이 튜토리얼에서는 BigQuery ML의 바이너리 로지스틱 회귀 모델을 사용하여 인구통계 데이터를 기준으로 개인의 소득 범위를 예측합니다. 바이너리 로지스틱 회귀 모델은 값이 두 범주 중 하나에 속할지 예측합니다. 이 경우 개인의 연간 소득이 $50,000를 초과하거나 이에 미달하는지 여부를 예측합니다.
이 튜토리얼에서는 bigquery-public-data.ml_datasets.census_adult_income 데이터 세트를 사용합니다. 이 데이터 세트에는 2000년과 2010년 미국 거주자의 인구 통계 및 소득 정보가 포함되어 있습니다.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the BigQuery API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.
필수 권한
BigQuery ML을 사용하여 모델을 만들려면 다음 IAM 권한이 필요합니다.
bigquery.jobs.createbigquery.models.createbigquery.models.getDatabigquery.models.updateDatabigquery.models.updateMetadata
추론을 실행하려면 다음 권한이 필요합니다.
- 모델에 대한
bigquery.models.getData bigquery.jobs.create
소개
머신 러닝의 일반적인 문제는 데이터를 라벨이라고 하는 두 가지 유형 중 하나로 분류하는 것입니다. 예를 들어 소매업체는 한 고객의 여러 정보를 기반으로 이 고객이 새 제품을 구입할지를 예측하고 싶어 합니다. 이 경우 두 라벨은 will buy과 won't buy이 될 수 있습니다. 소매업체는 하나의 열이 두 라벨을 모두 나타내고 고객의 위치, 이전 구매, 보고된 선호도와 같은 고객 정보도 포함하도록 데이터 세트를 구성할 수 있습니다. 그러면 소매업체는 이 고객 정보를 사용하여 각 고객을 가장 잘 나타내는 라벨을 예측하는 바이너리 로지스틱 회귀 모델을 사용할 수 있습니다.
이 튜토리얼에서는 미국 인구조사 응답자의 소득이 응답자의 인구 통계학적 속성에 따라 두 범위 중 하나에 속할지 예측하는 바이너리 로지스틱 회귀 모델을 만들려고 합니다.
데이터 세트 만들기
모델을 저장할 BigQuery 데이터 세트를 만듭니다.
Google Cloud 콘솔에서 BigQuery 페이지로 이동합니다.
왼쪽 창에서 탐색기를 클릭합니다.

왼쪽 창이 표시되지 않으면 왼쪽 창 펼치기를 클릭하여 창을 엽니다.
탐색기 창에서 프로젝트 이름을 클릭합니다.
작업 보기 > 데이터 세트 만들기를 클릭합니다.
데이터 세트 만들기 페이지에서 다음을 수행합니다.
데이터 세트 ID에
census를 입력합니다.위치 유형에 대해 멀티 리전을 선택한 다음 US(미국 내 여러 리전)를 선택합니다.
공개 데이터 세트는
US멀티 리전에 저장됩니다. 편의상 같은 위치에 데이터 세트를 저장합니다.나머지 기본 설정은 그대로 두고 데이터 세트 만들기를 클릭합니다.
데이터 검토
데이터 세트를 검사하고 로지스틱 회귀 모델의 학습 데이터로 사용할 열을 식별합니다. census_adult_income 테이블에서 100개의 행을 선택합니다.
SQL
Google Cloud 콘솔에서 BigQuery 페이지로 이동합니다.
쿼리 편집기에서 다음 GoogleSQL 쿼리를 실행합니다.
SELECT age, workclass, marital_status, education_num, occupation, hours_per_week, income_bracket, functional_weight FROM `bigquery-public-data.ml_datasets.census_adult_income` LIMIT 100;
결과는 다음과 유사합니다.

BigQuery DataFrames
이 샘플을 사용해 보기 전에 BigQuery DataFrames를 사용하여 BigQuery 빠른 시작의 BigQuery DataFrames 설정 안내를 따르세요. 자세한 내용은 BigQuery DataFrames 참고 문서를 확인하세요.
BigQuery에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 로컬 개발 환경의 ADC 설정을 참조하세요.
쿼리 결과에서는 census_adult_income 테이블의 income_bracket 열에 <=50K 또는 >50K 값 중 하나만 있음을 보여줍니다.
샘플 데이터 준비
이 튜토리얼에서는 census_adult_income 테이블의 다음 열 값을 기반으로 인구조사 응답자 소득을 예측합니다.
age: 응답자의 연령workclass: 수행된 작업의 클래스 예를 들어 지방 정부, 민간 또는 자영업자입니다.marital_statuseducation_num: 응답자의 최고 학력occupationhours_per_week: 주당 근무 시간
데이터가 중복된 열을 제외합니다. 예를 들어 education 열은 education 및 education_num 열 값이 동일한 데이터를 서로 다른 형식으로 표현하기 때문입니다.
functional_weight 열은 인구조사기관에서 특정 행이 대표한다고 판단하는 개인의 수입니다. 이 열의 값은 지정된 행의 income_bracket 값과 관련이 없으므로 이 열의 값을 사용하여 functional_weight 열에서 파생된 새 dataframe 열을 만들어 데이터를 학습, 평가, 예측 세트로 구분합니다. 모델 학습에 사용할 데이터의 80%, 평가에 사용할 데이터의 10%, 예측에 사용할 데이터의 10%에 라벨을 지정합니다.
SQL
샘플 데이터로 뷰를 만듭니다.
이 뷰는 이 튜토리얼 뒷부분에 있는 CREATE MODEL 문에서 사용됩니다.
샘플 데이터를 준비하는 쿼리를 실행합니다.
Google Cloud 콘솔에서 BigQuery 페이지로 이동합니다.
쿼리 편집기 창에서 다음 쿼리를 실행합니다.
CREATE OR REPLACE VIEW `census.input_data` AS SELECT age, workclass, marital_status, education_num, occupation, hours_per_week, income_bracket, CASE WHEN MOD(functional_weight, 10) < 8 THEN 'training' WHEN MOD(functional_weight, 10) = 8 THEN 'evaluation' WHEN MOD(functional_weight, 10) = 9 THEN 'prediction' END AS dataframe FROM `bigquery-public-data.ml_datasets.census_adult_income`;
샘플 데이터를 확인합니다.
SELECT * FROM `census.input_data`;
BigQuery DataFrames
input_data라는 DataFrame을 만듭니다. 이 튜토리얼의 뒷부분에서 input_data를 사용하여 모델을 학습시키고 모델을 평가하고 예측을 수행합니다.
이 샘플을 사용해 보기 전에 BigQuery DataFrames를 사용하여 BigQuery 빠른 시작의 BigQuery DataFrames 설정 안내를 따르세요. 자세한 내용은 BigQuery DataFrames 참고 문서를 확인하세요.
BigQuery에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 로컬 개발 환경의 ADC 설정을 참조하세요.
로지스틱 회귀 모델 만들기
이전 섹션에서 라벨을 지정한 학습 데이터를 사용하여 로지스틱 회귀 모델을 만듭니다.
SQL
CREATE MODEL 문을 사용하고 모델 유형에 LOGISTIC_REG를 지정합니다.
다음은 CREATE MODEL 문에 대해 알아두면 유용한 정보입니다.
input_label_cols옵션은SELECT문에서 라벨 열로 사용할 열을 지정합니다. 여기서 라벨 열은income_bracket이므로 모델은 특정 행에 있는 다른 값을 기반으로income_bracket의 두 값 중 해당 행에 가장 가능성이 높은 값을 학습합니다.로지스틱 회귀 모델이 바이너리 또는 멀티클래스인지 여부를 지정할 필요는 없습니다. BigQuery ML은 라벨 열의 고유 값 수를 기반으로 학습할 모델 유형을 결정합니다.
학습 데이터에서 클래스 라벨의 균형을 맞추도록
auto_class_weights옵션이TRUE로 설정됩니다. 기본적으로 학습 데이터는 가중치가 더해지지 않습니다. 학습 데이터 라벨의 균형이 맞지 않는 경우 모델은 가장 인기 있는 라벨 클래스에 더 가중치를 둬서 예측하도록 학습할 수 있습니다. 이 예시에서는 데이터 세트의 응답자 대부분이 저소득층에 속합니다. 이것은 저소득층을 너무 많이 예측하는 모델로 이어질 수 있습니다. 클래스 가중치는 각 클래스의 가중치를 해당 클래스의 빈도에 반비례하게 계산하여 클래스 라벨의 균형을 맞춥니다.튜토리얼 후반부에서 모델에
ML.GLOBAL_EXPLAIN함수를 사용할 수 있도록enable_global_explain옵션이TRUE로 설정됩니다.SELECT문은 샘플 데이터가 포함된input_data뷰를 쿼리합니다.WHERE절은 학습 데이터로 라벨이 지정된 행만 모델을 학습하는 데 사용되도록 행을 필터링합니다.
로지스틱 회귀 모델을 만드는 쿼리를 실행합니다.
Google Cloud 콘솔에서 BigQuery 페이지로 이동합니다.
쿼리 편집기 창에서 다음 쿼리를 실행합니다.
CREATE OR REPLACE MODEL `census.census_model` OPTIONS ( model_type='LOGISTIC_REG', auto_class_weights=TRUE, enable_global_explain=TRUE, data_split_method='NO_SPLIT', input_label_cols=['income_bracket'], max_iterations=15) AS SELECT * EXCEPT(dataframe) FROM `census.input_data` WHERE dataframe = 'training'
왼쪽 창에서 탐색기를 클릭합니다.
탐색기 창에서 데이터 세트를 클릭합니다.
데이터 세트 창에서
census를 클릭합니다.모델 탭을 클릭합니다.
census_model을 클릭합니다.세부정보 탭에는 BigQuery ML이 로지스틱 회귀를 수행하는 데 사용한 속성이 나열됩니다.
BigQuery DataFrames
fit 메서드를 사용하여 모델을 학습시키고 to_gbq 메서드를 사용하여 이 모델을 데이터 세트에 저장합니다.
이 샘플을 사용해 보기 전에 BigQuery DataFrames를 사용하여 BigQuery 빠른 시작의 BigQuery DataFrames 설정 안내를 따르세요. 자세한 내용은 BigQuery DataFrames 참고 문서를 확인하세요.
BigQuery에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 로컬 개발 환경의 ADC 설정을 참조하세요.
모델의 성능 평가
모델을 만든 후 평가 데이터를 기준으로 모델의 성능을 평가합니다.
SQL
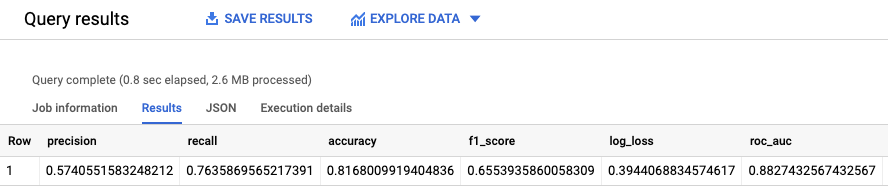
ML.EVALUATE 함수는 평가 데이터를 기준으로 모델이 생성한 예측 값을 평가합니다.
입력의 경우 ML.EVALUATE 함수는 dataframe 열 값으로 evaluation를 갖는 input_data 뷰로부터 학습된 모델과 모델 행을 가져옵니다. 이 함수는 모델에 대한 단일 행의 통계를 반환합니다.
ML.EVALUATE 쿼리 실행:
Google Cloud 콘솔에서 BigQuery 페이지로 이동합니다.
쿼리 편집기 창에서 다음 쿼리를 실행합니다.
SELECT * FROM ML.EVALUATE (MODEL `census.census_model`, ( SELECT * FROM `census.input_data` WHERE dataframe = 'evaluation' ) );
결과는 다음과 유사합니다.
BigQuery DataFrames
score 메서드를 사용하여 실제 데이터를 기준으로 모델을 평가합니다.
이 샘플을 사용해 보기 전에 BigQuery DataFrames를 사용하여 BigQuery 빠른 시작의 BigQuery DataFrames 설정 안내를 따르세요. 자세한 내용은 BigQuery DataFrames 참고 문서를 확인하세요.
BigQuery에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 로컬 개발 환경의 ADC 설정을 참조하세요.
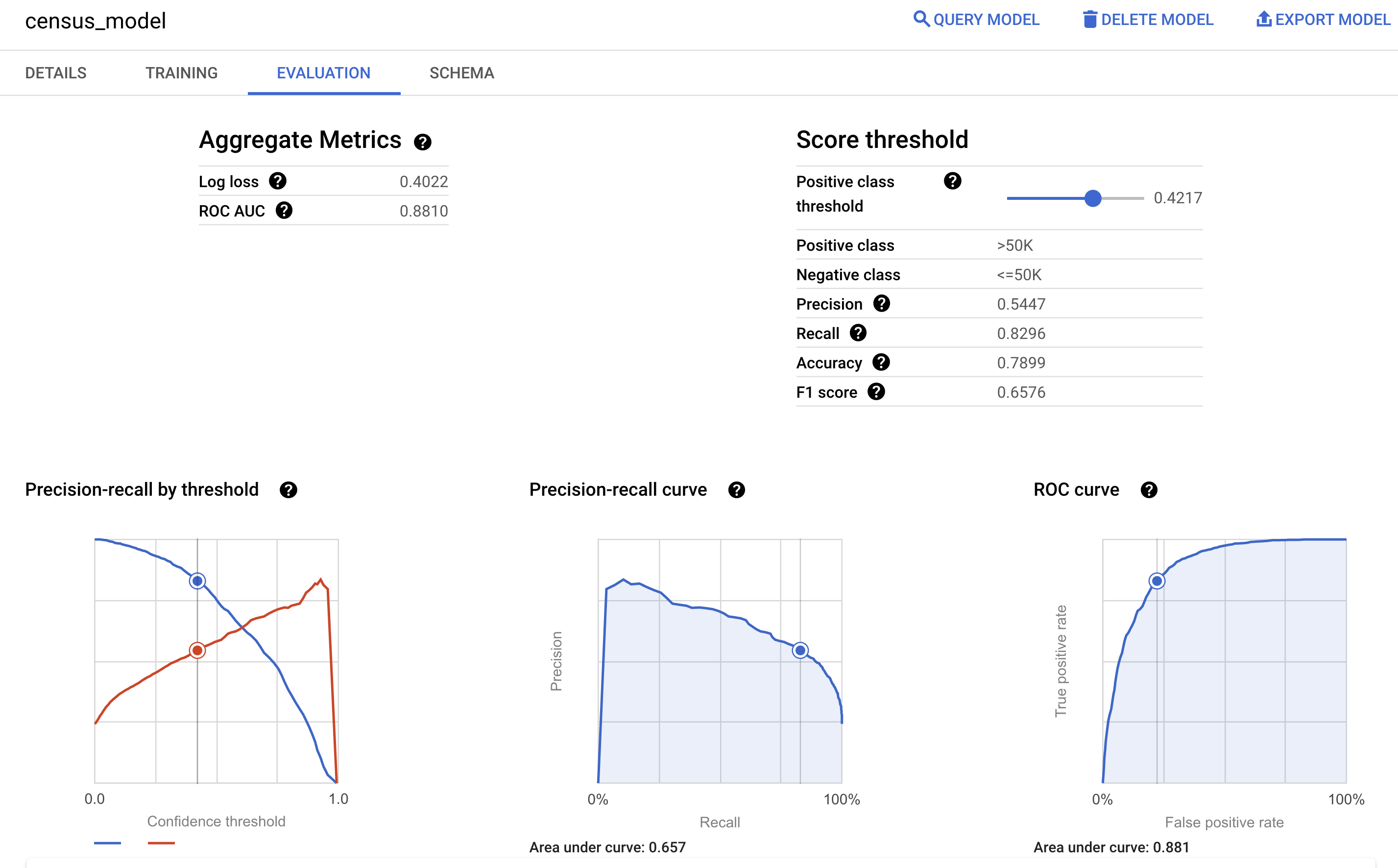
Google Cloud 콘솔에서 모델의 평가 창을 통해 학습 중에 계산된 평가 측정항목을 볼 수도 있습니다.
소득 구간 예측
모델을 사용하여 각 응답자의 소득 구간을 예측합니다.
SQL
ML.PREDICT 함수를 사용하여 예상 소득 구간을 예측합니다. 입력의 경우 ML.PREDICT 함수는 dataframe 열 값으로 prediction를 갖는 input_data 뷰로부터 학습된 모델과 모델 행을 가져옵니다.
ML.PREDICT 쿼리 실행:
Google Cloud 콘솔에서 BigQuery 페이지로 이동합니다.
쿼리 편집기 창에서 다음 쿼리를 실행합니다.
SELECT * FROM ML.PREDICT (MODEL `census.census_model`, ( SELECT * FROM `census.input_data` WHERE dataframe = 'prediction' ) );
결과는 다음과 유사합니다.
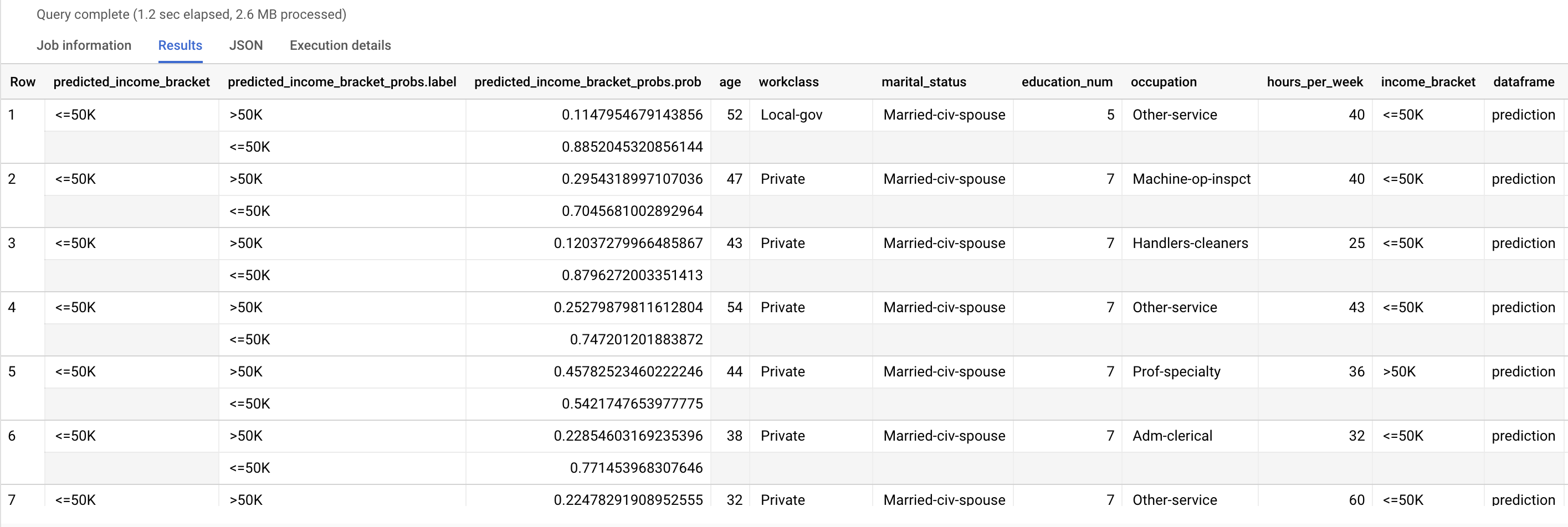
predicted_income_bracket 열에는 응답자의 예상 소득 구간이 포함됩니다.
BigQuery DataFrames
predict 메서드를 사용하여 예상 소득 구간을 예측합니다.
이 샘플을 사용해 보기 전에 BigQuery DataFrames를 사용하여 BigQuery 빠른 시작의 BigQuery DataFrames 설정 안내를 따르세요. 자세한 내용은 BigQuery DataFrames 참고 문서를 확인하세요.
BigQuery에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 로컬 개발 환경의 ADC 설정을 참조하세요.
예측 결과 설명
모델에서 이러한 예측 결과를 생성하는 이유를 알아보려면 ML.EXPLAIN_PREDICT 함수를 사용하면 됩니다.
ML.EXPLAIN_PREDICT는 ML.PREDICT 함수의 확장된 버전입니다.
ML.EXPLAIN_PREDICT는 예측 결과를 출력할 뿐만 아니라 예측 결과를 설명하는 추가 열을 출력합니다. 설명 가능성에 대한 자세한 내용은 BigQuery ML Explainable AI 개요를 참고하세요.
ML.EXPLAIN_PREDICT 쿼리 실행:
Google Cloud 콘솔에서 BigQuery 페이지로 이동합니다.
쿼리 편집기 창에서 다음 쿼리를 실행합니다.
SELECT * FROM ML.EXPLAIN_PREDICT(MODEL `census.census_model`, ( SELECT * FROM `census.input_data` WHERE dataframe = 'evaluation'), STRUCT(3 as top_k_features));
결과는 다음과 유사합니다.
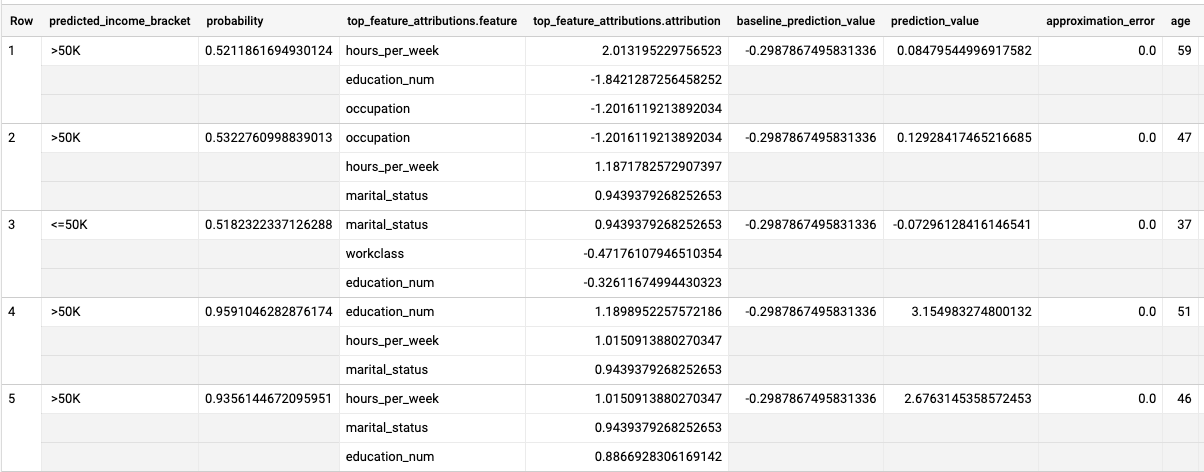
로지스틱 회귀 모델에서 Shapley 값은 모델의 각 특성에 대한 상대적 특성 기여도를 결정하는 데 사용됩니다. 쿼리에서 top_k_features 옵션이 3으로 설정되었기 때문에 ML.EXPLAIN_PREDICT는 input_data 뷰의 각 행에 대한 특성 기여 항목 3개를 출력합니다. 이러한 기여 항목은 절댓값을 기준으로 내림차순으로 표시됩니다.
모델을 전역적으로 설명
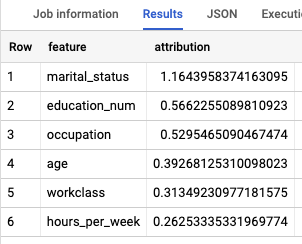
소득 계층을 결정하는 데 가장 중요한 특성을 알아보려면 ML.GLOBAL_EXPLAIN 함수를 사용하세요.
모델의 전역 설명을 가져옵니다.
Google Cloud 콘솔에서 BigQuery 페이지로 이동합니다.
쿼리 편집기에서 다음 쿼리를 실행하여 전역 설명을 가져옵니다.
SELECT * FROM ML.GLOBAL_EXPLAIN(MODEL `census.census_model`)
결과는 다음과 유사합니다.