In dieser Anleitung verwenden Sie ein binäres logistisches Regressionsmodell in BigQuery ML, um den Einkommensbereich von Personen anhand ihrer demografischen Daten vorherzusagen. Ein binäres logistisches Regressionsmodell sagt vorher, ob ein Wert in eine von zwei Kategorien fällt. In diesem Fall, ob das jährliche Einkommen einer Person über oder unter 50.000 $ fällt.
In dieser Anleitung wird das Dataset bigquery-public-data.ml_datasets.census_adult_income verwendet. Dieses Dataset enthält demografische und einkommensbezogene Informationen von US-Bürgern aus den Jahren 2000 und 2010.
Ziele
Aufgaben in dieser Anleitung:- Logistisches Regressionsmodell erstellen
- Modell bewerten
- Vorhersagen mithilfe des Modells treffen.
- Die vom Modell generierten Ergebnisse erklären.
Kosten
In dieser Anleitung werden kostenpflichtige Komponenten von Google Cloudverwendet, darunter:
- BigQuery
- BigQuery ML
Weitere Informationen zu den Kosten für BigQuery finden Sie auf der Seite BigQuery-Preise.
Weitere Informationen zu den Kosten für BigQuery ML finden Sie unter BigQuery ML-Preise.
Hinweise
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the BigQuery API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.
Erforderliche Berechtigungen
Zum Erstellen des Modells mit BigQuery ML benötigen Sie die folgenden IAM-Berechtigungen:
bigquery.jobs.createbigquery.models.createbigquery.models.getDatabigquery.models.updateDatabigquery.models.updateMetadata
Zum Ausführen von Inferenzen benötigen Sie die folgenden Berechtigungen:
bigquery.models.getDatafür das Modellbigquery.jobs.create
Einführung
Eine häufige Aufgabe beim maschinellen Lernen besteht darin, Daten einem von zwei Typen zuzuordnen, den sogenannten Labels. Beispielsweise wäre es für einen Einzelhändler interessant, anhand von bestimmten Informationen zu einem Kunden vorherzusagen, ob dieser Kunde ein neues Produkt kauft. In diesem Fall könnten die beiden Labels will buy und won't buy lauten. Der Einzelhändler kann ein Dataset so erstellen, dass eine Spalte beide Labels darstellt und außerdem Kundeninformationen wie den Standort des Kunden, seine vorherigen Einkäufe und die gemeldeten Präferenzen enthält. Der Einzelhändler kann dann ein binäres logistisches Regressionsmodell verwenden, das anhand dieser Kundeninformationen vorhersagt, welches Label den jeweiligen Kunden am besten repräsentiert.
In dieser Anleitung erstellen Sie ein binäres logistisches Regressionsmodell, das anhand der demografischen Attribute eines Befragten bei der US-Volkszählung vorhersagt, ob sein Einkommen in einen von zwei Bereichen fällt.
Dataset erstellen
Erstellen Sie ein BigQuery-Dataset zum Speichern Ihres Modells:
Öffnen Sie in der Google Cloud Console die Seite BigQuery.
Klicken Sie im Bereich Explorer auf den Namen Ihres Projekts.
Klicken Sie auf Aktionen ansehen > Dataset erstellen.
Führen Sie auf der Seite Dataset erstellen die folgenden Schritte aus:
Geben Sie unter Dataset-ID
censusein.Wählen Sie als Standorttyp die Option Multiregional und dann USA (mehrere Regionen in den USA) aus.
Die öffentlichen Datasets sind am multiregionalen Standort
USgespeichert. Der Einfachheit halber sollten Sie Ihr Dataset am selben Standort speichern.Übernehmen Sie die verbleibenden Standardeinstellungen und klicken Sie auf Dataset erstellen.
Sehen Sie sich die Daten an
Untersuchen Sie das Dataset und ermitteln Sie, welche Spalten als Trainingsdaten für das logistische Regressionsmodell verwendet werden sollen. Wählen Sie 100 Zeilen aus der Tabelle census_adult_income aus:
SQL
Öffnen Sie in der Google Cloud Console die Seite BigQuery.
Führen Sie im Abfrageeditor die folgende GoogleSQL-Abfrage aus:
SELECT age, workclass, marital_status, education_num, occupation, hours_per_week, income_bracket, functional_weight FROM `bigquery-public-data.ml_datasets.census_adult_income` LIMIT 100;
Die Ergebnisse sehen in etwa so aus:

BigQuery DataFrames
Bevor Sie dieses Beispiel ausprobieren, folgen Sie den Schritten zur Einrichtung von BigQuery DataFrames in der BigQuery-Kurzanleitung: BigQuery DataFrames verwenden. Weitere Informationen finden Sie in der Referenzdokumentation zu BigQuery DataFrames.
Richten Sie zur Authentifizierung bei BigQuery die Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter ADC für eine lokale Entwicklungsumgebung einrichten.
In den Abfrageergebnissen sehen Sie, dass die Spalte income_bracket der Tabelle census_adult_income nur einen von zwei Werten enthält: <=50K oder >50K.
Beispieldaten vorbereiten
In dieser Anleitung sagen Sie das Einkommen der Befragten bei der Volkszählung anhand der Werte der folgenden Spalten in der Tabelle census_adult_income vorher:
age: das Alter des Befragten.workclass: Art der ausgeführten Arbeit. Beispiele: Kommunalverwaltung, privat oder selbstständig.marital_statuseducation_num: Das höchste Bildungsniveau des Befragten.occupationhours_per_week: Arbeitsstunden pro Woche.
Sie schließen Spalten aus, die doppelte Daten enthalten. Beispielsweise die Spalte education, da die Spaltenwerte education und education_num dieselben Daten in verschiedenen Formaten ausdrücken.
Die Spalte functional_weight gibt die Anzahl der Personen an, die nach Ansicht der Volkszählungs-Organisationdurch eine bestimmte Zeile repräsentiert wird. Da der Wert dieser Spalte für eine bestimmte Zeile nicht mit dem Wert von income_bracket zusammenhängt, verwenden Sie den Wert in dieser Spalte, um die Daten in Trainings-, Auswertungs- und Vorhersage-Sets zu unterteilen. Dazu erstellen Sie eine neue dataframe-Spalte, die von der functional_weight-Spalte abgeleitet wird. Sie weisen 80% der Daten dem Training des Modells, 10% der Daten der Bewertung und 10% der Daten der Vorhersage zu.
SQL
Erstellen Sie eine Ansicht mit den Beispieldaten.
Diese Ansicht wird später in dieser Anleitung von der CREATE MODEL-Anweisung verwendet.
Führen Sie die Abfrage aus, mit der die Beispieldaten vorbereitet werden:
Öffnen Sie in der Google Cloud Console die Seite BigQuery.
Führen Sie im Abfrageeditor folgende Abfrage aus:
CREATE OR REPLACE VIEW `census.input_data` AS SELECT age, workclass, marital_status, education_num, occupation, hours_per_week, income_bracket, CASE WHEN MOD(functional_weight, 10) < 8 THEN 'training' WHEN MOD(functional_weight, 10) = 8 THEN 'evaluation' WHEN MOD(functional_weight, 10) = 9 THEN 'prediction' END AS dataframe FROM `bigquery-public-data.ml_datasets.census_adult_income`;
Beispieldaten ansehen:
SELECT * FROM `census.input_data`;
BigQuery DataFrames
Erstellen Sie einen DataFrame mit dem Namen input_data. input_data wird später in dieser Anleitung verwendet, um das Modell zu trainieren, zu bewerten und Vorhersagen zu treffen.
Bevor Sie dieses Beispiel ausprobieren, folgen Sie den Schritten zur Einrichtung von BigQuery DataFrames in der BigQuery-Kurzanleitung: BigQuery DataFrames verwenden. Weitere Informationen finden Sie in der Referenzdokumentation zu BigQuery DataFrames.
Richten Sie zur Authentifizierung bei BigQuery die Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter ADC für eine lokale Entwicklungsumgebung einrichten.
Logistisches Regressionsmodell erstellen
Erstellen Sie ein logistisches Regressionsmodell mit den Trainingsdaten, die Sie im vorherigen Abschnitt mit Labels versehen haben.
SQL
Verwenden Sie die Anweisung CREATE MODEL und geben Sie LOGISTIC_REG als Modelltyp an.
Im Folgenden finden Sie nützliche Informationen zur CREATE MODEL-Anweisung:
Die Option
input_label_colsgibt an, welche Spalte in derSELECT-Anweisung als Labelspalte verwendet werden soll. Hier ist die Labelspalteincome_bracket, sodass das Modell anhand der anderen in jeder Zeile vorhandenen Werte lernt, welcher der beiden Werte vonincome_bracketam wahrscheinlichsten ist.Sie müssen nicht angeben, ob ein logistisches Regressionsmodell binär oder mehrklassig ist. BigQuery ML bestimmt anhand der Anzahl der eindeutigen Werte in der Labelspalte, welcher Modelltyp trainiert werden soll.
Die Option
auto_class_weightsist aufTRUEfestgelegt, um die Klassenlabels in den Trainingsdaten auszugleichen. Standardmäßig sind die Trainingsdaten ungewichtet. Wenn die Labels in den Trainingsdaten nicht ausgewogen sind, lernt das Modell die Vorhersage der beliebtesten Labelklasse unter Umständen zu intensiv. In diesem Fall befinden sich die meisten Befragten im Dataset in der unteren Einkommensklasse. Dies kann zu einem Modell führen, in dem bei der Vorhersage die untere Einkommensklasse zu stark berücksichtigt wird. Mit Klassengewichtungen werden die Klassenlabels ausgeglichen. Dazu werden für jede Klasse die Gewichtungen im umgekehrten Verhältnis zur Häufigkeit dieser Klasse berechnet.Die Option
enable_global_explainist aufTRUEfestgelegt, damit Sie die FunktionML.GLOBAL_EXPLAINfür das Modell verwenden können.Mit der
SELECT-Anweisung wird die Ansichtinput_dataabgefragt, die die Beispieldaten enthält. Die KlauselWHEREfiltert die Zeilen so, dass nur die Zeilen, die als Trainingsdaten gekennzeichnet sind, zum Trainieren des Modells verwendet werden.
Führen Sie die Abfrage aus, mit der Ihr logistisches Regressionsmodell erstellt wird:
Öffnen Sie in der Google Cloud Console die Seite BigQuery.
Führen Sie im Abfrageeditor folgende Abfrage aus:
CREATE OR REPLACE MODEL `census.census_model` OPTIONS ( model_type='LOGISTIC_REG', auto_class_weights=TRUE, enable_global_explain=TRUE, data_split_method='NO_SPLIT', input_label_cols=['income_bracket'], max_iterations=15) AS SELECT * EXCEPT(dataframe) FROM `census.input_data` WHERE dataframe = 'training'
Klicken Sie im Bereich Explorer auf Datasets.
Klicken Sie im Bereich Datasets auf
census.Klicken Sie auf den Bereich Modelle.
Klicken Sie auf
census_model.Auf dem Tab Details werden die Attribute aufgeführt, die BigQuery ML zur Durchführung der logistischen Regression verwendet hat.
BigQuery DataFrames
Verwenden Sie die Methode fit, um das Modell zu trainieren, und die Methode to_gbq, um es in Ihrem Dataset zu speichern.
Bevor Sie dieses Beispiel ausprobieren, folgen Sie den Schritten zur Einrichtung von BigQuery DataFrames in der BigQuery-Kurzanleitung: BigQuery DataFrames verwenden. Weitere Informationen finden Sie in der Referenzdokumentation zu BigQuery DataFrames.
Richten Sie zur Authentifizierung bei BigQuery die Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter ADC für eine lokale Entwicklungsumgebung einrichten.
Modellleistung bewerten
Nachdem Sie das Modell erstellt haben, können Sie die Leistung des Modells anhand der Bewertungsdaten bewerten.
SQL
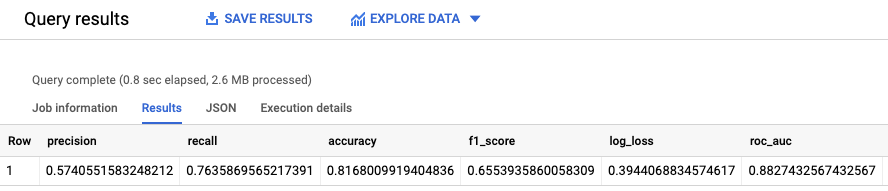
Die Funktion ML.EVALUATE-Funktion wertet die vom Modell generierten vorhergesagten Werte anhand der Bewertungsdaten aus.
Als Eingabe verwendet die Funktion ML.EVALUATE das trainierte Modell und die Zeilen aus der Ansicht input_data, für die evaluation als Spaltenwert dataframe festgelegt ist. Die Funktion gibt eine einzelne Zeile mit Statistiken zum Modell zurück.
Führen Sie die ML.EVALUATE-Abfrage aus:
Öffnen Sie in der Google Cloud Console die Seite BigQuery.
Führen Sie im Abfrageeditor folgende Abfrage aus:
SELECT * FROM ML.EVALUATE (MODEL `census.census_model`, ( SELECT * FROM `census.input_data` WHERE dataframe = 'evaluation' ) );
Die Ergebnisse sehen in etwa so aus:
BigQuery DataFrames
Verwenden Sie die Methode score, um das Modell anhand der tatsächlichen Daten zu bewerten.
Bevor Sie dieses Beispiel ausprobieren, folgen Sie den Schritten zur Einrichtung von BigQuery DataFrames in der BigQuery-Kurzanleitung: BigQuery DataFrames verwenden. Weitere Informationen finden Sie in der Referenzdokumentation zu BigQuery DataFrames.
Richten Sie zur Authentifizierung bei BigQuery die Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter ADC für eine lokale Entwicklungsumgebung einrichten.
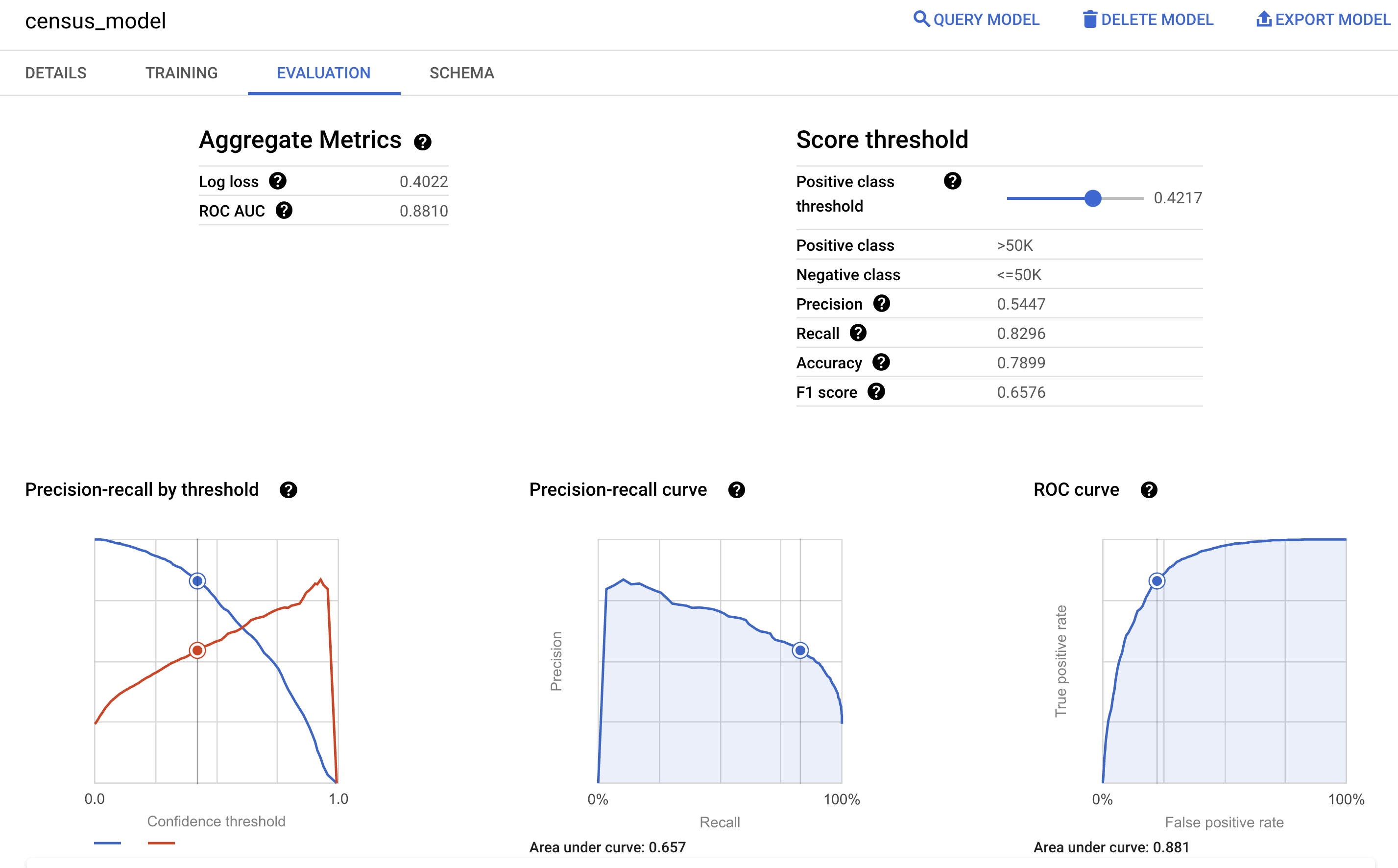
Sie können auch den Bereich Bewertung des Modells in der Google Cloud Console aufrufen, um die während des Trainings berechneten Bewertungsmesswerte aufzurufen:
Einkommensklasse vorhersagen
Verwenden Sie das Modell, um die wahrscheinlichste Einkommensklasse für jeden Befragten vorherzusagen.
SQL
Verwenden Sie die ML.PREDICT-Funktion, um Vorhersagen zur wahrscheinlichen Einkommensklasse zu treffen. Als Eingabe verwendet die Funktion ML.PREDICT das trainierte Modell und die Zeilen aus der Ansicht input_data, für die prediction als Spaltenwert dataframe festgelegt ist.
Führen Sie die ML.PREDICT-Abfrage aus:
Öffnen Sie in der Google Cloud Console die Seite BigQuery.
Führen Sie im Abfrageeditor folgende Abfrage aus:
SELECT * FROM ML.PREDICT (MODEL `census.census_model`, ( SELECT * FROM `census.input_data` WHERE dataframe = 'prediction' ) );
Die Ergebnisse sehen in etwa so aus:
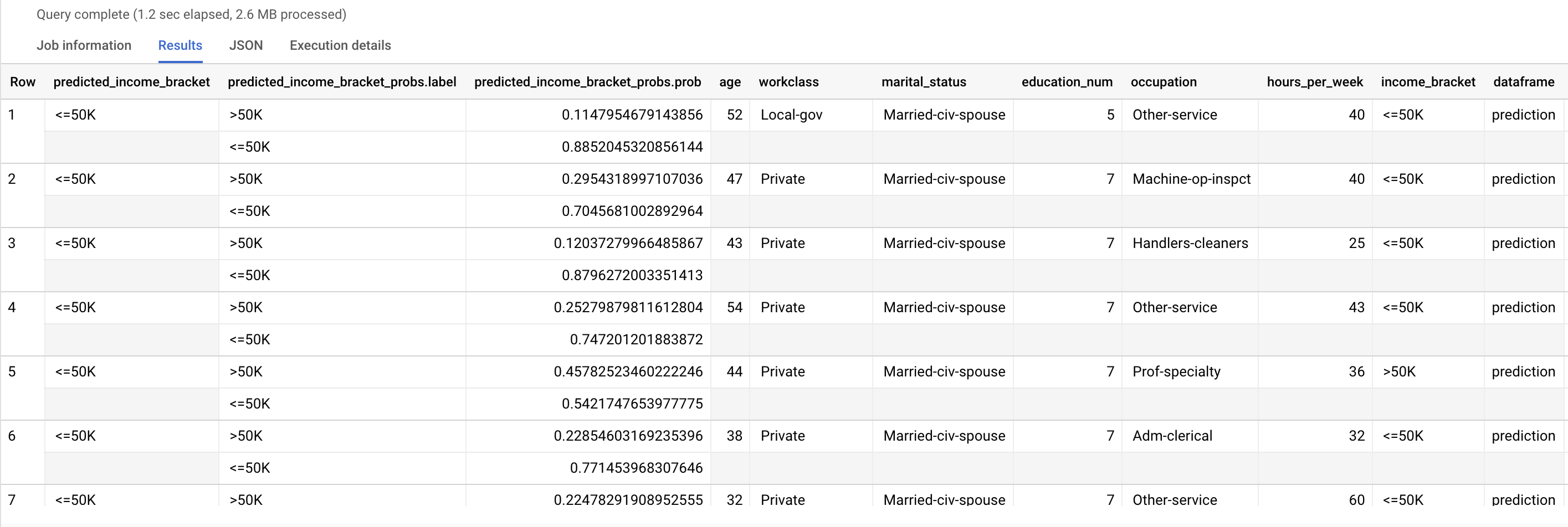
Die Spalte predicted_income_bracket enthält die prognostizierte Einkommensklasse für den Befragten.
BigQuery DataFrames
Verwenden Sie die Methode predict, um Vorhersagen zur wahrscheinlichen Einkommensklasse zu treffen.
Bevor Sie dieses Beispiel ausprobieren, folgen Sie den Schritten zur Einrichtung von BigQuery DataFrames in der BigQuery-Kurzanleitung: BigQuery DataFrames verwenden. Weitere Informationen finden Sie in der Referenzdokumentation zu BigQuery DataFrames.
Richten Sie zur Authentifizierung bei BigQuery die Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter ADC für eine lokale Entwicklungsumgebung einrichten.
Vorhersageergebnisse erklären
Mit der Funktion ML.EXPLAIN_PREDICT können Sie ermitteln, warum das Modell diese Vorhersageergebnisse generiert.
ML.EXPLAIN_PREDICT ist eine erweiterte Version der Funktion ML.PREDICT.
ML.EXPLAIN_PREDICT gibt nicht nur Vorhersageergebnisse aus, sondern gibt auch zusätzliche Spalten aus, um die Vorhersageergebnisse zu erklären. Weitere Informationen zur Erklärbarkeit finden Sie in der Übersicht zu BigQuery ML Explainable AI.
Führen Sie die ML.EXPLAIN_PREDICT-Abfrage aus:
Öffnen Sie in der Google Cloud Console die Seite BigQuery.
Führen Sie im Abfrageeditor folgende Abfrage aus:
SELECT * FROM ML.EXPLAIN_PREDICT(MODEL `census.census_model`, ( SELECT * FROM `census.input_data` WHERE dataframe = 'evaluation'), STRUCT(3 as top_k_features));
Die Ergebnisse sehen in etwa so aus:
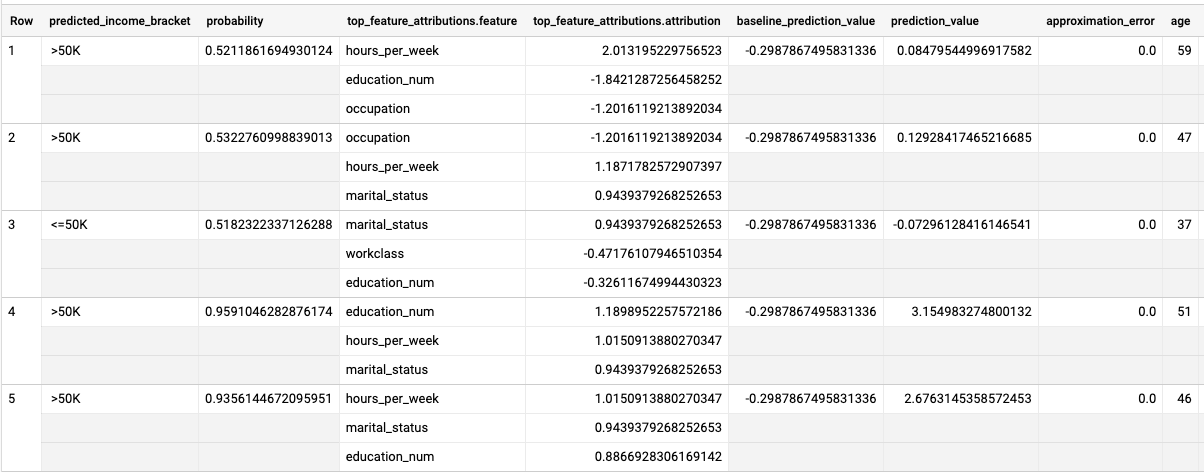
Bei logistischen Regressionsmodellen werden Shapley-Werte verwendet, um die relative Feature-Attribution für jedes Feature im Modell zu ermitteln. Da die Option top_k_features in der Abfrage auf 3 gesetzt wurde, gibt ML.EXPLAIN_PREDICT die drei wichtigsten Featureattributionen für jede Zeile der Ansicht input_data aus. Diese Zuordnungen werden in absteigender Reihenfolge nach dem absoluten Wert der Attribution angezeigt.
Modell global erklären
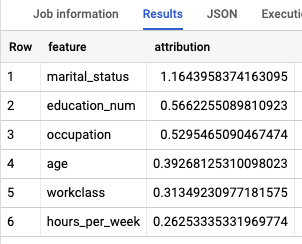
Mit der Funktion ML.GLOBAL_EXPLAIN können Sie ermitteln, welche Features am wichtigsten sind, um die Einkommensklasse zu bestimmen.
Globale Erläuterungen für das Modell abrufen:
Öffnen Sie in der Google Cloud Console die Seite BigQuery.
Führen Sie im Abfrageeditor die folgende Abfrage aus, um globale Erläuterungen zu erhalten:
SELECT * FROM ML.GLOBAL_EXPLAIN(MODEL `census.census_model`)
Die Ergebnisse sehen in etwa so aus:
Bereinigen
Damit Ihrem Google Cloud-Konto die in dieser Anleitung verwendeten Ressourcen nicht in Rechnung gestellt werden, löschen Sie entweder das Projekt, das die Ressourcen enthält, oder Sie behalten das Projekt und löschen die einzelnen Ressourcen.
Dataset löschen
Wenn Sie Ihr Projekt löschen, werden alle Datasets und Tabellen entfernt. Wenn Sie das Projekt wieder verwenden möchten, können Sie das in dieser Anleitung erstellte Dataset löschen:
Rufen Sie, falls erforderlich, die Seite „BigQuery“ in derGoogle Cloud Console auf.
Klicken Sie im Navigationsbereich auf das Dataset census, das Sie erstellt haben.
Klicken Sie rechts im Fenster auf Dataset löschen. Dadurch werden das Dataset und das Modell gelöscht.
Bestätigen Sie im Dialogfeld Dataset löschen den Löschbefehl. Geben Sie dazu den Namen des Datasets (
census) ein und klicken Sie auf Löschen.
Projekt löschen
So löschen Sie das Projekt:
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
Nächste Schritte
- Einführung in BigQuery ML
- Mehr zum Erstellen von Modellen auf der Seite zur
CREATE MODEL-Syntax