Datasets erstellen
In diesem Dokument wird beschrieben, wie Sie Datasets in BigQuery erstellen.
Datasets können folgendermaßen erstellt werden:
- Google Cloud Console verwenden
- SQL-Abfrage verwenden.
- Mit dem Befehl
bq mkim bq-Befehlszeilentool. - Durch Aufruf der API-Methode
datasets.insert - Mithilfe der Clientbibliotheken
- Durch Kopieren eines vorhandenen Datasets
Unter Datasets kopieren erfahren Sie, wie Sie ein Dataset kopieren, auch regionenübergreifend.
In diesem Dokument wird beschrieben, wie Sie mit regulären Datasets arbeiten, in denen Daten in BigQuery gespeichert werden. Informationen zum Arbeiten mit externen Spanner-Datasets finden Sie unter Externe Spanner-Datasets erstellen. Informationen zum Arbeiten mit föderierten AWS Glue-Datasets finden Sie unter Föderierte AWS Glue-Datasets erstellen.
Informationen zum Abfragen von Tabellen in einem öffentlichen Dataset finden Sie unter Öffentliches Dataset mit der Google Cloud Console abfragen.
Dataset-Einschränkungen
BigQuery-Datasets unterliegen den folgenden Einschränkungen:
- Der Dataset-Speicherort kann nur zum Zeitpunkt der Erstellung festgelegt werden. Nachdem ein Dataset erstellt wurde, kann sein Standort nicht mehr geändert werden.
- Alle in einer Abfrage referenzierten Tabellen müssen in Datasets an demselben Standort gespeichert werden.
Externe Datasets unterstützen keine Tabellenablaufzeiten, Replikate, Zeitreisen, Standardsortierung, Standardrundungsmodus oder die Option, bei Tabellennamen die Groß-/Kleinschreibung zu berücksichtigen.
Wenn Sie eine Tabelle kopieren, müssen sich die Datasets mit der Quell- und Zieltabelle am selben Speicherort befinden.
Datasetnamen müssen für jedes Projekt eindeutig sein.
Wenn Sie das Speicherabrechnungsmodell eines Datasets geändert haben, müssen Sie 14 Tage warten, bevor Sie das Speicherabrechnungsmodell wieder ändern können.
Sie können ein Dataset nicht für die physische Speicherabrechnung registrieren, wenn sich Legacy-Slot-Zusicherungen zum Pauschalpreis in derselben Region wie das Dataset befinden.
Hinweise
Weisen Sie IAM-Rollen (Identity and Access Management) zu, die Nutzern die erforderlichen Berechtigungen zum Ausführen der einzelnen Aufgaben in diesem Dokument gewähren.
Erforderliche Berechtigungen
Sie benötigen die IAM-Berechtigung bigquery.datasets.create, um ein Dataset zu erstellen.
Jede der folgenden vordefinierten IAM-Rollen enthält die Berechtigungen, die Sie zum Erstellen eines Datasets benötigen:
roles/bigquery.dataEditorroles/bigquery.dataOwnerroles/bigquery.userroles/bigquery.admin
Weitere Informationen zu IAM-Rollen in BigQuery finden Sie unter Vordefinierte Rollen und Berechtigungen.
Datasets erstellen
So erstellen Sie ein Dataset:
Console
- Öffnen Sie in der Google Cloud Console die Seite „BigQuery“. Zur Seite „BigQuery“
- Klicken Sie im linken Bereich auf Explorer.
- Wählen Sie das Projekt aus, in dem Sie das Dataset erstellen möchten.
- Klicken Sie auf Aktionen ansehen und dann auf Dataset erstellen.
- Führen Sie auf der Seite Dataset erstellen die folgenden Schritte aus:
- Geben Sie für die Dataset-ID einen eindeutigen Dataset-Namen ein.
- Wählen Sie unter Standorttyp einen geografischen Standort für das Dataset aus. Nachdem ein Dataset erstellt wurde, kann der Standort nicht mehr geändert werden.
- Optional: Wählen Sie Link zu einem externen Dataset aus, wenn Sie ein externes Dataset erstellen.
- Wenn Sie keine zusätzlichen Optionen wie Tags und Tabellenablauf konfigurieren müssen, klicken Sie auf Dataset erstellen. Andernfalls maximieren Sie den folgenden Abschnitt, um die zusätzlichen Dataset-Optionen zu konfigurieren.
- Optional: Maximieren Sie den Bereich Tags, um Ihrem Dataset Tags hinzuzufügen.
- So wenden Sie ein vorhandenes Tag an:
- Klicken Sie auf den Drop-down-Pfeil neben Bereich auswählen und wählen Sie Aktueller Bereich – Aktuelle Organisation auswählen oder Aktuelles Projekt auswählen aus.
- Wählen Sie für Schlüssel 1 und Wert 1 die entsprechenden Werte aus den Listen aus.
- So geben Sie ein neues Tag manuell ein:
- Klicken Sie neben Bereich auswählen auf den Drop-down-Pfeil und wählen Sie IDs manuell eingeben > Organisation, Projekt oder Tags aus.
- Wenn Sie ein Tag für Ihr Projekt oder Ihre Organisation erstellen, geben Sie im Dialogfeld die
PROJECT_IDoder dieORGANIZATION_IDein und klicken Sie auf Speichern. - Wählen Sie für Schlüssel 1 und Wert 1 die entsprechenden Werte aus den Listen aus.
- Wenn Sie der Tabelle weitere Tags hinzufügen möchten, klicken Sie auf Tag hinzufügen und folgen Sie der Anleitung oben.
- Optional: Maximieren Sie den Abschnitt Erweiterte Optionen, um eine oder mehrere der folgenden Optionen zu konfigurieren.
- Wenn Sie die Option Verschlüsselung ändern möchten, um Ihren eigenen kryptografischen Schlüssel mit dem Cloud Key Management Service zu verwenden, wählen Sie Cloud KMS-Schlüssel aus.
- Wenn Sie Tabellennamen verwenden möchten, bei denen die Groß-/Kleinschreibung nicht berücksichtigt wird, wählen Sie Tabellennamen aktivieren, bei denen die Groß-/Kleinschreibung nicht berücksichtigt wird aus.
- Wenn Sie die Standardsortierung ändern möchten, wählen Sie den Sortierungstyp in der Liste aus.
- Wenn Sie ein Ablaufdatum für Tabellen im Dataset festlegen möchten, wählen Sie Tabellenablauf aktivieren aus und geben Sie dann das standardmäßige Höchstalter für Tabellen in Tagen an.
- Wenn Sie einen Standardrundungsmodus festlegen möchten, wählen Sie den gewünschten Modus in der Liste aus.
- Wenn Sie das Abrechnungsmodell für physischen Speicher aktivieren möchten, wählen Sie das Abrechnungsmodell aus der Liste aus.
- Wenn Sie das Zeitreisefenster für das Dataset festlegen möchten, wählen Sie die Fenstergröße aus der Liste aus.
- Klicken Sie auf Dataset erstellen.
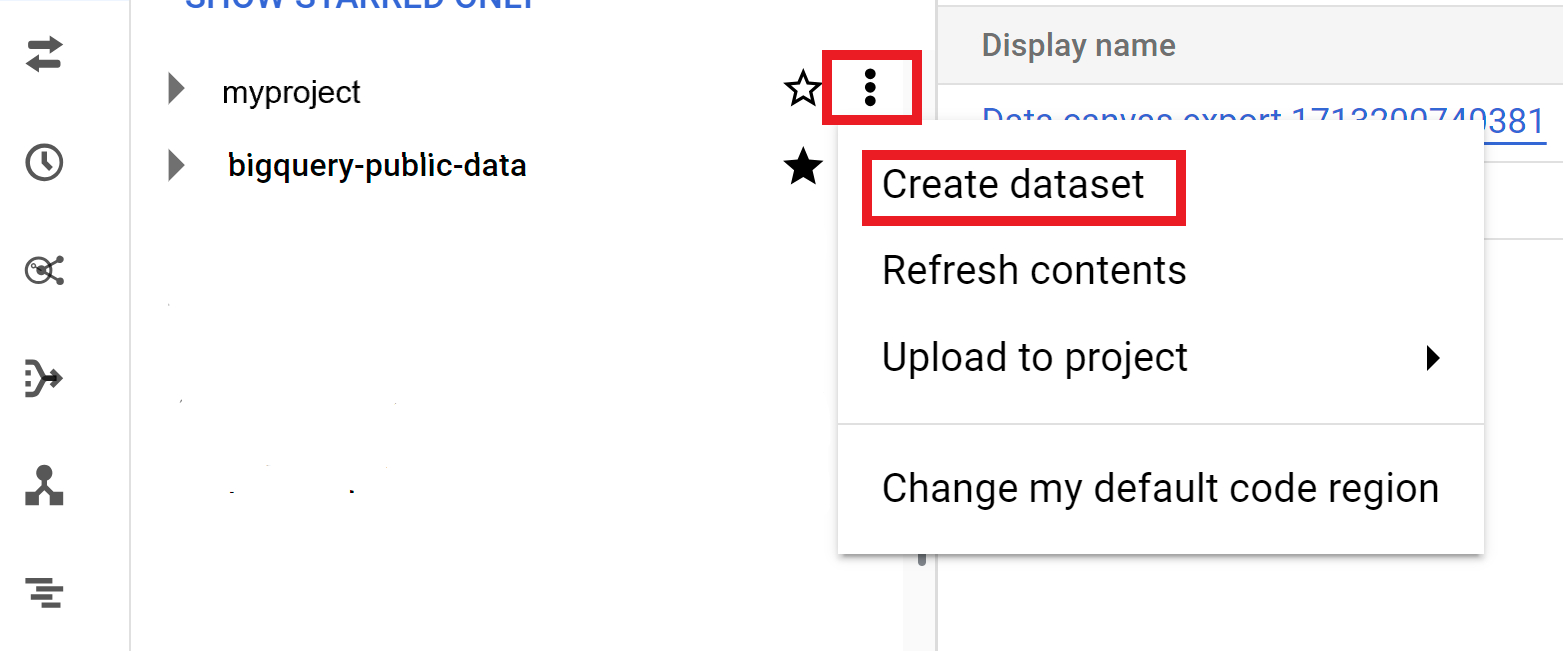
Zusätzliche Optionen für Datasets
Alternativ können Sie auf Bereich auswählen klicken, um nach einer Ressource zu suchen oder eine Liste der aktuellen Ressourcen aufzurufen.
Wenn Sie das Abrechnungsmodell eines Datasets ändern, dauert es 24 Stunden, bis die Änderung wirksam wird.
Nachdem Sie das Speicherabrechnungsmodell eines Datasets geändert haben, müssen Sie 14 Tage warten, bevor Sie das Speicherabrechnungsmodell wieder ändern können.
SQL
Verwenden Sie die Anweisung CREATE SCHEMA.
Wenn Sie ein Dataset in einem anderen Projekt als dem Standardprojekt erstellen möchten, fügen Sie die Projekt-ID im Format PROJECT_ID.DATASET_ID der Dataset-ID hinzu.
Öffnen Sie in der Google Cloud Console die Seite BigQuery.
Geben Sie im Abfrageeditor die folgende Anweisung ein:
CREATE SCHEMA PROJECT_ID.DATASET_ID OPTIONS ( default_kms_key_name = 'KMS_KEY_NAME', default_partition_expiration_days = PARTITION_EXPIRATION, default_table_expiration_days = TABLE_EXPIRATION, description = 'DESCRIPTION', labels = [('KEY_1','VALUE_1'),('KEY_2','VALUE_2')], location = 'LOCATION', max_time_travel_hours = HOURS, storage_billing_model = BILLING_MODEL);
Dabei gilt:
PROJECT_ID: Ihre Projekt-IDDATASET_ID: der Name des zu erstellenden Datasets.KMS_KEY_NAME: der Name des standardmäßigen Cloud Key Management Service-Schlüssels, der zum Schutz neu erstellter Tabellen in diesem Dataset verwendet wird, sofern beim Erstellen kein anderer Schlüssel angegeben wird. Wenn dieser Parameter gesetzt ist, können Sie in einem Dataset keine von Google verschlüsselte Tabelle erstellen.PARTITION_EXPIRATION: die Standardlebensdauer (in Tagen) für Partitionen in neu erstellten partitionierten Tabellen. Für den Standardpartitionsablauf gibt es keinen Mindestwert. Die Ablaufzeit entspricht dem Datum der Partition plus dem ganzzahligen Wert. Jede Partition, die in einer partitionierten Tabelle im Dataset erstellt wurde, wirdPARTITION_EXPIRATIONTage nach dem Datum der Partition gelöscht. Wenn Sie beim Erstellen oder Aktualisieren einer partitionierten Tabelle die Optiontime_partitioning_expirationangeben, hat der Partitionsablauf auf Tabellenebene Vorrang vor dem Standardpartitionsablauf auf Dataset-Ebene.TABLE_EXPIRATION: die Standardlebensdauer (in Tagen) für neu erstellte Tabellen. Der Mindestwert beträgt 0,042 Tage (eine Stunde). Die Ablaufzeit entspricht der aktuellen Zeit plus dem ganzzahligen Wert. Jede im Dataset erstellte Tabelle wirdTABLE_EXPIRATIONTage nach dem Erstellen gelöscht. Der Wert wird angewendet, wenn Sie beim Erstellen der Tabelle keine Ablaufzeit für die Tabelle festlegen.DESCRIPTION: eine Beschreibung des DatasetsKEY_1:VALUE_1: das Schlüssel/Wert-Paar, das Sie als erstes Label für dieses Dataset festlegen möchtenKEY_2:VALUE_2: das Schlüssel/Wert-Paar, das Sie als zweites Label festlegen möchtenLOCATION: Speicherort des Datasets. Nachdem ein Dataset erstellt wurde, kann der Standort nicht mehr geändert werden.HOURS: die Dauer des Zeitreisefensters für das neue Dataset in Stunden. Der WertHOURSmuss eine Ganzzahl sein, die als Vielfaches von 24 (48, 72, 96, 120, 144, 168) zwischen 48 (2 Tagen) und 168 (7 Tage) ausgedrückt wird. Wenn diese Option nicht angegeben ist, wird als Standardeinstellung 168 Stunden verwendet.BILLING_MODEL: legt das Speicherabrechnungsmodell für das Dataset fest. Legen Sie den WertBILLING_MODELaufPHYSICALfest, um physische Bytes bei der Berechnung der Speichergebühren zu verwenden, oder aufLOGICAL, um logische Byte zu verwenden. Standardmäßig istLOGICALausgewählt.Wenn Sie das Abrechnungsmodell eines Datasets ändern, dauert es 24 Stunden, bis die Änderung wirksam wird.
Nachdem Sie das Speicherabrechnungsmodell eines Datasets geändert haben, müssen Sie 14 Tage warten, bevor Sie das Speicherabrechnungsmodell wieder ändern können.
Klicken Sie auf Ausführen.
Informationen zum Ausführen von Abfragen finden Sie unter Interaktive Abfrage ausführen.
bq
Wenn Sie ein neues Dataset erstellen möchten, verwenden Sie den Befehl bq mk mit dem Flag --location. Eine vollständige Liste der möglichen Parameter finden Sie in der bq mk --dataset-Befehlsreferenz.
Wenn Sie ein Dataset in einem anderen Projekt als dem Standardprojekt erstellen möchten, fügen Sie die Projekt-ID im Format PROJECT_ID:DATASET_ID dem Dataset-Namen hinzu.
bq --location=LOCATION mk \ --dataset \ --default_kms_key=KMS_KEY_NAME \ --default_partition_expiration=PARTITION_EXPIRATION \ --default_table_expiration=TABLE_EXPIRATION \ --description="DESCRIPTION" \ --label=KEY_1:VALUE_1 \ --label=KEY_2:VALUE_2 \ --add_tags=KEY_3:VALUE_3[,...] \ --max_time_travel_hours=HOURS \ --storage_billing_model=BILLING_MODEL \ PROJECT_ID:DATASET_ID
Dabei gilt:
LOCATION: Speicherort des Datasets. Nachdem ein Dataset erstellt wurde, kann der Standort nicht mehr geändert werden. Mit der Datei.bigqueryrckönnen Sie für den Standort einen Standardwert festlegen.KMS_KEY_NAME: der Name des standardmäßigen Cloud Key Management Service-Schlüssels, der zum Schutz neu erstellter Tabellen in diesem Dataset verwendet wird, sofern beim Erstellen kein anderer Schlüssel angegeben wird. Wenn dieser Parameter gesetzt ist, können Sie in einem Dataset keine von Google verschlüsselte Tabelle erstellen.PARTITION_EXPIRATION: die Standardlebensdauer von Partitionen in neu erstellten partitionierten Tabellen in Sekunden. Für den Standardpartitionsablauf gibt es keinen Mindestwert. Die Ablaufzeit entspricht dem Datum der Partition plus dem ganzzahligen Wert. Jede Partition, die in einer partitionierten Tabelle im Dataset erstellt wurde, wirdPARTITION_EXPIRATIONSekunden nach dem Datum der Partition gelöscht. Wenn Sie beim Erstellen oder Aktualisieren einer partitionierten Tabelle das Flag--time_partitioning_expirationangeben, hat der Ablauf der Partition auf Tabellenebene Vorrang vor dem Standardablauf der Partition auf Dataset-Ebene.TABLE_EXPIRATION: die Standardlebensdauer neu erstellter Tabellen in Sekunden. Der Mindestwert beträgt 3.600 Sekunden bzw. eine Stunde. Die Ablaufzeit entspricht der aktuellen Zeit plus dem ganzzahligen Wert. Jede im Dataset erstellte Tabelle wirdTABLE_EXPIRATIONSekunden nach dem Erstellen gelöscht. Der Wert wird angewendet, wenn Sie beim Erstellen der Tabelle keine Ablaufzeit für die Tabelle festlegen.DESCRIPTION: eine Beschreibung des DatasetsKEY_1:VALUE_1: das Schlüssel/Wert-Paar, das Sie als erstes Label für dieses Dataset festlegen möchten;KEY_2:VALUE_2ist das Schlüssel/Wert-Paar, das Sie als zweites Label festlegen möchten.KEY_3:VALUE_3: das Schlüssel/Wert-Paar, das Sie als Tag für das Dataset festlegen möchten. Fügen Sie unter demselben Flag mehrere Tags hinzu, indem Sie die Schlüssel/Wert-Paare durch Kommas trennen.HOURS: die Dauer des Zeitreisefensters für das neue Dataset in Stunden. Der WertHOURSmuss eine Ganzzahl sein, die als Vielfaches von 24 (48, 72, 96, 120, 144, 168) zwischen 48 (2 Tagen) und 168 (7 Tage) ausgedrückt wird. Wenn diese Option nicht angegeben ist, wird als Standardeinstellung 168 Stunden verwendet.BILLING_MODEL: legt das Speicherabrechnungsmodell für das Dataset fest. Legen Sie den WertBILLING_MODELaufPHYSICALfest, um physische Bytes bei der Berechnung der Speichergebühren zu verwenden, oder aufLOGICAL, um logische Byte zu verwenden. Standardmäßig istLOGICALausgewählt.Wenn Sie das Abrechnungsmodell eines Datasets ändern, dauert es 24 Stunden, bis die Änderung wirksam wird.
Nachdem Sie das Speicherabrechnungsmodell eines Datasets geändert haben, müssen Sie 14 Tage warten, bevor Sie das Speicherabrechnungsmodell wieder ändern können.
PROJECT_IDist Ihre Projekt-ID.DATASET_ID: der Name des zu erstellenden Datasets.
Mit dem folgenden Befehl wird beispielsweise ein Dataset namens mydataset mit dem Standort US für die Daten, einem Standardtabellenablauf von 3.600 Sekunden (1 Stunde) und der Beschreibung This is my dataset erstellt. Anstelle des Flags --dataset verwendet der Befehl die verkürzte Form -d. Wenn Sie -d und --dataset auslassen, wird standardmäßig ein Dataset erstellt.
bq --location=US mk -d \ --default_table_expiration 3600 \ --description "This is my dataset." \ mydataset
Mit dem Befehl bq ls können Sie prüfen, ob das Dataset erstellt wurde. Sie können auch eine Tabelle erstellen, wenn Sie ein neues Dataset mit dem Format bq mk -t dataset.table erstellen.
Weitere Informationen zum Erstellen von Tabellen finden Sie unter Tabelle erstellen.
Terraform
Verwenden Sie die Ressource google_bigquery_dataset:
Richten Sie zur Authentifizierung bei BigQuery die Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter Authentifizierung für Clientbibliotheken einrichten.
Dataset erstellen
Im folgenden Beispiel wird ein Dataset mit dem Namen mydataset erstellt:
Wenn Sie ein Dataset mit der Ressource google_bigquery_dataset erstellen, wird automatisch allen Konten, die zu einfachen Rollen auf Projektebene gehören, Zugriff auf das Dataset gewährt.
Wenn Sie nach dem Erstellen des Datasets den Befehl terraform show ausführen, sieht der access-Block für das Dataset etwa so aus:
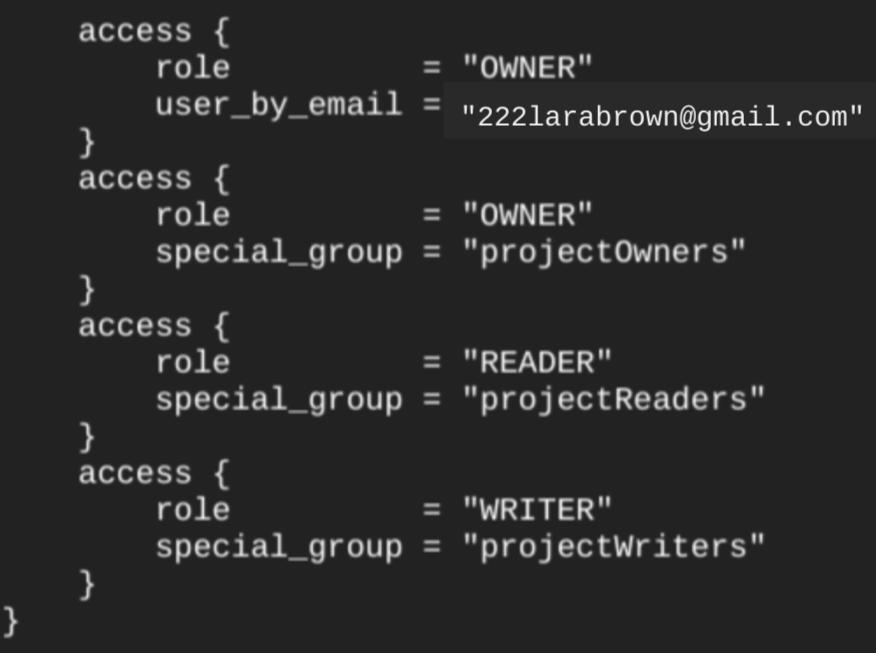
Wenn Sie Zugriff auf das Dataset gewähren möchten, empfehlen wir die Verwendung einer google_bigquery_iam-Ressource, wie im folgenden Beispiel gezeigt, sofern Sie keine autorisierten Objekte erstellen möchten, z. B. als autorisierte Ansichten innerhalb des Datasets.
Nutzen Sie in diesem Fall die Ressource google_bigquery_dataset_access. Beispiele finden Sie in dieser Dokumentation.
Dataset erstellen und Zugriff darauf gewähren
Im folgenden Beispiel wird ein Dataset mit dem Namen mydataset erstellt und dann mit der Ressource google_bigquery_dataset_iam_policy Zugriff darauf gewährt.
Dataset mit einem vom Kunden verwalteten Verschlüsselungsschlüssel erstellen
Im folgenden Beispiel wird ein Dataset mit dem Namen mydataset erstellt. Außerdem werden die google_kms_crypto_key und google_kms_key_ring verwendet, um einen Cloud Key Management Service-Schlüssel für das Dataset anzugeben. Sie müssen die Cloud Key Management Service API aktivieren, bevor Sie dieses Beispiel ausführen.
Führen Sie die Schritte in den folgenden Abschnitten aus, um Ihre Terraform-Konfiguration auf ein Google Cloud -Projekt anzuwenden.
Cloud Shell vorbereiten
- Rufen Sie Cloud Shell auf.
-
Legen Sie das Standardprojekt Google Cloud fest, auf das Sie Ihre Terraform-Konfigurationen anwenden möchten.
Sie müssen diesen Befehl nur einmal pro Projekt und in jedem beliebigen Verzeichnis ausführen.
export GOOGLE_CLOUD_PROJECT=PROJECT_ID
Umgebungsvariablen werden überschrieben, wenn Sie in der Terraform-Konfigurationsdatei explizite Werte festlegen.
Verzeichnis vorbereiten
Jede Terraform-Konfigurationsdatei muss ein eigenes Verzeichnis haben (auch als Stammmodul bezeichnet).
-
Erstellen Sie in Cloud Shell ein Verzeichnis und eine neue Datei in diesem Verzeichnis. Der Dateiname muss die Erweiterung
.tfhaben, z. B.main.tf. In dieser Anleitung wird die Datei alsmain.tfbezeichnet.mkdir DIRECTORY && cd DIRECTORY && touch main.tf
-
Wenn Sie einer Anleitung folgen, können Sie den Beispielcode in jedem Abschnitt oder Schritt kopieren.
Kopieren Sie den Beispielcode in das neu erstellte
main.tf.Kopieren Sie optional den Code aus GitHub. Dies wird empfohlen, wenn das Terraform-Snippet Teil einer End-to-End-Lösung ist.
- Prüfen und ändern Sie die Beispielparameter, die auf Ihre Umgebung angewendet werden sollen.
- Speichern Sie die Änderungen.
-
Initialisieren Sie Terraform. Dies ist nur einmal für jedes Verzeichnis erforderlich.
terraform init
Fügen Sie optional die Option
-upgradeein, um die neueste Google-Anbieterversion zu verwenden:terraform init -upgrade
Änderungen anwenden
-
Prüfen Sie die Konfiguration und prüfen Sie, ob die Ressourcen, die Terraform erstellen oder aktualisieren wird, Ihren Erwartungen entsprechen:
terraform plan
Korrigieren Sie die Konfiguration nach Bedarf.
-
Wenden Sie die Terraform-Konfiguration an. Führen Sie dazu den folgenden Befehl aus und geben Sie
yesan der Eingabeaufforderung ein:terraform apply
Warten Sie, bis Terraform die Meldung „Apply complete“ anzeigt.
- Öffnen Sie Ihr Google Cloud Projekt, um die Ergebnisse aufzurufen. Rufen Sie in der Google Cloud Console Ihre Ressourcen in der Benutzeroberfläche auf, um sicherzustellen, dass Terraform sie erstellt oder aktualisiert hat.
API
Rufen Sie die Methode datasets.insert mit einer definierten Dataset-Ressource auf.
C#
Bevor Sie dieses Beispiel ausprobieren, folgen Sie der C#-Einrichtungsanleitung in der BigQuery-Kurzanleitung zur Verwendung von Clientbibliotheken. Weitere Angaben finden Sie in der Referenzdokumentation zur BigQuery C# API.
Richten Sie zur Authentifizierung bei BigQuery die Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter Authentifizierung für Clientbibliotheken einrichten.
Go
Bevor Sie dieses Beispiel anwenden, folgen Sie den Schritten zur Einrichtung von Go in der BigQuery-Kurzanleitung zur Verwendung von Clientbibliotheken. Weitere Angaben finden Sie in der Referenzdokumentation zur BigQuery Go API.
Richten Sie zur Authentifizierung bei BigQuery die Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter Authentifizierung für Clientbibliotheken einrichten.
Java
Bevor Sie dieses Beispiel anwenden, folgen Sie den Schritten zur Einrichtung von Java in der BigQuery-Kurzanleitung zur Verwendung von Clientbibliotheken. Weitere Angaben finden Sie in der Referenzdokumentation zur BigQuery Java API.
Richten Sie zur Authentifizierung bei BigQuery die Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter Authentifizierung für Clientbibliotheken einrichten.
Node.js
Bevor Sie dieses Beispiel anwenden, folgen Sie den Schritten zur Einrichtung von Node.js in der BigQuery-Kurzanleitung zur Verwendung von Clientbibliotheken. Weitere Angaben finden Sie in der Referenzdokumentation zur BigQuery Node.js API.
Richten Sie zur Authentifizierung bei BigQuery die Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter Authentifizierung für Clientbibliotheken einrichten.
PHP
Bevor Sie dieses Beispiel anwenden, folgen Sie den Schritten zur Einrichtung von PHP in der BigQuery-Kurzanleitung zur Verwendung von Clientbibliotheken. Weitere Angaben finden Sie in der Referenzdokumentation zur BigQuery PHP API.
Richten Sie zur Authentifizierung bei BigQuery die Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter Authentifizierung für Clientbibliotheken einrichten.
Python
Bevor Sie dieses Beispiel anwenden, folgen Sie den Schritten zur Einrichtung von Python in der BigQuery-Kurzanleitung zur Verwendung von Clientbibliotheken. Weitere Angaben finden Sie in der Referenzdokumentation zur BigQuery Python API.
Richten Sie zur Authentifizierung bei BigQuery die Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter Authentifizierung für Clientbibliotheken einrichten.
Ruby
Bevor Sie dieses Beispiel anwenden, folgen Sie den Schritten zur Einrichtung von Ruby in der BigQuery-Kurzanleitung zur Verwendung von Clientbibliotheken. Weitere Angaben finden Sie in der Referenzdokumentation zur BigQuery Ruby API.
Richten Sie zur Authentifizierung bei BigQuery die Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter Authentifizierung für Clientbibliotheken einrichten.
Datasets benennen
Wenn Sie ein Dataset in BigQuery erstellen, darf dessen Name innerhalb eines Projekts nur einmal vorhanden sein. Der Name des Datasets kann Folgendes enthalten:
- Bis zu 1.024 Zeichen
- Buchstaben (Groß- oder Kleinbuchstaben), Ziffern und Unterstriche.
Bei Dataset-Namen wird standardmäßig die Groß-/Kleinschreibung beachtet. mydataset und MyDataset können im selben Projekt gleichzeitig vorhanden sein, es sei denn, bei einem davon ist die Berücksichtigung der Groß-/Kleinschreibung deaktiviert. Beispiele finden Sie unter Dataset ohne Berücksichtigung der Groß-/Kleinschreibung erstellen und Ressource: Dataset.
Dataset-Namen dürfen keine Leerzeichen oder Sonderzeichen wie -, &, @ oder % enthalten.
Ausgeblendete Datasets
Ein ausgeblendetes Dataset ist ein Dataset, dessen Name mit einem Unterstrich beginnt. Sie können Tabellen und Ansichten in ausgeblendeten Datasets genauso wie in jedem anderen Dataset abfragen. Für ausgeblendete Datasets gelten folgende Einschränkungen:
- Sie werden im Bereich Explorer in der Google Cloud Console ausgeblendet.
- Sie werden nicht in
INFORMATION_SCHEMA-Ansichten angezeigt. - Sie können nicht mit verknüpften Datasets verwendet werden.
- Sie können nicht als Quell-Dataset mit den folgenden autorisierten Ressourcen verwendet werden:
- Sie werden nicht in Data Catalog (eingestellt) oder Dataplex Universal Catalog angezeigt.
Dataset-Sicherheit
Informationen zum Steuern des Zugriffs auf Datasets in BigQuery finden Sie unter Zugriff auf Datasets steuern. Informationen zur Datenverschlüsselung finden Sie unter Verschlüsselung inaktiver Daten.
Nächste Schritte
- Weitere Informationen zum Auflisten von Datasets in einem Projekt finden Sie unter Datasets auflisten.
- Weitere Informationen zu Dataset-Metadaten finden Sie unter Informationen zu Datasets abrufen.
- Weitere Informationen zum Ändern von Dataset-Attributen finden Sie unter Datasets aktualisieren.
- Weitere Informationen zum Erstellen und Verwalten von Labels finden Sie unter Labels erstellen und verwalten.
Jetzt testen
Wenn Sie mit Google Cloud noch nicht vertraut sind, erstellen Sie einfach ein Konto, um die Leistungsfähigkeit von BigQuery in der Praxis sehen und bewerten zu können. Neukunden erhalten außerdem ein Guthaben von 300 $, um Arbeitslasten auszuführen, zu testen und bereitzustellen.
BigQuery kostenlos testen