Criar conjuntos de dados
Neste documento, descrevemos como criar conjuntos de dados no BigQuery.
Crie conjuntos de dados das seguintes maneiras:
- Usando o Console do Google Cloud.
- Como usar uma consulta SQL
- Use o comando
bq mkna ferramenta de linha de comando bq - chamando o método de API
datasets.insert; - use bibliotecas de cliente;
- Copiando um conjunto de dados existente.
Para ver as etapas para essa ação, inclusive entre regiões, consulte Como copiar conjuntos de dados.
Neste documento, descrevemos como trabalhar com conjuntos de dados comuns que armazenam dados no BigQuery. Para saber como trabalhar com conjuntos de dados externos do Spanner, consulte Criar conjuntos de dados externos do Spanner. Para saber como trabalhar com conjuntos de dados federados do AWS Glue, consulte Criar conjuntos de dados federados do AWS Glue.
Para consultar tabelas em um conjunto de dados público, consulte Consultar um conjunto de dados público com o Console do Google Cloud.
Limitações do conjunto de dados
Os conjuntos de dados do BigQuery estão sujeitos às seguintes limitações:
- O local do conjunto de dados só pode ser definido no momento da criação. Depois que um conjunto de dados é criado, o local não pode ser alterado.
- Todas as tabelas referenciadas em uma consulta precisam ser armazenadas em conjuntos de dados no mesmo local.
Os conjuntos de dados externos não são compatíveis com a expiração de tabelas, réplicas, viagem no tempo, ordenação padrão, modo de arredondamento padrão ou a opção de ativar ou desativar o nome de tabelas sem distinção entre maiúsculas e minúsculas.
Ao copiar uma tabela, os conjuntos de dados que contêm as tabelas de origem e de destino precisam estar no mesmo local.
Os conjuntos de dados de cada projeto precisam ter nomes exclusivos.
Depois de alterar o modelo de faturamento do armazenamento de um conjunto de dados, aguarde 14 dias antes de alterar o modelo de faturamento do armazenamento novamente.
Não será possível registrar um conjunto de dados no faturamento do armazenamento físico se você tiver algum compromisso de slot de taxa fixa legado localizado na mesma região do conjunto de dados.
Antes de começar
Atribua papéis do Identity and Access Management (IAM) que concedam aos usuários as permissões necessárias para realizar cada tarefa deste documento.
Permissões necessárias
Para criar um conjunto de dados, é preciso ter a permissão
bigquery.datasets.create do IAM.
Cada um dos seguintes papéis predefinidos do IAM inclui as permissões necessárias para criar um conjunto de dados:
roles/bigquery.dataEditorroles/bigquery.dataOwnerroles/bigquery.userroles/bigquery.admin
Para mais informações sobre os papéis do IAM no BigQuery, consulte Papéis e permissões predefinidos.
Nomear conjuntos de dados
Ao criar um conjunto de dados no BigQuery, ele precisa ter um nome exclusivo para cada projeto. O nome do conjunto de dados pode conter:
- até 1.024 caracteres;
- letras (maiúsculas e minúsculas), números e sublinhados;
Os nomes dos conjuntos de dados diferenciam maiúsculas de minúsculas por padrão. mydataset e MyDataset podem
coexistir no mesmo projeto, a menos que um deles tenha desativado a diferenciação
de maiúsculas e minúsculas.
Os nomes de conjuntos de dados não podem conter espaços ou caracteres especiais, como -, &, @
e %.
Conjuntos de dados ocultos
Um conjunto de dados oculto é aquele cujo nome começa com um sublinhado. Consulte tabelas e visualizações em conjuntos de dados ocultos da mesma maneira que faria em qualquer outro conjunto de dados. Os conjuntos de dados ocultos têm as seguintes restrições:
- Eles estão ocultos no painel Explorer no console do Google Cloud.
- Eles não aparecem em nenhuma visualização de
INFORMATION_SCHEMA. - Não é possível usá-las com conjuntos de dados vinculados.
- Eles não aparecem no Data Catalog.
Criar conjuntos de dados
Para criar um conjunto de dados:
Console
Abra a página do BigQuery no console do Google Cloud.
No painel Explorer, selecione o projeto em que você quer criar o conjunto de dados.
Expanda a opção Ações e clique em Criar conjunto de dados.
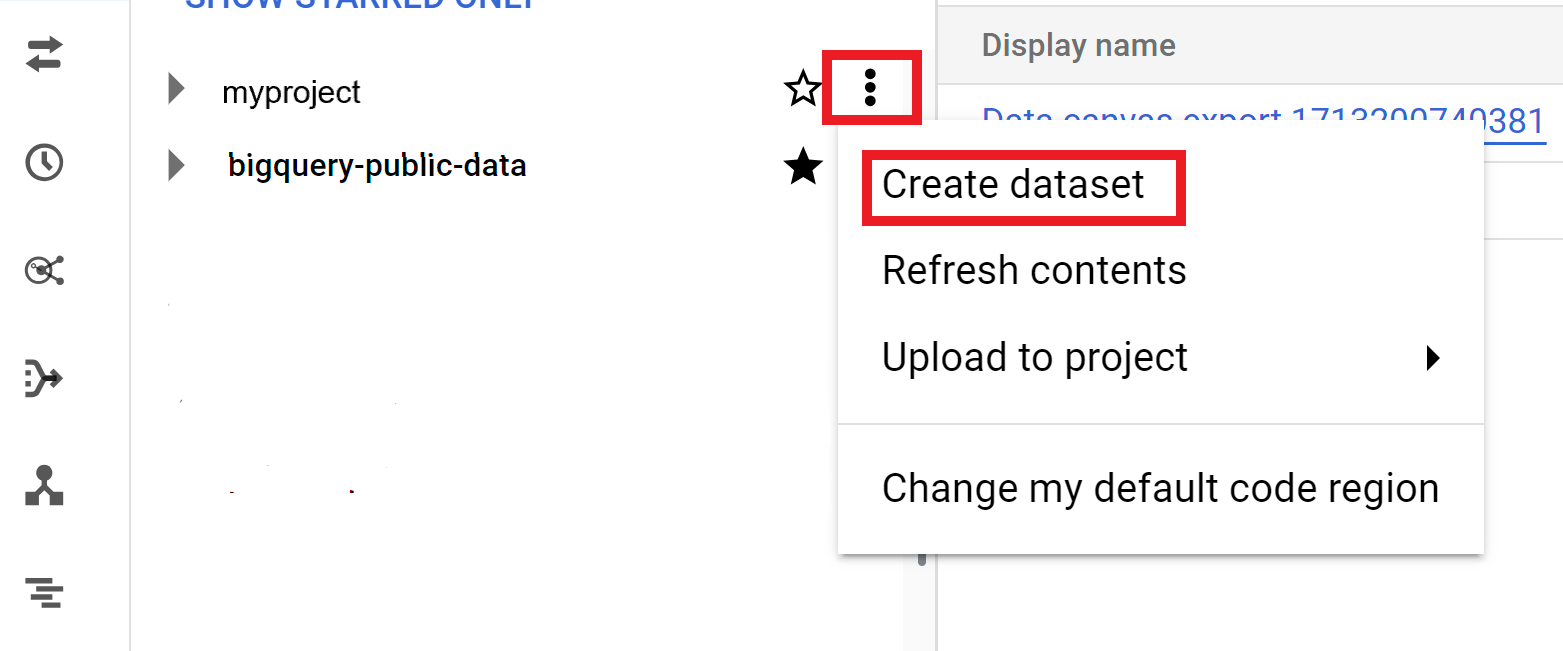
Na página Criar conjunto de dados, faça o seguinte:
- Em ID do conjunto de dados, insira um nome exclusivo para o conjunto de dados.
Em Tipo de local, escolha um local geográfico para o conjunto de dados. Após a criação de um conjunto de dados, o local não pode ser alterado.
Opcional: se você quer que as tabelas neste conjunto de dados expirem, selecione Ativar expiração da tabela e especifique a Idade máxima padrão da tabela em dias.
Opcional: se você quiser usar uma chave de criptografia gerenciada pelo cliente (CMEK), expanda Opções avançadas e selecione Chave de criptografia gerenciada pelo cliente (CMEK).
Opcional: se você quiser usar nomes de tabelas que não diferenciam maiúsculas de minúsculas, expanda Opções avançadas e selecione Ativar nomes de tabelas que não diferenciam maiúsculas de minúsculas.
Opcional: se você quiser usar um agrupamento padrão, abra Opções avançadas, selecione Ativar a ordenação padrão e selecione o Agrupamento padrão.
Opcional: se você quiser usar um modo de arredondamento padrão, expanda Opções avançadas e selecione o Modo de arredondamento padrão a ser usado.
Opcional: se você quiser ativar o modelo de faturamento de armazenamento físico, expanda Opções avançadas e selecione Ativar o modelo de faturamento de armazenamento físico. .
Leva 24 horas para alterar o modelo de faturamento de um conjunto de dados.
Depois de alterar o modelo de faturamento do armazenamento de um conjunto de dados, aguarde 14 dias antes de alterá-lo novamente.
Opcional: se você quiser definir a janela de viagem no tempo do conjunto de dados, abra as Opções avançadas e selecione a janela de viagem no tempo. usar.
Clique em Criar conjunto de dados.
SQL
Use a
instrução CREATE SCHEMA.
Para criar um conjunto de dados em um projeto diferente do projeto padrão, adicione a ID do projeto ao ID do conjunto de dados no seguinte formato: PROJECT_ID.DATASET_ID.
No Console do Google Cloud, acesse a página BigQuery.
No editor de consultas, digite a seguinte instrução:
CREATE SCHEMA PROJECT_ID.DATASET_ID OPTIONS ( default_kms_key_name = 'KMS_KEY_NAME', default_partition_expiration_days = PARTITION_EXPIRATION, default_table_expiration_days = TABLE_EXPIRATION, description = 'DESCRIPTION', labels = [('KEY_1','VALUE_1'),('KEY_2','VALUE_2')], location = 'LOCATION', max_time_travel_hours = HOURS, storage_billing_model = BILLING_MODEL);
Substitua:
PROJECT_ID: ID do projetoDATASET_ID: o ID do conjunto de dados que você está criandoKMS_KEY_NAME: o nome da chave padrão do Cloud Key Management Service usada para proteger tabelas recém-criadas nesse conjunto de dados, a menos que uma chave diferente seja fornecida no momento da criação. Não é possível criar uma tabela criptografada pelo Google em um conjunto de dados com este parâmetro definido.PARTITION_EXPIRATION: a vida útil padrão, em dias, das partições das tabelas particionadas recém-criadas. Não há um valor mínimo de validade de partição padrão. O prazo de validade é avaliado para a data da partição, acrescida deste valor. Qualquer partição criada em uma tabela particionada no conjunto de dados é excluídaPARTITION_EXPIRATIONdias após a data da partição. Se você fornecer a opçãotime_partitioning_expirationao criar ou atualizar uma tabela particionada, a validade da partição no nível da tabela terá prioridade sobre a validade da partição padrão no nível do conjunto de dados.TABLE_EXPIRATION: a vida útil padrão, em dias, das tabelas recém-criadas. O valor mínimo é 0,042 dias (uma hora). O prazo de validade é a soma do horário atual com o valor inteiro. Qualquer tabela criada no conjunto de dados é excluídaTABLE_EXPIRATIONdias após a hora de criação. Esse valor é aplicado caso a validade da tabela não seja definida ao criar a tabela.DESCRIPTION: uma descrição do conjunto de dados.KEY_1:VALUE_1: o par de chave-valor que você quer definir como o primeiro rótulo neste conjunto de dados.KEY_2:VALUE_2: o par de chave-valor que você quer definir como o segundo rótulo.LOCATION: o local do conjunto de dados. Após a criação de um conjunto de dados, o local não pode ser alterado.HOURS: a duração em horas do período de viagem do tempo para o novo conjunto de dados. O valorHOURSprecisa ser um número inteiro expresso em múltiplos de 24 (48, 72, 96, 120, 144, 168) entre 48 (2 dias) e 168 (7 dias). O padrão será 168 horas se essa opção não for especificada.BILLING_MODEL: atualiza o modelo de faturamento de armazenamento do conjunto de dados. Defina o valor deBILLING_MODELcomoPHYSICALpara usar bytes físicos ao calcular as cobranças de armazenamento ou comoLOGICALpara usar bytes lógicos. O padrão éLOGICAL.Leva 24 horas para alterar o modelo de faturamento de um conjunto de dados.
Depois de alterar o modelo de faturamento do armazenamento de um conjunto de dados, aguarde 14 dias antes de alterá-lo novamente.
Clique em Executar.
Para mais informações sobre como executar consultas, acesse Executar uma consulta interativa.
bq
Para criar um novo conjunto de dados, utilize o
comando bq mk
com a sinalização --location. Para obter uma lista completa de parâmetros, consulte a
referência
comando bq mk --dataset.
Para criar um conjunto de dados em um projeto diferente do projeto padrão, adicione a ID do projeto ao nome do conjunto de dados no seguinte formato: PROJECT_ID:DATASET_ID.
bq --location=LOCATION mk \ --dataset \ --default_kms_key=KMS_KEY_NAME \ --default_partition_expiration=PARTITION_EXPIRATION \ --default_table_expiration=TABLE_EXPIRATION \ --description="DESCRIPTION" \ --label=KEY_1:VALUE_1 \ --label=KEY_2:VALUE_2 \ --add_tags=KEY_3:VALUE_3[,...] \ --max_time_travel_hours=HOURS \ --storage_billing_model=BILLING_MODEL \ PROJECT_ID:DATASET_ID
Substitua:
LOCATION: o local do conjunto de dados. Após a criação de um conjunto de dados, o local não pode ser alterado. É possível definir um valor padrão para o local usando o arquivo.bigqueryrc.KMS_KEY_NAME: o nome da chave padrão do Cloud Key Management Service usada para proteger tabelas recém-criadas nesse conjunto de dados, a menos que uma chave diferente seja fornecida no momento da criação. Não é possível criar uma tabela criptografada pelo Google em um conjunto de dados com este parâmetro definido.PARTITION_EXPIRATION: a vida útil padrão (em segundos) das partições das tabelas particionadas recém-criadas. Não há um valor mínimo de expiração de partição padrão. O prazo de validade é avaliado para a data da partição, acrescida desse valor. Qualquer partição criada em uma tabela particionada no conjunto de dados é excluídaPARTITION_EXPIRATIONsegundos após a data da partição. Se você fornecer a sinalização--time_partitioning_expirationao criar ou atualizar uma tabela particionada, a validade da partição no nível da tabela terá prioridade sobre a validade da partição padrão no nível do conjunto de dados.TABLE_EXPIRATION: a vida útil padrão, em segundos, das tabelas recém-criadas. O valor mínimo é de 3.600 segundos (uma hora). O tempo de expiração é avaliado como o horário atual mais o valor inteiro. Qualquer tabela criada no conjunto de dados será excluídaTABLE_EXPIRATIONsegundos após a hora de criação. Esse valor será aplicado caso você não defina a validade da tabela ao criá-la.DESCRIPTION: uma descrição do conjunto de dados.KEY_1:VALUE_1: o par de chave-valor que você quer definir como o primeiro rótulo desse conjunto de dados, eKEY_2:VALUE_2é o par de chave-valor que você quer definir como o par segundo marcador.KEY_3:VALUE_3: o par de chave-valor. que você quer definir como uma tag no conjunto de dados. Adicione várias tags na mesma flag usando vírgulas entre os pares de chave-valor.HOURS: a duração em horas do período de viagem do tempo para o novo conjunto de dados. O valorHOURSprecisa ser um número inteiro expresso em múltiplos de 24 (48, 72, 96, 120, 144 e 168) entre 48 (2 dias) e 168 (7 dias). O padrão será 168 horas se essa opção não for especificada.BILLING_MODEL: define o modelo de faturamento de armazenamento do conjunto de dados. Defina o valor deBILLING_MODELcomoPHYSICALpara usar bytes físicos ao calcular as cobranças de armazenamento ou comoLOGICALpara usar bytes lógicos. O padrão éLOGICAL.Leva 24 horas para alterar o modelo de faturamento de um conjunto de dados.
Depois de alterar o modelo de faturamento do armazenamento de um conjunto de dados, aguarde 14 dias antes de alterá-lo novamente.
PROJECT_ID: o ID do projeto.DATASET_IDé o ID do conjunto de dados que você está criando.
Por exemplo: o comando a seguir cria um conjunto de dados chamado mydataset com o local do conjunto de dados definido nos US, uma expiração de tabela padrão de 3.600 segundos (1 hora) e uma descrição de This is my dataset. Em vez de usar a sinalização --dataset, o comando usa o atalho -d. Se você omitir -d e --dataset, o comando retorna ao padrão para criar um conjunto de dados.
bq --location=US mk -d \ --default_table_expiration 3600 \ --description "This is my dataset." \ mydataset
Para confirmar se o conjunto de dados foi criado, digite o comando bq ls. Além disso,
é possível criar uma tabela ao criar um novo conjunto de dados usando o
seguinte formato: bq mk -t dataset.table.
Para mais informações sobre como criar tabelas, consulte
Como criar uma tabela.
Terraform
Use o
recurso
google_bigquery_dataset.
Para autenticar no BigQuery, configure o Application Default Credentials. Para mais informações, acesse Configurar a autenticação para bibliotecas de cliente.
Criar um conjunto de dados
O exemplo a seguir cria um conjunto de dados chamado mydataset.
Ao criar um conjunto de dados usando o recurso google_bigquery_dataset,
ele concede automaticamente acesso ao conjunto de dados para todas as contas que sejam
membros de papéis básicos no nível do projeto.
Se você executar o
comando terraform show
depois de criar o conjunto de dados, o
bloco access do conjunto de dados será semelhante ao
seguinte:
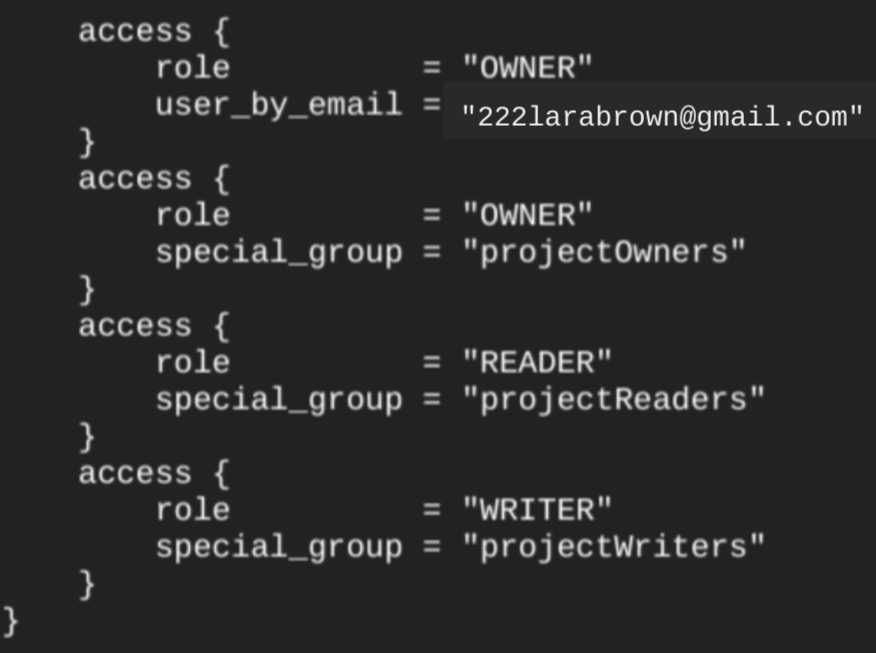
Para conceder acesso ao conjunto de dados, recomendamos o uso de um dos recursos google_bigquery_iam, como mostrado no exemplo a seguir, a menos que você planeje criar objetos autorizados, como como visualizações autorizadas, no conjunto de dados.
Nesse caso, use o
recurso google_bigquery_dataset_access. Consulte a documentação para conferir exemplos.
Criar um conjunto de dados e conceder acesso a ele
O exemplo a seguir cria um conjunto de dados chamado mydataset e usa o recurso google_bigquery_dataset_iam_policy para conceder acesso a ele.
Crie um conjunto de dados com uma chave de criptografia gerenciada pelo cliente
O exemplo a seguir cria um conjunto de dados chamado mydataset e também usa os recursos
google_kms_crypto_key
e
google_kms_key_ring para especificar uma chave do Cloud Key Management Service para o conjunto de dados. É necessário
ativar a API Cloud Key Management Service antes de executar este exemplo.
Para aplicar a configuração do Terraform em um projeto do Google Cloud, conclua as etapas nas seções a seguir.
Preparar o Cloud Shell
- Inicie o Cloud Shell.
-
Defina o projeto padrão do Google Cloud em que você quer aplicar as configurações do Terraform.
Você só precisa executar esse comando uma vez por projeto, e ele pode ser executado em qualquer diretório.
export GOOGLE_CLOUD_PROJECT=PROJECT_ID
As variáveis de ambiente serão substituídas se você definir valores explícitos no arquivo de configuração do Terraform.
Preparar o diretório
Cada arquivo de configuração do Terraform precisa ter o próprio diretório, também chamado de módulo raiz.
-
No Cloud Shell, crie um diretório e um novo
arquivo dentro dele. O nome do arquivo precisa ter a extensão
.tf, por exemplo,main.tf. Neste tutorial, o arquivo é chamado demain.tf.mkdir DIRECTORY && cd DIRECTORY && touch main.tf
-
Se você estiver seguindo um tutorial, poderá copiar o exemplo de código em cada seção ou etapa.
Copie o exemplo de código no
main.tfrecém-criado.Se preferir, copie o código do GitHub. Isso é recomendado quando o snippet do Terraform faz parte de uma solução de ponta a ponta.
- Revise e modifique os parâmetros de amostra para aplicar ao seu ambiente.
- Salve as alterações.
-
Inicialize o Terraform. Você só precisa fazer isso uma vez por diretório.
terraform init
Opcionalmente, para usar a versão mais recente do provedor do Google, inclua a opção
-upgrade:terraform init -upgrade
Aplique as alterações
-
Revise a configuração e verifique se os recursos que o Terraform vai criar ou
atualizar correspondem às suas expectativas:
terraform plan
Faça as correções necessárias na configuração.
-
Para aplicar a configuração do Terraform, execute o comando a seguir e digite
yesno prompt:terraform apply
Aguarde até que o Terraform exiba a mensagem "Apply complete!".
- Abra seu projeto do Google Cloud para ver os resultados. No console do Google Cloud, navegue até seus recursos na IU para verificar se foram criados ou atualizados pelo Terraform.
API
Chame o método datasets.insert com um recurso de conjunto de dados definido.
C#
Antes de testar esta amostra, siga as instruções de configuração do C# no Guia de início rápido do BigQuery: como usar bibliotecas de cliente. Para mais informações, consulte a documentação de referência da API BigQuery em C#.
Para autenticar no BigQuery, configure o Application Default Credentials. Para mais informações, acesse Configurar a autenticação para bibliotecas de cliente.
Go
Antes de testar esta amostra, siga as instruções de configuração do Go no Guia de início rápido do BigQuery: como usar bibliotecas de cliente. Para mais informações, consulte a documentação de referência da API BigQuery em Go.
Para autenticar no BigQuery, configure o Application Default Credentials. Para mais informações, acesse Configurar a autenticação para bibliotecas de cliente.
Java
Antes de testar esta amostra, siga as instruções de configuração do Java no Guia de início rápido do BigQuery: como usar bibliotecas de cliente. Para mais informações, consulte a documentação de referência da API BigQuery em Java.
Para autenticar no BigQuery, configure o Application Default Credentials. Para mais informações, acesse Configurar a autenticação para bibliotecas de cliente.
Node.js
Antes de testar esta amostra, siga as instruções de configuração do Node.js no Guia de início rápido do BigQuery: como usar bibliotecas de cliente. Para mais informações, consulte a documentação de referência da API BigQuery em Node.js.
Para autenticar no BigQuery, configure o Application Default Credentials. Para mais informações, acesse Configurar a autenticação para bibliotecas de cliente.
PHP
Antes de testar esta amostra, siga as instruções de configuração do PHP no Guia de início rápido do BigQuery: como usar bibliotecas de cliente. Para mais informações, consulte a documentação de referência da API BigQuery em PHP.
Para autenticar no BigQuery, configure o Application Default Credentials. Para mais informações, acesse Configurar a autenticação para bibliotecas de cliente.
Python
Antes de testar esta amostra, siga as instruções de configuração do Python no Guia de início rápido do BigQuery: como usar bibliotecas de cliente. Para mais informações, consulte a documentação de referência da API BigQuery em Python.
Para autenticar no BigQuery, configure o Application Default Credentials. Para mais informações, acesse Configurar a autenticação para bibliotecas de cliente.
Ruby
Antes de testar esta amostra, siga as instruções de configuração do Ruby no Guia de início rápido do BigQuery: como usar bibliotecas de cliente. Para mais informações, consulte a documentação de referência da API BigQuery em Ruby.
Para autenticar no BigQuery, configure o Application Default Credentials. Para mais informações, acesse Configurar a autenticação para bibliotecas de cliente.
Segurança do conjunto de dados
Para controlar o acesso a conjuntos de dados no BigQuery, consulte Como controlar o acesso a conjuntos de dados. Para saber mais sobre criptografia de dados, consulte Criptografia em repouso.
A seguir
- Para mais informações sobre como listar conjuntos de dados em um projeto, consulte Como listar conjuntos de dados.
- Para mais informações sobre metadados de conjuntos de dados, consulte Como receber informações sobre conjuntos de dados.
- Para mais informações sobre a alteração de propriedades de conjuntos de dados, consulte Como atualizar propriedades de conjuntos de dados.
- Para mais informações sobre como criar e gerenciar rótulos, consulte Como criar e gerenciar rótulos.
Faça um teste
Se você começou a usar o Google Cloud agora, crie uma conta para avaliar o desempenho do BigQuery em situações reais. Clientes novos também recebem US$ 300 em créditos para executar, testar e implantar cargas de trabalho.
Faça uma avaliação gratuita do BigQuery