Este tutorial ensina analistas de dados a usar o BigQuery ML.
Com o BigQuery ML, usuários podem criar e executar modelos de machine learning no BigQuery usando consultas SQL. Esse tutorial faz uma introdução à engenharia de atributos usando a cláusula TRANSFORM. Usando a cláusula TRANSFORM, é possível especificar todo o pré-processamento durante a criação do modelo. O pré-processamento é aplicado automaticamente durante as fases de previsão e avaliação do aprendizado de máquina.
Neste tutorial, você usa a natalitytabela de amostras para criar um modelo que prevê o peso ao nascer de uma criança com base em seu sexo, na duração da gestação e nas informações demográficas em intervalos da mãe. A tabela de amostras natality contém informações sobre todos os nascimentos nos Estados Unidos dos últimos 40 anos.
Objetivos
Neste tutorial, você usará:
- BigQuery ML para criar um modelo de regressão linear usando a instrução
CREATE MODELcom a cláusulaTRANSFORM; - as funções de pré-processamento
ML.FEATURE_CROSSeML.QUANTILE_BUCKETIZE; - a função
ML.EVALUATEpara avaliar o modelo de ML; - a função
ML.PREDICTpara fazer previsões usando o modelo de ML.
Custos
Neste tutorial, há componentes faturáveis do Google Cloud, entre eles:
- BigQuery
- BigQuery ML
Para mais informações sobre os custos do BigQuery, consulte a página de preços.
Antes de começar
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
- O BigQuery é ativado automaticamente em novos projetos.
Para ativar o BigQuery em um projeto preexistente, acesse
Enable the BigQuery API.
Etapa 1: criar conjunto de dados
Crie um conjunto de dados do BigQuery para armazenar o modelo de ML:
No console do Google Cloud, acesse a página do BigQuery.
No painel Explorer, clique no nome do seu projeto.
Clique em Conferir ações > Criar conjunto de dados.
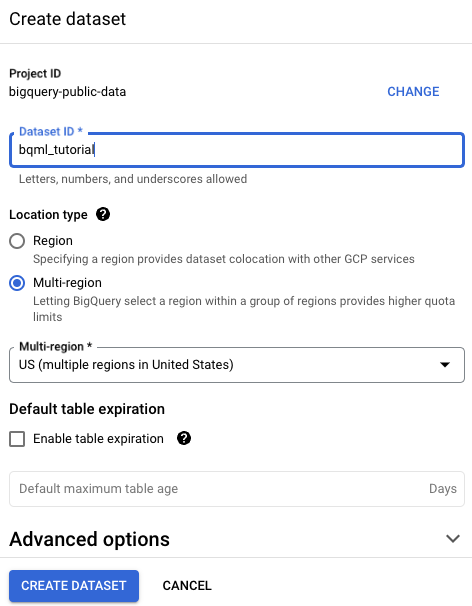
Na página Criar conjunto de dados, faça o seguinte:
Para o código do conjunto de dados, insira
bqml_tutorial.Em Tipo de local, selecione Multirregião e EUA (várias regiões nos Estados Unidos).
Os conjuntos de dados públicos são armazenados na multirregião
US. Para simplificar, armazene seus conjuntos de dados no mesmo local.Mantenha as configurações padrão restantes e clique em Criar conjunto de dados.
Etapa 2: criar modelo
Em seguida, crie um modelo de regressão linear usando a tabela de amostras de natalidade do BigQuery. Com a consulta GoogleSQL padrão abaixo, você cria o modelo usado para prever o peso de uma criança ao nascer.
#standardSQL CREATE MODEL `bqml_tutorial.natality_model` TRANSFORM(weight_pounds, is_male, gestation_weeks, ML.QUANTILE_BUCKETIZE(mother_age, 5) OVER() AS bucketized_mother_age, CAST(mother_race AS string) AS mother_race, ML.FEATURE_CROSS(STRUCT(is_male, CAST(mother_race AS STRING) AS mother_race)) is_male_mother_race) OPTIONS (model_type='linear_reg', input_label_cols=['weight_pounds']) AS SELECT * FROM `bigquery-public-data.samples.natality` WHERE weight_pounds IS NOT NULL AND RAND() < 0.001
Ao executar o comando CREATE MODEL, o modelo será criado e treinado.
Detalhes da consulta
A cláusula CREATE MODEL é usada para criar e treinar o modelo chamado bqml_tutorial.natality_model.
A cláusula OPTIONS(model_type='linear_reg', input_label_cols=['weight_pounds']) indica que você está criando um modelo de regressão linear. Regressão linear é um tipo de modelo de regressão que gera um valor contínuo a partir de uma combinação linear de recursos de entrada. A coluna weight_pounds é a coluna do rótulo de entrada. Para modelos de regressão linear, é preciso que a coluna de rótulo tenha valor real, isto é, os valores da coluna precisam ser números reais.
A cláusula TRANSFORM desta consulta usa as seguintes colunas da instrução SELECT:
weight_pounds: o peso, em libras, da criança (FLOAT64);is_male: o sexo da criança; TRUE para crianças do sexo masculino, FALSE para sexo feminino (BOOL);gestation_weeks: o número de semanas da gestação (INT64);mother_age: a idade da mãe ao dar à luz (INT64);mother_race: a raça da mãe (INT64). Esse valor inteiro é igual ao valorchild_raceno esquema da tabela. Para que o BigQuery ML tratemother_racecomo um recurso não numérico, com cada valor distinto representando uma categoria diferente, a consulta convertemother_raceem uma STRING. Isso é importante porque é mais provável que a raça funcione mais como categoria do que como um número inteiro, que tem ordenação e escala.
Por meio da cláusula TRANSFORM, os recursos originais são pré-processados para o feed no treinamento. As colunas geradas são:
weight_pounds: aprovado do jeito que está, sem nenhuma alteração;is_male: aprovado pelo feed no treinamento;gestation_weeks: aprovado pelo feed no treinamento;bucketized_mother_age: gerado a partir demother_age, dividindomother_agecom base em quantis com a função analíticaML.QUANTILE_BUCKETIZE();mother_race: formato de string do originalmother_race;is_male_mother_race: gerado a partir do cruzamento deis_maleemother_raceusando a funçãoML.FEATURE_CROSS.
A instrução SELECT da consulta fornece as colunas que podem ser usadas na cláusula TRANSFORM. No entanto, não é preciso usar todas as colunas na cláusula TRANSFORM. Assim, é possível fazer a seleção de recursos e o pré-processamento dentro da cláusula TRANSFORM.
A cláusula FROM — bigquery-public-data.samples.natality — indica que você está consultando a tabela de amostras de natalidade no conjunto de dados de amostras.
Esse conjunto de dados está no projeto bigquery-public-data.
A cláusula WHERE — WHERE weight_pounds IS NOT NULL AND RAND() < 0.001 — exclui linhas em que o peso é NULL e usa a função RAND para desenhar uma amostra aleatória dos dados.
Executar a consulta CREATE MODEL
Para executar a consulta CREATE MODEL para criar e treinar seu modelo:
No console do Google Cloud, clique no botão Escrever nova consulta.
Insira a seguinte consulta do GoogleSQL na área de texto do Editor de consultas.
#standardSQL CREATE MODEL `bqml_tutorial.natality_model` TRANSFORM(weight_pounds, is_male, gestation_weeks, ML.QUANTILE_BUCKETIZE(mother_age, 5) OVER() AS bucketized_mother_age, CAST(mother_race AS string) AS mother_race, ML.FEATURE_CROSS(STRUCT(is_male, CAST(mother_race AS STRING) AS mother_race)) is_male_mother_race) OPTIONS (model_type='linear_reg', input_label_cols=['weight_pounds']) AS SELECT * FROM `bigquery-public-data.samples.natality` WHERE weight_pounds IS NOT NULL AND RAND() < 0.001
Clique em Executar.
A consulta leva por volta de 30 segundos para ser concluída. Depois disso, o modelo (
natality_model) aparece no painel de navegação. Como a consulta usa uma instruçãoCREATE MODELpara criar uma tabela, não é possível ver os resultados da consulta.
Etapa 3 (opcional): receber estatísticas de treinamento
Para ver os resultados do treinamento de modelo, use a função
ML.TRAINING_INFO
ou visualize as estatísticas no console do Google Cloud. Neste
tutorial, você usa o console do Google Cloud.
Para criar um modelo, um algoritmo de machine learning examina vários exemplos e tenta encontrar um modelo que minimize a perda. Esse processo é chamado de minimização do risco empírico.
Perda é a penalidade para uma previsão ruim, ou seja, um número que indica como a previsão do modelo foi ruim em um único exemplo. Para uma previsão de modelo perfeita, a perda é zero. Caso contrário, a perda é maior. O treinamento de um modelo visa encontrar um conjunto de ponderações e tendências com uma média de perda menor em todos os exemplos.
Para ver as estatísticas de treinamento do modelo que foram geradas quando você executou a consulta CREATE MODEL:
Na seção Recursos do painel de navegação do console do Google Cloud, expanda project-name > bqml_tutorial e clique em natality_model.
Clique na guia Treinamento e, para Visualizar como, selecione a opção Tabela. Os resultados vão ter a aparência abaixo:
+-----------+--------------------+----------------------+--------------------+ | Iteration | Training data loss | Evaluation data loss | Duration (seconds) | +-----------+--------------------+----------------------+--------------------+ | 0 | 1.6640 | 1.7352 | 6.27 | +-----------+--------------------+----------------------+--------------------+
A coluna Perda de dados de treinamento representa métrica da perda, calculada depois de o modelo ser treinado no conjunto de dados de treinamento. Como você executou uma regressão linear, essa coluna é o erro quadrático médio.
A coluna Perda de dados de avaliação é a mesma métrica de perda calculada no conjunto de dados de validação, ou seja, dados do treinamento mantidos para validar o modelo. Como a estratégia de otimização padrão usada para o treinamento é "normal_equation", é necessária apenas uma iteração para convergir no modelo final.
Para mais informações sobre a opção
optimize_strategy, consulte a instruçãoCREATE MODEL.Para mais informações sobre a função
ML.TRAINING_INFOe a opção de treinamento "optimize_strategy", consulte a referência de sintaxe do BigQuery ML.
Etapa 4: avaliar o modelo
Depois de criar o modelo, avalie o desempenho do classificador por meio da função ML.EVALUATE. A função ML.EVALUATE avalia os valores previstos em relação aos dados reais.
A consulta usada para avaliar o modelo é a seguinte:
#standardSQL SELECT * FROM ML.EVALUATE(MODEL `bqml_tutorial.natality_model`, ( SELECT * FROM `bigquery-public-data.samples.natality` WHERE weight_pounds IS NOT NULL))
Detalhes da consulta
A instrução SELECT superior recupera as colunas do modelo.
A cláusula FROM usa a função ML.EVALUATE no modelo: bqml_tutorial.natality_model.
A cláusula FROM e a instrução SELECT aninhada desta consulta são as mesmas da consulta CREATE MODEL. Como a cláusula TRANSFORM é usada no treinamento, não é possível especificar as colunas e transformações. Elas são restauradas automaticamente.
A cláusula WHERE — WHERE weight_pounds IS NOT NULL — exclui linhas em que o peso é NULL.
#standardSQL SELECT * FROM ML.EVALUATE(MODEL `bqml_tutorial.natality_model`)
Executar a consulta ML.EVALUATE
Para executar a consulta ML.EVALUATE que avalia o modelo, conclua as seguintes etapas:
No console do Google Cloud, clique no botão Escrever nova consulta.
Insira a seguinte consulta do GoogleSQL na área de texto do Editor de consultas.
#standardSQL SELECT * FROM ML.EVALUATE(MODEL `bqml_tutorial.natality_model`, ( SELECT * FROM `bigquery-public-data.samples.natality` WHERE weight_pounds IS NOT NULL))
(Opcional) Para definir o local de processamento, na lista suspensa settings_applicationsMais, clique em Configurações de consulta. Para Local de processamento, selecione Estados Unidos (EUA). Essa etapa é opcional, já que o local de processamento é detectado automaticamente de acordo com o local do conjunto de dados.
Clique em Executar.
Após concluir a consulta, clique na guia Resultados abaixo da área de texto da consulta. Os resultados terão a aparência abaixo:
+---------------------+--------------------+------------------------+---------------------+---------------------+----------------------+ | mean_absolute_error | mean_squared_error | mean_squared_log_error | mean_absolute_error | r2_score | explained_variance | +---------------------+--------------------+------------------------+---------------------+---------------------+----------------------+ | 0.9566580179970666 | 1.6756289722442677 | 0.034241471462096516 | 0.7385590721661188 | 0.04650972930257946 | 0.046516832131241026 | +---------------------+--------------------+------------------------+---------------------+---------------------+----------------------+
Como você executou uma regressão linear, os resultados incluem as seguintes colunas:
mean_absolute_errormean_squared_errormean_squared_log_errormedian_absolute_errorr2_scoreexplained_variance
Uma métrica importante nos resultados da avaliação é a pontuação R2.
A pontuação R2 é uma medida estatística que determina se as previsões de regressão linear se aproximam dos dados reais. Um valor 0 indica que o modelo não explica a variabilidade dos dados de resposta em torno da média. Um valor 1 indica que o modelo explica toda a variabilidade dos dados de resposta em torno da média.
Etapa 5: usar o modelo para prever resultados
Agora seu modelo foi avaliado, a próxima etapa é usá-lo para prever um resultado. É possível usar o modelo para prever o peso ao nascer de todos os bebês nascidos em Wyoming.
A consulta usada para prever o resultado é a seguinte:
#standardSQL SELECT predicted_weight_pounds FROM ML.PREDICT(MODEL `bqml_tutorial.natality_model`, ( SELECT * FROM `bigquery-public-data.samples.natality` WHERE state = "WY"))
Detalhes da consulta
A principal instrução SELECT recupera a coluna predicted_weight_pounds.
Essa coluna é gerada pela função ML.PREDICT. Ao usar a função ML.PREDICT, o nome da coluna de saída para o modelo é predicted_label_column_name. Para modelos de regressão linear, predicted_label é o valor estimado de label. Para modelos de regressão logística, predicted_label é um dos dois rótulos de entrada, dependendo de qual rótulo tem a maior probabilidade prevista.
A função ML.PREDICT é usada para prever resultados usando o modelo: bqml_tutorial.natality_model.
A cláusula FROM e a instrução SELECT aninhada desta consulta são as mesmas da consulta CREATE MODEL. Observe que não é preciso aprovar todas as colunas como no treinamento. Somente as usadas na cláusula TRANSFORM são obrigatórias. Assim como a ML.EVALUATE, as transformações dentro de TRANSFORM são restauradas automaticamente.
A cláusula WHERE — WHERE state = "WY" — indica que você está limitando a previsão ao estado de Wyoming.
Executar a consulta ML.PREDICT
Veja como executar a consulta que usa o modelo para prever um resultado:
No console do Google Cloud, clique no botão Escrever nova consulta.
Insira a seguinte consulta do GoogleSQL na área de texto do Editor de consultas.
#standardSQL SELECT predicted_weight_pounds FROM ML.PREDICT(MODEL `bqml_tutorial.natality_model`, ( SELECT * FROM `bigquery-public-data.samples.natality` WHERE state = "WY"))
(Opcional) Para definir o local de processamento, na lista suspensa settings_applicationsMais, clique em Configurações de consulta. Para Local de processamento, selecione Estados Unidos (EUA). Essa etapa é opcional, já que o local de processamento é detectado automaticamente de acordo com o local do conjunto de dados.
Clique em Executar.
Após concluir a consulta, clique na guia Resultados abaixo da área de texto da consulta. Os resultados terão a aparência abaixo:
+----------------------------+ | predicted_weight_pounds | +----------------------------+ | 7.735962399307027 | +----------------------------+ | 7.728855793480761 | +----------------------------+ | 7.383850250400428 | +----------------------------+ | 7.4132677633242565 | +----------------------------+ | 7.734971309702814 | +----------------------------+
Limpar
Para evitar cobranças na sua conta do Google Cloud pelos recursos usados no tutorial, exclua o projeto que os contém ou mantenha o projeto e exclua os recursos individuais.
- exclua o projeto que você criou; ou
- Mantenha o projeto e exclua o conjunto de dados.
Excluir o conjunto de dados
A exclusão do seu projeto removerá todos os conjuntos de dados e tabelas no projeto. Caso prefira reutilizá-lo, exclua o conjunto de dados criado neste tutorial:
Se necessário, abra a página do BigQuery no console do Google Cloud.
No painel de navegação, clique no conjunto de dados bqml_tutorial que você criou.
No lado direito da janela, clique em Excluir conjunto de dados. Essa ação exclui o conjunto, a tabela e todos os dados.
Na caixa de diálogo Excluir conjunto de dados, confirme o comando de exclusão digitando o nome do seu conjunto de dados (
bqml_tutorial) e clique em Excluir.
Excluir o projeto
Para excluir o projeto:
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
A seguir
- Para saber mais sobre machine learning, consulte o Curso intensivo de machine learning.
- Para uma visão geral do BigQuery ML, consulte Introdução ao BigQuery ML.
- Para saber mais, consulte Como usar o console do Google Cloud.