モデルのエクスポート
このページでは、BigQuery ML モデルをエクスポートする方法を説明します。BigQuery ML モデルを Cloud Storage にエクスポートし、オンライン予測や Python での編集に利用できます。BigQuery ML モデルをエクスポートする方法は、次のとおりです。
- Google Cloud コンソールを使用する。
EXPORT MODELステートメントを使用する。- bq コマンドライン ツールの
bq extractコマンドを使用する。 - API またはクライアント ライブラリを介して
extractジョブを送信する。
エクスポートできるモデルタイプは、次のとおりです。
AUTOENCODERAUTOML_CLASSIFIERAUTOML_REGRESSORBOOSTED_TREE_CLASSIFIERBOOSTED_TREE_REGRESSORDNN_CLASSIFIERDNN_REGRESSORDNN_LINEAR_COMBINED_CLASSIFIERDNN_LINEAR_COMBINED_REGRESSORKMEANSLINEAR_REGLOGISTIC_REGMATRIX_FACTORIZATIONRANDOM_FOREST_CLASSIFIERRANDOM_FOREST_REGRESSORTENSORFLOW(インポートした TensorFlow モデル)PCATRANSFORM_ONLY
モデルの形式とサンプルをエクスポートする
次のテーブルに、各 BigQuery ML モデルタイプのエクスポート先フォーマットと、Cloud Storage バケットに書き込まれるファイルのサンプルを示します。
| モデルタイプ | エクスポート モデルの形式 | エクスポートされたファイルのサンプル |
|---|---|---|
| AUTOML_CLASSIFIER | TensorFlow SavedModel(TF 2.1.0) | gcs_bucket/
|
| AUTOML_REGRESSOR | ||
| AUTOENCODER | TensorFlow SavedModel(TF 1.15 以降) | |
| DNN_CLASSIFIER | ||
| DNN_REGRESSOR | ||
| DNN_LINEAR_COMBINED_CLASSIFIER | ||
| DNN_LINEAR_COMBINED_REGRESSOR | ||
| KMEANS | ||
| LINEAR_REGRESSOR | ||
| LOGISTIC_REG | ||
| MATRIX_FACTORIZATION | ||
| PCA | ||
| TRANSFORM_ONLY | ||
| BOOSTED_TREE_CLASSIFIER | ブースター(XGBoost 0.82) | gcs_bucket/
main.py はローカル実行用です。詳細については、モデルのデプロイをご覧ください。 |
| BOOSTED_TREE_REGRESSOR | ||
| RANDOM_FOREST_REGRESSOR | ||
| RANDOM_FOREST_REGRESSOR | ||
| TensorFlow(インポート) | TensorFlow SavedModel | モデルのインポート時に存在していたものとまったく同じファイル |
TRANSFORM でトレーニングされたモデルをエクスポートする
モデルが TRANSFORM 句でトレーニングされている場合、追加の前処理モデルでも TRANSFORM 句で同じロジックが実行され、サブディレクトリ transform に TensorFlow SavedModel 形式で保存されます。TRANSFORM 句でトレーニングされたモデルは、ローカルにも Vertex AI にもデプロイできます。詳細については、モデルのデプロイをご覧ください。
| エクスポート モデルの形式 | エクスポートされたファイルのサンプル |
|---|---|
|
予測モデル: TensorFlow SavedModel またはブースター(XGBoost 0.82)。 TRANSFORM 句の前処理モデル: TensorFlow SavedModel(TF 2.5 以降) |
gcs_bucket/
|
トレーニング中に TRANSFORM 句の外部で実行された特徴量エンジニアリングに関する情報はモデルに含まれません。たとえば、SELECT ステートメント内の任意の要素です。そのため、前処理モデルにフィードする前に、入力データを手動で変換する必要があります。
サポートされるデータタイプ
TRANSFORM 句でトレーニングされたモデルをエクスポートする場合、TRANSFORM 句へのフィードでは次のデータ型を使用できます。
| TRANSFORM 入力のデータ型 | TRANSFORM 入力サンプル | エクスポートされた前処理モデルの入力サンプル |
|---|---|---|
| INT64 |
10,
|
tf.constant(
|
| NUMERIC |
NUMERIC 10,
|
tf.constant(
|
| BIGNUMERIC |
BIGNUMERIC 10,
|
tf.constant(
|
| FLOAT64 |
10.0,
|
tf.constant(
|
| BOOL |
TRUE,
|
tf.constant(
|
| STRING |
'abc',
|
tf.constant(
|
| BYTES |
b'abc',
|
tf.constant(
|
| DATE |
DATE '2020-09-27',
|
tf.constant(
|
| DATETIME |
DATETIME '2023-02-02 02:02:01.152903',
|
tf.constant(
|
| TIME |
TIME '16:32:36.152903',
|
tf.constant(
|
| TIMESTAMP |
TIMESTAMP '2017-02-28 12:30:30.45-08',
|
tf.constant(
|
| ARRAY |
['a', 'b'],
|
tf.constant(
|
| ARRAY< STRUCT< INT64, FLOAT64>> |
[(1, 1.0), (2, 1.0)],
|
tf.sparse.from_dense(
|
| NULL |
NULL,
|
tf.constant(
|
サポートされている SQL 関数
TRANSFORM 句でトレーニングしたモデルをエクスポートする場合は、TRANSFORM 句内で次の SQL 関数を使用できます。
- 演算子
+、-、*、/、=、<、>、<=、>=、!=、<>、[NOT] BETWEEN、[NOT] IN、IS [NOT] NULL、IS [NOT] TRUE、IS [NOT] FALSE、NOT、AND、OR
- 条件式
CASE expr、CASE、COALESCE、IF、IFNULL、NULLIF
- 数学関数
ABS、ACOS、ACOSH、ASINH、ATAN、ATAN2、ATANH、CBRT、CEIL、CEILING、COS、COSH、COT、COTH、CSC、CSCH、EXP、FLOOR、IS_INF、IS_NAN、LN、LOG、LOG10、MOD、POW、POWER、SEC、SECH、SIGN、SIN、SINH、SQRT、TAN、TANH
- 変換関数
CAST AS INT64,CAST AS FLOAT64,CAST AS NUMERIC,CAST AS BIGNUMERIC,CAST AS STRING,SAFE_CAST AS INT64,SAFE_CAST AS FLOAT64
- 文字列関数
CONCAT、LEFT、LENGTH、LOWER、REGEXP_REPLACE、RIGHT、SPLIT、SUBSTR、SUBSTRING、TRIM、UPPER
- 日付関数
Date、DATE_ADD、DATE_SUB、DATE_DIFF、DATE_TRUNC、EXTRACT、FORMAT_DATE、PARSE_DATE、SAFE.PARSE_DATE
- 日時関数
DATETIME、DATETIME_ADD、DATETIME_SUB、DATETIME_DIFF,DATETIME_TRUNC、EXTRACT、PARSE_DATETIME、SAFE.PARSE_DATETIME
- 時間関数
TIME、TIME_ADD、TIME_SUB、TIME_DIFF、TIME_TRUNC、EXTRACT、FORMAT_TIME、PARSE_TIME、SAFE.PARSE_TIME
- タイムスタンプ関数
TIMESTAMP、TIMESTAMP_ADD、TIMESTAMP_SUB、TIMESTAMP_DIFF、TIMESTAMP_TRUNC、FORMAT_TIMESTAMP、PARSE_TIMESTAMP、SAFE.PARSE_TIMESTAMP、TIMESTAMP_MICROS、TIMESTAMP_MILLIS、TIMESTAMP_SECONDS、EXTRACT、STRING、UNIX_MICROS、UNIX_MILLIS、UNIX_SECONDS
- 手動前処理関数
ML.IMPUTER、ML.HASH_BUCKETIZE、ML.LABEL_ENCODER、ML.MULTI_HOT_ENCODER、ML.NGRAMS、ML.ONE_HOT_ENCODER、ML.BUCKETIZE、ML.MAX_ABS_SCALER、ML.MIN_MAX_SCALER、ML.NORMALIZER、ML.QUANTILE_BUCKETIZE、ML.ROBUST_SCALER、ML.STANDARD_SCALER
制限事項
モデルをエクスポートする場合は、次の制限が適用されます。
トレーニング中に次のいずれかの機能が使用された場合、モデルのエクスポートはサポートされません。
ARRAY、TIMESTAMP、GEOGRAPHYのいずれかの特徴タイプが入力データに存在している。
モデルタイプ
AUTOML_REGRESSORとAUTOML_CLASSIFIER用にエクスポートされたモデルは、オンライン予測の Vertex AI デプロイをサポートしていません。行列分解モデルのエクスポートの場合、モデルサイズの上限は 1 GB です。モデルサイズは
num_factorsにほぼ比例します。この上限に達したときは、トレーニング中にnum_factorsを小さくすることでモデルサイズを縮小できます。手動特徴前処理用に BigQuery ML
TRANSFORM句を使用してトレーニングされたモデルについては、エクスポートでサポートされているデータ型および関数をご覧ください。2023 年 9 月 18 日より前に BigQuery ML
TRANSFORM句を使用してトレーニングされたモデルは、オンライン予測のために Model Registry を通じてデプロイされる前に再トレーニングする必要があります。モデルのエクスポート中、
ARRAY<STRUCT<INT64, FLOAT64>>、ARRAY、TIMESTAMPは変換前のデータとしてサポートされますが、変換後のデータとしてはサポートされません。
BigQuery ML モデルをエクスポートする
モデルをエクスポートするには、次のいずれかを選択します。
コンソール
Google Cloud コンソールで [BigQuery] ページを開きます。
左側のペインで、 [エクスプローラ] をクリックします。

左側のペインが表示されていない場合は、 左側のペインを開くをクリックしてペインを開きます。
[エクスプローラ] ペインで、プロジェクトを開き、[データセット] をクリックして、データセットをクリックします。
[概要] > [モデル] をクリックし、エクスポートするモデル名をクリックします。
[その他> エクスポート] をクリックします。
[Google Cloud Storage へのモデルのエクスポート] ダイアログで、次の操作を行います。
- [GCS の場所を選択] で、モデルをエクスポートするバケットまたはフォルダの場所を参照し、[選択] をクリックします。
- [送信] をクリックしてモデルをエクスポートします。
ジョブの進行状況を確認するには、[エクスプローラ] ペインで [ジョブ履歴] をクリックし、EXTRACT タイプのジョブを探します。
SQL
EXPORT MODEL ステートメントを使用すると、GoogleSQL クエリ構文を使用して BigQuery ML モデルを Cloud Storage にエクスポートできます。
Google Cloud コンソールで EXPORT MODEL ステートメントを使用して BigQuery ML モデルをエクスポートする手順は次のとおりです。
Google Cloud コンソールで、[BigQuery] ページを開きます。
[クエリを新規作成] をクリックします。
[クエリエディタ] フィールドに、
EXPORT MODELステートメントを入力します。次のクエリは、
myproject.mydataset.mymodelという名前のモデルを URIgs://bucket/path/to/saved_model/で Cloud Storage バケットにエクスポートします。EXPORT MODEL `myproject.mydataset.mymodel` OPTIONS(URI = 'gs://bucket/path/to/saved_model/')
[実行] をクリックします。クエリが完了すると、[クエリ結果] ペインに
Successfully exported modelが表示されます。
bq
bq extract コマンドを使用し、--model フラグを指定します。
(省略可)--destination_format フラグを指定して、エクスポートするモデルの形式を選択します。(省略可)--location フラグを指定して、その値をロケーションに設定します。
bq --location=location extract \ --destination_format format \ --model project_id:dataset.model \ gs://bucket/model_folder
ここで
- location はロケーションの名前です。
--locationフラグは省略可能です。たとえば、BigQuery を東京リージョンで使用している場合は、このフラグの値をasia-northeast1に設定します。.bigqueryrc ファイルを使用してロケーションのデフォルト値を設定できます。 - destination_format は、エクスポートされるモデルの形式です。
ML_TF_SAVED_MODEL(デフォルト)またはML_XGBOOST_BOOSTERです。 - project_id はプロジェクト ID です。
- dataset はソース データセットの名前です。
- model は、エクスポートするモデルです。
- bucket は、データのエクスポート先の Cloud Storage バケットの名前です。BigQuery データセットと Cloud Storage バケットは同じロケーションに存在する必要があります。
- model_folder は、エクスポートされるモデルファイルが書き込まれるフォルダの名前です。
例:
たとえば、次のコマンドは mydataset.mymodel を TensorFlow SavedModel 形式で mymodel_folder という名前の Cloud Storage バケットにエクスポートします。
bq extract --model \ 'mydataset.mymodel' \ gs://example-bucket/mymodel_folder
destination_format のデフォルト値は ML_TF_SAVED_MODEL です。
次のコマンドは、mymodel_folder という Cloud Storage バケットに XGBoost ブースター形式で mydataset.mymodel をエクスポートします。
bq extract --model \ --destination_format ML_XGBOOST_BOOSTER \ 'mydataset.mytable' \ gs://example-bucket/mymodel_folder
API
モデルをエクスポートするには、extract ジョブを作成してジョブ構成に入力します。
(省略可)ジョブリソースの jobReference セクションにある location プロパティでロケーションを指定します。
BigQuery ML モデルと Cloud Storage のエクスポート先を指す抽出ジョブを作成します。
プロジェクト ID、データセット ID、モデル ID を含む
sourceModel構成オブジェクトを使用して、ソースモデルを指定します。destination URI(s)プロパティは、完全修飾の gs://bucket/model_folder の形式にする必要があります。configuration.extract.destinationFormatプロパティを設定して、宛先の形式を指定します。たとえば、ブーストツリー モデルをエクスポートする場合は、このプロパティの値をML_XGBOOST_BOOSTERに設定します。ジョブ ステータスを確認するには、最初のリクエストで返されるジョブの ID を指定して jobs.get(job_id) を呼び出します。
status.state = DONEである場合、ジョブは正常に完了しています。status.errorResultプロパティが存在する場合は、リクエストが失敗したことを意味し、該当するオブジェクトにエラーを説明する情報が格納されます。status.errorResultが存在しない場合、ジョブは正常に完了したものの、致命的でないエラーが発生した可能性があります。致命的でないエラーは、返されたジョブ オブジェクトのstatus.errorsプロパティに格納されています。
API に関する注記:
ベスト プラクティスとして、
jobs.insertを呼び出して読み込みジョブを作成する際に、一意の ID を生成して、その ID をjobReference.jobIdとして渡します。この手法は、ネットワーク障害時にクライアントは既知のジョブ ID を使ってポーリングまたは再試行できるので、より確実です。特定のジョブ ID で
jobs.insertを呼び出す操作は「べき等」です。つまり、同じジョブ ID で何回でも再試行できますが、成功するオペレーションはそのうちの 1 回だけです。
Java
このサンプルを試す前に、クライアント ライブラリを使用した BigQuery クイックスタートにある Java の設定手順を完了してください。詳細については、BigQuery Java API のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、クライアント ライブラリの認証情報を設定するをご覧ください。
モデルのデプロイ
エクスポートしたモデルは、ローカルにも Vertex AI にもデプロイできます。モデルの TRANSFORM 句に、日付関数、日時関数、時間関数、タイムスタンプ関数のいずれかが含まれている場合は、コンテナで bigquery-ml-utils ライブラリを使用する必要があります。エクスポートされたモデルやサービング コンテナを必要としない、Model Registry を使用したデプロイの場合は例外です。
Vertex AI のデプロイ
| エクスポート モデルの形式 | デプロイ |
|---|---|
| TensorFlow SavedModel(AutoML 以外のモデル) | TensorFlow SavedModel をデプロイします。TensorFlow のサポート対象バージョンを使用して SavedModel ファイルを作成する必要があります。 |
| TensorFlow SavedModel(AutoML モデル) | サポートされていません。 |
| XGBoost Booster |
カスタム予測ルーチンを使用します。XGBoost Booster モデルの場合、エクスポートされたファイルに前処理と後処理の情報が保存されます。カスタム予測ルーチンを使用すると、エクスポートされた追加ファイルを使用してモデルをデプロイできます。 XGBoost のサポート対象バージョンを使用して、モデルファイルを作成する必要があります。 |
ローカルへのデプロイ
| エクスポート モデルの形式 | デプロイ |
|---|---|
| TensorFlow SavedModel(AutoML 以外のモデル) | SavedModel は標準形式であり、TensorFlow Service Docker コンテナにデプロイできます。 Vertex AI オンライン予測ローカル実行も利用できます。 |
| TensorFlow SavedModel(AutoML モデル) | モデルをコンテナ化して実行します。 |
| XGBoost ブースター | XGBoost ブースター モデルをローカルで実行するには、エクスポートされた main.py ファイルを使用します。
|
予測出力形式
このセクションでは、エクスポートされたモデルのモデルタイプごとの予測出力形式について説明します。エクスポートされたすべてのモデルはバッチ予測をサポートしており、一度に複数の入力行を処理できます。たとえば、次の出力形式の例にはそれぞれ 2 つの入力行があります。
AUTOENCODER
| 予測出力形式 | 出力例 |
|---|---|
+------------------------+------------------------+------------------------+
| LATENT_COL_1 | LATENT_COL_2 | ... |
+------------------------+------------------------+------------------------+
| [FLOAT] | [FLOAT] | ... |
+------------------------+------------------------+------------------------+
|
+------------------+------------------+------------------+------------------+
| LATENT_COL_1 | LATENT_COL_2 | LATENT_COL_3 | LATENT_COL_4 |
+------------------------+------------+------------------+------------------+
| 0.21384512 | 0.93457112 | 0.64978097 | 0.00480489 |
+------------------+------------------+------------------+------------------+
|
AUTOML_CLASSIFIER
| 予測出力形式 | 出力例 |
|---|---|
+------------------------------------------+
| predictions |
+------------------------------------------+
| [{"scores":[FLOAT], "classes":[STRING]}] |
+------------------------------------------+
|
+---------------------------------------------+
| predictions |
+---------------------------------------------+
| [{"scores":[1, 2], "classes":['a', 'b']}, |
| {"scores":[3, 0.2], "classes":['a', 'b']}] |
+---------------------------------------------+
|
AUTOML_REGRESSOR
| 予測出力形式 | 出力例 |
|---|---|
+-----------------+
| predictions |
+-----------------+
| [FLOAT] |
+-----------------+
|
+-----------------+
| predictions |
+-----------------+
| [1.8, 2.46] |
+-----------------+
|
BOOSTED_TREE_CLASSIFIER と RANDOM_FOREST_CLASSIFIER
| 予測出力形式 | 出力例 |
|---|---|
+-------------+--------------+-----------------+
| LABEL_PROBS | LABEL_VALUES | PREDICTED_LABEL |
+-------------+--------------+-----------------+
| [FLOAT] | [STRING] | STRING |
+-------------+--------------+-----------------+
|
+-------------+--------------+-----------------+
| LABEL_PROBS | LABEL_VALUES | PREDICTED_LABEL |
+-------------+--------------+-----------------+
| [0.1, 0.9] | ['a', 'b'] | ['b'] |
+-------------+--------------+-----------------+
| [0.8, 0.2] | ['a', 'b'] | ['a'] |
+-------------+--------------+-----------------+
|
BOOSTED_TREE_REGRESSOR と RANDOM_FOREST_REGRESSOR
| 予測出力形式 | 出力例 |
|---|---|
+-----------------+
| predicted_label |
+-----------------+
| FLOAT |
+-----------------+
|
+-----------------+
| predicted_label |
+-----------------+
| [1.8] |
+-----------------+
| [2.46] |
+-----------------+
|
DNN_CLASSIFIER
| 予測出力形式 | 出力例 |
|---|---|
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| ALL_CLASS_IDS | ALL_CLASSES | CLASS_IDS | CLASSES | LOGISTIC (binary only) | LOGITS | PROBABILITIES |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| [INT64] | [STRING] | INT64 | STRING | FLOAT | [FLOAT]| [FLOAT] |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
|
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| ALL_CLASS_IDS | ALL_CLASSES | CLASS_IDS | CLASSES | LOGISTIC (binary only) | LOGITS | PROBABILITIES |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| [0, 1] | ['a', 'b'] | [0] | ['a'] | [0.36] | [-0.53]| [0.64, 0.36] |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| [0, 1] | ['a', 'b'] | [0] | ['a'] | [0.2] | [-1.38]| [0.8, 0.2] |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
|
DNN_REGRESSOR
| 予測出力形式 | 出力例 |
|---|---|
+-----------------+
| PREDICTED_LABEL |
+-----------------+
| FLOAT |
+-----------------+
|
+-----------------+
| PREDICTED_LABEL |
+-----------------+
| [1.8] |
+-----------------+
| [2.46] |
+-----------------+
|
DNN_LINEAR_COMBINED_CLASSIFIER
| 予測出力形式 | 出力例 |
|---|---|
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| ALL_CLASS_IDS | ALL_CLASSES | CLASS_IDS | CLASSES | LOGISTIC (binary only) | LOGITS | PROBABILITIES |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| [INT64] | [STRING] | INT64 | STRING | FLOAT | [FLOAT]| [FLOAT] |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
|
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| ALL_CLASS_IDS | ALL_CLASSES | CLASS_IDS | CLASSES | LOGISTIC (binary only) | LOGITS | PROBABILITIES |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| [0, 1] | ['a', 'b'] | [0] | ['a'] | [0.36] | [-0.53]| [0.64, 0.36] |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| [0, 1] | ['a', 'b'] | [0] | ['a'] | [0.2] | [-1.38]| [0.8, 0.2] |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
|
DNN_LINEAR_COMBINED_REGRESSOR
| 予測出力形式 | 出力例 |
|---|---|
+-----------------+
| PREDICTED_LABEL |
+-----------------+
| FLOAT |
+-----------------+
|
+-----------------+
| PREDICTED_LABEL |
+-----------------+
| [1.8] |
+-----------------+
| [2.46] |
+-----------------+
|
KMEANS
| 予測出力形式 | 出力例 |
|---|---|
+--------------------+--------------+---------------------+
| CENTROID_DISTANCES | CENTROID_IDS | NEAREST_CENTROID_ID |
+--------------------+--------------+---------------------+
| [FLOAT] | [INT64] | INT64 |
+--------------------+--------------+---------------------+
|
+--------------------+--------------+---------------------+
| CENTROID_DISTANCES | CENTROID_IDS | NEAREST_CENTROID_ID |
+--------------------+--------------+---------------------+
| [1.2, 1.3] | [1, 2] | [1] |
+--------------------+--------------+---------------------+
| [0.4, 0.1] | [1, 2] | [2] |
+--------------------+--------------+---------------------+
|
LINEAR_REG
| 予測出力形式 | 出力例 |
|---|---|
+-----------------+
| PREDICTED_LABEL |
+-----------------+
| FLOAT |
+-----------------+
|
+-----------------+
| PREDICTED_LABEL |
+-----------------+
| [1.8] |
+-----------------+
| [2.46] |
+-----------------+
|
LOGISTIC_REG
| 予測出力形式 | 出力例 |
|---|---|
+-------------+--------------+-----------------+
| LABEL_PROBS | LABEL_VALUES | PREDICTED_LABEL |
+-------------+--------------+-----------------+
| [FLOAT] | [STRING] | STRING |
+-------------+--------------+-----------------+
|
+-------------+--------------+-----------------+
| LABEL_PROBS | LABEL_VALUES | PREDICTED_LABEL |
+-------------+--------------+-----------------+
| [0.1, 0.9] | ['a', 'b'] | ['b'] |
+-------------+--------------+-----------------+
| [0.8, 0.2] | ['a', 'b'] | ['a'] |
+-------------+--------------+-----------------+
|
MATRIX_FACTORIZATION
注: 現在サポートされているのは、入力ユーザーと出力の上位 50 位(predicted_rating、predicted_item)のペアを、predicted_rating 別に降順で並べ替えることだけです。
| 予測出力形式 | 出力例 |
|---|---|
+--------------------+--------------+
| PREDICTED_RATING | PREDICTED_ITEM |
+------------------+----------------+
| [FLOAT] | [STRING] |
+------------------+----------------+
|
+--------------------+--------------+
| PREDICTED_RATING | PREDICTED_ITEM |
+------------------+----------------+
| [5.5, 1.7] | ['A', 'B'] |
+------------------+----------------+
| [7.2, 2.7] | ['B', 'A'] |
+------------------+----------------+
|
TensorFlow(インポート)
| 予測出力形式 |
|---|
| インポートしたモデルと同じ |
PCA
| 予測出力形式 | 出力例 |
|---|---|
+-------------------------+---------------------------------+
| PRINCIPAL_COMPONENT_IDS | PRINCIPAL_COMPONENT_PROJECTIONS |
+-------------------------+---------------------------------+
| [INT64] | [FLOAT] |
+-------------------------+---------------------------------+
|
+-------------------------+---------------------------------+
| PRINCIPAL_COMPONENT_IDS | PRINCIPAL_COMPONENT_PROJECTIONS |
+-------------------------+---------------------------------+
| [1, 2] | [1.2, 5.0] |
+-------------------------+---------------------------------+
|
TRANSFORM_ONLY
| 予測出力形式 |
|---|
モデルの TRANSFORM 句で指定された列と同じです。 |
XGBoost モデルの可視化
モデルのエクスポート後に plot_tree Python API を使用して、ブーストツリーを可視化します。たとえば、依存関係をインストールせずに Colab を利用できます。
- ブーストツリー モデルを Cloud Storage バケットにエクスポートします。
- Cloud Storage バケットから
model.bstファイルをダウンロードします。 - Colab ノートブックで、
model.bstファイルをFilesにアップロードします。 ノートブックで次のコードを実行します。
import xgboost as xgb import matplotlib.pyplot as plt model = xgb.Booster(model_file="model.bst") num_iterations = <iteration_number> for tree_num in range(num_iterations): xgb.plot_tree(model, num_trees=tree_num) plt.show
この例では、複数のツリーを作成します(イテレーションごとに 1 つのツリー)。
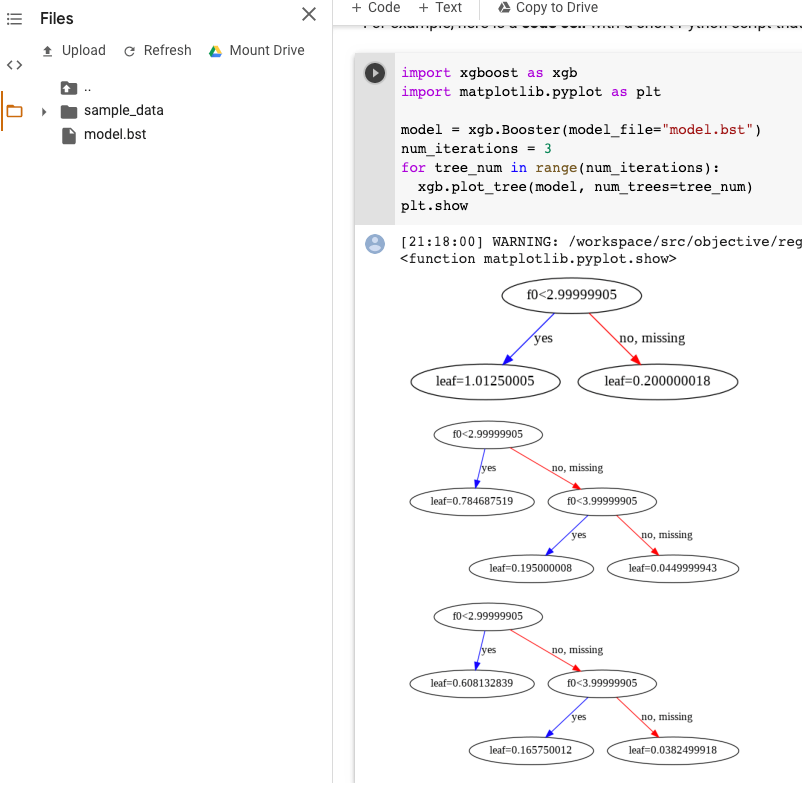
現在、モデルに特徴名を保存していないため、f0 や f1 のような名前が表示されます。これらの名前(たとえば f0)をインデックスとして使用して、エクスポートされた assets/model_metadata.json ファイルで対応する特徴名を探すことができます。
必要な権限
BigQuery ML モデルを Cloud Storage にエクスポートするには、BigQuery ML モデルにアクセスする権限、抽出ジョブを実行する権限、Cloud Storage バケットにデータを書き込む権限が必要です。
BigQuery の権限
モデルをエクスポートするには、少なくとも
bigquery.models.export権限が付与されている必要があります。以下の Identity and Access Management(IAM)の事前定義ロールには、bigquery.models.export権限が含まれています。bigquery.dataViewerbigquery.dataOwnerbigquery.dataEditorbigquery.admin
エクスポート ジョブを実行するには、少なくとも
bigquery.jobs.create権限が付与されている必要があります。事前定義された以下の IAM のロールにはbigquery.jobs.create権限が含まれています。bigquery.userbigquery.jobUserbigquery.admin
Cloud Storage の権限
既存の Cloud Storage バケットにデータを書き込むには、
storage.objects.create権限が付与されている必要があります。事前定義された以下の IAM のロールにはstorage.objects.create権限が含まれています。storage.objectCreatorstorage.objectAdminstorage.admin
BigQuery ML での IAM のロールと権限の詳細については、アクセス制御をご覧ください。
ロケーション間で BigQuery データを移動する
データセットの作成後にそのロケーションを変更することはできませんが、データセットのコピーを作成することはできます。
割り当てポリシー
抽出ジョブの割り当てについては、「割り当てと上限」のページの抽出ジョブをご覧ください。
料金
BigQuery ML モデルのエクスポートは無料で利用できますが、エクスポートには BigQuery の割り当てと上限が適用されます。BigQuery の料金設定の詳細については、料金設定のページをご覧ください。
データのエクスポート終了後、Cloud Storage へのデータの保存に対して課金されます。Cloud Storage の料金設定の詳細については、クラウドの料金設定のページをご覧ください。
次のステップ
- オンライン予測の BigQuery ML モデルをエクスポートするチュートリアルを確認する。