在本教程中,您将在 BigQuery ML 中使用二元逻辑回归模型,根据个人的人口统计学特征数据预测个人收入范围。二元逻辑回归模型可预测某个值是否属于两类之一,在本示例中,即个人年收入是高于还是低于 50,000 美元。
本教程使用 bigquery-public-data.ml_datasets.census_adult_income 数据集。该数据集包含 2000 年和 2010 年美国居民的人口统计学特征和收入信息。
目标
在本教程中,您将执行以下任务:- 创建逻辑回归模型。
- 评估此模型。
- 使用此模型进行预测。
- 说明此模型产生的结果。
费用
本教程使用 Google Cloud的可计费组件,包括以下组件:
- BigQuery
- BigQuery ML
如需了解有关 BigQuery 费用的更多信息,请参阅 BigQuery 价格页面。
如需详细了解 BigQuery ML 费用,请参阅 BigQuery ML 价格。
准备工作
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the BigQuery API.
所需权限
如需使用 BigQuery ML 创建模型,您需要以下 IAM 权限:
bigquery.jobs.createbigquery.models.createbigquery.models.getDatabigquery.models.updateDatabigquery.models.updateMetadata
如需运行推理,您需要以下权限:
- 模型的
bigquery.models.getData权限 bigquery.jobs.create
简介
机器学习中的一个常见问题是如何将数据归入两个类型(称为标签)之一。例如,某零售商可能想要根据有关给定客户的其他信息,预测该客户是否会购买新产品。在这种情况下,这两个标签可能是 will buy 和 won't buy。零售商可以构建一个数据集,使一列同时代表两个标签,还包含客户信息,例如客户的位置、他们之前的购买记录及其反馈的偏好。然后,零售商可以使用这样一个二元逻辑回归模型,该模型使用这些客户信息预测哪个标签最能代表每位客户。
在本教程中,您将创建一个二元逻辑回归模型,以根据美国人口普查受访者的人口统计学特征特性来预测受访者的收入属于两个范围中的哪个范围。
创建数据集
创建 BigQuery 数据集来存储您的模型:
在 Google Cloud 控制台中,前往 BigQuery 页面。
在探索器窗格中,点击您的项目名称。
点击 查看操作 > 创建数据集。
在 创建数据集 页面上,执行以下操作:
在数据集 ID 部分,输入
census。在位置类型部分,选择多区域,然后选择 US (multiple regions in United States)(美国[美国的多个区域])。
公共数据集存储在
US多区域中。为简单起见,请将数据集存储在同一位置。保持其余默认设置不变,然后点击创建数据集。
检查数据
检查数据集,并确定将哪些列用作逻辑回归模型的训练数据。从 census_adult_income 表中选择 100 行:
SQL
在 Google Cloud 控制台中,前往 BigQuery 页面。
在查询编辑器中,运行以下 GoogleSQL 查询:
SELECT age, workclass, marital_status, education_num, occupation, hours_per_week, income_bracket, functional_weight FROM `bigquery-public-data.ml_datasets.census_adult_income` LIMIT 100;
结果类似于以下内容:

BigQuery DataFrame
在尝试此示例之前,请按照《BigQuery 快速入门:使用 BigQuery DataFrames》中的 BigQuery DataFrames 设置说明进行操作。如需了解详情,请参阅 BigQuery DataFrames 参考文档。
如需向 BigQuery 进行身份验证,请设置应用默认凭证。如需了解详情,请参阅为本地开发环境设置 ADC。
查询结果显示,census_adult_income 表中的 income_bracket 列只有两个值中的其中一个:<=50K 或 >50K。
准备示例数据
在本教程中,您将根据 census_adult_income 表中以下列的值预测人口普查受访者收入:
age:受访者的年龄。workclass:所从事工作的类别。例如,地方政府、私营企业或个体经营。marital_statuseducation_num:受访者的最高受教育程度。occupationhours_per_week:每周工作小时数。
排除数据重复的列。例如,education 列,因为 education 和 education_num 列值以不同的格式表示相同的数据。
functional_weight 列是人口普查组织认为某个特定行所代表的个体数量。由于此列的值与任何给定行的 income_bracket 值无关,因此您可以使用此列中的值将数据分为训练集、评估集和预测集,方法是创建派生自 functional_weight 列的新 dataframe 列。您需要为 80% 的数据添加标签以用于训练模型,为 10% 的数据添加标签以用于评估,并为 10% 的数据添加标签以用于预测。
SQL
创建包含示例数据的视图。本教程后面的 CREATE MODEL 语句将使用此视图。
运行准备示例数据的查询:
在 Google Cloud 控制台中,前往 BigQuery 页面。
在查询编辑器中,运行以下查询:
CREATE OR REPLACE VIEW `census.input_data` AS SELECT age, workclass, marital_status, education_num, occupation, hours_per_week, income_bracket, CASE WHEN MOD(functional_weight, 10) < 8 THEN 'training' WHEN MOD(functional_weight, 10) = 8 THEN 'evaluation' WHEN MOD(functional_weight, 10) = 9 THEN 'prediction' END AS dataframe FROM `bigquery-public-data.ml_datasets.census_adult_income`;
查看示例数据:
SELECT * FROM `census.input_data`;
BigQuery DataFrame
创建名为 input_data 的 DataFrame。在本教程的后面部分,您将使用 input_data 来训练、评估模型并进行预测。
在尝试此示例之前,请按照《BigQuery 快速入门:使用 BigQuery DataFrames》中的 BigQuery DataFrames 设置说明进行操作。如需了解详情,请参阅 BigQuery DataFrames 参考文档。
如需向 BigQuery 进行身份验证,请设置应用默认凭证。如需了解详情,请参阅为本地开发环境设置 ADC。
创建逻辑回归模型
使用您在上一部分中添加标签的训练数据创建一个逻辑回归模型。
SQL
使用 CREATE MODEL 语句并指定 LOGISTIC_REG 作为模型类型。
以下是有关 CREATE MODEL 语句的实用信息:
input_label_cols选项指定SELECT语句中的哪个列将用作标签列。在这里,标签列是income_bracket,因此模型会根据相应行中的其他值学习得出income_bracket的两个值中的哪一个值最有可能。无需指定逻辑回归模型是二元分类模型还是多类别模型。BigQuery ML 可以根据标签列中唯一值的数量确定要训练的模型类型。
将
auto_class_weights选项设置为TRUE,以平衡训练数据中的类别标签。默认情况下,训练数据未加权。如果训练数据中的标签不平衡,则模型可能会更频繁地学习预测最热门的标签类别。在此示例中,数据集中的大多数受访者属于较低收入等级。这可能会导致模型过于频繁地预测较低收入等级。类别权重通过计算与其频率成反比的每个类别的权重,来平衡类别标签。enable_global_explain选项设置为TRUE,以便您在本教程的后面部分对模型使用ML.GLOBAL_EXPLAIN函数。SELECT语句会查询包含示例数据的input_data视图。WHERE子句过滤行,以便只使用标记为训练数据的行来训练模型。
运行可创建逻辑回归模型的查询:
在 Google Cloud 控制台中,前往 BigQuery 页面。
在查询编辑器中,运行以下查询:
CREATE OR REPLACE MODEL `census.census_model` OPTIONS ( model_type='LOGISTIC_REG', auto_class_weights=TRUE, enable_global_explain=TRUE, data_split_method='NO_SPLIT', input_label_cols=['income_bracket'], max_iterations=15) AS SELECT * EXCEPT(dataframe) FROM `census.input_data` WHERE dataframe = 'training'
在探索器窗格中,点击数据集。
在数据集窗格中,点击
census。点击模型窗格。
点击
census_model。详细信息标签页列出了 BigQuery ML 用于执行逻辑回归的属性。
BigQuery DataFrame
使用 fit 方法训练模型,并使用 to_gbq 方法将其保存到数据集。
在尝试此示例之前,请按照《BigQuery 快速入门:使用 BigQuery DataFrames》中的 BigQuery DataFrames 设置说明进行操作。如需了解详情,请参阅 BigQuery DataFrames 参考文档。
如需向 BigQuery 进行身份验证,请设置应用默认凭证。如需了解详情,请参阅为本地开发环境设置 ADC。
评估模型的性能
创建模型后,根据评估数据评估模型的性能。
SQL
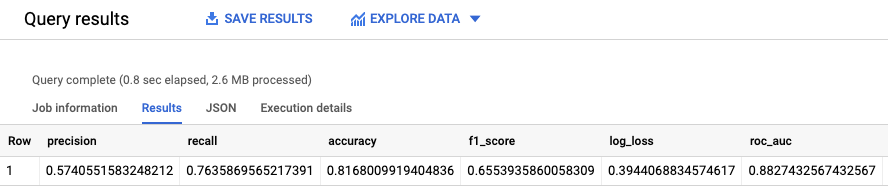
ML.EVALUATE 函数根据评估数据评估模型生成的预测值。
对于输入,ML.EVALUATE 函数采用经过训练的模型以及 input_data 视图中将 evaluation 作为 dataframe 列值的行。此函数会返回有关模型的一行统计信息。
运行 ML.EVALUATE 查询:
在 Google Cloud 控制台中,前往 BigQuery 页面。
在查询编辑器中,运行以下查询:
SELECT * FROM ML.EVALUATE (MODEL `census.census_model`, ( SELECT * FROM `census.input_data` WHERE dataframe = 'evaluation' ) );
结果类似于以下内容:
BigQuery DataFrame
使用 score 方法根据实际数据评估模型。
在尝试此示例之前,请按照《BigQuery 快速入门:使用 BigQuery DataFrames》中的 BigQuery DataFrames 设置说明进行操作。如需了解详情,请参阅 BigQuery DataFrames 参考文档。
如需向 BigQuery 进行身份验证,请设置应用默认凭证。如需了解详情,请参阅为本地开发环境设置 ADC。
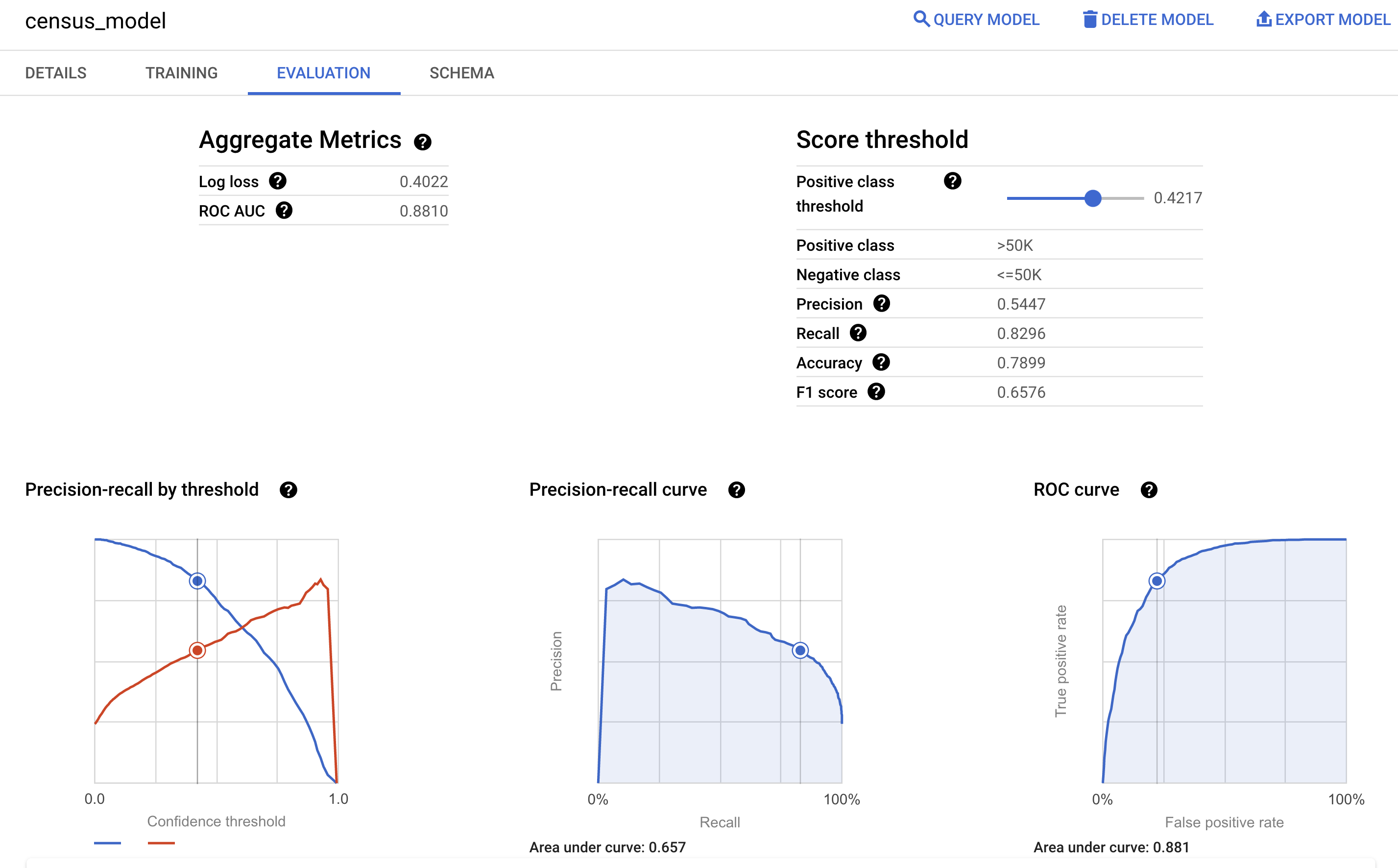
您还可以在 Google Cloud 控制台中查看模型的评估窗格,以查看训练期间计算得出的评估指标:
预测收入等级
使用模型预测每位受访者最有可能所属的收入等级。
SQL
使用 ML.PREDICT 函数预测可能的收入等级。对于输入,ML.PREDICT 函数采用经过训练的模型以及 input_data 视图中将 prediction 作为 dataframe 列值的行。
运行 ML.PREDICT 查询:
在 Google Cloud 控制台中,前往 BigQuery 页面。
在查询编辑器中,运行以下查询:
SELECT * FROM ML.PREDICT (MODEL `census.census_model`, ( SELECT * FROM `census.input_data` WHERE dataframe = 'prediction' ) );
结果类似于以下内容:
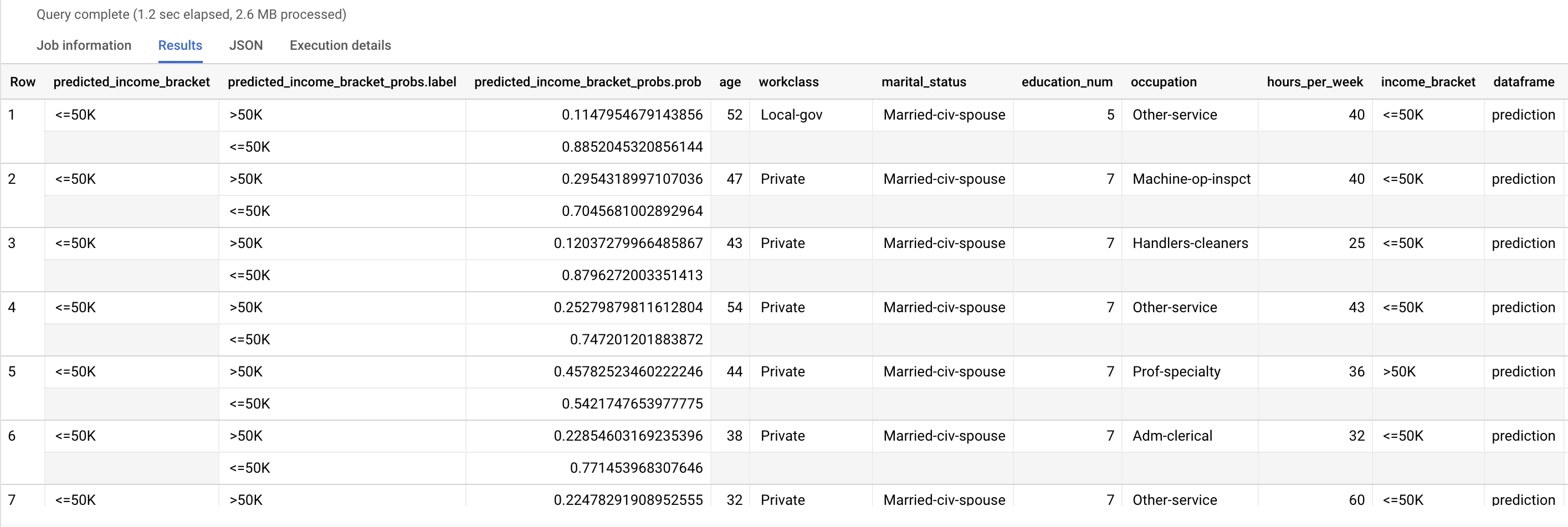
predicted_income_bracket 列包含受访者的预测收入范围。
BigQuery DataFrame
使用 predict 方法预测可能的收入等级。
在尝试此示例之前,请按照《BigQuery 快速入门:使用 BigQuery DataFrames》中的 BigQuery DataFrames 设置说明进行操作。如需了解详情,请参阅 BigQuery DataFrames 参考文档。
如需向 BigQuery 进行身份验证,请设置应用默认凭证。如需了解详情,请参阅为本地开发环境设置 ADC。
解释预测结果
如需了解您的模型为何生成这些预测结果,您可以使用 ML.EXPLAIN_PREDICT 函数。
ML.EXPLAIN_PREDICT 是 ML.PREDICT 函数的扩展版本。ML.EXPLAIN_PREDICT 不仅输出预测结果,还会输出其他列来解释预测结果。如需详细了解可解释性,请参阅 BigQuery ML 可解释 AI 概览。
运行 ML.EXPLAIN_PREDICT 查询:
在 Google Cloud 控制台中,前往 BigQuery 页面。
在查询编辑器中,运行以下查询:
SELECT * FROM ML.EXPLAIN_PREDICT(MODEL `census.census_model`, ( SELECT * FROM `census.input_data` WHERE dataframe = 'evaluation'), STRUCT(3 as top_k_features));
结果类似于以下内容:
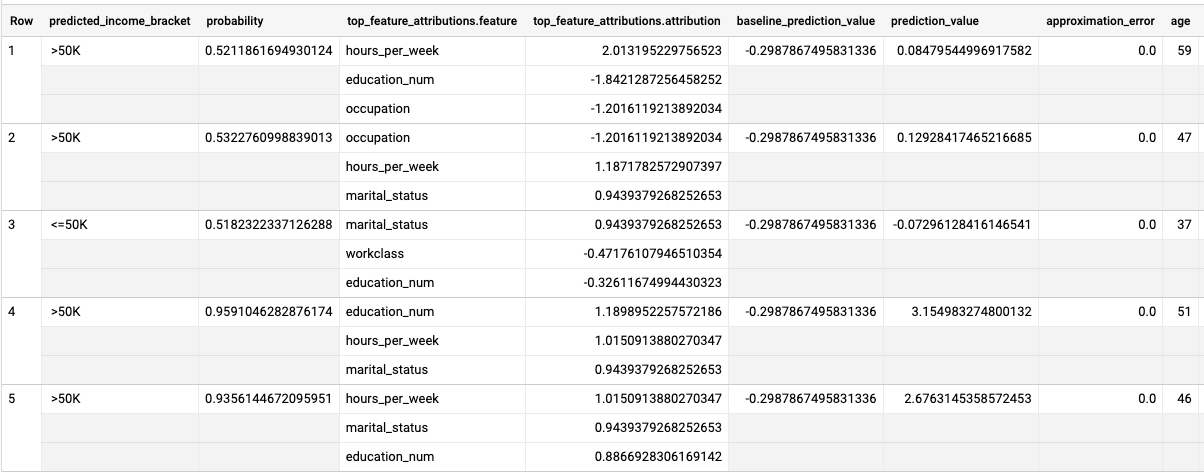
对于逻辑回归模型,Shapley 值用于确定模型中每个特征的相对特征归因。由于在查询中 top_k_features 选项设置为 3,因此 ML.EXPLAIN_PREDICT 会输出 input_data 视图中每行的前三个特征归因。这些归因按归因的绝对值降序显示。
对模型进行全局说明
如需了解哪些特征对确定收入等级最为重要,请使用 ML.GLOBAL_EXPLAIN 函数。
获取模型的全局说明:
在 Google Cloud 控制台中,前往 BigQuery 页面。
在查询编辑器中,运行以下查询来获取全局说明:
SELECT * FROM ML.GLOBAL_EXPLAIN(MODEL `census.census_model`)
结果类似于以下内容:
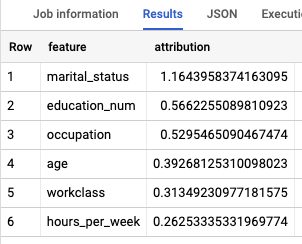
清理
为避免因本教程中使用的资源导致您的 Google Cloud 账号产生费用,请删除包含这些资源的项目,或者保留项目但删除各个资源。
删除数据集
删除项目也将删除项目中的所有数据集和所有表。如果您希望重复使用该项目,则可以删除在本教程中创建的数据集:
如有必要,请在Google Cloud 控制台中打开 BigQuery 页面。
在导航窗格中,点击您创建的 census 数据集。
点击窗口右侧的删除数据集。此操作会删除数据集和模型。
在删除数据集对话框中,通过输入数据集的名称 (
census) 来确认该删除命令,然后点击删除。
删除项目
如需删除项目,请执行以下操作:
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
后续步骤
- 如需大致了解 BigQuery ML,请参阅 BigQuery ML 简介。
- 如需了解如何创建模型,请参阅
CREATE MODEL语法页面。