In dieser Anleitung erfahren Sie, wie Sie ein ONNX-Modell (Open Neural Network Exchange) importieren, das mit scikit-learn trainiert wurde. Sie importieren das Modell in ein BigQuery-Dataset und verwenden es, um Vorhersagen mit einer SQL-Abfrage zu treffen.
ONNX bietet ein einheitliches Format für die Darstellung von Frameworks für maschinelles Lernen (ML). Die BigQuery ML-Unterstützung für ONNX bietet folgende Möglichkeiten:
- Trainieren eines Modells mit Ihrem bevorzugten Framework.
- Konvertieren des Modells in das ONNX-Modellformat.
- ONNX-Modell in BigQuery importieren und Vorhersagen mit BigQuery ML treffen.
Ziele
- Modell mit scikit-learn erstellen und trainieren
- Konvertieren Sie das Modell mit sklearn-onnx in das ONNX-Format.
- Verwenden Sie die
CREATE MODEL-Anweisung, um das ONNX-Modell in BigQuery zu importieren. - Verwenden Sie die Funktion
ML.PREDICT, um Vorhersagen mit dem importierten ONNX-Modell zu treffen.
Kosten
In diesem Dokument verwenden Sie die folgenden kostenpflichtigen Komponenten von Google Cloud:
Mit dem Preisrechner können Sie eine Kostenschätzung für Ihre voraussichtliche Nutzung vornehmen.
Nach Abschluss der in diesem Dokument beschriebenen Aufgaben können Sie weitere Kosten vermeiden, indem Sie die erstellten Ressourcen löschen. Weitere Informationen finden Sie unter Bereinigen.
Hinweise
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the BigQuery and Cloud Storage APIs.
- Prüfen Sie, ob Sie die erforderlichen Berechtigungen haben, um die Aufgaben in diesem Dokument ausführen zu können.
- BigQuery Studio Admin (
roles/bigquery.studioAdmin) - Storage Object Creator (
roles/storage.objectCreator) -
In the Google Cloud console, go to the IAM page.
Go to IAM - Select the project.
-
In the Principal column, find all rows that identify you or a group that you're included in. To learn which groups you're included in, contact your administrator.
- For all rows that specify or include you, check the Role column to see whether the list of roles includes the required roles.
-
In the Google Cloud console, go to the IAM page.
IAM aufrufen - Wählen Sie das Projekt aus.
- Klicken Sie auf Zugriffsrechte erteilen.
-
Geben Sie im Feld Neue Hauptkonten Ihre Nutzer-ID ein. Das ist in der Regel die E‑Mail-Adresse eines Google-Kontos.
- Wählen Sie in der Liste Rolle auswählen eine Rolle aus.
- Klicken Sie auf Weitere Rolle hinzufügen, wenn Sie weitere Rollen zuweisen möchten.
- Klicken Sie auf Speichern.
- Erstellen Sie einen Cloud Storage-Bucket zum Speichern des Modells.
- Laden Sie das ONNX-Modell in Ihren Cloud Storage-Bucket hoch.
Rufen Sie in der Google Cloud Console die Seite BigQuery auf.
Klicken Sie im Bereich Explorer auf den Namen Ihres Projekts.
Klicken Sie auf Aktionen ansehen > Dataset erstellen.
Führen Sie auf der Seite Dataset erstellen die folgenden Schritte aus:
Geben Sie unter Dataset-ID
bqml_tutorialein.Wählen Sie als Standorttyp die Option Mehrere Regionen und dann USA (mehrere Regionen in den USA) aus.
Übernehmen Sie die verbleibenden Standardeinstellungen unverändert und klicken Sie auf Dataset erstellen.
Erstellen Sie ein Dataset mit dem Namen
bqml_tutorial, wobei der Datenspeicherort aufUSund die Beschreibung aufBigQuery ML tutorial datasetfestgelegt ist:bq --location=US mk -d \ --description "BigQuery ML tutorial dataset." \ bqml_tutorial
Anstelle des Flags
--datasetverwendet der Befehl die verkürzte Form-d. Wenn Sie-dund--datasetauslassen, wird standardmäßig ein Dataset erstellt.Prüfen Sie, ob das Dataset erstellt wurde:
bq lsRufen Sie in der Google Cloud Console die Seite BigQuery Studio auf.
Geben Sie im Abfrageeditor die folgende
CREATE MODEL-Anweisung ein.CREATE OR REPLACE MODEL `bqml_tutorial.imported_onnx_model` OPTIONS (MODEL_TYPE='ONNX', MODEL_PATH='BUCKET_PATH')
Ersetzen Sie
BUCKET_PATHdurch den Pfad zum Modell, das Sie in Cloud Storage hochgeladen haben. Wenn Sie das Beispielmodell verwenden, ersetzen SieBUCKET_PATHdurch den folgenden Wert:gs://cloud-samples-data/bigquery/ml/onnx/pipeline_rf.onnx.Nach Abschluss des Vorgangs erhalten Sie in etwa folgende Meldung:
Successfully created model named imported_onnx_model.Ihr neues Modell wird im Bereich Ressourcen angezeigt. Modelle sind am Modellsymbol
 zu erkennen.
Wenn Sie das neue Modell im Bereich Ressourcen auswählen, werden Informationen zum Modell neben dem Abfrageeditor angezeigt.
zu erkennen.
Wenn Sie das neue Modell im Bereich Ressourcen auswählen, werden Informationen zum Modell neben dem Abfrageeditor angezeigt.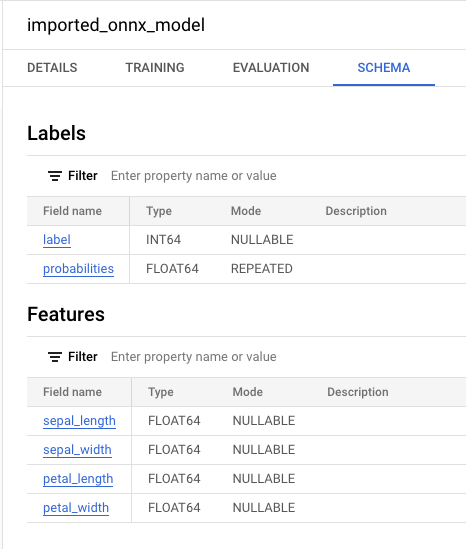
Importieren Sie das ONNX-Modell aus Cloud Storage, indem Sie die folgende
CREATE MODEL-Anweisung eingeben.bq query --use_legacy_sql=false \ "CREATE OR REPLACE MODEL `bqml_tutorial.imported_onnx_model` OPTIONS (MODEL_TYPE='ONNX', MODEL_PATH='BUCKET_PATH')"
Ersetzen Sie
BUCKET_PATHdurch den Pfad zum Modell, das Sie in Cloud Storage hochgeladen haben. Wenn Sie das Beispielmodell verwenden, ersetzen SieBUCKET_PATHdurch den folgenden Wert:gs://cloud-samples-data/bigquery/ml/onnx/pipeline_rf.onnx.Nach Abschluss des Vorgangs erhalten Sie in etwa folgende Meldung:
Successfully created model named imported_onnx_model.Nachdem Sie das Modell importiert haben, prüfen Sie, ob es im Dataset angezeigt wird.
bq ls bqml_tutorial
Die Ausgabe sieht etwa so aus:
tableId Type --------------------- ------- imported_onnx_model MODEL
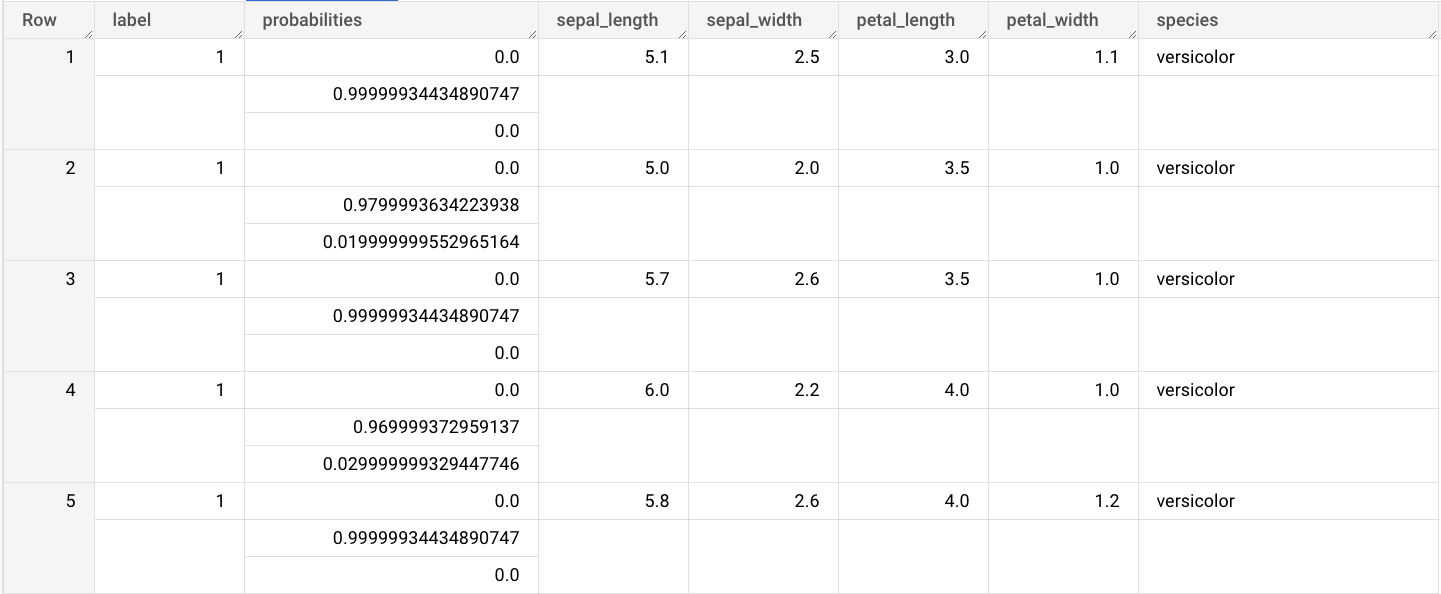
sepal_lengthsepal_widthpetal_lengthpetal_widthRufen Sie die Seite BigQuery Studio auf.
Geben Sie im Abfrageeditor diese Abfrage mit der Funktion
ML.PREDICTein.SELECT * FROM ML.PREDICT(MODEL `bqml_tutorial.imported_onnx_model`, ( SELECT * FROM `bigquery-public-data.ml_datasets.iris` ) )
Die Abfrageergebnisse sehen in etwa so aus:
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
Optional: Dataset löschen
- Weitere Informationen zum Importieren von ONNX-Modellen finden Sie unter
CREATE MODEL-Anweisung für ONNX-Modelle. - Weitere Informationen zu verfügbaren ONNX-Convertern und Anleitungen finden Sie unter In ONNX-Format konvertieren.
- Einführung in BigQuery ML
- Informationen zur Verwendung von BigQuery ML finden Sie unter Modelle für maschinelles Lernen in BigQuery ML erstellen.
Erforderliche Rollen
Wenn Sie ein neues Projekt erstellen, sind Sie der Projektinhaber und erhalten alle erforderlichen IAM-Berechtigungen (Identity and Access Management), die Sie für diese Anleitung benötigen.
Wenn Sie ein vorhandenes Projekt verwenden, gehen Sie so vor.
Make sure that you have the following role or roles on the project:
Check for the roles
Grant the roles
Weitere Informationen zu IAM-Berechtigungen in BigQuery finden Sie unter IAM-Berechtigungen.
Optional: Modell trainieren und in das ONNX-Format konvertieren
Die folgenden Codebeispiele zeigen, wie Sie ein Klassifizierungsmodell mit scikit-learn trainieren und die resultierende Pipeline in das ONNX-Format konvertieren. In dieser Anleitung wird ein vorgefertigtes Beispielmodell verwendet, das unter gs://cloud-samples-data/bigquery/ml/onnx/pipeline_rf.onnx gespeichert ist. Wenn Sie das Beispielmodell verwenden, müssen Sie diese Schritte nicht ausführen.
Klassifizierungsmodell mit scikit-learn trainieren
Mit dem folgenden Beispielcode können Sie eine scikit-learn-Pipeline für das Dataset Iris erstellen und trainieren. Eine Anleitung zum Installieren und Verwenden von scikit-learn finden Sie in der Installationsanleitung für scikit-learn.
import numpy
from sklearn.datasets import load_iris
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.ensemble import RandomForestClassifier
data = load_iris()
X = data.data[:, :4]
y = data.target
ind = numpy.arange(X.shape[0])
numpy.random.shuffle(ind)
X = X[ind, :].copy()
y = y[ind].copy()
pipe = Pipeline([('scaler', StandardScaler()),
('clr', RandomForestClassifier())])
pipe.fit(X, y)
Pipeline in ein ONNX-Modell konvertieren
Verwenden Sie den folgenden Beispielcode in sklearn-onnx, um die scikit-learn-Pipeline in ein ONNX-Modell mit dem Namen pipeline_rf.onnx zu konvertieren.
from skl2onnx import convert_sklearn
from skl2onnx.common.data_types import FloatTensorType
# Disable zipmap as it is not supported in BigQuery ML.
options = {id(pipe): {'zipmap': False}}
# Define input features. scikit-learn does not store information about the
# training dataset. It is not always possible to retrieve the number of features
# or their types. That's why the function needs another argument called initial_types.
initial_types = [
('sepal_length', FloatTensorType([None, 1])),
('sepal_width', FloatTensorType([None, 1])),
('petal_length', FloatTensorType([None, 1])),
('petal_width', FloatTensorType([None, 1])),
]
# Convert the model.
model_onnx = convert_sklearn(
pipe, 'pipeline_rf', initial_types=initial_types, options=options
)
# And save.
with open('pipeline_rf.onnx', 'wb') as f:
f.write(model_onnx.SerializeToString())
ONNX-Modell in Cloud Storage hochladen
Nachdem Sie das Modell gespeichert haben, gehen Sie so vor:
Dataset erstellen
Erstellen Sie ein BigQuery-Dataset zum Speichern Ihres ML-Modells.
Konsole
bq
Wenn Sie ein neues Dataset erstellen möchten, verwenden Sie den Befehl bq mk mit dem Flag --location. Eine vollständige Liste der möglichen Parameter finden Sie in der bq mk --dataset-Befehlsreferenz.
API
Rufen Sie die Methode datasets.insert mit einer definierten Dataset-Ressource auf.
{ "datasetReference": { "datasetId": "bqml_tutorial" } }
BigQuery DataFrames
Bevor Sie dieses Beispiel ausprobieren, folgen Sie den Schritten zur Einrichtung von BigQuery DataFrames in der BigQuery-Kurzanleitung: BigQuery DataFrames verwenden. Weitere Informationen finden Sie in der Referenzdokumentation zu BigQuery DataFrames.
Richten Sie zur Authentifizierung bei BigQuery die Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter ADC für eine lokale Entwicklungsumgebung einrichten.
ONNX-Modell in BigQuery importieren
In den folgenden Schritten wird gezeigt, wie Sie das ONNX-Beispielmodell aus Cloud Storage importieren, indem Sie eine CREATE MODEL-Anweisung verwenden.
Wählen Sie eine der folgenden Optionen aus, um das ONNX-Modell in Ihr Dataset zu importieren:
Konsole
bq
BigQuery DataFrames
Bevor Sie dieses Beispiel ausprobieren, folgen Sie den Schritten zur Einrichtung von BigQuery DataFrames in der BigQuery-Kurzanleitung: BigQuery DataFrames verwenden. Weitere Informationen finden Sie in der Referenzdokumentation zu BigQuery DataFrames.
Richten Sie zur Authentifizierung bei BigQuery die Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter ADC für eine lokale Entwicklungsumgebung einrichten.
Importieren Sie das Modell mit dem ONNXModel-Objekt.
Weitere Informationen zum Importieren von ONNX-Modellen in BigQuery, einschließlich Format- und Speicheranforderungen, finden Sie unter Anweisung CREATE MODEL zum Importieren von ONNX-Modellen.
Vorhersagen mit dem importierten ONNX-Modell treffen
Nachdem Sie das ONNX-Modell importiert haben, verwenden Sie die Funktion ML.PREDICT, um Vorhersagen mit dem Modell zu treffen.
In der Abfrage in den folgenden Schritten wird imported_onnx_model verwendet, um Vorhersagen anhand von Eingabedaten aus der Tabelle iris im öffentlichen Dataset ml_datasets zu treffen. Das ONNX-Modell erwartet vier FLOAT-Werte als Eingabe:
Diese Eingaben entsprechen den initial_types, die beim Konvertieren des Modells in das ONNX-Format definiert wurden.
Die Ausgaben enthalten die Spalten label und probabilities sowie die Spalten aus der Eingabetabelle. label steht für das vorhergesagte Klassenlabel.
probabilities ist ein Array von Wahrscheinlichkeiten, die Wahrscheinlichkeiten für jede Klasse darstellen.
Wählen Sie eine der folgenden Optionen aus, um Vorhersagen mit dem importierten TensorFlow-Modell zu treffen:
Konsole
bq
Führen Sie die Abfrage mit ML.PREDICT aus.
bq query --use_legacy_sql=false \ 'SELECT * FROM ML.PREDICT( MODEL `example_dataset.imported_onnx_model`, (SELECT * FROM `bigquery-public-data.ml_datasets.iris`))'
BigQuery DataFrames
Bevor Sie dieses Beispiel ausprobieren, folgen Sie den Schritten zur Einrichtung von BigQuery DataFrames in der BigQuery-Kurzanleitung: BigQuery DataFrames verwenden. Weitere Informationen finden Sie in der Referenzdokumentation zu BigQuery DataFrames.
Richten Sie zur Authentifizierung bei BigQuery die Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter ADC für eine lokale Entwicklungsumgebung einrichten.
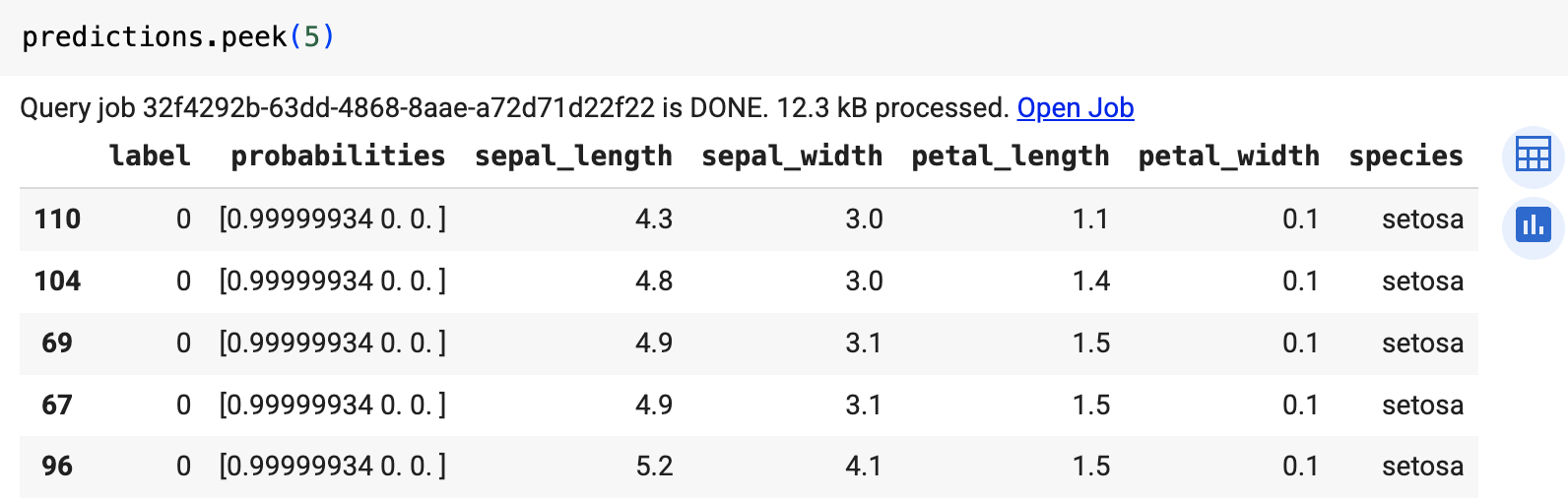
Verwenden Sie die Funktion predict, um das Remote-Modell auszuführen.
Das Ergebnis sieht etwa so aus:
Bereinigen
Damit Ihrem Google Cloud-Konto die in dieser Anleitung verwendeten Ressourcen nicht in Rechnung gestellt werden, löschen Sie entweder das Projekt, das die Ressourcen enthält, oder Sie behalten das Projekt und löschen die einzelnen Ressourcen.
Projekt löschen
Konsole
gcloud
Einzelne Ressourcen löschen
Alternativ können Sie die einzelnen Ressourcen, die in dieser Anleitung verwendet werden, so entfernen: