이 튜토리얼에서는 BigQuery ML 모델을 내보낸 다음 AI Platform 또는 로컬 머신에 배포하는 방법을 보여줍니다. BigQuery 공개 데이터 세트의 iris 테이블을 사용하고 다음과 같은 3개의 엔드 투 엔드 시나리오를 살펴봅니다.
- 로지스틱 회귀 모델을 학습하고 배포합니다. 또한 DNN 분류, DNN 회귀, k-평균, 선형 회귀, 행렬 분해 모델에도 적용됩니다.
- 부스티드 트리 분류 모델을 학습하고 배포합니다. 또한 부스티드 트리 회귀 모델에도 적용됩니다.
- AutoML 분류 모델을 학습하고 배포합니다. 또한 AutoML 회귀 모델에도 적용됩니다.
비용
이 튜토리얼에서는 비용이 청구될 수 있는 Google Cloud구성요소를 사용합니다.
- BigQuery ML
- Cloud Storage
- AI Platform(선택사항, 온라인 예측에 사용)
BigQuery ML 비용에 대한 자세한 내용은 BigQuery ML 가격 책정을 참조하세요.
Cloud Storage 비용에 대한 자세한 내용은 Cloud Storage 가격 책정 페이지를 참조하세요.
AI Platform 비용에 대한 자세한 내용은 예측 노드 및 리소스 할당 페이지를 참조하세요.
시작하기 전에
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
- BigQuery는 새 프로젝트에서 자동으로 사용 설정됩니다.
기존 프로젝트에서 BigQuery를 활성화하려면 다음으로 이동합니다.
Enable the BigQuery API.
-
Enable the AI Platform Training and Prediction API and Compute Engine APIs.
- Google Cloud CLI 및 Google Cloud CLI를 설치합니다.
데이터 세트 만들기
ML 모델을 저장할 BigQuery 데이터 세트를 만듭니다.
콘솔
Google Cloud 콘솔에서 BigQuery 페이지로 이동합니다.
탐색기 창에서 프로젝트 이름을 클릭합니다.
작업 보기 > 데이터 세트 만들기를 클릭합니다.
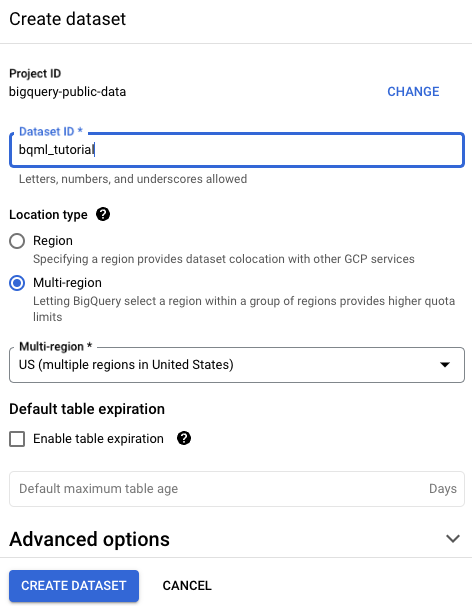
데이터 세트 만들기 페이지에서 다음을 수행합니다.
데이터 세트 ID에
bqml_tutorial를 입력합니다.위치 유형에 대해 멀티 리전을 선택한 다음 US(미국 내 여러 리전)를 선택합니다.
공개 데이터 세트는
US멀티 리전에 저장됩니다. 편의상 같은 위치에 데이터 세트를 저장합니다.- 나머지 기본 설정은 그대로 두고 데이터 세트 만들기를 클릭합니다.
bq
새 데이터 세트를 만들려면 --location 플래그와 함께 bq mk 명령어를 실행합니다. 사용할 수 있는 전체 파라미터 목록은 bq mk --dataset 명령어 참조를 확인하세요.
데이터 위치가
US로 설정되고 설명이BigQuery ML tutorial dataset인bqml_tutorial데이터 세트를 만듭니다.bq --location=US mk -d \ --description "BigQuery ML tutorial dataset." \ bqml_tutorial
--dataset플래그를 사용하는 대신 이 명령어는-d단축키를 사용합니다.-d와--dataset를 생략하면 이 명령어는 기본적으로 데이터 세트를 만듭니다.데이터 세트가 생성되었는지 확인합니다.
bq ls
API
데이터 세트 리소스가 정의된 datasets.insert 메서드를 호출합니다.
{ "datasetReference": { "datasetId": "bqml_tutorial" } }
로지스틱 회귀 모델 학습 및 배포
모델 학습
BigQuery ML CREATE MODEL 문을 사용하여 iris 유형을 예측하는 로지스틱 회귀 모델을 학습시킵니다. 이 학습 작업은 완료하는 데 약 1분이 소요됩니다.
bq query --use_legacy_sql=false \ 'CREATE MODEL `bqml_tutorial.iris_model` OPTIONS (model_type="logistic_reg", max_iterations=10, input_label_cols=["species"]) AS SELECT * FROM `bigquery-public-data.ml_datasets.iris`;'
모델 내보내기
bq 명령줄 도구를 사용하여 모델을 Cloud Storage 버킷으로 내보냅니다. 모델을 내보내는 다른 방법은 BigQuery ML 모델 내보내기를 참조하세요. 이 추출 작업은 완료하는 데 1분 미만이 소요됩니다.
bq extract -m bqml_tutorial.iris_model gs://some/gcs/path/iris_model
로컬 배포 및 제공
TensorFlow Serving Docker 컨테이너를 사용하여 내보낸 TensorFlow 모델을 배포할 수 있습니다. 다음 단계에서는 Docker를 설치해야 합니다.
내보낸 모델 파일을 임시 디렉터리에 다운로드
mkdir tmp_dir
gcloud storage cp gs://some/gcs/path/iris_model tmp_dir --recursive
버전 하위 디렉터리 만들기
이 단계에서는 모델의 버전 번호(이 경우 1)를 설정합니다.
mkdir -p serving_dir/iris_model/1
cp -r tmp_dir/iris_model/* serving_dir/iris_model/1
rm -r tmp_dir
Docker 이미지 가져오기
docker pull tensorflow/serving
Docker 컨테이너 실행
docker run -p 8500:8500 --network="host" --mount type=bind,source=`pwd`/serving_dir/iris_model,target=/models/iris_model -e MODEL_NAME=iris_model -t tensorflow/serving &
예측 실행
curl -d '{"instances": [{"sepal_length":5.0, "sepal_width":2.0, "petal_length":3.5, "petal_width":1.0}]}' -X POST http://localhost:8501/v1/models/iris_model:predict
온라인 배포 및 제공
이 섹션에서는 Google Cloud CLI를 사용하여 내보낸 모델에 대한 예측을 배포하고 실행합니다.
온라인/일괄 예측을 위해 AI Platform에 모델 배포하기에 대한 자세한 내용은 모델 배포를 참조하세요.
모델 리소스 만들기
MODEL_NAME="IRIS_MODEL"
gcloud ai-platform models create $MODEL_NAME
모델 버전 만들기
1) 환경 변수를 설정합니다.
MODEL_DIR="gs://some/gcs/path/iris_model"
// Select a suitable version for this model
VERSION_NAME="v1"
FRAMEWORK="TENSORFLOW"
2) 버전을 만듭니다.
gcloud ai-platform versions create $VERSION_NAME --model=$MODEL_NAME --origin=$MODEL_DIR --runtime-version=1.15 --framework=$FRAMEWORK
이 단계를 완료하는 데 몇 분이 걸릴 수 있습니다. Creating version (this might take a few minutes)...... 메시지가 표시됩니다.
3) (선택사항) 새 버전에 대한 정보를 가져옵니다.
gcloud ai-platform versions describe $VERSION_NAME --model $MODEL_NAME
다음과 비슷한 출력이 표시됩니다.
createTime: '2020-02-28T16:30:45Z'
deploymentUri: gs://your_bucket_name
framework: TENSORFLOW
machineType: mls1-c1-m2
name: projects/[YOUR-PROJECT-ID]/models/IRIS_MODEL/versions/v1
pythonVersion: '2.7'
runtimeVersion: '1.15'
state: READY
온라인 예측
배포된 모델에 대한 온라인 예측 실행에 대한 자세한 내용은 예측 요청을 참고하세요.
1) 입력을 위해 줄바꿈으로 구분된 JSON 파일을 만듭니다(예: 다음 콘텐츠가 포함된 instances.json 파일).
{"sepal_length":5.0, "sepal_width":2.0, "petal_length":3.5, "petal_width":1.0}
{"sepal_length":5.3, "sepal_width":3.7, "petal_length":1.5, "petal_width":0.2}
2) 예측을 위한 환경 변수를 설정합니다.
INPUT_DATA_FILE="instances.json"
3) 예측을 실행합니다.
gcloud ai-platform predict --model $MODEL_NAME --version $VERSION_NAME --json-instances $INPUT_DATA_FILE
부스티드 트리 분류 모델 학습 및 배포
모델 학습
CREATE MODEL 문을 사용하여 iris 유형을 예측하는 부스티드 트리 분류 모델을 학습시킵니다. 이 학습 작업은 완료하는 데 약 7분 정도 걸립니다.
bq query --use_legacy_sql=false \ 'CREATE MODEL `bqml_tutorial.boosted_tree_iris_model` OPTIONS (model_type="boosted_tree_classifier", max_iterations=10, input_label_cols=["species"]) AS SELECT * FROM `bigquery-public-data.ml_datasets.iris`;'
모델 내보내기
bq 명령줄 도구를 사용하여 모델을 Cloud Storage 버킷으로 내보냅니다. 모델을 내보내는 다른 방법은 BigQuery ML 모델 내보내기를 참조하세요.
bq extract --destination_format ML_XGBOOST_BOOSTER -m bqml_tutorial.boosted_tree_iris_model gs://some/gcs/path/boosted_tree_iris_model
로컬 배포 및 제공
내보낸 파일에는 로컬 실행을 위한 main.py 파일이 있습니다.
내보낸 모델 파일을 로컬 디렉터리로 다운로드
mkdir serving_dir
gcloud storage cp gs://some/gcs/path/boosted_tree_iris_model serving_dir --recursive
예측자 추출
tar -xvf serving_dir/boosted_tree_iris_model/xgboost_predictor-0.1.tar.gz -C serving_dir/boosted_tree_iris_model/
XGBoost 라이브러리 설치
XGBoost 라이브러리 - 버전 0.82 이상을 설치합니다.
예측 실행
cd serving_dir/boosted_tree_iris_model/
python main.py '[{"sepal_length":5.0, "sepal_width":2.0, "petal_length":3.5, "petal_width":1.0}]'
온라인 배포 및 제공
이 섹션에서는 Google Cloud CLI를 사용하여 AI Platform 온라인 예측에서 내보낸 모델에 대한 예측을 배포하고 실행합니다.
커스텀 루틴을 사용해서 온라인/일괄 예측을 위해 AI Platform에 모델을 배포하는 방법에 대한 자세한 내용은 모델 배포를 참조하세요.
모델 리소스 만들기
MODEL_NAME="BOOSTED_TREE_IRIS_MODEL"
gcloud ai-platform models create $MODEL_NAME
모델 버전 만들기
1) 환경 변수를 설정합니다.
MODEL_DIR="gs://some/gcs/path/boosted_tree_iris_model"
VERSION_NAME="v1"
2) 버전을 만듭니다.
gcloud beta ai-platform versions create $VERSION_NAME --model=$MODEL_NAME --origin=$MODEL_DIR --package-uris=${MODEL_DIR}/xgboost_predictor-0.1.tar.gz --prediction-class=predictor.Predictor --runtime-version=1.15
이 단계를 완료하는 데 몇 분이 걸릴 수 있습니다. Creating version (this might take a few minutes)...... 메시지가 표시됩니다.
3) (선택사항) 새 버전에 대한 정보를 가져옵니다.
gcloud ai-platform versions describe $VERSION_NAME --model $MODEL_NAME
다음과 비슷한 출력이 표시됩니다.
createTime: '2020-02-07T00:35:42Z'
deploymentUri: gs://some/gcs/path/boosted_tree_iris_model
etag: rp090ebEnQk=
machineType: mls1-c1-m2
name: projects/[YOUR-PROJECT-ID]/models/BOOSTED_TREE_IRIS_MODEL/versions/v1
packageUris:
- gs://some/gcs/path/boosted_tree_iris_model/xgboost_predictor-0.1.tar.gz
predictionClass: predictor.Predictor
pythonVersion: '2.7'
runtimeVersion: '1.15'
state: READY
온라인 예측
배포된 모델에 대해 온라인 예측을 실행하는 방법에 대한 자세한 내용은 예측 요청을 참조하세요.
1) 입력을 위해 줄바꿈으로 구분된 JSON 파일을 만듭니다. 예를 들어 다음 콘텐츠가 포함된 instances.json 파일입니다.
{"sepal_length":5.0, "sepal_width":2.0, "petal_length":3.5, "petal_width":1.0}
{"sepal_length":5.3, "sepal_width":3.7, "petal_length":1.5, "petal_width":0.2}
2) 예측을 위해 환경 변수를 설정합니다.
INPUT_DATA_FILE="instances.json"
3) 예측을 실행합니다.
gcloud ai-platform predict --model $MODEL_NAME --version $VERSION_NAME --json-instances $INPUT_DATA_FILE
AutoML 분류 모델 학습 및 배포
모델 학습
CREATE MODEL 문을 사용하여 iris 유형을 예측하는 AutoML 분류 모델을 학습합니다. AutoML 모델에는 최소 1,000개의 입력 데이터 행이 필요합니다. ml_datasets.iris에 행이 150개 뿐이므로 데이터를 10배로 복제합니다. 이 학습 작업은 완료하는 데 2시간 정도 걸립니다.
bq query --use_legacy_sql=false \ 'CREATE MODEL `bqml_tutorial.automl_iris_model` OPTIONS (model_type="automl_classifier", budget_hours=1, input_label_cols=["species"]) AS SELECT * EXCEPT(multiplier) FROM `bigquery-public-data.ml_datasets.iris`, unnest(GENERATE_ARRAY(1, 10)) as multiplier;'
모델 내보내기
bq 명령줄 도구를 사용하여 모델을 Cloud Storage 버킷으로 내보냅니다. 모델을 내보내는 다른 방법은 BigQuery ML 모델 내보내기를 참조하세요.
bq extract -m bqml_tutorial.automl_iris_model gs://some/gcs/path/automl_iris_model
로컬 배포 및 제공
AutoML 컨테이너 빌드에 대한 자세한 내용은 모델 내보내기를 참조하세요. 다음 단계에서는 Docker를 설치해야 합니다.
내보낸 모델 파일을 로컬 디렉터리에 복사
mkdir automl_serving_dir
gcloud storage cp gs://some/gcs/path/automl_iris_model/* automl_serving_dir/ --recursive
AutoML Docker 이미지 가져오기
docker pull gcr.io/cloud-automl-tables-public/model_server
Docker 컨테이너 시작
docker run -v `pwd`/automl_serving_dir:/models/default/0000001 -p 8080:8080 -it gcr.io/cloud-automl-tables-public/model_server
예측 실행
1) 입력을 위해 줄바꿈으로 구분된 JSON 파일을 만듭니다. 예를 들어 다음 콘텐츠가 포함된 input.json 파일입니다.
{"instances": [{"sepal_length":5.0, "sepal_width":2.0, "petal_length":3.5, "petal_width":1.0},
{"sepal_length":5.3, "sepal_width":3.7, "petal_length":1.5, "petal_width":0.2}]}
2) 예측 호출을 수행합니다.
curl -X POST --data @input.json http://localhost:8080/predict
온라인 배포 및 제공
AutoML 회귀 및 AutoML 분류 모델에 대한 온라인 예측은 AI Platform에서 지원되지 않습니다.
삭제
이 튜토리얼에서 사용된 리소스 비용이 Google Cloud 계정에 청구되지 않도록 하려면 리소스가 포함된 프로젝트를 삭제하거나 프로젝트를 유지하고 개별 리소스를 삭제하세요.
- 만든 프로젝트를 삭제할 수 있습니다.
- 또는 프로젝트는 유지하고 데이터 세트와 Cloud Storage 버킷을 삭제할 수 있습니다.
Docker 컨테이너 중지
1) 실행 중인 모든 Docker 컨테이너를 나열합니다.
docker ps
2) 컨테이너 목록에서 해당 컨테이너 ID를 가진 컨테이너를 중지합니다.
docker stop container_id
AI Platform 리소스 삭제
1) 모델 버전을 삭제합니다.
gcloud ai-platform versions delete $VERSION_NAME --model=$MODEL_NAME
2) 모델을 삭제합니다.
gcloud ai-platform models delete $MODEL_NAME
데이터 세트 삭제
프로젝트를 삭제하면 프로젝트의 데이터 세트와 테이블이 모두 삭제됩니다. 프로젝트를 다시 사용하려면 이 튜토리얼에서 만든 데이터 세트를 삭제할 수 있습니다.
필요한 경우 Google Cloud 콘솔에서 BigQuery 페이지를 엽니다.
앞서 만든 bqml_tutorial 데이터 세트를 탐색에서 선택합니다.
창의 오른쪽에 있는 데이터 세트 삭제를 클릭합니다. 데이터 세트, 테이블, 모든 데이터가 삭제됩니다.
데이터 세트 삭제 대화상자에서 데이터 세트 이름(
bqml_tutorial)을 입력하여 삭제 명령어를 확인한 후 삭제를 클릭합니다.
Cloud Storage 버킷 삭제
프로젝트를 삭제하면 프로젝트의 모든 Cloud Storage 버킷이 삭제됩니다. 프로젝트를 재사용하려는 경우 이 튜토리얼에서 만든 버킷을 삭제할 수 있습니다.
- Google Cloud 콘솔에서 Cloud Storage 버킷 페이지로 이동합니다.
삭제할 버킷의 체크박스를 선택합니다.
삭제를 클릭합니다.
표시되는 오버레이 창에서 삭제를 클릭하여 버킷과 콘텐츠를 삭제합니다.
프로젝트 삭제
프로젝트를 삭제하는 방법은 다음과 같습니다.
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
다음 단계
- BigQuery ML 개요는 BigQuery ML 소개를 참조하세요.
- 모델 내보내기에 대한 자세한 내용은 모델 내보내기를 참조하세요.
- 모델 만들기에 대한 자세한 내용은
CREATE MODEL구문 페이지를 참조하세요.