Gerar texto usando um modelo text-bison e a função ML.GENERATE_TEXT
Neste tutorial, mostramos como criar um modelo remoto baseado no modelo de linguagem grande text-bison@002 e depois usar esse modelo com a função ML.GENERATE_TEXT para executar várias tarefas de geração de texto. Este tutorial usa a tabela pública bigquery-public-data.imdb.reviews.
Permissões necessárias
- Para criar o conjunto de dados, você precisa da permissão
bigquery.datasets.createdo Identity and Access Management (IAM). Para criar o recurso de conexão, você precisa das seguintes permissões do IAM:
bigquery.connections.createbigquery.connections.get
Para conceder permissões à conta de serviço da conexão, você precisa da seguinte permissão:
resourcemanager.projects.setIamPolicy
Para criar o modelo, você precisa das seguintes permissões:
bigquery.jobs.createbigquery.models.createbigquery.models.getDatabigquery.models.updateDatabigquery.connections.delegate
Para executar a inferência, você precisa das seguintes permissões:
bigquery.models.getDatabigquery.jobs.create
Custos
Neste documento, você usará os seguintes componentes faturáveis do Google Cloud:
- BigQuery ML: You incur costs for the data that you process in BigQuery.
- Vertex AI: You incur costs for calls to the Vertex AI service that's represented by the remote model.
Para gerar uma estimativa de custo baseada na projeção de uso deste tutorial, use a calculadora de preços.
Para mais informações, consulte Preços do BigQuery na documentação do BigQuery.
Para mais informações sobre preços da Vertex AI, consulte esta página.
Antes de começar
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
Enable the BigQuery, BigQuery Connection, and Vertex AI APIs.
Criar um conjunto de dados
Crie um conjunto de dados do BigQuery para armazenar seu modelo de ML.
Console
No Console do Google Cloud, acesse a página BigQuery.
No painel Explorer, clique no nome do seu projeto.
Clique em Conferir ações > Criar conjunto de dados.
Na página Criar conjunto de dados, faça o seguinte:
Para o código do conjunto de dados, insira
bqml_tutorial.Em Tipo de local, selecione Multirregião e EUA (várias regiões nos Estados Unidos).
Mantenha as configurações padrão restantes e clique em Criar conjunto de dados.
bq
Para criar um novo conjunto de dados, utilize o
comando bq mk
com a sinalização --location. Para obter uma lista completa de parâmetros, consulte a
referência
comando bq mk --dataset.
Crie um conjunto de dados chamado
bqml_tutorialcom o local de dados definido comoUSe uma descrição deBigQuery ML tutorial dataset:bq --location=US mk -d \ --description "BigQuery ML tutorial dataset." \ bqml_tutorial
Em vez de usar a flag
--dataset, o comando usa o atalho-d. Se você omitir-de--dataset, o comando vai criar um conjunto de dados por padrão.Confirme se o conjunto de dados foi criado:
bq ls
API
Chame o método datasets.insert com um recurso de conjunto de dados definido.
{ "datasetReference": { "datasetId": "bqml_tutorial" } }
Crie uma conexão
Crie uma Conexão de recursos do Cloud e tenha acesso à conta de serviço da conexão. Crie a conexão no mesmo local do conjunto de dados criado na etapa anterior.
Selecione uma das seguintes opções:
Console
Acessar a página do BigQuery.
No painel Explorer, clique em Adicionar dados.
A caixa de diálogo Adicionar dados é aberta.
No painel Filtrar por, na seção Tipo de fonte de dados, selecione Bancos de dados.
Como alternativa, no campo Pesquisar fontes de dados, insira
Vertex AI.Na seção Fontes de dados em destaque, clique em Vertex AI.
Clique no card da solução Vertex AI Models: BigQuery Federation.
Na lista Tipo de conexão, selecione Modelos remotos da Vertex AI, funções remotas e BigLake (recurso do Cloud).
No campo ID da conexão, insira um nome para a conexão.
Clique em Criar conexão.
Clique em Ir para conexão.
No painel Informações da conexão, copie o ID da conta de serviço para uso em uma etapa posterior.
bq
Em um ambiente de linha de comando, crie uma conexão:
bq mk --connection --location=REGION --project_id=PROJECT_ID \ --connection_type=CLOUD_RESOURCE CONNECTION_ID
O parâmetro
--project_idsubstitui o projeto padrão.Substitua:
REGION: sua região de conexãoPROJECT_ID: o ID do projeto do Google CloudCONNECTION_ID: um ID para sua conexão
Quando você cria um recurso de conexão, o BigQuery cria uma conta de serviço do sistema exclusiva e a associa à conexão.
Solução de problemas: se você receber o seguinte erro de conexão, atualize o SDK Google Cloud:
Flags parsing error: flag --connection_type=CLOUD_RESOURCE: value should be one of...
Recupere e copie o ID da conta de serviço para uso em uma etapa posterior:
bq show --connection PROJECT_ID.REGION.CONNECTION_ID
O resultado será assim:
name properties 1234.REGION.CONNECTION_ID {"serviceAccountId": "connection-1234-9u56h9@gcp-sa-bigquery-condel.iam.gserviceaccount.com"}
Terraform
Use o
recurso
google_bigquery_connection.
Para autenticar no BigQuery, configure o Application Default Credentials. Para mais informações, acesse Configurar a autenticação para bibliotecas de cliente.
O exemplo a seguir cria uma conexão de recurso do Cloud chamada my_cloud_resource_connection na região US:
Para aplicar a configuração do Terraform em um projeto do Google Cloud, conclua as etapas nas seções a seguir.
Preparar o Cloud Shell
- Inicie o Cloud Shell.
-
Defina o projeto padrão do Google Cloud em que você quer aplicar as configurações do Terraform.
Você só precisa executar esse comando uma vez por projeto, e ele pode ser executado em qualquer diretório.
export GOOGLE_CLOUD_PROJECT=PROJECT_ID
As variáveis de ambiente serão substituídas se você definir valores explícitos no arquivo de configuração do Terraform.
Preparar o diretório
Cada arquivo de configuração do Terraform precisa ter o próprio diretório, também chamado de módulo raiz.
-
No Cloud Shell, crie um diretório e um novo
arquivo dentro dele. O nome do arquivo precisa ter a extensão
.tf, por exemplo,main.tf. Neste tutorial, o arquivo é chamado demain.tf.mkdir DIRECTORY && cd DIRECTORY && touch main.tf
-
Se você estiver seguindo um tutorial, poderá copiar o exemplo de código em cada seção ou etapa.
Copie o exemplo de código no
main.tfrecém-criado.Se preferir, copie o código do GitHub. Isso é recomendado quando o snippet do Terraform faz parte de uma solução de ponta a ponta.
- Revise e modifique os parâmetros de amostra para aplicar ao seu ambiente.
- Salve as alterações.
-
Inicialize o Terraform. Você só precisa fazer isso uma vez por diretório.
terraform init
Opcionalmente, para usar a versão mais recente do provedor do Google, inclua a opção
-upgrade:terraform init -upgrade
Aplique as alterações
-
Revise a configuração e verifique se os recursos que o Terraform vai criar ou
atualizar correspondem às suas expectativas:
terraform plan
Faça as correções necessárias na configuração.
-
Para aplicar a configuração do Terraform, execute o comando a seguir e digite
yesno prompt:terraform apply
Aguarde até que o Terraform exiba a mensagem "Apply complete!".
- Abra seu projeto do Google Cloud para ver os resultados. No console do Google Cloud, navegue até seus recursos na IU para verificar se foram criados ou atualizados pelo Terraform.
Conceder permissões para a conta de serviço do portal
Conceda à conta de serviço da conexão a função de usuário da Vertex AI. É necessário conceder essa função no mesmo projeto que você criou ou selecionou na seção Antes de começar. Conceder o papel em um projeto diferente resulta no erro bqcx-1234567890-xxxx@gcp-sa-bigquery-condel.iam.gserviceaccount.com does not have the permission to access resource.
Para conceder o papel, siga estas etapas:
Acessar a página AM e administrador
Clique em Conceder acesso.
No campo Novos principais, digite o ID da conta de serviço que você copiou anteriormente.
No campo Selecionar um papel, escolha Vertex AI e, em seguida, selecione o papel Usuário da Vertex AI.
Clique em Salvar.
Criar o modelo remoto
Crie um modelo remoto que represente um modelo de linguagem grande (LLM, na sigla em inglês) hospedado da Vertex AI:
SQL
No Console do Google Cloud, acesse a página BigQuery.
No editor de consultas, execute a seguinte instrução:
CREATE OR REPLACE MODEL `bqml_tutorial.llm_model` REMOTE WITH CONNECTION `LOCATION.CONNECTION_ID` OPTIONS (ENDPOINT = 'text-bison@002');
Substitua:
LOCATION: o local da conexãoCONNECTION_ID: o ID da sua conexão do BigQueryQuando você visualiza os detalhes da conexão no console do Google Cloud, esse é o valor na última seção do ID da conexão totalmente qualificado, mostrado em ID da conexão, por exemplo
projects/myproject/locations/connection_location/connections/myconnection
A consulta leva alguns segundos para ser concluída. Depois disso, o modelo
llm_modelaparece no conjunto de dadosbqml_tutorialno painel Explorer. Como a consulta usa uma instruçãoCREATE MODELpara criar um modelo, não há resultados de consulta.
BigQuery DataFrames
Antes de testar esta amostra, siga as instruções de configuração dos BigQuery DataFrames no Guia de início rápido do BigQuery: como usar os BigQuery DataFrames. Para mais informações, consulte a documentação de referência do BigQuery DataFrames.
Para autenticar no BigQuery, configure o Application Default Credentials. Para mais informações, consulte Configurar o ADC para um ambiente de desenvolvimento local.
Realizar extração de palavra-chave
Realize a extração de palavra-chave em avaliações de filmes do IMDB usando o modelo remoto e a função ML.GENERATE_TEXT:
SQL
No Console do Google Cloud, acesse a página BigQuery.
No editor de consultas, insira a seguinte instrução para realizar a extração de palavra-chave em cinco avaliações de filmes:
SELECT ml_generate_text_result['predictions'][0]['content'] AS generated_text, ml_generate_text_result['predictions'][0]['safetyAttributes'] AS safety_attributes, * EXCEPT (ml_generate_text_result) FROM ML.GENERATE_TEXT( MODEL `bqml_tutorial.llm_model`, ( SELECT CONCAT('Extract the key words from the text below: ', review) AS prompt, * FROM `bigquery-public-data.imdb.reviews` LIMIT 5 ), STRUCT( 0.2 AS temperature, 100 AS max_output_tokens));
A saída é semelhante à seguinte, com as colunas não geradas omitidas para fins de esclarecimento:
+----------------------------------------+---------------------------------------------+-------------------------+----------------------------+-----+ | generated_text | safety_attributes | ml_generate_text_status | prompt | ... | +----------------------------------------+---------------------------------------------+-------------------------+----------------------------+-----+ | " Keywords:\n- British Airways\n- | {"blocked":false,"categories": | | Extract the key words from | | | acting\n- story\n- kid\n- switch off" | ["Death, Harm & Tragedy","Derogatory", | | the text below: I had to | | | | "Finance","Health","Insult", | | see this on the British | | | | "Profanity","Religion & Belief", | | Airways plane. It was | | | | "Sexual","Toxic"] | | terribly bad acting and | | | | "safetyRatings":[{"category": | | a dumb story. Not even | | | | "Dangerous Content","probabilityScore"... | | a kid would enjoy this... | | +----------------------------------------+---------------------------------------------+-------------------------+----------------------------+-----+ | " - Family movie\n- ITV station\n- THE | {"blocked":false,"categories": | | Extract the key words from | | | REAL HOWARD SPITZ\n- Roald Dahl\n- | ["Death, Harm & Tragedy","Derogatory", | | the text below: This is | | | DOCTOR WHO\n- Pulp fiction\n- Child | "Health","Illicit Drugs","Insult", | | a family movie that was | | | abuse\n- KINDERGARTEN COP\n- PC\n- | "Legal","Profanity","Public Safety", | | broadcast on my local | | | Children's author\n- Vadim Jean\n- | "Sexual","Toxic","Violent"], | | ITV station at 1.00 am a | | | Haphazard\n- Kelsey Grammar\n- | "safetyRatings":[{"category": | | couple of nights ago. | | | Dead pan\n- Ridiculous camera angles" | "Dangerous Content","probabilityScore"... | | This might be a strange... | | +----------------------------------------+---------------------------------------------+-------------------------+----------------------------+-----+Os resultados incluem as seguintes colunas:
generated_text: o texto gerado.safety_attributes: os atributos de segurança, com informações sobre eventual bloqueio do conteúdo devido a uma das categorias de bloqueio. Para mais informações sobre os atributos de segurança, consulte a API Vertex PaLM.ml_generate_text_status: o status da resposta da API sobre a linha correspondente. Se a operação tiver sido bem-sucedida, esse valor estará vazio.prompt: o comando usado para a análise de sentimento.- Todas as colunas da tabela
bigquery-public-data.imdb.reviews.
Opcional: em vez de analisar manualmente o JSON retornado pela função, como você fez na etapa anterior, use o argumento
flatten_json_outputpara retornar o texto gerado e os atributos de segurança em colunas separadas.No editor de consultas, execute a seguinte instrução:
SELECT * FROM ML.GENERATE_TEXT( MODEL `bqml_tutorial.llm_model`, ( SELECT CONCAT('Extract the key words from the text below: ', review) AS prompt, * FROM `bigquery-public-data.imdb.reviews` LIMIT 5 ), STRUCT( 0.2 AS temperature, 100 AS max_output_tokens, TRUE AS flatten_json_output));
A saída é semelhante à seguinte, com as colunas não geradas omitidas para fins de esclarecimento:
+----------------------------------------+---------------------------------------------+-------------------------+----------------------------+-----+ | ml_generate_text_llm_result | ml_generate_text_rai_result | ml_generate_text_status | prompt | ... | +----------------------------------------+---------------------------------------------+-------------------------+----------------------------+-----+ | Keywords: | {"blocked":false,"categories": | | Extract the key words from | | | - British Airways | ["Death, Harm & Tragedy","Derogatory", | | the text below: I had to | | | - acting | "Finance","Health","Insult", | | see this on the British | | | - story | "Profanity","Religion & Belief", | | Airways plane. It was | | | - kid | "Sexual","Toxic"] | | terribly bad acting and | | | - switch off | "safetyRatings":[{"category": | | a dumb story. Not even | | | | "Dangerous Content","probabilityScore"... | | a kid would enjoy this... | | +----------------------------------------+---------------------------------------------+-------------------------+----------------------------+-----+ | - Family movie | {"blocked":false,"categories": | | Extract the key words from | | | - ITV station | ["Death, Harm & Tragedy","Derogatory", | | the text below: This is | | | - THE REAL HOWARD SPITZ | "Health","Illicit Drugs","Insult", | | a family movie that was | | | - Roald Dahl | "Legal","Profanity","Public Safety", | | broadcast on my local | | | - DOCTOR WHO | "Sexual","Toxic","Violent"], | | ITV station at 1.00 am a | | | - Pulp Fiction | "safetyRatings":[{"category": | | couple of nights ago. | | | - ... | "Dangerous Content","probabilityScore"... | | This might be a strange... | | +----------------------------------------+---------------------------------------------+-------------------------+----------------------------+-----+Os resultados incluem as seguintes colunas:
ml_generate_text_llm_result: o texto gerado.ml_generate_text_rai_result: os atributos de segurança, com informações sobre eventual bloqueio do conteúdo devido a uma das categorias de bloqueio. Para mais informações sobre os atributos de segurança, consulte a API Vertex PaLM.ml_generate_text_status: o status da resposta da API sobre a linha correspondente. Se a operação tiver sido bem-sucedida, esse valor estará vazio.prompt: o prompt usado para a extração da palavra-chave.- Todas as colunas da tabela
bigquery-public-data.imdb.reviews.
BigQuery DataFrames
Antes de testar esta amostra, siga as instruções de configuração dos BigQuery DataFrames no Guia de início rápido do BigQuery: como usar os BigQuery DataFrames. Para mais informações, consulte a documentação de referência do BigQuery DataFrames.
Para autenticar no BigQuery, configure o Application Default Credentials. Para mais informações, consulte Configurar o ADC para um ambiente de desenvolvimento local.
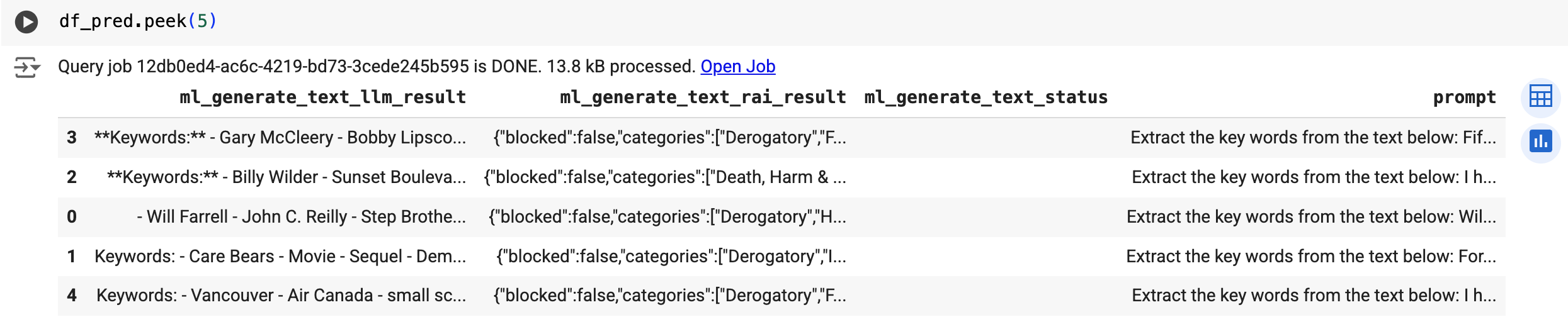
Use a função predict para executar o modelo remoto:
O resultado será semelhante ao seguinte:
Realizar análise de sentimento
Realize a análise de sentimento nas avaliações de filmes do IMDB usando o modelo remoto e a função ML.GENERATE_TEXT:
SQL
No Console do Google Cloud, acesse a página BigQuery.
No editor de consultas, execute a seguinte instrução para realizar a análise de sentimento em cinco avaliações de filmes:
SELECT ml_generate_text_result['predictions'][0]['content'] AS generated_text, ml_generate_text_result['predictions'][0]['safetyAttributes'] AS safety_attributes, * EXCEPT (ml_generate_text_result) FROM ML.GENERATE_TEXT( MODEL `bqml_tutorial.llm_model`, ( SELECT CONCAT( 'perform sentiment analysis on the following text, return one the following categories: positive, negative: ', review) AS prompt, * FROM `bigquery-public-data.imdb.reviews` LIMIT 5 ), STRUCT( 0.2 AS temperature, 100 AS max_output_tokens));
A saída é semelhante à seguinte, com as colunas não geradas omitidas para fins de esclarecimento:
+----------------+---------------------------------------------+-------------------------+----------------------------+-----+ | generated_text | safety_attributes | ml_generate_text_status | prompt | ... | +----------------+---------------------------------------------+-------------------------+----------------------------+-----+ | "negative" | {"blocked":false,"categories": | | perform sentiment analysis | | | | ["Death, Harm & Tragedy","Derogatory", | | on the following text, | | | | "Finance","Health","Insult", | | return one the following | | | | "Profanity","Religion & Belief", | | categories: positive, | | | | "Sexual","Toxic"] | | negative: I had to see | | | | "safetyRatings":[{"category": | | this on the British | | | | "Dangerous Content","probabilityScore"... | | Airways plane. It was... | | +----------------+---------------------------------------------+-------------------------+----------------------------+-----+ | "negative" | {"blocked":false,"categories": | | perform sentiment analysis | | | | ["Death, Harm & Tragedy","Derogatory", | | on the following text, | | | | "Health","Illicit Drugs","Insult", | | return one the following | | | | "Legal","Profanity","Public Safety", | | categories: positive, | | | | "Sexual","Toxic","Violent"], | | negative: This is a family | | | | "safetyRatings":[{"category": | | movie that was broadcast | | | | "Dangerous Content","probabilityScore"... | | on my local ITV station... | | +----------------+---------------------------------------------+-------------------------+----------------------------+-----+Os resultados incluem as mesmas colunas documentadas para Realizar a extração de palavra-chave.
BigQuery DataFrames
Antes de testar esta amostra, siga as instruções de configuração dos BigQuery DataFrames no Guia de início rápido do BigQuery: como usar os BigQuery DataFrames. Para mais informações, consulte a documentação de referência do BigQuery DataFrames.
Para autenticar no BigQuery, configure o Application Default Credentials. Para mais informações, consulte Configurar o ADC para um ambiente de desenvolvimento local.
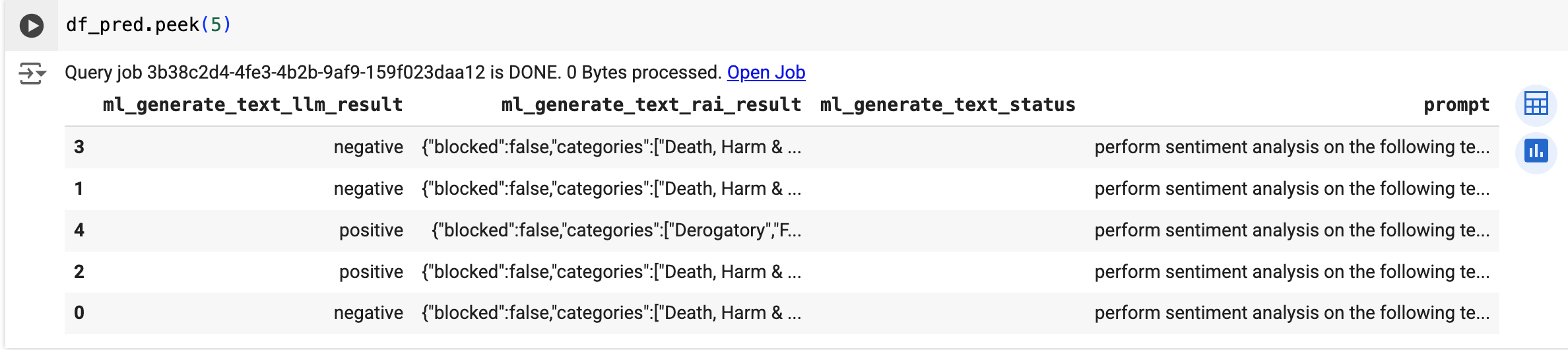
Use a função predict para executar o modelo remoto:
O resultado será semelhante ao seguinte:
Limpar
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.