Create datasets
This document describes how to create datasets in BigQuery.
You can create datasets in the following ways:
- Using the Google Cloud console.
- Using a SQL query.
- Using the
bq mkcommand in the bq command-line tool. - Calling the
datasets.insertAPI method. - Using the client libraries.
- Copying an existing dataset.
To see steps for copying a dataset, including across regions, see Copying datasets.
This document describes how to work with regular datasets that store data in BigQuery. To learn how to work with Spanner external datasets see Create Spanner external datasets. To learn how to work with AWS Glue federated datasets see Create AWS Glue federated datasets.
To learn to query tables in a public dataset, see Query a public dataset with the Google Cloud console.
Dataset limitations
BigQuery datasets are subject to the following limitations:
- The dataset location can only be set at creation time. After a dataset is created, its location cannot be changed.
- All tables that are referenced in a query must be stored in datasets in the same location.
External datasets don't support table expiration, replicas, time travel, default collation, default rounding mode, or the option to enable or disable case-insensitive table names.
When you copy a table, the datasets that contain the source table and destination table must reside in the same location.
Dataset names must be unique for each project.
If you change a dataset's storage billing model, you must wait 14 days before you can change the storage billing model again.
You can't enroll a dataset in physical storage billing if you have any existing legacy flat-rate slot commitments located in the same region as the dataset.
Before you begin
Grant Identity and Access Management (IAM) roles that give users the necessary permissions to perform each task in this document.
Required permissions
To create a dataset, you need the bigquery.datasets.create
IAM permission.
Each of the following predefined IAM roles includes the permissions that you need in order to create a dataset:
roles/bigquery.dataEditorroles/bigquery.dataOwnerroles/bigquery.userroles/bigquery.admin
For more information about IAM roles in BigQuery, see Predefined roles and permissions.
Create datasets
To create a dataset:
Console
- Open the BigQuery page in the Google Cloud console. Go to the BigQuery page
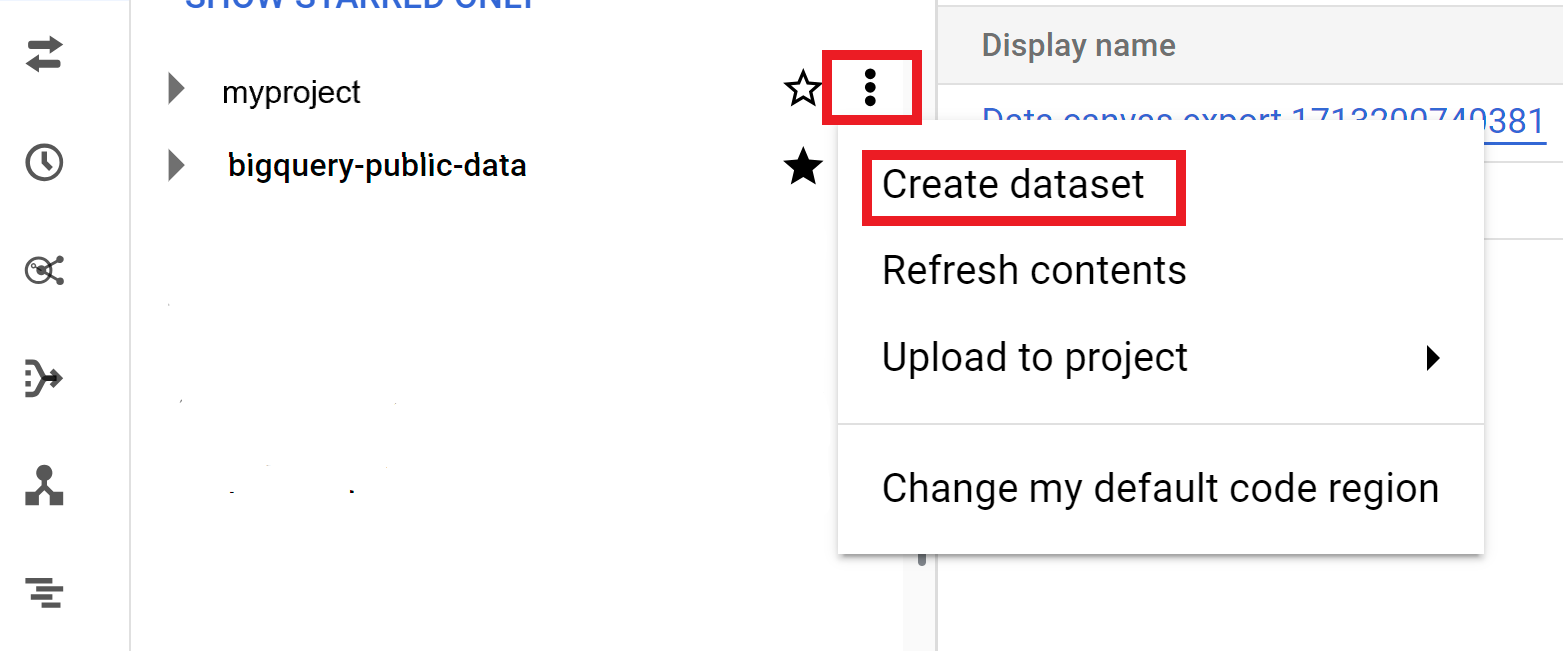
- In the left pane, click Explorer.
- Select the project where you want to create the dataset.
- Click View actions, and then click Create dataset.
- On the Create dataset page:
- For Dataset ID, enter a unique dataset name.
- For Location type, choose a geographic location for the dataset. After a dataset is created, the location can't be changed.
- Optional: Select Link to an external dataset if you're creating an external dataset.
- If you don't need to configure additional options such as tags and table expirations, click Create dataset. Otherwise, expand the following section to configure the additional dataset options.
- Optional: Expand the Tags section to add tags to your dataset.
- To apply an existing tag, do the following:
- Click the drop-down arrow beside Select scope and choose Current scope—Select current organization or Select current project.
- For Key 1 and Value 1, choose the appropriate values from the lists.
- To manually enter a new tag, do the following:
- Click the drop-down arrow beside Select a scope and choose Manually enter IDs > Organization, Project, or Tags.
- If you're creating a tag for your project or organization,
in the dialog, enter the
PROJECT_IDor theORGANIZATION_ID, and then click Save. - For Key 1 and Value 1, choose the appropriate values from the lists.
- To add additional tags to the table, click Add tag and follow the previous steps.
- Optional: Expand the Advanced options section to configure one or more of the following options.
- To change the Encryption option to use your own cryptographic key with the Cloud Key Management Service, select Cloud KMS key.
- To use case-insensitive table names, select Enable case insensitive table names.
- To change the Default collation specification, choose the collation type from the list.
- To set an expiration for tables in the dataset, select Enable table expiration, then specify the Default maximum table age in days.
- To set a Default rounding mode, choose the rounding mode from the list.
- To enable the physical Storage billing model, choose the billing model from the list.
- To set the dataset's time travel window, choose the window size from the list.
- Click Create dataset.
Additional options for datasets
Alternatively, click Select scope to search for a resource or to see a list of current resources.
When you change a dataset's billing model, it takes 24 hours for the change to take effect.
Once you change a dataset's storage billing model, you must wait 14 days before you can change the storage billing model again.
SQL
Use the
CREATE SCHEMA statement.
To create a dataset in a project other than your default project, add the
project ID to the dataset ID in the following format:
PROJECT_ID.DATASET_ID.
In the Google Cloud console, go to the BigQuery page.
In the query editor, enter the following statement:
CREATE SCHEMA PROJECT_ID.DATASET_ID OPTIONS ( default_kms_key_name = 'KMS_KEY_NAME', default_partition_expiration_days = PARTITION_EXPIRATION, default_table_expiration_days = TABLE_EXPIRATION, description = 'DESCRIPTION', labels = [('KEY_1','VALUE_1'),('KEY_2','VALUE_2')], location = 'LOCATION', max_time_travel_hours = HOURS, storage_billing_model = BILLING_MODEL);
Replace the following:
PROJECT_ID: your project IDDATASET_ID: the ID of the dataset that you're creatingKMS_KEY_NAME: the name of the default Cloud Key Management Service key used to protect newly created tables in this dataset unless a different key is supplied at the time of creation. You cannot create a Google-encrypted table in a dataset with this parameter set.PARTITION_EXPIRATION: the default lifetime (in days) for partitions in newly created partitioned tables. The default partition expiration has no minimum value. The expiration time evaluates to the partition's date plus the integer value. Any partition created in a partitioned table in the dataset is deletedPARTITION_EXPIRATIONdays after the partition's date. If you supply thetime_partitioning_expirationoption when you create or update a partitioned table, the table-level partition expiration takes precedence over the dataset-level default partition expiration.TABLE_EXPIRATION: the default lifetime (in days) for newly created tables. The minimum value is 0.042 days (one hour). The expiration time evaluates to the current time plus the integer value. Any table created in the dataset is deletedTABLE_EXPIRATIONdays after its creation time. This value is applied if you do not set a table expiration when you create the table.DESCRIPTION: a description of the datasetKEY_1:VALUE_1: the key-value pair that you want to set as the first label on this datasetKEY_2:VALUE_2: the key-value pair that you want to set as the second labelLOCATION: the dataset's location. After a dataset is created, the location can't be changed.HOURS: the duration in hours of the time travel window for the new dataset. TheHOURSvalue must be an integer expressed in multiples of 24 (48, 72, 96, 120, 144, 168) between 48 (2 days) and 168 (7 days). 168 hours is the default if this option isn't specified.BILLING_MODEL: sets the storage billing model for the dataset. Set theBILLING_MODELvalue toPHYSICALto use physical bytes when calculating storage charges, or toLOGICALto use logical bytes.LOGICALis the default.When you change a dataset's billing model, it takes 24 hours for the change to take effect.
Once you change a dataset's storage billing model, you must wait 14 days before you can change the storage billing model again.
Click Run.
For more information about how to run queries, see Run an interactive query.
bq
To create a new dataset, use the
bq mk command
with the --location flag. For a full list of possible parameters, see the
bq mk --dataset command
reference.
To create a dataset in a project other than your default project, add the
project ID to the dataset name in the following format:
PROJECT_ID:DATASET_ID.
bq --location=LOCATION mk \ --dataset \ --default_kms_key=KMS_KEY_NAME \ --default_partition_expiration=PARTITION_EXPIRATION \ --default_table_expiration=TABLE_EXPIRATION \ --description="DESCRIPTION" \ --label=KEY_1:VALUE_1 \ --label=KEY_2:VALUE_2 \ --add_tags=KEY_3:VALUE_3[,...] \ --max_time_travel_hours=HOURS \ --storage_billing_model=BILLING_MODEL \ PROJECT_ID:DATASET_ID
Replace the following:
LOCATION: the dataset's location. After a dataset is created, the location can't be changed. You can set a default value for the location by using the.bigqueryrcfile.KMS_KEY_NAME: the name of the default Cloud Key Management Service key used to protect newly created tables in this dataset unless a different key is supplied at the time of creation. You cannot create a Google-encrypted table in a dataset with this parameter set.PARTITION_EXPIRATION: the default lifetime (in seconds) for partitions in newly created partitioned tables. The default partition expiration has no minimum value. The expiration time evaluates to the partition's date plus the integer value. Any partition created in a partitioned table in the dataset is deletedPARTITION_EXPIRATIONseconds after the partition's date. If you supply the--time_partitioning_expirationflag when you create or update a partitioned table, the table-level partition expiration takes precedence over the dataset-level default partition expiration.TABLE_EXPIRATION: the default lifetime (in seconds) for newly created tables. The minimum value is 3600 seconds (one hour). The expiration time evaluates to the current time plus the integer value. Any table created in the dataset is deletedTABLE_EXPIRATIONseconds after its creation time. This value is applied if you don't set a table expiration when you create the table.DESCRIPTION: a description of the datasetKEY_1:VALUE_1: the key-value pair that you want to set as the first label on this dataset, andKEY_2:VALUE_2is the key-value pair that you want to set as the second label.KEY_3:VALUE_3: the key-value pair that you want to set as a tag on the dataset. Add multiple tags under the same flag with commas between key:value pairs.HOURS: the duration in hours of the time travel window for the new dataset. TheHOURSvalue must be an integer expressed in multiples of 24 (48, 72, 96, 120, 144, 168) between 48 (2 days) and 168 (7 days). 168 hours is the default if this option isn't specified.BILLING_MODEL: sets the storage billing model for the dataset. Set theBILLING_MODELvalue toPHYSICALto use physical bytes when calculating storage charges, or toLOGICALto use logical bytes.LOGICALis the default.When you change a dataset's billing model, it takes 24 hours for the change to take effect.
Once you change a dataset's storage billing model, you must wait 14 days before you can change the storage billing model again.
PROJECT_ID: your project ID.DATASET_IDis the ID of the dataset that you're creating.
For example, the following command creates a dataset named mydataset with data
location set to US, a default table expiration of 3600 seconds (1 hour), and a
description of This is my dataset. Instead of using the --dataset flag, the
command uses the -d shortcut. If you omit -d and --dataset, the command
defaults to creating a dataset.
bq --location=US mk -d \ --default_table_expiration 3600 \ --description "This is my dataset." \ mydataset
To confirm that the dataset was created, enter the bq ls command. Also,
you can create a table when you create a new dataset using the
following format: bq mk -t dataset.table.
For more information about creating tables, see
Creating a table.
Terraform
Use the
google_bigquery_dataset
resource.
To authenticate to BigQuery, set up Application Default Credentials. For more information, see Set up authentication for client libraries.
Create a dataset
The following example creates a dataset named mydataset:
When you create a dataset using the google_bigquery_dataset resource,
it automatically grants access to the dataset to all accounts that are
members of project-level basic roles.
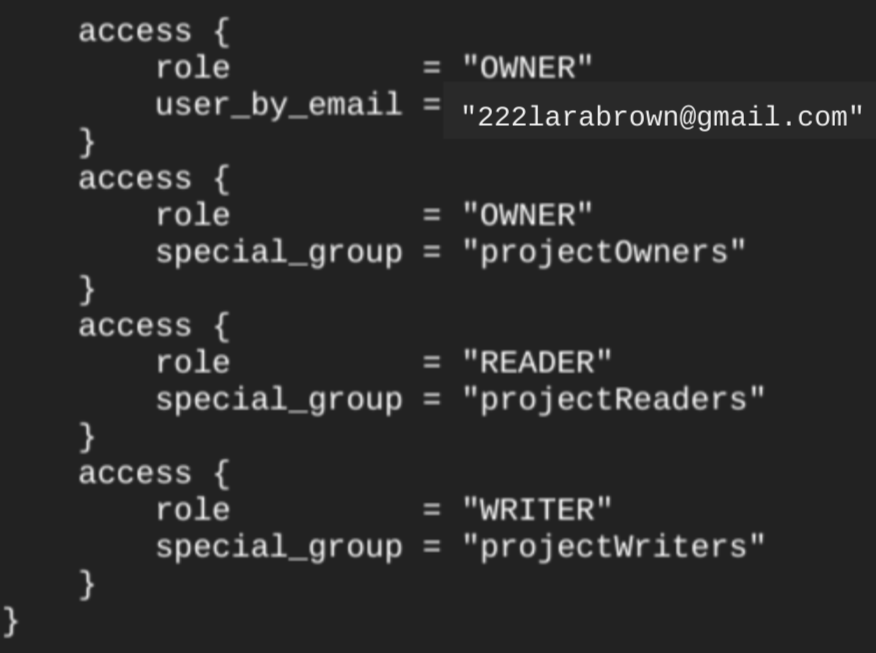
If you run the
terraform show command
after creating the dataset, the
access block for the dataset looks similar to the
following:
To grant access to the dataset, we recommend that you use one of the
google_bigquery_iam resources, as shown in the following example, unless you plan
to create authorized objects, such as
authorized views, within the dataset.
In that case, use the
google_bigquery_dataset_access resource. Refer to that documentation for examples.
Create a dataset and grant access to it
The following example creates a dataset named mydataset, then uses the
google_bigquery_dataset_iam_policy resource to grant
access to it.
Create a dataset with a customer-managed encryption key
The following example creates a dataset named mydataset, and also uses the
google_kms_crypto_key
and
google_kms_key_ring
resources to specify a Cloud Key Management Service key for the dataset. You must
enable the Cloud Key Management Service API before running this example.
To apply your Terraform configuration in a Google Cloud project, complete the steps in the following sections.
Prepare Cloud Shell
- Launch Cloud Shell.
-
Set the default Google Cloud project where you want to apply your Terraform configurations.
You only need to run this command once per project, and you can run it in any directory.
export GOOGLE_CLOUD_PROJECT=PROJECT_ID
Environment variables are overridden if you set explicit values in the Terraform configuration file.
Prepare the directory
Each Terraform configuration file must have its own directory (also called a root module).
-
In Cloud Shell, create a directory and a new
file within that directory. The filename must have the
.tfextension—for examplemain.tf. In this tutorial, the file is referred to asmain.tf.mkdir DIRECTORY && cd DIRECTORY && touch main.tf
-
If you are following a tutorial, you can copy the sample code in each section or step.
Copy the sample code into the newly created
main.tf.Optionally, copy the code from GitHub. This is recommended when the Terraform snippet is part of an end-to-end solution.
- Review and modify the sample parameters to apply to your environment.
- Save your changes.
-
Initialize Terraform. You only need to do this once per directory.
terraform init
Optionally, to use the latest Google provider version, include the
-upgradeoption:terraform init -upgrade
Apply the changes
-
Review the configuration and verify that the resources that Terraform is going to create or
update match your expectations:
terraform plan
Make corrections to the configuration as necessary.
-
Apply the Terraform configuration by running the following command and entering
yesat the prompt:terraform apply
Wait until Terraform displays the "Apply complete!" message.
- Open your Google Cloud project to view the results. In the Google Cloud console, navigate to your resources in the UI to make sure that Terraform has created or updated them.
API
Call the datasets.insert
method with a defined dataset resource.
C#
Before trying this sample, follow the C# setup instructions in the BigQuery quickstart using client libraries. For more information, see the BigQuery C# API reference documentation.
To authenticate to BigQuery, set up Application Default Credentials. For more information, see Set up authentication for client libraries.
Go
Before trying this sample, follow the Go setup instructions in the BigQuery quickstart using client libraries. For more information, see the BigQuery Go API reference documentation.
To authenticate to BigQuery, set up Application Default Credentials. For more information, see Set up authentication for client libraries.
Java
Before trying this sample, follow the Java setup instructions in the BigQuery quickstart using client libraries. For more information, see the BigQuery Java API reference documentation.
To authenticate to BigQuery, set up Application Default Credentials. For more information, see Set up authentication for client libraries.
Node.js
Before trying this sample, follow the Node.js setup instructions in the BigQuery quickstart using client libraries. For more information, see the BigQuery Node.js API reference documentation.
To authenticate to BigQuery, set up Application Default Credentials. For more information, see Set up authentication for client libraries.
PHP
Before trying this sample, follow the PHP setup instructions in the BigQuery quickstart using client libraries. For more information, see the BigQuery PHP API reference documentation.
To authenticate to BigQuery, set up Application Default Credentials. For more information, see Set up authentication for client libraries.
Python
Before trying this sample, follow the Python setup instructions in the BigQuery quickstart using client libraries. For more information, see the BigQuery Python API reference documentation.
To authenticate to BigQuery, set up Application Default Credentials. For more information, see Set up authentication for client libraries.
Ruby
Before trying this sample, follow the Ruby setup instructions in the BigQuery quickstart using client libraries. For more information, see the BigQuery Ruby API reference documentation.
To authenticate to BigQuery, set up Application Default Credentials. For more information, see Set up authentication for client libraries.
Name datasets
When you create a dataset in BigQuery, the dataset name must be unique for each project. The dataset name can contain the following:
- Up to 1,024 characters.
- Letters (uppercase or lowercase), numbers, and underscores.
Dataset names are case-sensitive by default. mydataset and MyDataset can
coexist in the same project, unless one of them has case-sensitivity
turned off. For examples, see
Creating a case-insensitive dataset
and Resource: Dataset.
Dataset names cannot contain spaces or special characters such as -, &, @,
or %.
Hidden datasets
A hidden dataset is a dataset whose name begins with an underscore. You can query tables and views in hidden datasets the same way you would in any other dataset. Hidden datasets have the following restrictions:
- They are hidden from the Explorer panel in the Google Cloud console.
- They don't appear in any
INFORMATION_SCHEMAviews. - They can't be used with linked datasets.
- They can't be used as a source dataset with the following authorized resources:
- They don't appear in Data Catalog (deprecated) or Dataplex Universal Catalog.
Dataset security
To control access to datasets in BigQuery, see Controlling access to datasets. For information about data encryption, see Encryption at rest.
What's next
- For more information about listing datasets in a project, see Listing datasets.
- For more information about dataset metadata, see Getting information about datasets.
- For more information about changing dataset properties, see Updating datasets.
- For more information about creating and managing labels, see Creating and managing labels.
Try it for yourself
If you're new to Google Cloud, create an account to evaluate how BigQuery performs in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
Try BigQuery free