Gestire i suggerimenti per partizioni e cluster
Questo documento descrive il funzionamento del suggeritore di partizioni e cluster, come visualizzare i suggerimenti e gli approfondimenti e come applicare i suggerimenti di partizionamento e clustering.
Come funziona il sistema di raccomandazione
Il suggeritore di partizionamento e clustering BigQuery genera suggerimenti per il partizionamento o il clustering per ottimizzare le tabelle BigQuery. Il sistema di suggerimenti analizza i workflow nelle tabelle BigQuery e offre suggerimenti per ottimizzare meglio i workflow e i costi delle query utilizzando il partizionamento o il clustering delle tabelle.
Per saperne di più sul servizio Recommender, consulta la panoramica di Recommender.
Il suggeritore di partizionamento e clustering utilizza i dati di esecuzione del carico di lavoro del progetto degli ultimi 30 giorni per analizzare ogni tabella BigQuery per configurazioni di partizionamento e clustering non ottimali. Il sistema di suggerimenti utilizza anche il machine learning per prevedere in che modo l'esecuzione del workload potrebbe essere ottimizzata con diverse configurazioni di partizionamento o clustering. Se il motore per suggerimenti rileva che il partizionamento o il clustering di una tabella comporta risparmi significativi, genera un suggerimento. Il sistema di suggerimenti per il partizionamento e il clustering genera i seguenti tipi di suggerimenti:
| Tipo di tabella esistente | Sottotipo di suggerimento | Esempio di suggerimento |
|---|---|---|
| Non partizionato, non raggruppato in cluster | Partition | "Risparmia circa 64 ore di slot al mese eseguendo il partizionamento in base a column_C per DAY" |
| Non partizionato, non raggruppato in cluster | Cluster | "Risparmia circa 64 ore di slot al mese eseguendo il clustering in base a column_C" |
| Partizionata, non in cluster | Cluster | "Risparmia circa 64 ore di slot al mese eseguendo il clustering in base a column_C" |
Ogni consiglio è composto da tre parti:
- Indicazioni per partizionare o raggruppare una tabella specifica
- La colonna specifica di una tabella da partizionare o raggruppare
- Risparmi mensili stimati per l'applicazione del consiglio
Per calcolare i potenziali risparmi del workload, il suggeritore presuppone che i dati storici del workload di esecuzione degli ultimi 30 giorni rappresentino il workload futuro.
L'API Recommender restituisce anche informazioni sul workload della tabella sotto forma di approfondimenti. Gli approfondimenti sono risultati che ti aiutano a comprendere il carico di lavoro del tuo progetto, fornendo maggiori informazioni su come un suggerimento per una partizione o un cluster potrebbe migliorare i costi del carico di lavoro.
Limitazioni
Il suggeritore per il partizionamento e il clustering non supporta le tabelle BigQuery con SQL precedente. Quando genera un suggerimento, il motore per suggerimenti esclude qualsiasi query SQL precedente dalla sua analisi. Inoltre, l'applicazione dei suggerimenti per le partizioni alle tabelle BigQuery con SQL precedente interrompe tutti i flussi di lavoro SQL precedenti in quella tabella.
Prima di applicare i suggerimenti per le partizioni, esegui la migrazione dei flussi di lavoro SQL precedente a GoogleSQL.
BigQuery non supporta la modifica dello schema di partizionamento di una tabella sul posto. Puoi modificare il partizionamento di una tabella solo su una copia della tabella. Per saperne di più, consulta Applicare i suggerimenti per le partizioni.
Località
Il sistema di suggerimenti per il partizionamento e il clustering è disponibile nelle seguenti posizioni di elaborazione:
| Descrizione della regione | Nome regione | Dettagli | |
|---|---|---|---|
| Asia Pacifico | |||
| Delhi | asia-south2 |
||
| Hong Kong | asia-east2 |
||
| Giacarta | asia-southeast2 |
||
| Mumbai | asia-south1 |
||
| Osaka | asia-northeast2 |
||
| Seul | asia-northeast3 |
||
| Singapore | asia-southeast1 |
||
| Sydney | australia-southeast1 |
||
| Taiwan | asia-east1 |
||
| Tokyo | asia-northeast1 |
||
| Europa | |||
| Belgio | europe-west1 |
|
|
| Berlino | europe-west10 |
|
|
| Multiregione EU | eu |
||
| Francoforte | europe-west3 |
||
| Londra | europe-west2 |
|
|
| Paesi Bassi | europe-west4 |
|
|
| Zurigo | europe-west6 |
|
|
| Americhe | |||
| Iowa | us-central1 |
|
|
| Las Vegas | us-west4 |
||
| Los Angeles | us-west2 |
||
| Montréal | northamerica-northeast1 |
|
|
| Virginia del Nord | us-east4 |
||
| Oregon | us-west1 |
|
|
| Salt Lake City | us-west3 |
||
| San Paolo | southamerica-east1 |
|
|
| Toronto | northamerica-northeast2 |
|
|
| Stati Uniti (multiregionale) | us |
||
Prima di iniziare
- Assicurati che Gemini in BigQuery sia abilitato per il tuo progetto Google Cloud .
- Abilita l'API Recommender.
Autorizzazioni obbligatorie
Per ottenere le autorizzazioni necessarie per accedere ai suggerimenti su partizioni e cluster, chiedi all'amministratore di concederti il ruolo IAM BigQuery Partitioning Clustering Recommender Viewer (roles/recommender.bigqueryPartitionClusterViewer).
Per saperne di più sulla concessione dei ruoli, consulta Gestisci l'accesso a progetti, cartelle e organizzazioni.
Questo ruolo predefinito contiene le autorizzazioni necessarie per accedere ai suggerimenti su partizioni e cluster. Per vedere quali sono esattamente le autorizzazioni richieste, espandi la sezione Autorizzazioni obbligatorie:
Autorizzazioni obbligatorie
Per accedere ai suggerimenti per partizioni e cluster sono necessarie le seguenti autorizzazioni:
-
recommender.bigqueryPartitionClusterRecommendations.get -
recommender.bigqueryPartitionClusterRecommendations.list
Potresti anche ottenere queste autorizzazioni con ruoli personalizzati o altri ruoli predefiniti.
Per saperne di più sui ruoli e sulle autorizzazioni IAM in BigQuery, consulta Introduzione a IAM.
Visualizza i suggerimenti
Questa sezione descrive come visualizzare i suggerimenti e gli approfondimenti su partizioni e cluster utilizzando la console Google Cloud , Google Cloud CLI o l'API Recommender.
Seleziona una delle seguenti opzioni:
Console
Nella console Google Cloud , vai alla pagina BigQuery.
Nel menu di navigazione, fai clic su Suggerimenti.
La scheda Consigli elenca tutti i consigli disponibili per il tuo progetto.
Nel riquadro Ottimizza i costi dei workload BigQuery, fai clic su Visualizza tutto.
La tabella dei suggerimenti sui costi elenca tutti i suggerimenti generati per il progetto attuale. Ad esempio, lo screenshot seguente mostra che il sistema di suggerimenti ha analizzato la tabella
example_tablee poi ha consigliato di raggruppare la colonnaexample_columnper risparmiare una quantità approssimativa di byte e slot.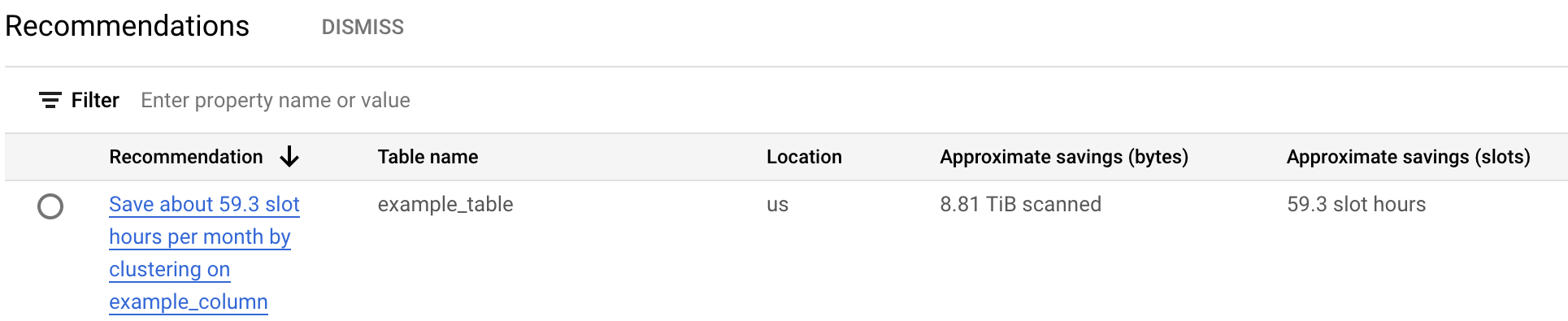
Per visualizzare ulteriori informazioni sull'insight e sul suggerimento della tabella, fai clic su un suggerimento.
gcloud
Per visualizzare i suggerimenti per partizioni o cluster per un progetto specifico, utilizza
il comando gcloud recommender recommendations list:
gcloud recommender recommendations list \
--project=PROJECT_NAME \
--location=REGION_NAME \
--recommender=google.bigquery.table.PartitionClusterRecommender \
--format=FORMAT_TYPE \
Sostituisci quanto segue:
PROJECT_NAME: il nome del progetto che contiene la tabella BigQueryREGION_NAME: la regione in cui si trova il progettoFORMAT_TYPE: un formato di output di gcloud CLI supportato, ad esempio JSON
| Proprietà | Pertinente per il sottotipo | Descrizione |
|---|---|---|
recommenderSubtype |
Partiziona o raggruppa | Indica il tipo di consiglio. |
content.overview.partitionColumn |
Partition | Nome della colonna di partizionamento consigliata. |
content.overview.partitionTimeUnit |
Partition | Unità di tempo di partizionamento consigliata. Ad esempio, DAY significa che il
consiglio è di avere partizioni giornaliere nella colonna consigliata. |
content.overview.clusterColumns |
Cluster | Nomi delle colonne di clustering consigliati. |
- Per ulteriori informazioni sugli altri campi nella risposta del sistema di suggerimenti, vedi Risorsa REST:
projects.locations.recommendersrecommendation. - Per ulteriori informazioni sull'utilizzo dell'API Recommender, consulta Utilizzo dell'API - Suggerimenti.
Per visualizzare gli approfondimenti sulle tabelle utilizzando gcloud CLI, utilizza il
comando gcloud recommender insights list:
gcloud recommender insights list \
--project=PROJECT_NAME \
--location=REGION_NAME \
--insight-type=google.bigquery.table.StatsInsight \
--format=FORMAT_TYPE \
Sostituisci quanto segue:
PROJECT_NAME: il nome del progetto che contiene la tabella BigQueryREGION_NAME: la regione in cui si trova il progettoFORMAT_TYPE: un formato di output di gcloud CLI supportato, ad esempio JSON
| Proprietà | Pertinente per il sottotipo | Descrizione |
|---|---|---|
content.existingPartitionColumn |
Cluster | Eventuale colonna di partizionamento esistente |
content.tableSizeTb |
Tutti | Dimensioni della tabella in terabyte |
content.bytesReadMonthly |
Tutti | Byte letti mensilmente dalla tabella |
content.slotMsConsumedMonthly |
Tutti | Millisecondi slot mensili utilizzati dal workload in esecuzione sulla tabella |
content.queryJobsCountMonthly |
Tutti | Conteggio mensile dei job in esecuzione sulla tabella |
- Per saperne di più sugli altri campi nella risposta degli insight, consulta Risorsa REST:
projects.locations.insightTypes.insights. - Per saperne di più sull'utilizzo degli approfondimenti, consulta Utilizzo dell'API - Approfondimenti.
API REST
Per visualizzare i suggerimenti per partizioni o cluster per un progetto specifico, utilizza l'API REST. Per ogni comando, devi fornire un token di autenticazione, che puoi ottenere utilizzando gcloud CLI. Per saperne di più su come ottenere un token di autenticazione, consulta Metodi per ottenere un token ID.
Puoi utilizzare la richiesta curl list per visualizzare tutti i consigli per un
progetto specifico:
curl
-H "Authorization: Bearer $GCLOUD_AUTH_TOKEN"
-H "x-goog-user-project: PROJECT_NAME" https://recommender.googleapis.com/v1/projects/my-project/locations/us/recommenders/google.bigquery.table.PartitionClusterRecommender/recommendations
Sostituisci quanto segue:
GCLOUD_AUTH_TOKEN: il nome di un token di accesso gcloud CLI validoPROJECT_NAME: il nome del progetto che contiene la tabella BigQuery
| Proprietà | Pertinente per il sottotipo | Descrizione |
|---|---|---|
recommenderSubtype |
Partiziona o raggruppa | Indica il tipo di consiglio. |
content.overview.partitionColumn |
Partition | Nome della colonna di partizionamento consigliata. |
content.overview.partitionTimeUnit |
Partition | Unità di tempo di partizionamento consigliata. Ad esempio, DAY significa che il
consiglio è di avere partizioni giornaliere nella colonna consigliata. |
content.overview.clusterColumns |
Cluster | Nomi delle colonne di clustering consigliati. |
- Per ulteriori informazioni sugli altri campi nella risposta del sistema di suggerimenti, vedi Risorsa REST:
projects.locations.recommendersrecommendation. - Per ulteriori informazioni sull'utilizzo dell'API Recommender, consulta Utilizzo dell'API - Suggerimenti.
Per visualizzare gli approfondimenti sulle tabelle utilizzando l'API REST, esegui questo comando:
curl -H "Authorization: Bearer $GCLOUD_AUTH_TOKEN" -H "x-goog-user-project: PROJECT_NAME" https://recommender.googleapis.com/v1/projects/my-project/locations/us/insightTypes/google.bigquery.table.StatsInsight/insights
Sostituisci quanto segue:
GCLOUD_AUTH_TOKEN: il nome di un token di accesso gcloud CLI validoPROJECT_NAME: il nome del progetto che contiene la tabella BigQuery
| Proprietà | Pertinente per il sottotipo | Descrizione |
|---|---|---|
content.existingPartitionColumn |
Cluster | Eventuale colonna di partizionamento esistente |
content.tableSizeTb |
Tutti | Dimensioni della tabella in terabyte |
content.bytesReadMonthly |
Tutti | Byte letti mensilmente dalla tabella |
content.slotMsConsumedMonthly |
Tutti | Millisecondi slot mensili utilizzati dal workload in esecuzione sulla tabella |
content.queryJobsCountMonthly |
Tutti | Conteggio mensile dei job in esecuzione sulla tabella |
- Per saperne di più sugli altri campi nella risposta degli insight, consulta Risorsa REST:
projects.locations.insightTypes.insights. - Per saperne di più sull'utilizzo degli approfondimenti, consulta Utilizzo dell'API - Approfondimenti.
Applica i suggerimenti per i cluster
Per applicare i suggerimenti per i cluster, esegui una delle seguenti operazioni:
- Applicare i cluster direttamente alla tabella originale
- Applicare i cluster a una tabella copiata
- Applicare i cluster in una vista materializzata
Applica i cluster direttamente alla tabella originale
Puoi applicare i suggerimenti per il clustering direttamente a una tabella BigQuery esistente. Questo metodo è più rapido rispetto all'applicazione dei suggerimenti a una tabella copiata, ma non conserva una tabella di backup.
Segui questi passaggi per applicare una nuova specifica di clustering a tabelle non partizionate o partizionate.
Nello strumento bq, aggiorna la specifica di clustering della tabella in modo che corrisponda al nuovo clustering:
bq update --clustering_fields=CLUSTER_COLUMN DATASET.ORIGINAL_TABLE
Sostituisci quanto segue:
CLUSTER_COLUMN: la colonna su cui stai eseguendo il clustering, ad esempiomycolumnDATASET: il nome del set di dati contenente la tabella, ad esempiomydatasetORIGINAL_TABLE: il nome della tabella originale, ad esempiomytable
Puoi anche chiamare il metodo API
tables.updateotables.patchper modificare la specifica di clustering.Per raggruppare tutte le righe in base alla nuova specifica di clustering, esegui la seguente istruzione
UPDATE:UPDATE DATASET.ORIGINAL_TABLE SET CLUSTER_COLUMN=CLUSTER_COLUMN WHERE true
Applicare i cluster a una tabella copiata
Quando applichi i suggerimenti per il clustering a una tabella BigQuery, puoi prima copiare la tabella originale e poi applicare il suggerimento alla tabella copiata. Questo metodo garantisce che i dati originali vengano conservati se è necessario eseguire il rollback della modifica alla configurazione del clustering.
Puoi utilizzare questo metodo per applicare i suggerimenti di clustering sia alle tabelle non partizionate sia a quelle partizionate.
Nella console Google Cloud , vai alla pagina BigQuery.
Nell'editor di query, crea una tabella vuota con gli stessi metadati (incluse le specifiche di clustering) della tabella originale utilizzando l'operatore
LIKE:CREATE TABLE DATASET.COPIED_TABLE LIKE DATASET.ORIGINAL_TABLE
Sostituisci quanto segue:
DATASET: il nome del set di dati contenente la tabella, ad esempiomydatasetCOPIED_TABLE: un nome per la tabella copiata, ad esempiocopy_mytableORIGINAL_TABLE: il nome della tabella originale, ad esempiomytable
Nella console Google Cloud , apri l'editor di Cloud Shell.
Nell'editor di Cloud Shell, aggiorna la specifica di clustering della tabella copiata in modo che corrisponda al clustering consigliato utilizzando il comando
bq update:bq update --clustering_fields=CLUSTER_COLUMN DATASET.COPIED_TABLE
Sostituisci
CLUSTER_COLUMNcon la colonna su cui stai eseguendo il clustering, ad esempiomycolumn.Puoi anche chiamare il metodo API
tables.updateotables.patchper modificare la specifica di clustering.Nell'editor di query, recupera lo schema della tabella con la configurazione di partizionamento e clustering della tabella originale, se esiste un partizionamento o un clustering. Puoi recuperare lo schema visualizzando la visualizzazione
INFORMATION_SCHEMA.TABLESdella tabella originale:SELECT ddl FROM DATASET.INFORMATION_SCHEMA.TABLES WHERE table_name = 'DATASET.ORIGINAL_TABLE;'
L'output è l'istruzione DDL (Data Definition Language) completa di ORIGINAL_TABLE, inclusa la clausola
PARTITION BY. Per ulteriori informazioni sugli argomenti nell'output DDL, vedi l'istruzioneCREATE TABLE.L'output DDL indica il tipo di partizionamento nella tabella originale:
Tipo di partizionamento Esempio di output Non partizionato La clausola PARTITION BYè assente.Partizionato per colonna della tabella PARTITION BY c0PARTITION BY DATE(c0)PARTITION BY DATETIME_TRUNC(c0, MONTH)Partizionata per tempo di importazione PARTITION BY _PARTITIONDATEPARTITION BY DATETIME_TRUNC(_PARTITIONTIME, MONTH)Importa i dati nella tabella copiata. La procedura che utilizzi si basa sul tipo di partizione.
- Se la tabella originale non è partizionata o è partizionata in base a una colonna della tabella,
importa i dati dalla tabella originale alla tabella copiata:
INSERT INTO DATASET.COPIED_TABLE SELECT * FROM DATASET.ORIGINAL_TABLE
Se la tabella originale è partizionata in base alla data di importazione:
Recupera l'elenco delle colonne per formare l'espressione di importazione dati utilizzando la visualizzazione
INFORMATION_SCHEMA.COLUMNS:SELECT ARRAY_TO_STRING(( SELECT ARRAY( SELECT column_name FROM DATASET.INFORMATION_SCHEMA.COLUMNS WHERE table_name = 'ORIGINAL_TABLE')), ", ")
L'output è un elenco di nomi di colonna separati da virgole.
Importa i dati dalla tabella originale a quella copiata:
INSERT DATASET.COPIED_TABLE (COLUMN_NAMES, _PARTITIONTIME) SELECT *, _PARTITIONTIME FROM DATASET.ORIGINAL_TABLE
Sostituisci
COLUMN_NAMEScon l'elenco di colonne che era l'output del passaggio precedente, separato da virgole, ad esempiocol1, col2, col3.
Ora hai una tabella copiata in cluster con gli stessi dati della tabella originale. Nei passaggi successivi, sostituisci la tabella originale con una tabella appena raggruppata.
- Se la tabella originale non è partizionata o è partizionata in base a una colonna della tabella,
importa i dati dalla tabella originale alla tabella copiata:
Rinomina la tabella originale in una tabella di backup:
ALTER TABLE DATASET.ORIGINAL_TABLE RENAME TO DATASET.BACKUP_TABLE
Sostituisci
BACKUP_TABLEcon un nome per la tabella di backup, ad esempiobackup_mytable.Rinomina la tabella copiata con il nome della tabella originale:
ALTER TABLE DATASET.COPIED_TABLE RENAME TO DATASET.ORIGINAL_TABLE
La tabella originale è ora raggruppata in cluster in base al suggerimento di clustering.
- Accesso e autorizzazioni, ad esempio autorizzazioni IAM, accesso a livello di riga o accesso a livello di colonna.
- Elementi della tabella come cloni della tabella, snapshot della tabella o indici di ricerca.
- Lo stato di tutti i processi di tabella in corso, ad esempio le viste materializzate o i job eseguiti durante la copia della tabella.
- La possibilità di accedere ai dati storici delle tabelle utilizzando lo spostamento cronologico.
- Qualsiasi metadato associato alla tabella originale, ad esempio
table_option_listocolumn_option_list. Per maggiori informazioni, consulta Istruzioni del linguaggio di definizione dei dati.
In caso di problemi, devi eseguire manualmente la migrazione degli artefatti interessati alla nuova tabella.
Dopo aver esaminato la tabella in cluster, puoi eliminare facoltativamente la tabella di backup con il seguente comando:DROP TABLE DATASET.BACKUP_TABLE
Applicare i cluster in una vista materializzata
Puoi creare una vista materializzata della tabella per archiviare i dati della tabella originale con il consiglio applicato. L'utilizzo di viste materializzate per applicare i consigli garantisce che i dati in cluster vengano mantenuti aggiornati tramite aggiornamenti automatici. Esistono considerazioni sui prezzi quando esegui query, gestisci e memorizzi le viste materializzate. Per scoprire come creare una vista materializzata in cluster, consulta Viste materializzate in cluster.Applica i suggerimenti di partizionamento
Per applicare i suggerimenti per le partizioni, devi applicarli a una copia della tabella originale. BigQuery non supporta la modifica dello schema di partizionamento di una tabella sul posto, ad esempio la modifica di una tabella non partizionata in una tabella partizionata, la modifica dello schema di partizionamento di una tabella o la creazione di una vista materializzata con uno schema di partizionamento diverso da quello della tabella di base. Puoi modificare il partizionamento di una tabella solo su una copia della tabella.
Applica i suggerimenti di partizionamento a una tabella copiata
Quando applichi i suggerimenti per le partizioni a una tabella BigQuery, devi prima copiare la tabella originale e poi applicare il suggerimento alla tabella copiata. Questo approccio garantisce la conservazione dei dati originali se devi eseguire il rollback di una partizione.
La seguente procedura utilizza una raccomandazione di esempio per partizionare una tabella in base all'unità di tempo della partizione DAY.
Crea una tabella copiata utilizzando i suggerimenti per le partizioni:
CREATE TABLE DATASET.COPIED_TABLE PARTITION BY DATE_TRUNC(PARTITION_COLUMN, DAY) AS SELECT * FROM DATASET.ORIGINAL_TABLE
Sostituisci quanto segue:
DATASET: il nome del set di dati contenente la tabella, ad esempiomydatasetCOPIED_TABLE: un nome per la tabella copiata, ad esempiocopy_mytablePARTITION_COLUMN: la colonna in base alla quale stai partizionando, ad esempiomycolumn
Per saperne di più sulla creazione di tabelle partizionate, consulta Creazione di tabelle partizionate.
Rinomina la tabella originale in una tabella di backup:
ALTER TABLE DATASET.ORIGINAL_TABLE RENAME TO DATASET.BACKUP_TABLE
Sostituisci
BACKUP_TABLEcon un nome per la tabella di backup, ad esempiobackup_mytable.Rinomina la tabella copiata con il nome della tabella originale:
ALTER TABLE DATASET.COPIED_TABLE RENAME TO DATASET.ORIGINAL_TABLE
La tabella originale è ora partizionata in base al suggerimento per la partizione.
- Accesso e autorizzazioni, ad esempio autorizzazioni IAM, accesso a livello di riga o accesso a livello di colonna.
- Elementi della tabella come cloni della tabella, snapshot della tabella o indici di ricerca.
- Lo stato di tutti i processi di tabella in corso, ad esempio le viste materializzate o i job eseguiti durante la copia della tabella.
- La possibilità di accedere ai dati storici delle tabelle utilizzando lo spostamento cronologico.
- Qualsiasi metadato associato alla tabella originale, ad esempio
table_option_listocolumn_option_list. Per maggiori informazioni, consulta Istruzioni del linguaggio di definizione dei dati. - Possibilità di utilizzare SQL precedente per scrivere i risultati delle query in tabelle partizionate. L'utilizzo di SQL precedente non è completamente supportato nelle tabelle partizionate. Una soluzione consiste nell'eseguire la migrazione dei flussi di lavoro SQL precedente in GoogleSQL prima di applicare un suggerimento di partizione.
In caso di problemi, devi eseguire manualmente la migrazione degli artefatti interessati alla nuova tabella.
Dopo aver esaminato la tabella partizionata, puoi eliminare facoltativamente la tabella di backup con il seguente comando:DROP TABLE DATASET.BACKUP_TABLE
Prezzi
Quando applichi un consiglio a una tabella, puoi sostenere i seguenti costi:
- Costi di elaborazione. Quando applichi un suggerimento, esegui una query Data Definition Language (DDL) o Data Manipulation Language (DML) nel tuo progetto BigQuery.
- Costi di archiviazione. Se utilizzi il metodo di copia di una tabella, utilizzi spazio di archiviazione aggiuntivo per la tabella copiata (o di backup).
Si applicano addebiti standard per l'elaborazione e l'archiviazione a seconda dell'account di fatturazione associato al progetto. Per ulteriori informazioni, vedi Prezzi di BigQuery.
Risoluzione dei problemi
Problema:non vengono visualizzati suggerimenti per una tabella specifica.
I consigli per le partizioni potrebbero non essere visualizzati per le tabelle che soddisfano questi criteri:
- La tabella è inferiore a 100 GB.
- La tabella è già partizionata o raggruppata in cluster.
I consigli sui cluster potrebbero non essere visualizzati per le tabelle che soddisfano questi criteri:
- La tabella ha dimensioni inferiori a 10 GB.
- La tabella è già in cluster.
I suggerimenti di partizionamento e clustering potrebbero essere eliminati quando:
- La tabella ha un costo di scrittura elevato dovuto alle operazioni di data manipulation language (DML).
- La tabella non è stata letta negli ultimi 30 giorni.
- Il risparmio mensile stimato è troppo insignificante (meno di un'ora di slot di risparmio).