Présentation de la préparation de données BigQuery
Ce document décrit la préparation de données augmentée par l'IA dans BigQuery. Les préparations de données sont des ressources BigQuery qui utilisent Gemini dans BigQuery pour analyser vos données et vous fournir des suggestions intelligentes pour les nettoyer, les transformer et les enrichir. Vous pouvez réduire considérablement le temps et les efforts nécessaires pour les tâches manuelles de préparation des données. La planification des préparations de données est assurée par Dataform.
Avantages
- Vous pouvez réduire le temps consacré au développement de pipelines de données grâce aux suggestions de transformation générées par Gemini et adaptées au contexte.
- Vous pouvez valider les résultats générés dans un aperçu et recevoir des suggestions de nettoyage et d'enrichissement de la qualité des données grâce au mappage de schéma automatisé.
- Dataform vous permet d'utiliser un processus d'intégration et de développement continus (CI/CD), ce qui favorise la collaboration entre équipes pour les révisions de code et le contrôle des sources.
Points d'entrée de la préparation des données
Vous pouvez créer et gérer des préparations de données sur la page BigQuery Studio (consultez Ouvrir l'éditeur de préparation des données dans BigQuery).
Lorsque vous ouvrez une table dans la préparation des données BigQuery, un job BigQuery s'exécute à l'aide de vos identifiants. L'exécution crée des exemples de lignes à partir de la table choisie et écrit les résultats dans une table temporaire du même projet. Gemini utilise l'exemple de données et le schéma pour générer des suggestions de préparation des données affichées dans l'éditeur de préparation des données.
Vues dans l'éditeur de préparation des données
Les préparations de données s'affichent sous forme d'onglets sur la page BigQuery. Chaque onglet comporte une série de sous-onglets, ou vues de préparation des données, dans lesquels vous concevez et gérez vos préparations de données.
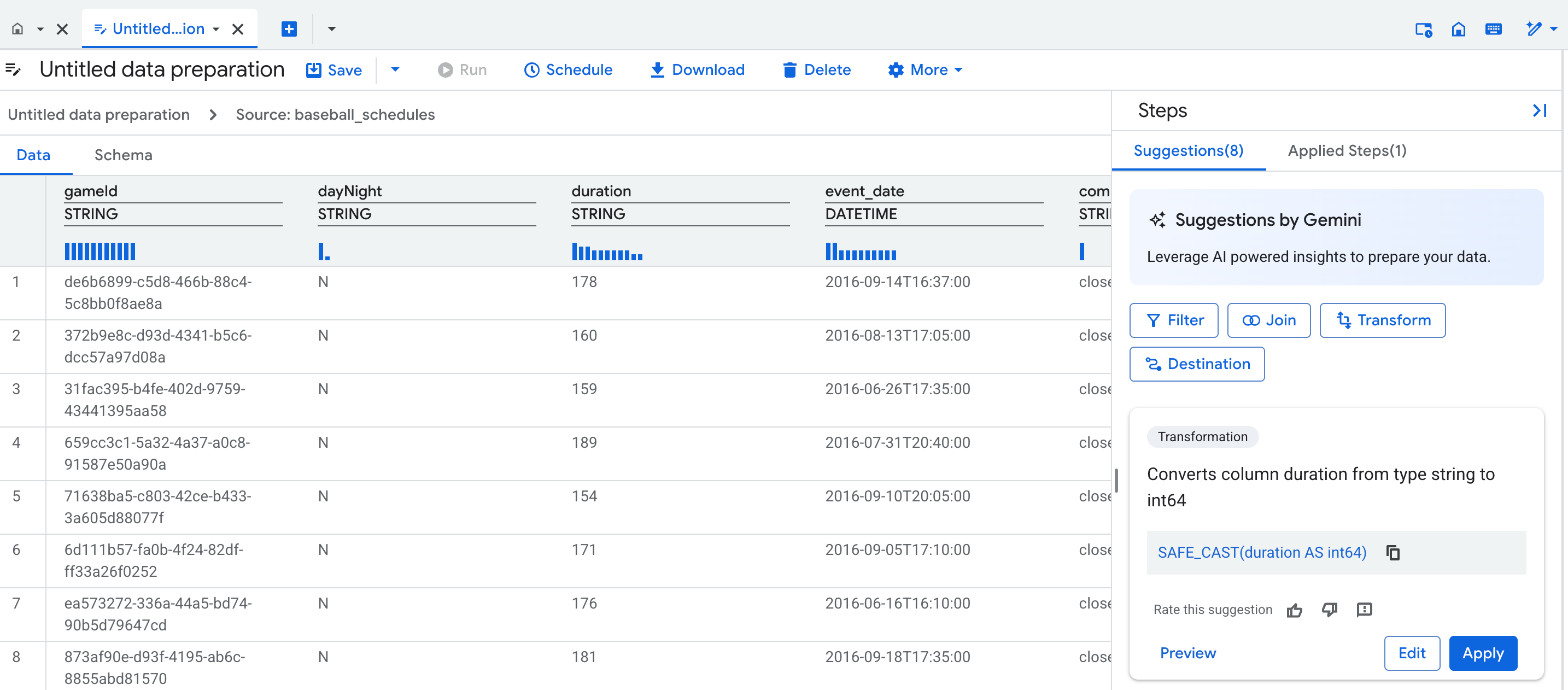
Vue Données
Lorsque vous créez une préparation des données, un onglet d'éditeur de préparation des données s'ouvre et affiche la vue des données, qui contient un échantillon représentatif du tableau. Pour les préparations de données existantes, vous pouvez accéder à la vue de données en cliquant sur un nœud dans la vue graphique de votre pipeline de préparation de données.
La vue Données vous permet d'effectuer les opérations suivantes :
- Interagissez avec vos données pour créer des étapes de préparation des données.
- Appliquez les suggestions de Gemini.
- Améliorez la qualité des suggestions Gemini en saisissant des exemples de valeurs dans les cellules.
Au-dessus de chaque colonne de votre tableau, un profil statistique (histogramme) indique le nombre de valeurs les plus fréquentes de chaque colonne dans les lignes d'aperçu.
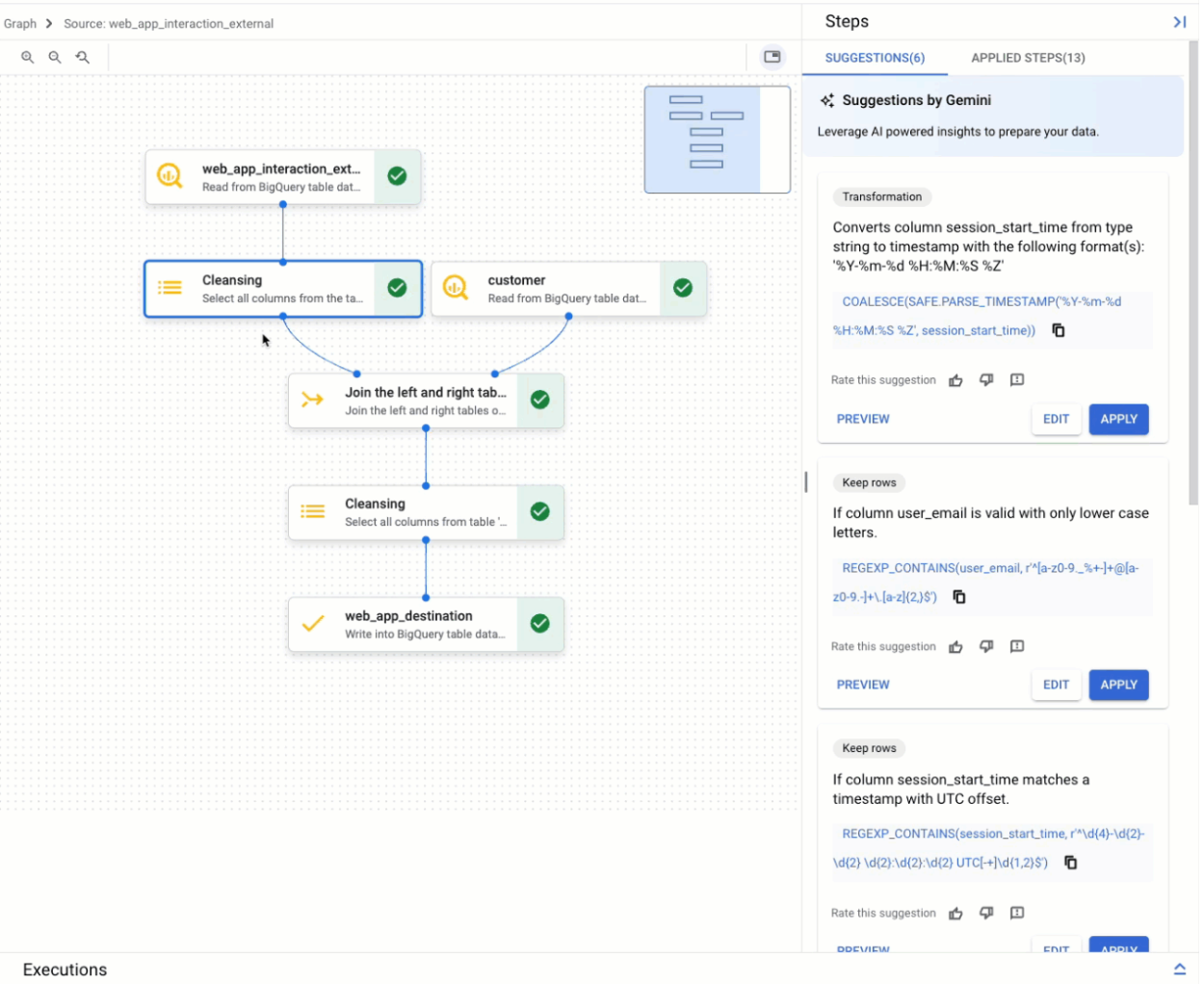
Vue graphique
La vue Graphique est un aperçu visuel de la préparation de vos données. Il s'affiche sous forme d'onglet sur la page BigQuery de la console lorsque vous ouvrez une préparation des données. Le graphique affiche les nœuds pour toutes les étapes de votre pipeline de préparation des données. Vous pouvez sélectionner un nœud du graphique pour configurer les étapes de préparation des données qu'il représente.
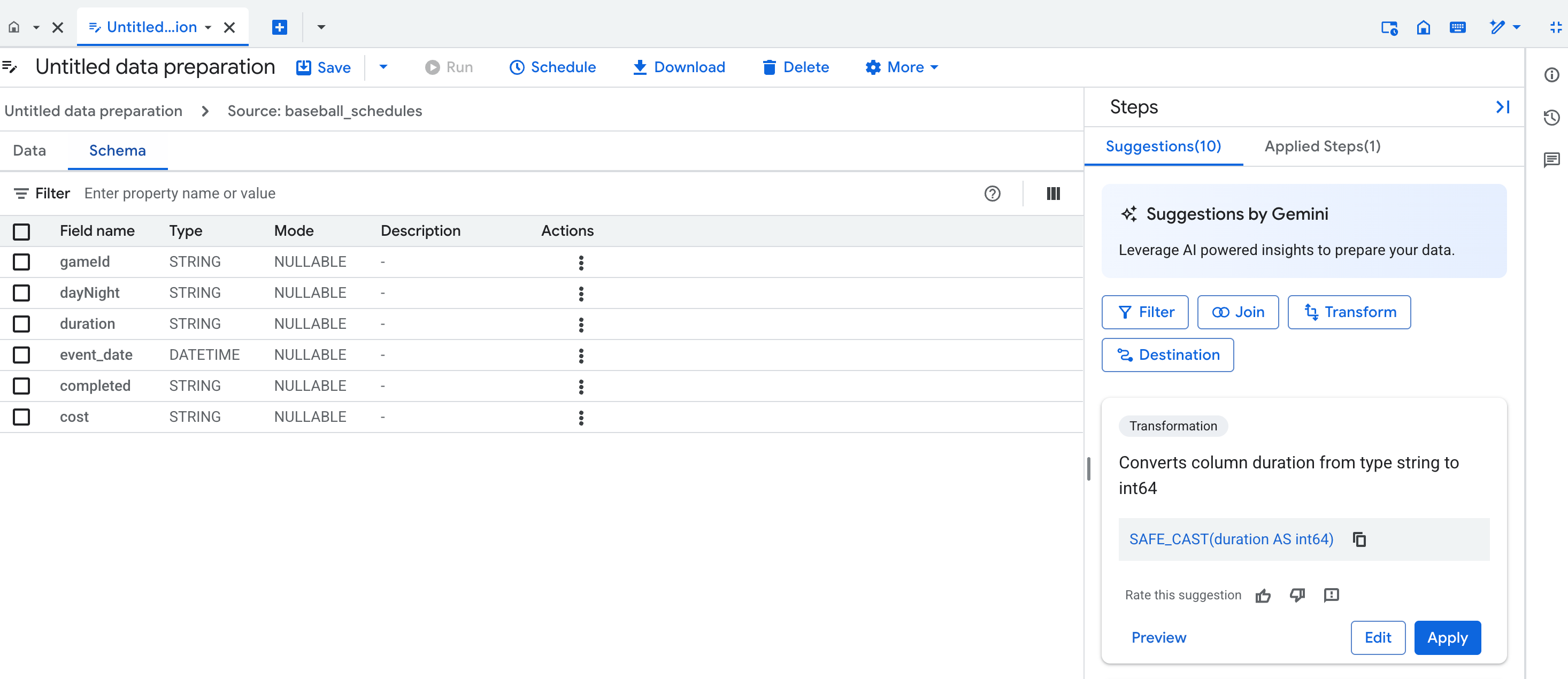
Vue Schéma
La vue du schéma de préparation des données affiche le schéma actuel de l'étape de préparation des données active. Le schéma affiché correspond aux colonnes de la vue de données.
Dans la vue Schéma, vous pouvez effectuer des opérations de schéma spécifiques, comme supprimer des colonnes, ce qui crée également des étapes dans la liste Étapes appliquées.
Suggestions de Gemini
Gemini fournit des suggestions contextuelles pour vous aider à effectuer les tâches de préparation des données suivantes :
- Appliquer des transformations et des règles de qualité des données
- Standardiser et enrichir les données
- Automatiser le mappage de schéma
Chaque suggestion s'affiche dans une fiche de la liste des suggestions de l'éditeur de préparation des données. La fiche contient les informations suivantes :
- Catégorie générale de l'étape, comme Conserver les lignes ou Transformation
- Description de l'étape, par exemple Conserver les lignes si
COLUMN_NAMEn'est pasNULL - Expression SQL correspondante utilisée pour exécuter l'étape
Vous pouvez prévisualiser, modifier ou appliquer la fiche de suggestion, ou affiner la suggestion. Vous pouvez également ajouter des étapes manuellement. Pour en savoir plus, consultez Préparer des données avec Gemini.
Pour affiner les suggestions de Gemini, donnez-lui un exemple de ce qu'il doit modifier dans une colonne.
Échantillonnage de données
BigQuery utilise l'échantillonnage des données pour fournir un aperçu de la préparation de vos données. Vous pouvez afficher l'échantillon dans la vue de données de chaque nœud.
Lorsque vous ajoutez des tables standards BigQuery comme source, les données sont préparées à l'aide d'une fonction TABLESAMPLE BigQuery. Cette fonction crée un échantillon de 10 000 enregistrements.
Lorsque vous ajoutez une vue ou une table externe comme source, le système lit le premier million d'enregistrements. À partir de ces enregistrements, le système sélectionne un échantillon représentatif de 10 000 enregistrements.
Les données de l'échantillon ne sont pas actualisées automatiquement. Les tables d'échantillons sont stockées sous forme de résultats de requêtes mis en cache et expirent au bout de 24 heures environ. Pour actualiser manuellement l'exemple de tableau, consultez Actualiser les exemples de préparation des données.
Mode d'écriture
Pour optimiser les coûts et le temps de traitement, vous pouvez modifier les paramètres du mode d'écriture afin de traiter de manière incrémentielle les nouvelles données de la source. Par exemple, si vous avez une table dans BigQuery où les enregistrements sont insérés quotidiennement et un tableau de bord Looker qui doit refléter les données modifiées, vous pouvez planifier la préparation des données BigQuery pour lire de manière incrémentielle les nouveaux enregistrements de la table source et les propager à la table de destination.
Pour configurer la façon dont la préparation de vos données est écrite dans une table de destination, consultez Optimiser la préparation des données en les traitant de manière incrémentielle.
Les modes d'écriture suivants sont acceptés :
| Option du mode d'écriture | Description |
|---|---|
| Actualisation complète | Effectue les étapes de préparation des données sur toutes les données sources, puis reconstruit entièrement la table de destination. La table est recréée, et non tronquée. L'actualisation complète est le mode par défaut lors de l'écriture dans une table de destination. |
| Ajouter | Insère toutes les données de la préparation des données sous forme de lignes supplémentaires dans la table de destination. |
| Incrémentielle | Insère uniquement les données nouvelles ou modifiées (selon la colonne incrémentielle choisie) dans la table de destination. En fonction de la colonne incrémentielle que vous avez choisie, la préparation des données sélectionnera le mécanisme de détection des enregistrements de modification optimal. Il sélectionne les valeurs maximales pour les types de données numériques et datetime, et les valeurs uniques pour les données catégorielles. "Maximum" n'insère que les enregistrements pour lesquels la valeur de la colonne spécifiée est supérieure à la valeur maximale de cette même colonne dans la table de destination. Les insertions uniques n'enregistrent que les enregistrements dont les valeurs de colonne spécifiées ne sont pas présentes dans les valeurs existantes de la même colonne dans la table de destination. |
Étapes de préparation des données prises en charge
BigQuery accepte les types d'étapes de préparation de données suivants :
| Type d'étape | Description |
|---|---|
| Source | Ajoute une source lorsque vous sélectionnez une table BigQuery à partir de laquelle lire les données ou lorsque vous ajoutez une étape de jointure. |
| Transformation | Nettoie et transforme les données à l'aide d'une expression SQL. Vous recevez des fiches de suggestions pour les expressions suivantes :
Vous pouvez également utiliser n'importe quelle expression SQL BigQuery valide dans les étapes de transformation manuelle. Par exemple :
Pour en savoir plus, consultez Ajouter une transformation. |
| Filtre | Supprime des lignes à l'aide de la syntaxe de la clause WHERE. Lorsque vous ajoutez une étape de filtre, vous pouvez choisir de la transformer en étape de validation.
Pour en savoir plus, consultez Filtrer les lignes. |
| Supprimer les doublons (aperçu) | Supprime les lignes en double des données en fonction des clés et de l'ordre sélectionnés.
Pour en savoir plus, consultez Dédupliquer les données. |
| Validation | Envoie les lignes qui ne respectent pas les critères de la règle de validation vers une table d'erreurs. Si les données ne respectent pas la règle de validation et qu'aucune table d'erreurs n'est configurée, la préparation des données échoue lors de l'exécution.
Pour en savoir plus, consultez Configurer la table des erreurs et ajouter une règle de validation. |
| Rejoindre | Joint les valeurs de deux sources. Les tables doivent se trouver au même emplacement.
Les colonnes de clés de jointure doivent être du même type de données. Les préparations de données sont compatibles avec les opérations de jointure suivantes :
Pour en savoir plus, consultez Ajouter une opération de jointure. |
| Destination | Définit une destination pour la sortie des étapes de préparation des données. Si vous saisissez une table de destination qui n'existe pas, la préparation des données crée une table à l'aide des informations du schéma actuel. Pour en savoir plus, consultez Ajouter ou modifier une table de destination. |
| Supprimer les colonnes | Supprime des colonnes du schéma. Vous effectuez cette étape depuis la vue Schéma.
Pour en savoir plus, consultez Supprimer une colonne. |
Planifier des exécutions de préparation des données
Pour exécuter les étapes de préparation des données et charger les données préparées dans la table de destination, créez un planning. Vous pouvez planifier des préparations de données depuis l'éditeur de préparation des données et les gérer depuis la page Planification de BigQuery. Pour en savoir plus, consultez Planifier des préparations de données.
Créer des pipelines avec des tâches de préparation des données
Vous pouvez créer des pipelines BigQuery composés de tâches de préparation des données, de requêtes SQL et de notebooks. Vous pouvez ensuite exécuter ces pipelines selon une planification. Pour en savoir plus, consultez Présentation des pipelines BigQuery.
Contrôler les accès
Contrôlez l'accès aux préparations de données à l'aide des rôles Identity and Access Management (IAM), du chiffrement avec les clés BigQuery et Dataform Cloud KMS, et de VPC Service Controls.
Rôles et autorisations IAM
Les utilisateurs qui préparent les données et les comptes de service Dataform qui exécutent les jobs ont besoin d'autorisations IAM. Pour en savoir plus, consultez Rôles requis et Configurer Gemini pour BigQuery.
Chiffrement avec des clés Cloud KMS
Chiffrez les données au niveau de l'ensemble de données ou du projet à l'aide des clés Cloud KMS par défaut gérées par le client dans BigQuery. Pour en savoir plus, consultez Définir une clé par défaut pour un ensemble de données et Définir une clé par défaut pour un projet.
Vous pouvez chiffrer le code du pipeline au niveau du projet par défaut à l'aide d'une clé Dataform Cloud KMS.
Périmètres VPC Service Controls
Si vous utilisez VPC Service Controls, vous devez configurer le périmètre pour protéger Dataform et BigQuery. Pour en savoir plus, consultez les limites de VPC Service Controls pour BigQuery et Dataform.
Limites
La préparation des données est disponible avec les limites suivantes :
- Tous les ensembles de données source et de destination de préparation des données BigQuery d'une préparation des données donnée doivent se trouver au même emplacement. Pour en savoir plus, consultez Emplacements.
- Lorsque vous modifiez un pipeline, les données et les interactions sont envoyées à un centre de données Gemini pour traitement. Pour en savoir plus, consultez Emplacements.
- Gemini dans BigQuery n'est pas compatible avec Assured Workloads.
- Les préparations de données BigQuery ne permettent pas d'afficher, de comparer ni de restaurer les versions de préparation de données.
- Les réponses de Gemini sont basées sur un échantillon de l'ensemble de données que vous fournissez lorsque vous concevez votre pipeline de préparation des données. Pour en savoir plus, consultez Utilisation de vos données par Gemini pour Google Cloud et les conditions du Programme Testeur de confiance de Gemini pour Google Cloud .
- La préparation de données BigQuery ne dispose pas de sa propre API. Pour connaître les API nécessaires, consultez Configurer Gemini dans BigQuery.
Emplacements
Vous pouvez utiliser la préparation des données dans n'importe quel emplacement BigQuery compatible. Vos jobs de traitement des données sont exécutés et stockés à l'emplacement de vos ensembles de données sources. Si un emplacement de dépôt est spécifié, il doit être identique à celui des ensembles de données sources. La région de stockage du code de préparation des données peut être différente de la région d'exécution du job.
Tous les composants de code dans BigQuery Studio utilisent la même région par défaut. Pour définir la région par défaut des composants de code, procédez comme suit :
Accédez à la page BigQuery.
Dans le volet Explorateur, recherchez le projet dans lequel vous avez activé des éléments de code.
Cliquez sur Afficher les actions à côté du projet, puis sur Modifier la région du code par défaut.
Dans Région, sélectionnez la région que vous souhaitez utiliser pour les composants de code.
Cliquez sur Sélectionner.
Pour obtenir la liste des régions compatibles, consultez Emplacements BigQuery Studio.
Gemini dans BigQuery fonctionne à l'échelle mondiale. Vous ne pouvez donc pas limiter le traitement des données Gemini à une région spécifique lorsque vous concevez vos préparations de données. Toutefois, le traitement des données BigQuery lors de la conception et de l'exécution est toujours effectué à l'emplacement de vos ensembles de données sources. Pour en savoir plus sur les emplacements où Gemini dans BigQuery traite les données, consultez Zones de mise en service de Gemini.
Tarifs
L'exécution de préparations de données et la création d'échantillons d'aperçu des données utilisent des ressources BigQuery, qui sont facturées selon les tarifs indiqués sur la page Tarifs de BigQuery.
La préparation des données est incluse dans les tarifs de Gemini dans BigQuery. Vous pouvez utiliser la préparation des données BigQuery en version Preview sans frais supplémentaires. Pour en savoir plus, consultez Configurer Gemini dans BigQuery.
Quotas
Pour en savoir plus, consultez les quotas pour Gemini dans BigQuery.
Étapes suivantes
- Découvrez comment préparer des données avec Gemini dans BigQuery.
- Découvrez comment exécuter des préparations de données manuellement ou avec un calendrier.