Introduction to Blob Storage transfers
The BigQuery Data Transfer Service for Azure Blob Storage lets you automatically schedule and manage recurring load jobs from Azure Blob Storage and Azure Data Lake Storage Gen2 into BigQuery.
Supported file formats
The BigQuery Data Transfer Service currently supports loading data from Blob Storage in the following formats:
- Comma-separated values (CSV)
- JSON (newline delimited)
- Avro
- Parquet
- ORC
Supported compression types
The BigQuery Data Transfer Service for Blob Storage supports loading compressed data. The compression types supported by the BigQuery Data Transfer Service are the same as the compression types supported by BigQuery load jobs. For more information, see Loading compressed and uncompressed data.
Transfer prerequisites
To load data from a Blob Storage data source, first gather the following:
- The Blob Storage account name, container name, and data path (optional) for your source data. The data path field is optional; it's used to match common object prefixes and file extensions. If the data path is omitted, all files in the container are transferred.
- An Azure shared access signature (SAS) token that grants read access to your data source. For details on creating a SAS token, see Shared access signature (SAS).
Transfer runtime parameterization
The Blob Storage data path and the destination table can both be parameterized, letting you load data from containers organized by date. The parameters used by Blob Storage transfers are the same as those used by Cloud Storage transfers. For details, see Runtime parameters in transfers.
Data ingestion for Azure Blob transfers
You can specify how data is loaded into BigQuery by selecting a Write Preference in the transfer configuration when you set up an Azure Blob transfer.
There are two types of write preferences available, incremental transfers and truncated transfers.Incremental transfers
A transfer configuration with an APPEND or WRITE_APPEND write
preference, also called an incremental transfer, incrementally appends new data
since the previous successful transfer to a BigQuery destination
table. When a transfer configuration runs with an APPEND write preference,
the
BigQuery Data Transfer Service filters for files which have been modified since the
previous successful transfer run. To determine when a file is modified,
BigQuery Data Transfer Service looks at the file metadata for a "last modified time"
property. For example, the BigQuery Data Transfer Service looks at the updated timestamp property
in a Cloud Storage file. If the
BigQuery Data Transfer Service finds any files with a "last modified time" that have
occurred after the timestamp of the last successful transfer, the
BigQuery Data Transfer Service transfers those files in an incremental transfer.
To demonstrate how incremental transfers work, consider the following
Cloud Storage transfer example. A user creates a file in a
Cloud Storage bucket at time 2023-07-01T00:00Z named file_1. The
updated timestamp for file_1 is
the time that the file was created. The user then
creates an incremental transfer from the Cloud Storage bucket,
scheduled to run once daily at time 03:00Z, starting from 2023-07-01T03:00Z.
- At 2023-07-01T03:00Z, the first transfer run starts. As this is the first
transfer run for this configuration, BigQuery Data Transfer Service attempts to
load all files matching the source URI into the destination
BigQuery table. The transfer run succeeds and
BigQuery Data Transfer Service successfully loads
file_1into the destination BigQuery table. - The next transfer run, at 2023-07-02T03:00Z, detects no files where the
updatedtimestamp property is greater than the last successful transfer run (2023-07-01T03:00Z). The transfer run succeeds without loading any additional data into the destination BigQuery table.
The preceding example shows how the BigQuery Data Transfer Service looks at the
updated timestamp property of the source file to determine if any changes were
made to the source files, and to transfer those changes if any were detected.
Following the same example, suppose that the user then creates another file in
the Cloud Storage bucket at time 2023-07-03T00:00Z, named file_2. The
updated timestamp for file_2 is
the time that the file was created.
- The next transfer run, at 2023-07-03T03:00Z, detects that
file_2has anupdatedtimestamp greater than the last successful transfer run (2023-07-01T03:00Z). Suppose that when the transfer run starts it fails due to a transient error. In this scenario,file_2is not loaded into the destination BigQuery table. The last successful transfer run timestamp remains at 2023-07-01T03:00Z. - The next transfer run, at 2023-07-04T03:00Z, detects that
file_2has anupdatedtimestamp greater than the last successful transfer run (2023-07-01T03:00Z). This time, the transfer run completes without issue, so it successfully loadsfile_2into the destination BigQuery table. - The next transfer run, at 2023-07-05T03:00Z, detects no files where the
updatedtimestamp is greater than the last successful transfer run (2023-07-04T03:00Z). The transfer run succeeds without loading any additional data into the destination BigQuery table.
The preceding example shows that when a transfer fails, no files are transferred to the BigQuery destination table. Any file changes are transferred at the next successful transfer run. Any subsequent successful transfers following a failed transfer does not cause duplicate data. In the case of a failed transfer, you can also choose to manually trigger a transfer outside its regularly scheduled time.
Truncated transfers
A transfer configuration with a MIRROR or WRITE_TRUNCATE write
preference, also called a truncated transfer, overwrites data in the
BigQuery destination table during each transfer run with data
from all files matching the source URI. MIRROR overwrites a fresh copy of
data in the destination table. If the destination table is using a partition
decorator, the transfer run only overwrites data in the specified partition. A
destination table with a partition decorator has the format
my_table${run_date}—for example, my_table$20230809.
Repeating the same incremental or truncated transfers in a day does not cause duplicate data. However, if you run multiple different transfer configurations that affect the same BigQuery destination table, this can cause the BigQuery Data Transfer Service to duplicate data.
Wildcard support for the Blob Storage data path
You can select source data that is separated into multiple files by specifying
one or more asterisk (*) wildcard characters in the data path.
While more than one wildcard can be used in the data path, some optimization is possible when only a single wildcard is used:
- There is a higher limit on the maximum number of files per transfer run.
- The wildcard will span directory boundaries. For example, the data path
my-folder/*.csvwill match the filemy-folder/my-subfolder/my-file.csv.
Blob Storage data path examples
The following are examples of valid data paths for a Blob Storage
transfer. Note that data paths do not begin with /.
Example: Single file
To load a single file from Blob Storage into BigQuery, specify the Blob Storage filename:
my-folder/my-file.csv
Example: All files
To load all files from a Blob Storage container into BigQuery, set the data path to a single wildcard:
*
Example: Files with a common prefix
To load all files from Blob Storage that share a common prefix, specify the common prefix with or without a wildcard:
my-folder/
or
my-folder/*
Example: Files with a similar path
To load all files from Blob Storage with a similar path, specify the common prefix and suffix:
my-folder/*.csv
When you only use a single wildcard, it spans directories. In this example,
every CSV file in my-folder is selected, as well as every CSV file in every
subfolder of my-folder.
Example: Wildcard at end of path
Consider the following data path:
logs/*
All of the following files are selected:
logs/logs.csv
logs/system/logs.csv
logs/some-application/system_logs.log
logs/logs_2019_12_12.csv
Example: Wildcard at beginning of path
Consider the following data path:
*logs.csv
All of the following files are selected:
logs.csv
system/logs.csv
some-application/logs.csv
And none of the following files are selected:
metadata.csv
system/users.csv
some-application/output.csv
Example: Multiple wildcards
By using multiple wildcards, you gain more control over file selection, at the cost of lower limits. When you use multiple wildcards, each individual wildcard only spans a single subdirectory.
Consider the following data path:
*/*.csv
Both of the following files are selected:
my-folder1/my-file1.csv
my-other-folder2/my-file2.csv
And neither of the following files are selected:
my-folder1/my-subfolder/my-file3.csv
my-other-folder2/my-subfolder/my-file4.csv
Shared access signature (SAS)
The Azure SAS token is used to access Blob Storage data on your behalf. Use the following steps to create a SAS token for your transfer:
- Create or use an existing Blob Storage user to access the storage account for your Blob Storage container.
Create a SAS token at the storage account level. To create a SAS token using Azure Portal, do the following:
- For Allowed services, select Blob.
- For Allowed resource types, select both Container and Object.
- For Allowed permissions, select Read and List.
- The default expiration time for SAS tokens is 8 hours. Set an expiration time that works for your transfer schedule.
- Do not specify any IP addresses in the Allowed IP addresses field.
- For Allowed protocols, select HTTPS only.
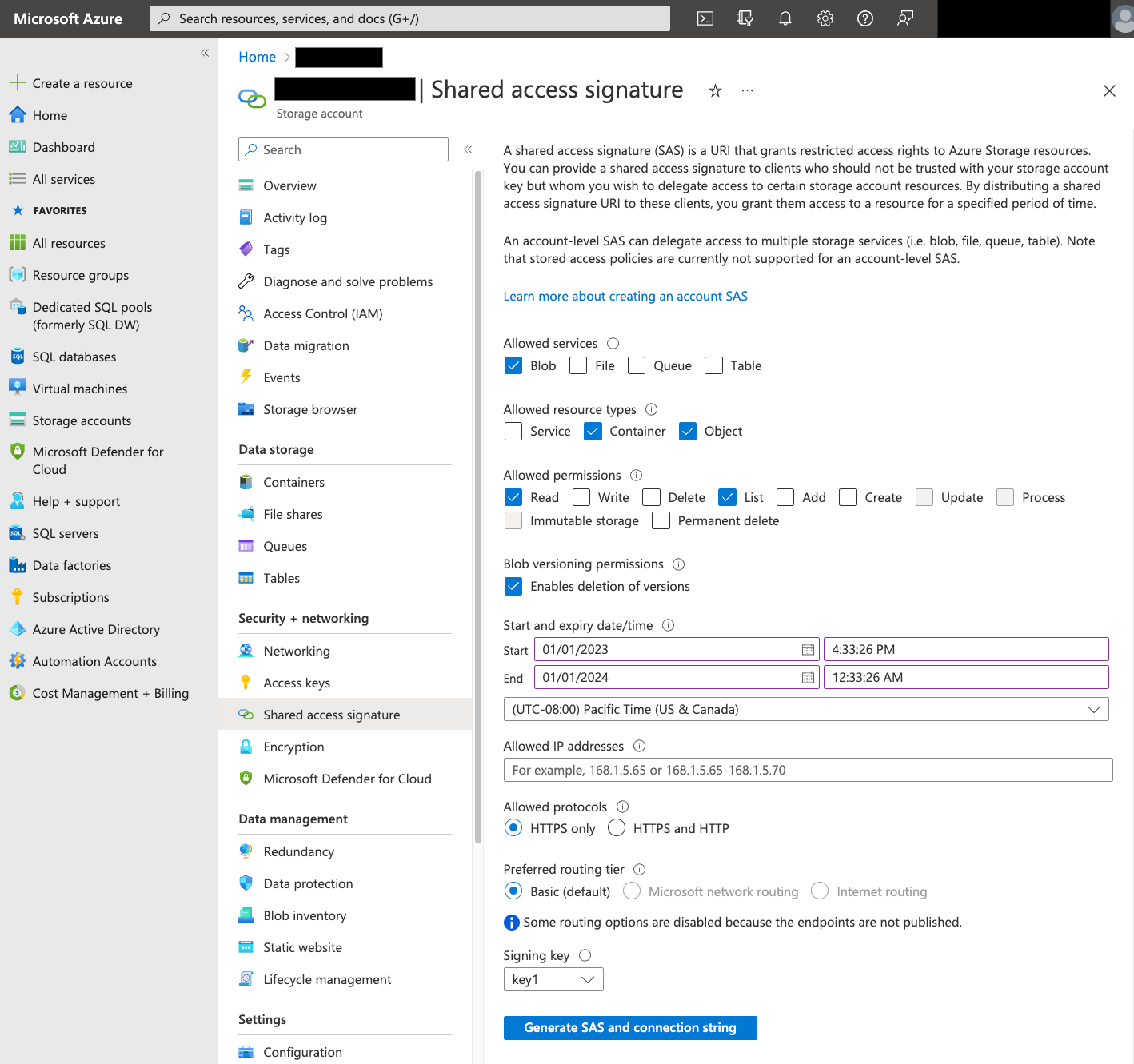
After the SAS token is created, note the SAS token value that is returned. You need this value when you configure transfers.
IP restrictions
If you restrict access to your Azure resources using an Azure Storage firewall, you must add the IP ranges used by BigQuery Data Transfer Service workers to your list of allowed IPs.
To add IP ranges as allowed IPs to Azure Storage firewalls, see IP restrictions.
Consistency considerations
It should take approximately 5 minutes for a file to become available to the BigQuery Data Transfer Service after it is added to the Blob Storage container.
Best practices for controlling egress costs
Transfers from Blob Storage could fail if the destination table is not configured properly. Possible causes of an improper configuration include the following:
- The destination table does not exist.
- The table schema is not defined.
- The table schema is not compatible with the data being transferred.
To avoid extra Blob Storage egress costs, first test a transfer with a small but representative subset of files. Ensure that this test is small in both data size and file count.
It's also important to note that prefix matching for data paths happens before files are transferred from Blob Storage, but wildcard matching happens within Google Cloud. This distinction could increase Blob Storage egress costs for files that are transferred to Google Cloud but not loaded into BigQuery.
As an example, consider this data path:
folder/*/subfolder/*.csv
Both of the following files are transferred to Google Cloud, because
they have the prefix folder/:
folder/any/subfolder/file1.csv
folder/file2.csv
However, only the folder/any/subfolder/file1.csv file is loaded into
BigQuery, because it matches the full data path.
Pricing
For more information, see BigQuery Data Transfer Service pricing.
You can also incur costs outside of Google by using this service. For more information, see Blob Storage pricing.
Quotas and limits
The BigQuery Data Transfer Service uses load jobs to load Blob Storage data into BigQuery. All BigQuery quotas and limits on load jobs apply to recurring Blob Storage transfers, with the following additional considerations:
| Limit | Default |
|---|---|
| Maximum size per load job transfer run | 15 TB |
| Maximum number of files per transfer run when the Blob Storage data path includes 0 or 1 wildcards | 10,000,000 files |
| Maximum number of files per transfer run when the Blob Storage data path includes 2 or more wildcards | 10,000 files |
What's next
- Learn more about setting up a Blob Storage transfer.
- Learn more about runtime parameters in transfers.
- Learn more about the BigQuery Data Transfer Service.