Sistemi di griglia per l'analisi spaziale
Questo documento spiega lo scopo e i metodi di utilizzo dei sistemi di griglia geospaziali (come S2 e H3) in BigQuery per organizzare i dati spaziali in aree geografiche standardizzate. Inoltre, spiega come scegliere il sistema di griglia giusto per la tua applicazione. Questo documento è utile per chiunque lavori con dati spaziali ed esegua analisi spaziali in BigQuery.
Panoramica e sfide dell'utilizzo dell'analisi spaziale
L'analisi spaziale consente di mostrare la relazione tra entità (negozi o case) ed eventi in uno spazio fisico. L'analisi spaziale che utilizza la superficie terrestre come spazio fisico è chiamata analisi geospaziale. BigQuery include funzionalità e funzioni geospaziali che ti consentono di eseguire analisi geospaziali su larga scala.
Molti casi d'uso geospaziali prevedono l'aggregazione dei dati all'interno di aree localizzate e il confronto delle aggregazioni statistiche di queste aree tra loro. Queste area geografiche sono rappresentate come poligoni in una tabella di database spaziale. In alcuni contesti, questo metodo è chiamato geografia statistica. Il metodo di determinazione dell'estensione delle aree geografiche deve essere standardizzato per migliorare la generazione di report, l'analisi e l'indicizzazione spaziale. Ad esempio, un rivenditore potrebbe voler analizzare le variazioni demografiche nel tempo nelle aree in cui si trovano i suoi negozi o in quelle in cui sta valutando la possibilità di aprire un nuovo negozio. In alternativa, un'assicurazione potrebbe voler migliorare la propria comprensione dei rischi per le proprietà analizzando i rischi di calamità naturali prevalenti in una determinata area.
A causa di normative sulla privacy dei dati molto rigide in molte aree, i set di dati che contengono informazioni sulla posizione devono essere anonimizzati o parzialmente anonimizzati per contribuire a proteggere la privacy delle persone rappresentate nei dati. Ad esempio, potresti dover eseguire un'analisi del rischio di concentrazione geografica del credito su un set di dati contenente dati su mutui insoluti. Per anonimizzare il set di dati in modo da renderlo adatto per l'analisi conforme, devi conservare le informazioni pertinenti sulla posizione delle proprietà, ma evitare di utilizzare un indirizzo specifico o le coordinate di longitudine e latitudine.
Negli esempi precedenti, i progettisti di queste analisi si trovano di fronte alle seguenti sfide:
- Come tracciare i confini dell'area all'interno della quale analizzi le variazioni nel tempo?
- Come utilizzare i confini amministrativi esistenti, come i lotti del censimento o un sistema di griglie a più risoluzioni?
Lo scopo di questo documento è rispondere a queste domande spiegando ogni opzione, descrivendo le best practice e aiutandoti a evitare errori comuni.
Errori comuni durante la scelta delle aree statistiche
I set di dati aziendali, come vendite immobiliari, campagne di marketing, spedizioni di e-commerce e polizze assicurative, sono adatti all'analisi spaziale. Spesso questi dataset contengono quella che sembra essere una comoda chiave di join spaziale, ad esempio un trattino del censimento, un codice postale o il nome di una città. I set di dati pubblici che contengono rappresentazioni di lotti del censimento, codici postali e città sono facilmente disponibili, quindi è allettante utilizzarli come confini amministrativi per l'aggregazione statistica.
Sebbene apparentemente pratici, questi e altri confini amministrativi presentano degli svantaggi. Inoltre, questi limiti potrebbero funzionare bene nelle fasi iniziali di un progetto di analisi, ma gli svantaggi possono essere notati nelle fasi successive.
Codici postali
I codici postali vengono utilizzati per indirizzare la posta in vari paesi in tutto il mondo e, grazie a questa ubiquità, vengono spesso utilizzati per fare riferimento a località e aree in set di dati sia spaziali che non spaziali. Facendo riferimento all'esempio precedente sul prestiti ipotecari, spesso è necessario anonimizzare un set di dati prima di poter eseguire un'analisi downstream. Poiché ogni indirizzo della struttura contiene un codice postale, le tabelle di riferimento dei codici postali sono accessibili, il che rappresenta un'opzione pratica per una chiave di join per l'analisi spaziale.
Un problema dell'utilizzo dei codici postali è che non sono rappresentati come poligoni e non esiste un'unica fonte attendibile per le aree dei codici postali. Inoltre, i codici postali non sono una buona rappresentazione del comportamento umano reale. I dati sui codici postali più comunemente utilizzati negli Stati Uniti provengono dagli shapefile TIGER/Line del Census Bureau degli Stati Uniti, che contengono un set di dati chiamato ZCTA5 (Zip Code Tabulation Area). Questo set di dati rappresenta un'approssimazione dei confini dei codici postali ricavati dai percorsi di consegna della posta. Tuttavia, alcuni codici postali che rappresentano singoli edifici non hanno confini. Questo problema è presente anche in altri paesi, il che rende difficile formare una singola tabella di fatti globale contenente un insieme autorevole di confini dei codici postali che può essere utilizzato in più sistemi e set di dati.
Inoltre, non esiste un formato standardizzato dei codici postali utilizzato in tutto il mondo. Alcuni sono numerici, con un numero di cifre compreso tra tre e dieci, mentre altri sono alfanumerici. Inoltre, esiste una sovrapposizione tra i paesi, il che rende necessario memorizzare il paese di origine in una colonna separata insieme al codice postale. Alcuni paesi non utilizzano i codici postali, complicando ulteriormente l'analisi.
Sezioni censuarie, città e contee
Esistono alcune unità amministrative, come sezioni censuarie, città e contee, che non soffrono della mancanza di un confine autorevole. I confini delle città, ad esempio, nella maggior parte dei casi sono ben definiti dalle autorità governative. I lotti censuari sono ben definiti dal Census Bureau degli Stati Uniti e dalle sue istituzioni analoghe nella maggior parte degli altri paesi.
Uno svantaggio dell'utilizzo di questi e altri confini amministrativi è che cambiano nel tempo e non sono geograficamente coerenti tra loro. I contee e le città si fondono o si separano e a volte vengono rinominati. I lotti censuari vengono aggiornati una volta ogni dieci anni negli Stati Uniti e in momenti diversi in altri paesi. In alcuni casi, il confine geografico può cambiare, ma il relativo identificatore univoco rimane invariato, il che rende difficile analizzare e comprendere le variazioni nel tempo.
Un altro svantaggio comune ad alcuni confini amministrativi è che si tratta di aree distinte senza gerarchia geografica. Oltre a confrontare le singole aree tra loro, un requisito comune è confrontare le aggregazioni delle aree stesse con altre aggregazioni. Ad esempio, un rivenditore che implementa il modello di Huff potrebbe voler eseguire questa analisi utilizzando più distanze, che potrebbero non corrispondere alle aree amministrative utilizzate altrove nell'attività.
Griglie a risoluzione singola e multipla
Le griglie a singola risoluzione sono costituite da unità distinte che non hanno alcuna relazione geografica con le aree più grandi che le contengono. Ad esempio, i codici postali hanno un rapporto geografico incoerente con i confini di unità amministrative più grandi, come città o contee che potrebbero contenere codici postali. Per l'analisi spaziale, è importante capire in che modo le diverse aree sono correlate tra loro senza una conoscenza approfondita della storia e della legislazione che definisce il poligono dell'area.
Le griglie multirisoluzione sono a volte chiamate griglie gerarchiche perché le celle a ogni livello di zoom sono suddivise in celle più piccole a livelli di zoom superiori. Le griglie multirisoluzione sono costituite da una gerarchia ben definita di unità contenute in unità più grandi. I lotti censuari, ad esempio, contengono gruppi di isolati, che a loro volta contengono isolati. Questa relazione gerarchica coerente può essere utile per l'aggregazione statistica. Ad esempio, calcolando la media degli utili di tutti i gruppi di lotti contenuti in un trecentro, puoi mostrare l'utile medio per quel trecentro contenente i gruppi di lotti. Ciò non sarebbe possibile con i codici postali perché tutte le aree postali si trovano a una singola risoluzione. Sarebbe difficile confrontare il reddito di un appezzamento con quelli degli appezzamenti circostanti, in quanto non esiste un modo standardizzato per definire l'adiacenza o confrontare i redditi in paesi diversi.
Sistemi di griglia S2 e H3
Questa sezione fornisce una panoramica dei sistemi di griglia S2 e H3.
S2
La geometria S2 è un sistema di griglia gerarchica open source sviluppato da Google e reso disponibile al pubblico nel 2011. Puoi utilizzare il sistema di griglia S2 per organizzare e indicizzare i dati spaziali assegnando un numero intero a 64 bit univoco a ogni cella. Esistono 31 livelli di risoluzione. Ogni cella è rappresentata come un quadrato ed è progettata per operazioni su geometrie sferiche (a volte chiamate geografie). Ogni quadrato è suddiviso in quattro quadrati più piccoli. L'esplorazione dei vicini, ovvero la capacità di identificare le celle S2 vicine, è meno ben definita perché i quadrati possono avere quattro o otto vicini pertinenti a seconda del tipo di analisi. Di seguito è riportato un esempio di celle della griglia S2 multirisoluzione:
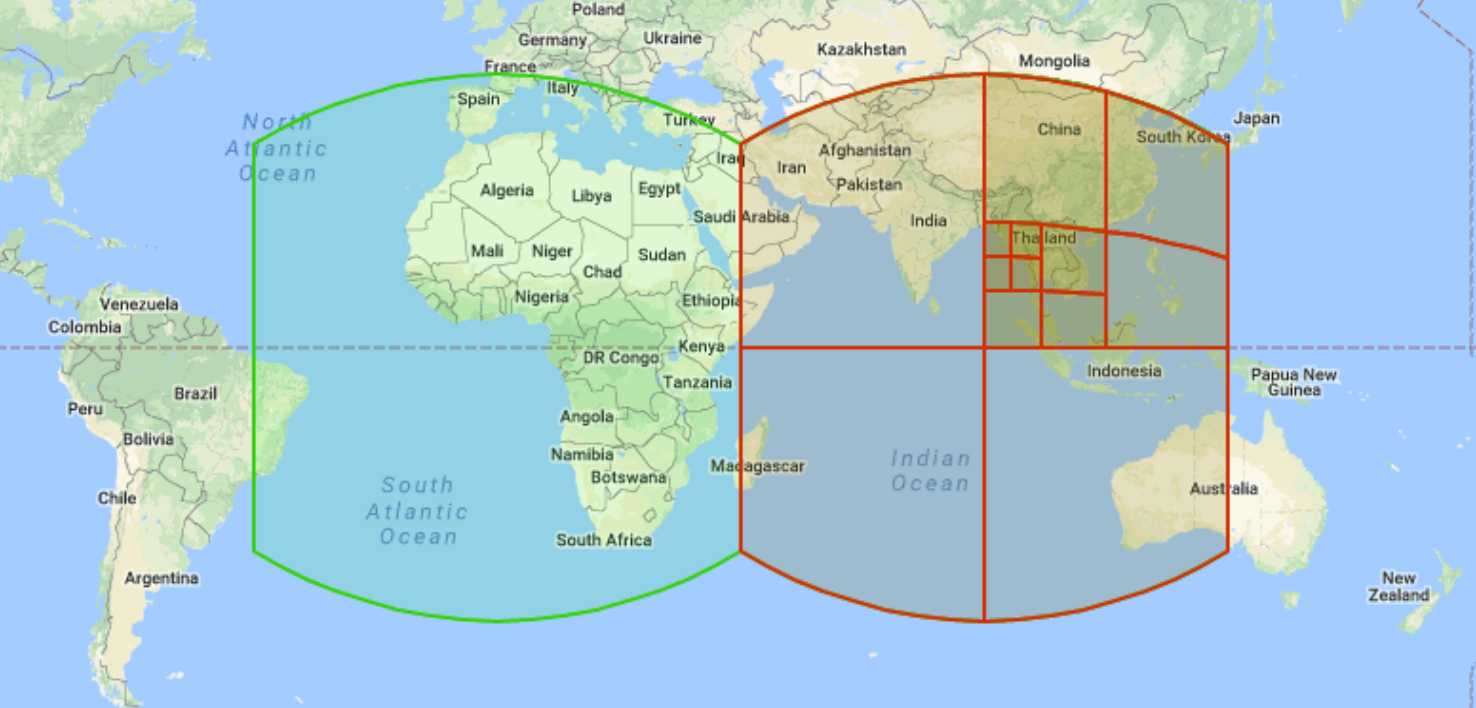
BigQuery utilizza le celle S2 per indicizzare i dati spaziali ed espone più funzioni. Ad esempio, S2_CELLIDFROMPOINT
restituisce l'ID cella S2 contenente un punto sulla superficie terrestre a un determinato livello.
H3
H3 è un sistema di griglie gerarchiche open source sviluppato da Uber e utilizzato da Overture Maps. Esistono 16 livelli di risoluzione. Ogni cella è rappresentata da un esagono e, come in S2, a ogni cella viene assegnato un numero intero a 64 bit univoco. Nell'esempio sulla visualizzazione delle celle H3 che coprono il Golfo del Messico, le celle H3 più piccole non sono perfettamente contenute dalle celle più grandi.
Ogni cella si suddivide in sette esagoni più piccoli. La suddivisione non è esatta, ma è adeguata per molti casi d'uso. Ogni cella condivide un bordo con sei celle adiacenti, semplificando il traversale dei vicini. Ad esempio, a ogni livello, sono presenti 12 pentagoni, che invece condividono un lato con cinque vicini anziché con sei. Anche se H3 non è supportato in BigQuery, puoi aggiungere il supporto di H3 a BigQuery utilizzando la Carto Analytics Toolbox per BigQuery.
Sebbene entrambe le librerie S2 e H3 siano open source e disponibili ai sensi della licenza Apache 2, la libreria H3 ha una documentazione più dettagliata.
HEALPix
Uno schema aggiuntivo per creare una griglia sulla sfera, comunemente utilizzato nel campo dell'astronomia, è noto come HEALPix (Hierarchical Equal Area isoLatitude Pixelation). HEALPix è indipendente dalla profondità gerarchica dei pixel, ma il tempo di calcolo rimane costante.
HEALPix è uno schema di pixelizzazione gerarchico con aree uguali per la sfera. Viene utilizzato per rappresentare e analizzare i dati sulla sfera celeste (o di altro tipo). Oltre a un tempo di calcolo costante, la griglia HEALPix presenta le seguenti caratteristiche:
- Le celle della griglia sono gerarchiche e le relazioni padre-figlio vengono mantenute.
- In una gerarchia specifica, le celle hanno aree uguali.
- Le celle seguono una distribuzione iso-latitudine, consentendo prestazioni più elevate per i metodi spettrali.
BigQuery non supporta HEALPix, ma esistono numerose implementazioni in vari linguaggi, tra cui JavaScript, che lo rendono pratico da utilizzare nelle funzioni definite dall'utente (UDF) di BigQuery.
Esempi di casi d'uso per ogni strategia di indicizzazione
Questa sezione fornisce alcuni esempi che ti aiutano a valutare quale sia il sistema di griglie migliore per il tuo caso d'uso.
Molti casi d'uso di analisi e generazione di report prevedono la visualizzazione, nell'ambito dell'analisi stessa o per la generazione di report per gli stakeholder aziendali. Queste visualizzazioni vengono comunemente presentate in Web Mercatore, che è la proiezione piana utilizzata da Google Maps e da molte altre applicazioni di mappatura web. Nei casi in cui la visualizzazione svolga un ruolo fondamentale, le celle H3 offrono un'esperienza di visualizzazione soggettivamente migliore. Le celle S2, soprattutto alle latitudini più elevate, tendono a sembrare più distorte rispetto a quelle H3 e non sono coerenti con le celle di latitudini più basse quando vengono presentate in una proiezione piana.
Le celle H3 semplificano l'implementazione quando il confronto con i vicini svolge un ruolo importante nell'analisi. Ad esempio, un'analisi comparativa tra le sezioni di una città potrebbe essere utile per decidere quale località è adatta per l'apertura di un nuovo negozio di vendita al dettaglio o di un centro di distribuzione. L'analisi richiede calcoli statistici per gli attributi di una determinata cella rispetto alle celle adiacenti.
Le celle S2 possono funzionare meglio in analisi di natura globale, come quelle che richiedono misurazioni di distanze e angoli. Pokemon Go di Niantic utilizza le celle S2 per determinare dove sono posizionati gli asset di gioco e come vengono distribuiti. La proprietà di suddivisione esatta delle celle S2 garantisce che gli asset di gioco possano essere distribuiti in modo uniforme in tutto il mondo.
Passaggi successivi
- Per le best practice sul clustering spaziale, consulta Clustering spaziale su BigQuery - Best practice.
- Scopri come creare una gerarchia spaziale da dati imperfetti.
- Scopri di più sulla geometria S2 su GitHub.
- Scopri di più sulla geometria H3 su GitHub.
- Consulta gli esempi che utilizzano H3, BigQuery ed Earth Engine.