BigQuery 데이터 캔버스를 사용한 분석
이 문서에서는 데이터 분석에 데이터 캔버스를 사용하는 방법을 설명합니다. Dataplex를 사용하여 데이터 캔버스 메타데이터를 관리할 수도 있습니다.
BigQuery의 Gemini 기능인 BigQuery Studio 데이터 캔버스를 사용하면 자연어 프롬프트와 분석 워크플로용 그래픽 인터페이스를 통해 데이터를 찾고, 변환하고, 쿼리하고, 시각화할 수 있습니다.
분석 워크플로의 경우 BigQuery 데이터 캔버스는 워크플로의 그래픽 뷰를 제공하는 방향성 비순환 그래프(DAG)를 사용합니다. BigQuery 데이터 캔버스에서는 쿼리 결과를 반복하고 한 곳에서 여러 문의 브랜치로 작업할 수 있습니다.
BigQuery 데이터 캔버스는 분석 작업을 가속화하고 데이터 분석가, 데이터 엔지니어 등의 데이터 전문가가 데이터에서 유용한 정보로 이동하는 여정을 지원하도록 설계되었습니다. 특정 도구에 대한 기술적 지식이 없어도 되며 SQL 읽기 및 쓰기에 대한 기본적인 지식만 있으면 됩니다. BigQuery 데이터 캔버스는 Dataplex 메타데이터와 함께 작동하여 자연어를 기반으로 적절한 테이블을 식별합니다.
BigQuery 데이터 캔버스는 비즈니스 사용자가 직접 사용하는 용도가 아닙니다.
BigQuery 데이터 캔버스는 BigQuery의 Gemini를 사용하여 데이터를 찾고, SQL을 만들고, 차트를 생성하고, 데이터 요약을 만듭니다.
Google Cloud 용 Gemini에서 사용자의 데이터를 사용하는 방법과 시점을 알아보세요.
기능
BigQuery 데이터 캔버스를 사용하면 다음 작업을 할 수 있습니다.
Dataplex 메타데이터와 함께 자연어 쿼리 또는 키워드 검색 구문을 사용하여 테이블, 뷰 또는 구체화된 뷰와 같은 애셋을 찾습니다.
다음과 같은 기본 SQL 쿼리에 자연어를 사용합니다.
FROM절, 수학 함수, 배열, 구조체가 포함된 쿼리- 두 테이블의
JOIN작업
다음 그래픽 유형을 사용하여 데이터를 시각화합니다.
- 막대 차트
- 히트맵
- 선 그래프
- 원형 차트
- 분산형 차트
원하는 내용을 자연어로 설명하여 커스텀 시각화를 만듭니다.
데이터 통계 자동화
제한사항
다음과 같은 경우에는 자연어 명령이 제대로 작동하지 않을 수 있습니다.
- BigQuery ML
- Apache Spark
- 객체 테이블
- BigLake
- 조회수
INFORMATION_SCHEMA회 - JSON
- 중첩되고 반복되는 필드
- 복잡한 함수 및 데이터 유형(예:
DATETIME및TIMEZONE)
데이터 시각화는 Geomap 차트에서 작동하지 않습니다.
프롬프트 권장사항
적절한 프롬프트 기법을 사용하면 복잡한 SQL 쿼리를 생성할 수 있습니다. 다음 제안은 BigQuery 데이터 캔버스에서 자연어 프롬프트를 미세 조정하여 쿼리의 정확성을 높이는 데 도움이 됩니다.
명확하게 작성합니다. 요청을 명확하게 서술하고 모호하게 표현하지 마세요.
직접적으로 질문하세요. 가장 정확한 답변을 얻으려면 한 번에 하나의 질문을 하고 프롬프트는 간결하게 유지하세요. 필요한 경우 BigQuery 데이터 캔버스에서 프롬프트를 여러 노드로 구분합니다.
중점적으로 명확한 지침을 주세요. 프롬프트에서 주요 용어를 강조합니다.
작업 순서를 지정합니다. 명확하고 체계적인 방식으로 지침을 제공합니다. 작업을 집중적으로 수행할 수 있는 작은 단계로 나눕니다.
수정하고 반복하세요. 다양한 문구와 접근 방식을 시도하여 가장 좋은 결과를 얻는 방법을 알아보세요.
자세한 내용은 BigQuery 데이터 캔버스 프롬프트 권장사항을 참조하세요.
시작하기 전에
- BigQuery의 Gemini가 Google Cloud 프로젝트에 사용 설정되어 있는지 확인합니다. 일반적으로 관리자가 이 단계를 실행합니다.
- BigQuery 데이터 캔버스를 사용하기 위한 필요한 Identity and Access Management(IAM) 권한이 있는지 확인합니다.
- Dataplex에서 데이터 캔버스 메타데이터를 관리하려면 Google Cloud 프로젝트에서 Dataplex API가 사용 설정되어 있는지 확인합니다.
필요한 역할
BigQuery 데이터 캔버스를 사용하는 데 필요한 권한을 얻으려면 관리자에게 프로젝트에 대한 다음 IAM 역할을 부여해 달라고 요청하세요.
-
BigQuery Studio 사용자(
roles/bigquery.studioUser) -
Google Cloud를 위한 Gemini 사용자(
roles/cloudaicompanion.user)
역할 부여에 대한 자세한 내용은 프로젝트, 폴더, 조직에 대한 액세스 관리를 참조하세요.
커스텀 역할이나 다른 사전 정의된 역할을 통해 필요한 권한을 얻을 수도 있습니다.
BigQuery에서 IAM 역할 및 권한에 대한 자세한 내용은 IAM 소개를 참조하세요.
Dataplex에서 데이터 캔버스 메타데이터를 관리하려면 필요한 Dataplex 역할과 dataform.repository.get 권한이 있는지 확인합니다.
BigQuery 데이터 캔버스 사용
Google Cloud 콘솔, 쿼리 또는 테이블에서 BigQuery 데이터 캔버스를 사용할 수 있습니다.
BigQuery 페이지로 이동합니다.
쿼리 편집기에서 SQL 쿼리 옆에 있는 새로 만들기를 클릭한 다음 데이터 캔버스를 클릭합니다.
자연어 프롬프트 필드에 자연어 프롬프트를 입력합니다.
예를 들어
Find me tables related to trees를 입력하면 BigQuery 데이터 캔버스는bigquery-public-data.usfs_fia.plot_tree또는bigquery-public-data.new_york_trees.tree_species와 같은 공개 데이터 세트를 포함하여 가능한 테이블 목록을 반환합니다.테이블을 선택하세요.
선택한 테이블의 테이블 노드가 BigQuery 데이터 캔버스에 추가됩니다. 스키마 정보를 보거나 테이블 세부정보를 보거나 데이터를 미리 보려면 테이블 노드에서 다양한 탭을 선택하세요.
예시 워크플로 사용해 보기
이 섹션에서는 분석 워크플로에서 BigQuery 데이터 캔버스를 사용하는 다양한 방법을 보여줍니다.
워크플로 예시: 데이터 찾기, 쿼리, 시각화
이 예시에서는 BigQuery 데이터 캔버스의 자연어 프롬프트를 사용하여 데이터를 찾고, 쿼리를 생성하고, 쿼리를 수정합니다. 그런 다음 차트를 만듭니다.
프롬프트 1: 데이터 찾기
Google Cloud 콘솔에서 BigQuery 페이지로 이동합니다.
쿼리 편집기에서 SQL 쿼리 옆에 있는 새로 만들기를 클릭한 다음 데이터 캔버스를 클릭합니다.
자연어 프롬프트 필드에 다음 자연어 프롬프트를 입력합니다.
Chicago taxi tripsBigQuery 데이터 캔버스는 Dataplex 메타데이터를 기반으로 가능한 테이블 목록을 생성합니다. 여러 테이블을 선택할 수 있습니다.
bigquery-public-data.chicago_taxi_trips.taxi_trips테이블을 선택한 다음 캔버스에 추가를 클릭합니다.taxi_trips의 테이블 노드가 BigQuery 데이터 캔버스에 추가됩니다. 스키마 정보를 보거나 테이블 세부정보를 보거나 데이터를 미리 보려면 테이블 노드에서 다양한 탭을 선택하세요.
프롬프트 2: 선택한 테이블에서 SQL 쿼리 생성
bigquery-public-data.chicago_taxi_trips.taxi_trips 테이블의 SQL 쿼리를 생성하려면 다음을 수행합니다.
데이터 캔버스에서 쿼리를 클릭합니다.
자연어 프롬프트 필드에 다음을 입력합니다.
Get me the 100 longest tripsBigQuery 데이터 캔버스는 다음과 유사한 SQL 쿼리를 생성합니다.
SELECT taxi_id, trip_start_timestamp, trip_end_timestamp, trip_miles FROM `bigquery-public-data.chicago_taxi_trips.taxi_trips` ORDER BY trip_miles DESC LIMIT 100;
프롬프트 3: 쿼리 수정
생성한 쿼리를 수정하려면 쿼리를 수동으로 수정하거나 자연어 프롬프트를 변경하고 쿼리를 다시 생성하면 됩니다. 이 예시에서는 자연어 프롬프트를 사용하여 고객이 현금으로 결제한 이동만 선택하도록 쿼리를 수정합니다.
자연어 프롬프트 필드에 다음을 입력합니다.
Get me the 100 longest trips where the payment type is cashBigQuery 데이터 캔버스는 다음과 유사한 SQL 쿼리를 생성합니다.
SELECT taxi_id, trip_start_timestamp, trip_end_timestamp, trip_miles FROM `PROJECT_ID.chicago_taxi_trips_123123.taxi_trips` WHERE payment_type = 'Cash' ORDER BY trip_miles DESC LIMIT 100;
위 예시에서
PROJECT_ID는 Google Cloud 프로젝트의 ID입니다.쿼리 결과를 보려면 실행을 클릭합니다.
차트 만들기
- 데이터 캔버스에서 시각화를 클릭합니다.
막대 그래프 만들기를 클릭합니다.
BigQuery 데이터 캔버스는 이동 ID별로 가장 많은 이동 거리를 보여주는 막대 그래프를 만듭니다. BigQuery 데이터 캔버스는 차트를 제공하는 것 외에도 시각화를 뒷받침하는 데이터의 일부 주요 세부정보를 요약합니다.
선택사항: 다음 중 하나 이상을 수행합니다.
- 차트를 수정하려면 수정을 클릭한 다음 시각화 수정 창에서 차트를 수정합니다.
- 데이터 캔버스를 공유하려면 공유를 클릭한 다음 링크 공유를 클릭하여 BigQuery 데이터 캔버스 링크를 복사합니다.
- 데이터 캔버스를 정리하려면 작업 더보기를 선택한 다음 캔버스 지우기를 선택합니다. 이 단계를 완료하면 빈 캔버스가 표시됩니다.
워크플로 예시: 테이블 조인
이 예시에서는 BigQuery 데이터 캔버스의 자연어 프롬프트를 사용하여 데이터를 찾고 테이블을 조인합니다. 그런 다음 쿼리를 노트북으로 내보냅니다.
프롬프트 1: 데이터 찾기
자연어 프롬프트 필드에 다음 프롬프트를 입력합니다.
Information about treesBigQuery 데이터 캔버스에는 나무에 관한 정보가 포함된 여러 테이블이 표시됩니다.
이 예시에서는
bigquery-public-data.new_york_trees.tree_census_1995테이블을 선택한 다음 캔버스에 추가를 클릭합니다.테이블이 캔버스에 표시됩니다.
프롬프트 2: 주소에 따라 테이블 조인
데이터 캔버스에서 조인을 클릭합니다.
BigQuery 데이터 캔버스에서 조인할 테이블을 추천합니다.
새 자연어 프롬프트 필드를 열려면 테이블 검색을 클릭합니다.
자연어 프롬프트 필드에 다음 프롬프트를 입력합니다.
Information about treesbigquery-public-data.new_york_trees.tree_census_2005테이블을 선택한 다음 캔버스에 추가를 클릭합니다.테이블이 캔버스에 표시됩니다.
데이터 캔버스에서 조인을 클릭합니다.
이 캔버스 섹션에서 테이블 셀 체크박스를 선택한 다음 확인을 클릭합니다.
자연어 프롬프트 필드에 다음 프롬프트를 입력합니다.
Join on addressBigQuery 데이터 캔버스는 주소를 기준으로 두 테이블을 조인하는 SQL 쿼리를 제안합니다.
SELECT * FROM `bigquery-public-data.new_york_trees.tree_census_2015` AS t2015 JOIN `bigquery-public-data.new_york_trees.tree_census_1995` AS t1995 ON t2015.address = t1995.address;
쿼리를 실행하고 결과를 보려면 실행을 클릭합니다.
쿼리를 노트북으로 내보내기
BigQuery 데이터 캔버스를 사용하면 쿼리를 노트북으로 내보낼 수 있습니다.
- 데이터 캔버스에서 노트북으로 내보내기를 클릭합니다.
- 노트북 저장 창에서 노트북의 이름과 저장할 리전을 입력합니다.
- 저장을 클릭합니다. 노트북이 생성됩니다.
- 선택사항: 만든 노트북을 보려면 열기를 클릭합니다.
워크플로 예시: 프롬프트를 사용하여 차트 수정
이 예시에서는 BigQuery 데이터 캔버스의 자연어 프롬프트를 사용하여 데이터를 찾고, 쿼리하고, 필터링한 다음 시각화 세부정보를 수정합니다.
프롬프트 1: 데이터 찾기
미국 이름에 관한 데이터를 찾으려면 다음 프롬프트를 입력합니다.
Find data about USA namesBigQuery 데이터 캔버스에서 테이블 목록이 생성됩니다.
이 예시에서는
bigquery-public-data.usa_names.usa_1910_current테이블을 선택한 다음 캔버스에 추가를 클릭합니다.
프롬프트 2: 데이터 쿼리
데이터를 쿼리하려면 데이터 캔버스에서 쿼리를 클릭하고 다음 프롬프트를 입력합니다.
Summarize this dataBigQuery 데이터 캔버스는 다음과 유사한 쿼리를 생성합니다.
SELECT state, gender, year, name, number FROM `bigquery-public-data.usa_names.usa_1910_current`
실행을 클릭합니다. 쿼리 결과가 표시됩니다.
프롬프트 3: 데이터 필터링
- 데이터 캔버스에서 결과 쿼리를 클릭합니다.
데이터를 필터링하려면 SQL 프롬프트 필드에 다음 프롬프트를 입력합니다.
Get me the top 10 most popular names in 1980BigQuery 데이터 캔버스는 다음과 유사한 쿼리를 생성합니다.
SELECT name, SUM(number) AS total_count FROM `bigquery-public-data`.usa_names.usa_1910_current WHERE year = 1980 GROUP BY name ORDER BY total_count DESC LIMIT 10;
쿼리를 실행하면 1980년에 태어난 아이의 가장 흔한 이름 10개가 포함된 테이블이 표시됩니다.
차트 만들기 및 수정
데이터 캔버스에서 시각화를 클릭합니다.
BigQuery 데이터 캔버스에서는 막대 그래프, 원형 차트, 선 그래프, 커스텀 시각화 등 여러 시각화 옵션을 제안합니다.
이 예시에서는 막대 그래프 만들기를 클릭합니다.
BigQuery 데이터 캔버스는 다음과 유사한 막대 그래프를 만듭니다.
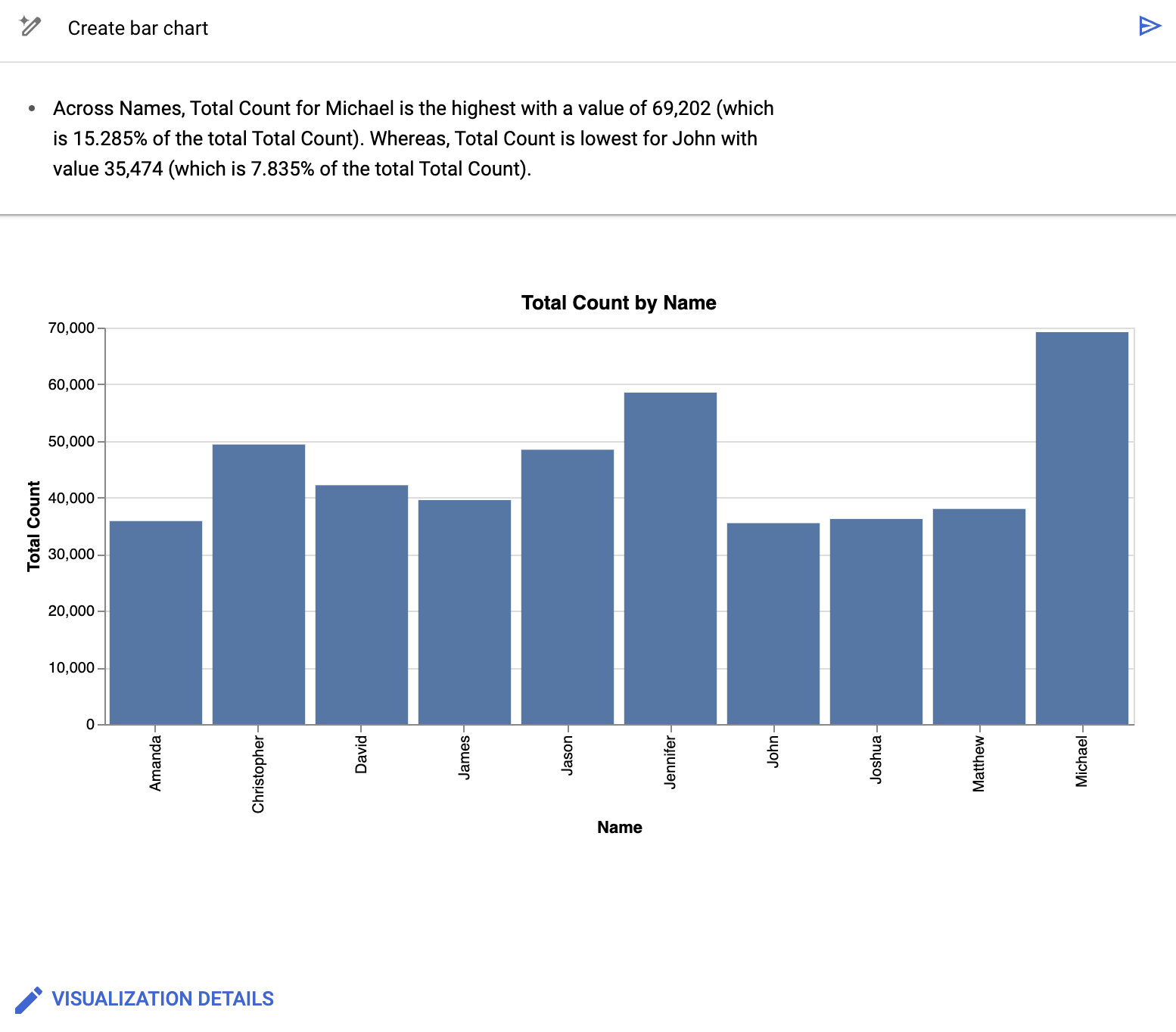
BigQuery 데이터 캔버스는 차트를 제공하는 것 외에도 시각화를 뒷받침하는 데이터의 일부 주요 세부정보를 요약합니다. 시각화 세부정보를 클릭하고 측면 패널에서 차트를 수정하여 차트를 수정할 수 있습니다.
프롬프트 4: 시각화 세부정보 수정
시각화 프롬프트 필드에 다음을 입력합니다.
Create a bar chart sorted high to low, with a gradientBigQuery 데이터 캔버스는 다음과 유사한 막대 그래프를 만듭니다.
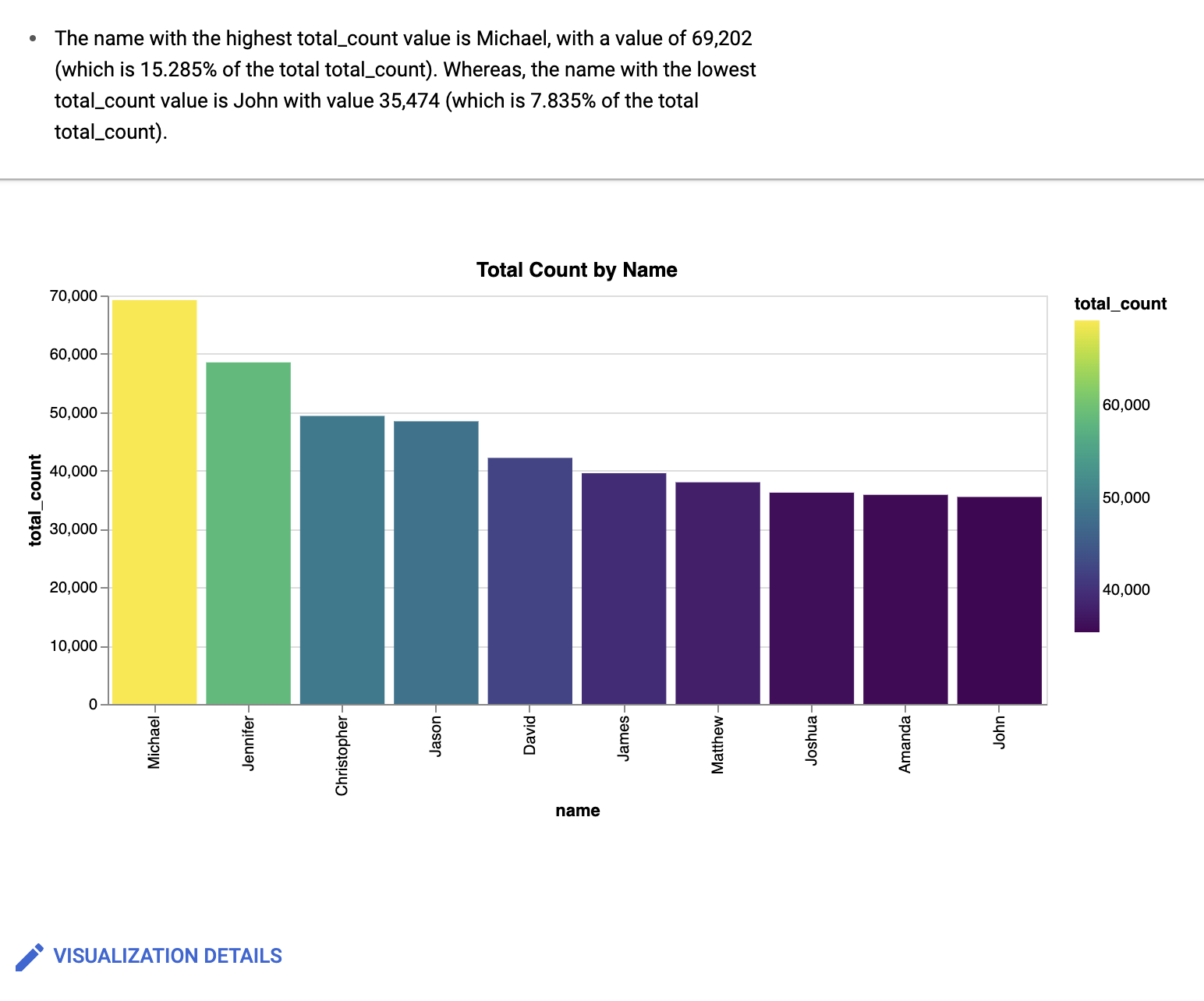
선택사항: 추가로 변경하려면 수정을 클릭합니다.
시각화 수정 창이 표시됩니다. 차트 제목, x축 이름, y축 이름과 같은 세부정보를 수정할 수 있습니다. 또한 JSON 편집기 탭을 클릭하면 JSON 값을 기반으로 차트를 직접 수정할 수 있습니다.
모든 데이터 캔버스 보기
프로젝트의 모든 데이터 캔버스 목록을 보려면 다음 단계를 따르세요.
Google Cloud 콘솔에서 BigQuery 페이지로 이동합니다.
탐색기 창에서 데이터 캔버스 옆에 있는 작업 보기를 클릭한 후 다음 중 하나를 수행합니다.
- 현재 탭에서 목록을 열려면 모두 표시를 클릭합니다.
- 목록을 새 탭에서 열려면 모두 표시 > 새 탭을 클릭합니다.
- 분할 탭에서 목록을 열려면 모두 표시 > 분할 탭을 클릭합니다.
데이터 캔버스 메타데이터 보기
데이터 캔버스 메타데이터를 보려면 다음 단계를 따르세요.
Google Cloud 콘솔에서 BigQuery 페이지로 이동합니다.
탐색기 창에서 프로젝트와 데이터 캔버스 폴더를 펼치고 필요한 경우 공유 데이터 캔버스 폴더를 펼칩니다. 메타데이터를 보려는 데이터 캔버스의 이름을 클릭합니다.
요약 창에서 사용되는 리전 및 마지막으로 수정된 날짜 등 데이터 캔버스에 대한 정보를 확인합니다.
데이터 캔버스 버전 지원
데이터 캔버스의 버전을 보고, 비교하고, 복원할 수 있습니다.
데이터 캔버스 버전 보기 및 비교
데이터 캔버스의 여러 버전을 보고 현재 버전과 비교하려면 다음 단계를 따르세요.
Google Cloud 콘솔에서 BigQuery 페이지로 이동합니다.
탐색기 창에서 프로젝트와 데이터 캔버스 폴더를 펼치고 필요한 경우 공유 데이터 캔버스 폴더를 펼칩니다. 활동을 보려는 데이터 캔버스의 이름을 클릭합니다.
활동 탭을 클릭하여 날짜 기준 내림차순으로 정렬된 데이터 캔버스 버전 목록을 확인합니다.
데이터 캔버스 버전 옆에 있는 작업 보기를 클릭한 다음 비교를 클릭합니다. 선택한 데이터 캔버스 버전을 현재 데이터 캔버스 버전과 비교하는 비교 창이 열립니다.
(선택사항): 별도의 창 대신 버전을 인라인 비교하려면 비교를 클릭한 다음 인라인을 클릭합니다.
데이터 캔버스 버전 복원
다음 옵션 중 하나를 사용하여 데이터 캔버스 버전을 복원합니다. 비교 창에서 복원하면 복원 여부를 선택하기 전에 데이터 캔버스의 이전 버전을 현재 버전과 비교할 수 있습니다.
활동 창
- 탐색기 창에서 프로젝트와 데이터 캔버스 폴더를 펼치고 필요한 경우 공유 데이터 캔버스 폴더를 펼칩니다. 이전 버전을 복원할 데이터 캔버스의 이름을 클릭합니다.
- 활동 창을 선택합니다.
- 복원할 데이터 캔버스 버전 옆에 있는 작업 보기를 클릭한 후 복원을 클릭합니다.
- 확인을 클릭하여 작업을 확인합니다.
비교 창
- 탐색기 창에서 프로젝트와 데이터 캔버스 폴더를 펼치고 필요한 경우 공유 데이터 캔버스 폴더를 펼칩니다. 이전 버전을 복원할 데이터 캔버스의 이름을 클릭합니다.
- 활동 창을 선택합니다.
- 데이터 캔버스 버전 옆에 있는 작업 보기를 클릭한 다음 비교를 클릭합니다. 선택한 데이터 캔버스 버전을 가장 최근 데이터 캔버스 버전과 비교하는 비교 창이 열립니다.
- 비교한 후 이전 데이터 캔버스 버전을 복원하려면 복원을 클릭합니다.
- 확인을 클릭하여 작업을 확인합니다.
Dataplex에서 메타데이터 관리
Dataplex를 사용하면 데이터 캔버스의 메타데이터를 보고 관리할 수 있습니다. 데이터 캔버스는 추가 구성 없이 기본적으로 Dataplex에서 사용할 수 있습니다.
Dataplex를 사용하여 모든 BigQuery 위치에서 데이터 캔버스를 관리할 수 있습니다. Dataplex에서 데이터 캔버스를 관리하는 경우 Dataplex 할당량 및 한도와 Dataplex 가격 책정이 적용됩니다.
Dataplex는 데이터 캔버스에서 다음 메타데이터를 자동으로 검색합니다.
- 데이터 애셋 이름
- 데이터 애셋 상위 항목
- 데이터 애셋 위치
- 데이터 애셋 유형
- 해당 Google Cloud 프로젝트
Dataplex는 데이터 캔버스를 다음 항목 값을 사용해 항목으로 로깅합니다.
- 시스템 항목 그룹
- 데이터 캔버스의 시스템 항목 그룹은
@dataform입니다. Dataplex에서 데이터 캔버스 항목의 세부정보를 보려면dataform시스템 항목 그룹을 확인해야 합니다. 항목 그룹의 모든 항목 목록을 보는 방법에 관한 안내는 Dataplex 문서의 항목 그룹 세부정보 보기를 참조하세요. - 시스템 항목 유형
- 데이터 캔버스의 시스템 항목 유형은
dataform-code-asset입니다. 데이터 캔버스의 세부정보를 보려면dataform-code-asset시스템 항목 유형을 확인하고, 관점 기반 필터로 결과를 필터링하고,dataform-code-asset관점 내의type필드를DATA_CANVAS로 설정해야 합니다. 그런 다음 선택한 데이터 캔버스의 항목을 선택합니다. 선택한 항목 유형의 세부정보를 보는 방법에 관한 안내는 Dataplex 문서의 항목 유형의 세부정보 보기를 참조하세요. 선택한 항목의 세부정보를 보는 방법에 관한 안내는 Dataplex 문서의 항목 세부정보 보기를 참조하세요. - 시스템 관점 유형
- 데이터 캔버스의 시스템 관점 유형은
dataform-code-asset입니다. 관점으로 데이터 캔버스 항목에 주석을 추가하여 Dataplex의 데이터 캔버스에 추가 컨텍스트를 제공하려면dataform-code-asset관점 유형을 확인하고 관점 기반 필터로 결과를 필터링한 다음dataform-code-asset관점 내의type필드를DATA_CANVAS로 설정합니다. 관점으로 항목에 주석을 추가하는 방법에 관한 안내는 Dataplex 문서의 관점 관리 및 메타데이터 보강을 참조하세요. - 유형
- 데이터 캔버스의 유형은
DATA_CANVAS입니다. 이 유형을 사용하면 관점 기반 필터에서aspect:dataplex-types.global.dataform-code-asset.type=DATA_CANVAS쿼리를 사용하여dataform-code-asset시스템 항목 유형 및dataform-code-asset관점 유형의 데이터 캠버스를 필터링할 수 있습니다.
Dataplex에서 애셋을 검색하는 방법에 관한 안내는 Dataplex 문서의 Dataplex에서 데이터 애셋 검색을 참조하세요.
가격 책정
이 기능의 가격 책정에 관한 자세한 내용은 BigQuery의 Gemini 가격 책정 개요를 참고하세요.
할당량 및 한도
이 기능의 할당량 및 한도에 대한 자세한 내용은 BigQuery의 Gemini 할당량을 참조하세요.
의견 보내기
Google에 의견을 제출하여 BigQuery 데이터 캔버스 제안을 개선할 수 있습니다. 의견을 제공하려면 다음 단계를 따르세요.
Google Cloud 콘솔 툴바에서 의견 제출을 클릭합니다.
선택사항: DAG JSON 정보를 복사하여 의견에 추가 컨텍스트를 제공하려면 복사를 클릭합니다.
양식을 작성하고 의견을 제공하려면 양식을 클릭합니다.
데이터 공유 설정은 전체 프로젝트에 적용되며 serviceusage.services.enable 및 serviceusage.services.list IAM 권한이 있는 프로젝트 관리자만 이 설정을 설정할 수 있습니다. 신뢰할 수 있는 테스터 프로그램에서 데이터 사용에 대한 자세한 내용은 Google Cloud 신뢰할 수 있는 테스터 프로그램의 Gemini를 참조하세요.
이 기능에 대한 직접적인 의견을 제공하려면 datacanvas-feedback@google.com으로 문의하세요.
다음 단계
Gemini 지원으로 쿼리를 작성하는 방법을 알아보세요.
노트북을 만드는 방법 알아보기