Introduzione ai trasferimenti di Blob Storage
BigQuery Data Transfer Service per Azure Blob Storage consente di pianificare e gestire automaticamente i job di caricamento ricorrenti da Azure Blob Storage e Azure Data Lake Storage Gen2 in BigQuery.
Formati di file supportati
BigQuery Data Transfer Service attualmente supporta il caricamento di dati da Blob Storage nei seguenti formati:
- Valori separati da virgola (CSV)
- JSON (delimitato da nuova riga)
- Avro
- Parquet
- ORC
Tipi di compressione supportati
BigQuery Data Transfer Service per Blob Storage supporta il caricamento di dati compressi. I tipi di compressione supportati da BigQuery Data Transfer Service sono gli stessi supportati dai job di caricamento BigQuery. Per ulteriori informazioni, consulta Caricare dati compressi e non compressi.
Prerequisiti per il trasferimento
Per caricare i dati da un'origine dati Archiviazione blob, innanzitutto raccogli quanto segue:
- Il nome dell'account Blob Storage, il nome del contenitore e il percorso dei dati (facoltativo) per i dati di origine. Il campo Percorso dati è facoltativo e viene utilizzato per associare prefissi di oggetti ed estensioni di file comuni. Se il percorso dei dati viene omesso, tutti i file nel contenitore vengono trasferiti.
- Un token SAS (firma di accesso condiviso) di Azure che concede l'accesso in lettura all'origine dati. Per informazioni dettagliate sulla creazione di un token SAS, consulta Firma di accesso condiviso (SAS).
Parametrizzazione del runtime del trasferimento
Sia il percorso dei dati di Archiviazione blob sia la tabella di destinazione possono essere parametrizzati, consentendo di caricare i dati dai contenitori organizzati per data. I parametri utilizzati dai trasferimenti di Archiviazione BLOB sono gli stessi utilizzati dai trasferimenti di Cloud Storage. Per maggiori dettagli, consulta Parametri di runtime nei trasferimenti.
Importazione dei dati per i trasferimenti Azure Blob
Puoi specificare la modalità di caricamento dei dati in BigQuery selezionando una preferenza di scrittura nella configurazione del trasferimento quando configuri un trasferimento di Azure Blob.
Sono disponibili due tipi di preferenze di scrittura: trasferimenti incrementali e trasferimenti troncati.Trasferimenti incrementali
Una configurazione di trasferimento con una preferenza di scrittura APPEND o WRITE_APPEND, chiamata anche trasferimento incrementale, aggiunge in modo incrementale i nuovi dati dal trasferimento riuscito precedente a una tabella di destinazione BigQuery. Quando una configurazione di trasferimento viene eseguita con una preferenza di scrittura APPEND,
BigQuery Data Transfer Service filtra i file che sono stati modificati dall'ultima esecuzione di trasferimento riuscita. Per determinare quando un file viene modificato,
BigQuery Data Transfer Service esamina i metadati del file per una proprietà "data di ultima modifica". Ad esempio, BigQuery Data Transfer Service esamina la proprietà timestamp updated in un file Cloud Storage. Se
BigQuery Data Transfer Service trova file con una "data di ultima modifica" che si sono
verificati dopo il timestamp dell'ultimo trasferimento riuscito, BigQuery Data Transfer Service trasferisce questi file in un trasferimento incrementale.
Per dimostrare come funzionano i trasferimenti incrementali, considera il seguente
esempio di trasferimento di Cloud Storage. Un utente crea un file in un bucket Cloud Storage alle ore 01-07-2023T00:00Z denominato file_1. Il
timestamp updated per file_1 è
l'ora in cui è stato creato il file. L'utente quindi
crea un trasferimento incrementale dal bucket Cloud Storage,
programmato per essere eseguito una volta al giorno alle ore 03:00Z, a partire dal giorno 01-07-2023T03:00Z.
- Il 1° luglio 2023 alle ore 03:00Z inizia la prima esecuzione del trasferimento. Poiché si tratta della prima esecuzione del trasferimento per questa configurazione, BigQuery Data Transfer Service tenta di caricare tutti i file corrispondenti all'URI di origine nella tabella BigQuery di destinazione. L'esecuzione del trasferimento va a buon fine e
BigQuery Data Transfer Service carica correttamente
file_1nella tabella BigQuery di destinazione. - L'esecuzione di trasferimento successiva, il 02-07-2023T03:00Z, non rileva file in cui la proprietà del timestamp
updatedè maggiore rispetto all'ultima esecuzione di trasferimento riuscita (01-07-2023T03:00Z). L'esecuzione del trasferimento avviene correttamente senza caricare dati aggiuntivi nella tabella BigQuery di destinazione.
L'esempio precedente mostra in che modo BigQuery Data Transfer Service esamina la proprietà del timestamp updated del file di origine per determinare se sono state apportate modifiche ai file di origine e per trasferirle, se rilevate.
Seguendo lo stesso esempio, supponiamo che l'utente crei quindi un altro file nel bucket Cloud Storage alle ore 2023-07-03T00:00Z, denominato file_2. Il
timestamp updated per file_2 è
l'ora in cui è stato creato il file.
- L'esecuzione di trasferimento successiva, il 03-07-2023 alle ore 03:00:00 UTC, rileva che
file_2ha unupdatedtimestamp maggiore dell'ultima esecuzione di trasferimento riuscita (01-07-2023 alle ore 03:00:00 UTC). Supponiamo che all'avvio l'esecuzione del trasferimento non vada a buon fine a causa di un errore temporaneo. In questo scenario,file_2non viene caricato nella tabella BigQuery di destinazione. Il timestamp dell'ultima esecuzione di trasferimento riuscita rimane 01-07-2023T03:00Z. - L'esecuzione di trasferimento successiva, il 04-07-2023T03:00Z, rileva che
file_2ha unupdatedtimestamp maggiore dell'ultima esecuzione di trasferimento riuscita (01-07-2023T03:00Z). Questa volta l'esecuzione del trasferimento viene completata senza problemi, quindi caricafile_2nella tabella BigQuery di destinazione. - La successiva esecuzione del trasferimento, il 05-07-2023 alle 03:00 UTC, non rileva file in cui il timestamp
updatedè maggiore dell'ultima esecuzione del trasferimento riuscita (04-07-2023 alle 03:00 UTC). L'esecuzione del trasferimento va a buon fine senza caricare dati aggiuntivi nella tabella BigQuery di destinazione.
L'esempio precedente mostra che quando un trasferimento non va a buon fine, nessun file viene trasferito alla tabella di destinazione BigQuery. Eventuali modifiche ai file vengono trasferite alla successiva esecuzione del trasferimento riuscita. Eventuali trasferimenti riusciti successivi a un trasferimento non riuscito non causano dati duplicati. In caso di trasferimento non riuscito, puoi anche scegliere di attivare manualmente un trasferimento al di fuori dell'orario programmato regolarmente.
Trasferimenti troncati
Una configurazione di trasferimento con una preferenza di scrittura MIRROR o WRITE_TRUNCATE, chiamata anche trasferimento troncato, sovrascrive i dati nella tabella di destinazione BigQuery durante ogni esecuzione del trasferimento con i dati di tutti i file corrispondenti all'URI di origine. MIRROR sovrascrive una copia aggiornata dei
dati nella tabella di destinazione. Se la tabella di destinazione utilizza un decoratore di partizione, l'esecuzione del trasferimento sovrascrive solo i dati nella partizione specificata. Una tabella di destinazione con un decoratore di partizione ha il formato my_table${run_date}, ad esempio my_table$20230809.
La ripetizione degli stessi trasferimenti incrementali o troncati in un giorno non causa dati duplicati. Tuttavia, se esegui più configurazioni di trasferimento diverse che interessano la stessa tabella di destinazione BigQuery, BigQuery Data Transfer Service potrebbe duplicare i dati.
Supporto dei caratteri jolly per il percorso dei dati di Blob Storage
Puoi selezionare i dati di origine separati in più file specificando uno o più caratteri jolly asterisco (*) nel percorso dei dati.
Sebbene nel percorso dei dati sia possibile utilizzare più di un carattere jolly, è possibile un'ottimizzazione se viene utilizzato un solo carattere jolly:
- Esiste un limite più elevato per il numero massimo di file per esecuzione del trasferimento.
- Il carattere jolly si estende oltre i confini delle directory. Ad esempio, il percorso dati
my-folder/*.csvcorrisponderà al filemy-folder/my-subfolder/my-file.csv.
Esempi di percorso dei dati di Blob Storage
Di seguito sono riportati esempi di percorsi dati validi per un trasferimento di Blob Storage. Tieni presente che i percorsi dei dati non iniziano con /.
Esempio: file singolo
Per caricare un singolo file da Archiviazione BLOB in BigQuery, specifica il nome file di Archiviazione BLOB:
my-folder/my-file.csv
Esempio: Tutti i file
Per caricare tutti i file da un contenitore Blob Storage in BigQuery, imposta il percorso dei dati su un'unica stringa jolly:
*
Esempio: file con un prefisso comune
Per caricare tutti i file da Blob Storage che condividono un prefisso comune, specifica il prefisso comune con o senza un carattere jolly:
my-folder/
o
my-folder/*
Esempio: file con un percorso simile
Per caricare tutti i file da Blob Storage con un percorso simile, specifica il prefisso e il suffisso comuni:
my-folder/*.csv
Se utilizzi un solo carattere jolly, questo si estende alle directory. In questo esempio,
vengono selezionati tutti i file CSV in my-folder, nonché tutti i file CSV in ogni
sottocartella di my-folder.
Esempio: carattere jolly alla fine del percorso
Considera il seguente percorso dati:
logs/*
Sono selezionati tutti i seguenti file:
logs/logs.csv
logs/system/logs.csv
logs/some-application/system_logs.log
logs/logs_2019_12_12.csv
Esempio: carattere jolly all'inizio del percorso
Considera il seguente percorso dati:
*logs.csv
Sono selezionati tutti i seguenti file:
logs.csv
system/logs.csv
some-application/logs.csv
Inoltre, nessuno dei seguenti file è selezionato:
metadata.csv
system/users.csv
some-application/output.csv
Esempio: più caratteri jolly
L'utilizzo di più caratteri jolly ti consente di avere un maggiore controllo sulla selezione dei file, con il costo di limiti inferiori. Quando utilizzi più caratteri jolly, ogni carattere jolly si estende a una sola sottodirectory.
Considera il seguente percorso dati:
*/*.csv
Entrambi i seguenti file sono selezionati:
my-folder1/my-file1.csv
my-other-folder2/my-file2.csv
Né uno dei seguenti file è selezionato:
my-folder1/my-subfolder/my-file3.csv
my-other-folder2/my-subfolder/my-file4.csv
Firma di accesso condiviso
Il token SAS di Azure viene utilizzato per accedere ai dati di Blob Storage per tuo conto. Per creare un token SAS per il trasferimento:
- Crea o utilizza un utente Blob Storage esistente per accedere all'account di archiviazione per il tuo contenitore Blob Storage.
Crea un token SAS a livello di account di archiviazione. Per creare un token SAS utilizzando il portale Azure:
- Per Servizi consentiti, seleziona Blob.
- In Tipi di risorse consentiti, seleziona sia Contenitore sia Oggetto.
- In Autorizzazioni consentite, seleziona Lettura e Elenco.
- La data e l'ora di scadenza predefiniti per i token SAS sono 8 ore. Imposta una scadenza adatta alla tua pianificazione dei trasferimenti.
- Non specificare indirizzi IP nel campo Indirizzi IP consentiti.
- In Protocolli consentiti, seleziona Solo HTTPS.
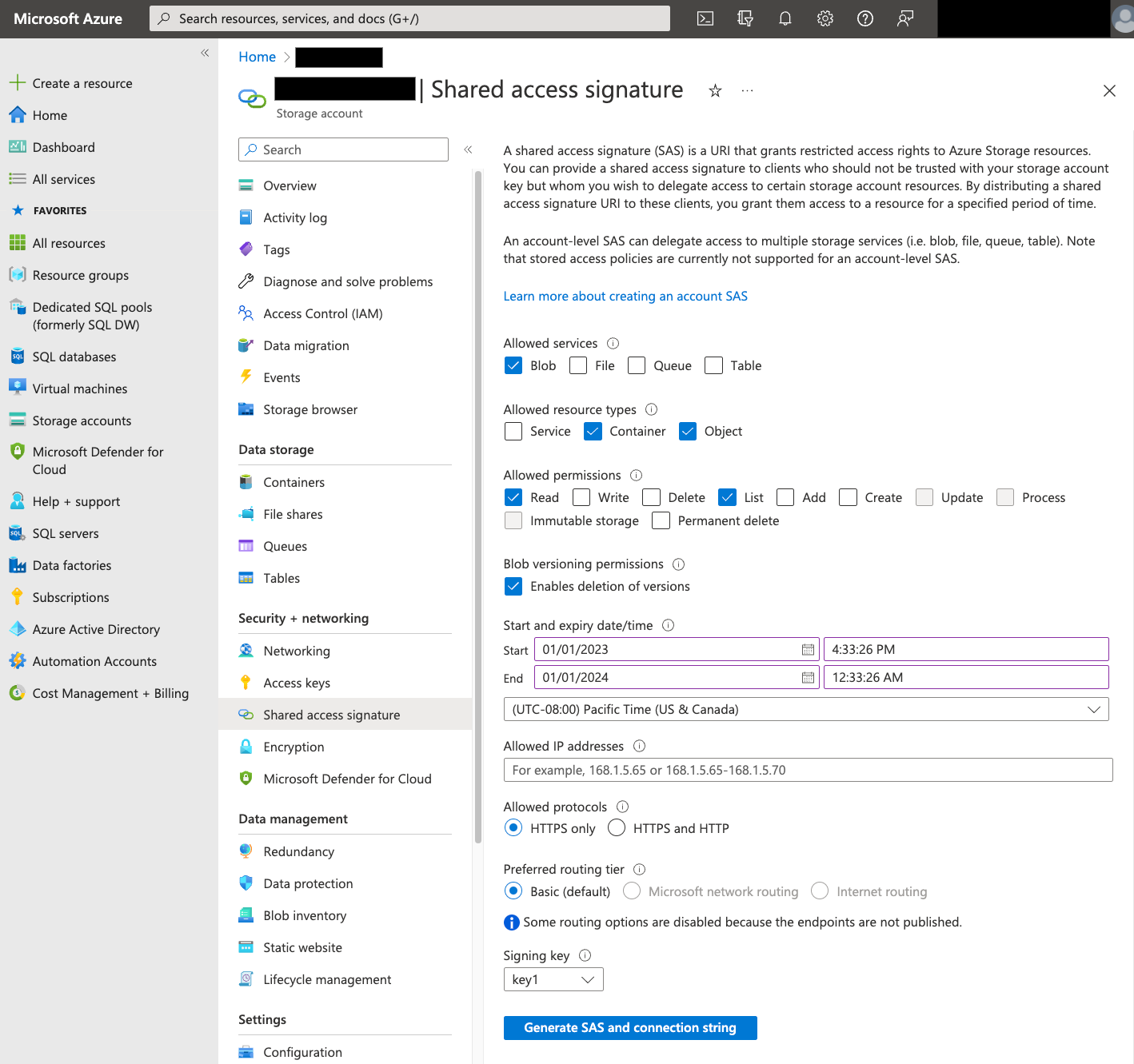
Dopo aver creato il token SAS, prendi nota del valore del token SAS che viene visualizzato. Questo valore ti servirà per configurare i trasferimenti.
Restrizioni IP
Se limiti l'accesso alle risorse Azure utilizzando una firewall di Azure Storage, devi aggiungere gli intervalli IP utilizzati dai worker di BigQuery Data Transfer Service all'elenco di IP consentiti.
Per aggiungere intervalli IP come indirizzi IP consentiti ai firewall di Azure Storage, consulta Restrizioni IP.
Considerazioni sulla coerenza
Dovrebbero essere necessari circa 5 minuti prima che un file diventi disponibile per BigQuery Data Transfer Service dopo essere stato aggiunto al contenitore Blob Storage.
Best practice per il controllo dei costi in uscita
I trasferimenti da Blob Storage potrebbero non riuscire se la tabella di destinazione non è configurata correttamente. Ecco alcune possibili cause di una configurazione non corretta:
- La tabella di destinazione non esiste.
- Lo schema della tabella non è definito.
- Lo schema della tabella non è compatibile con i dati trasferiti.
Per evitare costi aggiuntivi per i dati in uscita di Blob Storage, prova prima un trasferimento con un sottoinsieme di file piccolo, ma rappresentativo. Assicurati che questo test sia di piccole dimensioni sia per quanto riguarda le dimensioni dei dati sia per il numero di file.
È inoltre importante notare che la corrispondenza dei prefissi per i percorsi dei dati avviene prima del trasferimento dei file da Blob Storage, mentre la corrispondenza delle caratteri jolly avviene all'interno di Google Cloud. Questa distinzione potrebbe aumentare i costi di uscita di Blob Storage per i file trasferiti aGoogle Cloud ma non caricati in BigQuery.
Ad esempio, considera questo percorso dei dati:
folder/*/subfolder/*.csv
Entrambi i seguenti file vengono trasferiti in Google Cloudperché hanno il prefisso folder/:
folder/any/subfolder/file1.csv
folder/file2.csv
Tuttavia, solo il file folder/any/subfolder/file1.csv viene caricato in
BigQuery, perché corrisponde al percorso dei dati completo.
Prezzi
Per ulteriori informazioni, consulta Prezzi di BigQuery Data Transfer Service.
L'utilizzo di questo servizio può comportare anche costi esterni a Google. Per ulteriori informazioni, consulta la pagina Prezzi di Blob Storage.
Quote e limiti
BigQuery Data Transfer Service utilizza i job di caricamento per caricare i dati di Blob Storage in BigQuery. A tutti i job di caricamento di BigQuery si applicano tutte le quote e i limiti, con le seguenti considerazioni aggiuntive:
| Limite | Predefinito |
|---|---|
| Dimensioni massime per esecuzione di trasferimento del job di caricamento | 15 TB |
| Numero massimo di file per esecuzione di trasferimento quando il percorso dei dati di Archiviazione blob include 0 o 1 caratteri jolly | 10.000.000 file |
| Numero massimo di file per esecuzione di trasferimento quando il percorso dei dati di Archiviazione blob include due o più caratteri jolly | 10.000 file |
Passaggi successivi
- Scopri di più sulla configurazione di un trasferimento di Blob Storage.
- Scopri di più sui parametri di runtime nei trasferimenti.
- Scopri di più su BigQuery Data Transfer Service.