Réplication interrégionale des ensembles de données
La réplication d'ensembles de données BigQuery vous permet de configurer la réplication automatique d'un ensemble de données entre deux régions ou multirégions différentes.
Présentation
Lorsque vous créez un ensemble de données dans BigQuery, vous sélectionnez la région ou la zone multirégionale dans laquelle les données sont stockées. Une région est un ensemble de centres de données situés dans une zone géographique, et une zone multirégionale correspond à une zone géographique de grande étendue contenant au moins deux régions géographiques. Vos données sont stockées dans l'une des régions incluses et ne sont pas répliquées dans la région multirégionale. Pour en savoir plus sur les régions et les zones multirégionales, consultez Emplacements BigQuery.
BigQuery stocke toujours des copies de vos données dans deux zonesGoogle Cloud différentes au sein de l'emplacement de l'ensemble de données. Une zone est une zone de déploiement pour les ressources Google Cloud au sein d'une région. Dans toutes les régions, la réplication entre les zones utilise des doubles écritures synchrones. La sélection d'un emplacement multirégional ne permet pas la réplication interrégionale ni la redondance régionale. Il n'y a donc pas d'augmentation de la disponibilité de l'ensemble de données en cas de panne régionale. Les données sont stockées dans une seule région au sein de l'emplacement géographique.
Pour une géo-redondance supplémentaire, vous pouvez répliquer n'importe quel ensemble de données. BigQuery crée une instance répliquée secondaire de l'ensemble de données, située dans une autre région que vous spécifiez. Cette instance répliquée est ensuite répliquée de manière asynchrone entre deux zones de l'autre région, soit un total de quatre copies zonales.
Réplication d'ensembles de données
Si vous répliquez un ensemble de données, BigQuery stocke les données dans la région que vous spécifiez.
Région principale. Lorsque vous créez un ensemble de données pour la première fois, BigQuery le place dans la région principale.
Région secondaire. Lorsque vous ajoutez une instance répliquée d'un ensemble de données, BigQuery la place dans la région secondaire.
Initialement, l'instance répliquée de la région principale est l'instance répliquée principale et l'instance répliquée de l'instance secondaire est l'instance répliquée secondaire.
L'instance répliquée principale est accessible en écriture et l'instance répliquée secondaire est en lecture seule. Les écritures sur l'instance répliquée principale sont répliquées de manière asynchrone sur l'instance répliquée secondaire. Dans chaque région, les données sont stockées de manière redondante dans deux zones. Le trafic réseau ne quitte jamais le réseau Google Cloud .
Le schéma suivant illustre la réplication qui se produit lorsqu'un ensemble de données est répliqué :
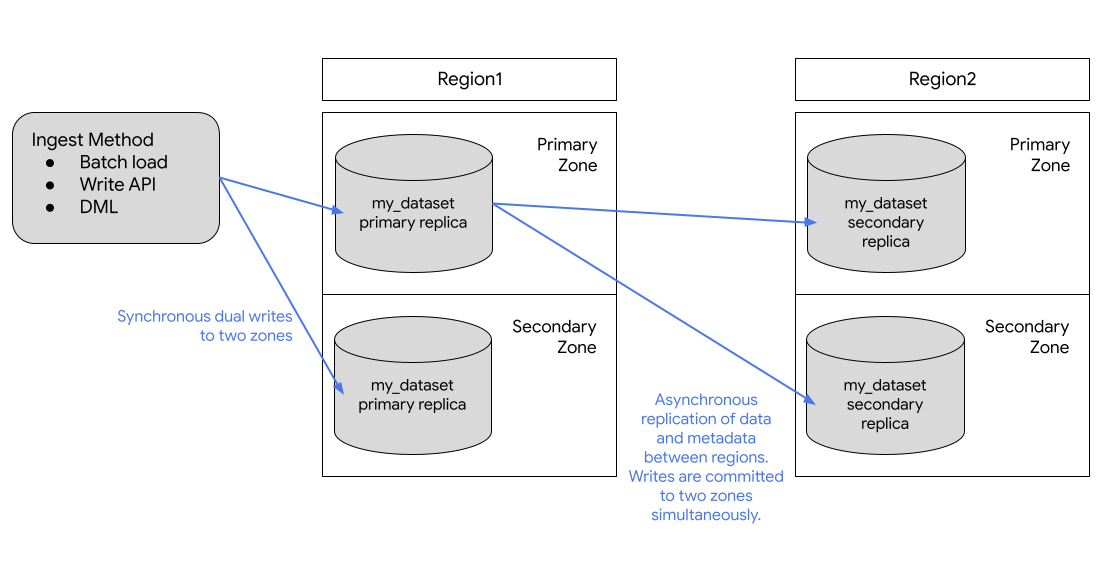
Si la région principale est en ligne, vous pouvez passer manuellement à l'instance répliquée secondaire. Pour en savoir plus, consultez la section Promouvoir l'instance répliquée secondaire.
Tarifs
Les éléments suivants vous sont facturés pour les ensembles de données répliqués :
- Stockage. Les octets de stockage dans la région secondaire sont facturés en tant que copie distincte dans la région secondaire. Consultez les tarifs de stockage BigQuery.
- Réplication de données. Pour en savoir plus sur le mode de facturation de la réplication de données, consultez la page Tarifs de réplication de données.
Capacité de calcul dans la région secondaire
Pour exécuter des tâches et des requêtes sur l'instance répliquée dans la région secondaire, vous devez acheter des emplacements dans la région secondaire ou exécuter une requête à la demande.
Vous pouvez utiliser les emplacements pour effectuer des requêtes en lecture seule à partir de l'instance répliquée secondaire. Si vous promouvez l'instance répliquée secondaire en tant qu'instance principale, vous pouvez également utiliser ces emplacements pour écrire sur l'instance répliquée.
Vous pouvez acheter le même nombre d'emplacements que celui de la région principale ou un nombre différent. Si vous achetez moins d'emplacements, cela peut affecter les performances des requêtes.
Considérations relatives aux emplacements
Avant d'ajouter une instance répliquée d'ensemble de données, vous devez créer l'ensemble de données initial que vous souhaitez dupliquer dans BigQuery s'il n'existe pas déjà. L'emplacement de l'instance répliquée ajoutée est défini sur l'emplacement que vous spécifiez lors de l'ajout de l'instance répliquée. L'emplacement de l'instance répliquée ajoutée doit être différent de celui de l'ensemble de données initial. Cela signifie que les données de votre ensemble de données sont répliquées en continu entre l'emplacement dans lequel l'ensemble de données a été créé et l'emplacement de l'instance répliquée. Pour les instances répliquées qui nécessitent une colocation, telles que les vues, les vues matérialisées ou les tables externes autres que BigLake, l'ajout d'une instance répliquée dans un emplacement différent ou non compatible avec l'emplacement de vos données sources peut entraîner des erreurs de jobs.
Lorsque les clients répliquent un ensemble de données dans plusieurs régions, BigQuery garantit que les données ne sont situées que dans les emplacements où les instances répliquées ont été créées.
Exigences de colocation
L'utilisation de la réplication de l'ensemble de données dépend des exigences de colocation suivantes.
Cloud Storage
Pour interroger des données sur Cloud Storage, le bucket Cloud Storage doit être colocalisé avec l'instance répliquée. Reportez-vous aux considérations relatives à l'emplacement des tables externes pour déterminer l'emplacement de votre instance répliquée.
Limites
La réplication d'ensembles de données BigQuery est soumise aux limitations suivantes :
- La réplication des données par flux écrites dans l'instance répliquée principale à partir de l'API BigQuery Storage Write ou de la méthode
tabledata.insertAll, qui sont ensuite répliquées dans l'instance répliquée secondaire, est la meilleure possible et peut entraîner un délai de réplication élevé. - Les opérations upsert par flux écrites dans le réplica principal à partir de Datastream ou de la capture de données modifiées BigQuery, qui sont ensuite répliquées dans le réplica secondaire, sont les meilleures possibles et peuvent entraîner un délai de réplication élevé. Une fois les upserts répliqués, ils sont fusionnés dans la référence de table de la réplique secondaire, conformément à la valeur
max_stalenessconfigurée pour la table. - Vous ne pouvez pas activer le LMD précis sur une table d'un ensemble de données répliqué, ni répliquer un ensemble de données contenant une table sur laquelle le LMD précis est activé.
- La réplication et la commutation sont gérées via des instructions LDD (langage de définition de données) SQL.
- Vous êtes limité à une instance répliquée de chaque ensemble de données par région ou ensemble multirégional. Vous ne pouvez pas créer deux instances répliquées secondaires du même ensemble de données dans la même région de destination.
- Les ressources au sein d'instances répliquées sont soumises aux limites décrites dans la section Comportement des ressources.
- Les tags avec stratégie et les stratégies de données associées ne sont pas répliqués sur l'instance répliquée secondaire. Toutes les requêtes faisant référence à des colonnes avec des tags avec stratégie dans des régions autres que la région d'origine échouent, même si cette instance répliquée est promue.
- Les fonctionnalités temporelles ne sont disponibles dans l'instance répliquée secondaire qu'une fois la création de l'instance répliquée secondaire terminée.
- La limite de taille de la région de destination pour activer la réplication multirégionale sur un ensemble de données est de 10 PB pour les multirégions
useteu, et de 500 To pour les autres régions par défaut. Ces limites sont configurables. Pour en savoir plus, contactez l'assistanceGoogle Cloud . - Le quota s'applique aux ressources logiques.
- Vous ne pouvez répliquer un ensemble de données que s'il comporte moins de 100 000 tables.
- Vous êtes limité à un maximum de quatre instances répliquées ajoutées (puis supprimées) à la même région par ensemble de données et par jour.
- Vous êtes limité par la bande passante.
- Les tables auxquelles des clés de chiffrement gérées par le client (CMEK) sont appliquées ne peuvent pas être interrogées dans la région secondaire si la valeur
replica_kms_keyn'est pas configurée. - Les tables BigLake ne sont pas compatibles.
- Vous ne pouvez pas répliquer les ensembles de données externes ni fédérés.
- Les emplacements BigQuery Omni ne sont pas compatibles.
- Vous ne pouvez pas configurer les paires de régions suivantes si vous configurez la réplication de données pour la reprise après sinistre :
us-central1-us(multirégional)us-west1-us(multirégional)eu-west1-eu(multirégional)eu-west4-eu(multirégional)
- Les contrôles d'accès au niveau des routines ne peuvent pas être répliqués, mais vous pouvez répliquer les contrôles d'accès au niveau des ensembles de données pour les routines.
Comportement des ressources
Les opérations suivantes ne sont pas compatibles avec les ressources de l'instance répliquée secondaire :
Si vous devez créer une copie d'une ressource dans une instance répliquée secondaire, vous devez copier la ressource ou l'interroger, puis matérialiser les résultats en dehors de l'instance répliquée secondaire. Par exemple, utilisez CREATE TABLE AS SELECT pour créer une ressource à partir de la ressource d'instance répliquée secondaire.
Les instances répliquées principales et secondaires sont soumises aux différences suivantes :
| Instance répliquée principale de la région 1 | Instance répliquée secondaire de la région 2 | Remarques |
|---|---|---|
| Table BigLake | Table BigLake | Non compatible. |
| Table externe | Table externe | Seule la définition de la table externe est répliquée. La requête échoue lorsque le bucket Cloud Storage n'est pas colocalisé dans le même emplacement qu'une instance répliquée. |
| Vue logique | Vue logique | Les vues logiques qui font référence à un ensemble de données ou à une ressource qui ne se trouve pas au même emplacement que la vue logique échouent lors de leur interrogation. |
| Table gérée | Table gérée | Aucune différence. |
| Vue matérialisée | Vue matérialisée | Si une table référencée ne se trouve pas dans la même région que la vue matérialisée, la requête échoue. Les vues matérialisées répliquées peuvent présenter une obsolescence supérieure à la valeur maximale d'obsolescence de la vue. |
| Modèle | Modèle | Stockées sous forme de tables gérées. |
| Fonction à distance | Fonction à distance | Les connexions sont régionales. Les fonctions à distance qui font référence à un ensemble de données ou à une ressource (connexion) qui ne se trouve pas au même emplacement que la fonction à distance échouent lors de leur exécution. |
| Routines | Fonction définie par l'utilisateur (UDF) ou procédure stockée | Les routines qui font référence à un ensemble de données ou à une ressource qui ne se trouve pas au même emplacement que la routine échouent lors de leur exécution. Toute routine qui fait référence à une connexion, comme les fonctions à distance, ne fonctionne pas en dehors de la région source. |
| Règle d'accès aux lignes | Règle d'accès aux lignes | Aucune différence. |
| index de recherche | index de recherche | Non répliqué. |
| Procédure stockée | Procédure stockée | Les procédures stockées qui font référence à un ensemble de données ou à une ressource qui ne se trouve pas au même emplacement que la procédure stockée échouent lors de leur exécution. |
| Clone de table | Table gérée | Facturée en tant que copie approfondie dans une instance répliquée secondaire. |
| Instantané de table | Instantané de table | Facturée en tant que copie approfondie dans une instance répliquée secondaire. |
| Fonction de valeur de table (TVF) | TVF | Les TVF qui font référence à un ensemble de données ou à une ressource qui ne se trouve pas au même emplacement que la TVF échouent lors de leur exécution. |
| UDF | UDF | Les UDF qui font référence à un ensemble de données ou à une ressource qui ne se trouve pas au même emplacement que l'UDF échouent lors de leur exécution. |
Scénarios d'indisponibilité
La réplication interrégionale n'est pas conçue pour être utilisée comme plan de reprise après sinistre en cas de panne régionale totale. En cas de panne régionale totale de l'instance répliquée principale, vous ne pouvez pas promouvoir l'instance répliquée secondaire. Les instances répliquées secondaires étant en lecture seule, vous ne pouvez pas exécuter de tâches d'écriture sur l'instance répliquée secondaire et vous ne pouvez pas promouvoir la région secondaire tant que la région de l'instance répliquée principale n'est pas restaurée. Pour en savoir plus sur la préparation de la reprise après sinistre, consultez la page Reprise après sinistre gérée.
Le tableau suivant explique l'impact des pannes régionales totales sur vos données répliquées :
| Région 1 | Région 2 | Région de panne | Impact |
|---|---|---|---|
| Instance répliquée principale | Instance répliquée secondaire | Région 2 | Les tâches en lecture seule exécutées dans la région 2 par rapport à l'instance répliquée secondaire échouent. |
| Instance répliquée principale | Instance répliquée secondaire | Région 1 | Tous les jobs exécutés dans la région 1 échouent. Les tâches en lecture seule continuent de s'exécuter dans la région 2 où se trouve l'instance répliquée secondaire. Le contenu de la région 2 est obsolète jusqu'à sa synchronisation avec la région 1. |
Utiliser la réplication d'ensembles de données
Cette section explique comment répliquer un ensemble de données, promouvoir l'instance répliquée secondaire et exécuter des tâches de lecture BigQuery dans la région secondaire.
Autorisations requises
Pour obtenir les autorisations nécessaires pour gérer des instances répliquées, demandez à votre administrateur de vous accorder l'autorisation bigquery.datasets.update.
Répliquer un ensemble de données
Pour répliquer un ensemble de données, utilisez
l'instruction DDL ALTER SCHEMA ADD REPLICA.
Vous pouvez ajouter une instance répliquée à tout ensemble de données situé dans une région ou un emplacement multirégional qui n'est pas déjà répliqué dans cette région ou cet emplacement multirégional. Une fois que vous avez ajouté une instance répliquée, l'opération de copie initiale peut prendre un certain temps. Vous pouvez toujours exécuter des requêtes faisant référence à l'instance répliquée principale pendant la réplication des données, sans réduire la capacité de traitement des requêtes. Vous ne pouvez pas répliquer les données dans les zones géographiques d'une région multirégionale.
L'exemple suivant crée un ensemble de données nommé my_dataset dans la région us-central1, puis ajoute une instance répliquée dans la région us-east4 :
-- Create the primary replica in the us-central1 region. CREATE SCHEMA my_dataset OPTIONS(location='us-central1'); -- Create a replica in the secondary region. ALTER SCHEMA my_dataset ADD REPLICA `my_replica` OPTIONS(location='us-east4');
Pour confirmer la date de création de l'instance répliquée secondaire, vous pouvez interroger la colonne creation_complete dans la vue INFORMATION_SCHEMA.SCHEMATA_REPLICAS.
Une fois la réplique secondaire créée, vous pouvez l'interroger en définissant explicitement l'emplacement de la requête sur la région secondaire. Si aucun emplacement n'est défini explicitement, BigQuery utilise la région de la réplique principale de l'ensemble de données.
Promouvoir l'instance répliquée secondaire
Si la région principale est en ligne, vous pouvez promouvoir l'instance répliquée secondaire. La promotion bascule sur l'instance répliquée secondaire en tant qu'instance principale avec accès en écriture. Cette opération s'effectue en quelques secondes si l'instance répliquée secondaire a rattrapé l'instance répliquée principale. Si l'instance répliquée secondaire n'est pas rattrapée, la promotion ne peut pas se terminer tant que l'instance n'est pas rattrapée. L'instance répliquée secondaire ne peut pas être promue en instance principale si la région contenant l'instance principale subit une panne.
Veuillez noter les points suivants :
- Toutes les écritures dans les tables renvoient des erreurs pendant le processus de promotion. L'ancienne instance répliquée principale devient immédiatement non accessible en écriture lorsque la promotion commence.
- Les tables qui ne sont pas entièrement répliquées au moment où la promotion est lancée renvoient des lectures obsolètes.
Pour promouvoir une instance répliquée en tant qu'instance répliquée principale, utilisez l'instruction LDD ALTER SCHEMA SET
OPTIONS et définissez l'option primary_replica.
Veuillez noter le point suivant : vous devez définir explicitement l'emplacement du job sur la région secondaire dans les paramètres de requête. Consultez Spécifier des emplacements BigQuery.
L'exemple suivant montre comment promouvoir l'instance répliquée us-east4 en tant qu'instance principale :
ALTER SCHEMA my_dataset SET OPTIONS(primary_replica = 'us-east4')
Pour vérifier quand l'instance répliquée secondaire a bien été promue, vous pouvez interroger la colonne replica_primary_assignment_complete dans la vue INFORMATION_SCHEMA.SCHEMATA_REPLICAS.
Supprimer une instance répliquée d'un ensemble de données
Pour supprimer une instance répliquée et arrêter la duplication de l'ensemble de données, utilisez l'instruction LDD ALTER SCHEMA DROP REPLICA.
L'exemple suivant permet de supprimer l'instance répliquée us :
ALTER SCHEMA my_dataset DROP REPLICA IF EXISTS `us`;
Vous devez d'abord supprimer toutes les instances répliquées secondaires pour supprimer l'intégralité de l'ensemble de données. Si vous supprimez l'intégralité de l'ensemble de données, par exemple à l'aide de l'instruction DROP
SCHEMA, sans supprimer toutes les instances répliquées secondaires, vous recevez le message d'erreur suivant :
The dataset replica of the cross region dataset 'project_id:dataset_id' in region 'REGION' is not yet writable because the primary assignment is not yet complete.
Pour en savoir plus, consultez Promouvoir l'instance répliquée secondaire.
Répertorier les instances répliquées d'ensembles de données
Pour répertorier les instances répliquées d'un ensemble de données dans un projet, interrogez la vue INFORMATION_SCHEMA.SCHEMATA_REPLICAS.
Migrer des ensembles de données
Vous pouvez utiliser la réplication d'ensembles de données interrégionaux pour migrer vos ensembles de données d'une région vers une autre. L'exemple suivant montre le processus de migration de l'ensemble de données my_migration existant depuis l'emplacement multirégional US vers l'emplacement multirégional EU à l'aide de la réplication interrégionale.
Répliquer l'ensemble de données
Pour commencer le processus de migration, répliquez d'abord l'ensemble de données dans la région vers laquelle vous souhaitez migrer les données. Dans ce scénario, vous migrez l'ensemble de données my_migration vers la région multiple EU.
-- Create a replica in the secondary region. ALTER SCHEMA my_migration ADD REPLICA `eu` OPTIONS(location='eu');
Cela crée une instance répliquée secondaire nommée eu dans l'emplacement multirégional EU.
L'instance répliquée principale est l'ensemble de données my_migration situé dans l'emplacement multirégional US.
Promouvoir l'instance répliquée secondaire
Pour continuer à migrer l'ensemble de données vers l'emplacement multirégional EU, promouvez l'instance répliquée secondaire :
ALTER SCHEMA my_migration SET OPTIONS(primary_replica = 'eu')
Une fois la promotion terminée, eu est l'instance répliquée principale. Il s'agit d'une instance répliquée avec accès en écriture.
Terminer la migration
Pour effectuer la migration de l'emplacement multirégional US vers l'emplacement multirégional EU, supprimez l'instance répliquée us. Cette étape n'est pas obligatoire, mais elle est utile si vous n'avez pas besoin d'une instance répliquée d'ensemble de données en plus de vos besoins de migration.
ALTER SCHEMA my_migration DROP REPLICA IF EXISTS us;
Votre ensemble de données est situé dans l'emplacement multirégional EU, et il n'existe aucune instance répliquée de l'ensemble de données my_migration. Vous avez bien migré votre ensemble de données vers la région multirégionale EU. Pour obtenir la liste complète des ressources migrées, consultez Comportement des ressources.
Clés de chiffrement gérées par le client (CMEK)
Les clés Cloud Key Management Service gérées par le client ne sont pas automatiquement répliquées lorsque vous créez une instance répliquée secondaire. Pour conserver le chiffrement sur votre ensemble de données répliqué, vous devez définir replica_kms_key pour l'emplacement de l'instance répliquée ajoutée. Vous pouvez définir replica_kms_key à l'aide de l'instruction LDD ALTER SCHEMA ADD REPLICA.
La réplication d'ensembles de données avec des clés CMEK se comporte comme décrit dans les scénarios suivants :
Si l'ensemble de données source comporte un
default_kms_key, vous devez fournir unreplica_kms_keycréé dans la région de l'ensemble de données de l'instance répliquée lors de l'utilisation de l'instruction LDDALTER SCHEMA ADD REPLICA.Si l'ensemble de données source n'a pas de valeur définie pour
default_kms_key, vous ne pouvez pas définirreplica_kms_key.Si vous utilisez la rotation des clés Cloud KMS sur l'une des ressources
default_kms_keyoureplica_kms_key(ou les deux), l'ensemble de données répliqué peut toujours être interrogé après la rotation des clés.- La rotation des clés dans la région principale ne permet de mettre à jour la version de clé que dans les tables créées après la rotation. Les tables qui existaient avant la rotation des clés utilisent toujours la version de clé définie avant la rotation.
- La rotation des clés dans la région secondaire met à jour toutes les tables de l'instance répliquée secondaire vers la nouvelle version de clé.
- Le passage de l'instance répliquée principale à l'instance répliquée secondaire met à jour toutes les tables de l'instance répliquée secondaire (anciennement instance répliquée principale) vers la nouvelle version de clé.
- Si la version de clé définie sur les tables de l'instance répliquée principale avant la rotation des clés est supprimée, les tables qui utilisent encore la version de clé antérieure à la rotation ne peuvent pas être interrogées tant que la version de clé n'est pas mise à jour. Pour mettre à jour la version de la clé, l'ancienne version doit être active (et non désactivée ni supprimée).
Si l'ensemble de données source n'a pas de valeur définie pour
default_kms_key, mais qu'il existe des tables individuelles dans l'ensemble de données source avec une table CMEK appliquée, ces tables ne peuvent pas être interrogées dans l'ensemble de données répliqué. Pour interroger les tables, procédez comme suit :- Ajoutez une valeur
default_kms_keypour l'ensemble de données source. - Lorsque vous créez une instance répliquée à l'aide de l'instruction LDD
ALTER SCHEMA ADD REPLICA, définissez une valeur pour l'optionreplica_kms_key. Les tables CMEK peuvent être interrogées dans la région de destination.
Toutes les tables CMEK de la région de destination utilisent la même
replica_kms_key, quelle que soit la clé utilisée dans la région source.- Ajoutez une valeur
Créer une instance répliquée avec CMEK
L'exemple suivant crée une instance répliquée dans la région us-west1 avec une valeur replica_kms_key définie. Pour la clé CMEK, autorisez le compte de service BigQuery à chiffrer et déchiffrer.
-- Create a replica in the secondary region. ALTER SCHEMA my_dataset ADD REPLICA `us-west1` OPTIONS(location='us-west1', replica_kms_key='my_us_west1_kms_key_name');
Limites de CMEK
Les ensembles de données de réplication avec des tables CMEK appliquées sont soumis aux limitations suivantes :
Vous ne pouvez pas mettre à jour la clé Cloud KMS répliquée une fois la réplique créée.
Vous ne pouvez pas mettre à jour la valeur
default_kms_keyde l'ensemble de données source après la création des instances répliquées.Si la
replica_kms_keyfournie n'est pas valide dans la région de destination, l'ensemble de données ne sera pas répliqué.
Étapes suivantes
- Découvrez comment utiliser les réservations BigQuery.
- En savoir plus sur les fonctionnalités de fiabilité de BigQuery