Questo tutorial spiega come creare un
modello di fattorizzazione della matrice
e addestrarlo sui dati delle sessioni utente di Google Analytics 360 nella tabella
GA360_test.ga_sessions_sample pubblica. Poi utilizzi il modello di fattorizzazione matriciale per generare consigli sui contenuti per gli utenti del sito.
L'utilizzo di informazioni indirette sulle preferenze dei clienti, come la durata della sessione utente, per addestrare il modello è chiamato addestramento con feedback implicito. I modelli di fattorizazione della matrice vengono addestrati utilizzando l'algoritmo dei minimi quadrati alternati ponderati quando utilizzi il feedback implicito come dati di addestramento.
Obiettivi
Questo tutorial ti guiderà nel completamento delle seguenti attività:
- Creare un modello di fattorizzazione matriciale utilizzando l'istruzione
CREATE MODEL. - Valutare il modello utilizzando la
funzione
ML.EVALUATE. - Generare consigli sui contenuti per gli utenti utilizzando il modello con la
funzione
ML.RECOMMEND.
Costi
Questo tutorial utilizza i componenti fatturabili di Google Cloud, tra cui:
- BigQuery
- BigQuery ML
Per ulteriori informazioni sui costi di BigQuery, consulta la pagina Prezzi di BigQuery.
Per ulteriori informazioni sui costi di BigQuery ML, consulta Prezzi di BigQuery ML.
Prima di iniziare
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
- BigQuery viene attivato automaticamente nei nuovi progetti.
Per attivare BigQuery in un progetto preesistente, vai a
Enable the BigQuery API.
Autorizzazioni richieste
Per creare il set di dati, devi disporre dell'autorizzazione IAM
bigquery.datasets.create.Per creare il modello, devi disporre delle seguenti autorizzazioni:
bigquery.jobs.createbigquery.models.createbigquery.models.getDatabigquery.models.updateData
Per eseguire l'inferenza, devi disporre delle seguenti autorizzazioni:
bigquery.models.getDatabigquery.jobs.create
Per saperne di più sui ruoli e sulle autorizzazioni IAM in BigQuery, consulta Introduzione a IAM.
Crea un set di dati
Crea un set di dati BigQuery per archiviare il tuo modello ML.
Console
Nella console Google Cloud, vai alla pagina BigQuery.
Nel riquadro Explorer, fai clic sul nome del progetto.
Fai clic su Visualizza azioni > Crea set di dati.
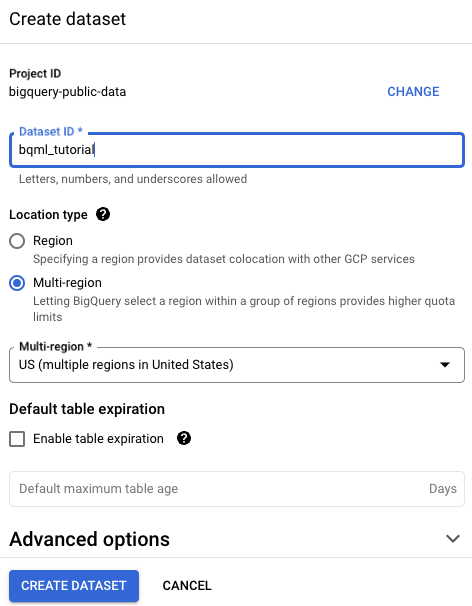
Nella pagina Crea set di dati:
In ID set di dati, inserisci
bqml_tutorial.Per Tipo di località, seleziona Più regioni e poi Stati Uniti (più regioni negli Stati Uniti).
I set di dati pubblici sono archiviati nella
USmultiregione. Per semplicità, archivia il tuo set di dati nella stessa posizione.- Lascia invariate le restanti impostazioni predefinite e fai clic su Crea set di dati.
bq
Per creare un nuovo set di dati, utilizza il comando
bq mk con il flag --location. Per un elenco completo dei possibili parametri, consulta la documentazione di riferimento del comando bq mk --dataset.
Crea un set di dati denominato
bqml_tutorialcon la posizione dei dati impostata suUSe una descrizione diBigQuery ML tutorial dataset:bq --location=US mk -d \ --description "BigQuery ML tutorial dataset." \ bqml_tutorial
Anziché utilizzare il flag
--dataset, il comando utilizza la scorciatoia-d. Se ometti-de--dataset, il comando crea per impostazione predefinita un set di dati.Verifica che il set di dati sia stato creato:
bq ls
API
Chiama il metodo datasets.insert con una risorsa set di dati definita.
{ "datasetReference": { "datasetId": "bqml_tutorial" } }
Prepara i dati di esempio
Trasforma i dati della tabella GA360_test.ga_sessions_sample in una struttura migliore per l'addestramento del modello, quindi scrivi questi dati in una tabella BigQuery. La seguente query calcola la durata della sessione per ogni utente e per ogni contenuto, che puoi poi utilizzare come feedback implicito per dedurre la preferenza dell'utente per i contenuti in questione.
Per creare la tabella dei dati di addestramento:
Nella console Google Cloud, vai alla pagina BigQuery.
Crea la tabella dei dati di addestramento. Nell'editor di query, incolla la seguente query e fai clic su Esegui:
CREATE OR REPLACE TABLE `bqml_tutorial.analytics_session_data` AS WITH visitor_page_content AS ( SELECT fullVisitorID, ( SELECT MAX( IF( index = 10, value, NULL)) FROM UNNEST(hits.customDimensions) ) AS latestContentId, (LEAD(hits.time, 1) OVER (PARTITION BY fullVisitorId ORDER BY hits.time ASC) - hits.time) AS session_duration FROM `cloud-training-demos.GA360_test.ga_sessions_sample`, UNNEST(hits) AS hits WHERE # only include hits on pages hits.type = 'PAGE' GROUP BY fullVisitorId, latestContentId, hits.time ) # aggregate web stats SELECT fullVisitorID AS visitorId, latestContentId AS contentId, SUM(session_duration) AS session_duration FROM visitor_page_content WHERE latestContentId IS NOT NULL GROUP BY fullVisitorID, latestContentId HAVING session_duration > 0 ORDER BY latestContentId;
Visualizza un sottoinsieme dei dati di addestramento. Nell'editor di query, incolla la seguente query e fai clic su Esegui:
SELECT * FROM `bqml_tutorial.analytics_session_data` LIMIT 5;
I risultati dovrebbero essere simili ai seguenti:
+---------------------+-----------+------------------+ | visitorId | contentId | session_duration | +---------------------+-----------+------------------+ | 7337153711992174438 | 100074831 | 44652 | +---------------------+-----------+------------------+ | 5190801220865459604 | 100170790 | 121420 | +---------------------+-----------+------------------+ | 2293633612703952721 | 100510126 | 47744 | +---------------------+-----------+------------------+ | 5874973374932455844 | 100510126 | 32109 | +---------------------+-----------+------------------+ | 1173698801255170595 | 100676857 | 10512 | +---------------------+-----------+------------------+
Crea il modello
Crea un modello di fattorizzazione matriciale e addestralo sui dati della tabellaanalytics_session_data. Il modello viene addestrato per prevedere un valore di affidabilità per ogni coppia visitorId-contentId. La valutazione della confidenza viene creata con il centro e la scalatura in base alla durata media della sessione. I record in cui la durata della sessione è superiore a 3,33 volte la media vengono esclusi come valori anomali.
Il seguente statement CREATE MODEL utilizza queste colonne per generare consigli:
visitorId: l'ID visitatore.contentId: l'ID contenuto.rating: la valutazione implicita da 0 a 1 calcolata per ogni coppia di visitatore e contenuti, centrata e scalata.
Nella console Google Cloud, vai alla pagina BigQuery.
Nell'editor di query, incolla la seguente query e fai clic su Esegui:
CREATE OR REPLACE MODEL `bqml_tutorial.mf_implicit` OPTIONS ( MODEL_TYPE = 'matrix_factorization', FEEDBACK_TYPE = 'implicit', USER_COL = 'visitorId', ITEM_COL = 'contentId', RATING_COL = 'rating', L2_REG = 30, NUM_FACTORS = 15) AS SELECT visitorId, contentId, 0.3 * (1 + (session_duration - 57937) / 57937) AS rating FROM `bqml_tutorial.analytics_session_data` WHERE 0.3 * (1 + (session_duration - 57937) / 57937) < 1;
Il completamento della query richiede circa 10 minuti, dopodiché il
mf_implicitmodello viene visualizzato nel riquadro Explorer. Poiché la query utilizza un'istruzioneCREATE MODELper creare un modello, non vengono visualizzati i risultati della query.
Visualizzare le statistiche di addestramento
Se vuoi, puoi visualizzare le statistiche di addestramento del modello nella console Google Cloud.
Un algoritmo di machine learning crea un modello creando molte iterazioni del modello utilizzando parametri diversi e poi selezionando la versione del modello che riduce al minimo la perdita. Questo processo è noto come minimizzazione empirica del rischio. Le statistiche di addestramento del modello ti consentono di vedere la perdita associata a ogni iterazione del modello.
Per visualizzare le statistiche di addestramento del modello:
Nella console Google Cloud, vai alla pagina BigQuery.
Nel riquadro Explorer, espandi il progetto, il set di dati
bqml_tutoriale la cartella Modelli.Fai clic sul modello
mf_implicite poi sulla scheda Addestramento.Nella sezione Visualizza come, fai clic su Tabella. I risultati dovrebbero essere simili ai seguenti:
+-----------+--------------------+--------------------+ | Iteration | Training Data Loss | Duration (seconds) | +-----------+--------------------+--------------------+ | 5 | 0.0027 | 47.27 | +-----------+--------------------+--------------------+ | 4 | 0.0028 | 39.60 | +-----------+--------------------+--------------------+ | 3 | 0.0032 | 55.57 | +-----------+--------------------+--------------------+ | ... | ... | ... | +-----------+--------------------+--------------------+
La colonna Perdita di dati di addestramento rappresenta la metrica relativa alla perdita calcolata dopo l'addestramento del modello. Poiché si tratta di un modello di fattorizzazione della matrice, questa colonna mostra l'errore quadratico medio.
Valuta il modello
Valuta le prestazioni del modello utilizzando la funzione ML.EVALUATE.
La funzione ML.EVALUATE valuta le classificazioni dei contenuti previste restituite dal
modello in base alle metriche di valutazione calcolate durante l'addestramento.
Per valutare il modello:
Nella console Google Cloud, vai alla pagina BigQuery.
Nell'editor di query, incolla la seguente query e fai clic su Esegui:
SELECT * FROM ML.EVALUATE(MODEL `bqml_tutorial.mf_implicit`);
I risultati dovrebbero essere simili ai seguenti:
+------------------------+-----------------------+---------------------------------------+---------------------+ | mean_average_precision | mean_squared_error | normalized_discounted_cumulative_gain | average_rank | +------------------------+-----------------------+---------------------------------------+---------------------+ | 0.4434341257478137 | 0.0013381759837648962 | 0.9433280547112802 | 0.24031636088594222 | +------------------------+-----------------------+---------------------------------------+---------------------+
Per saperne di più sull'output della funzione
ML.EVALUATE, consulta Modelli di fattorizzazione della matrice.
Ottenere le valutazioni previste per un sottoinsieme di coppie di visitatori e contenuti
Utilizza ML.RECOMMEND per ottenere la classificazione prevista per ogni contenuto per cinque visitatori del sito.
Per ottenere le valutazioni previste:
Nella console Google Cloud, vai alla pagina BigQuery.
Nell'editor di query, incolla la seguente query e fai clic su Esegui:
SELECT * FROM ML.RECOMMEND( MODEL `bqml_tutorial.mf_implicit`, ( SELECT visitorId FROM `bqml_tutorial.analytics_session_data` LIMIT 5 ));
I risultati dovrebbero essere simili ai seguenti:
+-------------------------------+---------------------+-----------+ | predicted_rating_confidence | visitorId | contentId | +-------------------------------+---------------------+-----------+ | 0.0033608418060270262 | 7337153711992174438 | 277237933 | +-------------------------------+---------------------+-----------+ | 0.003602395397293956 | 7337153711992174438 | 158246147 | +-------------------------------+---------------------+-- -------+ | 0.0053197670652785356 | 7337153711992174438 | 299389988 | +-------------------------------+---------------------+-----------+ | ... | ... | ... | +-------------------------------+---------------------+-----------+
Genera suggerimenti
Utilizza le valutazioni previste per generare i cinque ID contenuti consigliati migliori per ogni ID visitatore.
Per generare consigli:
Nella console Google Cloud, vai alla pagina BigQuery.
Scrivi le valutazioni previste in una tabella. Nell'editor di query, incolla la seguente query e fai clic su Esegui:
CREATE OR REPLACE TABLE `bqml_tutorial.recommend_content` AS SELECT * FROM ML.RECOMMEND(MODEL `bqml_tutorial.mf_implicit`);
Seleziona i cinque risultati principali per visitatore. Nell'editor di query, incolla la seguente query e fai clic su Esegui:
SELECT visitorId, ARRAY_AGG( STRUCT(contentId, predicted_rating_confidence) ORDER BY predicted_rating_confidence DESC LIMIT 5) AS rec FROM `bqml_tutorial.recommend_content` GROUP BY visitorId;
I risultati dovrebbero essere simili ai seguenti:
+---------------------+-----------------+---------------------------------+ | visitorId | rec:contentId | rec:predicted_rating_confidence | +---------------------+-----------------+------------------------- ------+ | 867526255058981688 | 299804319 | 0.88170525357178664 | | | 299935287 | 0.54699439944935124 | | | 299410466 | 0.53424780863188659 | | | 299826767 | 0.46949603950374219 | | | 299809748 | 0.3379991197434149 | +---------------------+-----------------+---------------------------------+ | 2434264018925667659 | 299824032 | 1.3903516407308065 | | | 299410466 | 0.9921995618196483 | | | 299903877 | 0.92333625294129218 | | | 299816215 | 0.91856701667757279 | | | 299852437 | 0.86973661454890561 | +---------------------+-----------------+---------------------------------+ | ... | ... | ... | +---------------------+-----------------+---------------------------------+
Esegui la pulizia
Per evitare che al tuo account Google Cloud vengano addebitati costi relativi alle risorse utilizzate in questo tutorial, elimina il progetto che contiene le risorse oppure mantieni il progetto ed elimina le singole risorse.
- Puoi eliminare il progetto che hai creato.
- In alternativa, puoi conservare il progetto ed eliminare il set di dati.
Eliminare il set di dati
L'eliminazione del progetto rimuove tutti i set di dati e tutte le tabelle nel progetto. Se preferisci riutilizzare il progetto, puoi eliminare il set di dati creato in questo tutorial:
Se necessario, apri la pagina BigQuery nella console Google Cloud.
Nella barra di navigazione, fai clic sul set di dati bqml_tutorial che hai creato.
Fai clic su Elimina set di dati sul lato destro della finestra. Questa azione elimina il set di dati, la tabella e tutti i dati.
Nella finestra di dialogo Elimina set di dati, conferma il comando di eliminazione digitando il nome del set di dati (
bqml_tutorial) e poi fai clic su Elimina.
Elimina il progetto
Per eliminare il progetto:
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
Passaggi successivi
- Prova a creare un modello di fattorizzazione matriciale basato su feedback espliciti.
- Per una panoramica di BigQuery ML, consulta Introduzione a BigQuery ML.
- Per saperne di più sul machine learning, consulta Machine Learning Crash Course.