이 튜토리얼에서는 BigQuery ML의 k-평균 모델을 사용하여 데이터 세트의 클러스터를 식별하는 방법을 알아봅니다.
데이터를 클러스터로 그룹화하는 k-평균 알고리즘은 비지도 머신러닝의 한 형태입니다. 지도 머신러닝의 핵심이 예측 분석이라면 비지도 머신러닝의 핵심은 설명적 분석입니다. 비지도 머신러닝을 사용하면 데이터를 이해하여 데이터를 토대로 의사 결정을 내릴 수 있습니다.
이 튜토리얼의 쿼리에서는 지리정보 분석에서 사용할 수 있는 지리 함수를 사용합니다. 자세한 내용은 지리정보 분석 소개를 참조하세요.
이 튜토리얼에서는 런던 자전거 공유 공개 데이터 세트를 사용합니다. 데이터에는 시작 및 중지 타임스탬프, 정거장 이름, 자전거 이용 시간이 포함됩니다.
데이터 세트 만들기
k-평균 모델을 저장할 BigQuery 데이터 세트를 만듭니다.
Google Cloud 콘솔에서 BigQuery 페이지로 이동합니다.
왼쪽 창에서 탐색기를 클릭합니다.

왼쪽 창이 표시되지 않으면 왼쪽 창 펼치기를 클릭하여 창을 엽니다.
탐색기 창에서 프로젝트 이름을 클릭합니다.
작업 보기 > 데이터 세트 만들기를 클릭합니다.
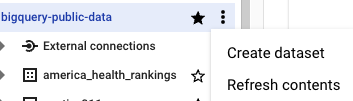
데이터 세트 만들기 페이지에서 다음을 수행합니다.
데이터 세트 ID에
bqml_tutorial를 입력합니다.위치 유형으로 멀티 리전을 선택한 후 EU(유럽 연합의 여러 리전)를 선택합니다.
런던 자전거 공유 공개 데이터 세트는
EU멀티 리전에 저장됩니다. 데이터 세트도 같은 위치에 있어야 합니다.나머지 기본 설정은 그대로 두고 데이터 세트 만들기를 클릭합니다.

학습 데이터 검토
k-평균 모델을 학습시키는 데 사용할 데이터를 검사합니다. 이 튜토리얼에서는 다음 속성에 따라 자전거 정거장을 클러스터링합니다.
- 대여 기간
- 일일 운행 횟수
- 도심에서의 거리
SQL
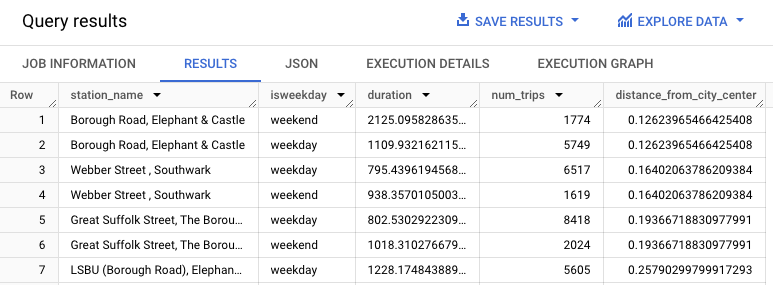
이 쿼리는 start_station_name 및 duration 열을 포함한 자전거 대여에 대한 데이터를 추출하고 이 데이터를 정거장 정보와 조인합니다. 여기에는 도심에서 정거장까지의 거리가 포함된 계산된 열을 만드는 작업이 포함됩니다. 그런 다음 평균 운행 시간과 운행 횟수를 포함하여 stationstats 열의 정거장 속성과 계산된 distance_from_city_center 열을 계산합니다.
다음 단계에 따라 학습 데이터를 검사합니다.
Google Cloud 콘솔에서 BigQuery 페이지로 이동합니다.
쿼리 편집기에 다음 쿼리를 붙여넣고 실행을 클릭합니다.
WITH hs AS ( SELECT h.start_station_name AS station_name, IF( EXTRACT(DAYOFWEEK FROM h.start_date) = 1 OR EXTRACT(DAYOFWEEK FROM h.start_date) = 7, 'weekend', 'weekday') AS isweekday, h.duration, ST_DISTANCE(ST_GEOGPOINT(s.longitude, s.latitude), ST_GEOGPOINT(-0.1, 51.5)) / 1000 AS distance_from_city_center FROM `bigquery-public-data.london_bicycles.cycle_hire` AS h JOIN `bigquery-public-data.london_bicycles.cycle_stations` AS s ON h.start_station_id = s.id WHERE h.start_date BETWEEN CAST('2015-01-01 00:00:00' AS TIMESTAMP) AND CAST('2016-01-01 00:00:00' AS TIMESTAMP) ), stationstats AS ( SELECT station_name, isweekday, AVG(duration) AS duration, COUNT(duration) AS num_trips, MAX(distance_from_city_center) AS distance_from_city_center FROM hs GROUP BY station_name, isweekday ) SELECT * FROM stationstats ORDER BY distance_from_city_center ASC;
결과는 다음과 비슷하게 표시됩니다.
BigQuery DataFrames
이 샘플을 사용해 보기 전에 BigQuery DataFrames를 사용하여 BigQuery 빠른 시작의 BigQuery DataFrames 설정 안내를 따르세요. 자세한 내용은 BigQuery DataFrames 참고 문서를 확인하세요.
BigQuery에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 로컬 개발 환경의 ADC 설정을 참조하세요.
k-평균 모델 만들기
런던 자전거 공유 학습 데이터를 사용하여 k-평균 모델을 만듭니다.
SQL
다음 쿼리에서 CREATE MODEL 문은 사용할 클러스터 수(4개)를 지정합니다. station_name 열에는 특성이 포함되어 있지 않으므로 SELECT 문에서 EXCEPT 절은 이 열을 제외합니다. 쿼리는 station_name별로 고유한 행을 만들며, 특성만 SELECT 문에 언급됩니다.
k-평균 모델을 만들려면 다음 단계를 따르세요.
Google Cloud 콘솔에서 BigQuery 페이지로 이동합니다.
쿼리 편집기에 다음 쿼리를 붙여넣고 실행을 클릭합니다.
CREATE OR REPLACE MODEL `bqml_tutorial.london_station_clusters` OPTIONS ( model_type = 'kmeans', num_clusters = 4) AS WITH hs AS ( SELECT h.start_station_name AS station_name, IF( EXTRACT(DAYOFWEEK FROM h.start_date) = 1 OR EXTRACT(DAYOFWEEK FROM h.start_date) = 7, 'weekend', 'weekday') AS isweekday, h.duration, ST_DISTANCE(ST_GEOGPOINT(s.longitude, s.latitude), ST_GEOGPOINT(-0.1, 51.5)) / 1000 AS distance_from_city_center FROM `bigquery-public-data.london_bicycles.cycle_hire` AS h JOIN `bigquery-public-data.london_bicycles.cycle_stations` AS s ON h.start_station_id = s.id WHERE h.start_date BETWEEN CAST('2015-01-01 00:00:00' AS TIMESTAMP) AND CAST('2016-01-01 00:00:00' AS TIMESTAMP) ), stationstats AS ( SELECT station_name, isweekday, AVG(duration) AS duration, COUNT(duration) AS num_trips, MAX(distance_from_city_center) AS distance_from_city_center FROM hs GROUP BY station_name, isweekday ) SELECT * EXCEPT (station_name, isweekday) FROM stationstats;
BigQuery DataFrames
이 샘플을 사용해 보기 전에 BigQuery DataFrames를 사용하여 BigQuery 빠른 시작의 BigQuery DataFrames 설정 안내를 따르세요. 자세한 내용은 BigQuery DataFrames 참고 문서를 확인하세요.
BigQuery에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 로컬 개발 환경의 ADC 설정을 참조하세요.
데이터 클러스터 해석
모델의 평가 탭에 있는 정보를 통해 모델에서 생성된 클러스터를 해석할 수 있습니다.
모델의 평가 정보를 보려면 다음 단계를 따르세요.
Google Cloud 콘솔에서 BigQuery 페이지로 이동합니다.
왼쪽 창에서 탐색기를 클릭합니다.
탐색기 창에서 프로젝트를 펼치고 데이터 세트를 클릭합니다.
bqml_tutorial데이터 세트를 클릭한 다음 모델 탭으로 이동합니다.london_station_clusters모델을 선택합니다.평가 탭을 선택합니다. 이 탭에는 k-평균 모델로 식별된 클러스터가 시각화되어 표시됩니다. 숫자 특성 섹션에서 막대 그래프는 각 중심에 가장 중요한 숫자 특성 값을 표시합니다. 각 중심은 지정된 데이터 클러스터를 나타냅니다. 드롭다운 메뉴에서 시각화할 특성을 선택할 수 있습니다.
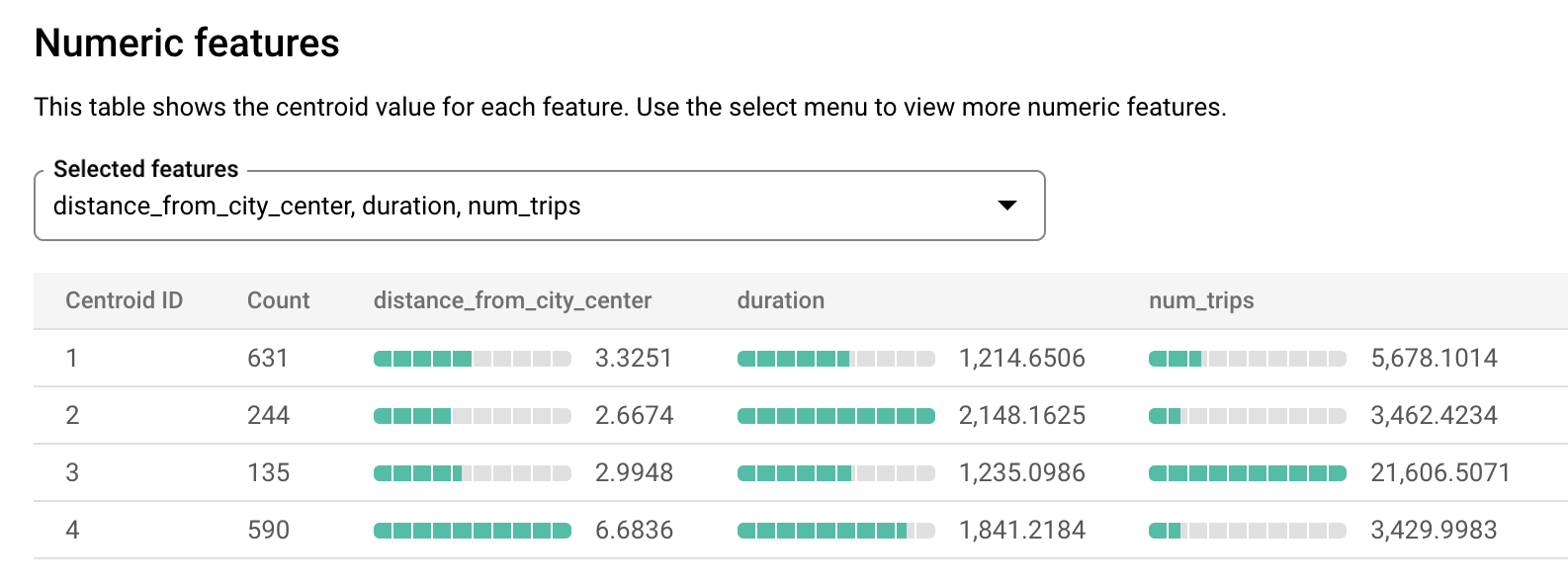
이 모델은 다음과 같은 중심을 만듭니다.
- 중심 1은 대여 기간이 더 짧고 덜 혼잡한 도시 정거장을 보여줍니다.
- 중심 2는 덜 혼잡하고 장기 대여용으로 사용되는 두 번째 도시 정거장을 보여줍니다.
- 중심 3은 도심에 가까운 혼잡한 도시 정거장을 보여줍니다.
- 중심 4는 운행 거리가 더 긴 교외 정거장을 보여줍니다.
자전거 대여 비즈니스를 운영하는 경우 이 정보를 참고하여 비즈니스 결정을 내릴 수 있습니다. 예를 들면 다음과 같습니다.
새로운 유형의 자물쇠를 실험해야 하는 경우를 가정해 보겠습니다. 이 실험 대상으로 어느 정거장 클러스터를 선택해야 할까요? 중심 1, 중심 2, 중심 4의 정거장은 사용량이 높은 정거장이 아니므로 논리적인 대안으로 보입니다.
일부 정거장에 경주용 자전거를 비치하려는 경우를 가정해 보겠습니다. 어느 정거장을 선택해야 할까요? 중심 4는 도심에서 멀리 떨어져 있어 운행 거리가 가장 긴 정거장 그룹입니다. 경주용 자전거를 위한 후보지로 적합할 수 있습니다.
ML.PREDICT 함수를 사용하여 정거장의 클러스터 예측
ML.PREDICT SQL 함수 또는 predict BigQuery DataFrames 함수를 사용하여 특정 정거장이 속한 클러스터를 식별합니다.
SQL
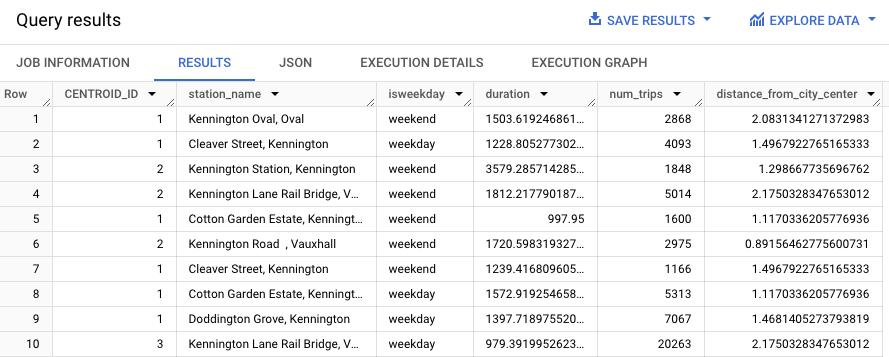
다음 쿼리는 REGEXP_CONTAINS 함수를 사용하여 station_name 열에서 Kennington 문자열이 포함된 모든 항목을 찾습니다. ML.PREDICT 함수는 이 값을 사용하여 어느 클러스터에 이러한 정거장이 포함되어 있는지 예측합니다.
다음 단계에 따라 이름에 Kennington 문자열이 포함된 모든 정거장의 클러스터를 예측합니다.
Google Cloud 콘솔에서 BigQuery 페이지로 이동합니다.
쿼리 편집기에 다음 쿼리를 붙여넣고 실행을 클릭합니다.
WITH hs AS ( SELECT h.start_station_name AS station_name, IF( EXTRACT(DAYOFWEEK FROM h.start_date) = 1 OR EXTRACT(DAYOFWEEK FROM h.start_date) = 7, 'weekend', 'weekday') AS isweekday, h.duration, ST_DISTANCE(ST_GEOGPOINT(s.longitude, s.latitude), ST_GEOGPOINT(-0.1, 51.5)) / 1000 AS distance_from_city_center FROM `bigquery-public-data.london_bicycles.cycle_hire` AS h JOIN `bigquery-public-data.london_bicycles.cycle_stations` AS s ON h.start_station_id = s.id WHERE h.start_date BETWEEN CAST('2015-01-01 00:00:00' AS TIMESTAMP) AND CAST('2016-01-01 00:00:00' AS TIMESTAMP) ), stationstats AS ( SELECT station_name, isweekday, AVG(duration) AS duration, COUNT(duration) AS num_trips, MAX(distance_from_city_center) AS distance_from_city_center FROM hs GROUP BY station_name, isweekday ) SELECT * EXCEPT (nearest_centroids_distance) FROM ML.PREDICT( MODEL `bqml_tutorial.london_station_clusters`, ( SELECT * FROM stationstats WHERE REGEXP_CONTAINS(station_name, 'Kennington') ));
결과는 다음과 비슷하게 표시됩니다.
BigQuery DataFrames
이 샘플을 사용해 보기 전에 BigQuery DataFrames를 사용하여 BigQuery 빠른 시작의 BigQuery DataFrames 설정 안내를 따르세요. 자세한 내용은 BigQuery DataFrames 참고 문서를 확인하세요.
BigQuery에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 로컬 개발 환경의 ADC 설정을 참조하세요.