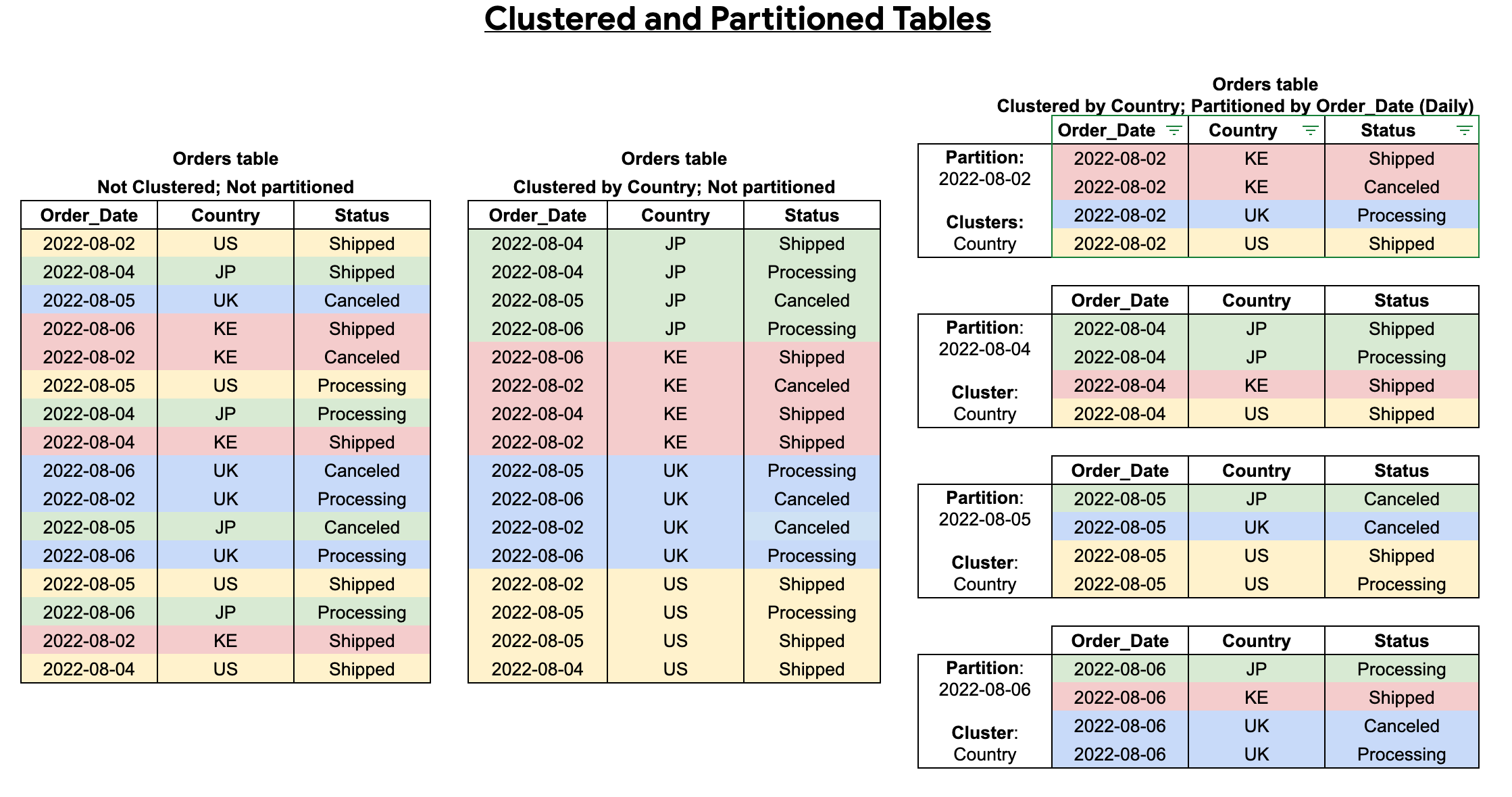
分區與資料分割的比較
資料表區塊化是指使用 [PREFIX]_YYYYMMDD 等命名前置字,將資料儲存在多個資料表中。
建議您使用分區功能,而非資料表分割功能,因為分區資料表的效能較佳。對於分割的資料表,BigQuery 必須為每個資料表保留一份結構定義和中繼資料的複本。BigQuery 也可能需要驗證每個查詢資料表的權限。這個做法也會增加查詢的負擔,並影響查詢效能。
如果您先前已建立日期資料分割資料表,可以將這些資料表轉換為擷取時間分區資料表。詳情請參閱「將日期資料分割資料表轉換成擷取時間分區資料表」。
分區修飾符
您可以使用分區修飾符參照資料表中的分區。例如,您可以使用這些指令,將資料寫入特定分區。
分區修飾符的格式為 table_name$partition_id,其中 partition_id 區段的格式取決於分區類型:
| 分區類型 | 格式 | 範例 |
|---|---|---|
| 每小時 | yyyymmddhh |
my_table$2021071205 |
| 每日 | yyyymmdd |
my_table$20210712 |
| 每月 | yyyymm |
my_table$202107 |
| 每年 | yyyy |
my_table$2021 |
| 整數範圍 | range_start |
my_table$40 |
瀏覽分區中的資料
如要瀏覽指定分區中的資料,請使用 bq head 指令搭配分區修飾符。
例如,下列指令會列出 2018-02-24 分區中 my_dataset.my_table 內前 10 列的所有欄位:
bq head --max_rows=10 'my_dataset.my_table$20180224'
匯出資料表資料
從分區資料表匯出所有資料的處理程序與從非分區資料表匯出資料相同。詳情請參閱「匯出資料表資料」。
如要從個別分區匯出資料,請使用 bq extract 指令,並將分區修飾符附加至資料表名稱。例如,my_table$20160201。您也可以將分區名稱附加至資料表名稱,以從 __NULL__ 和 __UNPARTITIONED__ 分區匯出資料,例如 my_table$__NULL__ 或 my_table$__UNPARTITIONED__。
限制
您無法使用舊版 SQL 查詢分區資料表或將查詢結果寫入分區資料表。
BigQuery 不支援以多個欄進行分區。只能使用單一資料欄來分區資料表。
時間單位資料欄分區資料表有下列限制:
- 分區欄必須是純量
DATE、TIMESTAMP或DATETIME資料欄。資料欄模式可以是REQUIRED或NULLABLE,但不能是REPEATED(以陣列為基礎)。 - 此外,分區資料欄必須是頂層欄位。您無法將
RECORD(STRUCT) 中的分葉欄位當成分區資料欄使用。
如要瞭解時間單位資料欄分區資料表,請參閱「建立時間單位資料欄分區資料表」一文。
整數範圍分區資料表有下列幾項限制:
- 分區資料欄必須是
INTEGER資料欄。資料欄模式可能是REQUIRED或NULLABLE,但不能是REPEATED(以陣列為基礎)。 - 此外,分區資料欄必須是頂層欄位。您無法將
RECORD(STRUCT) 中的分葉欄位當成分區資料欄使用。
如要瞭解整數範圍分區資料表,請參閱「建立整數範圍分區資料表」。
配額與限制
BigQuery 中的分區資料表已定義了限制。
配額和限制也適用於您可以針對分區資料表執行的各類型工作,包括:
如要深入瞭解所有配額和限制,請參閱配額與限制一文。
資料表價格
在 BigQuery 中建立和使用分區資料表時,向您收取的費用是以在分區中儲存的資料量以及針對資料執行的查詢量為計算依據:
許多分區資料表作業都是免費的,包括將資料載入分區、複製分區,以及從分區匯出資料。雖然這些作業都是免費的,但仍受限於 BigQuery 的配額和限制。如需所有免費作業的相關資訊,請參閱定價頁面上的免費作業項目一節。
如要瞭解在 BigQuery 中控管費用的最佳做法,請參閱「在 BigQuery 中控管費用」
表格安全性
分區資料表的存取權控管與標準資料表的存取權控管相同。詳情請參閱「資料表存取權控管簡介」。