Cloud Storage-Daten in BigQuery laden
Mit dem BigQuery Data Transfer Service für Cloud Storage-Connector können Sie Daten aus Cloud Storage in BigQuery laden. Mit dem BigQuery Data Transfer Service können Sie wiederkehrende Übertragungsjobs planen, mit denen Ihre neuesten Daten aus Cloud Storage in BigQuery eingefügt werden.
Hinweise
Führen Sie vor dem Erstellen einer Cloud Storage-Datenübertragung die folgenden Schritte aus:
- Prüfen Sie, ob Sie alle erforderlichen Aktionen zum Aktivieren von BigQuery Data Transfer Service ausgeführt haben.
- Rufen Sie Ihren Cloud Storage-URI ab.
- Erstellen Sie ein BigQuery-Dataset zum Speichern Ihrer Daten.
- Erstellen Sie die Zieltabelle für Ihre Datenübertragung und geben Sie die Schemadefinition an.
- Wenn Sie einen vom Kunden verwalteten Verschlüsselungsschlüssel (CMEK) angeben möchten, muss Ihr Dienstkonto über die Berechtigungen zum Verschlüsseln und Entschlüsseln verfügen und Sie müssen die für die Verwendung von CMEK erforderliche Cloud KMS-Schlüsselressourcen-ID haben. Informationen zur Funktionsweise von CMEK mit dem BigQuery Data Transfer Service finden Sie unter Verschlüsselungsschlüssel mit Übertragungen angeben.
Beschränkungen
Für wiederkehrende Datenübertragungen von Cloud Storage nach BigQuery gelten die folgenden Beschränkungen:
- Alle Dateien, die entweder durch einen Platzhalter oder durch Laufzeitparameter für Ihre Datenübertragung definiert wurden, müssen dasselbe Schema verwenden, das Sie für die Zieltabelle definiert haben. Sonst schlägt die Datenübertragung fehl. Wenn das Tabellenschema zwischen zwei Ausführungen geändert wird, schlägt die Übertragung ebenfalls fehl.
- Cloud Storage-Objekte können versioniert werden. Deshalb ist zu beachten, dass archivierte Cloud Storage-Objekte für BigQuery-Datenübertragungen nicht unterstützt werden. Objekte müssen für die Übertragung live sein.
- Im Gegensatz zu einzelnen Datenlasten von Cloud Storage zu BigQuery müssen Sie für fortlaufende Datenübertragungen die Zieltabelle erstellen, bevor Sie die Datenübertragung einrichten. Für CSV- und JSON-Dateien müssen Sie auch das Tabellenschema im Voraus definieren. BigQuery kann die Tabelle nicht als Teil des wiederkehrenden Datenübertragungsprozesses erstellen.
- Bei Datenübertragungen aus Cloud Storage ist der Parameter Schreibeinstellung standardmäßig auf
APPENDgesetzt. In diesem Modus kann eine unveränderte Datei nur einmal in BigQuery geladen werden. Wenn das Attributlast modification timeder Datei aktualisiert wird, wird die Datei neu geladen. BigQuery Data Transfer Service garantiert nicht, dass alle Dateien übertragen oder nur einmal übertragen werden, wenn Cloud Storage-Dateien während einer Datenübertragung geändert werden. Beim Laden von Daten aus einem Cloud Storage-Bucket in BigQuery gelten die folgenden Beschränkungen:
BigQuery übernimmt bei externen Datenquellen keine Garantie für die Datenkonsistenz. Werden die zugrunde liegenden Daten während der Ausführung der Abfrage geändert, kann dies zu einem unerwarteten Verhalten führen.
BigQuery unterstützt nicht die Cloud Storage-Objektversionierung. Wenn Sie dem Cloud Storage-URI eine Generierungsnummer hinzufügen, schlägt der Ladejob fehl.
Je nach dem Format Ihrer Cloud Storage-Quelldaten sind weitere Beschränkungen möglich. Weitere Informationen finden Sie unter:
Ihr Cloud Storage-Bucket muss sich an einem Standort befinden, der mit der Region oder dem multiregionalen Standort des Ziel-Datasets in BigQuery kompatibel ist. Dies wird als Colocation bezeichnet. Ausführliche Informationen zur Cloud Storage-Übertragung finden Sie unter Datenspeicherorte.
Mindestintervalle
- Quelldateien werden ohne Mindestalter sofort zur Datenübertragung aufgenommen.
- Das Mindestintervall zwischen wiederkehrenden Übertragungen beträgt 15 Minuten. Das Standardintervall für wiederkehrende Datenübertragungen beträgt 24 Stunden.
- Sie können eine ereignisgesteuerte Übertragung einrichten, um Datenübertragungen automatisch in kürzeren Intervallen zu planen.
Erforderliche Berechtigungen
Wenn Sie Daten in BigQuery laden, benötigen Sie Berechtigungen zum Laden von Daten in neue oder vorhandene BigQuery-Tabellen und -Partitionen. Wenn Sie Daten aus Cloud Storage laden, benötigen Sie auch Zugriff auf den Bucket, der Ihre Daten enthält. Prüfen Sie, ob Sie die folgenden erforderlichen Berechtigungen haben:
BigQuery: Achten Sie darauf, dass die Person oder das Dienstkonto, die die Datenübertragung erstellt, die folgenden Berechtigungen in BigQuery hat:
bigquery.transfers.update-Berechtigungen zum Erstellen der Datenübertragung- Die Berechtigungen
bigquery.datasets.getundbigquery.datasets.updatefür das Ziel-Dataset
Die vordefinierte IAM-Rolle
bigquery.adminenthält die Berechtigungenbigquery.transfers.update,bigquery.datasets.updateundbigquery.datasets.get. Weitere Informationen zu IAM-Rollen im BigQuery Data Transfer Service finden Sie in der Zugriffssteuerung.Cloud Storage:
storage.objects.getEs sind Berechtigungen für die einzelnen Buckets oder höhere Berechtigungen erforderlich. Wenn Sie einen URI-Platzhalter verwenden, benötigen Sie außerdem Berechtigungen des Typsstorage.objects.list. Wenn Sie die Quelldateien nach jeder erfolgreichen Übertragung löschen möchten, benötigen Sie außerdem Berechtigungen vom Typstorage.objects.delete. Die vordefinierte Cloud IAM-Rollestorage.objectAdminenthält alle diese Berechtigungen.
Cloud Storage-Übertragung einrichten
So erstellen Sie eine Cloud Storage-Datenübertragung im BigQuery Data Transfer Service:
Console
Rufen Sie in der Google Cloud -Console die Seite „Datenübertragungen“ auf.
Klicken Sie auf Übertragung erstellen.
Wählen Sie im Abschnitt Quelltyp für Quelle die Option Google Cloud Storage aus.
Geben Sie im Abschnitt Transfer config name (Konfigurationsname für Übertragung) für Display name (Anzeigename) einen Namen wie
My Transferfür die Datenübertragung ein. Der Name kann ein beliebiger Wert sein, anhand dessen Sie die Übertragung identifizieren können, falls Sie sie später ändern müssen.
Wählen Sie im Abschnitt Zeitplanoptionen eine Wiederholungshäufigkeit aus:
Wenn Sie Stunden, Tage, Wochen oder Monate auswählen, müssen Sie auch eine Häufigkeit angeben. Sie können auch Benutzerdefiniert auswählen, um eine benutzerdefinierte Wiederholungshäufigkeit anzugeben. Wählen Sie Jetzt starten oder Zu festgelegter Zeit starten aus und geben Sie ein Startdatum und eine Ausführungszeit an.
Wenn Sie On demand auswählen, wird diese Datenübertragung ausgeführt, wenn Sie die Übertragung manuell auslösen.
Wenn Sie Ereignisgesteuert auswählen, müssen Sie auch ein Pub/Sub-Abo angeben. Wählen Sie den Namen für das Abo aus oder klicken Sie auf Abo erstellen. Mit dieser Option wird eine ereignisgesteuerte Übertragung aktiviert, die Übertragungen auslöst, wenn Ereignisse beim Pub/Sub-Abo eintreffen.
Wählen Sie im Abschnitt Zieleinstellungen für Ziel-Dataset das Dataset aus, das Sie zum Speichern Ihrer Daten erstellt haben.
Führen Sie im Abschnitt Details zur Datenquelle Folgendes aus:
- Geben Sie für Destination table (Zieltabelle) den Namen Ihrer Zieltabelle ein. Die Zieltabelle muss den Regeln für die Tabellenbenennung folgen. In Namen von Zieltabellen sind auch Parameter möglich.
- Geben Sie bei Cloud Storage-URI den Cloud Storage-URI ein. Platzhalter und Parameter werden unterstützt. Wenn der URI mit keiner Datei übereinstimmt, werden in der Zieltabelle keine Daten überschrieben.
Wählen Sie unter Schreibeinstellung eine der folgenden Optionen aus:
- APPEND, um neue Daten an die vorhandene Zieltabelle inkrementell anzuhängen. APPEND ist der Standardwert für die Schreibeinstellung.
- MIRROR, um Daten in der Zieltabelle bei jeder Datenübertragungsausführung zu überschreiben.
Weitere Informationen dazu, wie der BigQuery Data Transfer Service Daten mit APPEND oder MIRROR aufnimmt, finden Sie unter Datenaufnahme für Cloud Storage-Übertragungen. Weitere Informationen zum Feld
writeDispositionfinden Sie unterJobConfigurationLoad.Klicken Sie das Kästchen Quelldateien nach Übertragung löschen an, wenn Sie die Quelldateien nach jeder erfolgreichen Übertragung löschen möchten. Für Löschjobs besteht keine Erfolgsgarantie. Löschjobs werden nicht noch einmal versucht, wenn der erste Versuch zum Löschen der Quelldateien fehlschlägt.
Im Abschnitt Transfer Options (Übertragungsoptionen):
- Unter All Formats (Alle Formate):
- Geben Sie unter Number of errors allowed (Anzahl zulässiger Fehler) die maximale Anzahl fehlerhafter Datensätze ein, die BigQuery beim Ausführen des Jobs ignorieren kann. Wenn die Anzahl fehlerhafter Datensätze diesen Wert überschreitet, wird im Jobergebnis
invalidzurückgegeben und der Job schlägt fehl. Der Standardwert ist0. - (Optional) Geben Sie unter Dezimalzieltypen eine durch Kommas getrennte Liste möglicher SQL-Datentypen ein, in die Quelldezimalwerte konvertiert werden können. Welcher SQL-Datentyp für die Konvertierung ausgewählt wird, hängt von folgenden Bedingungen ab:
- Der für die Konvertierung ausgewählte Datentyp ist der erste Datentyp in der folgenden Liste, der die Genauigkeit und die Skalierung der Quelldaten in dieser Reihenfolge unterstützt:
NUMERIC,BIGNUMERICundSTRING. - Wenn keiner der aufgelisteten Datentypen die Genauigkeit und Skalierung unterstützt, wird der Datentyp aus der Liste ausgewählt, der den breitesten Bereich unterstützt. Geht ein Wert beim Lesen der Quelldaten über den unterstützten Bereich hinaus, wird ein Fehler ausgegeben.
- Der Datentyp
STRINGunterstützt alle Genauigkeits- und Skalierungswerte. - Wenn dieses Feld leer bleibt, wird der Datentyp standardmäßig auf
NUMERIC,STRINGfür ORC undNUMERICfür die anderen Dateiformate gesetzt. - Dieses Feld darf keine doppelten Datentypen enthalten.
- In welcher Reihenfolge Sie die Datentypen in diesem Feld auflisten, ist nicht relevant.
- Der für die Konvertierung ausgewählte Datentyp ist der erste Datentyp in der folgenden Liste, der die Genauigkeit und die Skalierung der Quelldaten in dieser Reihenfolge unterstützt:
- Geben Sie unter Number of errors allowed (Anzahl zulässiger Fehler) die maximale Anzahl fehlerhafter Datensätze ein, die BigQuery beim Ausführen des Jobs ignorieren kann. Wenn die Anzahl fehlerhafter Datensätze diesen Wert überschreitet, wird im Jobergebnis
- Klicken Sie unter JSON, CSV das Kästchen Unbekannte Werte ignorieren an, wenn bei der Datenübertragung Daten ignoriert werden sollen, die nicht in das Schema der Zieltabelle passen.
- Klicken Sie unter AVRO das Kästchen Logische Avro-Typen verwenden an, wenn bei der Datenübertragung logische Avro-Typen in die entsprechenden BigQuery-Datentypen konvertiert werden sollen. Standardmäßig wird das Attribut
logicalTypefür die meisten Typen ignoriert und stattdessen der zugrunde liegende Avro-Typ verwendet. Unter CSV:
- Geben Sie unter Field delimiter (Feldtrennzeichen) das Zeichen ein, das die Felder trennt. Der Standardwert ist ein Komma.
- Geben Sie unter Anführungszeichen das Zeichen ein, das zum Kennzeichnen von Datenabschnitten in einer CSV-Datei verwendet wird. Der Standardwert ist ein doppeltes Anführungszeichen (
"). - Geben Sie unter Header rows to skip (Zu überspringende Kopfzeilen) die Anzahl der Kopfzeilen in den Quelldateien ein, wenn Sie diese nicht importieren möchten. Der Standardwert ist
0. - Klicken Sie das Kästchen Allow quoted newlines (Zeilenumbrüche in Abschnitten in Anführungszeichen zulassen) an, wenn Sie Zeilenumbrüche innerhalb von Feldern in Anführungszeichen zulassen möchten.
- Klicken Sie auf das Kästchen Unvollständige Zeilen zulassen, wenn Sie die Datenübertragung von Zeilen mit fehlenden
NULLABLE-Spalten erlauben möchten.
Weitere Informationen finden Sie unter CSV-Optionen.
- Unter All Formats (Alle Formate):
Wählen Sie im Menü Dienstkonto ein Dienstkonto aus den Dienstkonten aus, die mit Ihrem Google Cloud -Projekt verknüpft sind. Sie können Ihre Datenübertragung mit einem Dienstkonto verknüpfen, anstatt Ihre Nutzeranmeldedaten zu verwenden. Weitere Informationen zur Verwendung von Dienstkonten mit Datenübertragungen finden Sie unter Dienstkonten verwenden.
- Wenn Sie sich mit einer föderierten Identität angemeldet haben, ist ein Dienstkonto zum Erstellen einer Datenübertragung erforderlich. Wenn Sie sich mit einem Google-Konto angemeldet haben, ist ein Dienstkonto für die Übertragung optional.
- Das Dienstkonto muss die erforderlichen Berechtigungen für BigQuery und Cloud Storage haben.
Optional: Im Abschnitt Benachrichtigungsoptionen:
- Klicken Sie auf den Umschalter, um E-Mail-Benachrichtigungen zu aktivieren. Wenn Sie diese Option aktivieren, erhält der Inhaber der Datenübertragungskonfiguration eine E-Mail-Benachrichtigung, wenn eine Datenübertragung fehlschlägt.
- Wählen Sie unter Pub/Sub-Thema auswählen Ihr Thema aus oder klicken Sie auf Thema erstellen. Mit dieser Option werden Pub/Sub-Ausführungsbenachrichtigungen für Ihre Übertragung konfiguriert.
Optional: Wenn Sie CMEKs verwenden, wählen Sie im Abschnitt Erweiterte Optionen die Option Vom Kunden verwalteter Schlüssel aus. Es wird eine Liste Ihrer verfügbaren CMEKs angezeigt, aus denen Sie wählen können. Informationen zur Funktionsweise von CMEKs mit dem BigQuery Data Transfer Service finden Sie unter Verschlüsselungsschlüssel mit Übertragungen angeben.
Klicken Sie auf Speichern.
bq
Geben Sie den Befehl bq mk ein und geben Sie das Flag --transfer_config für die Übertragungserstellung an. Die folgenden Flags sind ebenfalls erforderlich:
--data_source--display_name--target_dataset--params
Optionale Flags:
--destination_kms_keygibt die Schlüsselressourcen-ID für den Cloud KMS-Schlüssel an, wenn Sie für diese Datenübertragung einen vom Kunden verwalteten Verschlüsselungsschlüssel (CMEK) verwenden. Informationen zur Funktionsweise von CMEKs mit dem BigQuery Data Transfer Service finden Sie unter Verschlüsselungsschlüssel mit Übertragungen angeben.--service_account_name: Gibt ein Dienstkonto an, das für die Cloud Storage-Übertragungsauthentifizierung anstelle Ihres Nutzerkontos verwendet werden soll.
bq mk \ --transfer_config \ --project_id=PROJECT_ID \ --data_source=DATA_SOURCE \ --display_name=NAME \ --target_dataset=DATASET \ --destination_kms_key="DESTINATION_KEY" \ --params='PARAMETERS' \ --service_account_name=SERVICE_ACCOUNT_NAME
Dabei gilt:
- PROJECT_ID ist die Projekt-ID. Wenn
--project_idnicht bereitgestellt wird, um ein bestimmtes Projekt anzugeben, wird das Standardprojekt verwendet. - DATA_SOURCE ist die Datenquelle, z. B.
google_cloud_storage. - NAME ist der Anzeigename für die Datenübertragungskonfiguration. Der Übertragungsname kann ein beliebiger Wert sein, mit dem Sie die Übertragung identifizieren können, wenn Sie sie später ändern müssen.
- DATASET ist das Ziel-Dataset für die Übertragungskonfiguration.
- DESTINATION_KEY: Die Cloud KMS-Schlüsselressourcen-ID, z. B.
projects/project_name/locations/us/keyRings/key_ring_name/cryptoKeys/key_name. - PARAMETERS enthält die Parameter für die erstellte Übertragungskonfiguration im JSON-Format. Beispiel:
--params='{"param":"param_value"}'.destination_table_name_template: der Name der BigQuery-Zieltabelle.data_path_template: Der Cloud Storage-URI, der die zu übertragenden Dateien enthält. Platzhalter und Parameter werden unterstützt.write_disposition: Legt fest, ob übereinstimmende Dateien an die Zieltabelle angehängt oder vollständig gespiegelt werden. Die unterstützten Werte sindAPPENDoderMIRROR. Informationen dazu, wie BigQuery Data Transfer Service Daten an Cloud Storage-Übertragungen anhängt oder spiegelt, finden Sie unter Datenaufnahme für Cloud Storage-Übertragungen.file_format: Das Format der Dateien, die Sie übertragen möchten. Das Format kannCSV,JSON,AVRO,PARQUEToderORCsein. Der Standardwert istCSV.max_bad_records: Für jedenfile_format-Wert die maximale Anzahl fehlerhafter Einträge, die ignoriert werden können. Der Standardwert ist0.decimal_target_types: Für jedenfile_format-Wert eine durch Kommas getrennte Liste möglicher SQL-Datentypen, in die die Dezimalwerte der Quelle konvertiert werden können. Wenn dieses Feld nicht angegeben ist, wird der Datentyp standardmäßig auf"NUMERIC,STRING"fürORCund für die anderen Dateiformate auf"NUMERIC"gesetzt.ignore_unknown_values: Für einen beliebigenfile_format-Wert aufTRUEsetzen, um Zeilen zu akzeptieren, die Werte enthalten, die nicht mit dem Schema übereinstimmen. Weitere Informationen finden Sie in der Referenztabelle fürJobConfigurationLoadim Abschnitt mit den Details zum FeldignoreUnknownvalues.use_avro_logical_types: FürAVROfile_format-Werte, die aufTRUEfestgelegt sind, um logische Typen in die entsprechenden Typen zu interpretieren (z. B.TIMESTAMP), anstatt nur deren Rohtypen (z. B.INTEGER) zu verwenden.parquet_enum_as_string: fürPARQUET-file_format-Werte, die aufTRUEfestgelegt sind, um den logischen TypPARQUETENUMalsSTRINGanstelle der StandardeinstellungBYTESfestzulegen.parquet_enable_list_inference: Legen Sie fürPARQUETfile_format-Werte den WertTRUEfest, um die Schemainferenz speziell für den logischen TypPARQUETLISTzu verwenden.reference_file_schema_uri: ein URI-Pfad zu einer Referenz mit dem Reader-Schema.field_delimiter: beiCSV-file_format-Werten ein Zeichen, das Felder trennt. Der Standardwert ist ein Komma.quote: fürCSV-file_format-Werte ein Zeichen, das zum Kennzeichnen von Datenabschnitten in einer CSV-Datei verwendet wird. Der Standardwert ist ein doppeltes Anführungszeichen (").skip_leading_rows: Geben Sie fürCSV-file_format-Werte die Anzahl der führenden Headerzeilen an, die Sie nicht importieren möchten. Der Standardwert ist 0.allow_quoted_newlines: Legen Sie fürCSV-file_format-Werte den WertTRUEfest, um Zeilenumbrüche in Feldern in Anführungszeichen zuzulassen.allow_jagged_rows: FürCSV-file_format-Werte, die aufTRUEfestgelegt sind, um Zeilen zu akzeptieren, bei denen optionale Spalten am Ende fehlen. Die fehlenden Werte werden mitNULLausgefüllt.preserve_ascii_control_characters: FürCSV-file_format-Werte, die aufTRUEfestgelegt sind, um eingebettete ASCII-Steuerzeichen zu erhalten.encoding: Geben Sie den CodierungstypCSVan. Unterstützte Werte sindUTF8,ISO_8859_1,UTF16BE,UTF16LE,UTF32BEundUTF32LE.delete_source_files: Legen SieTRUEfest, um die Quelldateien nach jeder erfolgreichen Übertragung zu löschen. Löschjobs werden nicht noch einmal ausgeführt, wenn der erste Versuch, die Quelldatei zu löschen, fehlschlägt. Der Standardwert istFALSE.
- SERVICE_ACCOUNT_NAME ist der Name des Dienstkontos, der zur Authentifizierung der Übertragung verwendet wird. Das Dienstkonto sollte zum selben
project_idgehören, das für die Erstellung der Übertragung verwendet wurde, und sollte alle erforderlichen Berechtigungen haben.
Mit dem folgenden Befehl wird beispielsweise eine Cloud Storage-Datenübertragung mit dem Namen My Transfer erstellt. Dabei wird ein data_path_template-Wert von gs://mybucket/myfile/*.csv, ein Ziel-Dataset mydataset und file_format CSV verwendet. Dieses Beispiel enthält nicht standardmäßige Werte für die optionalen Parameter, die dem CSV-Dateiformat zugeordnet sind.
Die Datenübertragung wird im Standardprojekt erstellt:
bq mk --transfer_config \
--target_dataset=mydataset \
--project_id=myProject \
--display_name='My Transfer' \
--destination_kms_key=projects/myproject/locations/mylocation/keyRings/myRing/cryptoKeys/myKey \
--params='{"data_path_template":"gs://mybucket/myfile/*.csv",
"destination_table_name_template":"MyTable",
"file_format":"CSV",
"max_bad_records":"1",
"ignore_unknown_values":"true",
"field_delimiter":"|",
"quote":";",
"skip_leading_rows":"1",
"allow_quoted_newlines":"true",
"allow_jagged_rows":"false",
"delete_source_files":"true"}' \
--data_source=google_cloud_storage \
--service_account_name=abcdef-test-sa@abcdef-test.iam.gserviceaccount.com projects/862514376110/locations/us/transferConfigs/ 5dd12f26-0000-262f-bc38-089e0820fe38
Nachdem Sie den Befehl ausgeführt haben, erhalten Sie eine Meldung wie die Folgende:
[URL omitted] Please copy and paste the above URL into your web browser and
follow the instructions to retrieve an authentication code.
Folgen Sie der Anleitung und fügen Sie den Authentifizierungscode in die Befehlszeile ein.
API
Verwenden Sie die Methode projects.locations.transferConfigs.create und geben Sie eine Instanz der Ressource TransferConfig an.
Java
Bevor Sie dieses Beispiel anwenden, folgen Sie den Schritten zur Einrichtung von Java in der BigQuery-Kurzanleitung zur Verwendung von Clientbibliotheken. Weitere Angaben finden Sie in der Referenzdokumentation zur BigQuery Java API.
Richten Sie zur Authentifizierung bei BigQuery die Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter Authentifizierung für Clientbibliotheken einrichten.
Verschlüsselungsschlüssel mit Übertragungen angeben
Sie können vom Kunden verwaltete Verschlüsselungsschlüssel (CMEKs) angeben, um Daten für eine Übertragungsausführung zu verschlüsseln. Sie können einen CMEK verwenden, um Übertragungen von Cloud Storage zu unterstützen.Wenn Sie einen CMEK mit einer Übertragung angeben, wendet der BigQuery Data Transfer Service den CMEK auf einen zwischengeschalteten Festplatten-Cache von aufgenommenen Daten an, sodass der gesamte Datenübertragungsworkflow CMEK-konform ist.
Sie können eine vorhandene Übertragung nicht aktualisieren, um einen CMEK hinzuzufügen, wenn die Übertragung nicht ursprünglich mit einem CMEK erstellt wurde. Sie können beispielsweise keine Zieltabelle ändern, die ursprünglich standardmäßig verschlüsselt wurde, um jetzt mit CMEK zu verschlüsseln. Umgekehrt können Sie eine CMEK-verschlüsselte Zieltabelle auch nicht auf einen anderen Verschlüsselungstyp ändern.
Sie können einen CMEK für eine Übertragung aktualisieren, wenn die Übertragungskonfiguration ursprünglich mit einer CMEK-Verschlüsselung erstellt wurde. Wenn Sie einen CMEK für eine Übertragungskonfiguration aktualisieren, leitet der BigQuery Data Transfer Service den CMEK bei der nächsten Ausführung der Übertragung an die Zieltabellen weiter, wobei der BigQuery Data Transfer Service während der Übertragungsausführung alle veralteten CMEKs durch den neuen CMEK ersetzt. Weitere Informationen finden Sie unter Übertragung aktualisieren.
Sie können auch Standardschlüssel für Projekte verwenden. Wenn Sie einen Projektstandardschlüssel für eine Übertragung angeben, verwendet der BigQuery Data Transfer Service den Standardschlüssel des Projekts als Standardschlüssel für neue Übertragungskonfigurationen.
Übertragung manuell auslösen
Zusätzlich zu den automatisch geplanten Datenübertragungen von Cloud Storage können Sie manuell eine Datenübertragung auslösen, um zusätzliche Datendateien zu laden.
Wenn die Übertragungskonfiguration laufzeitparametrisiert ist, müssen Sie einen Zeitraum angeben, für den zusätzliche Übertragungen gestartet werden.
So lösen Sie eine Datenübertragung aus:
Console
Rufen Sie in der Google Cloud Console die Seite „BigQuery“ auf.
Klicken Sie auf Datenübertragungen.
Wählen Sie die Datenübertragung aus der Liste aus.
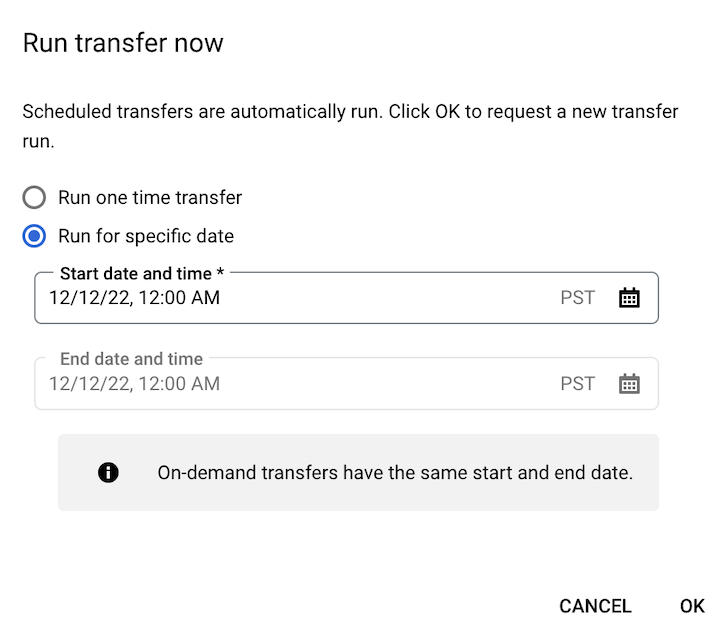
Klicken Sie auf Übertragung jetzt ausführen oder Backfill planen (für laufzeitparametrisierte Übertragungskonfigurationen).
Wenn Sie auf Übertragung jetzt ausführen geklickt haben, wählen Sie Einmalige Übertragung ausführen oder Für bestimmtes Datum ausführen aus. Wenn Sie Für ein bestimmtes Datum ausführen ausgewählt haben, wählen Sie ein bestimmtes Datum und eine bestimmte Uhrzeit aus:
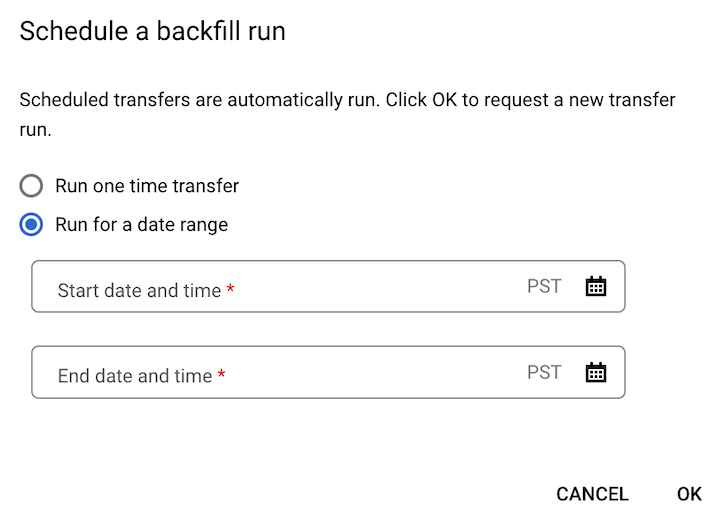
Wenn Sie auf Backfill planen geklickt haben, wählen Sie entweder Einmalige Übertragung ausführen oder Für einen Zeitraum ausführen aus. Wenn Sie Für einen Zeitraum ausführen ausgewählt haben, wählen Sie ein Start- und ein Enddatum sowie eine Uhrzeit aus:
Klicken Sie auf OK.
bq
Geben Sie den Befehl bq mk mit dem Flag --transfer_run ein. Sie können entweder das Flag --run_time oder die Flags --start_time und --end_time verwenden.
bq mk \ --transfer_run \ --start_time='START_TIME' \ --end_time='END_TIME' \ RESOURCE_NAME
bq mk \ --transfer_run \ --run_time='RUN_TIME' \ RESOURCE_NAME
Dabei gilt:
START_TIME und END_TIME sind Zeitstempel, die in
Zenden oder einen gültigen Zeitzonen-Offset enthalten. Beispiele:2017-08-19T12:11:35.00Z2017-05-25T00:00:00+00:00
RUN_TIME ist ein Zeitstempel, der den Zeitpunkt für die Datenübertragungsausführung angibt. Wenn Sie eine einmalige Übertragung für die aktuelle Zeit ausführen möchten, können Sie das Flag
--run_timeverwenden.RESOURCE_NAME ist der Ressourcenname der Übertragung (auch als Übertragungskonfiguration bezeichnet), z. B.
projects/myproject/locations/us/transferConfigs/1234a123-1234-1a23-1be9-12ab3c456de7. Wenn Sie den Ressourcennamen der Übertragung nicht kennen, führen Sie den Befehlbq ls --transfer_config --transfer_location=LOCATIONaus, um den Ressourcennamen zu ermitteln.
API
Verwenden Sie die Methode projects.locations.transferConfigs.startManualRuns und geben Sie die Übertragungskonfigurationsressource mithilfe des Parameters parent an.
Nächste Schritte
- Laufzeitparameter in Cloud Storage-Übertragungen
- Weitere Informationen zum BigQuery Data Transfer Service