Looker Studio でデータを分析する
BigQuery を使用して、セルフサービス型ビジネス インテリジェンス プラットフォームである Looker Studio でデータを探索できます。このプラットフォームでは、データの可視化、ダッシュボード、レポートを構築して使用できます。Looker Studio を使用すると、データに接続し、可視化を行い、分析情報を他のユーザーと共有できます。
Looker Studio にはプレミアム バージョンの Looker Studio Pro があります。これには、Identity and Access Management による権限管理、コラボレーション用のチーム ワークスペース、モバイルアプリ、テクニカル サポートなどのエンタープライズ向けの高度な機能が含まれています。
BigQuery BI Engine を使用すると、コンピューティング費用を削減しながらレポートのパフォーマンスを向上させることができます。BI Engine の詳細については、BI Engine の概要をご覧ください。
次の例では、Looker Studio を使用して BigQuery の austin_bikeshare データセットのデータを可視化します。一般公開データセットの詳細については、BigQuery の一般公開データセットをご覧ください。
クエリ結果を調べる
Looker Studio では、任意の SQL クエリを作成してデータを可視化できます。これは、Looker Studio で作業する前に BigQuery のデータを変更する場合や、テーブル内のフィールドのサブセットのみが必要な場合に便利です。ダッシュボードは、クエリ結果に基づく一時テーブルに基づいています。一時テーブルは最大 24 時間保存されます。
Google Cloud コンソールで、[BigQuery] ページに移動します。
[課金プロジェクト] を選択します。
[エクスプローラ] ペインで、[入力して検索] フィールドに「
bikeshare_trips」と入力します。bigquery-public-data > austin_bikeshare > bikeshare_trips の順に移動します。
[アクションを表示] をクリックし、[開く] をクリックします。
Query Editor でクエリを作成します。例:
SELECT * FROM `bigquery-public-data.austin_bikeshare.bikeshare_trips` LIMIT 1000;
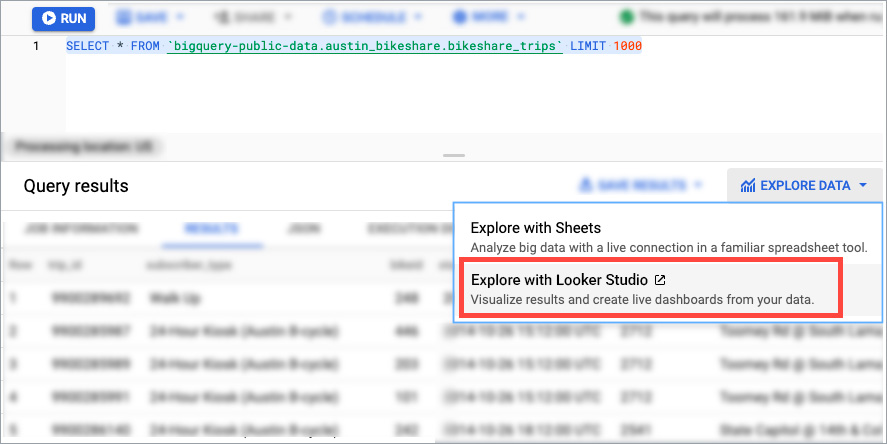
[ 実行] をクリックします。
[クエリ結果] セクションで、[データを探索] をクリックして、[Looker Studio で探索] をクリックします。
[Welcome to Looker Studio] ページで Google Looker Studio と Google の利用規約に同意する場合は [Get Started] をクリックします。
[Authorize Looker Studio access] ページで、利用規約に同意する場合は [Authorize] をクリックして接続を承認し、マーケティング設定を選択します。他のユーザーにデータを表示する権限を付与しない限り、レポート内のデータを表示できるのはユーザー本人だけです。
レポート エディタに、クエリ結果が Looker Studio のグラフとして表示されます。
次の図は、Looker Studio レポートの一部の機能を示しています。
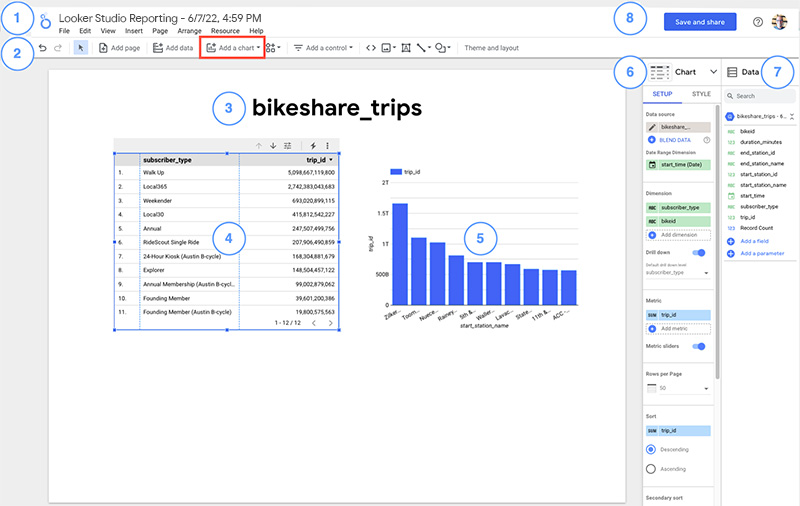
Legend:
- Looker Studio のロゴとレポート名。
- ロゴをクリックして、Looker Studio ページに移動します。
- レポート名を編集するには、名前をクリックします。
- Looker Studio のツールバー。[グラフの追加] ツールがハイライト表示されます。
- レポート タイトル。テキストを編集するには、テキスト ボックスをクリックします。
- 表(選択済み) 選択したグラフは、グラフのヘッダーにあるオプションを使って操作できます。
- 棒グラフ(未選択)。
- グラフのプロパティ ペイン。選択したグラフのデータの特性と外観は、[設定] タブと [スタイル] タブで構成できます。
- データ ペインこのペインでは、レポートで使用するフィールドとデータソースにアクセスできます。
- グラフにデータを追加するには、[データ] ペインから項目をグラフにドラッグします。
- グラフを作成するには、[データ] ペインから項目をキャンバスにドラッグします。
- 保存して共有します。このレポートを保存して、後で表示、編集、共有できるようにします。レポートを保存する前に、データソースの設定と、データソースで使用される認証情報を確認します。
データソースの認証情報のオーナーであるユーザーは、リソースをクリックすると、ジョブの統計情報、結果テーブル、BI Engine の詳細を表示できます。
グラフを操作する
Looker Studio のグラフはインタラクティブです。データが Looker Studio に表示されたので、次のような操作を行えます。
- テーブルをスクロールし、ページ間を移動します。
- 棒グラフで、バーの上にポインタを置くと、データの詳細が表示されます。
- 棒グラフでバーを選択すると、そのディメンションでテーブルをクロスフィルタできます。
グラフを追加する
Looker Studio は、さまざまなビジュアリゼーションのタイプをサポートしています。レポートにグラフを追加する手順は次のとおりです。
- ツールバーで「グラフを追加」をクリックします。
- 追加するグラフを選択します。
- キャンバスをクリックしてグラフをレポートに追加します。
- [グラフ] のプロパティ ペインを使用してグラフを構成します。
レポートにグラフを追加する方法について詳しくは、グラフをレポートに追加するをご覧ください。
テーブル スキーマを調べる
テーブル スキーマをエクスポートすると、Looker Studio でデータのメタデータを表示できます。これは、Looker Studio でデータを操作する前に BigQuery でデータを変更したくない場合に便利です。
Google Cloud コンソールで、[BigQuery] ページに移動します。
[課金プロジェクト] を選択します。
[エクスプローラ] ペインで、[入力して検索] フィールドに「
bigquery-public-data」と入力します。bigquery-public-data > austin_bikeshare > bikeshare_trips の順に移動します。
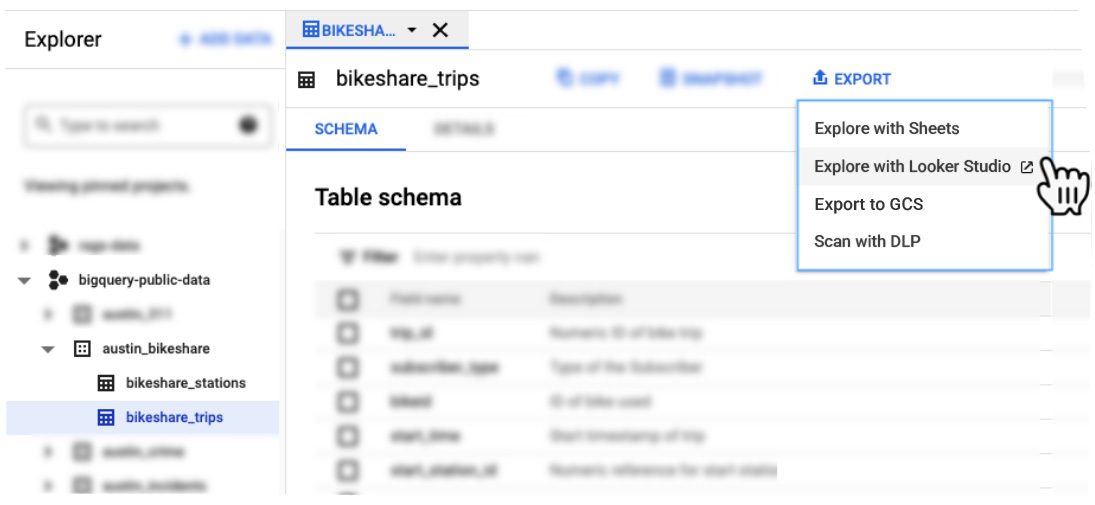
ツールバーで [ エクスポート] をクリックします。エクスポートが表示されない場合は、[ その他の操作] を選択して [エクスポート] をクリックします。
[Looker Studio で探索] をクリックします。
レポートを共有する
レポートを他のユーザーと共有するには、Looker Studio への招待を他のユーザーにメールで送信します。特定のユーザーまたは Google グループを招待できます。幅広く共有できるように、Looker Studio レポートに誰でもアクセスできるリンクを作成することもできます。
他のユーザーとレポートを共有するには、次の手順を行います。
- [Looker Studio] ページのヘッダーで、[共有] をクリックします。
- [Sharing with others] ダイアログで、受信者のメールアドレスを入力します。複数のメールアドレスまたは Google グループ アドレスを入力できます。
- 受信者がレポートを表示または編集できるかどうかを指定します。
- [送信] をクリックします。
詳しくは、レポートの共有についての記事をご覧ください。
データソースがプロジェクトに関連付けられているため、プロジェクトを削除すると、Looker Studio でデータのクエリを行えなくなります。 Google Cloud プロジェクトを削除しない場合は、Looker Studio のレポートとデータソースを削除できます。
BigQuery ジョブの詳細を表示する
データソースの認証情報が現在のユーザーに設定されている場合、そのユーザーはデータソース認証情報のオーナーと呼ばれます。データソースの認証情報のオーナーがダッシュボード要素を表示すると、ほとんどのダッシュボード要素に BigQuery アイコンが表示されます。BigQuery の [ジョブの詳細] に移動するには、BigQuery アイコンをクリックします。
Looker Studio の情報スキーマの詳細を表示する
BigQuery で使用されている Looker Studio レポートとデータソースを追跡するには、INFORMATION_SCHEMA.JOBS ビューを表示します。すべての Looker Studio ジョブには looker_studio_report_id ラベルと looker_studio_datasource_id ラベルがあります。これらの ID は、レポートまたはデータソースのページを開くときに、Looker Studio の URL の末尾に表示されます。たとえば、URL が https://lookerstudio.google.com/navigation/reporting/XXXX-YYY-ZZ のレポートの場合、レポート ID は「XXXX-YYY-ZZ」です。
次の例は、レポートとデータソースを表示する方法を示しています。
Looker Studio BigQuery のジョブレポートとデータソースの URL を表示する
Looker Studio の各 BigQuery ジョブのレポートとデータソースの URL を表示するには、次のクエリを実行します。
-- Standard labels used by Looker Studio. DECLARE requestor_key STRING DEFAULT 'requestor'; DECLARE requestor_value STRING DEFAULT 'looker_studio'; CREATE TEMP FUNCTION GetLabel(labels ANY TYPE, label_key STRING) AS ( (SELECT l.value FROM UNNEST(labels) l WHERE l.key = label_key) ); CREATE TEMP FUNCTION GetDatasourceUrl(labels ANY TYPE) AS ( CONCAT("https://lookerstudio.google.com/datasources/", GetLabel(labels, 'looker_studio_datasource_id')) ); CREATE TEMP FUNCTION GetReportUrl(labels ANY TYPE) AS ( CONCAT("https://lookerstudio.google.com/reporting/", GetLabel(labels, 'looker_studio_report_id')) ); SELECT job_id, GetDatasourceUrl(labels) AS datasource_url, GetReportUrl(labels) AS report_url, FROM `region-us`.INFORMATION_SCHEMA.JOBS jobs WHERE creation_time > TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 7 DAY) AND GetLabel(labels, requestor_key) = requestor_value LIMIT 100;
レポートとデータソースを使用して生成されたジョブを表示する
生成されたジョブを表示するには、次のクエリを実行します。
-- Specify report and data source id, which can be found in the end of Looker Studio URLs. DECLARE user_report_id STRING DEFAULT '*report id here*'; DECLARE user_datasource_id STRING DEFAULT '*datasource id here*'; -- Looker Studio labels for BigQuery jobs. DECLARE requestor_key STRING DEFAULT 'requestor'; DECLARE requestor_value STRING DEFAULT 'looker_studio'; DECLARE datasource_key STRING DEFAULT 'looker_studio_datasource_id'; DECLARE report_key STRING DEFAULT 'looker_studio_report_id'; CREATE TEMP FUNCTION GetLabel(labels ANY TYPE, label_key STRING) AS ( (SELECT l.value FROM UNNEST(labels) l WHERE l.key = label_key) ); SELECT creation_time, job_id, FROM `region-us`.INFORMATION_SCHEMA.JOBS jobs WHERE creation_time > TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 7 DAY) AND GetLabel(labels, requestor_key) = requestor_value AND GetLabel(labels, datasource_key) = user_datasource_id AND GetLabel(labels, report_key) = user_report_id ORDER BY 1 LIMIT 100;
次のステップ
- BI Engine の容量の予約の詳細については、BI Engine の容量を予約するをご覧ください。
- BigQuery 用のクエリの作成の詳細については、BigQuery 分析の概要をご覧ください。このドキュメントでは、クワの実行方法やユーザー定義関数(UDF)の作成方法などのタスクについて説明します。
- BigQuery の構文については、BigQuery での SQL の概要をご覧ください。BigQuery では、SQL クエリ用の優先言語は標準 SQL です。BigQuery の古い SQL に似た構文については、レガシー SQL 関数と演算子をご覧ください。