Neste tutorial, você usa um modelo de regressão logística binário no BigQuery ML para prever a faixa de renda de indivíduos com base nos dados demográficos deles. Um modelo de regressão logística binária prevê se um valor se enquadra em uma das duas categorias. Nesse caso, se a renda anual de um indivíduo fica acima ou abaixo de US$ 50.000.
Neste tutorial, usamos o conjunto de dados bigquery-public-data.ml_datasets.census_adult_income. Esse conjunto contém as informações demográficas e de renda de residentes dos EUA entre 2000 e 2010.
Objetivos
Neste tutorial, você realizará as seguintes tarefas:- Criar um modelo de regressão logística
- Avaliar o modelo.
- Fazer previsões usando o modelo.
- Explicar os resultados produzidos pelo modelo.
Custos
Neste tutorial, usamos componentes faturáveis do Google Cloud, incluindo:
- BigQuery
- BigQuery ML
Para mais informações sobre os custos do BigQuery, consulte a página de preços do BigQuery.
Para mais informações sobre os custos do BigQuery ML, consulte os preços do BigQuery ML.
Antes de começar
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the BigQuery API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.
Permissões necessárias
Para criar o modelo usando o BigQuery ML, você precisa das seguintes permissões do IAM:
bigquery.jobs.createbigquery.models.createbigquery.models.getDatabigquery.models.updateDatabigquery.models.updateMetadata
Para executar a inferência, você precisa das seguintes permissões:
bigquery.models.getDatano modelobigquery.jobs.create
Introdução
Uma tarefa comum do aprendizado de máquina é a classificação dos dados em um de dois tipos, conhecidos como rótulos. Por exemplo, talvez um revendedor queira prever se determinado cliente comprará um novo produto com base em outras informações sobre essa pessoa. Nesse caso, os dois rótulos podem ser will buy e won't buy. O varejista pode criar um conjunto de dados em que uma coluna represente os dois rótulos e também contenha informações do cliente, como localização do cliente, compras anteriores e preferências informadas. O varejista pode usar um modelo de regressão logística binária que usa as informações desses clientes para prever qual rótulo representa melhor cada cliente.
Neste tutorial, você cria um modelo de regressão logística binária que prevê se a renda de um entrevistado do censo dos EUA se enquadra em uma das duas faixas com base nos atributos demográficos do entrevistado.
Criar um conjunto de dados
Crie um conjunto de dados do BigQuery para armazenar o modelo:
No console do Google Cloud , acesse a página BigQuery.
No painel Explorer, clique no nome do seu projeto.
Clique em Conferir ações > Criar conjunto de dados.
Na página Criar conjunto de dados, faça o seguinte:
Para o código do conjunto de dados, insira
census.Em Tipo de local, selecione Multirregião e EUA (várias regiões nos Estados Unidos).
Os conjuntos de dados públicos são armazenados na multirregião
US. Para simplificar, armazene seus conjuntos de dados no mesmo local.Mantenha as configurações padrão restantes e clique em Criar conjunto de dados.
analise os dados
Analise o conjunto de dados e identifique quais colunas usar como dados de treinamento para o modelo de regressão logística. Selecione 100 linhas da
tabela census_adult_income:
SQL
No console do Google Cloud , acesse a página BigQuery.
No editor de consultas, execute a seguinte consulta do GoogleSQL:
SELECT age, workclass, marital_status, education_num, occupation, hours_per_week, income_bracket, functional_weight FROM `bigquery-public-data.ml_datasets.census_adult_income` LIMIT 100;
Os resultados são semelhantes aos seguintes:

BigQuery DataFrames
Antes de testar esta amostra, siga as instruções de configuração dos BigQuery DataFrames no Guia de início rápido do BigQuery: como usar os BigQuery DataFrames. Para mais informações, consulte a documentação de referência do BigQuery DataFrames.
Para autenticar no BigQuery, configure o Application Default Credentials. Para mais informações, consulte Configurar o ADC para um ambiente de desenvolvimento local.
Os resultados da consulta mostram que a coluna income_bracket na tabela census_adult_income tem apenas um dos dois valores: <=50K ou >50K.
Preparar os dados de amostra
Neste tutorial, você prevê a renda dos entrevistados do censo com base nos valores das seguintes colunas na tabela census_adult_income:
age: a idade do participante.workclass: classe de trabalho realizado. Por exemplo, governo local, particular ou autônomo.marital_statuseducation_num: o nível de escolaridade mais alto do participante.occupationhours_per_week: horas trabalhadas por semana.
Você exclui colunas que duplicam dados. Por exemplo, a coluna education, porque os valores das colunas education e education_num expressam os mesmos dados em formatos diferentes.
A coluna functional_weight é o número de indivíduos que a organização de censo acredita que uma linha específica representa. Como o valor dessa coluna não está relacionado ao valor de income_bracket para qualquer linha, use o valor nessa coluna para separar os dados em conjuntos de treinamento, avaliação e previsão criando uma nova coluna dataframe derivada da coluna functional_weight. Você rotula 80% dos dados para treinamento do modelo, 10% para avaliação e 10% para previsão.
SQL
Crie uma visualização com os dados de amostra.
Essa visualização é usada pela instrução CREATE MODEL posteriormente neste tutorial.
Execute a consulta que prepara os dados de amostra:
No console do Google Cloud , acesse a página BigQuery.
No Editor de consultas, execute esta consulta:
CREATE OR REPLACE VIEW `census.input_data` AS SELECT age, workclass, marital_status, education_num, occupation, hours_per_week, income_bracket, CASE WHEN MOD(functional_weight, 10) < 8 THEN 'training' WHEN MOD(functional_weight, 10) = 8 THEN 'evaluation' WHEN MOD(functional_weight, 10) = 9 THEN 'prediction' END AS dataframe FROM `bigquery-public-data.ml_datasets.census_adult_income`;
Confira os dados de amostra:
SELECT * FROM `census.input_data`;
BigQuery DataFrames
Crie um DataFrame chamado input_data. Você usará input_data posteriormente
neste tutorial para treinar o modelo, avaliá-lo e fazer previsões.
Antes de testar esta amostra, siga as instruções de configuração dos BigQuery DataFrames no Guia de início rápido do BigQuery: como usar os BigQuery DataFrames. Para mais informações, consulte a documentação de referência do BigQuery DataFrames.
Para autenticar no BigQuery, configure o Application Default Credentials. Para mais informações, consulte Configurar o ADC para um ambiente de desenvolvimento local.
Criar um modelo de regressão logística
Crie um modelo de regressão logística com os dados de treinamento rotulados na seção anterior.
SQL
Use a
instrução CREATE MODEL
e especifique LOGISTIC_REG para o tipo de modelo.
Confira abaixo informações úteis sobre a instrução CREATE MODEL:
A opção
input_label_colsespecifica qual coluna na instruçãoSELECTdeve ser usada como a coluna de rótulo. Aqui, a coluna de rótulo éincome_bracket, então o modelo aprende qual dos dois valores deincome_bracketé mais provável para uma determinada linha com base nos outros valores presentes nessa linha.Não é necessário especificar se um modelo de regressão logística é binário ou multiclasse. O BigQuery ML determina qual tipo de modelo treinar com base no número de valores exclusivos na coluna de rótulos.
A opção
auto_class_weightsestá definida comoTRUEpara equilibrar os rótulos de classe nos dados de treinamento. Por padrão, os dados de treinamento não são ponderados. Se os rótulos nos dados de treinamento estiverem desequilibrados, o modelo poderá aprender a prever a classe mais comum de rótulos com mais intensidade. Nesse caso, a maioria dos entrevistados no conjunto de dados está na faixa de renda mais baixa. Isso pode levar a um modelo que prevê a faixa de renda mais baixa de maneira exagerada. Os pesos das classes equilibram os rótulos. Isso é feito por meio do cálculo dos pesos de cada classe em proporção inversa à frequência dessa classe.A opção
enable_global_explainé definida comoTRUEpara permitir que você use a funçãoML.GLOBAL_EXPLAINno modelo mais adiante no tutorial.A instrução
SELECTconsulta a visualizaçãoinput_dataque contém os dados de amostra. A cláusulaWHEREfiltra as linhas para que apenas as linhas rotuladas como dados de treinamento sejam usadas para treinar o modelo.
Execute a consulta que cria seu modelo de regressão logística:
No console do Google Cloud , acesse a página BigQuery.
No Editor de consultas, execute esta consulta:
CREATE OR REPLACE MODEL `census.census_model` OPTIONS ( model_type='LOGISTIC_REG', auto_class_weights=TRUE, enable_global_explain=TRUE, data_split_method='NO_SPLIT', input_label_cols=['income_bracket'], max_iterations=15) AS SELECT * EXCEPT(dataframe) FROM `census.input_data` WHERE dataframe = 'training'
No painel Explorer, clique em Conjuntos de dados.
No painel Conjuntos de dados, clique em
census.Clique no painel Modelos.
Clique em
census_model.A guia Detalhes lista os atributos que o BigQuery ML usou para realizar a regressão logística.
BigQuery DataFrames
Use o método
fit
para treinar o modelo e o método
to_gbq
para salvá-lo no seu conjunto de dados ,
Antes de testar esta amostra, siga as instruções de configuração dos BigQuery DataFrames no Guia de início rápido do BigQuery: como usar os BigQuery DataFrames. Para mais informações, consulte a documentação de referência do BigQuery DataFrames.
Para autenticar no BigQuery, configure o Application Default Credentials. Para mais informações, consulte Configurar o ADC para um ambiente de desenvolvimento local.
Avaliar o desempenho do modelo
Depois de criar o modelo, avalie o desempenho dele em relação aos dados de avaliação.
SQL
A
função ML.EVALUATE
avalia os valores previstos gerados pelo modelo em relação aos
dados de avaliação.
Para entrada, a função ML.EVALUATE usa o modelo treinado e as linhas da visualização input_data que têm evaluation como o valor da coluna dataframe. A função retorna uma única linha de estatísticas sobre o modelo.
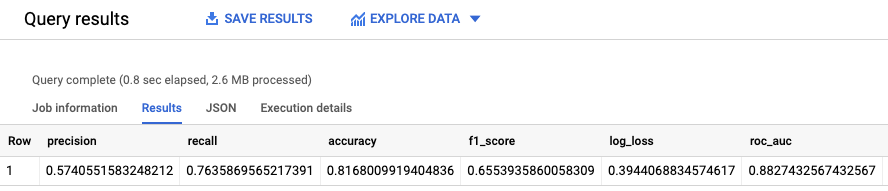
Execute a consulta ML.EVALUATE:
No console do Google Cloud , acesse a página BigQuery.
No Editor de consultas, execute esta consulta:
SELECT * FROM ML.EVALUATE (MODEL `census.census_model`, ( SELECT * FROM `census.input_data` WHERE dataframe = 'evaluation' ) );
Os resultados são semelhantes aos seguintes:
BigQuery DataFrames
Use o método
score
para avaliar o modelo com os dados reais.
Antes de testar esta amostra, siga as instruções de configuração dos BigQuery DataFrames no Guia de início rápido do BigQuery: como usar os BigQuery DataFrames. Para mais informações, consulte a documentação de referência do BigQuery DataFrames.
Para autenticar no BigQuery, configure o Application Default Credentials. Para mais informações, consulte Configurar o ADC para um ambiente de desenvolvimento local.
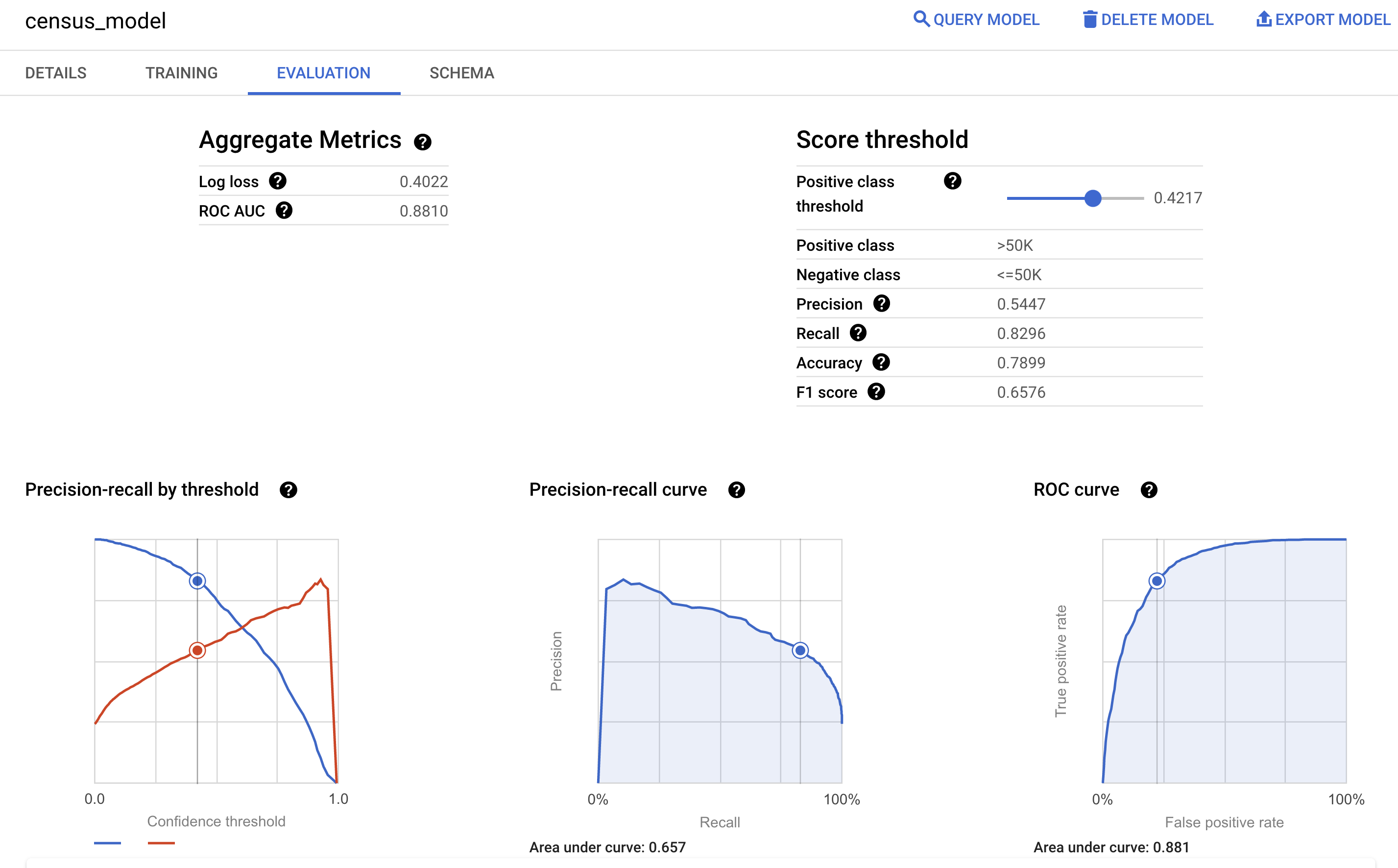
Também é possível consultar o painel Avaliação do modelo no console Google Cloud para conferir as métricas de avaliação calculadas durante o treinamento:
Prever a faixa de renda
Use o modelo para prever a faixa de renda mais provável de cada entrevistado.
SQL
Use a
função ML.PREDICT
para fazer previsões sobre a provável faixa de renda. Para entrada, a função
ML.PREDICT usa o modelo treinado e as linhas da
visualização input_data que têm prediction como o valor da coluna dataframe.
Execute a consulta ML.PREDICT:
No console do Google Cloud , acesse a página BigQuery.
No Editor de consultas, execute esta consulta:
SELECT * FROM ML.PREDICT (MODEL `census.census_model`, ( SELECT * FROM `census.input_data` WHERE dataframe = 'prediction' ) );
Os resultados são semelhantes aos seguintes:
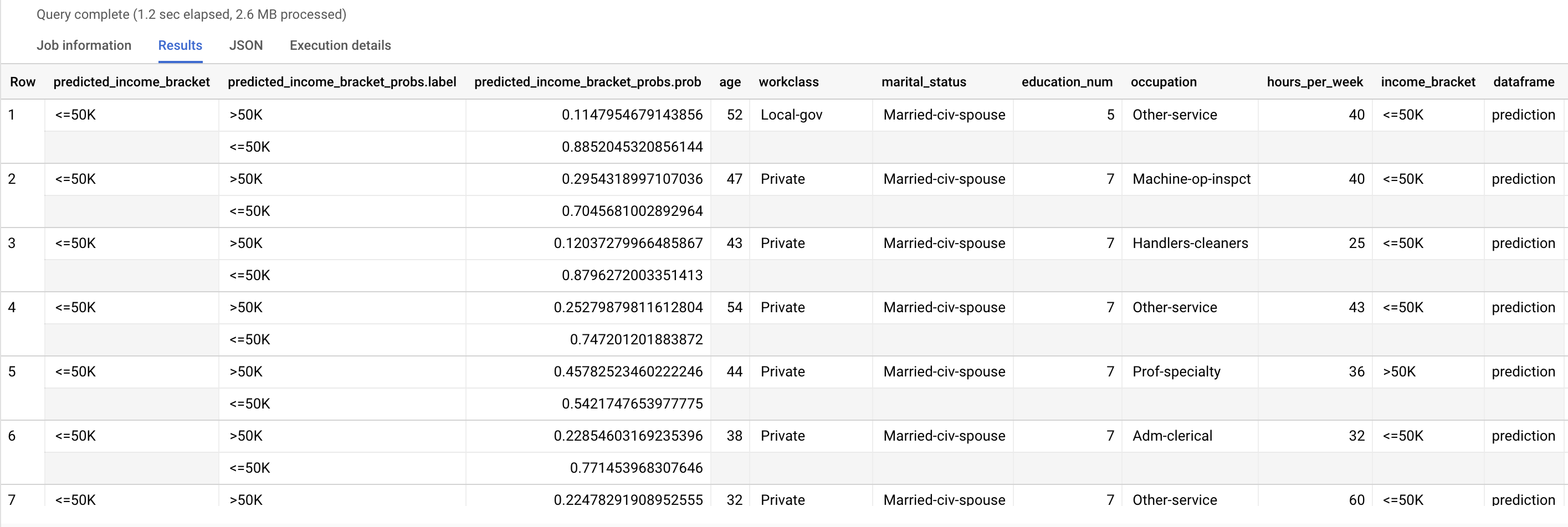
A coluna predicted_income_bracket contém a faixa de renda prevista para o entrevistado.
BigQuery DataFrames
Use o método
predict
para fazer previsões sobre a provável faixa de renda.
Antes de testar esta amostra, siga as instruções de configuração dos BigQuery DataFrames no Guia de início rápido do BigQuery: como usar os BigQuery DataFrames. Para mais informações, consulte a documentação de referência do BigQuery DataFrames.
Para autenticar no BigQuery, configure o Application Default Credentials. Para mais informações, consulte Configurar o ADC para um ambiente de desenvolvimento local.
Explicar os resultados da previsão
Para entender por que o modelo está gerando esses resultados de previsão, use a função ML.EXPLAIN_PREDICT.
ML.EXPLAIN_PREDICT é uma versão estendida da função ML.PREDICT.
ML.EXPLAIN_PREDICT não apenas gera resultados de previsão, mas também gera colunas extras para explicar os resultados da previsão. Para mais informações
sobre explicabilidade, consulte
Visão geral da Explainable AI no BigQuery ML.
Execute a consulta ML.EXPLAIN_PREDICT:
No console do Google Cloud , acesse a página BigQuery.
No Editor de consultas, execute esta consulta:
SELECT * FROM ML.EXPLAIN_PREDICT(MODEL `census.census_model`, ( SELECT * FROM `census.input_data` WHERE dataframe = 'evaluation'), STRUCT(3 as top_k_features));
Os resultados são semelhantes aos seguintes:
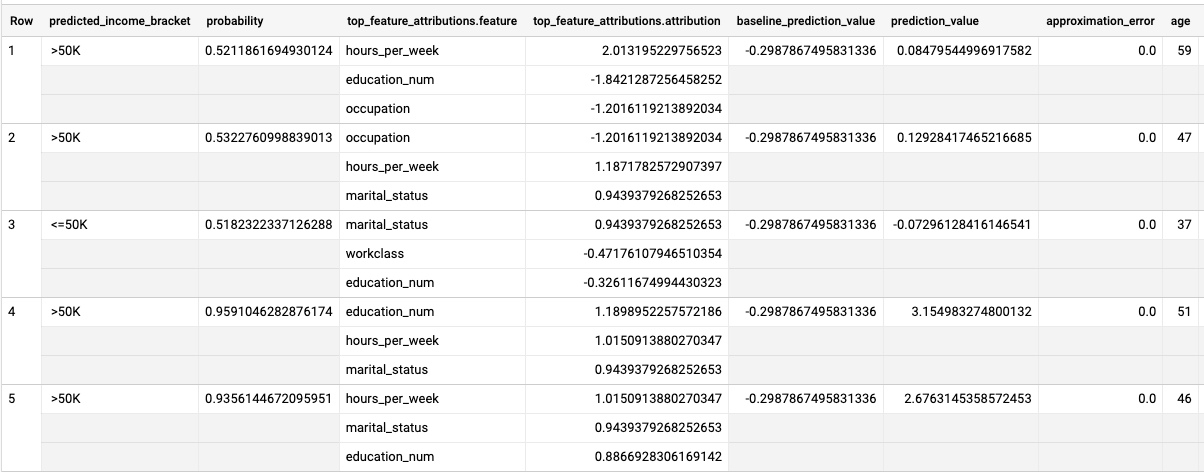
Para modelos de regressão logística, os valores de Shapley são usados para determinar a atribuição relativa de recursos para cada recurso no modelo. Como a opção top_k_features foi definida como 3 na consulta, ML.EXPLAIN_PREDICT gera as três principais atribuições de recursos para cada linha da visualização input_data. Essas atribuições são mostradas em ordem decrescente pelo valor absoluto da atribuição.
Explicar o modelo globalmente
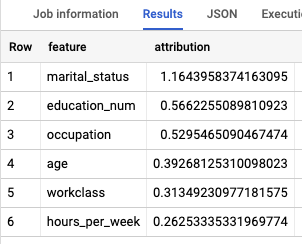
Para saber quais recursos são os mais importantes para determinar a faixa de renda, use a função ML.GLOBAL_EXPLAIN.
Receba explicações globais para o modelo:
No console do Google Cloud , acesse a página BigQuery.
No editor de consultas, execute a seguinte consulta para receber explicações globais:
SELECT * FROM ML.GLOBAL_EXPLAIN(MODEL `census.census_model`)
Os resultados são semelhantes aos seguintes:
Limpar
Para evitar cobranças na sua conta do Google Cloud pelos recursos usados no tutorial, exclua o projeto que os contém ou mantenha o projeto e exclua os recursos individuais.
Excluir o conjunto de dados
A exclusão do seu projeto removerá todos os conjuntos de dados e tabelas no projeto. Caso prefira reutilizá-lo, exclua o conjunto de dados criado neste tutorial:
Se necessário, abra a página do BigQuery no console doGoogle Cloud .
Na navegação, clique no conjunto de dados do census que você criou.
Clique em Excluir conjunto de dados no lado direito da janela. Essa ação exclui o conjunto de dados e o modelo.
Na caixa de diálogo Excluir conjunto de dados, confirme o comando de exclusão digitando o nome do seu conjunto de dados (
census). Em seguida, clique em Excluir.
Excluir o projeto
Para excluir o projeto:
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
A seguir
- Para uma visão geral sobre ML do BigQuery, consulte Introdução ao ML do BigQuery.
- Para mais informações sobre como criar modelos, consulte a página de sintaxe
CREATE MODEL.