Grid-Systeme für räumliche Analysen
In diesem Dokument werden der Zweck und die Methoden der Verwendung von raumbezogenen Rastersystemen (wie S2 und H3) in BigQuery erläutert, um räumliche Daten in standardisierten geografischen Gebieten zu organisieren. Außerdem erfahren Sie, wie Sie das richtige Gitternetz für Ihre Anwendung auswählen. Dieses Dokument ist hilfreich für alle, die mit räumlichen Daten arbeiten und räumliche Analysen in BigQuery durchführen.
Überblick und Herausforderungen bei der Verwendung der räumlichen Analyse
Räumliche Analysen helfen dabei, die Beziehung zwischen Entitäten (Geschäften oder Häusern) und Veranstaltungen in einem physischen Bereich zu zeigen. Räumliche Analysen, die die Erdoberfläche als physischen Raum verwenden, werden als raumbezogene Analysen bezeichnet. BigQuery enthält raumbezogene Features und Funktionen, mit denen Sie raumbezogene Analysen in großem Maßstab ausführen können.
In vielen raumbezogenen Anwendungsfällen werden Daten innerhalb lokalisierter Gebiete aggregiert und statistische Aggregationen dieser Bereiche miteinander verglichen. Diese lokalisierten Bereiche werden als Polygone in einer räumlichen Datenbanktabelle dargestellt. Manchmal wird diese Methode als statistische Geografie bezeichnet. Die Methode zur Bestimmung des Umfangs der geografischen Gebiete muss standardisiert werden, um bessere Berichte, Analysen und räumliche Indexierungen zu ermöglichen. So kann ein Einzelhändler beispielsweise die Veränderungen der demografischen Merkmale im Laufe der Zeit in Bereichen analysieren, in denen sich seine Geschäfte befinden oder in denen er darüber nachdenken will, ein neues Geschäft zu bauen. Oder ein Versicherungsunternehmen möchte das Verständnis von Immobilienrisiken besser verstehen, indem es die vorherrschenden Naturrisikorisiken in einem bestimmten Bereich analysiert.
Aufgrund strenger Datenschutzbestimmungen in vielen Bereichen müssen Datasets, die Standortinformationen enthalten, de-identifiziert oder teilweise anonymisiert werden, um die Privatsphäre der in den Daten dargestellten Personen zu schützen. Beispielsweise kann es sein, dass Sie eine geografische Kreditkonzentrationsrisikoanalyse für ein Dataset durchführen müssen, das Daten zu ausstehenden Hypothekenkrediten enthält. Wenn Sie das Dataset de-identifizieren möchten, damit es für konforme Analysen geeignet ist, müssen Sie relevante Informationen zum Standort der Attribute beibehalten, aber keine bestimmte Adresse oder Längen- und Breitengrade verwenden.
In den vorangegangenen Beispielen stehen die Designer dieser Analysen vor folgenden Herausforderungen:
- Wie werden die Flächengrenzen gezeichnet, innerhalb derer Änderungen im Zeitverlauf analysiert werden?
- Wie werden die vorhandenen administrativen Grenzen wie Volkszählungen oder ein Rastersystem mit mehreren Auflösungen genutzt?
In diesem Dokument werden diese Fragen beantwortet, indem jede Option erläutert, Best Practices beschrieben und wie Sie häufige Probleme vermeiden können.
Häufige Schwierigkeiten bei der Auswahl statistischer Bereiche
Geschäfts-Datasets wie Immobilienverkauf, Marketingkampagnen, E-Commerce-Versand und Versicherungen eignen sich für räumliche Analysen. Häufig enthalten diese Datasets einen scheinbar bequemen räumlichen Join-Schlüssel, z. B. ein Volkszählungsprotokoll, eine Postleitzahl oder den Namen einer Stadt. Da öffentliche Datasets, die Darstellungen von Volkszählungen, Postleitzahlen und Städten enthalten, sind es verlockend, als administrative Grenzen für die statistische Aggregation zu verwenden.
Diese und andere administrative Grenzen haben zwar einen Schwierigkeitsgrad, aber sie haben Nachteile. Darüber hinaus funktionieren diese Grenzen in den frühen Phasen eines Analyseprojekts möglicherweise gut, die Nachteile werden jedoch in den späteren Phasen erkannt.
Postleitzahlen
Postleitzahlen werden für die Weiterleitung von Post in verschiedenen Ländern auf der ganzen Welt verwendet. Aufgrund dieser Alleinstellungsmerkmale werden sie häufig verwendet, um in räumlichen und nicht räumlichen Datasets auf Orte und Gebiete zu verweisen. Im vorherigen Beispiel zu dem Hypothekenkredit muss ein Dataset häufig de-identifiziert werden, bevor eine nachgelagerte Analyse durchgeführt werden kann. Da jede Attributadresse eine Postleitzahl enthält, sind auch Referenztabellen für Postleitzahlen zugänglich. Dies ist eine bequeme Option für einen Join-Schlüssel für räumliche Analysen.
Ein Problem bei der Verwendung von Postleitzahlen besteht darin, dass sie nicht als Polygone dargestellt werden und es keine einzige korrekte "Source of Truth" für Postleitzahlen gibt. Außerdem sind Postleitzahlen keine gute Darstellung des realen menschlichen Verhaltens. Die am häufigsten verwendeten Postleitzahlendaten in den USA stammen von den US Census Bureau TIGER/Line Shapefiles, das ein Dataset mit dem Namen ZCTA5 (Zip Code Tabulation Area) enthält. Dieses Dataset stellt eine Näherung der Grenzen von Postleitzahlen dar, die von Postzustellrouten abgeleitet werden. Einige Postleitzahlen, die einzelne Gebäude darstellen, haben jedoch keine Grenze. Dieses Problem tritt auch in anderen Ländern auf, was die Erstellung einer einzigen globalen Faktentabelle mit einem autoritativen Satz von Postleitzahlengrenzen erschwert, die system- und Dataset-übergreifend verwendet werden können.
Außerdem gibt es auf der ganzen Welt kein standardisiertes Postleitzahlenformat. Einige sind numerisch und reichen von drei bis zehn Ziffern, während andere alphanumerisch sind. Es gibt auch eine Überschneidung zwischen Ländern. Deshalb muss das Herkunftsland zusammen mit der Postleitzahl in einer separaten Spalte gespeichert werden. In einigen Ländern werden keine Postleitzahlen verwendet, was die Analyse weiter erschwert.
Volkszählungen, Städte und Countys
Es gibt einige Verwaltungseinheiten, wie z. B. Erhebungsgebiete, Städte und Bezirke, die nicht unter dem Fehlen einer verbindlichen Grenze leiden. Die Grenzen von Städte werden beispielsweise in den meisten Fällen von den Behörden gut festgelegt. Erhebungsgebiete werden vom US Census Bureau und den entsprechenden Einrichtungen in den meisten anderen Ländern klar definiert.
Ein Nachteil der Verwendung dieser und anderer administrativer Grenzen besteht darin, dass sie sich im Laufe der Zeit ändern und geografisch nicht miteinander konsistent sind. Bezirke und Städte werden zusammengeführt oder voneinander getrennt und gelegentlich werden umbenannt. Volkszählungen werden in den USA einmal pro Jahrzehnt und in anderen Ländern zu unterschiedlichen Zeiten aktualisiert. Verwirrend ist, dass sich in einigen Fällen die geografische Grenze ändern kann, ihre eindeutige Kennzeichnung aber gleich bleibt, was die Analyse und das Verständnis von Änderungen im Laufe der Zeit erschwert.
Ein weiterer Nachteil, der einigen administrativen Grenzen gemeinsam ist, besteht darin, dass sie diskrete Bereiche ohne geografische Hierarchie sind. Neben dem Vergleich einzelner Bereiche besteht eine gängige Anforderung darin, Aggregationen der Bereiche selbst mit anderen Aggregationen zu vergleichen. Beispielsweise könnte ein Einzelhändler, der das Huff-Modell implementiert hat, diese Analyse mit mehreren Entfernungen ausführen, die möglicherweise nicht mit den Verwaltungsgebieten übereinstimmen, die an anderer Stelle im Unternehmen verwendet werden.
Raster mit einer oder mehreren Auflösungen
Raster mit einfacher Auflösung bestehen aus einzelnen Einheiten, die keine geografische Beziehung zu größeren Bereichen haben, die diese Einheiten enthalten. So haben beispielsweise Postleitzahlen eine inkonsistente geografische Beziehung zu den Grenzen größerer Verwaltungseinheiten, z. B. Städte oder Bezirke, die Postleitzahlen enthalten können. Für die räumliche Analyse ist es wichtig zu verstehen, wie verschiedene Gebiete miteinander zusammenhängen, ohne umfassende Kenntnisse der Geschichte und Gesetzgebung zu haben, mit der das Flächenpolygon definiert wird.
Raster mit mehreren Auflösungen werden manchmal als hierarchische Raster bezeichnet, da die Zellen bei jeder Zoomstufe in kleinere Zellen bei höheren Zoomstufen unterteilt werden. Raster mit mehreren Auflösungen bestehen aus einer klar definierten Hierarchie von Einheiten, die in größeren Einheiten enthalten sind. Erhebungsgebiete enthalten beispielsweise Blockgruppen, die wiederum Blöcke enthalten. Diese konsistente hierarchische Beziehung kann für die statistische Aggregation nützlich sein. Wenn Sie beispielsweise den Durchschnitt der Einkommen aller Blockgruppen eines Diagramms ermitteln, können Sie das Durchschnittseinkommen für das Erhebungsgebiet der Blockgruppen anzeigen. Dies wäre mit Postleitzahlen nicht möglich, da sich alle Postleitzahlen in einer einzigen Auflösung befinden. Es wäre schwierig, das Einkommen eines Gebiets mit den zugehörigen Bereichen zu vergleichen, da es keine standardisierte Möglichkeit gibt, um die Adjazenz zu definieren oder das Einkommen in verschiedenen Ländern zu vergleichen.
S2- und H3-Gittersysteme
Dieser Abschnitt bietet eine Übersicht über S2- und H3-Grid-Systeme.
S2
S2-Geometrie ist ein hierarchisches Open-Source-Netzwerksystem, das von Google entwickelt und 2011 für die Öffentlichkeit freigegeben wurde. Sie können das S2-Grid-System verwenden, um räumliche Daten zu organisieren und zu indexieren, indem Sie jeder Zelle eine eindeutige 64-Bit-Ganzzahl zuweisen. Es gibt 31 Auflösungsstufen. Jede Zelle wird als Quadrat dargestellt und für Vorgänge mit sphärischen Geometrien (manchmal auch als Geografien bezeichnet) entwickelt. Jedes Quadrat ist in vier kleinere Quadrate unterteilt. Der Nachbardurchlauf, bei dem benachbarte S2-Zellen identifiziert werden können, ist weniger gut definiert, da Quadrate je nach Analysetyp entweder vier oder acht relevante Nachbarn haben können. Das folgende Beispiel zeigt S2-Rasterzellen mit mehreren Auflösungen:
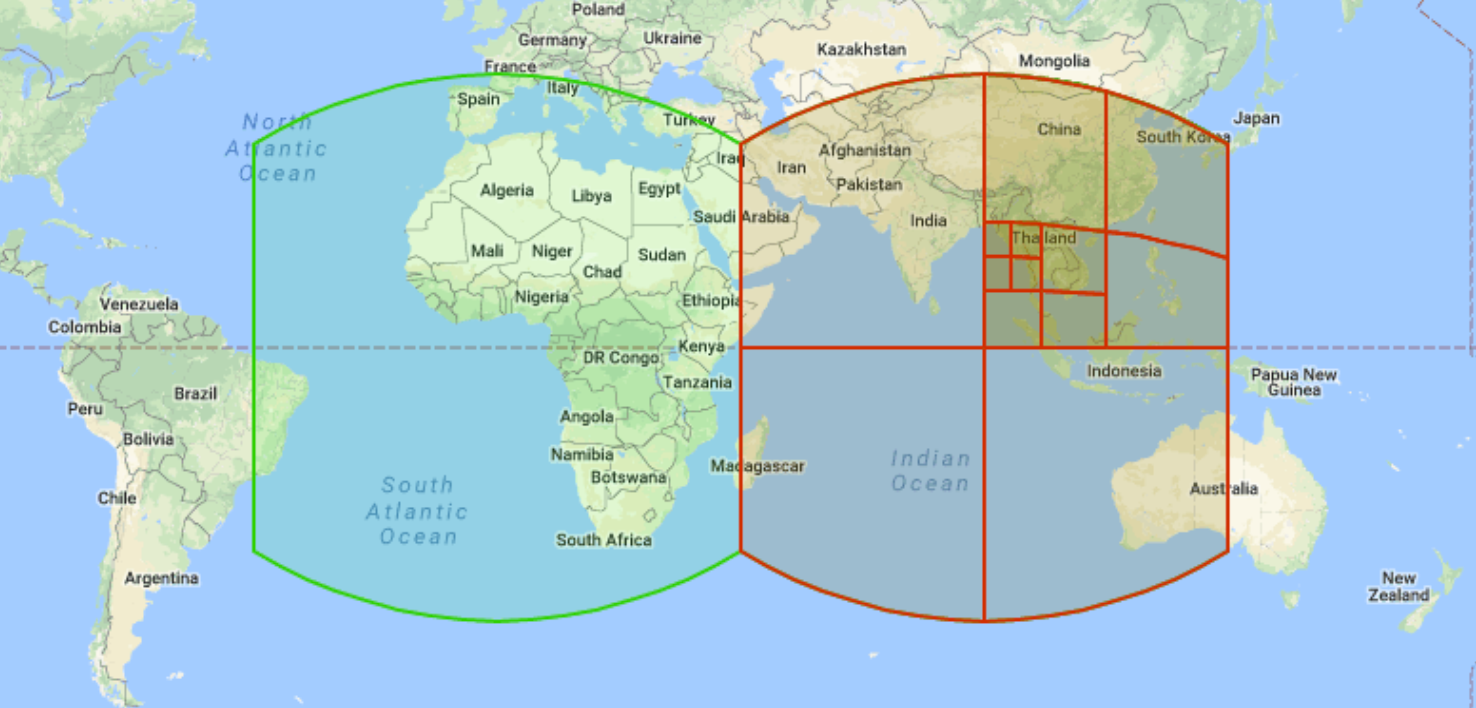
BigQuery verwendet S2-Zellen, um räumliche Daten zu indexieren, und stellt mehrere Funktionen bereit. Zum Beispiel gibt S2_CELLIDFROMPOINT die S2-Zellen-ID zurück, die einen Punkt auf der Erdoberfläche auf einer bestimmten Ebene enthält.
H3
H3 ist ein hierarchisches Open-Source-Gittersystem, das von Uber entwickelt und von Overture Maps verwendet wird. Es gibt 16 Auflösungsstufen. Jede Zelle wird als Sechseck dargestellt und wie bei S2 wird jeder Zelle eine eindeutige 64-Bit-Ganzzahl zugewiesen. In dem Beispiel zur Visualisierung von H3-Zellen, die den Golf von Mexiko abdecken, sind die kleineren H3-Zellen in den größeren Zellen nicht perfekt enthalten.
Jede Zelle ist in sieben kleinere Sechsecke unterteilt. Die Unterteilung ist nicht genau, eignet sich jedoch für viele Anwendungsfälle. Jede Zelle hat eine Kante mit sechs benachbarten Zellen, was den Durchlauf des Nachbarn vereinfacht. Beispielsweise gibt es auf jeder Ebene 12 Fünfecke, die sich stattdessen ein Edge mit fünf Nachbarn statt mit sechs teilen. Obwohl H3 in BigQuery nicht unterstützt wird, können Sie BigQuery mithilfe der Carto Analytics Toolbox für BigQuery H3-Unterstützung hinzufügen.
Sowohl die S2- als auch die H3-Bibliotheken sind Open Source und unter der Apache 2-Lizenz verfügbar. Die H3-Bibliothek enthält jedoch eine ausführlichere Dokumentation.
HEALPix
Ein zusätzliches Schema zur Raster der Kugel, das häufig im Astronomiefeld verwendet wird, ist als Hierarchical Equal Area isoLatitude Pixelation (HEALPix) bekannt. HEALPix ist unabhängig von der hierarchischen Pixeltiefe, die Rechenzeit bleibt jedoch konstant.
HEALPix ist ein hierarchisches Schema zur Verpixelung der Kugel. Sie wird verwendet, um Daten auf der Himmelssphäre (oder einer anderen Kugel) darzustellen und zu analysieren. Neben der konstanten Rechenzeit weist das HEALPix-Raster folgende Eigenschaften auf:
- Die Rasterzellen sind hierarchisch, wobei Beziehungen zwischen übergeordneten und untergeordneten Elementen beibehalten werden.
- In einer bestimmten Hierarchie haben Zellen dieselben Flächen.
- Die Zellen folgen einer iso-latitude-Verteilung, was eine höhere Leistung für Spektralmethoden ermöglicht.
BigQuery unterstützt HEALPix nicht. Es gibt jedoch mehrere Implementierungen in einer Vielzahl von Sprachen, einschließlich JavaScript, was die Verwendung in benutzerdefinierten Funktionen (UDFs) von BigQuery erleichtert.
Anwendungsfälle für jede Indexierungsstrategie
Dieser Abschnitt enthält einige Beispiele, mit denen Sie beurteilen können, welches Grid-System für Ihren Anwendungsfall am besten geeignet ist.
Viele Analyse- und Berichterstellungsanwendungsfälle beinhalten Visualisierungen, entweder als Teil der Analyse selbst oder zur Berichterstellung an die Stakeholder des Unternehmens. Diese Visualisierungen werden häufig in Web Mercator dargestellt. Dies ist die planare Projektion, die von Google Maps und vielen anderen Webkartenanwendungen verwendet wird. In Fällen, in denen die Visualisierung eine wichtige Rolle spielt, bieten H3-Zellen eine subjektiv bessere Visualisierung. S2-Zellen erscheinen, insbesondere in höheren Breitengraden, in der Regel stärker verzerrt als H3-Zellen und stimmen in einer ebenen Projektion nicht mit Zellen in niedrigeren Breitengraden überein.
H3-Zellen vereinfachen die Implementierung, wenn der Vergleich mit benachbarten Zellen bei der Analyse eine wichtige Rolle spielt. So könnte zum Beispiel eine Vergleichsanalyse zwischen Abschnitten einer Stadt helfen zu entscheiden, welcher Standort für die Eröffnung eines neuen Einzelhandelsgeschäfts oder Vertriebszentrums geeignet ist. Die Analyse erfordert statistische Berechnungen für Attribute einer bestimmten Zelle, die mit ihren benachbarten Zellen verglichen wird.
S2-Zellen funktionieren besser bei Analysen, die global sind, z. B. bei Analysen von Entfernungen und Winkeln. Pokemon Go von Niantic nutzt S2-Zellen, um zu bestimmen, wo Spiel-Assets platziert und wie sie verteilt werden. Die genaue Unterteilungseigenschaft von S2-Zellen sorgt dafür, dass Spiel-Assets gleichmäßig über die ganze Welt verteilt sind.
Nächste Schritte
- Best Practices für das räumliche Clustering finden Sie unter Räumliche Clustering-Funktion in BigQuery – Best Practices.
- Weitere Informationen zur Erstellung einer räumlichen Hierarchie aus nicht perfekten Daten
- Mehr über S2-Geometrie auf GitHub erfahren
- Weitere Informationen zur H3-Geometrie auf GitHub
- Beispiele für die Verwendung von H3, BigQuery und Earth Engine