Introduction to data masking
BigQuery supports data masking at the column level. You can use data masking to selectively obscure column data for users groups, while still allowing them access to the column. Data masking functionality is built on top of column-level access control, so you should familiarize yourself with that feature before you proceed.
When you use data masking in combination with column-level access control, you can configure a range of access to column data, from full access to no access, based on the needs of different user groups. For example, for tax ID data, you might want to grant your accounting group full access, your analyst group masked access, and your sales group no access.
Benefits
Data masking provides the following benefits:
- It streamlines the data sharing process. You can mask sensitive columns to make it possible to share tables with larger groups.
- Unlike with column-level access control, you don't need to modify existing queries by excluding the columns that the user cannot access. When you configure data masking, existing queries automatically mask column data based on the roles the user has been granted.
- You can apply data access policies at scale. You can write a data policy, associate it with a policy tag, and apply the policy tag to any number of columns.
- It enables attribute-based access control. A policy tag attached to a column provides contextual data access, which is determined by the data policy and the principals that are associated with that policy tag.
Data masking workflow
There are two ways of masking data. You can create a taxonomy and policy tags, then configure data policies on the policy tags. Alternatively, you can set a data policy directly on a column Preview. This lets you map a data masking rule on your data without handling policy tags or creating additional taxonomies.
Set a data policy directly on a column
You can configure dynamic data masking directly on a column (Preview). To do so, perform the following steps:
Assign a data policy to a column.
Mask data with policy tags
Figure 1 shows the workflow for configuring data masking:
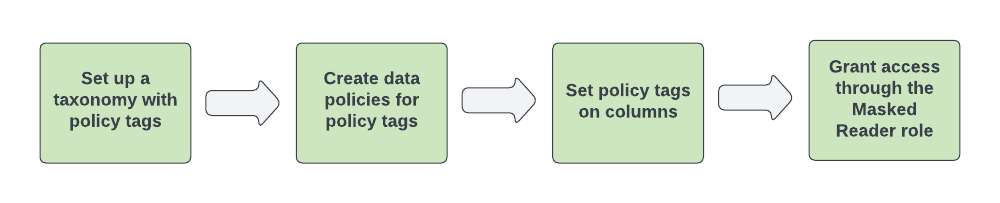 Figure 1. Data masking components.
Figure 1. Data masking components.
You configure data masking with the following steps:
- Set up a taxonomy and one or more policy tags.
Configure data policies for the policy tags. A data policy maps a data masking rule and one or more principals, which represent users or groups, to the policy tag.
When creating a data policy by using the Google Cloud console, you create the data masking rule and specify the principals in one step. When creating a data policy by using the BigQuery Data Policy API, you create the data policy and data masking rule in one step, and specify the principals for the data policy in a second step.
Assign the policy tags to columns in BigQuery tables to apply the data policies.
Assign users who should have access to masked data to the BigQuery Masked Reader role. As a best practice, assign the BigQuery Masked Reader role at the data policy level. Assigning the role at the project level or higher grants users permissions to all data policies under the project, which can lead to issues caused by excess permissions.
The policy tag that is associated with a data policy can also be used for column-level access control. In that case, the policy tag is also associated with one or more principals who are granted the Data Catalog Fine-Grained Reader role. This enables these principals to access the original, unmasked column data.
Figure 2 shows how column-level access control and data masking work together:
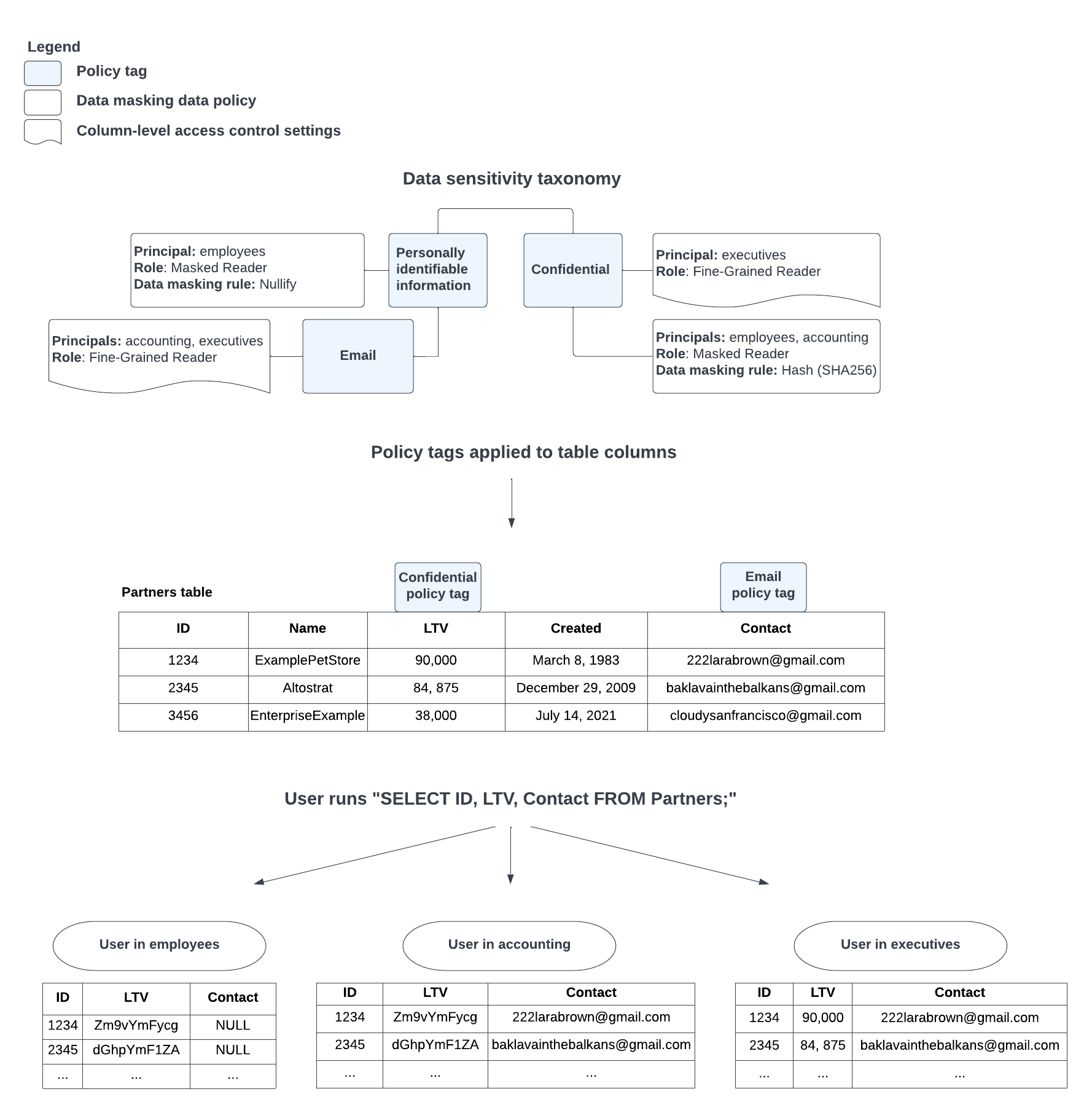 Figure 2. Data masking components.
Figure 2. Data masking components.
For more information about role interaction, see How Masked Reader and Fine-Grained Reader roles interact. For more information about policy tag inheritance, see Roles and policy tag hierarchy.
Data masking rules
When you use data masking, a data masking rule is applied to a column at query runtime, based on the role of the user running the query. Masking takes precedence to any other operations involved in the query. The data masking rule determines the type of data masking applied to the column data.
You can use the following data masking rules:
Custom masking routine. Returns the column's value after applying a user-defined function (UDF) to the column. Routine permissions are required to manage the masking rule. This rule, by design, supports all BigQuery data types except for the
STRUCTdata type. However, support for data types other thanSTRINGandBYTESis limited. The output depends on the defined function.For more information about creating UDFs for custom masking routines, see Create custom masking routines.
Date year mask. Returns the column's value after truncating the value to its year, setting all non-year parts of the value to the beginning of the year. You can only use this rule with columns that use the
DATE,DATETIME, andTIMESTAMPdata types. For example:Type Original Masked DATE2030-07-17 2030-01-01 DATETIME2030-07-17T01:45:06 2030-01-01T00:00:00 TIMESTAMP2030-07-17 01:45:06 2030-01-01 00:00:00 Default masking value. Returns a default masking value for the column based on the column's data type. Use this when you want to hide the value of the column but reveal the data type. When this data masking rule is applied to a column, it makes it less useful in query
JOINoperations for users with Masked Reader access. This is because a default value isn't sufficiently unique to be useful when joining tables.The following table shows the default masking value for each data type:
Data type Default masking value STRING"" BYTESb'' INTEGER0 FLOAT0.0 NUMERIC0 BOOLEANFALSETIMESTAMP1970-01-01 00:00:00 UTC DATE1970-01-01 TIME00:00:00 DATETIME1970-01-01T00:00:00 GEOGRAPHYPOINT(0 0) BIGNUMERIC0 ARRAY[] STRUCTNOT_APPLICABLE
Policy tags can't be applied to columns that use the
STRUCTdata type, but they can be associated with the leaf fields of such columns.JSONnull Email mask. Returns the column's value after replacing the username of a valid email with
XXXXX. If the column's value is not a valid email address, then it returns the column's value after it has been run through the SHA-256 hash function. You can only use this rule with columns that use theSTRINGdata type. For example:Original Masked abc123@gmail.comXXXXX@gmail.comrandomtextjQHDyQuj7vJcveEe59ygb3Zcvj0B5FJINBzgM6Bypgw=test@gmail@gmail.comQdje6MO+GLwI0u+KyRyAICDjHbLF1ImxRqaW08tY52k=First four characters. Returns the first 4 characters of the column's value, replacing the rest of the string with
XXXXX. If the column's value is equal to or less than 4 characters in length, then it returns the column's value after it has been run through the SHA-256 hash function. You can only use this rule with columns that use theSTRINGdata type.Hash (SHA-256). Returns the column's value after it has been run through the SHA-256 hash function. Use this when you want the end user to be able to use this column in a
JOINoperation for a query. You can only use this rule with columns that use theSTRINGorBYTESdata types.The SHA-256 function used in data masking is type preserving, so the hash value it returns has the same data type as the column value. For example, the hash value for a
STRINGcolumn value also has aSTRINGdata type.Last four characters. Returns the last 4 characters of the column's value, replacing the rest of the string with
XXXXX. If the column's value is equal to or less than 4 characters in length, then it returns the column's value after it has been run through the SHA-256 hash function. You can only use this rule with columns that use theSTRINGdata type.Nullify. Returns
NULLinstead of the column value. Use this when you want to hide both the value and the data type of the column. When this data masking rule is applied to a column, it makes it less useful in queryJOINoperations for users with Masked Reader access. This is because aNULLvalue isn't sufficiently unique to be useful when joining tables.
Data masking rule hierarchy
You can configure up to nine data policies for a policy tag, each with a different data masking rule associated with it. One of these policies is reserved for column-level access control settings. This makes it possible for several data policies to be applied to a column in a user's query, based on the groups that the user is a member of. When this happens, BigQuery chooses which data masking rule to apply based on the following hierarchy:
- Custom masking routine
- Hash (SHA-256)
- Email mask
- Last four characters
- First four characters
- Date year mask
- Default masking value
- Nullify
For example, user A is a member of both the employees and the accounting
groups. User A runs a query that includes the sales_total field, which
has the confidential policy tag applied. The confidential policy tag has
two data policies associated with it: one that has the employees role as the
principal and applies the nullify data masking rule, and one that has the
accounting role as the principal and applies the hash (SHA-256) data masking
rule. In this case, the hash (SHA-256) data masking rule is prioritized over
the nullify data masking rule, so the hash (SHA-256) rule is applied to the
sales_total field value in user A's query.
Figure 3 shows this scenario:

Figure 3. Data masking rule prioritization.
Roles and permissions
Roles for managing taxonomies and policy tags
You need the Data Catalog Policy Tag Admin role to create and manage taxonomies and policy tags.
| Role/ID | Permissions | Description |
|---|---|---|
Data Catalog Policy Tag Admin/datacatalog.categoryAdmin
|
datacatalog.categories.getIamPolicydatacatalog.categories.setIamPolicydatacatalog.taxonomies.createdatacatalog.taxonomies.deletedatacatalog.taxonomies.getdatacatalog.taxonomies.getIamPolicydatacatalog.taxonomies.listdatacatalog.taxonomies.setIamPolicydatacatalog.taxonomies.updateresourcemanager.projects.getresourcemanager.projects.list
|
Applies at the project level. This role grants the ability to do the following:
|
Roles for creating and managing data policies
You need one of the following BigQuery roles to create and manage data policies:
| Role/ID | Permissions | Description |
|---|---|---|
BigQuery Data Policy Admin/bigquerydatapolicy.admin BigQuery Admin/ bigquery.admin BigQuery Data Owner/ bigquery.dataOwner
|
bigquery.dataPolicies.createbigquery.dataPolicies.deletebigquery.dataPolicies.getbigquery.dataPolicies.getIamPolicybigquery.dataPolicies.listbigquery.dataPolicies.setIamPolicybigquery.dataPolicies.update
|
The This role grants the ability to do the following:
|
datacatalog.taxonomies.get permission, which you can get from several
of the
Data Catalog predefined roles.
Roles for attaching policy tags to columns
You need the datacatalog.taxonomies.get and bigquery.tables.setCategory
permissions to attach policy tags to columns.
datacatalog.taxonomies.get is included in the
Data Catalog Policy Tags Admin and Viewer roles.
bigquery.tables.setCategory is included in the
BigQuery Admin (roles/bigquery.admin) and
BigQuery Data Owner (roles/bigquery.dataOwner) roles.
Roles for querying masked data
You need the BigQuery Masked Reader role to query the data from a column that has data masking applied.
| Role/ID | Permissions | Description |
|---|---|---|
Masked Reader/bigquerydatapolicy.maskedReader
|
bigquery.dataPolicies.maskedGet |
Applies at the data policy level. This role grants the ability to view the masked data of a column that is associated with a data policy. Additionally, a user must have appropriate permissions to query the table. For more information, see Required permissions. |
How Masked Reader and Fine-Grained Reader roles interact
Data masking builds on top of column-level access control. For a given column, it is possible to have some users with the BigQuery Masked Reader role that allows them to read masked data, some users with the Data Catalog Fine-Grained Reader role that allows them to read unmasked data, some users with both, and some users with neither. These roles interact as follows:
- User with both Fine-Grained Reader and Masked Reader roles: what the user sees depends on where in the policy tag hierarchy each role is granted. For more information, see Authorization inheritance in a policy tag hierarchy.
- User with Fine-Grained Reader role: can see unmasked (unobscured) column data.
- User with Masked Reader role: can see masked (obscured) column data.
- User with neither role: permission denied.
In the case where a table has columns that are secured or secured and
masked, in order to run a SELECT * FROM statement on that table,
a user must be a member of appropriate groups such that they are granted
Masked Reader or Fine-Grained Reader roles on all of these columns.
A user who is not granted these roles must instead specify only columns that
they have access to in the SELECT statement, or use SELECT * EXCEPT
(restricted_columns) FROM to exclude the secured or
masked columns.
Authorization inheritance in a policy tag hierarchy
Roles are evaluated starting at the policy tag associated with a column, and then checked at each ascending level of the taxonomy, until the user either is determined to have appropriate permissions or the top of the policy tag hierarchy is reached.
For example, take the policy tag and data policy configuration shown in Figure 4:
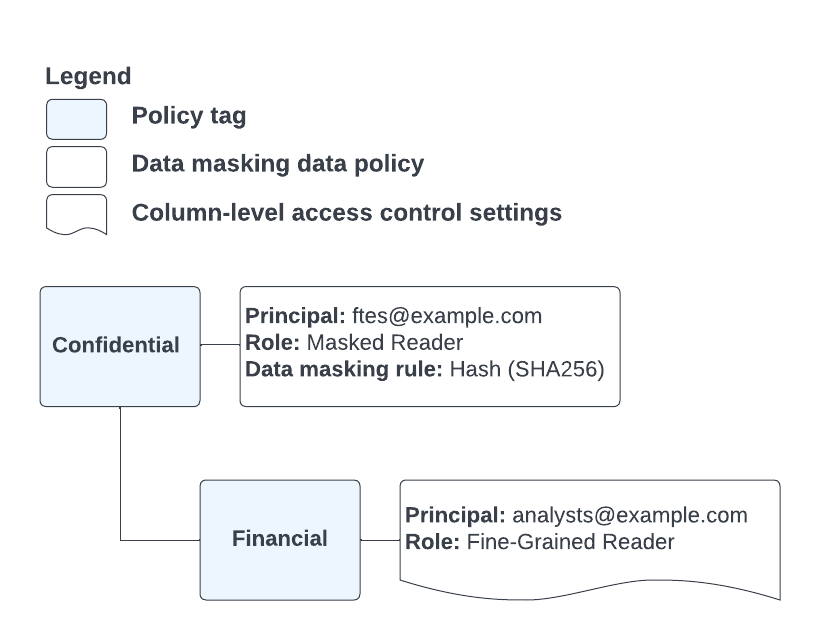
Figure 4. Policy tag and data policy configuration.
You have a table column that is annotated with the Financial policy tag,
and a user who is a member of both the ftes@example.com and analysts@example.com
groups. When this user runs a query that includes the annotated column, their
access is determined by the hierarchy defined in the
policy tag taxonomy. Because the user is granted
the Data Catalog Fine-Grained Reader role by the Financial
policy tag, the query returns unmasked column data.
If another user who is
only a member of the ftes@example.com role runs a query that includes the
annotated column, the query returns column data that has been hashed using
the SHA-256 algorithm, because the user is granted the BigQuery
Masked Reader role by the Confidential policy tag, which is the parent of
the Financial policy tag.
A user who is not a member of either of those roles gets an access denied error if they try to query the annotated column.
In contrast with the preceding scenario, take the policy tag and data policy configuration shown in Figure 5:
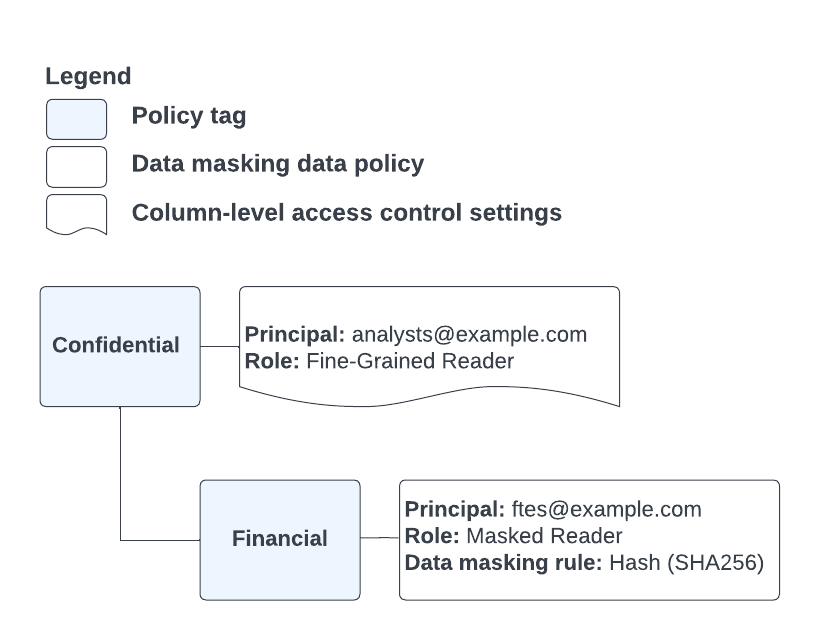
Figure 5. Policy tag and data policy configuration.
You have the same situation as shown in Figure 4, but the user is granted the Fine-Grained Reader role at a higher level of the policy tag hierarchy, and the Masked Reader role at a lower level of the policy tag hierarchy. Because of this, the query returns masked column data for this user. This happens even though the user is granted the Fine-Grained Reader role further up the tag hierarchy, because the service uses the first assigned role it encounters as it ascends the policy tag hierarchy to check for user access.
If you want to create a single data policy and have it apply to several levels of a policy tag hierarchy, you can set the data policy on the policy tag that represents the topmost hierarchy level to which it should apply. For example, take a taxonomy with the following structure:
- Policy tag 1
- Policy tag 1a
- Policy tag 1ai
- Policy tag 1b
- Policy tag 1bi
- Policy tag 1bii
- Policy tag 1a
If you want a data policy to apply to all of these policy tags, set the data policy on policy tag 1. If you want a data policy to apply to policy tag 1b and its children, set the data policy on policy tag 1b.
Data masking with incompatible features
When you use BigQuery features that aren't compatible with data masking, the service treats the masked column as a secured column, and only grants access to users who have the Data Catalog Fine-Grained Reader role.
For example, take the policy tag and data policy configuration shown in Figure 6:
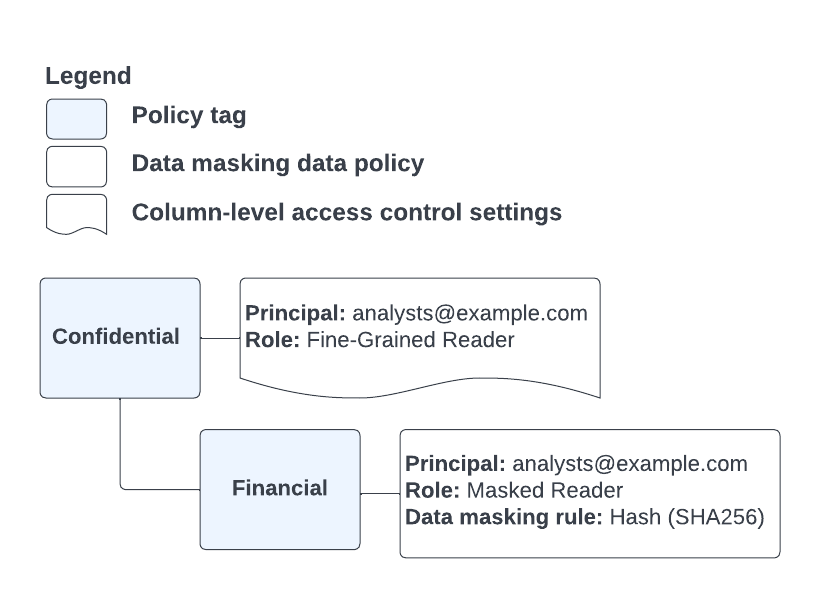
Figure 6. Policy tag and data policy configuration.
You have a table column that is annotated with the Financial policy tag, and
a user who is a member of the analysts@example.com group. When this user tries
to access the annotated column through one of the incompatible features, they
get an access denied error. This is because they are granted the
BigQuery Masked Reader by Financial policy tag, but in this
case, they must have the Data Catalog Fine-Grained Reader role.
Because the service has already determined an applicable role for the user, it
does not continue to check farther up the policy tag hierarchy for additional
permissions.
Data masking example with output
To see how tags, principals, and roles work together, consider this example.
At example.com, basic access is granted through the data-users@example.com group. All employees who need regular access to BigQuery data are members of this group, which is assigned all the necessary permissions to read from tables as well as the BigQuery Masked Reader role.
Employees are assigned to additional groups that provide access to secured or masked columns where that is required for their work. All members of these additional groups are also members of data-users@example.com. You can see how these groups are associated with appropriate roles in Figure 7:
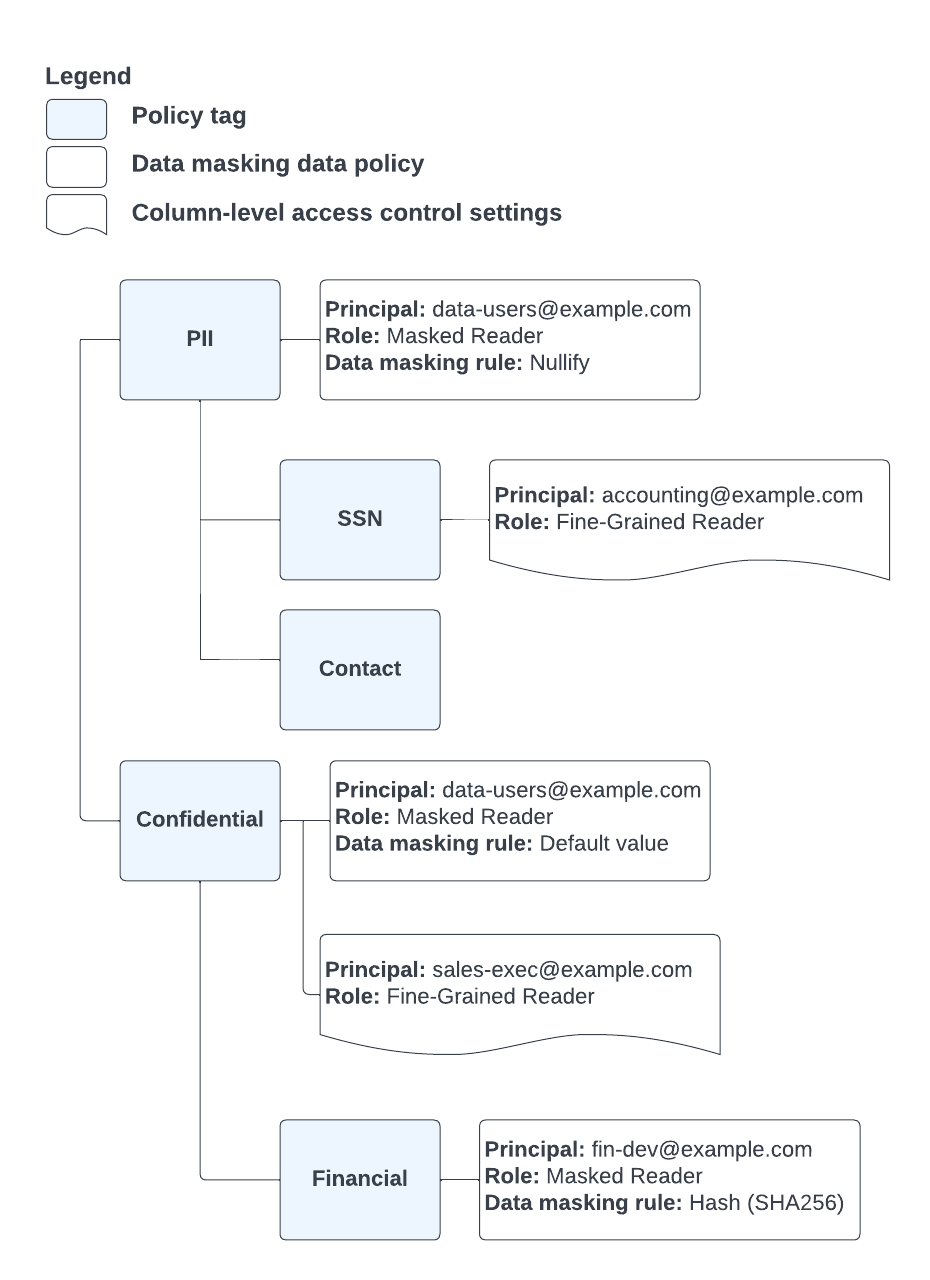
Figure 7. Policy tags and data policies for example.com.
The policy tags are then associated with table columns, as shown in Figure 8:
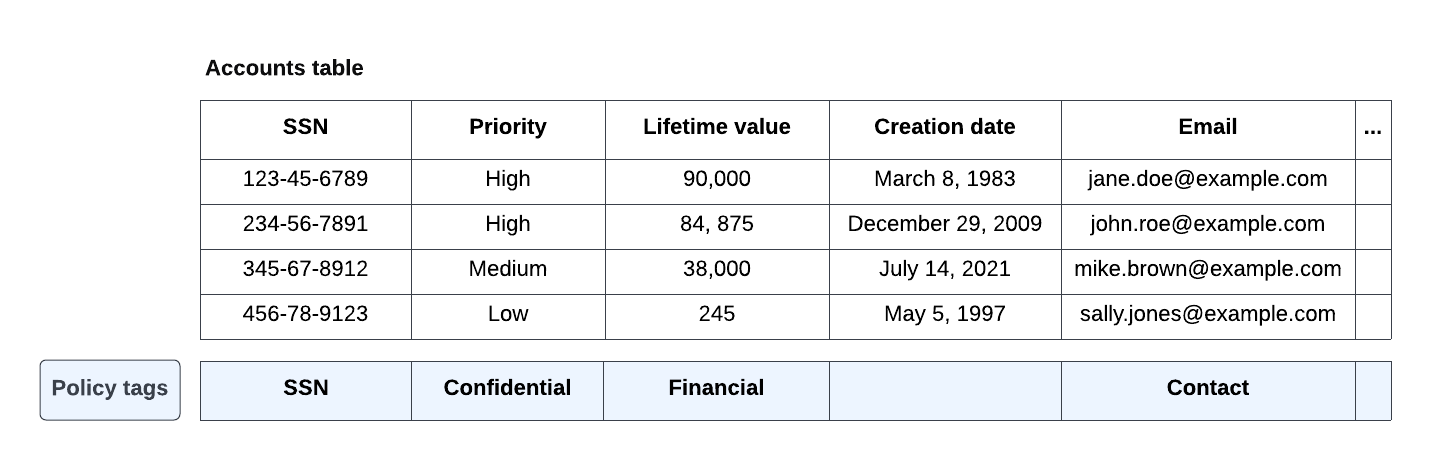
Figure 8. Example.com policy tags associated with table columns.
Given the tags that are associated with the columns, running
SELECT * FROM Accounts; leads to the
following results for the different groups:
data-users@example.com: This group has been granted the BigQuery Masked Reader role on both the
PIIandConfidentialpolicy tags. The following results are returned:SSN Priority Lifetime value Creation date Email NULL "" 0 March 8, 1983 NULL NULL "" 0 December 29, 2009 NULL NULL "" 0 July 14, 2021 NULL NULL "" 0 May 5, 1997 NULL accounting@example.com: This group has been granted the Data Catalog Fine-Grained Reader role on the
SSNpolicy tag. The following results are returned:SSN Priority Lifetime value Creation date NULL 123-45-6789 "" 0 March 8, 1983 NULL 234-56-7891 "" 0 December 29, 2009 NULL 345-67-8912 "" 0 July 14, 2021 NULL 456-78-9123 "" 0 May 5, 1997 NULL sales-exec@example.com: This group has been granted the Data Catalog Fine-Grained Reader role on the
Confidentialpolicy tag. The following results are returned:SSN Priority Lifetime value Creation date Email NULL High 90,000 March 8, 1983 NULL NULL High 84,875 December 29, 2009 NULL NULL Medium 38,000 July 14, 2021 NULL NULL Low 245 May 5, 1997 NULL fin-dev@example.com: This group has been granted the BigQuery Masked Reader role on the
Financialpolicy tag. The following results are returned:SSN Priority Lifetime value Creation date Email NULL "" Zmy9vydG5q= March 8, 1983 NULL NULL "" GhwTwq6Ynm= December 29, 2009 NULL NULL "" B6y7dsgaT9= July 14, 2021 NULL NULL "" Uh02hnR1sg= May 5, 1997 NULL All other users: Any user who does not belong to one of the listed groups gets an access denied error, because they haven't been granted the Data Catalog Fine-Grained Reader or BigQuery Masked Reader roles. To query the
Accountstable, they must instead specify only columns that they have access to in theSELECT * EXCEPT (restricted_columns) FROM Accountsto exclude the secured or masked columns.
Cost considerations
Data masking might indirectly affect the number of bytes processed, and therefore affect the cost of the query. If a user queries a column that is masked for them with the Nullify or Default Masking Value rules, then that column isn't scanned at all, resulting in fewer bytes processed.
Restrictions and limitations
The following sections describe the categories of restrictions and limitations that data masking is subject to.
Data policy management
- This feature may not be available when using reservations that are created with certain BigQuery editions. For more information about which features are enabled in each edition, see Introduction to BigQuery editions.
- You can create up to nine data policies for each policy tag. One of these policies is reserved for column-level access control settings.
- Data policies, their associated policy tags, and any routines that use them must be in the same project.
Policy tags
- The project containing the policy tag taxonomy must belong to an organization.
A policy tag hierarchy can be no more than five levels deep from the root node to the lowest-level subtag, as shown in the following screenshot:
Set access control
After a taxonomy has a data policy associated with at least one of its policy tags, access control is automatically enforced. If you want to turn off access control, you must first delete all of the data policies associated with the taxonomy.
Materialized views and repeated record masking queries
If you have existing materialized views, repeated record masking queries on the associated base table fail. To resolve this issue, delete the materialized view. If the materialized view is needed for other reasons, you can create it in another dataset.
Query masked columns in partitioned tables
Queries that include data masking on the partitioned or clustered columns are not supported.
SQL dialects
Legacy SQL is not supported.
Custom masking routines
Custom masking routines are subject to the following limitations:
- Custom data masking supports all
BigQuery data types
except
STRUCT, because data masking can only apply to leaf fields of theSTRUCTdata type. - Deleting a custom masking routine doesn't delete all data policies that use
it. However, the data policies that use the deleted masking routine are left
with an empty masking rule. Users with the Masked Reader role on other data
policies with the same tag can see masked data. Others see the message
Permission denied.Dangling references to empty masking rules might be cleaned by automated processes after seven days.
Compatibility with other BigQuery features
BigQuery API
Not compatible with the
tabledata.list method. To
call tabledata.list, you need full access to all of the columns returned by
this method. The Data Catalog Fine-Grained Reader role grants
appropriate access.
BigLake tables
Compatible. Data masking policies are enforced on BigLake tables.
BigQuery Storage Read API
Compatible. Data masking policies are enforced in the BigQuery Storage Read API.
BigQuery BI Engine
Compatible. Data masking policies are enforced in the BI Engine. Queries that have data masking in effect are not accelerated by BI Engine. Use of such queries in Looker Studio might cause related reports or dashboards to become slower and more expensive.
BigQuery Omni
Compatible. Data masking policies are enforced on the BigQuery Omni tables.
Collation
Partially compatible. You can apply DDM to collated columns, but masking is applied before collation. This order of operations can lead to unexpected results, as collation might not affect the masked values as intended (for example, case-insensitive matching might not work after masking). Workarounds are possible, such as using custom masking routines that normalize data before applying the masking function.
Copy jobs
Not compatible. To copy a table from source to the destination, you need to to have full access to all of the columns on the source table. The Data Catalog Fine-Grained Reader role grants appropriate access.
Data export
Compatible. If you have the BigQuery Masked Reader role, then the exported data is masked. If you have the Data Catalog Fine-Grained Reader role, then the exported data is not masked.
Row-level security
Compatible. Data masking is applied on top of row-level security. For example, if
there is a row access policy applied on location = "US" and location is
masked, then users are able to see rows where location = "US" but the
location field is masked.
Search in BigQuery
Partially compatible. You can call the
SEARCH
function on indexed or unindexed columns that have data masking applied.
When you call the SEARCH function on columns that have data masking applied,
you must use search criteria compatible with your level of access. For example,
if you have Masked Reader access with a Hash (SHA-256) data masking rule, you
would use the hash value in your SEARCH clause, similar to the following:
SELECT * FROM myDataset.Customers WHERE SEARCH(Email, "sg172y34shw94fujaweu");
If you have Fine-Grained Reader access, you would use the actual column
value in your SEARCH clause, similar to the following:
SELECT * FROM myDataset.Customers WHERE SEARCH(Email, "jane.doe@example.com");
Searching is less likely to be useful if you have
Masked Reader access to a column where the data masking rule used is Nullify or
Default Masking Value. This is because the masked results you would use as
search criteria, such as NULL or "", aren't sufficiently unique to be
useful.
When searching on an indexed column that has data masking applied, the search index is only used if you have Fine-Grained Reader access to the column.
Snapshots
Not compatible. To create a snapshot of a table, you need full access to all of the columns on the source table. The Data Catalog Fine-Grained Reader role grants appropriate access.
Table renaming
Compatible. Table renaming is not affected by data masking.
Time travel
Compatible with both
time decorators and the
FOR SYSTEM_TIME AS OF
option in SELECT statements. The policy tags for the current dataset schema
are applied to the retrieved data.
Query caching
Partly compatible. BigQuery caches query results for approximately 24 hours, although the cache is invalidated if changes are made to the table data or schema before that. In the following circumstance, it is possible that a user who does not have the Data Catalog Fine-Grained Reader role granted on a column can still see the column data when they run a query:
- A user has been granted the Data Catalog Fine-Grained Reader role on a column.
- The user runs a query that includes the restricted column and the data is cached.
- Within 24 hours of Step 2, the user is granted the BigQuery Masked Reader role, and has the Data Catalog Fine-Grained Reader role revoked.
- Within 24 hours of Step 2, the user runs that same query, and the cached data is returned.
Wildcard table queries
Not compatible. You need full access to all of the referenced columns on all of the tables matching the wildcard query. The Data Catalog Fine-Grained Reader role grants appropriate access.
What's next
- Get step-by-step instructions to enable data masking.