Membuat model machine learning di BigQuery ML
Tutorial ini menunjukkan cara membuat model regresi logistik menggunakan BigQuery ML di konsol Google Cloud.
BigQuery ML memungkinkan Anda membuat dan melatih model machine learning di BigQuery menggunakan kueri SQL. Hal ini membantu membuat machine learning lebih mudah diakses dengan memungkinkan Anda menggunakan alat yang sudah dikenal seperti editor SQL BigQuery, dan juga meningkatkan kecepatan pengembangan dengan meniadakan kebutuhan untuk memindahkan data ke lingkungan machine learning terpisah.
Dalam tutorial ini, Anda akan menggunakan contoh set data contoh Google Analytics untuk BigQuery untuk membuat model yang memprediksi apakah pengunjung situs akan melakukan transaksi atau tidak. Untuk mendapatkan informasi tentang skema set data Analytics, lihat skema BigQuery Export di Pusat Bantuan Analytics.
Tujuan
Tutorial ini menunjukkan cara melakukan tugas-tugas berikut:
- Menggunakan
pernyataan
CREATE MODELuntuk membuat model regresi logistik biner. - Menggunakan
fungsi
ML.EVALUATEuntuk mengevaluasi model. - Menggunakan
fungsi
ML.PREDICTuntuk membuat prediksi menggunakan model.
Biaya
Tutorial ini menggunakan komponen Google Cloud yang dapat dikenai biaya, termasuk:
- BigQuery
- BigQuery ML
Untuk informasi selengkapnya tentang biaya BigQuery, lihat halaman harga BigQuery.
Untuk informasi selengkapnya tentang biaya BigQuery ML, lihat harga BigQuery ML.
Sebelum memulai
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
- BigQuery secara otomatis diaktifkan dalam project baru.
Untuk mengaktifkan BigQuery dalam project yang sudah ada, buka
Enable the BigQuery API.
Membuat set data
Buat set data BigQuery untuk menyimpan model ML Anda:
Di konsol Google Cloud, buka halaman BigQuery.
Di panel Explorer, klik nama project Anda.
Klik View actions > Create dataset.
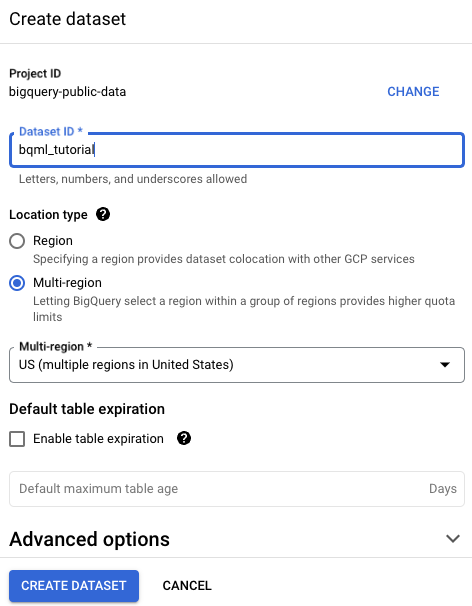
Di halaman Create dataset, lakukan hal berikut:
Untuk Dataset ID, masukkan
bqml_tutorial.Untuk Location type, pilih Multi-region, lalu pilih US (multiple regions in United States).
Set data publik disimpan di
USmulti-region. Untuk mempermudah, simpan set data Anda di lokasi yang sama.Jangan ubah setelan default yang tersisa, lalu klik Create dataset.
Membuat model regresi logistik
Buat model regresi logistik menggunakan set data contoh Analytics untuk BigQuery.
SQL
Di Konsol Google Cloud, buka halaman BigQuery.
Di editor kueri, jalankan pernyataan berikut:
CREATE OR REPLACE MODEL `bqml_tutorial.sample_model` OPTIONS(model_type='logistic_reg') AS SELECT IF(totals.transactions IS NULL, 0, 1) AS label, IFNULL(device.operatingSystem, "") AS os, device.isMobile AS is_mobile, IFNULL(geoNetwork.country, "") AS country, IFNULL(totals.pageviews, 0) AS pageviews FROM `bigquery-public-data.google_analytics_sample.ga_sessions_*` WHERE _TABLE_SUFFIX BETWEEN '20160801' AND '20170630'
Kueri membutuhkan waktu beberapa menit hingga selesai. Setelah iterasi pertama selesai, model Anda (
sample_model) akan muncul di panel navigasi. Karena kueri menggunakan pernyataanCREATE MODELuntuk membuat model, Anda tidak akan melihat hasil kueri.
Detail kueri
Pernyataan CREATE MODEL membuat model, lalu melatih model
menggunakan data yang diambil oleh pernyataan SELECT kueri Anda.
Klausa OPTIONS(model_type='logistic_reg') membuat model regresi logistik. Model
regresi logistik membagi data input menjadi dua class, lalu
memperkirakan probabilitas bahwa data tersebut berada dalam salah satu class. Hal yang ingin Anda
deteksi, seperti apakah email adalah spam, diwakili oleh 1 dan
nilai lainnya diwakili oleh 0. Kemungkinan nilai tertentu yang termasuk dalam class yang Anda coba deteksi ditunjukkan dengan nilai antara 0 dan 1.
Misalnya, jika email menerima estimasi probabilitas 0,9, berarti ada
probabilitas 90% bahwa email tersebut adalah spam.
Pernyataan SELECT kueri ini mengambil kolom berikut yang digunakan
oleh model untuk memprediksi probabilitas pelanggan akan menyelesaikan
transaksi:
totals.transactions: jumlah total transaksi e-commerce dalam sesi. Jika jumlah transaksi adalahNULL, maka nilai dalam kolomlabelditetapkan ke0. Jika tidak, nilai ini akan ditetapkan ke1. Nilai-nilai ini mewakili kemungkinan hasil. Membuat alias bernamalabelmerupakan alternatif untuk menyetel opsiinput_label_cols=dalam pernyataanCREATE MODEL.device.operatingSystem: sistem operasi perangkat pengunjung.device.isMobile— Menunjukkan apakah perangkat pengunjung adalah perangkat seluler.geoNetwork.country: negara tempat sesi berasal, berdasarkan alamat IP.totals.pageviews: jumlah total kunjungan halaman dalam sesi.
Klausa FROM — menyebabkan kueri melatih model menggunakan
tabel sampel bigquery-public-data.google_analytics_sample.ga_sessions.
Tabel ini di-sharding berdasarkan tanggal, sehingga Anda menggabungkannya menggunakan karakter pengganti dalam
nama tabel: google_analytics_sample.ga_sessions_*.
Klausa WHERE — _TABLE_SUFFIX BETWEEN '20160801' AND '20170630'
— membatasi jumlah tabel yang dipindai oleh kueri. Rentang tanggal
yang dipindai adalah 1 Agustus 2016 hingga 30 Juni 2017.
DataFrame BigQuery
Sebelum mencoba contoh ini, ikuti petunjuk penyiapan BigQuery DataFrames di panduan memulai BigQuery menggunakan BigQuery DataFrames. Untuk mengetahui informasi selengkapnya, lihat dokumentasi referensi BigQuery DataFrames.
Untuk melakukan autentikasi ke BigQuery, siapkan Kredensial Default Aplikasi. Untuk informasi selengkapnya, lihat Menyiapkan ADC untuk lingkungan pengembangan lokal.
Melihat statistik kerugian model
Machine learning berfokus pada membuat model yang dapat menggunakan data untuk membuat prediksi. Model ini pada dasarnya adalah fungsi yang mengambil input dan menerapkan kalkulasi ke input untuk menghasilkan output, yaitu prediksi.
Algoritma machine learning bekerja dengan mengambil beberapa contoh yang prediksinya sudah diketahui (seperti data historis pembelian pengguna) dan secara berulang menyesuaikan berbagai bobot dalam model sehingga prediksi model cocok dengan nilai sebenarnya. Hal ini dilakukan dengan meminimalkan seberapa salah model menggunakan metrik yang disebut kerugian.
Untuk setiap iterasi, kerugiannya harus berkurang, idealnya ke nol. Jika kerugian bernilai nol, berarti model 100% akurat.
Saat melatih model, BigQuery ML secara otomatis membagi data input menjadi set pelatihan dan evaluasi, untuk menghindari overfitting model. Hal ini diperlukan agar algoritma pelatihan tidak terlalu menyesuaikan diri dengan data pelatihan sehingga tidak dapat digeneralisasi ke contoh baru.
Gunakan konsol Google Cloud untuk melihat perubahan loss model selama iterasi pelatihan model:
Di Konsol Google Cloud, buka halaman BigQuery.
Di panel Explorer, luaskan bqml_tutorial > Models, lalu klik sample_model.
Klik tab Training dan lihat grafik Loss. Grafik Loss menunjukkan perubahan metrik loss selama iterasi pada set data pelatihan. Jika kursor diarahkan ke grafik, Anda dapat melihat bahwa ada garis untuk Training loss dan Evaluation loss. Karena Anda melakukan regresi logistik, nilai kerugian pelatihan dihitung sebagai kerugian log, menggunakan data pelatihan. Kerugian evaluasi adalah kerugian log yang dihitung pada data evaluasi. Kedua jenis kerugian mewakili nilai kerugian rata-rata, yang dirata-ratakan dari semua contoh dalam set data masing-masing untuk setiap iterasi.
Anda juga dapat melihat hasil pelatihan model menggunakan
fungsi ML.TRAINING_INFO.
Mengevaluasi model
Evaluasi performa model menggunakan fungsi ML.EVALUATE. Fungsi
ML.EVALUATE mengevaluasi nilai yang diprediksi yang dihasilkan oleh model
terhadap data sebenarnya. Untuk menghitung metrik khusus regresi logistik, Anda dapat menggunakan fungsi SQL ML.ROC_CURVE atau fungsi DataFrame BigQuery bigframes.ml.metrics.roc_curve.
Dalam tutorial ini, Anda menggunakan model klasifikasi biner yang mendeteksi transaksi. Nilai dalam kolom label adalah dua class
yang dihasilkan oleh model: 0 (tanpa transaksi) dan 1 (transaksi yang dilakukan).
SQL
Di Konsol Google Cloud, buka halaman BigQuery.
Di editor kueri, jalankan pernyataan berikut:
SELECT * FROM ML.EVALUATE(MODEL `bqml_tutorial.sample_model`, ( SELECT IF(totals.transactions IS NULL, 0, 1) AS label, IFNULL(device.operatingSystem, "") AS os, device.isMobile AS is_mobile, IFNULL(geoNetwork.country, "") AS country, IFNULL(totals.pageviews, 0) AS pageviews FROM `bigquery-public-data.google_analytics_sample.ga_sessions_*` WHERE _TABLE_SUFFIX BETWEEN '20170701' AND '20170801'))
Hasilnya akan terlihat seperti berikut:
+--------------------+---------------------+---------------------+---------------------+---------------------+--------------------+ | precision | recall | accuracy | f1_score | log_loss | roc_auc | +--------------------+---------------------+---------------------+---------------------+---------------------+--------------------+ | 0.468503937007874 | 0.11080074487895716 | 0.98534315834767638 | 0.17921686746987953 | 0.04624221101176898 | 0.98174125874125873 | +--------------------+---------------------+---------------------+---------------------+---------------------+--------------------+
Karena Anda melakukan regresi logistik, hasilnya mencakup kolom berikut:
precision: metrik untuk model klasifikasi. Presisi mengidentifikasi frekuensi terkait apakah model benar saat memprediksi class positif.recall: metrik untuk model klasifikasi yang menjawab pertanyaan berikut: Dari semua kemungkinan label positif, berapa banyak model yang diidentifikasi dengan benar?accuracy: Akurasi adalah fraksi prediksi yang dilakukan model klasifikasi dengan benar.f1_score: ukuran akurasi model. Skor f1 adalah rata-rata harmonik presisi dan perolehan. Nilai terbaik skor f1 adalah 1. Nilai terendahnya adalah 0.log_loss: fungsi kerugian yang digunakan dalam regresi logistik. Ini adalah ukuran seberapa jauh prediksi model dari label yang benar.roc_auc: area di bawah kurva ROC. Ini adalah probabilitas bahwa pengklasifikasi lebih yakin bahwa contoh positif yang dipilih secara acak sebenarnya positif daripada contoh negatif yang dipilih secara acak adalah positif. Untuk mengetahui informasi selengkapnya, lihat Klasifikasi di Kursus Singkat Machine Learning.
Detail kueri
Pernyataan SELECT awal mengambil kolom dari model Anda.
Klausa FROM menggunakan fungsi ML.EVALUATE terhadap model Anda.
Pernyataan SELECT dan klausa FROM bertingkat sama dengan pernyataan dan klausa dalam kueri CREATE MODEL.
Klausa WHERE — _TABLE_SUFFIX BETWEEN '20170701' AND '20170801'
— membatasi jumlah tabel yang dipindai oleh kueri. Rentang tanggal
yang dipindai adalah 1 Juli 2017 hingga 1 Agustus 2017. Ini adalah data yang Anda gunakan untuk
mengevaluasi performa prediktif model. Data ini dikumpulkan pada bulan
segera setelah jangka waktu yang mencakup data pelatihan.
DataFrame BigQuery
Sebelum mencoba contoh ini, ikuti petunjuk penyiapan BigQuery DataFrames di panduan memulai BigQuery menggunakan BigQuery DataFrames. Untuk mengetahui informasi selengkapnya, lihat dokumentasi referensi BigQuery DataFrames.
Untuk melakukan autentikasi ke BigQuery, siapkan Kredensial Default Aplikasi. Untuk informasi selengkapnya, lihat Menyiapkan ADC untuk lingkungan pengembangan lokal.
Menggunakan model untuk memprediksi hasil
Gunakan model untuk memprediksi jumlah transaksi yang dilakukan oleh pengunjung situs dari setiap negara.
SQL
Di Konsol Google Cloud, buka halaman BigQuery.
Di editor kueri, jalankan pernyataan berikut:
SELECT country, SUM(predicted_label) as total_predicted_purchases FROM ML.PREDICT(MODEL `bqml_tutorial.sample_model`, ( SELECT IFNULL(device.operatingSystem, "") AS os, device.isMobile AS is_mobile, IFNULL(totals.pageviews, 0) AS pageviews, IFNULL(geoNetwork.country, "") AS country FROM `bigquery-public-data.google_analytics_sample.ga_sessions_*` WHERE _TABLE_SUFFIX BETWEEN '20170701' AND '20170801')) GROUP BY country ORDER BY total_predicted_purchases DESC LIMIT 10
Hasilnya akan terlihat seperti berikut:
+----------------+---------------------------+ | country | total_predicted_purchases | +----------------+---------------------------+ | United States | 220 | | Taiwan | 8 | | Canada | 7 | | India | 2 | | Turkey | 2 | | Japan | 2 | | Italy | 1 | | Brazil | 1 | | Singapore | 1 | | Australia | 1 | +----------------+---------------------------+
Detail kueri
Pernyataan SELECT awal mengambil kolom country dan menjumlahkan
kolom predicted_label. Kolom predicted_label dihasilkan oleh fungsi ML.PREDICT. Saat Anda menggunakan fungsi ML.PREDICT, nama kolom output untuk model adalah predicted_<label_column_name>. Untuk model
regresi linear, predicted_label adalah perkiraan nilai label.
Untuk model regresi logistik, predicted_label adalah label yang paling
menjelaskan nilai data input yang diberikan, baik 0 maupun 1.
Fungsi ML.PREDICT digunakan untuk memprediksi hasil menggunakan model Anda.
Pernyataan SELECT dan klausa FROM bertingkat sama dengan pernyataan dan klausa dalam kueri CREATE MODEL.
Klausa WHERE — _TABLE_SUFFIX BETWEEN '20170701' AND '20170801'
— membatasi jumlah tabel yang dipindai oleh kueri. Rentang tanggal
yang dipindai adalah 1 Juli 2017 hingga 1 Agustus 2017. Ini adalah data yang
Anda buat prediksinya. Data ini dikumpulkan pada bulan segera setelah jangka
waktu yang dicakup oleh data pelatihan.
Klausa GROUP BY dan ORDER BY mengelompokkan hasil berdasarkan negara dan mengurutkannya
berdasarkan jumlah prediksi pembelian dalam urutan menurun.
Klausa LIMIT digunakan di sini untuk menampilkan hanya 10 hasil teratas.
DataFrame BigQuery
Sebelum mencoba contoh ini, ikuti petunjuk penyiapan BigQuery DataFrames di panduan memulai BigQuery menggunakan BigQuery DataFrames. Untuk mengetahui informasi selengkapnya, lihat dokumentasi referensi BigQuery DataFrames.
Untuk melakukan autentikasi ke BigQuery, siapkan Kredensial Default Aplikasi. Untuk informasi selengkapnya, lihat Menyiapkan ADC untuk lingkungan pengembangan lokal.
Memprediksi pembelian per pengguna
Memprediksi jumlah transaksi yang akan dilakukan setiap pengunjung situs.
SQL
Kueri ini sama dengan kueri di bagian sebelumnya, kecuali untuk klausa GROUP BY. Di sini, klausa GROUP BY — GROUP BY fullVisitorId
— digunakan untuk mengelompokkan hasil menurut ID pengunjung.
Di Konsol Google Cloud, buka halaman BigQuery.
Di editor kueri, jalankan pernyataan berikut:
SELECT fullVisitorId, SUM(predicted_label) as total_predicted_purchases FROM ML.PREDICT(MODEL `bqml_tutorial.sample_model`, ( SELECT IFNULL(device.operatingSystem, "") AS os, device.isMobile AS is_mobile, IFNULL(totals.pageviews, 0) AS pageviews, IFNULL(geoNetwork.country, "") AS country, fullVisitorId FROM `bigquery-public-data.google_analytics_sample.ga_sessions_*` WHERE _TABLE_SUFFIX BETWEEN '20170701' AND '20170801')) GROUP BY fullVisitorId ORDER BY total_predicted_purchases DESC LIMIT 10
Hasilnya akan terlihat seperti berikut:
+---------------------+---------------------------+ | fullVisitorId | total_predicted_purchases | +---------------------+---------------------------+ | 9417857471295131045 | 4 | | 112288330928895942 | 2 | | 2158257269735455737 | 2 | | 489038402765684003 | 2 | | 057693500927581077 | 2 | | 2969418676126258798 | 2 | | 5073919761051630191 | 2 | | 7420300501523012460 | 2 | | 0456807427403774085 | 2 | | 2105122376016897629 | 2 | +---------------------+---------------------------+
DataFrame BigQuery
Sebelum mencoba contoh ini, ikuti petunjuk penyiapan BigQuery DataFrames di panduan memulai BigQuery menggunakan BigQuery DataFrames. Untuk mengetahui informasi selengkapnya, lihat dokumentasi referensi BigQuery DataFrames.
Untuk melakukan autentikasi ke BigQuery, siapkan Kredensial Default Aplikasi. Untuk informasi selengkapnya, lihat Menyiapkan ADC untuk lingkungan pengembangan lokal.
Pembersihan
Agar tidak menimbulkan biaya pada akun Google Cloud Anda untuk resource yang digunakan pada halaman ini, ikuti langkah-langkah berikut.
Anda dapat menghapus project yang dibuat, atau menyimpan project dan menghapus set data.
Menghapus set data
Jika project Anda dihapus, semua set data dan semua tabel dalam project akan dihapus. Jika ingin menggunakan kembali project tersebut, Anda dapat menghapus set data yang dibuat dalam tutorial ini:
Di Konsol Google Cloud, buka halaman BigQuery.
Di panel Explorer, pilih set data bqml_tutorial yang telah Anda buat.
Klik Tindakan > Hapus.
Pada dialog Delete dataset, konfirmasi perintah hapus dengan mengetik
delete.Klik Hapus.
Menghapus project
Untuk menghapus project:
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
Langkah berikutnya
- Untuk mempelajari machine learning lebih lanjut, lihat Kursus singkat machine learning.
- Untuk ringkasan BigQuery ML, lihat Pengantar BigQuery ML.
- Untuk mempelajari konsol Google Cloud lebih lanjut, lihat Menggunakan konsol Google Cloud.