Sistemas de red para el análisis espacial
En este documento, se explica el propósito y los métodos del uso de sistemas de cuadrícula geoespaciales (como S2 y H3) en BigQuery para organizar datos espaciales en áreas geográficas estandarizadas. También se explica cómo elegir el sistema de cuadrícula adecuado para tu aplicación. Este documento es útil para cualquier persona que trabaje con datos espaciales y realice análisis espaciales en BigQuery.
Descripción general y desafíos del uso del análisis espacial
Las estadísticas espaciales ayudan a mostrar la relación entre entidades (tiendas o casas) y los eventos en un espacio físico. Las estadísticas espaciales que usan la superficie de la Tierra como el espacio físico se denominan estadísticas geoespaciales. BigQuery incluye características y funciones geoespaciales que te permiten realizar análisis geoespaciales a gran escala.
Muchos casos de uso geoespaciales incluyen agregar datos dentro de áreas localizadas y comparar agregaciones estadísticas de esas áreas entre sí. Estas áreas localizadas se representan como polígonos en una tabla de base de datos espacial. En algunos contextos, este método se denomina geografía estadística. El método para determinar la extensión de las áreas geográficas se debe estandarizar para mejorar la generación de informes, el análisis y la indexación espacial. Por ejemplo, es posible que un minorista quiera analizar los cambios en los datos demográficos a lo largo del tiempo en las áreas donde se encuentran sus tiendas o en las áreas en las que consideran construir una tienda nueva. O bien, es posible que una empresa de seguros desee mejorar su comprensión de los riesgos de propiedad mediante el análisis de los riesgos de peligro natural predominantes en un área en particular.
Debido a las estrictas regulaciones de privacidad de los datos en muchas áreas, los conjuntos de datos que contienen información de ubicación deben desidentificarse o anonimizarse parcialmente para ayudar a proteger la privacidad de las personas representadas en los datos. Por ejemplo, es posible que debas realizar un análisis de riesgo de concentración de crédito geográfico en un conjunto de datos que contenga datos sobre préstamos hipotecarios pendientes. Si deseas desidentificar el conjunto de datos a fin de que sea apropiado para el análisis compatible, debes conservar información relevante sobre la ubicación de las propiedades, pero debes evitar usar una dirección específica o coordenadas de longitud y latitud.
En los ejemplos anteriores, a los diseñadores de estos análisis se los presentan los siguientes desafíos:
- ¿Cómo dibujar los límites de área dentro de los cuales analizas los cambios a lo largo del tiempo?
- ¿Cómo se usan los límites administrativos existentes, como los tramos censales o un sistema de cuadrícula con varias resoluciones?
En este documento, el objetivo es responder estas preguntas mediante la explicación de cada opción, describir las prácticas recomendadas y ayudarte a evitar errores comunes.
Errores comunes en la elección de áreas estadísticas
Los conjuntos de datos empresariales, como las ventas de bienes raíces, las campañas de marketing, los envíos de comercio electrónico y las políticas de seguros, son adecuados para el análisis espacial. A menudo, estos conjuntos de datos contienen lo que parece ser una clave de unión espacial conveniente, como un área del censo, un código postal o el nombre de una ciudad. Los conjuntos de datos públicos que contienen representaciones de terrenos del censo, códigos postales y ciudades están disponibles de manera fácil, lo que los hace tentadores de usarlos como límites administrativos para la agregación estadística.
Si bien es nominalmente conveniente, estos y otros límites administrativos presentan desventajas. Además, estos límites pueden funcionar bien en las primeras etapas de un proyecto de estadísticas, pero se pueden notar las desventajas en las etapas posteriores.
Códigos postales
Los códigos postales se usan para enrutar el correo en varios países del mundo y, debido a esta ubicuidad, se suelen usar para hacer referencia a ubicaciones y áreas en conjuntos de datos espaciales y no espaciales. En referencia al ejemplo anterior sobre el préstamo hipotecario, a menudo un conjunto de datos debe desidentificarse antes de que se pueda realizar un análisis posterior. Dado que cada dirección de propiedad contiene un código postal, se puede acceder a las tablas de referencia de código postal, por lo que son una opción conveniente para una clave de unión para el análisis espacial.
Un error en el uso de códigos postales es que no se representan como polígonos y no hay una única fuente de información correcta para las áreas de código postal. Además, los códigos postales no son una buena representación del comportamiento real de las personas. Los datos de código postal que más se usan en EE.UU. son el TIGER/Line Shapefiles de la Oficina del Censo de EE.UU., que contiene un conjunto de datos llamado ZCTA5 (Área de tabulación de códigos postales). Este conjunto de datos representa una aproximación de los límites de códigos postales que se derivan de las rutas de entrega de correo electrónico. Sin embargo, algunos códigos postales que representan edificios individuales no tienen ningún límite. Este problema también está presente en otros países, lo que dificulta la creación de una única tabla de hechos global que contenga un conjunto autorizado de límites de código postal que puede usarse en sistemas y conjuntos de datos.
Además, no existe un formato de código postal estandarizado que se usa en todo el mundo. Algunos son numéricos, de tres a diez dígitos, mientras que otros son alfanuméricos. También existe una superposición entre los países, por lo que es necesario almacenar el país de origen en una columna separada junto con el código postal. Algunos países no usan códigos postales, lo que complica aún más el análisis.
Tratamientos de censos, ciudades y condados
Hay algunas unidades administrativas, como los distritos de censos, las ciudades y los condados, que no se ven afectados por la falta de un límite autorizado. Por ejemplo, los límites de las ciudades están bien establecidos por las autoridades gubernamentales. Los paneles del censo están bien definidos por la Oficina del Censo de EE.UU. y por sus instituciones análogas en la mayoría de los demás países.
Un inconveniente de usar estos y otros límites administrativos es que cambian con el tiempo y no son coherentes a nivel geográfico entre sí. Los condados y las ciudades se combinan o se separan entre sí y, a veces, se les cambia su nombre. Los resúmenes del censo se actualizan una vez por década en EE.UU. y en momentos diferentes en otros países. Es confuso, en algunos casos, el límite geográfico puede cambiar, pero su identificador único sigue siendo el mismo, lo que dificulta el análisis y la comprensión de los cambios a lo largo del tiempo.
Otra desventaja común a algunos límites administrativos es que son áreas discretas sin jerarquía geográfica. Además de comparar las áreas individuales entre sí, un requisito común es comparar las agregaciones de las áreas con otras agregaciones. Por ejemplo, un minorista que implementa el modelo de Huff podría ejecutar este análisis mediante varias distancias, que podrían no corresponder a áreas administrativas que se usan en otro lugar de la empresa.
Cuadrículas de una y varias resolución
Las cuadrículas de una sola resolución constan de unidades discretas que no tienen relación geográfica con áreas más grandes que contienen esas unidades. Por ejemplo, los códigos postales tienen una relación geográfica incoherente con los límites de unidades administrativas más grandes, como ciudades o condados que pueden contener códigos postales. Para el análisis espacial, es importante comprender cómo se relacionan las diferentes áreas entre sí sin un conocimiento profundo de la historia y la legislación que define el polígono del área.
Las cuadrículas de varias resolución a veces se denominan cuadrículas jerárquicas porque las celdas de cada nivel de zoom se subdividen en celdas más pequeñas en niveles de zoom más altos. Las cuadrículas de varias resoluciones consisten en una jerarquía bien definida de unidades que se encuentran dentro de unidades más grandes. Los segmentos del censo, por ejemplo, contienen grupos de bloques, que a su vez contienen bloques. Esta relación jerárquica coherente puede ser útil para la agregación estadística. Por ejemplo, si tomas un promedio de los ingresos de todos los grupos de bloques contenidos en un segmento, puedes mostrar los ingresos promedio de ese segmento del censo que contiene los grupos de bloques. Esto no sería posible con códigos postales, ya que todas las áreas postales están ubicadas en una misma resolución. Sería difícil comparar el ingreso de un tramo con sus segmentos, ya que no existe una forma estandarizada de definir la adyacencia o comparar los ingresos en diferentes países.
Sistemas de cuadrícula S2 y H3
En esta sección, se proporciona una descripción general de los sistemas de cuadrícula de S2 y H3.
S2
La geometría S2 es un sistema de cuadrícula jerárquica de código abierto desarrollado por Google y lanzado al público en 2011. Puedes usar el sistema de cuadrícula de S2 para indexar y organizar los datos espaciales mediante la asignación de un número entero único de 64 bits a cada celda. Hay 31 niveles de resolución. Cada celda se representa como un cuadrado y está diseñada para operaciones en geometrías esféricas (a veces llamadas geografías). Cada cuadrado se subdivide en cuatro cuadrados más pequeños. El recorrido del vecino, que es la capacidad de identificar celdas S2 vecinas, no está bien definido porque los cuadrados pueden tener cuatro u ocho vecinos relevantes según el tipo de análisis. El siguiente es un ejemplo de celdas de cuadrícula de S2 con varias resolución:
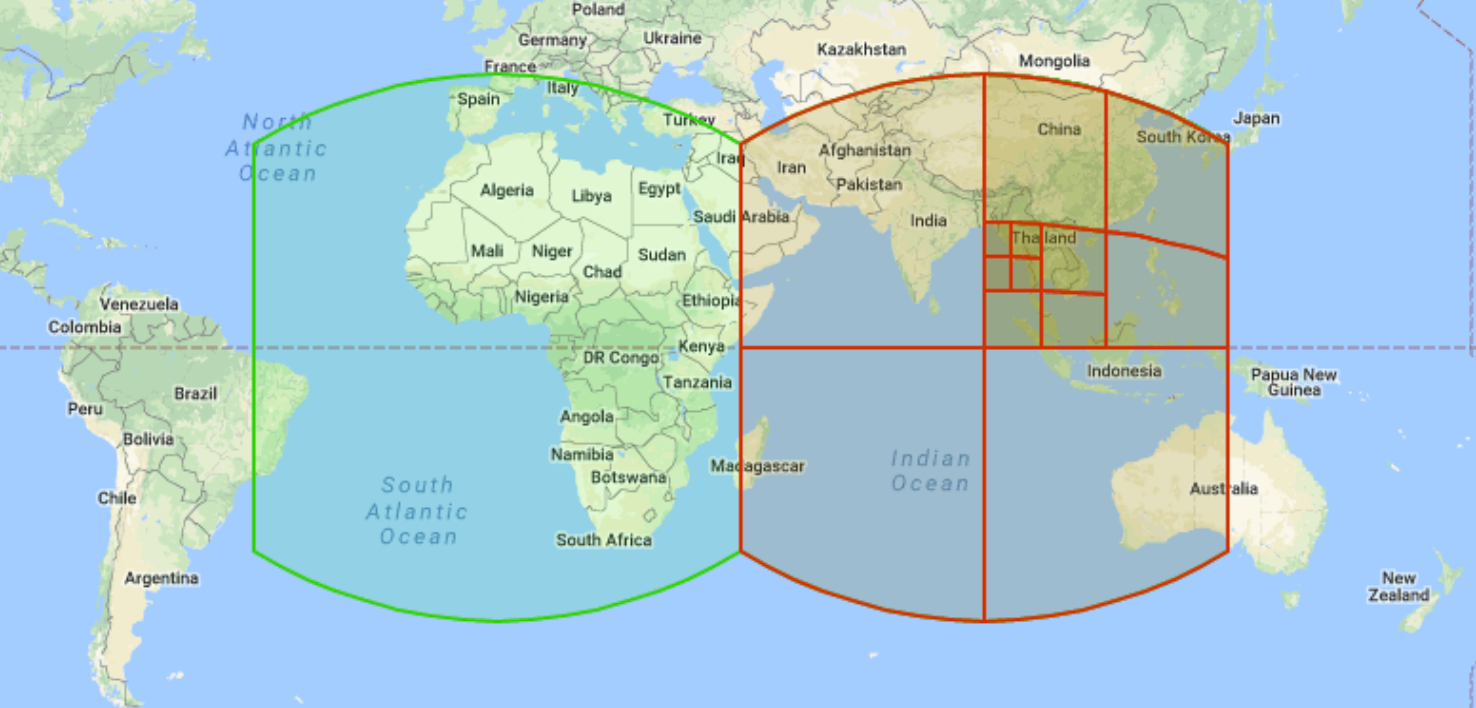
BigQuery usa celdas de S2 para indexar datos espaciales y expone varias funciones. Por ejemplo, S2_CELLIDFROMPOINT muestra el ID de celda de S2 que contiene un punto sobre la superficie de la Tierra en un nivel determinado.
H3
H3 es un sistema de red jerárquica de código abierto desarrollado por Uber y utilizado por Overture Maps. Hay 16 niveles de resolución. Cada celda se representa como un hexágono y, al igual que S2, a cada celda se le asigna un número entero único de 64 bits. En el ejemplo sobre la visualización de celdas H3 que cubren el Gulf de México, las celdas H3 más pequeñas no están perfectamente contenidas en las celdas más grandes.
Cada celda se subdivide en siete hexágonos más pequeños. La subdivisión no es exacta, pero es adecuada para muchos casos de uso. Cada celda comparte una arista con seis celdas vecinas, lo que simplifica el recorrido del vecino. Por ejemplo, en cada nivel, hay 12 pentagones, que comparten un borde con cinco vecinos en lugar de seis. Aunque H3 no es compatible con BigQuery, puedes agregar compatibilidad con H3 a BigQuery mediante la caja de herramientas de estadísticas de Carto para BigQuery.
Si bien las bibliotecas de S2 y H3 son de código abierto y están disponibles con la licencia de Apache 2, la biblioteca H3 tiene documentación más detallada.
HEALPix
Un esquema adicional para trazar la esfera, que se suele usar en el campo de astronomía, se conoce como Pixelación de isoLatitud de La Igualdad en el Área Jerárquica (HEALPix). HEALPix es independiente de la profundidad de píxeles jerárquico, pero el tiempo de procesamiento permanece constante.
HEALPix es un esquema jerárquico de píxelización de áreas iguales para la esfera. Se usa para representar y analizar datos en la esfera celestial (o de otra). Además del tiempo de procesamiento constante, la cuadrícula de HEALPix tiene las siguientes características:
- Las celdas de cuadrícula son jerárquicas, en las que se mantienen las relaciones entre tablas superiores y secundarias.
- En una jerarquía específica, las celdas son de áreas iguales.
- Las celdas siguen una distribución de iso-latitude, lo que permite un mayor rendimiento de los métodos espectrales.
BigQuery no es compatible con HEALPix, pero existen muchas implementaciones en una variedad de lenguajes, incluido JavaScript, por lo que es conveniente su uso en funciones definidas por el usuario (UDFs) de BigQuery.
Ejemplos de casos de uso para cada estrategia de indexación
En esta sección, se proporcionan algunos ejemplos que te ayudarán a evaluar cuál es el mejor sistema de cuadrícula para tu caso de uso.
Muchos casos de uso de informes y estadísticas incluyen la visualización, ya sea como parte del análisis en sí o para informar a las partes interesadas de la empresa. Estas visualizaciones suelen presentarse en Web Mercator, que es la proyección plana que usan Google Maps y muchas otras aplicaciones de mapeo web. En los casos en los que la visualización cumple un rol vital, las celdas H3 ofrecen una experiencia de visualización subjetivamente mejor. Las celdas de S2, en especial en latitudes más altas, tienden a parecer más distorsionadas que las de H3 y no se ven coherentes con las celdas de latitudes más bajas cuando se presentan en una proyección plana.
Las celdas H3 simplifican la implementación en la que la comparación de vecinos cumple un rol importante en el análisis. Por ejemplo, un análisis comparativo entre las secciones de una ciudad puede ayudar a decidir qué ubicación es adecuada para abrir una nueva tienda minorista o un centro de distribución. El análisis requiere cálculos estadísticos para los atributos de una celda determinada que se comparan con sus celdas vecinas.
Las celdas S2 pueden funcionar mejor en análisis que son globales por naturaleza, como los análisis que involucran medidas de distancias y ángulos. Pokémon GO de Niantic usa celdas de S2 para determinar dónde se colocan los elementos del juego y cómo se distribuyen. La propiedad de subdivisión exacta de las celdas de S2 garantiza que los elementos del juego se puedan distribuir de manera uniforme en todo el mundo.
¿Qué sigue?
- Para obtener prácticas recomendadas de agrupamiento en clústeres espaciales, consulta Agrupamiento en clústeres espaciales en BigQuery: Prácticas recomendadas.
- Aprende a crear una jerarquía espacial a partir de datos imperfectos.
- Obtén información sobre la geometría de S2 en GitHub.
- Obtén información sobre la geometría H3 en GitHub.
- Consulta ejemplos que usan H3, BigQuery y Earth Engine.