聚簇表简介
BigQuery 中的聚簇表是使用聚簇列具有用户定义的列排列顺序的表。聚簇表可以提高查询性能并降低查询费用。
在 BigQuery 中,聚簇列是用户定义的表属性,用于根据聚簇列中的值对存储块进行排序。存储块根据表的大小进行自适应调整。共置发生在存储块级层,而不是在个别行级层;如需详细了解在此上下文中的共置,请参阅聚簇。
在对聚簇表进行修改的每个操作的上下文中,聚簇表都会维护排序属性。按聚簇列过滤或聚合的查询只会根据聚簇列(而不是整个表或表分区)扫描相关块。因此,BigQuery 可能无法准确地估算查询处理的字节数或查询费用,但它会在执行查询时尝试减少总字节数。
使用多个列对表进行聚簇时,列顺序决定了 BigQuery 在将数据排序并分组到存储块中时优先使用哪些列,如以下示例所示。表 1 显示了未聚簇表的逻辑存储块布局。相比之下,表 2 仅按 Country 列聚簇,而表 3 按多个列(Country 和 Status)聚簇。
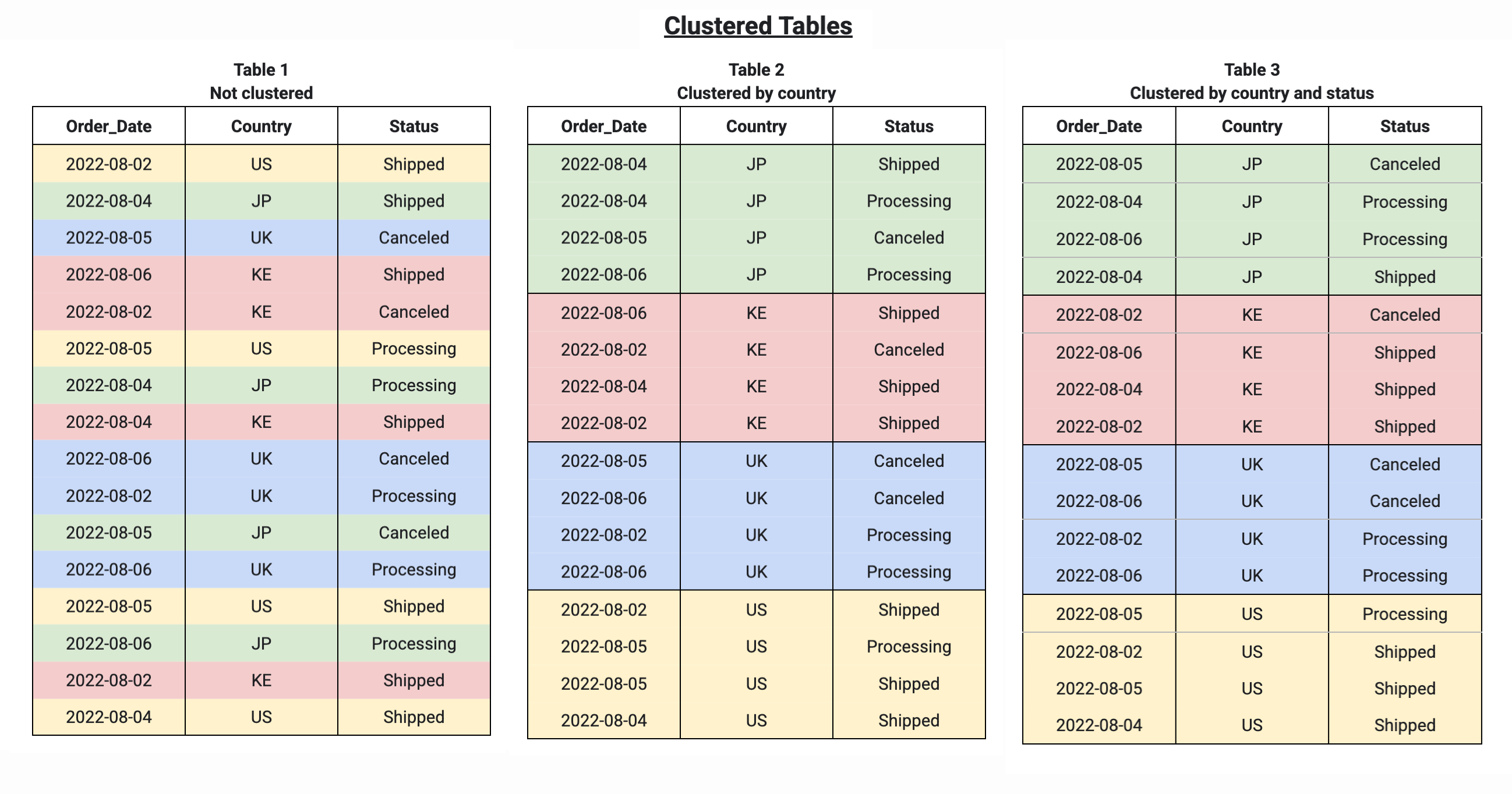
如果您查询聚簇表,则在查询执行之前,您不会收到准确的查询费用估算,因为在查询执行之前要扫描的存储块数量未知。最终费用是在查询执行完成后确定的,并且基于已扫描的特定存储块。
何时使用聚簇
聚簇解决了表的存储方式,因此它通常是一种提高查询性能的优选方法。因此,您应始终考虑聚簇,因为它可提供以下优势:
- 大小超过 64 MB 的未分区表可能会受益于聚簇。同样,大小超过 64 MB 的表分区也可能会受益于聚簇。可以对较小的表或分区进行聚簇,但性能提升通常微乎其微。
- 如果查询通常对特定列进行过滤,则聚簇会加快查询速度,因为查询只会扫描与过滤条件匹配的块。
- 如果查询对具有许多不同值(高基数)的列进行过滤,则聚簇可向 BigQuery 提供获取输入数据的位置的详细元数据,从而加快这些查询的速度。
- 通过聚簇,表的底层存储块可根据表的大小进行自适应调整。
除了聚簇之外,您还可以考虑对表进行分区。在此方法中,首先将数据细分为分区,然后按聚簇列对每个分区中的数据进行聚簇。在以下情况下,请考虑使用此方法:
- 在运行查询之前,您需要严格的查询费用估算。只有在运行查询后,才能确定对聚簇表的查询的费用。分区在运行查询之前提供精细的查询费用估算。
- 对表进行分区后,每个分区的平均分区大小至少为 10 GB。创建许多小型分区会增加表的元数据,并且在查询表时可能会影响元数据访问时间。
- 您需要持续更新表,但仍希望利用长期存储价格这一优惠。通过分区,您可以单独考虑每个分区是否符合长期价格的条件。如果表未分区,则对于整个表,不得连续 90 天进行修改,才会考虑使用长期价格。
如需了解详情,请参阅结合使用聚簇表和分区表。
聚簇列类型和排序
本部分介绍列类型以及列顺序在表聚簇中的工作原理。
聚簇列类型
聚簇列必须是以下任一类型的顶级非重复列:
BIGNUMERICBOOLDATEDATETIMEGEOGRAPHYINT64NUMERICRANGESTRINGTIMESTAMP
如需详细了解数据类型,请参阅 GoogleSQL 数据类型。
聚簇列排序
聚簇列的顺序会影响查询性能。在以下示例中,Orders表使用列排列顺序 Order_Date、Country 和 Status 进行聚簇。此示例中的第一个聚簇列为 Order_Date,因此按 Order_Date 和 Country 过滤的查询针对聚簇进行了优化,而仅按 Country 和 Status 过滤的查询未进行优化。
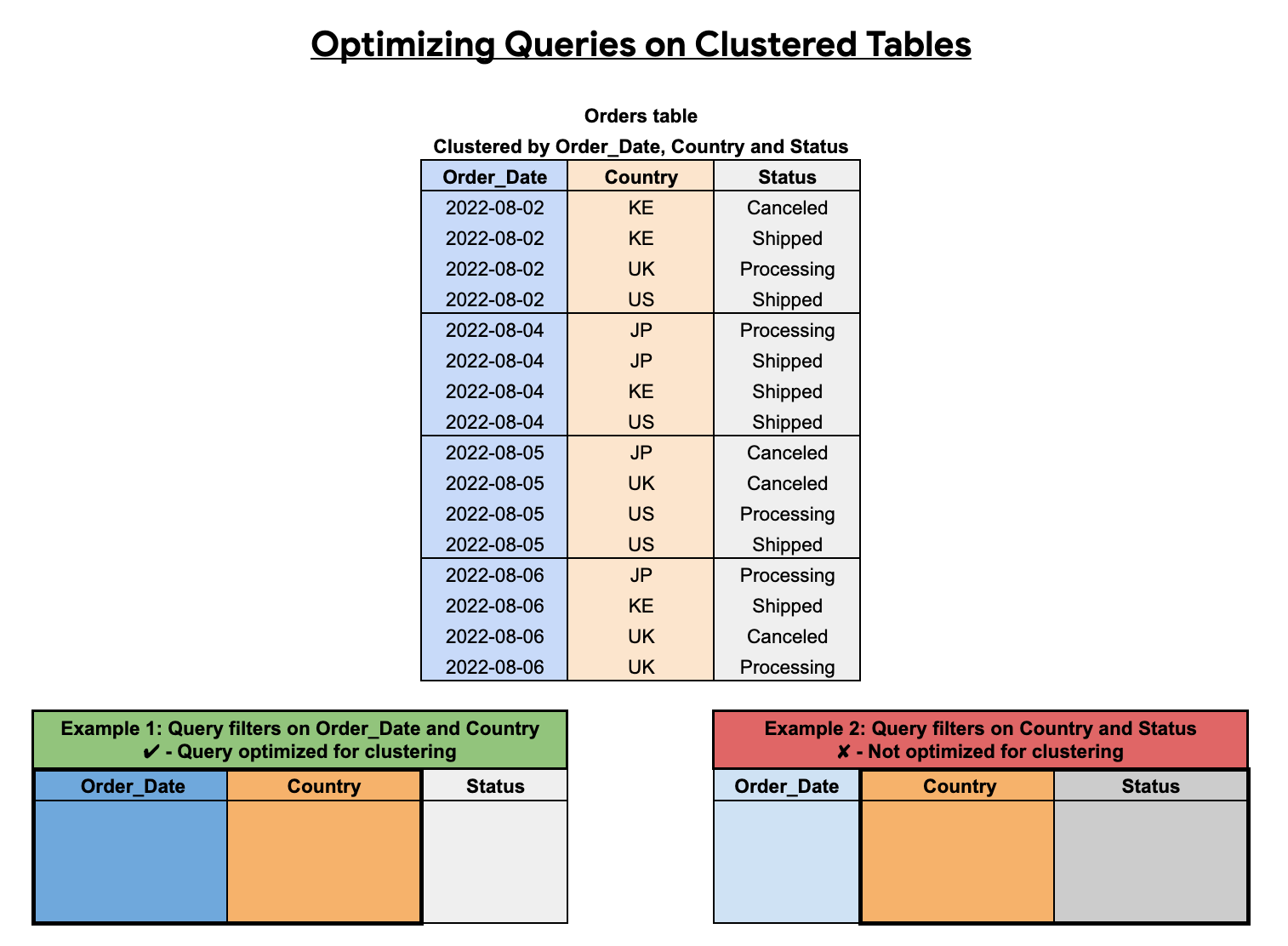
块剪除
聚簇表可通过剪除数据,使其免于查询处理,从而帮助降低查询费用。此过程称为块剪除。 BigQuery 会根据聚簇列中的值对聚簇表中的数据排序,并将这些数据整理为块的形式。
如果您对聚簇表运行查询,并且此查询包含针对聚簇列的过滤条件,则 BigQuery 会使用过滤条件表达式和块元数据来删减查询扫描的块。这样一来,BigQuery 就可以仅扫描相关块。
当某个块被剪除后,系统不会对其进行扫描。只有经过扫描的块才会计入查询所处理的数据量(以字节为单位)。对聚簇表运行的查询所处理的字节数,等于系统在所扫描的块内从该查询引用的每个列中读取的字节总数。
如果聚簇表在使用了多个过滤条件的查询中被引用了多次,则 BigQuery 会分别收取各个过滤条件下相应块中列的扫描费用。 如需查看块删减工作原理的示例,请参阅示例。
结合使用聚簇表和分区表
您可以将表聚簇与表分区结合使用,以实现精细排序,从而进一步优化查询。
在分区表中,数据存储在物理块中,而每个物理块都包含一个数据分区。每个分区表都会维护修改它的所有操作的相关排序属性的各种元数据。元数据可让 BigQuery 在查询运行之前更准确地估算查询费用。但是,与使用未分区表相比,分区要求 BigQuery 保留更多的元数据。随着分区数量的增加,要维护的元数据量也会增加。
创建聚簇和分区的表时,您可以实现更精细的排序,如下图所示:
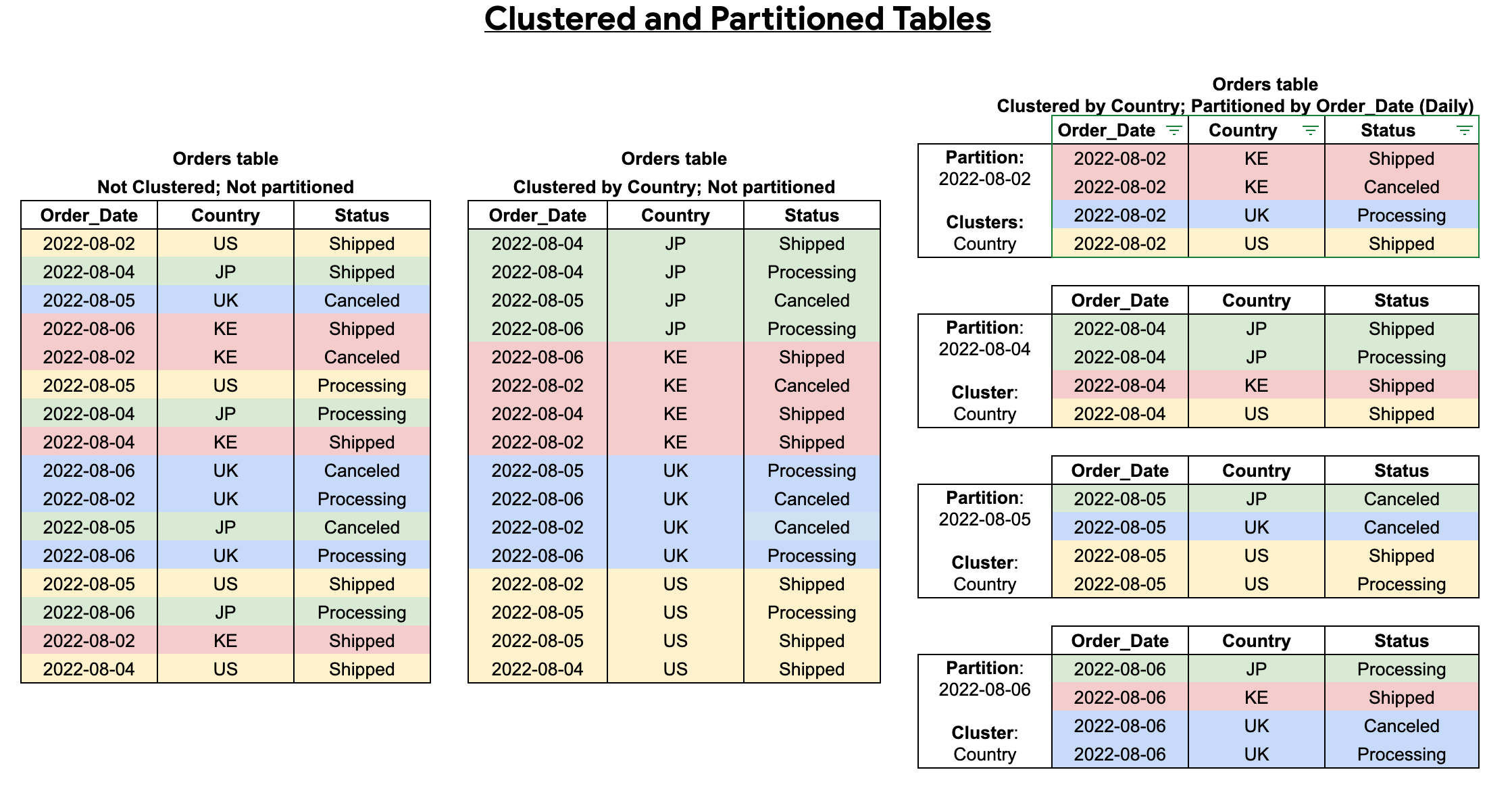
示例
您有一个名为 ClusteredSalesData 的聚簇表。该表按 timestamp 列分区,并按 customer_id 列聚簇。数据整理到下面这些块中:
| 分区标识符 | 块 ID | 块中 customer_id 的最小值 | 块中 customer_id 的最大值 |
|---|---|---|---|
| 20160501 | B1 | 10000 | 19999 |
| 20160501 | B2 | 20000 | 24999 |
| 20160502 | B3 | 15000 | 17999 |
| 20160501 | B4 | 22000 | 27999 |
您对该表运行以下查询。此查询包含对 customer_id 列应用的过滤条件。
SELECT SUM(totalSale) FROM `mydataset.ClusteredSalesData` WHERE customer_id BETWEEN 20000 AND 23000 AND DATE(timestamp) = "2016-05-01"
上述查询涉及以下步骤:
- 扫描 B2 和 B4 块中的
timestamp、customer_id、totalSale列。 - 剪除 B3 块,因为在
timestamp分区列上应用了DATE(timestamp) = "2016-05-01"过滤条件谓语。 - 剪除 B1 块,因为在
customer_id聚簇列上应用了customer_id BETWEEN 20000 AND 23000过滤条件谓语。
自动重新聚簇
当数据添加到聚簇表时,新数据会整理成块,这可能会创建新的存储块或更新现有块。必须进行块优化才能获得最佳查询和存储性能,因为新数据可能无法与具有相同聚簇值的现有数据分组。
为了维护聚簇表的性能特征,BigQuery 会在后台执行自动重新聚簇。对于分区表,系统会为每个分区范围内的数据维护聚簇操作。
限制
- 仅支持使用 GoogleSQL 查询聚簇表以及将查询结果写入聚簇表。
- 您最多只能指定四个聚簇列。如果您需要更多列,请考虑将聚簇与分区结合使用。
- 使用
STRING类型的列进行聚簇时,BigQuery 仅使用前 1,024 个字符为数据划分聚簇。列中的值本身可以超过 1,024 个字符。 - 如果将现有的非聚簇表更改为聚簇表,则现有数据不会自动进行聚簇。只有使用聚簇列存储的新数据才会自动进行重新聚簇。如需详细了解如何使用
UPDATE语句对现有数据进行重新聚簇,请参阅修改聚簇规范。
聚簇表配额和限制
BigQuery 会通过配额和限额限制共享 Google Cloud 资源的使用,包括对某些表操作或一天内运行的作业数量设置限制。
将聚簇表功能与分区表结合使用时,您需要遵循分区表限制。
配额和限制也适用于针对聚簇表运行的不同类型的作业。如需了解适用于表的作业配额,请参阅“配额和限制”中的作业。
聚簇表价格
在 BigQuery 中创建和使用聚簇表时,您要支付的费用取决于表中存储的数据量以及您对数据执行的查询。如需了解详情,请参阅存储价格和查询价格。
与其他 BigQuery 表操作一样,聚簇表操作可利用 BigQuery 免费操作,例如批量加载、表复制、自动重新聚簇和数据导出。这些操作受 BigQuery 配额和限制的约束。如需了解免费操作,请参阅免费操作。
如需查看详细的聚簇表价格示例,请参阅估算存储和查询费用。
表安全性
如需控制对 BigQuery 中的表的访问权限,请参阅使用 IAM 控制对资源的访问权限。