Introduzione alle tabelle in cluster
Le tabelle in cluster in BigQuery sono tabelle con un ordine di ordinamento delle colonne definito dall'utente che utilizza le colonne in cluster. Le tabelle in cluster possono migliorare le prestazioni delle query e ridurre i costi associati.
In BigQuery, una colonna in cluster è una proprietà della tabella definita dall'utente che ordina i blocchi di archiviazione in base ai valori nelle colonne in cluster. Le dimensioni dei blocchi di archiviazione sono adattabili in base alle dimensioni della tabella. La colocalizzazione avviene a livello di blocchi di archiviazione e non a livello di singole righe. Per saperne di più sulla colocalizzazione in questo contesto, consulta Clustering.
Una tabella cluster gestisce le proprietà di ordinamento nel contesto di ogni operazione che la modifica. Le query che filtrano o aggregano in base alle colonne in cluster analizzano solo i blocchi pertinenti in base alle colonne in cluster, anziché l'intera tabella o la partizione della tabella. Di conseguenza, BigQuery potrebbe non essere in grado di stimare con precisione i byte da elaborare dalla query o i costi delle query, ma tenta di ridurre i byte totali al momento dell'esecuzione.
Quando raggruppi una tabella utilizzando più colonne, l'ordine delle colonne determina quali colonne hanno la precedenza quando BigQuery ordina e raggruppa i dati in blocchi di archiviazione, come mostrato nell'esempio seguente. La tabella 1 mostra il layout del blocco di archiviazione logico di una tabella non raggruppata. In confronto, la tabella 2 è raggruppata solo in base alla colonna Country, mentre la tabella 3 è raggruppata in base a più colonne, Country e Status.
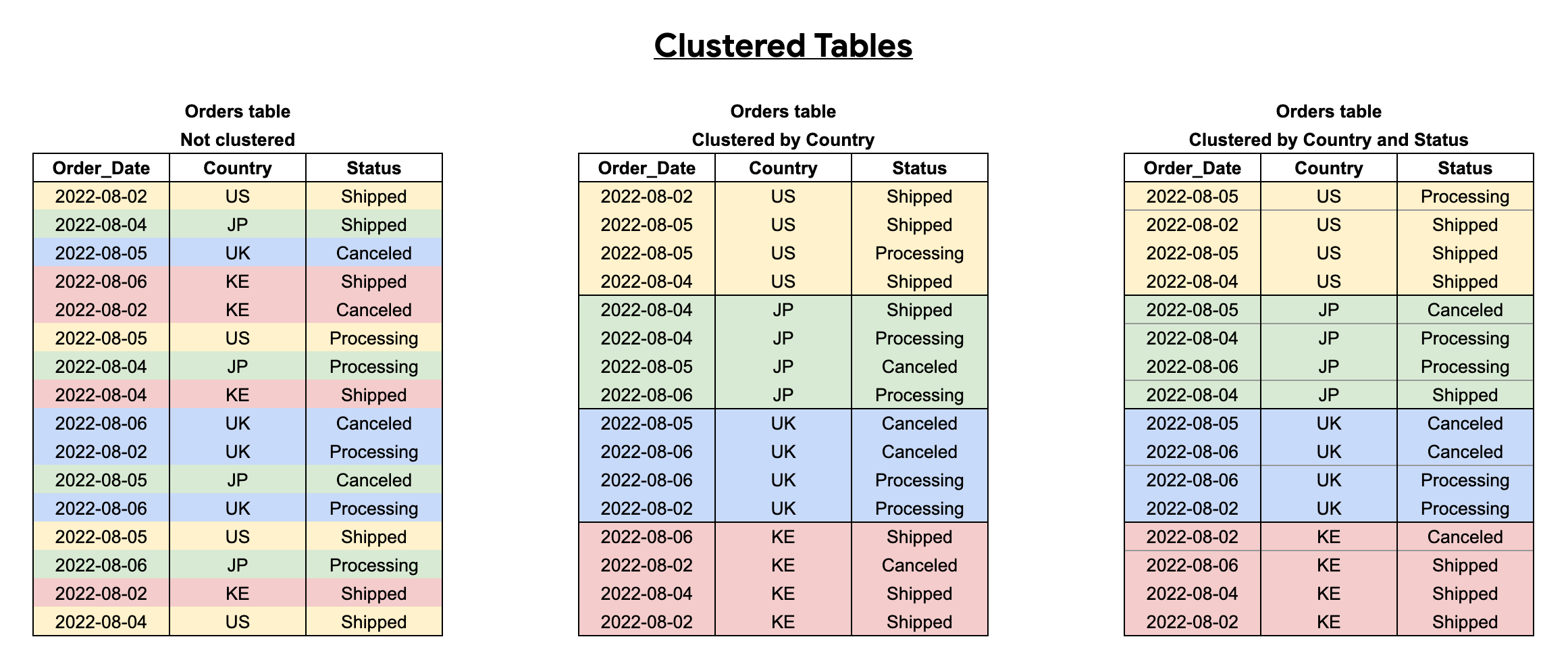
Quando esegui una query su una tabella clusterizzata, non ricevi una stima accurata del costo della query prima dell'esecuzione perché il numero di blocchi di archiviazione da analizzare non è noto prima dell'esecuzione della query. Il costo finale viene determinato al termine dell'esecuzione della query e si basa sui blocchi di archiviazione specifici sottoposti a scansione.
Quando usare il clustering
Il clustering riguarda il modo in cui una tabella viene archiviata, quindi in genere è una buona prima opzioni per migliorare le prestazioni delle query. Pertanto, devi sempre prendere in considerazione il clustering per i seguenti vantaggi:
- Le tabelle non partizionate di dimensioni superiori a 64 MB potrebbero trarre vantaggio dal clustering. Analogamente, anche le partizioni di tabelle superiori a 64 MB possono beneficiare del clustering. È possibile eseguire il clustering di tabelle o partizioni più piccole, ma il miglioramento delle prestazioni è in genere trascurabile.
- Se le query vengono spesso filtrate in base a colonne specifiche, il clustering accelera le query perché vengono analizzati solo i blocchi corrispondenti al filtro.
- Se le query filtrano in base a colonne con molti valori distinti (cardinalità elevata), il clustering accelera queste query fornendo a BigQuery metadati dettagliati su dove recuperare i dati di input.
- Il clustering consente di adattare le dimensioni dei blocchi di archiviazione sottostanti della tabella in base alle dimensioni della tabella.
Oltre al clustering, ti consigliamo di partizionare la tabella. In questo approccio, devi prima segmentare i dati in partizioni e poi raggrupparli in cluster all'interno di ciascuna partizione in base alle colonne di clustering. Valuta questo approccio nelle seguenti circostanze:
- Prima di eseguire una query, devi avere una stima rigorosa del costo della query. Il costo delle query sulle tabelle in cluster può essere determinato solo dopo l'esecuzione della query. Il partizionamento fornisce stime granulari dei costi delle query prima che vengano eseguite.
- La partizione della tabella comporta una dimensione media della partizione di almeno 10 GB per partizione. La creazione di molte piccole partizioni aumenta i metadati della tabella e può influire sui tempi di accesso ai metadati durante l'esecuzione di query sulla tabella.
- Devi aggiornare continuamente la tabella, ma vuoi comunque usufruire dei prezzi dello spazio di archiviazione a lungo termine. Il partizionamento consente di considerare ogni partizione separatamente per la verifica dell'idoneità ai prezzi a lungo termine. Se la tabella non è partizionata, per essere considerata ai fini della determinazione dei prezzi a lungo termine, l'intera tabella non deve essere modificata per 90 giorni consecutivi.
Per ulteriori informazioni, consulta Combinare tabelle in cluster e partizionate.
Tipi di colonne e ordine dei cluster
Questa sezione descrive i tipi di colonne e il funzionamento dell'ordine delle colonne nel clustering delle tabelle.
Tipi di colonne del cluster
Le colonne del cluster devono essere colonne di primo livello non ripetute che appartengono a uno dei seguenti tipi:
BIGNUMERICBOOLDATEDATETIMEGEOGRAPHYINT64NUMERICRANGESTRINGTIMESTAMP
Per saperne di più sui tipi di dati, consulta Tipi di dati di GoogleSQL.
Ordinamento delle colonne del cluster
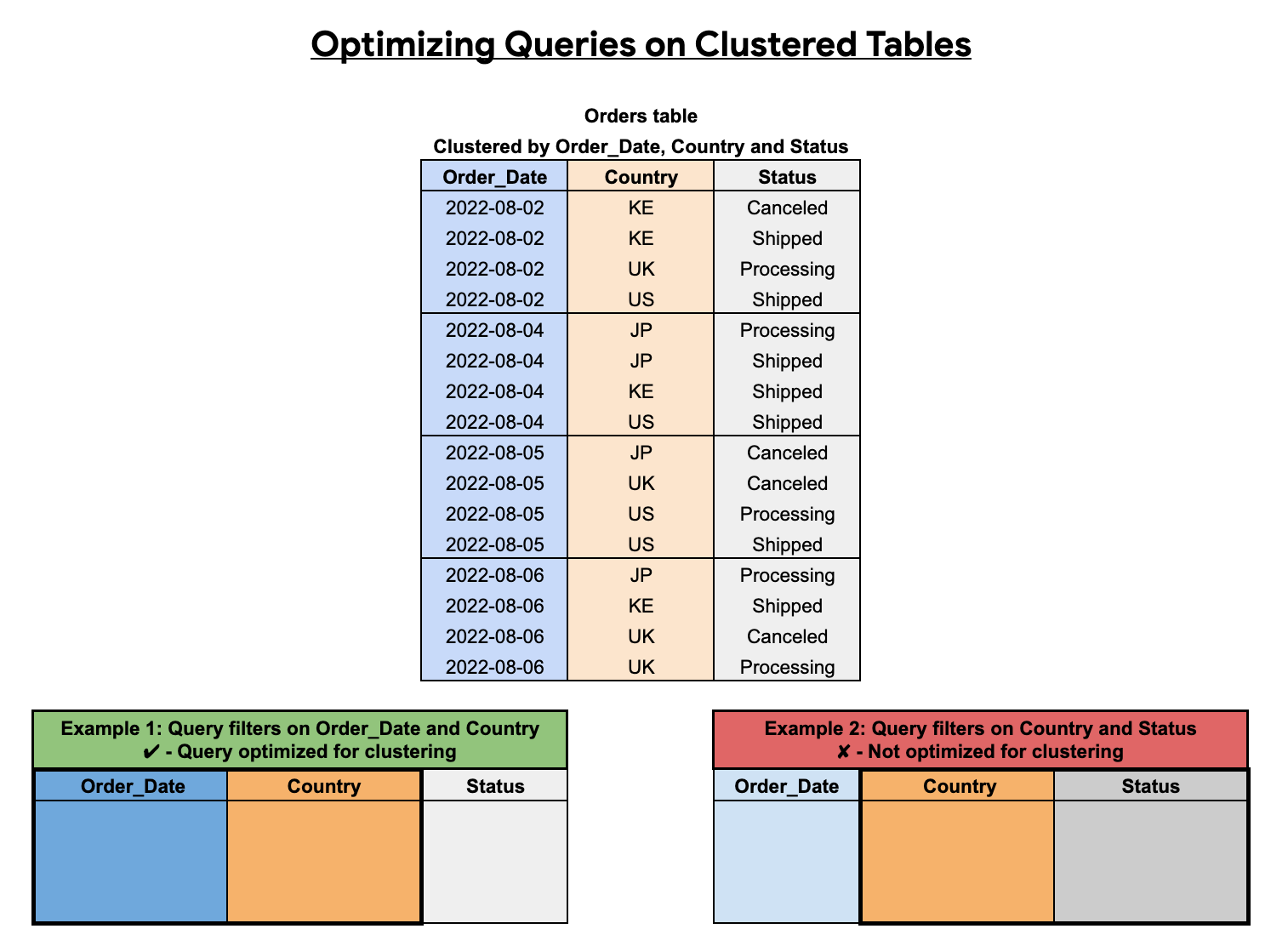
L'ordine delle colonne raggruppate influisce sulle prestazioni delle query. Nell'esempio seguente, la tabella Orders viene raggruppata in cluster utilizzando un ordine di ordinamento delle colonne Order_Date, Country e Status. La prima colonna raggruppata in questo esempio è Order_Date, pertanto una query che filtra in base a Order_Date e Country è ottimizzata per il clustering, mentre una query che filtra solo in base a Country e Status non è ottimizzata.
Eliminazione dei blocchi
Le tabelle in cluster possono aiutarti a ridurre i costi delle query eliminando i dati in modo che non vengano elaborati dalla query. Questo processo è chiamato eliminazione dei blocchi. BigQuery ordina i dati in una tabella in cluster in base ai valori nelle colonne di clustering e li organizza in blocchi.
Quando esegui una query su una tabella in cluster e la query include un filtro sulle colonne in cluster, BigQuery utilizza l'espressione di filtro e i metadati del blocco per eliminare i blocchi analizzati dalla query. In questo modo, BigQuery può eseguire la scansione solo dei blocchi pertinenti.
Quando un blocco viene eliminato, non viene scansionato. Solo i blocchi analizzati vengono utilizzati per calcolare i byte dei dati elaborati dalla query. Il numero di byte elaborati da una query su una tabella in cluster corrisponde alla somma dei byte letti in ogni colonna a cui fa riferimento la query nei blocchi analizzati.
Se una query che utilizza diversi filtri fa riferimento più volte a una tabella in cluster, BigQuery addebita l'analisi delle colonne nei blocchi appropriati in ciascuno dei rispettivi filtri. Per un esempio di come funziona l'eliminazione dei blocchi, vedi Esempio.
Combinare tabelle in cluster e partizionate
Puoi combinare il clustering delle tabelle con il partizionamento delle tabelle per ottenere un'ordinamento granulare per un'ulteriore ottimizzazione delle query.
In una tabella partizionata, i dati vengono archiviati in blocchi fisici, ciascuno dei quali contiene una partizione di dati. Ogni tabella partizionata gestisce vari metadati relativi alle proprietà di ordinamento in tutte le operazioni che la modificano. I metadati consentono a BigQuery di stimare con maggiore precisione il costo di una query prima che venga eseguita. Tuttavia, il partizionamento richiede a BigQuery di gestire più metadati rispetto a una tabella non partizionata. Man mano che il numero di partizioni aumenta, aumenta anche la quantità di metadati da gestire.
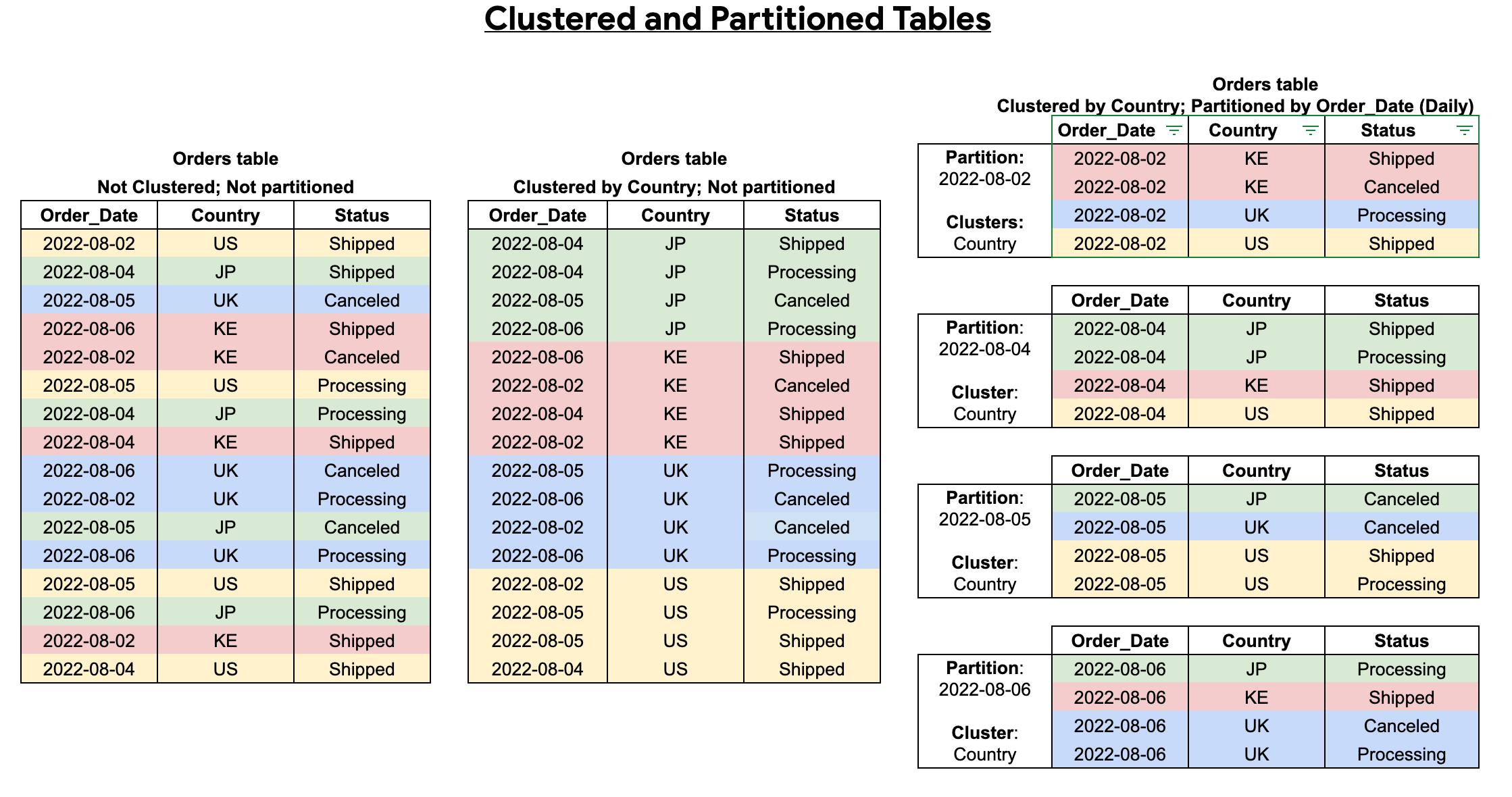
Quando crei una tabella clusterizzata e partizionata, puoi ottenere un'ordinamento più granulare, come mostrato nel seguente diagramma:
Esempio
Hai una tabella in cluster denominata ClusteredSalesData. La tabella è partizionata in base alla colonna timestamp ed è raggruppata in cluster in base alla colonna customer_id. I dati sono organizzati nel seguente insieme di blocchi:
| Identificatore di partizione | ID blocco | Valore minimo per customer_id nel blocco | Valore massimo per customer_id nel blocco |
|---|---|---|---|
| 20160501 | B1 | 10000 | 19999 |
| 20160501 | B2 | 20000 | 24999 |
| 20160502 | B3 | 15000 | 17999 |
| 20160501 | B4 | 22000 | 27999 |
Esegui la seguente query sulla tabella. La query contiene un filtro nella colonna customer_id.
SELECT SUM(totalSale) FROM `mydataset.ClusteredSalesData` WHERE customer_id BETWEEN 20000 AND 23000 AND DATE(timestamp) = "2016-05-01"
La query precedente prevede i seguenti passaggi:
- Analizza le colonne
timestamp,customer_idetotalSalenei blocchi B2 e B4. - Elimina il blocco B3 a causa del predicato del filtro
DATE(timestamp) = "2016-05-01"nella colonna di partizionamentotimestamp. - Elimina il blocco B1 a causa del predicato del filtro
customer_id BETWEEN 20000 AND 23000nella colonna di clusteringcustomer_id.
Ricoindicizzazione automatica
Quando i dati vengono aggiunti a una tabella cluster, i nuovi dati vengono organizzati in blocchi, che potrebbero creare nuovi blocchi di archiviazione o aggiornare quelli esistenti. L'ottimizzazione dei blocchi è necessaria per ottimizzare le prestazioni di query e archiviazione perché i nuovi dati potrebbero non essere raggruppati con i dati esistenti che hanno gli stessi valori del cluster.
Per mantenere le caratteristiche di rendimento di una tabella raggruppata, BigQuery esegue il ricoinvolgimento automatico in background. Per le tabelle partizionate, il clustering viene mantenuto per i dati nell'ambito di ogni partizione.
Limitazioni
- Solo GoogleSQL è supportato per eseguire query sulle tabelle clusterizzate e per scrivere i risultati delle query nelle tabelle clusterizzate.
- Puoi specificare fino a quattro colonne di raggruppamento. Se hai bisogno di altre colonne, ti consigliamo di combinare il clustering con il partizionamento.
- Quando utilizzi colonne di tipo
STRINGper il clustering, BigQuery utilizza solo i primi 1024 caratteri per raggruppare i dati. I valori nelle colonne possono essere più lunghi di 1024 caratteri. - Se modifichi una tabella non raggruppata esistente in modo che sia raggruppata, i dati esistenti
non vengono raggruppati automaticamente. Solo i nuovi dati archiviati utilizzando le colonne in cluster sono soggetti al ricoinvolgimento automatico. Per ulteriori informazioni sul ricoinvolgimento dei dati esistenti utilizzando un'istruzione
UPDATE, consulta Modificare la specifica di raggruppamento.
Quote e limiti delle tabelle in cluster
BigQuery limita l'utilizzo delle risorse Google Cloud condivise con quote e limiti, incluse limitazioni per determinate operazioni sulle tabelle o sul numero di job eseguiti in un giorno.
Quando utilizzi la funzionalità della tabella cluster con una tabella partizionata, devi rispettare i limiti per le tabelle partizionate.
Le quote e i limiti si applicano anche ai diversi tipi di job che puoi eseguire su tabelle clusterizzate. Per informazioni sulle quote dei job che si applicano alle tue tabelle, consulta Job in "Quote e limiti".
Prezzi delle tabelle in cluster
Quando crei e utilizzi tabelle in cluster in BigQuery, i tuoi addebiti dipendono dalla quantità di dati archiviati nelle tabelle e dalle query eseguite sui dati. Per maggiori informazioni, consulta Prezzi di archiviazione e Prezzi delle query.
Come le altre operazioni sulle tabelle BigQuery, le operazioni sulle tabelle raggruppate sfruttano le operazioni gratuite di BigQuery come il caricamento batch, la copia delle tabelle, il ricoinvolgimento automatico e l'esportazione dei dati. Queste operazioni sono soggette a quote e limiti di BigQuery. Per informazioni sulle operazioni gratuite, consulta Operazioni gratuite.
Per un esempio dettagliato dei prezzi delle tabelle in cluster, consulta Stimare i costi di query e archiviazione.
Sicurezza delle tabelle
Per controllare l'accesso alle tabelle in BigQuery, consulta Controllare l'accesso alle risorse con IAM.
Passaggi successivi
- Per scoprire come creare e utilizzare le tabelle in cluster, consulta Creare e utilizzare le tabelle in cluster.
- Per informazioni su come eseguire query sulle tabelle in cluster, consulta Eseguire query sulle tabelle in cluster.