Este documento fornece informações gerais sobre a privacidade diferencial para o BigQuery. Para ver a sintaxe, consulte a cláusula de privacidade diferencial. Para ver uma lista das funções que pode usar com esta sintaxe, consulte as funções agregadas diferencialmente privadas.
O que é a privacidade diferencial?
A privacidade diferencial é uma norma para cálculos sobre dados que limita as informações pessoais reveladas por um resultado. A privacidade diferencial é usada frequentemente para partilhar dados e permitir inferências sobre grupos de pessoas ao mesmo tempo que impede que alguém aprenda informações sobre um indivíduo.
A privacidade diferencial é útil:
- Quando existe um risco de reidentificação.
- Para quantificar a compensação entre o risco e a utilidade analítica.
Para compreender melhor a privacidade diferencial, vamos analisar um exemplo simples.
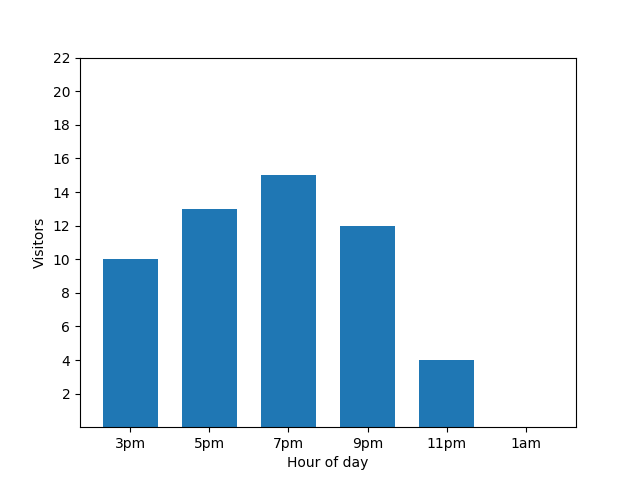
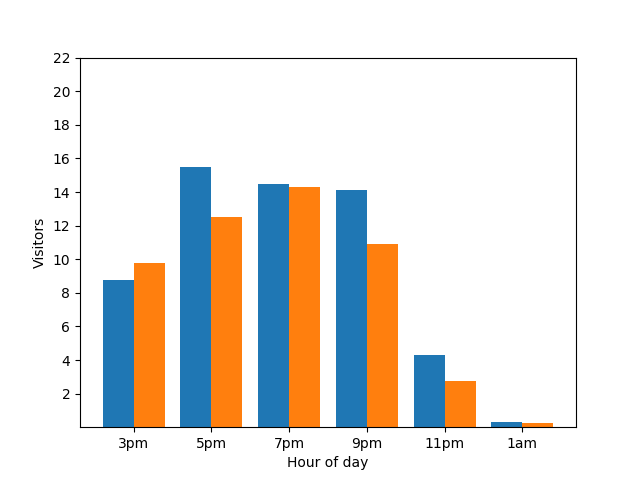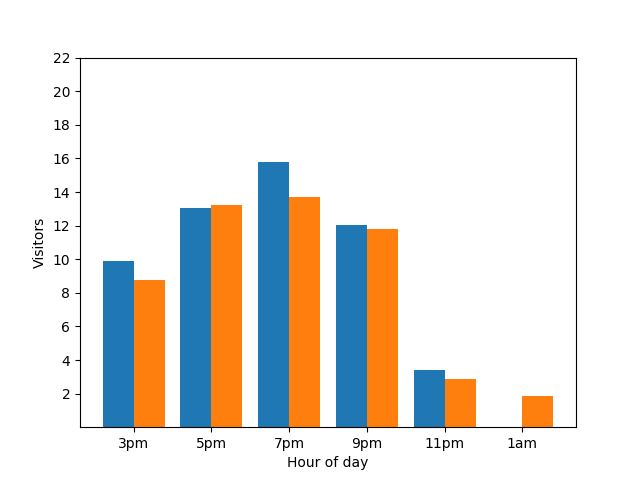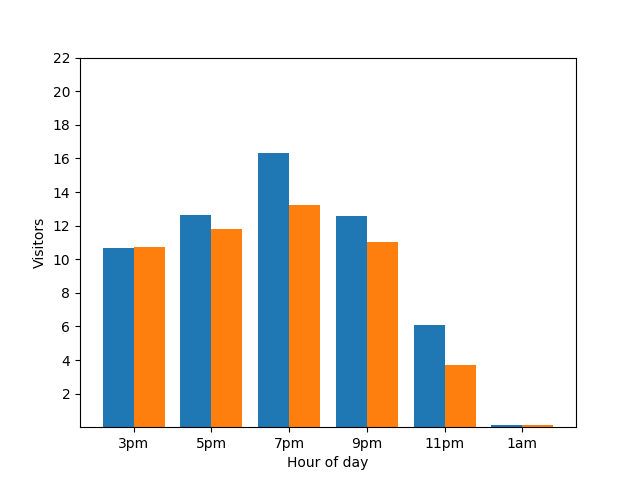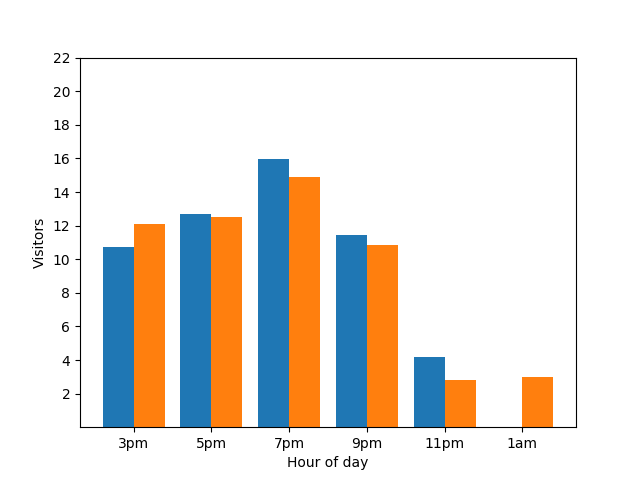
Este gráfico de barras mostra a afluência de um pequeno restaurante numa noite específica. Muitos hóspedes chegam às 19:00 e o restaurante está completamente vazio às 01:00:
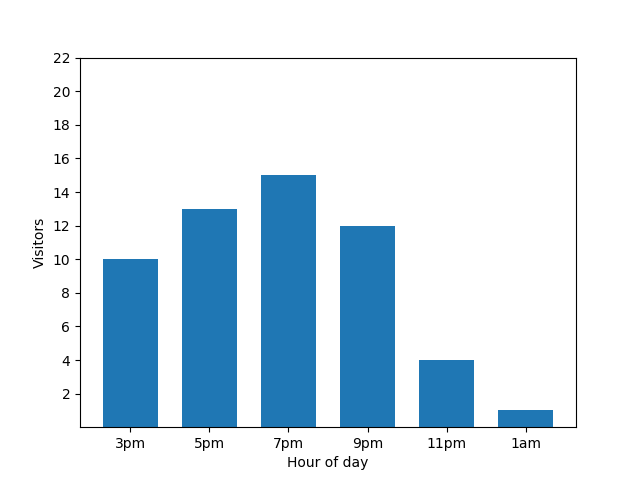
Este gráfico parece útil, mas tem um senão. Quando chega um novo hóspede, este facto é imediatamente revelado pelo gráfico de barras. No gráfico seguinte, é claro que existe um novo hóspede e que este chegou aproximadamente às 01:00:
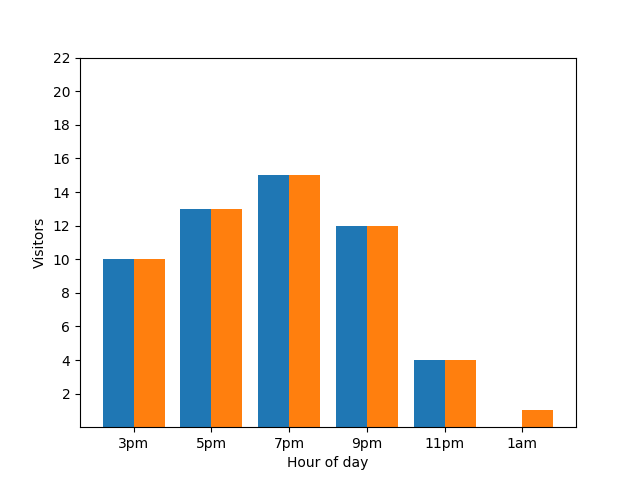
A apresentação deste detalhe não é ideal do ponto de vista da privacidade, uma vez que as estatísticas anónimas não devem revelar contribuições individuais. A colocação destes dois gráficos lado a lado torna ainda mais evidente que o gráfico de barras laranja tem mais um hóspede que chegou por volta da 1: 00:
Mais uma vez, isso não é bom. Para evitar este tipo de problema de privacidade, pode adicionar ruído aleatório aos gráficos de barras através da privacidade diferencial. No gráfico de comparação seguinte, os resultados são anónimos e deixam de revelar as contribuições individuais.
Como funciona a privacidade diferencial nas consultas
O objetivo da privacidade diferencial é mitigar o risco de divulgação, ou seja, de que alguém possa saber informações sobre uma entidade num conjunto de dados. A privacidade diferencial equilibra a necessidade de salvaguardar a privacidade com a necessidade de utilidade analítica estatística. À medida que a privacidade aumenta, a utilidade analítica estatística diminui e vice-versa.
Com o GoogleSQL para BigQuery, pode transformar os resultados de uma consulta com agregações diferencialmente privadas. Quando a consulta é executada, realiza o seguinte:
- Calcula agregações por entidade para cada grupo se os grupos forem especificados com uma cláusula
GROUP BY. Limita o número de grupos para os quais cada entidade pode contribuir, com base no parâmetro de privacidade diferencialmax_groups_contributed. - Restringe cada contribuição agregada por entidade a estar dentro dos limites de restrição. Se os limites de restrição não forem especificados, são calculados implicitamente de forma diferencialmente privada.
- Agrega as contribuições agregadas por entidade restritas para cada grupo.
- Adiciona ruído ao valor agregado final de cada grupo. A escala do ruído aleatório é uma função de todos os limites restringidos e parâmetros de privacidade.
- Calcula uma contagem de entidades com ruído para cada grupo e elimina os grupos com poucas entidades. Uma contagem de entidades com ruído ajuda a eliminar um conjunto não determinístico de grupos.
O resultado final é um conjunto de dados em que cada grupo tem resultados agregados com ruído e os grupos pequenos foram eliminados.
Para ver contexto adicional sobre o que é a privacidade diferencial e os respetivos exemplos de utilização, consulte os seguintes artigos:
- Uma introdução simples e não técnica à privacidade diferencial
- SQL diferencialmente privado com contribuição do utilizador limitada
- Privacidade diferencial na Wikipédia
Produza uma consulta diferencialmente privada válida
As seguintes regras têm de ser cumpridas para que a consulta com privacidade diferencial seja válida:
- É definida uma coluna de unidade de privacidade.
- A lista
SELECTcontém uma cláusula de privacidade diferencial. - Apenas as funções agregadas com privacidade diferencial estão na lista
SELECTcom a cláusula de privacidade diferencial.
Defina uma coluna de unidade de privacidade
Uma unidade de privacidade é a entidade num conjunto de dados que está a ser protegida através da privacidade diferencial. Uma entidade pode ser um indivíduo, uma empresa, uma localização ou qualquer coluna que escolher.
Uma consulta com privacidade diferencial tem de incluir uma e apenas uma coluna de unidade de privacidade. Uma coluna de unidade de privacidade é um identificador exclusivo de uma unidade de privacidade e pode existir em vários grupos. Uma vez que são suportados vários grupos, o tipo de dados da coluna de unidade de privacidade tem de ser agrupável.
Pode definir uma coluna de unidade de privacidade na cláusula OPTIONS de uma cláusula de privacidade diferencial com o identificador exclusivo privacy_unit_column.
Nos exemplos seguintes, é adicionada uma coluna de unidade de privacidade a uma cláusula de privacidade diferencial. id representa uma coluna com origem numa tabela denominada students.
SELECT WITH DIFFERENTIAL_PRIVACY
OPTIONS (epsilon=10, delta=.01, privacy_unit_column=id)
item,
COUNT(*, contribution_bounds_per_group=>(0, 100))
FROM students;
SELECT WITH DIFFERENTIAL_PRIVACY
OPTIONS (epsilon=10, delta=.01, privacy_unit_column=members.id)
item,
COUNT(*, contribution_bounds_per_group=>(0, 100))
FROM (SELECT * FROM students) AS members;
Remova o ruído de uma consulta diferencialmente privada
Na referência "Sintaxe de consulta", consulte Remover ruído.
Adicione ruído a uma consulta diferencialmente privada
Na referência "Sintaxe de consulta", consulte Adicionar ruído.
Limite os grupos nos quais um ID de unidade de privacidade pode existir
Na referência "Sintaxe de consulta", consulte o artigo Limite os grupos nos quais um ID de unidade de privacidade pode existir.
Limitações
Esta secção descreve as limitações da privacidade diferencial.
Implicações de desempenho da privacidade diferencial
As consultas com privacidade diferencial são executadas mais lentamente do que as consultas padrão, porque é realizada a agregação por entidade e é aplicada a limitação max_groups_contributed. Limitar os limites de contribuição pode ajudar a melhorar o desempenho das suas consultas com privacidade diferencial.
Os perfis de desempenho das seguintes consultas não são semelhantes:
SELECT
WITH DIFFERENTIAL_PRIVACY OPTIONS(epsilon=1, delta=1e-10, privacy_unit_column=id)
column_a, COUNT(column_b)
FROM table_a
GROUP BY column_a;
SELECT column_a, COUNT(column_b)
FROM table_a
GROUP BY column_a;
O motivo da diferença de desempenho é que é realizado um nível de agrupamento de granularidade mais fino para consultas com privacidade diferencial, porque também tem de ser realizada a agregação por entidade.
Os perfis de desempenho das seguintes consultas devem ser semelhantes, embora a consulta com privacidade diferencial seja ligeiramente mais lenta:
SELECT
WITH DIFFERENTIAL_PRIVACY OPTIONS(epsilon=1, delta=1e-10, privacy_unit_column=id)
column_a, COUNT(column_b)
FROM table_a
GROUP BY column_a;
SELECT column_a, id, COUNT(column_b)
FROM table_a
GROUP BY column_a, id;
A consulta com privacidade diferencial tem um desempenho mais lento porque tem um número elevado de valores distintos para a coluna da unidade de privacidade.
Limitações de delimitação implícitas para conjuntos de dados pequenos
A restrição implícita funciona melhor quando é calculada com grandes conjuntos de dados. A restrição implícita pode falhar com conjuntos de dados que contêm um número reduzido de unidades de privacidade, não devolvendo resultados. Além disso, a limitação implícita num conjunto de dados com um número reduzido de unidades de privacidade pode restringir uma grande parte dos valores não atípicos, o que leva a agregações subnotificadas e resultados mais alterados pela restrição do que pelo ruído adicionado. Os conjuntos de dados que têm um número reduzido de unidades de privacidade ou estão divididos de forma superficial devem usar a restrição explícita em vez da implícita.
Vulnerabilidades de privacidade
Qualquer algoritmo de privacidade diferencial, incluindo este, incorre no risco de uma fuga de dados privados quando um analista age de má-fé, especialmente quando calcula estatísticas básicas, como somas, devido a limitações aritméticas.
Limitações das garantias de privacidade
Embora a privacidade diferencial do BigQuery aplique o algoritmo de privacidade diferencial, não oferece uma garantia relativamente às propriedades de privacidade do conjunto de dados resultante.
Erros de tempo de execução
Um analista que atue de má-fé com a capacidade de escrever consultas ou controlar dados de entrada pode acionar um erro de tempo de execução em dados privados.
Ruído de vírgula flutuante
As vulnerabilidades relacionadas com o arredondamento, o arredondamento repetido e os ataques de reordenação devem ser consideradas antes de usar a privacidade diferencial. Estas vulnerabilidades são particularmente preocupantes quando um atacante pode controlar alguns dos conteúdos de um conjunto de dados ou a ordem dos conteúdos num conjunto de dados.
As adições de ruído diferencialmente privadas em tipos de dados de vírgula flutuante estão sujeitas às vulnerabilidades descritas no artigo Widespread Underestimation of Sensitivity in Differentially Private Libraries and How to Fix It. As adições de ruído em tipos de dados inteiros não estão sujeitas às vulnerabilidades descritas no artigo.
Riscos de ataques de temporização
Um analista que atue de má-fé pode executar uma consulta suficientemente complexa para fazer uma inferência sobre os dados de entrada com base na duração da execução de uma consulta.
Classificação incorreta
A criação de uma consulta de privacidade diferencial pressupõe que os seus dados estão numa estrutura bem conhecida e compreendida. Se aplicar a privacidade diferencial aos identificadores errados, como um que represente um ID da transação em vez do ID de um indivíduo, pode expor dados confidenciais.
Se precisar de ajuda para compreender os seus dados, considere usar serviços e ferramentas como os seguintes:
Preços
Não existe custo adicional para usar a privacidade diferencial, mas aplica-se a preçário do BigQuery padrão para análise.