クラスタ化テーブルの概要
BigQuery のクラスタ化テーブルは、クラスタ化列を使用したユーザー定義の列並べ替え順序があるテーブルです。クラスタ化テーブルを使用すると、クエリのパフォーマンスを向上させ、クエリ費用を削減できます。
BigQuery におけるクラスタ列は、クラスタ列の値に基づいてストレージ ブロックを並べ替える、ユーザー定義のテーブル プロパティです。ストレージ ブロックのサイズはテーブルのサイズに基づいて適切に調整されます。コローケーションは、個々の行のレベルではなく、ストレージ ブロックのレベルで行われます。このコンテキストにおけるコローケーションの詳細については、クラスタリングをご覧ください。
クラスタ化テーブルは、テーブルを変更する各オペレーションのコンテキストの中で並べ替えプロパティを維持します。クラスタ化列でフィルタや集計を行うクエリは、テーブルやテーブル パーティション全体ではなく、クラスタ化列に基づいて関連するブロックのみをスキャンします。その結果、BigQuery は、クエリで処理されるバイト数、またはクエリの費用を正確に見積もることができない場合でも、実行時に合計バイト数の削減を試みます。
複数の列を使用してテーブルをクラスタ化する場合、BigQuery がデータを並べ替えてストレージ ブロックにグループ化する際に、列の順序によってどの列が優先されるかが決まります(次の例を参照)。テーブル 1 は、クラスタ化されていないテーブルの論理ストレージ ブロック レイアウトを示しています。比較すると、テーブル 2 は Country 列でのみクラスタ化されていますが、テーブル 3 は複数の列(Country と Status)でクラスタ化されています。
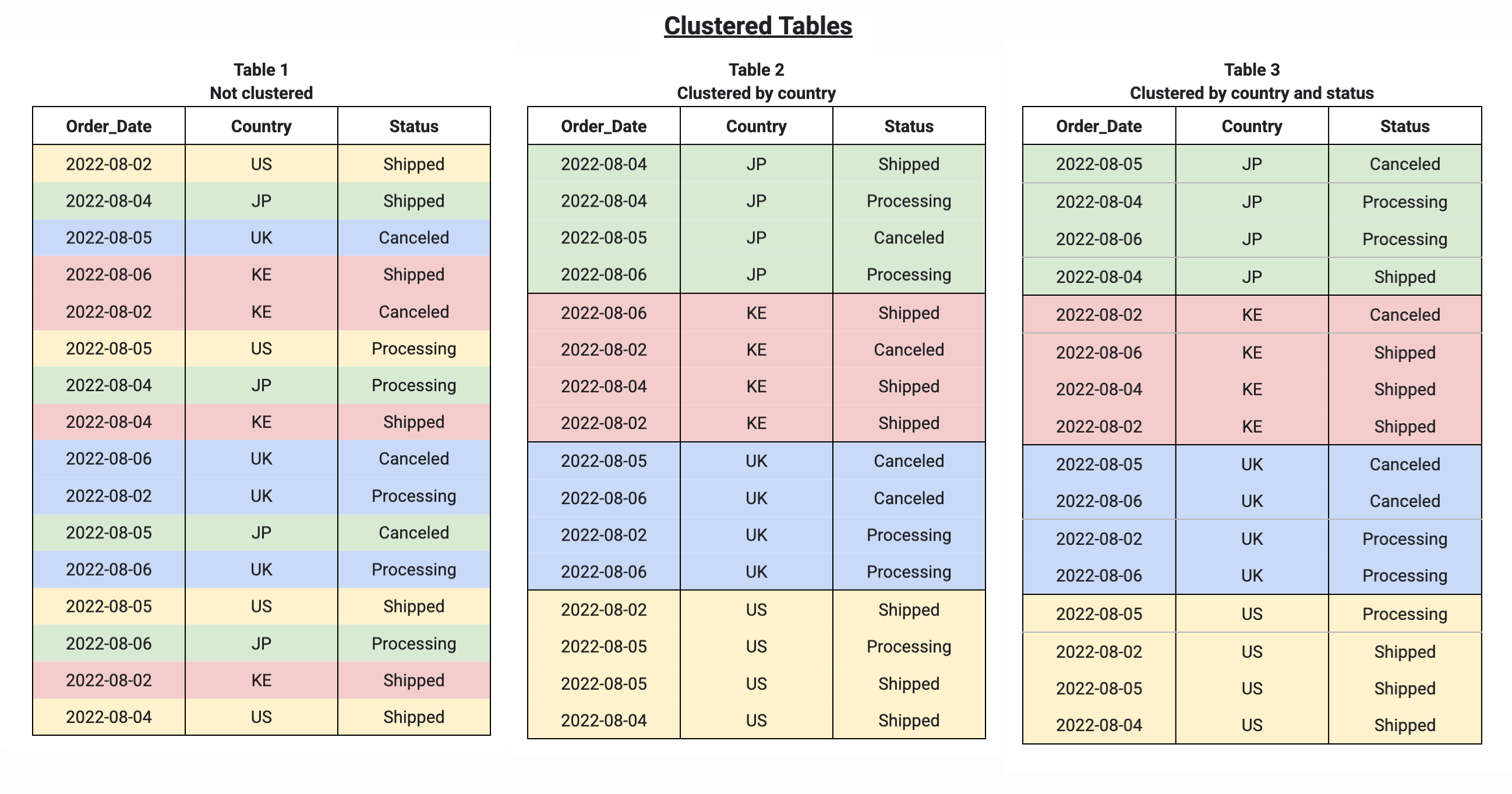
クラスタ化テーブルに対してクエリを実行する場合、クエリを実行する前はスキャンされるストレージ ブロック数が不明なため、正確なクエリ費用の見積りを得られません。最終的な費用は、クエリの完了後に、スキャンされた特定のストレージ ブロックに基づいて求められます。
クラスタリングを使用する場合
クラスタ化は、テーブルを保存する仕組みに対するものであるため、通常はクエリのパフォーマンスを向上させる最初の選択肢になります。したがって、次の利点を前提として、クラスタ化について常に検討する必要があります。
- 64 MB を超えるパーティション分割されていないテーブルは、クラスタ化によってメリットが得られる可能性があります。同様に、64 MB を超えるテーブル パーティションも、クラスタ化によってメリットが得られる可能性があります。より小さいテーブルやパーティションをクラスタ化することは可能ですが、通常、パフォーマンスの向上はごくわずかです。
- クエリでよく特定の列をフィルタする場合は、クラスタ化によってクエリが高速化されます。クエリはフィルタに一致するブロックのみをスキャンするためです。
- 異なる値が多い(カーディナリティが高い)列をクエリでフィルタする場合、クラスタ化によってこれらのクエリが高速化されます。入力データの取得場所に関する詳細なメタデータが BigQuery に提供されるためです。
- クラスタ化により、テーブルの基盤となるストレージ ブロックのサイズをテーブルのサイズに基づいて適切に調整できます。
クラスタ化に加えて、テーブルのパーティショニングも検討できます。この方法では、まずデータをパーティションに分割してから、クラスタ化列ごとに各パーティション内のデータをクラスタ化します。この方法は、次のような状況で検討してください。
- クエリを実行する前に、クエリ費用を厳密に見積る必要がある場合。クラスタ化テーブルに対するクエリの費用は、クエリ実行後にのみわかります。パーティショニングにより、クエリを実行する前にクエリの費用を細かく見積もることができます。
- テーブルをパーティショニングすると、平均のパーティション サイズがパーティションあたり 10 GB 以上になる場合。小さなパーティションを多数作成すると、テーブルのメタデータが増加し、テーブルをクエリする際のメタデータ アクセス時間に影響する可能性があります。
- テーブルを継続的に更新する必要があるものの、長期保存の料金を適用したい場合。パーティショニングを行うことで、長期保存料金が適用されるかどうかをパーティションごとにそれぞれ検討できるようになります。テーブルがパーティション分割されていない場合は、テーブル全体が 90 日間連続して編集されていない場合に限り、長期保存料金の対象となります。
詳細については、クラスタ化テーブルとパーティション分割テーブルを組み合わせるをご覧ください。
クラスタ列の型と順序
このセクションでは、テーブルのクラスタ化での列の型と列の順序について説明します。
クラスタ列の型
クラスタ列は、最上位の非繰り返し列で、次のいずれかの型である必要があります。
BIGNUMERICBOOLDATEDATETIMEGEOGRAPHYINT64NUMERICRANGESTRINGTIMESTAMP
データ型の詳細については、GoogleSQL のデータ型をご覧ください。
クラスタ列の順序
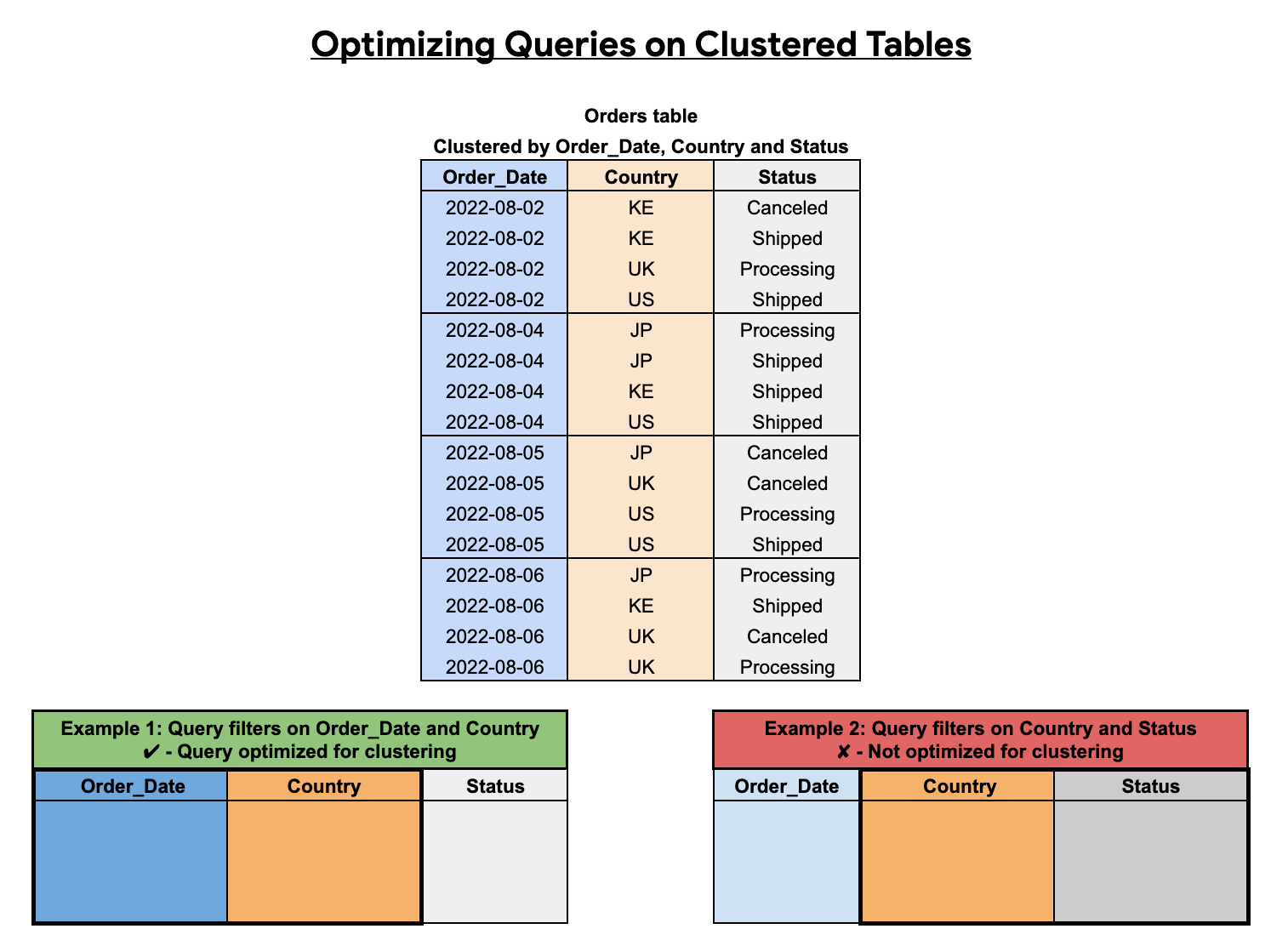
クラスタ化列の順序はクエリのパフォーマンスに影響します。次の例では、Orders 表は Order_Date、Country、Status の列並べ替え順序を使用してクラスタ化されます。この例の最初のクラスタ列は Order_Date であるため、Order_Date と Country でフィルタするクエリはクラスタ化用に最適化されていますが、Country と Status のみでフィルタするクエリは最適化されていません。
ブロック プルーニング
クラスタ化テーブルを使用すると、クエリで処理されないようにデータをプルーニングしてクエリの費用を抑えることができます。このプロセスはブロック プルーニングといいます。BigQuery は、クラスタ化列の値に基づいてクラスタ化テーブルのデータを並べ替えて、データをブロックに整理します。
クラスタ化テーブルにクエリを実行するときに、そのクエリにクラスタ化された列のフィルタが含まれている場合、BigQuery はフィルタ式とブロック メタデータを使用して、クエリでスキャンされるブロックをプルーニングします。これにより、BigQuery は関連するブロックのみをスキャンできます。
ブロックがプルーニングされると、スキャンの対象外となります。クエリで処理されたデータのバイト数を計算する際に、スキャンされたブロックのみが使用されます。クラスタ化テーブルに実行したクエリで処理されるバイト数は、スキャンされたブロック内で、クエリによって参照された各列から読み取られたバイト数の合計と等しくなります。
複数のフィルタを使用するクエリでクラスタ化テーブルが複数回参照された場合、BigQuery は、各フィルタによる該当するブロックの列のスキャンに対して課金します。ブロック プルーニングの仕組みの例については、例をご覧ください。
クラスタ化テーブルとパーティション分割テーブルを組み合わせる
テーブル クラスタ化とテーブル パーティショニングを組み合わせると、クエリを細かく最適化できます。
パーティション分割テーブルでは、データが物理ブロックに保存され、各ブロックに 1 つのデータ パーティションが保持されます。各パーティション分割テーブルには、そのテーブルを変更するすべてのオペレーションについて、並べ替えプロパティに関するさまざまなメタデータが保持されます。メタデータを使用すると、BigQuery でクエリを実行する前にクエリの費用をより正確に見積もることができます。ただし、パーティショニングでは、パーティション分割テーブル以外のテーブルより多くのメタデータを BigQuery で保持する必要があります。パーティションの数が増えると、保持されるメタデータの量も増加します。
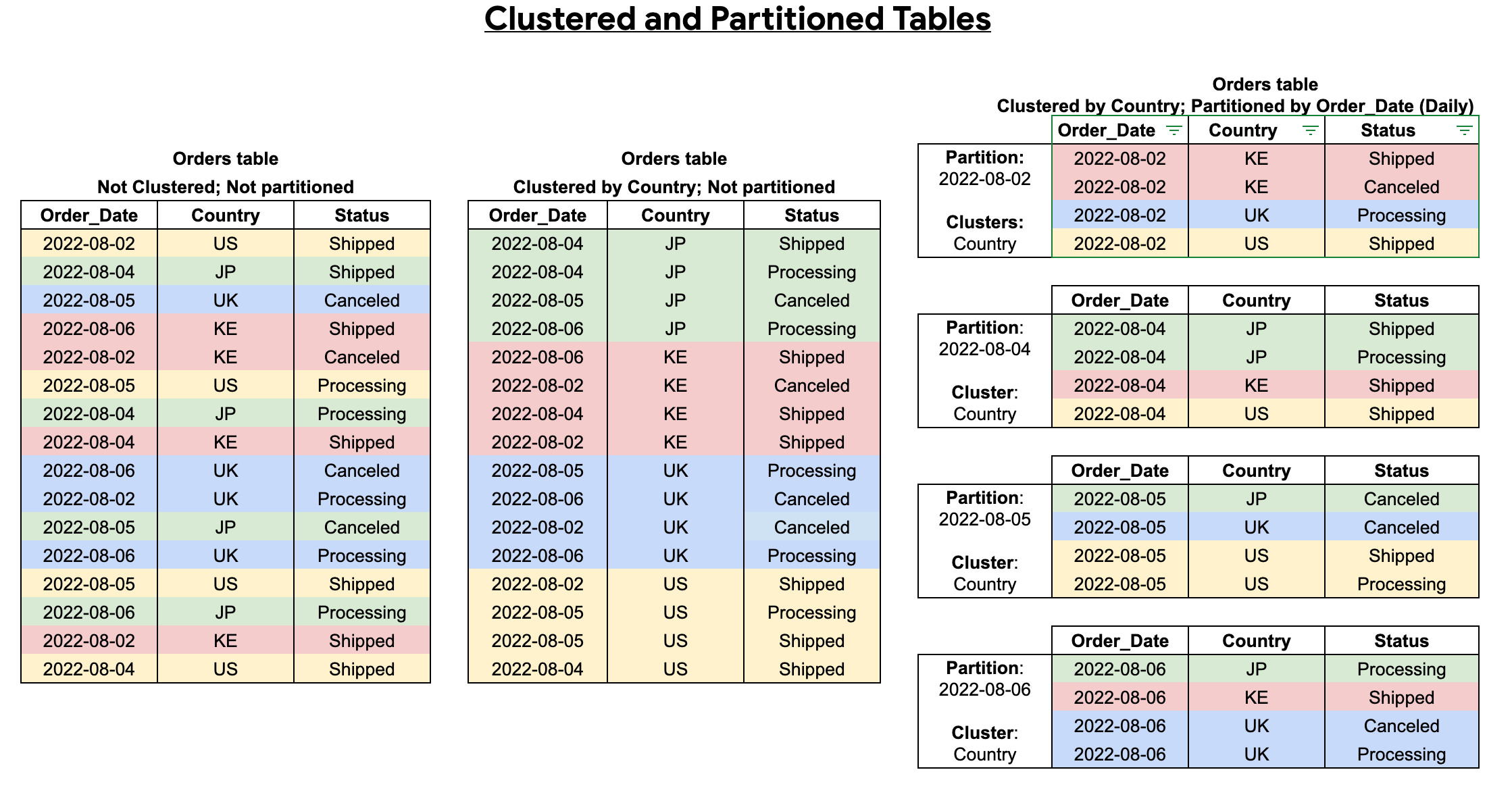
クラスタ化およびパーティション分割されたテーブルを作成すると、次の図に示すように、より細かい並べ替えを行うことができます。
例
ClusteredSalesData という名前のクラスタ化テーブルがあります。テーブルは timestamp 列で分割され、customer_id 列でクラスタ化されています。データは次のブロックセットに編成されます。
| パーティション ID | ブロック ID | ブロック内の customer_id の最小値 | ブロック内の customer_id の最大値 |
|---|---|---|---|
| 20160501 | B1 | 10000 | 19999 |
| 20160501 | B2 | 20000 | 24999 |
| 20160502 | B3 | 15000 | 17999 |
| 20160501 | B4 | 22000 | 27999 |
このテーブルに次のクエリを実行します。このクエリでは、customer_id 列のフィルタが含まれています。
SELECT SUM(totalSale) FROM `mydataset.ClusteredSalesData` WHERE customer_id BETWEEN 20000 AND 23000 AND DATE(timestamp) = "2016-05-01"
上記のクエリには次の手順が含まれます。
- ブロック B2 と B4 の
timestamp、customer_id、totalSale列をスキャンします。 timestampパーティショニング列に対するDATE(timestamp) = "2016-05-01"というフィルタ述語があるため、B3 ブロックをプルーニングします。customer_idクラスタ化列に対するcustomer_id BETWEEN 20000 AND 23000というフィルタ述語があるため、B1 ブロックをプルーニングします。
自動再クラスタリング
データがクラスタ化テーブルに追加されると、新しいデータがブロックに編成されます。これにより、新しいストレージ ブロックの作成または既存のブロックの更新が行われる場合があります。新しいデータは、同じクラスタ値を持つ既存のデータとグループ化されていない可能性があるため、クエリとストレージのパフォーマンスを最適化するには、ブロックの最適化が必要です。
クラスタ化テーブルのパフォーマンス特性を維持するため、BigQuery はバックグラウンドで自動再クラスタ化を実行します。パーティション分割テーブルでは、各パーティションの範囲内のデータに対してクラスタ化が維持されます。
制限事項
- クラスタ化テーブルのクエリと、クラスタ化テーブルへのクエリ結果の書き込みは、GoogleSQL でのみサポートされています。
- 最大で 4 つのクラスタ化列を指定できます。追加の列が必要な場合は、クラスタ化とパーティショニングを組み合わせることを検討してください。
- クラスタ化に
STRING型の列を使用する場合、BigQuery は最初の 1,024 文字のみを使用してデータをクラスタ化します。列の値自体、1,024 文字を超える場合があります。 - 既存の非クラスタ化テーブルを変更してクラスタ化する場合、既存のデータは自動ではクラスタ化されません。クラスタ列を使用して保存された新しいデータのみが自動再クラスタリングの対象となります。
UPDATEステートメントを使用して既存のデータを再クラスタリングする方法について、詳細はクラスタリング仕様を変更するをご覧ください。
クラスタ化テーブルの割り当てと上限
BigQuery では、共有 Google Cloud リソースの使用を、割り当てと上限によって制限します。これには、特定のテーブル オペレーションや 1 日あたりのジョブ数の上限などがあります。
クラスタ化テーブルの機能をパーティション分割テーブルとともに使用すると、パーティション分割テーブルの上限が適用されます。
割り当てと上限は、クラスタ化テーブルに対して実行されるさまざまな種類のジョブにも適用されます。テーブルに適用されるジョブの割り当てについては、「割り当てと上限」のジョブをご覧ください。
クラスタ化テーブルの料金
BigQuery でクラスタ化テーブルを作成して使用する場合、テーブルに格納されるデータの量とデータに対して実行するクエリに基づいて料金が発生します。詳細については、ストレージの料金とクエリの料金をご覧ください。
他の BigQuery テーブル オペレーションと同様、クラスタ化テーブル オペレーションは、一括読み込み、テーブルコピー、自動再クラスタ化、データ エクスポートなどの BigQuery の無料オペレーションを活用します。これらのオペレーションには、BigQuery の割り当てと上限が適用されます。無料オペレーションの詳細については、無料のオペレーションをご覧ください。
クラスタ化テーブルの料金の例について詳しくは、ストレージとクエリの費用を見積もるをご覧ください。
テーブルのセキュリティ
BigQuery でテーブルへのアクセスを制御するには、IAM を使用してリソースへのアクセスを制御するをご覧ください。
次のステップ
- クラスタ化テーブルの作成方法と使用方法については、クラスタ化テーブルの作成と使用をご覧ください。
- クラスタ化テーブルのクエリについては、クラスタ化テーブルのクエリをご覧ください。