Dalam tutorial ini, Anda menggunakan model regresi logistik biner di BigQuery ML untuk memprediksi rentang pendapatan individu berdasarkan data demografinya. Model regresi logistik biner memprediksi apakah suatu nilai termasuk dalam salah satu dari dua kategori, dalam hal ini apakah pendapatan tahunan seseorang berada di atas atau di bawah $50.000.
Tutorial ini menggunakan set data
bigquery-public-data.ml_datasets.census_adult_income. Set data ini berisi informasi demografis dan pendapatan penduduk AS dari tahun 2000 hingga 2010.
Tujuan
Dalam tutorial ini, Anda akan melakukan tugas-tugas berikut:- Membuat model regresi logistik.
- Mengevaluasi model.
- Buat prediksi menggunakan model.
- Menjelaskan hasil yang dihasilkan oleh model.
Biaya
Tutorial ini menggunakan komponen Google Cloudyang dapat ditagih, termasuk:
- BigQuery
- BigQuery ML
Untuk informasi selengkapnya tentang biaya BigQuery, lihat halaman harga BigQuery.
Untuk informasi selengkapnya tentang biaya BigQuery ML, lihat harga BigQuery ML.
Sebelum memulai
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the BigQuery API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.
Izin yang diperlukan
Untuk membuat model menggunakan BigQuery ML, Anda memerlukan izin IAM berikut:
bigquery.jobs.createbigquery.models.createbigquery.models.getDatabigquery.models.updateDatabigquery.models.updateMetadata
Untuk menjalankan inferensi, Anda memerlukan izin berikut:
bigquery.models.getDatapada modelbigquery.jobs.create
Pengantar
Tugas umum dalam machine learning adalah mengklasifikasikan data ke dalam salah satu dari dua jenis, yang dikenal sebagai label. Misalnya, retailer mungkin ingin memprediksi apakah pelanggan tertentu akan membeli produk baru, berdasarkan informasi lain tentang pelanggan tersebut. Dalam hal ini, kedua labelnya mungkin will buy dan won't buy. Retailer dapat menyusun set data sedemikian rupa sehingga satu kolom merepresentasikan kedua label, dan juga berisi informasi pelanggan seperti lokasi pelanggan, pembelian mereka sebelumnya, dan preferensi yang dilaporkan. Selanjutnya, retailer dapat menggunakan model regresi logistik biner yang menggunakan informasi pelanggan ini untuk memprediksi label mana yang paling sesuai untuk setiap pelanggan.
Dalam tutorial ini, Anda akan membuat model regresi logistik biner yang memprediksi apakah pendapatan responden Sensus AS termasuk dalam salah satu dari dua rentang berdasarkan atribut demografi responden.
Membuat set data
Buat set data BigQuery untuk menyimpan model Anda:
Di konsol Google Cloud , buka halaman BigQuery.
Di panel Explorer, klik nama project Anda.
Klik View actions > Create dataset.
Di halaman Create dataset, lakukan hal berikut:
Untuk Dataset ID, masukkan
census.Untuk Location type, pilih Multi-region, lalu pilih US (multiple regions in United States).
Set data publik disimpan di
USmulti-region. Agar mudah, simpanlah set data Anda di lokasi yang sama.Jangan ubah setelan default lainnya, lalu klik Create dataset.
Memeriksa data
Periksa set data dan identifikasi kolom yang akan digunakan sebagai data pelatihan untuk model regresi logistik. Pilih 100 baris dari tabel
census_adult_income:
SQL
Di konsol Google Cloud , buka halaman BigQuery.
Di editor kueri, jalankan kueri GoogleSQL berikut:
SELECT age, workclass, marital_status, education_num, occupation, hours_per_week, income_bracket, functional_weight FROM `bigquery-public-data.ml_datasets.census_adult_income` LIMIT 100;
Hasilnya akan terlihat seperti berikut:

DataFrame BigQuery
Sebelum mencoba contoh ini, ikuti petunjuk penyiapan BigQuery DataFrames di Panduan memulai BigQuery menggunakan BigQuery DataFrames. Untuk mengetahui informasi selengkapnya, lihat dokumentasi referensi BigQuery DataFrames.
Untuk melakukan autentikasi ke BigQuery, siapkan Kredensial Default Aplikasi. Untuk mengetahui informasi selengkapnya, lihat Menyiapkan ADC untuk lingkungan pengembangan lokal.
Hasil kueri menunjukkan bahwa kolom income_bracket dalam tabel census_adult_income hanya memiliki salah satu dari dua nilai: <=50K atau >50K.
Menyiapkan data sampel
Dalam tutorial ini, Anda akan memprediksi pendapatan responden sensus berdasarkan nilai
kolom berikut dalam tabel census_adult_income:
age: usia responden.workclass: jenis pekerjaan yang dilakukan. Misalnya, pemerintah daerah, swasta, atau wiraswastawan.marital_statuseducation_num: tingkat pendidikan tertinggi responden.occupationhours_per_week: jam kerja per minggu.
Anda mengecualikan kolom yang menduplikasi data. Misalnya, kolom education, karena nilai kolom education dan education_num mengekspresikan data yang sama dalam format yang berbeda.
Kolom functional_weight adalah jumlah individu yang menurut organisasi sensus diwakili oleh baris tertentu. Karena nilai kolom ini tidak terkait dengan nilai income_bracket untuk baris tertentu, Anda menggunakan nilai dalam kolom ini untuk memisahkan data ke dalam set pelatihan, evaluasi, dan prediksi dengan membuat kolom dataframe baru yang berasal dari kolom functional_weight. Anda memberi label 80% data untuk melatih model, 10% data untuk evaluasi, dan 10% data untuk prediksi.
SQL
Buat tampilan dengan data contoh.
Tabel virtual ini digunakan oleh pernyataan CREATE MODEL nanti dalam tutorial ini.
Jalankan kueri yang menyiapkan data sampel:
Di konsol Google Cloud , buka halaman BigQuery.
Di editor kueri, jalankan kueri berikut:
CREATE OR REPLACE VIEW `census.input_data` AS SELECT age, workclass, marital_status, education_num, occupation, hours_per_week, income_bracket, CASE WHEN MOD(functional_weight, 10) < 8 THEN 'training' WHEN MOD(functional_weight, 10) = 8 THEN 'evaluation' WHEN MOD(functional_weight, 10) = 9 THEN 'prediction' END AS dataframe FROM `bigquery-public-data.ml_datasets.census_adult_income`;
Lihat data sampel:
SELECT * FROM `census.input_data`;
DataFrame BigQuery
Buat DataFrame bernama input_data. Anda akan menggunakan input_data nanti dalam
tutorial ini untuk melatih model, mengevaluasinya, dan membuat prediksi.
Sebelum mencoba contoh ini, ikuti petunjuk penyiapan BigQuery DataFrames di Panduan memulai BigQuery menggunakan BigQuery DataFrames. Untuk mengetahui informasi selengkapnya, lihat dokumentasi referensi BigQuery DataFrames.
Untuk melakukan autentikasi ke BigQuery, siapkan Kredensial Default Aplikasi. Untuk mengetahui informasi selengkapnya, lihat Menyiapkan ADC untuk lingkungan pengembangan lokal.
Membuat model regresi logistik
Buat model regresi logistik dengan data pelatihan yang Anda beri label di bagian sebelumnya.
SQL
Gunakan
pernyataan CREATE MODEL
dan tentukan LOGISTIC_REG untuk jenis model.
Berikut adalah hal-hal berguna yang perlu diketahui tentang pernyataan CREATE MODEL:
Opsi
input_label_colsmenentukan kolom mana dalam pernyataanSELECTyang akan digunakan sebagai kolom label. Di sini, kolom labelnya adalahincome_bracket, sehingga model mempelajari mana dari dua nilaiincome_bracketyang paling mungkin untuk baris tertentu berdasarkan nilai lain yang ada di baris tersebut.Anda tidak perlu menentukan apakah model regresi logistik bersifat biner atau multi-class. BigQuery ML menentukan jenis model yang akan dilatih berdasarkan jumlah nilai unik dalam kolom label.
Opsi
auto_class_weightsditetapkan keTRUEuntuk menyeimbangkan label class dalam data pelatihan. Secara default, data pelatihan tidak diberi bobot. Jika label dalam data pelatihan tidak seimbang, model dapat belajar untuk lebih banyak memprediksi class label yang paling populer. Dalam hal ini, sebagian besar responden dalam set data berada dalam kelompok berpendapatan lebih rendah. Hal ini dapat menyebabkan model yang memprediksi terlalu banyak kelompok pendapatan yang lebih rendah. Bobot class menyeimbangkan label class dengan menghitung bobot untuk setiap class dengan proporsi yang terbalik dengan frekuensi class tersebut.Opsi
enable_global_explaindisetel keTRUEagar Anda dapat menggunakan fungsiML.GLOBAL_EXPLAINpada model di bagian selanjutnya dalam tutorial.Pernyataan
SELECTmembuat kueri tampilaninput_datayang berisi data sampel. KlausaWHEREmemfilter baris sehingga hanya baris yang diberi label sebagai data pelatihan yang digunakan untuk melatih model.
Jalankan kueri yang membuat model regresi logistik Anda:
Di konsol Google Cloud , buka halaman BigQuery.
Di editor kueri, jalankan kueri berikut:
CREATE OR REPLACE MODEL `census.census_model` OPTIONS ( model_type='LOGISTIC_REG', auto_class_weights=TRUE, enable_global_explain=TRUE, data_split_method='NO_SPLIT', input_label_cols=['income_bracket'], max_iterations=15) AS SELECT * EXCEPT(dataframe) FROM `census.input_data` WHERE dataframe = 'training'
Di panel Explorer, klik Set Data.
Di panel Set data, klik
census.Klik panel Model.
Klik
census_model.Tab Detail mencantumkan atribut yang digunakan BigQuery ML untuk melakukan regresi logistik.
DataFrame BigQuery
Gunakan metode
fit
untuk melatih model dan metode
to_gbq
untuk menyimpannya ke set data Anda.
Sebelum mencoba contoh ini, ikuti petunjuk penyiapan BigQuery DataFrames di Panduan memulai BigQuery menggunakan BigQuery DataFrames. Untuk mengetahui informasi selengkapnya, lihat dokumentasi referensi BigQuery DataFrames.
Untuk melakukan autentikasi ke BigQuery, siapkan Kredensial Default Aplikasi. Untuk mengetahui informasi selengkapnya, lihat Menyiapkan ADC untuk lingkungan pengembangan lokal.
Mengevaluasi performa model
Setelah membuat model, evaluasi performa model terhadap data evaluasi.
SQL
Fungsi
ML.EVALUATE
mengevaluasi nilai yang diprediksi yang dihasilkan oleh model terhadap
data evaluasi.
Untuk input, fungsi ML.EVALUATE menggunakan model terlatih dan baris
dari tampilan input_data yang memiliki evaluation sebagai nilai kolom
dataframe. Fungsi ini menampilkan satu baris statistik tentang model.
Jalankan kueri ML.EVALUATE:
Di konsol Google Cloud , buka halaman BigQuery.
Di editor kueri, jalankan kueri berikut:
SELECT * FROM ML.EVALUATE (MODEL `census.census_model`, ( SELECT * FROM `census.input_data` WHERE dataframe = 'evaluation' ) );
Hasilnya akan terlihat seperti berikut:
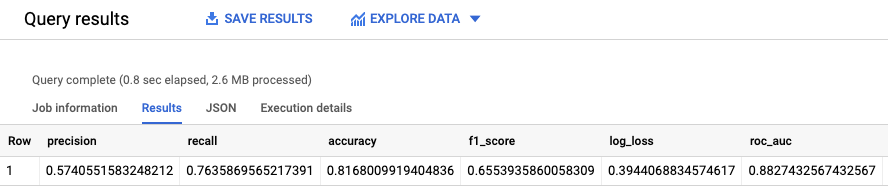
DataFrame BigQuery
Gunakan metode
score
untuk mengevaluasi model berdasarkan data aktual.
Sebelum mencoba contoh ini, ikuti petunjuk penyiapan BigQuery DataFrames di Panduan memulai BigQuery menggunakan BigQuery DataFrames. Untuk mengetahui informasi selengkapnya, lihat dokumentasi referensi BigQuery DataFrames.
Untuk melakukan autentikasi ke BigQuery, siapkan Kredensial Default Aplikasi. Untuk mengetahui informasi selengkapnya, lihat Menyiapkan ADC untuk lingkungan pengembangan lokal.
Anda juga dapat melihat panel Evaluasi model di konsol Google Cloud untuk melihat metrik evaluasi yang dihitung selama pelatihan:
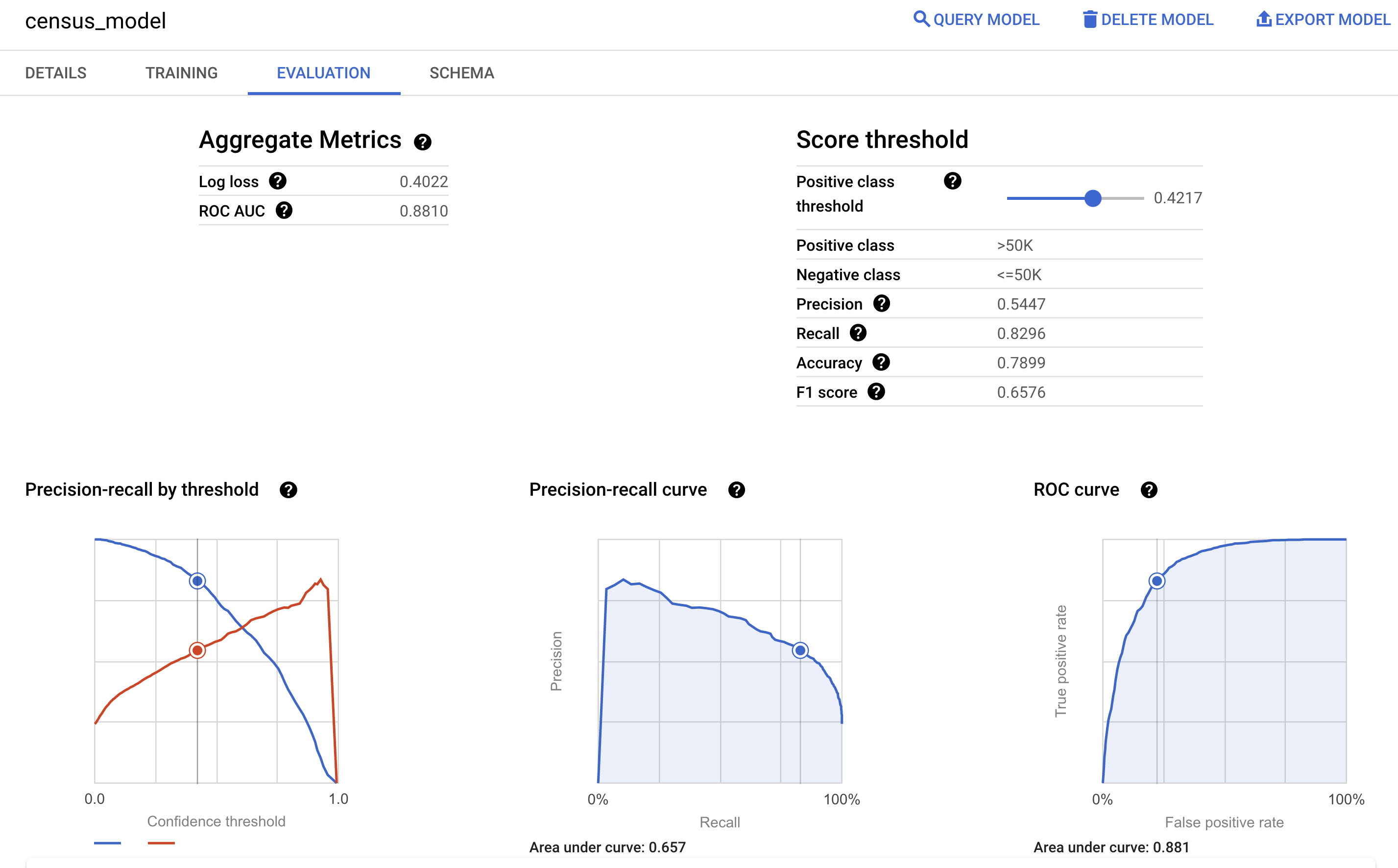
Memprediksi rentang pendapatan
Gunakan model untuk memprediksi rentang pendapatan yang paling mungkin untuk setiap responden.
SQL
Gunakan
fungsi ML.PREDICT
untuk membuat prediksi tentang kemungkinan kategori pendapatan. Untuk input, fungsi ML.PREDICT menggunakan model terlatih dan baris dari tampilan input_data yang memiliki prediction sebagai nilai kolom dataframe.
Jalankan kueri ML.PREDICT:
Di konsol Google Cloud , buka halaman BigQuery.
Di editor kueri, jalankan kueri berikut:
SELECT * FROM ML.PREDICT (MODEL `census.census_model`, ( SELECT * FROM `census.input_data` WHERE dataframe = 'prediction' ) );
Hasilnya akan terlihat seperti berikut:
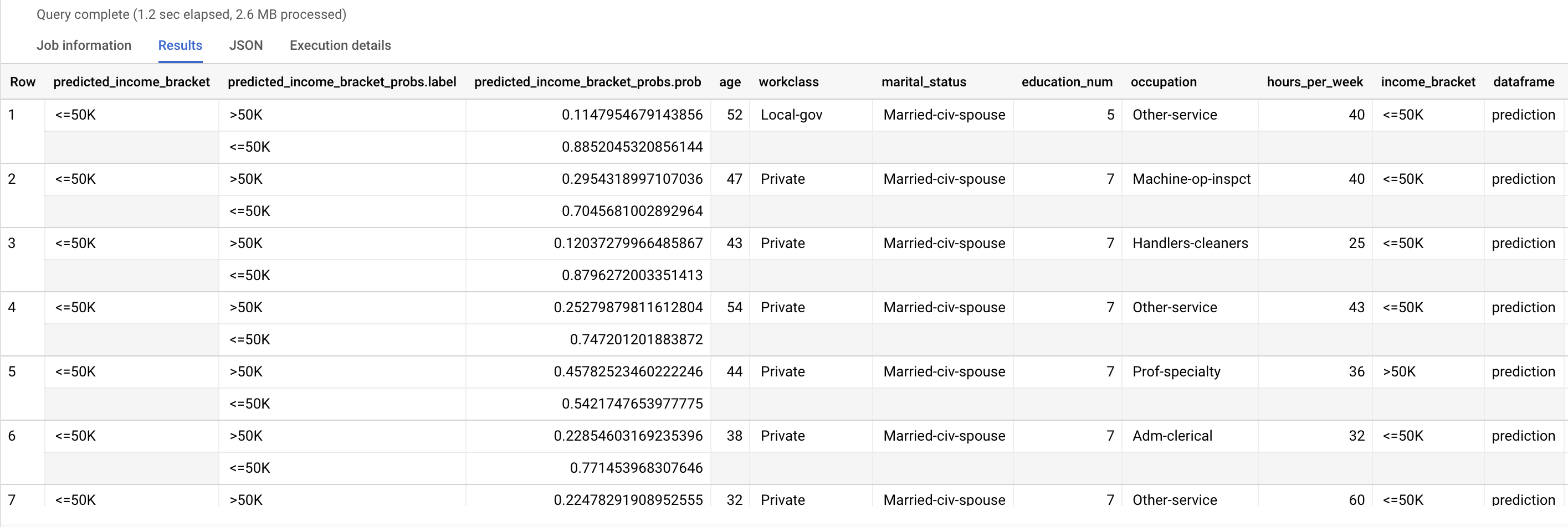
Kolom predicted_income_bracket berisi rentang pendapatan yang diprediksi
untuk responden.
DataFrame BigQuery
Gunakan metode
predict
untuk membuat prediksi tentang kemungkinan rentang pendapatan.
Sebelum mencoba contoh ini, ikuti petunjuk penyiapan BigQuery DataFrames di Panduan memulai BigQuery menggunakan BigQuery DataFrames. Untuk mengetahui informasi selengkapnya, lihat dokumentasi referensi BigQuery DataFrames.
Untuk melakukan autentikasi ke BigQuery, siapkan Kredensial Default Aplikasi. Untuk mengetahui informasi selengkapnya, lihat Menyiapkan ADC untuk lingkungan pengembangan lokal.
Menjelaskan hasil prediksi
Untuk memahami alasan model menghasilkan hasil prediksi ini, Anda dapat menggunakan
fungsi
ML.EXPLAIN_PREDICT.
ML.EXPLAIN_PREDICT adalah versi yang diperluas dari fungsi ML.PREDICT.
ML.EXPLAIN_PREDICT tidak hanya menghasilkan output hasil prediksi, tetapi juga menghasilkan
kolom tambahan untuk menjelaskan hasil prediksi. Untuk mengetahui informasi selengkapnya tentang kemampuan penjelasan, lihat Ringkasan Explainable AI BigQuery ML.
Jalankan kueri ML.EXPLAIN_PREDICT:
Di konsol Google Cloud , buka halaman BigQuery.
Di editor kueri, jalankan kueri berikut:
SELECT * FROM ML.EXPLAIN_PREDICT(MODEL `census.census_model`, ( SELECT * FROM `census.input_data` WHERE dataframe = 'evaluation'), STRUCT(3 as top_k_features));
Hasilnya akan terlihat seperti berikut:
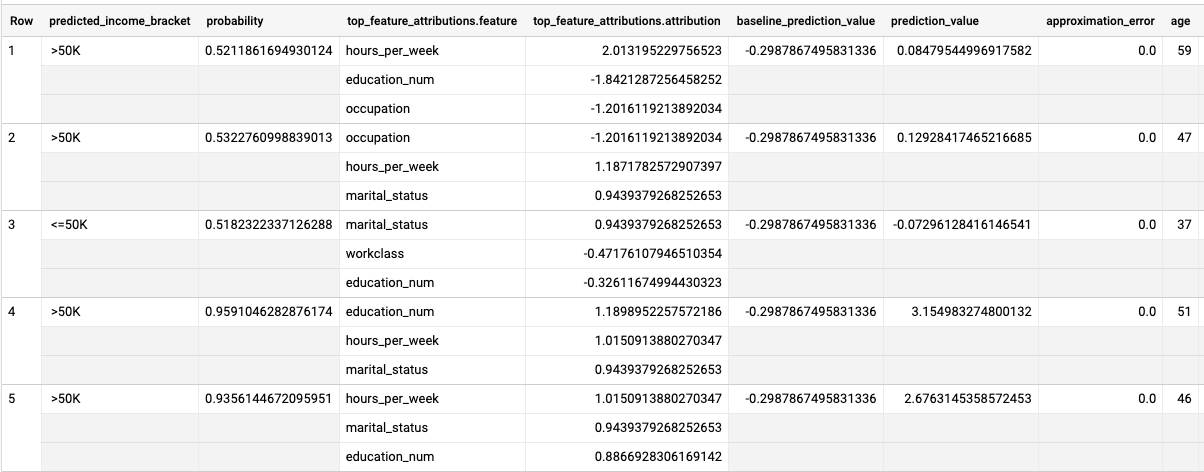
Untuk model regresi logistik, nilai Shapley digunakan untuk menentukan atribusi fitur relatif untuk setiap fitur dalam model. Karena opsi top_k_features
ditetapkan ke 3 dalam kueri, ML.EXPLAIN_PREDICT akan menghasilkan tiga
atribusi fitur teratas untuk setiap baris tampilan input_data. Atribusi ini
ditampilkan dalam urutan menurun menurut nilai absolut atribusi.
Menjelaskan model secara global
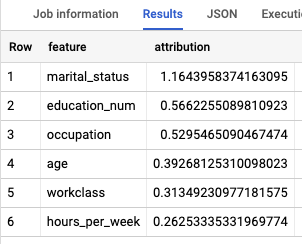
Untuk mengetahui fitur mana yang paling penting guna menentukan kelompok pendapatan, gunakan fungsi ML.GLOBAL_EXPLAIN.
Mendapatkan penjelasan global untuk model:
Di konsol Google Cloud , buka halaman BigQuery.
Di editor kueri, jalankan kueri berikut untuk mendapatkan penjelasan global:
SELECT * FROM ML.GLOBAL_EXPLAIN(MODEL `census.census_model`)
Hasilnya akan terlihat seperti berikut:
Pembersihan
Agar akun Google Cloud Anda tidak dikenai biaya untuk resource yang digunakan dalam tutorial ini, hapus project yang berisi resource tersebut, atau simpan project dan hapus resource satu per satu.
Menghapus set data Anda
Jika project Anda dihapus, semua set data dan semua tabel dalam project akan dihapus. Jika ingin menggunakan kembali project tersebut, Anda dapat menghapus set data yang dibuat dalam tutorial ini:
Jika perlu, buka halaman BigQuery di konsolGoogle Cloud .
Di navigasi, klik set data census yang Anda buat.
Klik Delete dataset di sisi kanan jendela. Tindakan ini akan menghapus set data dan model.
Pada dialog Hapus set data, konfirmasi perintah hapus dengan mengetikkan nama set data Anda (
census), lalu klik Hapus.
Menghapus project Anda
Untuk menghapus project:
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
Langkah berikutnya
- Untuk ringkasan BigQuery ML, lihat Pengantar BigQuery ML.
- Untuk informasi tentang cara membuat model, lihat halaman sintaksis
CREATE MODEL.