在本教程中,您将使用 BigQuery ML 中的线性回归模型,根据企鹅的群体特征信息来预测企鹅的体重。线性回归是一种回归模型,它根据输入特征的线性组合生成连续值。
本教程使用 bigquery-public-data.ml_datasets.penguins 数据集。
目标
在本教程中,您将执行以下任务:
- 创建一个线性回归模型。
- 评估此模型。
- 使用此模型进行预测。
费用
本教程使用 Google Cloud的收费组件,包括以下组件:
- BigQuery
- BigQuery ML
如需了解有关 BigQuery 费用的更多信息,请参阅 BigQuery 价格页面。
如需详细了解 BigQuery ML 费用,请参阅 BigQuery ML 价格。
准备工作
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
Enable the BigQuery API.
所需权限
如需使用 BigQuery ML 创建模型,您需要以下 IAM 权限:
bigquery.jobs.createbigquery.models.createbigquery.models.getDatabigquery.models.updateDatabigquery.models.updateMetadata
如需运行推理,您需要以下权限:
- 模型的
bigquery.models.getData权限 bigquery.jobs.create
创建数据集
创建 BigQuery 数据集以存储您的机器学习模型:
在 Google Cloud 控制台中,前往 BigQuery 页面。
在探索器窗格中,点击您的项目名称。
点击 查看操作 > 创建数据集。
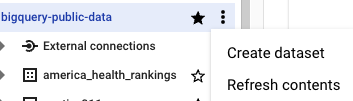
在创建数据集页面上,执行以下操作:
在数据集 ID 部分,输入
bqml_tutorial。在位置类型部分,选择多区域,然后选择 US (multiple regions in United States)(美国[美国的多个区域])。
公共数据集存储在
US多区域中。为简单起见,请将数据集存储在同一位置。保持其余默认设置不变,然后点击创建数据集。
创建模型
使用适用于 BigQuery 的 Google Analytics 示例数据集创建线性回归模型。
SQL
您可以使用 CREATE MODEL 语句并为模型类型指定 LINEAR_REG,来创建线性回归模型。创建模型包括训练模型。
以下是有关 CREATE MODEL 语句的实用信息:
input_label_cols选项指定SELECT语句中的哪个列将用作标签列。在这里,标签列为body_mass_g。对于线性回归模型来说,标签列必须为实值,即,列值必须是实数。此查询的
SELECT语句使用bigquery-public-data.ml_datasets.penguins表中的以下列来预测企鹅的体重:species:企鹅的种类。island:企鹅所在的岛屿。culmen_length_mm:企鹅嘴峰的长度(以毫米为单位)。culmen_depth_mm:企鹅嘴峰的深度(以毫米为单位)。flipper_length_mm:企鹅鳍肢的长度(以毫米为单位)。sex:企鹅的性别。
此查询的
SELECT语句WHERE body_mass_g IS NOT NULL中的WHERE子句不包括body_mass_g列为NULL的行。
运行可创建线性回归模型的查询:
在 Google Cloud 控制台中,前往 BigQuery 页面。
在查询编辑器中,运行以下查询:
CREATE OR REPLACE MODEL `bqml_tutorial.penguins_model` OPTIONS (model_type='linear_reg', input_label_cols=['body_mass_g']) AS SELECT * FROM `bigquery-public-data.ml_datasets.penguins` WHERE body_mass_g IS NOT NULL;
创建
penguins_model模型大约需要 30 秒。如需查看模型,请转到浏览器窗格,展开bqml_tutorial数据集,然后展开模型文件夹。
BigQuery DataFrame
在尝试此示例之前,请按照《BigQuery 快速入门:使用 BigQuery DataFrames》中的 BigQuery DataFrames 设置说明进行操作。如需了解详情,请参阅 BigQuery DataFrames 参考文档。
如需向 BigQuery 进行身份验证,请设置应用默认凭据。 如需了解详情,请参阅为本地开发环境设置 ADC。
创建模型大约需要 30 秒。如需查看模型,请前往浏览器窗格,展开 bqml_tutorial 数据集,然后展开模型文件夹。
获取训练统计信息
如需查看模型训练的结果,您可以使用 ML.TRAINING_INFO 函数,也可以在 Google Cloud 控制台中查看统计信息。在本教程中,您将使用 Google Cloud 控制台。
机器学习算法通过检查多个示例并尝试找到实现损失最小化的模型来构建模型。该过程称为经验风险最小化。
损失是对糟糕预测的惩罚。它是一个数字,表示模型在单个样本上的预测效果如何。如果模型的预测完全准确,则损失为零,否则损失会大于零。训练模型的目标是从所有示例中找到一组平均损失“较小”的权重和偏差。
查看运行 CREATE MODEL 查询时生成的模型训练统计信息:
在探索器窗格中,展开
bqml_tutorial数据集,然后展开模型文件夹。点击 penguins_model 打开模型信息窗格。点击训练标签页,然后点击表。结果应如下所示:
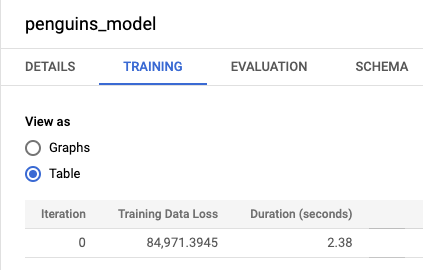
训练数据丢失列表示在训练数据集上训练模型后计算得出的损失指标。由于您执行了线性回归,因此此列显示均方误差值。系统会自动将 normal_equation 优化策略用于此训练,因此只需要一次迭代就可以收敛到最终模型。如需详细了解如何设置模型优化策略,请参阅
optimize_strategy。
评估模型
创建模型后,您可以使用 ML.EVALUATE 函数或 score BigQuery DataFrames 函数根据实际数据评估模型生成的预测值,从而评估模型的性能。
SQL
对于输入,ML.EVALUATE 函数会采用经过训练的模型以及一个与用于训练模型的数据架构匹配的数据集。在生产环境中,您应该使用与训练模型所用数据不同的数据评估模型。如果您在未提供输入数据的情况下运行 ML.EVALUATE,该函数会检索训练期间计算得出的评估指标。这些指标是使用自动预留的评估数据集计算的:
SELECT
*
FROM
ML.EVALUATE(MODEL bqml_tutorial.penguins_model);
运行 ML.EVALUATE 查询:
在 Google Cloud 控制台中,前往 BigQuery 页面。
在查询编辑器中,运行以下查询:
SELECT * FROM ML.EVALUATE(MODEL `bqml_tutorial.penguins_model`, ( SELECT * FROM `bigquery-public-data.ml_datasets.penguins` WHERE body_mass_g IS NOT NULL));
BigQuery DataFrame
在尝试此示例之前,请按照《BigQuery 快速入门:使用 BigQuery DataFrames》中的 BigQuery DataFrames 设置说明进行操作。如需了解详情,请参阅 BigQuery DataFrames 参考文档。
如需向 BigQuery 进行身份验证,请设置应用默认凭据。 如需了解详情,请参阅为本地开发环境设置 ADC。
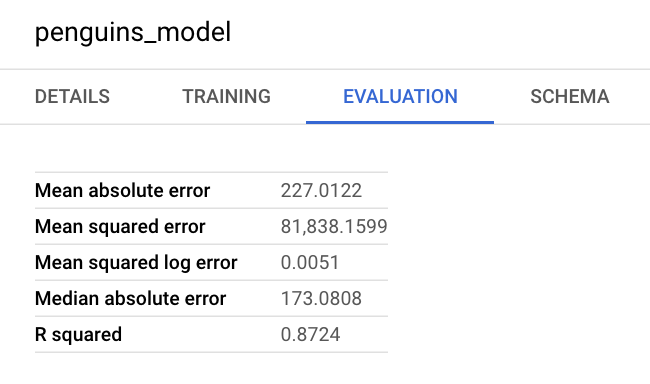
结果应如下所示:
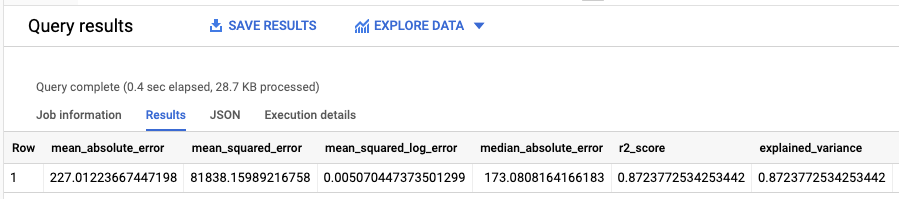
由于您执行了线性回归,因此结果包含以下列:
mean_absolute_errormean_squared_errormean_squared_log_errormedian_absolute_errorr2_scoreexplained_variance
评估结果中的一项重要指标为 R2 得分。R2 得分为统计测量结果,用于确定线性回归预测是否接近实际数据。0 值表示该模型未能说明响应数据相对于平均值的可变性。1 值表示该模型说明了响应数据相对于平均值的所有可变性。
您还可以在 Google Cloud 控制台中查看模型的信息窗格,以查看评估指标:
使用模型预测结果
您现已对模型进行了评估,下一步是用其预测结果。您可以对模型运行 ML.PREDICT 函数或 predict BigQuery DataFrames 函数,以预测比斯科群岛上所有企鹅的体重(以克为单位)。
SQL
对于输入,ML.PREDICT 函数会采用经过训练的模型,以及一个与您训练模型所用数据架构匹配的数据集(不包括标签列)。
运行 ML.PREDICT 查询:
在 Google Cloud 控制台中,前往 BigQuery 页面。
在查询编辑器中,运行以下查询:
SELECT * FROM ML.PREDICT(MODEL `bqml_tutorial.penguins_model`, ( SELECT * FROM `bigquery-public-data.ml_datasets.penguins` WHERE island = 'Biscoe'));
BigQuery DataFrame
在尝试此示例之前,请按照《BigQuery 快速入门:使用 BigQuery DataFrames》中的 BigQuery DataFrames 设置说明进行操作。如需了解详情,请参阅 BigQuery DataFrames 参考文档。
如需向 BigQuery 进行身份验证,请设置应用默认凭据。 如需了解详情,请参阅为本地开发环境设置 ADC。
结果应如下所示:

解释预测结果
如需了解您的模型为何生成这些预测结果,您可以使用 ML.EXPLAIN_PREDICT 函数。
ML.EXPLAIN_PREDICT 是 ML.PREDICT 函数的扩展版本。ML.EXPLAIN_PREDICT 不仅输出预测结果,还会输出其他列来解释预测结果。实际上,您可以运行 ML.EXPLAIN_PREDICT 而不是 ML.PREDICT。如需了解详情,请参阅 BigQuery ML Explainable AI 概览。
运行 ML.EXPLAIN_PREDICT 查询:
在 Google Cloud 控制台中,前往 BigQuery 页面。
在查询编辑器中,运行以下查询:
SELECT * FROM ML.EXPLAIN_PREDICT(MODEL `bqml_tutorial.penguins_model`, ( SELECT * FROM `bigquery-public-data.ml_datasets.penguins` WHERE island = 'Biscoe'), STRUCT(3 as top_k_features));
结果应如下所示:
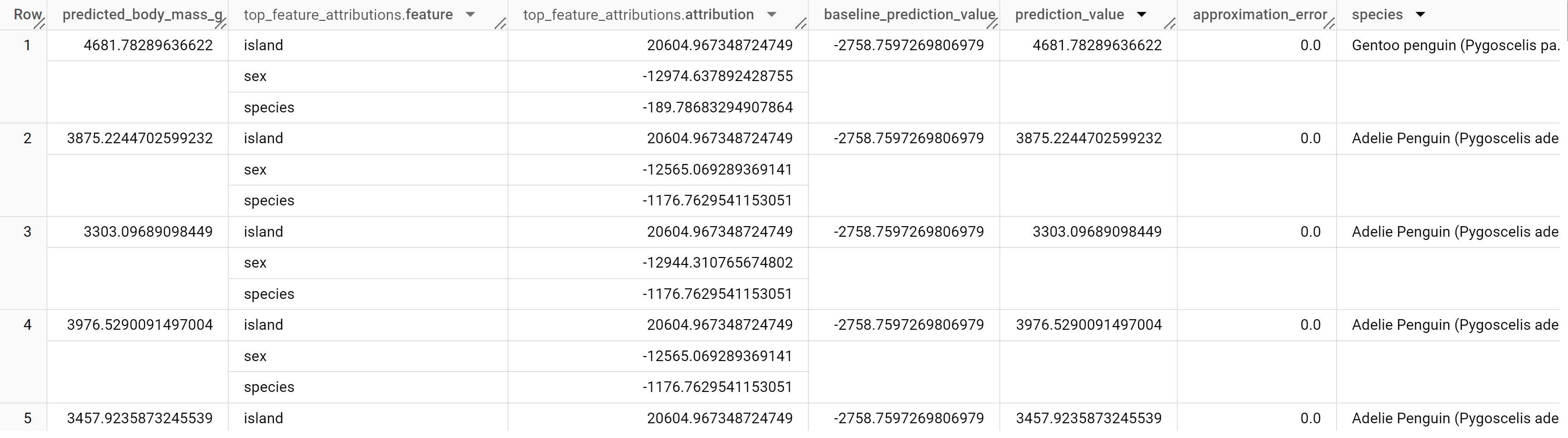
对于线性回归模型,Shapley 值用于为模型中的每个特征生成特征归因值。ML.EXPLAIN_PREDICT 会输出 penguins 表中每行的前三个特征归因,因为在查询中 top_k_features 被设置为 3。这些归因按照归因的绝对值降序排列。在所有示例中,特征 sex 对整体预测的贡献最大。
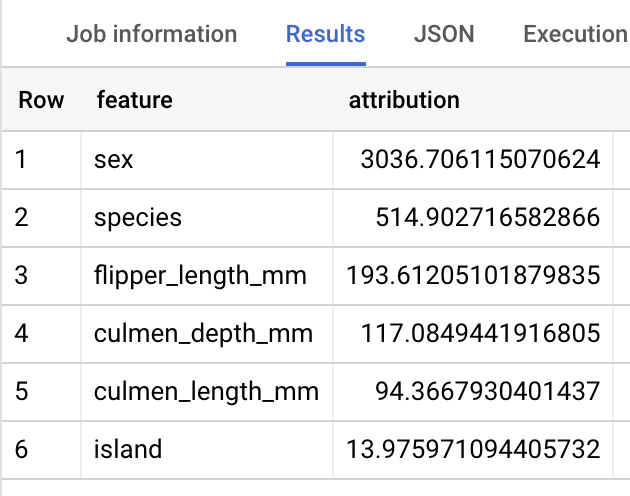
对模型进行全局说明
要了解哪些特征通常对于确定企鹅体重最重要,可以使用 ML.GLOBAL_EXPLAIN 函数。为了使用 ML.GLOBAL_EXPLAIN,您必须将 ENABLE_GLOBAL_EXPLAIN 选项设置为 TRUE 来重新训练模型。
重新训练模型并获取模型的全局说明:
在 Google Cloud 控制台中,前往 BigQuery 页面。
在查询编辑器中,运行以下查询来重新训练模型:
#standardSQL CREATE OR REPLACE MODEL `bqml_tutorial.penguins_model` OPTIONS ( model_type = 'linear_reg', input_label_cols = ['body_mass_g'], enable_global_explain = TRUE) AS SELECT * FROM `bigquery-public-data.ml_datasets.penguins` WHERE body_mass_g IS NOT NULL;
在查询编辑器中,运行以下查询来获取全局说明:
SELECT * FROM ML.GLOBAL_EXPLAIN(MODEL `bqml_tutorial.penguins_model`)
结果应如下所示:
清理
为避免因本教程中使用的资源导致您的 Google Cloud 账号产生费用,请删除包含这些资源的项目,或者保留项目但删除各个资源。
- 删除您在教程中创建的项目。
- 或者,保留项目但删除数据集。
删除数据集
删除项目也将删除项目中的所有数据集和所有表。如果您希望重复使用该项目,则可以删除在本教程中创建的数据集:
如有必要,请在Google Cloud 控制台中打开 BigQuery 页面。
在导航窗格中,点击您创建的 bqml_tutorial 数据集。
点击窗口右侧的删除数据集。此操作会删除相关数据集、表和所有数据。
在删除数据集对话框中,输入您的数据集的名称 (
bqml_tutorial),然后点击删除以确认删除命令。
删除项目
要删除项目,请执行以下操作:
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
后续步骤
- 如需大致了解 BigQuery ML,请参阅 BigQuery ML 简介。
- 如需了解如何创建模型,请参阅
CREATE MODEL语法页面。