Questo tutorial mostra come esportare un modello BigQuery ML
e poi eseguirlo su AI Platform o su un computer locale. Utilizzerai la tabella iris dei set di dati pubblici di BigQuery ed esaminerai i seguenti tre scenari end-to-end:
- Addestramento e implementazione di un modello di regressione logistica. Si applica anche ai modelli di classificazione DNN, di regressione DNN, K-means, di regressione lineare e di fattorizzazione matriciale.
- Addestra ed esegui il deployment di un modello di classificazione ad albero con boosting, applicabile anche al modello di regressione ad albero con boosting.
- Addestra ed esegui il deployment di un modello di classificazione AutoML. Si applica anche al modello di regressione AutoML.
Costi
Questo tutorial utilizza i componenti fatturabili di Google Cloud, tra cui:
- BigQuery ML
- Cloud Storage
- AI Platform (facoltativo, utilizzato per la previsione online)
Per ulteriori informazioni sui costi di BigQuery ML, consulta Prezzi di BigQuery ML.
Per maggiori informazioni sui costi di Cloud Storage, consulta la pagina Prezzi di Cloud Storage.
Per ulteriori informazioni sui costi di AI Platform, consulta la pagina su nodi di previsione e allocazione di risorse.
Prima di iniziare
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
- BigQuery viene attivato automaticamente nei nuovi progetti.
Per attivare BigQuery in un progetto preesistente, vai a
Enable the BigQuery API.
-
Enable the AI Platform Training and Prediction API and Compute Engine APIs.
- Installa Google Cloud CLI e Google Cloud CLI.
Crea il tuo set di dati
Crea un set di dati BigQuery per archiviare il tuo modello ML.
Console
Nella console Google Cloud, vai alla pagina BigQuery.
Nel riquadro Explorer, fai clic sul nome del progetto.
Fai clic su Visualizza azioni > Crea set di dati.
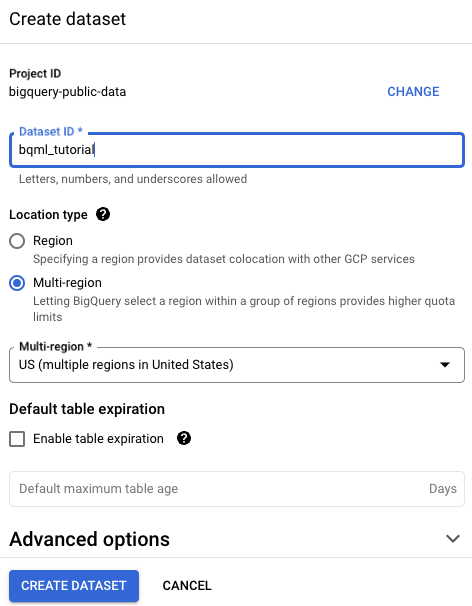
Nella pagina Crea set di dati:
In ID set di dati, inserisci
bqml_tutorial.Per Tipo di località, seleziona Più regioni e poi Stati Uniti (più regioni negli Stati Uniti).
I set di dati pubblici sono archiviati nella
USmultiregione. Per semplicità, archivia il tuo set di dati nella stessa posizione.- Lascia invariate le restanti impostazioni predefinite e fai clic su Crea set di dati.
bq
Per creare un nuovo set di dati, utilizza il comando
bq mk con il flag --location. Per un elenco completo dei possibili parametri, consulta la documentazione di riferimento del comando bq mk --dataset.
Crea un set di dati denominato
bqml_tutorialcon la posizione dei dati impostata suUSe una descrizione diBigQuery ML tutorial dataset:bq --location=US mk -d \ --description "BigQuery ML tutorial dataset." \ bqml_tutorial
Anziché utilizzare il flag
--dataset, il comando utilizza la scorciatoia-d. Se ometti-de--dataset, il comando crea per impostazione predefinita un set di dati.Verifica che il set di dati sia stato creato:
bq ls
API
Chiama il metodo datasets.insert con una risorsa set di dati definita.
{ "datasetReference": { "datasetId": "bqml_tutorial" } }
Addestra ed esegui il deployment di un modello di regressione logistica
Addestra il modello
Addestrare un modello di regressione logistica che preveda il tipo di iris utilizzando l'istruzione CREATE MODEL di BigQuery ML. Il completamento di questo job di addestramento dovrebbe richiedere circa un minuto.
bq query --use_legacy_sql=false \ 'CREATE MODEL `bqml_tutorial.iris_model` OPTIONS (model_type="logistic_reg", max_iterations=10, input_label_cols=["species"]) AS SELECT * FROM `bigquery-public-data.ml_datasets.iris`;'
Esporta il modello
Esporta il modello in un bucket Cloud Storage utilizzando lo strumento a riga di comando bq. Per altri modi per esportare i modelli, consulta Esportare i modelli BigQuery ML. Il completamento di questo job di estrazione dovrebbe richiedere meno di un minuto.
bq extract -m bqml_tutorial.iris_model gs://some/gcs/path/iris_model
Deployment e pubblicazione locale
Puoi eseguire il deployment dei modelli TensorFlow esportati utilizzando il container Docker di TensorFlow Serving. Per eseguire i passaggi che seguono, devi installare Docker.
Scarica i file del modello esportati in una directory temporanea
mkdir tmp_dir
gcloud storage cp gs://some/gcs/path/iris_model tmp_dir --recursive
Crea una sottodirectory della versione
Questo passaggio imposta un numero di versione (1 in questo caso) per il modello.
mkdir -p serving_dir/iris_model/1
cp -r tmp_dir/iris_model/* serving_dir/iris_model/1
rm -r tmp_dir
Esegui il pull dell'immagine Docker
docker pull tensorflow/serving
Esegui il container Docker
docker run -p 8500:8500 --network="host" --mount type=bind,source=`pwd`/serving_dir/iris_model,target=/models/iris_model -e MODEL_NAME=iris_model -t tensorflow/serving &
Esegui la previsione
curl -d '{"instances": [{"sepal_length":5.0, "sepal_width":2.0, "petal_length":3.5, "petal_width":1.0}]}' -X POST http://localhost:8501/v1/models/iris_model:predict
Deployment e pubblicazione online
Questa sezione utilizza Google Cloud CLI per eseguire il deployment e eseguire le previsioni sul modello esportato.
Per ulteriori dettagli sul deployment di un modello in AI Platform per le previsioni online/collettive, consulta Eseguire il deployment dei modelli.
Crea una risorsa modello
MODEL_NAME="IRIS_MODEL"
gcloud ai-platform models create $MODEL_NAME
Crea una versione del modello
1) Imposta le variabili di ambiente:
MODEL_DIR="gs://some/gcs/path/iris_model"
// Select a suitable version for this model
VERSION_NAME="v1"
FRAMEWORK="TENSORFLOW"
2) Crea la versione:
gcloud ai-platform versions create $VERSION_NAME --model=$MODEL_NAME --origin=$MODEL_DIR --runtime-version=1.15 --framework=$FRAMEWORK
Il completamento di questo passaggio potrebbe richiedere alcuni minuti. Dovresti vedere il messaggio
Creating version (this might take a few minutes).......
3) (Facoltativo) Visualizza le informazioni sulla nuova versione:
gcloud ai-platform versions describe $VERSION_NAME --model $MODEL_NAME
Dovresti visualizzare un output simile al seguente:
createTime: '2020-02-28T16:30:45Z'
deploymentUri: gs://your_bucket_name
framework: TENSORFLOW
machineType: mls1-c1-m2
name: projects/[YOUR-PROJECT-ID]/models/IRIS_MODEL/versions/v1
pythonVersion: '2.7'
runtimeVersion: '1.15'
state: READY
Previsione online
I dettagli sull'esecuzione di previsioni online su un modello di cui è stato eseguito il deployment sono disponibili in Richiedere previsioni.
1) Crea un file JSON delimitato da un carattere di nuova riga per gli input, ad esempio il file instances.json con i seguenti contenuti:
{"sepal_length":5.0, "sepal_width":2.0, "petal_length":3.5, "petal_width":1.0}
{"sepal_length":5.3, "sepal_width":3.7, "petal_length":1.5, "petal_width":0.2}
2) Configura le variabili di ambiente per la previsione:
INPUT_DATA_FILE="instances.json"
3) Esegui la previsione:
gcloud ai-platform predict --model $MODEL_NAME --version $VERSION_NAME --json-instances $INPUT_DATA_FILE
Addestra ed esegui il deployment di un modello di classificazione ad albero con boosting
Addestra il modello
Addestra un modello di classificazione ad albero con boosting che prevede il tipo di iris utilizzando l'istruzione
CREATE MODEL. Il completamento di questo job di addestramento dovrebbe richiedere circa 7 minuti.
bq query --use_legacy_sql=false \ 'CREATE MODEL `bqml_tutorial.boosted_tree_iris_model` OPTIONS (model_type="boosted_tree_classifier", max_iterations=10, input_label_cols=["species"]) AS SELECT * FROM `bigquery-public-data.ml_datasets.iris`;'
Esporta il modello
Esporta il modello in un bucket Cloud Storage utilizzando lo strumento a riga di comando bq. Per altri modi per esportare i modelli, consulta Esportare i modelli BigQuery ML.
bq extract --destination_format ML_XGBOOST_BOOSTER -m bqml_tutorial.boosted_tree_iris_model gs://some/gcs/path/boosted_tree_iris_model
Deployment e pubblicazione locale
Nei file esportati è presente un file main.py per l'esecuzione locale.
Scarica i file del modello esportati in una directory locale
mkdir serving_dir
gcloud storage cp gs://some/gcs/path/boosted_tree_iris_model serving_dir --recursive
Predictor di estrazione
tar -xvf serving_dir/boosted_tree_iris_model/xgboost_predictor-0.1.tar.gz -C serving_dir/boosted_tree_iris_model/
Installa la libreria XGBoost
Installa la libreria XGBoost, versione 0.82 o successive.
Esegui la previsione
cd serving_dir/boosted_tree_iris_model/
python main.py '[{"sepal_length":5.0, "sepal_width":2.0, "petal_length":3.5, "petal_width":1.0}]'
Deployment e pubblicazione online
Questa sezione utilizza Google Cloud CLI per eseguire il deployment e eseguire le previsioni sul modello esportato in AI Platform Prediction online.
Per ulteriori dettagli sul deployment di un modello in AI Platform per le predizioni online/collettive utilizzando routine personalizzate, consulta Eseguire il deployment dei modelli.
Crea una risorsa modello
MODEL_NAME="BOOSTED_TREE_IRIS_MODEL"
gcloud ai-platform models create $MODEL_NAME
Crea una versione del modello
1) Imposta le variabili di ambiente:
MODEL_DIR="gs://some/gcs/path/boosted_tree_iris_model"
VERSION_NAME="v1"
2) Crea la versione:
gcloud beta ai-platform versions create $VERSION_NAME --model=$MODEL_NAME --origin=$MODEL_DIR --package-uris=${MODEL_DIR}/xgboost_predictor-0.1.tar.gz --prediction-class=predictor.Predictor --runtime-version=1.15
Il completamento di questo passaggio potrebbe richiedere alcuni minuti. Dovresti vedere il messaggio
Creating version (this might take a few minutes).......
3) (Facoltativo) Visualizza le informazioni sulla nuova versione:
gcloud ai-platform versions describe $VERSION_NAME --model $MODEL_NAME
Dovresti visualizzare un output simile al seguente:
createTime: '2020-02-07T00:35:42Z'
deploymentUri: gs://some/gcs/path/boosted_tree_iris_model
etag: rp090ebEnQk=
machineType: mls1-c1-m2
name: projects/[YOUR-PROJECT-ID]/models/BOOSTED_TREE_IRIS_MODEL/versions/v1
packageUris:
- gs://some/gcs/path/boosted_tree_iris_model/xgboost_predictor-0.1.tar.gz
predictionClass: predictor.Predictor
pythonVersion: '2.7'
runtimeVersion: '1.15'
state: READY
Previsione online
Per maggiori dettagli sull'esecuzione di previsioni online su un modello di cui è stato eseguito il deployment, consulta Richiedere previsioni.
1) Crea un file JSON delimitato da nuova riga per gli input. Ad esempio, un file instances.json con i seguenti contenuti:
{"sepal_length":5.0, "sepal_width":2.0, "petal_length":3.5, "petal_width":1.0}
{"sepal_length":5.3, "sepal_width":3.7, "petal_length":1.5, "petal_width":0.2}
2) Configura le variabili di ambiente per la previsione:
INPUT_DATA_FILE="instances.json"
3) Esegui la previsione:
gcloud ai-platform predict --model $MODEL_NAME --version $VERSION_NAME --json-instances $INPUT_DATA_FILE
Addestra ed esegui il deployment di un modello di classificazione AutoML
Addestra il modello
Addestra un modello di classificazione AutoML che preveda il tipo di iris utilizzando l'istruzione
CREATE MODEL. I modelli AutoML richiedono almeno 1000 righe di dati di input. Poiché
ml_datasets.iris ha solo 150 righe, duplichiamo i dati 10 volte. Il completamento di questo job di addestramento dovrebbe richiedere circa 2 ore.
bq query --use_legacy_sql=false \ 'CREATE MODEL `bqml_tutorial.automl_iris_model` OPTIONS (model_type="automl_classifier", budget_hours=1, input_label_cols=["species"]) AS SELECT * EXCEPT(multiplier) FROM `bigquery-public-data.ml_datasets.iris`, unnest(GENERATE_ARRAY(1, 10)) as multiplier;'
Esporta il modello
Esporta il modello in un bucket Cloud Storage utilizzando lo strumento a riga di comando bq. Per altri modi per esportare i modelli, consulta Esportare i modelli BigQuery ML.
bq extract -m bqml_tutorial.automl_iris_model gs://some/gcs/path/automl_iris_model
Deployment e pubblicazione locale
Per informazioni dettagliate sulla creazione di container AutoML, consulta Esportazione dei modelli. I passaggi che seguono richiedono l'installazione di Docker.
Copiare i file del modello esportati in una directory locale
mkdir automl_serving_dir
gcloud storage cp gs://some/gcs/path/automl_iris_model/* automl_serving_dir/ --recursive
Esegui il pull dell'immagine Docker di AutoML
docker pull gcr.io/cloud-automl-tables-public/model_server
Avvia il container Docker
docker run -v `pwd`/automl_serving_dir:/models/default/0000001 -p 8080:8080 -it gcr.io/cloud-automl-tables-public/model_server
Esegui la previsione
1) Crea un file JSON delimitato da nuova riga per gli input. Ad esempio, un file input.json con i seguenti contenuti:
{"instances": [{"sepal_length":5.0, "sepal_width":2.0, "petal_length":3.5, "petal_width":1.0},
{"sepal_length":5.3, "sepal_width":3.7, "petal_length":1.5, "petal_width":0.2}]}
2) Esegui la chiamata di previsione:
curl -X POST --data @input.json http://localhost:8080/predict
Deployment e pubblicazione online
La previsione online per i modelli di classificazione e di regressione AutoML non è supportata in AI Platform.
Esegui la pulizia
Per evitare che al tuo account Google Cloud vengano addebitati costi relativi alle risorse utilizzate in questo tutorial, elimina il progetto che contiene le risorse oppure mantieni il progetto ed elimina le singole risorse.
- Puoi eliminare il progetto che hai creato.
- In alternativa, puoi conservare il progetto ed eliminare il set di dati e il bucket Cloud Storage.
Interrompi il container Docker
1) Elenca tutti i container Docker in esecuzione.
docker ps
2) Interrompi il contenitore con l'ID contenitore applicabile dall'elenco dei contenitori.
docker stop container_id
Eliminare le risorse di AI Platform
1) Elimina la versione del modello.
gcloud ai-platform versions delete $VERSION_NAME --model=$MODEL_NAME
2) Elimina il modello.
gcloud ai-platform models delete $MODEL_NAME
Eliminare il set di dati
L'eliminazione del progetto rimuove tutti i set di dati e tutte le tabelle nel progetto. Se preferisci riutilizzare il progetto, puoi eliminare il set di dati creato in questo tutorial:
Se necessario, apri la pagina BigQuery nella console Google Cloud.
Nella barra di navigazione, fai clic sul set di dati bqml_tutorial che hai creato.
Fai clic su Elimina set di dati sul lato destro della finestra. Questa azione elimina il set di dati, la tabella e tutti i dati.
Nella finestra di dialogo Elimina set di dati, conferma il comando di eliminazione digitando il nome del set di dati (
bqml_tutorial) e fai clic su Elimina.
Elimina il bucket Cloud Storage
L'eliminazione del progetto rimuove tutti i bucket Cloud Storage al suo interno. Se preferisci riutilizzare il progetto, puoi eliminare il bucket creato in questo tutorial
- Nella console Google Cloud, vai alla pagina Bucket in Cloud Storage.
Seleziona la casella di controllo del bucket da eliminare.
Fai clic su Elimina.
Nella finestra in overlay visualizzata, conferma di voler eliminare il bucket e i relativi contenuti facendo clic su Elimina.
Elimina il progetto
Per eliminare il progetto:
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
Passaggi successivi
- Per una panoramica di BigQuery ML, consulta Introduzione a BigQuery ML.
- Per informazioni sull'esportazione dei modelli, consulta Esportare i modelli.
- Per informazioni sulla creazione dei modelli, consulta la pagina della sintassi di
CREATE MODEL.