Migra código con el traductor de SQL por lotes
En este documento, se describe cómo usar el traductor de SQL por lotes en BigQuery para traducir secuencias de comandos escritas en otros dialectos de SQL a consultas de GoogleSQL. Este documento está dirigido a usuarios que estén familiarizados con la consola deGoogle Cloud .
Antes de comenzar
Antes de enviar un trabajo de traducción, completa los siguientes pasos:
- Asegúrate de tener todos los permisos necesarios.
- Habilita la API de BigQuery Migration.
- Recopila los archivos de origen que contienen las secuencias de comandos y las consultas de SQL que se deben traducir.
- Opcional. Crea un archivo de metadatos para mejorar la exactitud de la traducción.
- Opcional. Decide si necesitas asignar nombres de objetos SQL en los archivos de origen a nombres nuevos en BigQuery. Determina qué reglas de asignación de nombres usarás si es necesario.
- Decide qué método usar para enviar el trabajo de traducción.
- Sube los archivos de origen a Cloud Storage.
Permisos necesarios
Debes tener los siguientes permisos en el proyecto para habilitar el servicio de migración de BigQuery:
resourcemanager.projects.getserviceusage.services.enableserviceusage.services.get
Necesitas los siguientes permisos en el proyecto para acceder y usar el servicio de migración de BigQuery:
bigquerymigration.workflows.createbigquerymigration.workflows.getbigquerymigration.workflows.listbigquerymigration.workflows.deletebigquerymigration.subtasks.getbigquerymigration.subtasks.listComo alternativa, puedes usar las siguientes funciones para obtener los mismos permisos:
bigquerymigration.viewer: Acceso de solo lecturabigquerymigration.editor: Acceso de lectura/escritura.
Para acceder a los buckets de Cloud Storage para archivos de entrada y salida, sigue estos pasos:
storage.objects.geten el bucket de origen de Cloud Storage.storage.objects.listen el bucket de origen de Cloud Storage.storage.objects.createen el bucket de destino de Cloud Storage.
Puedes tener todos los permisos necesarios de Cloud Storage anteriores de las siguientes funciones:
roles/storage.objectAdminroles/storage.admin
Habilita la API de BigQuery Migration
Si tu proyecto de Google Cloud CLI se creó antes del 15 de febrero de 2022, habilita la API de BigQuery Migration de la siguiente manera:
En la consola de Google Cloud , ve a la página API de BigQuery Migration.
Haz clic en Habilitar.
Recopila los archivos de origen
Los archivos de origen deben ser archivos de texto que contengan SQL válido para el dialecto de origen. Los archivos de origen también pueden incluir comentarios. Haz todo lo posible para asegurarte de que SQL sea válido a través del uso de los métodos disponibles para ti.
Crea archivos de metadatos
Para ayudar a que el servicio genere resultados de traducción más precisos, te recomendamos que proporciones archivos de metadatos. Sin embargo, esto no es obligatorio.
Puedes usar la herramienta de extracción de línea de comandos dwh-migration-dumper para generar la información de metadatos o puedes proporcionar tus propios archivos de metadatos. Una vez que los archivos de metadatos están preparados, puedes incluirlos junto con los archivos de origen en la carpeta de origen de la traducción. El traductor los detecta automáticamente y los aprovecha para traducir archivos de origen; no necesitas establecer ninguna configuración adicional para habilitar esto.
Si deseas generar información de metadatos a través de la herramienta dwh-migration-dumper, consulta Genera metadatos para la traducción.
Si deseas proporcionar tus propios metadatos, recopila las declaraciones del lenguaje de definición de datos (DDL) para los objetos SQL del sistema de origen en archivos de texto separados.
Decide cómo enviar el trabajo de traducción
Tienes tres opciones para enviar un trabajo de traducción por lotes:
Cliente de traducción por lotes: Para configurar un trabajo, cambia parámetros de configuración de un archivo de configuración y envía el trabajo a través de la línea de comandos. No es necesario que subas de forma manual los archivos de origen a Cloud Storage con este enfoque. El cliente aún usa Cloud Storage para almacenar archivos durante el procesamiento del trabajo de traducción.
El cliente de traducción por lotes heredado es un cliente de Python de código abierto que te permite traducir archivos de origen ubicados en tu máquina local y hacer que los archivos traducidos se envíen a un directorio local. Puedes configurar el cliente para uso básico cambiando algunos parámetros de configuración en su archivo de configuración. Si lo deseas, también puedes configurar el cliente para que aborde tareas más complejas, como el reemplazo de macros, y el procesamiento previo y posterior de las entradas y salidas de traducción. Para obtener más información, consulta el readme del cliente traducción por lotes.
Consola deGoogle Cloud : Configura y envía un trabajo a través de una interfaz de usuario. Este enfoque requiere que subas los archivos de origen a Cloud Storage.
Crea archivos YAML de configuración
De forma opcional, puedes crear y usar archivos YAML de configuración de configuración para personalizar tus traducciones por lotes. Estos archivos se pueden usar para transformar el resultado de la traducción de varias maneras. Por ejemplo, puedes crear un archivo YAML de configuración para cambiar el caso de un objeto SQL durante la traducción.
Si deseas usar la Google Cloud consola o la API de BigQuery Migration para un trabajo de traducción por lotes, puedes subir el archivo YAML de configuración al bucket de Cloud Storage que contiene los archivos de origen.
Si deseas usar el cliente de traducción por lotes, puedes colocar el archivo YAML de configuración en la carpeta de entrada de traducción local.
Sube archivos de entrada a Cloud Storage
Si deseas usar la Google Cloud consola o la API de BigQuery Migration para realizar un trabajo de traducción, debes subir los archivos de origen que contienen las consultas y secuencias de comandos que deseas traducir a Cloud Storage. También puedes subir cualquier archivo de metadatos o archivos YAML de configuración al mismo bucket y directorio de Cloud Storage que contiene los archivos de origen. Si deseas obtener más información para crear buckets y subir archivos a Cloud Storage, consulta Crea buckets y Sube objetos desde un sistema de archivos.
Dialectos de SQL compatibles
El traductor de SQL por lotes es parte del servicio de migración de BigQuery. El traductor de SQL por lotes puede traducir los siguientes dialectos de SQL a GoogleSQL:
- SQL de Amazon Redshift
- Apache HiveQL y Beeline CLI
- SQL de IBM Netezza y NZPLSQL
- Teradata y Teradata Vantage
- SQL
- Consulta básica de Teradata (BTEQ)
- Teradata Parallel Transport (TPT)
Además, se admite la traducción de los siguientes dialectos de SQL en la vista previa:
- SQL de Apache Spark
- T-SQL de Azure Synapse
- Greenplum SQL
- IBM DB2 SQL
- SQL de MySQL
- SQL de Oracle, PL/SQL, Exadata
- PostgreSQL SQL
- Trino o PrestoSQL
- SQL de Snowflake
- SQL Server T-SQL
- SQLite
- SQL de Vertica
Cómo controlar las funciones de SQL no admitidas con UDF auxiliares
Cuando se traduce SQL de un dialecto de origen a BigQuery, es posible que algunas funciones no tengan un equivalente directo. Para abordar este problema, el Servicio de migración de BigQuery (y la comunidad más amplia de BigQuery) proporcionan funciones definidas por el usuario (UDF) auxiliares que replican el comportamiento de estas funciones de dialecto de origen no admitidas.
Estas UDF se suelen encontrar en el conjunto de datos públicos bqutil, lo que permite que las consultas traducidas hagan referencia a ellas inicialmente con el formato bqutil.<dataset>.<function>(). Por ejemplo, bqutil.fn.cw_count().
Consideraciones importantes para los entornos de producción:
Si bien bqutil ofrece acceso conveniente a estas UDF auxiliares para la traducción y las pruebas iniciales, no se recomienda depender directamente de bqutil para las cargas de trabajo de producción por varios motivos:
- Control de versiones: El proyecto
bqutilaloja la versión más reciente de estas UDF, lo que significa que sus definiciones pueden cambiar con el tiempo. Confiar directamente enbqutilpodría generar un comportamiento inesperado o cambios rotundos en tus consultas de producción si se actualiza la lógica de una UDF. - Aislamiento de dependencias: Cuando implementas UDFs en tu propio proyecto, aíslas tu entorno de producción de los cambios externos.
- Personalización: Es posible que debas modificar u optimizar estas UDF para que se adapten mejor a tu lógica comercial específica o a tus requisitos de rendimiento. Esto solo es posible si se encuentran dentro de tu propio proyecto.
- Seguridad y administración: Es posible que las políticas de seguridad de tu organización restrinjan el acceso directo a conjuntos de datos públicos, como
bqutil, para el procesamiento de datos de producción. Copiar UDF en tu entorno controlado se alinea con esas políticas.
Implementa UDF auxiliares en tu proyecto:
Para un uso de producción confiable y estable, debes implementar estas UDF auxiliares en tu propio proyecto y conjunto de datos. Esto te brinda control total sobre su versión, personalización y acceso. Para obtener instrucciones detalladas sobre cómo implementar estas UDF, consulta la guía de implementación de UDF en GitHub. En esta guía, se proporcionan las secuencias de comandos y los pasos necesarios para copiar las UDF en tu entorno.
Ubicaciones
El traductor de SQL por lotes está disponible en las siguientes ubicaciones de procesamiento:
| Descripción de la región | Nombre de la región | Detalles | |
|---|---|---|---|
| Asia-Pacífico | |||
| Delhi | asia-south2 |
||
| Hong Kong | asia-east2 |
||
| Yakarta | asia-southeast2 |
||
| Melbourne | australia-southeast2 |
||
| Bombay | asia-south1 |
||
| Osaka | asia-northeast2 |
||
| Seúl | asia-northeast3 |
||
| Singapur | asia-southeast1 |
||
| Sídney | australia-southeast1 |
||
| Taiwán | asia-east1 |
||
| Tokio | asia-northeast1 |
||
| Europa | |||
| Bélgica | europe-west1 |
|
|
| Berlín | europe-west10 |
||
| UE multirregión | eu |
||
| Finlandia | europe-north1 |
|
|
| Fráncfort | europe-west3 |
||
| Londres | europe-west2 |
|
|
| Madrid | europe-southwest1 |
|
|
| Milán | europe-west8 |
||
| Países Bajos | europe-west4 |
|
|
| París | europe-west9 |
|
|
| Estocolmo | europe-north2 |
|
|
| Turín | europe-west12 |
||
| Varsovia | europe-central2 |
||
| Zúrich | europe-west6 |
|
|
| América | |||
| Columbus, Ohio | us-east5 |
||
| Dallas | us-south1 |
|
|
| Iowa | us-central1 |
|
|
| Las Vegas | us-west4 |
||
| Los Ángeles | us-west2 |
||
| México | northamerica-south1 |
||
| Virginia del Norte | us-east4 |
||
| Oregón | us-west1 |
|
|
| Quebec | northamerica-northeast1 |
|
|
| São Paulo | southamerica-east1 |
|
|
| Salt Lake City | us-west3 |
||
| Santiago | southamerica-west1 |
|
|
| Carolina del Sur | us-east1 |
||
| Toronto | northamerica-northeast2 |
|
|
| EE.UU. multirregión | us |
||
| África | |||
| Johannesburgo | africa-south1 |
||
| MiddleEast | |||
| Dammam | me-central2 |
||
| Doha | me-central1 |
||
| Israel | me-west1 |
||
Envía un trabajo de traducción
Sigue estos pasos para iniciar un trabajo de traducción, ver su progreso y ver los resultados.
Console
En estos pasos, se da por sentado que ya subiste archivos de origen a un bucket de Cloud Storage.
En la consola de Google Cloud , ve a la página BigQuery.
En el menú de navegación, haz clic en Herramientas y guía.
En el panel Translate SQL, haz clic en Translate > Batch translation.
Se abrirá la página de configuración de la traducción. Ingresa los siguientes detalles:
- En Nombre visible, escribe un nombre para el trabajo de traducción. El nombre puede contener letras, números o guiones bajos.
- En Ubicación de procesamiento, selecciona la ubicación en la que deseas que se ejecute el trabajo de traducción. Por ejemplo, si estás en Europa y no quieres que tus datos pasen ningún límite de ubicación, selecciona la región
eu. El trabajo de traducción tiene un mejor rendimiento cuando eliges la misma ubicación que tu bucket de archivos de origen. - En Dialecto de origen, selecciona el dialecto de SQL que deseas traducir.
- En Dialecto de destino, selecciona BigQuery.
Haz clic en Siguiente.
En Ubicación de origen, especifica la ruta de acceso a la carpeta de Cloud Storage que contiene los archivos que deseas traducir. Puedes escribir la ruta en el formato
bucket_name/folder_name/o usar la opción Explorar.Haz clic en Siguiente.
En Ubicación de destino, especifica la ruta a la carpeta de Cloud Storage de destino de los archivos traducidos. Puedes escribir la ruta en el formato
bucket_name/folder_name/o usar la opción Explorar.Si realizas traducciones que no necesitan tener nombres de objetos predeterminados o una asignación de nombre de origen a destino especificada, ve al Paso 11. De lo contrario, haz clic en Siguiente.
Completa la configuración opcional que necesitas.
Opcional. En Base de datos predeterminada, escribe un nombre de base de datos predeterminado para usarlo con los archivos de origen. El traductor usa este nombre de base de datos predeterminado para resolver los nombres por completo calificados de los objetos SQL en los que falta el nombre de la base de datos.
Opcional. En Ruta de búsqueda del esquema, especifica un esquema para buscar cuando el traductor necesite resolver los nombres por completo calificados de los objetos SQL en los archivos de origen en los que falta el nombre del esquema. Si los archivos de origen usan varios nombres de esquema diferentes, haz clic en Agregar nombre del esquema y agrega un valor para cada nombre de esquema al que se pueda hacer referencia.
El traductor busca en los archivos de metadatos que proporcionaste para validar tablas con sus nombres de esquema. Si no se puede determinar una opción definida a partir de los metadatos, se usa como predeterminado el primer nombre de esquema que ingreses. Para obtener más información sobre cómo se usa el nombre de esquema predeterminado, consulta esquema predeterminado.
Opcional. Si quieres especificar reglas de asignación de nombres para cambiar el nombre de los objetos SQL entre el sistema de origen y BigQuery durante la traducción, puedes proporcionar un archivo JSON con el par de asignación de nombres o puedes usar la consola deGoogle Cloud para especificar los valores que se asignarán.
Para usar un archivo JSON, haz lo siguiente:
- Haz clic en Sube un archivo JSON para la asignación de nombres.
Navega hasta la ubicación de un archivo de asignación de nombres en el formato adecuado, selecciónalo y haz clic en Abrir.
Ten en cuenta que el tamaño del archivo debe ser inferior a 5 MB.
Para usar la consola de Google Cloud , haz lo siguiente:
- Haz clic en Agregar par de asignaciones de nombre.
- Agrega las partes apropiadas del nombre del objeto de origen en los campos Base de datos, Esquema, Relación y Atributo en la columna Fuente.
- Agrega las partes del nombre del objeto de destino en BigQuery en los campos de la columna Destino.
- Para Tipo, selecciona el tipo de objeto que describe al objeto que deseas asignar.
- Repite los pasos del 1 al 4 hasta que hayas especificado todos los pares de asignación de nombres que necesitas. Ten en cuenta que solo puedes especificar hasta 25 pares de asignación de nombres cuando usas la consola de Google Cloud .
Opcional. Para generar sugerencias de traducción con IA usando el modelo de Gemini, selecciona la casilla de verificación Sugerencias de IA de Gemini. Las sugerencias se basan en el archivo de configuración YAML que termina en
.ai_config.yamly se encuentra en el directorio de Cloud Storage. Cada tipo de resultado de sugerencia se guarda en su propio subdirectorio dentro de la carpeta de salida con el patrón de nombresREWRITETARGETSUGGESTION_TYPE_suggestion. Por ejemplo, las sugerencias para la personalización del SQL de destino mejorado con Gemini se almacenan entarget_sql_query_customization_suggestion, y la explicación de la traducción que genera Gemini se almacena entranslation_explanation_suggestion. Para obtener información sobre cómo escribir el archivo YAML de configuración para las sugerencias basadas en IA, consulta Crea un archivo YAML de configuración basado en Gemini.
Haz clic en Crear para iniciar el trabajo de traducción.
Una vez que se crea el trabajo de traducción, puedes ver su estado en la lista de trabajos de traducción.
Cliente de traducción por lotes
Instala el cliente de traducción por lotes y Google Cloud CLI.
En el directorio de instalación del cliente de traducción por lotes, usa el editor de texto que prefieras para abrir el archivo
config.yamly modificar los siguientes parámetros de configuración:project_number: Escribe el número de proyecto que deseas usar para el trabajo de traducción por lotes. Puedes encontrarlo en el panel Información del proyecto en la página de bienvenida de la consola del proyecto.Google Cloudgcs_bucket: Escribe el nombre del bucket de Cloud Storage que el cliente de traducción por lotes usa para almacenar archivos durante el procesamiento del trabajo de traducción.input_directory: Escribe la ruta absoluta o relativa al directorio que contiene los archivos de origen y cualquier archivo de metadatos.output_directory: Escribe la ruta de acceso absoluta o relativa al directorio de destino de los archivos traducidos.
Guarda los cambios y cierra el archivo
config.yaml.Coloca tus archivos de origen y metadatos en el directorio de entrada.
Ejecuta el cliente de traducción por lotes con el siguiente comando:
bin/dwh-migration-clientUna vez que se crea el trabajo de traducción, puedes ver su estado en la lista de trabajos de traducción en la consola de Google Cloud .
Opcional. Una vez que se haya completado el trabajo de traducción, borra los archivos que creó en el bucket de Cloud Storage que especificaste para evitar costos de almacenamiento.
Explora el resultado de la traducción
Después de ejecutar el trabajo de traducción, puedes ver información sobre el trabajo en la Google Cloud consola. Si usaste la Google Cloud consola para ejecutar el trabajo, puedes ver sus resultados en el bucket de Cloud Storage de destino que especificaste. Si usaste el cliente de traducción por lotes para ejecutar el trabajo, puedes ver sus resultados en el directorio de salida que especificaste. El traductor de SQL por lotes genera los siguientes archivos en el destino especificado:
- Los archivos traducidos
- El informe de resumen de traducción en formato CSV
- La asignación de nombres de salida consumida en formato JSON
- Son los archivos de sugerencias de IA.
Resultado de la consola deGoogle Cloud
Para ver los detalles del trabajo de traducción, sigue estos pasos:
En la consola de Google Cloud , ve a la página BigQuery.
En el menú de navegación, haz clic en Traducción de SQL.
En la lista de trabajos de traducción, busca el trabajo del que deseas ver los detalles de la traducción. Luego, haz clic en el nombre del trabajo de traducción. Puedes ver una visualización de Sankey que ilustra la calidad general del trabajo, la cantidad de líneas de código de entrada (sin incluir las líneas en blanco ni los comentarios) y una lista de los problemas que ocurrieron durante el proceso de traducción. Debes priorizar las correcciones de izquierda a derecha. Los problemas en una etapa inicial pueden causar problemas adicionales en etapas posteriores.
Mantén el puntero sobre las barras de error o advertencia y revisa las sugerencias para determinar los próximos pasos para depurar el trabajo de traducción.
Selecciona la pestaña Resumen de registro para ver un resumen de los problemas de traducción, incluidas las categorías de problema, las acciones sugeridas y la frecuencia con la que ocurrió cada problema. Puedes hacer clic en las barras de visualización de Sankey para filtrar los problemas. También puedes seleccionar una categoría de problema para ver los mensajes de registro asociados con esa categoría de problema.
Selecciona la pestaña Mensajes de registro para ver más detalles sobre cada problema de traducción, incluida la categoría de problema, el mensaje de problema específico y un vínculo al archivo en el que se produjo el problema. Puedes hacer clic en las barras de visualización de Sankey para filtrar los problemas. Puedes seleccionar un problema en la pestaña Mensaje de registro para abrir la pestaña Código que muestra el archivo de entrada y salida si es aplicable.
Haz clic en la pestaña Detalles del trabajo para ver los detalles de la configuración del trabajo de traducción.
Informe de resumen
El informe de resumen es un archivo CSV que contiene una tabla de todos los mensajes de advertencia y error que se encontraron durante el trabajo de traducción.
Para ver el archivo de resumen en la consola de Google Cloud , sigue estos pasos:
En la consola de Google Cloud , ve a la página BigQuery.
En el menú de navegación, haz clic en Traducción de SQL.
En la lista de trabajos de traducción, busca el que te interese y, luego, haz clic en su nombre o en Más opciones > Mostrar detalles.
En la pestaña Detalles del trabajo, en la sección Informe de traducción, haz clic en translation_report.csv.
En la página Detalles del objeto, haz clic en el valor de la fila URL autenticada para ver el archivo en tu navegador.
En la siguiente tabla, se describen las columnas de archivos de resumen:
| Columna | Descripción |
|---|---|
| Marca de tiempo | La marca de tiempo en la que ocurrió el problema. |
| FilePath | La ruta de acceso al archivo de origen con el que está asociado el problema. |
| Nombre del archivo | El nombre del archivo de origen con el que está asociado el problema. |
| ScriptLine | El número de línea en la que ocurrió el problema. |
| ScriptColumn | El número de columna en la que ocurrió el problema. |
| TranspilerComponent | El componente interno del motor de traducción en el que se produjo la advertencia o el error. Esta columna puede estar vacía. |
| Entorno | Es el entorno del dialecto de traducción asociado con la advertencia o el error. Esta columna puede estar vacía. |
| ObjectName | Es el objeto de SQL en el archivo de origen que está asociado con la advertencia o el error. Esta columna puede estar vacía. |
| Gravedad | La gravedad del problema, ya sea una advertencia o un error. |
| Categoría | La categoría del problema de traducción. |
| SourceType | Es la fuente de este problema. El valor de esta columna puede ser
SQL, que indica un problema en los archivos SQL de entrada, o
METADATA, que indica un problema en el paquete de metadatos. |
| Mensaje | El mensaje de advertencia o de error del problema de traducción. |
| ScriptContext | El fragmento de SQL en el archivo de origen que está asociado con el problema. |
| Acción | La acción que te recomendamos que realices para resolver el problema. |
Pestaña Código
La pestaña Código te permite revisar más información sobre los archivos de entrada y salida para un trabajo de traducción en particular. En la pestaña Código, puedes examinar los archivos usados en un trabajo de traducción, revisar una comparación en paralelo de un archivo de entrada y su traducción para detectar errores y ver resúmenes de registros y mensajes para un archivo específico en un trabajo.
Para acceder a la pestaña Código, sigue estos pasos:
En la consola de Google Cloud , ve a la página BigQuery.
En el menú de navegación, haz clic en Traducción de SQL.
En la lista de trabajos de traducción, busca el que te interese y, luego, haz clic en su nombre o en Más opciones > Mostrar detalles.
Seleccionar la pestaña Código. La pestaña de código consta de los siguientes paneles:
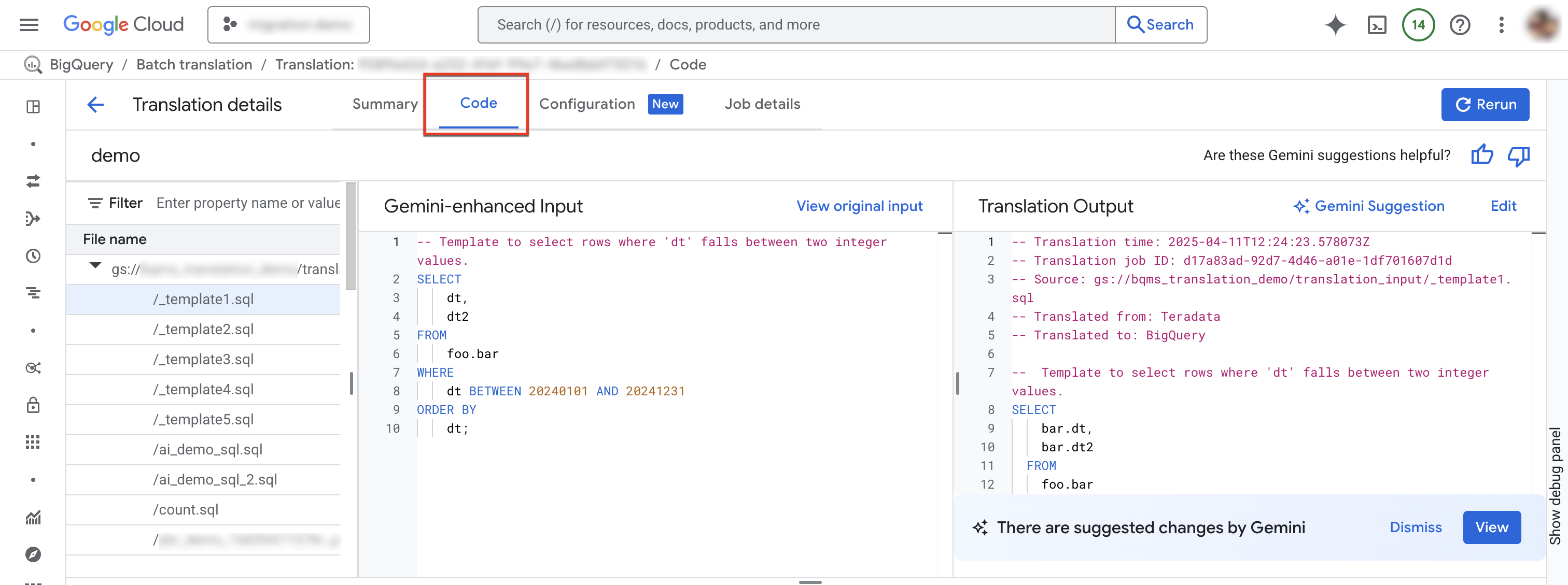
- Explorador de archivos: Contiene todos los archivos SQL que se usan para la traducción. Haz clic en un archivo para ver su entrada y salida de traducción, y cualquier problema de traducción.
- Entrada mejorada con Gemini: Es el código SQL de entrada que tradujo el motor de traducción. Si especificaste reglas de personalización de Gemini para el SQL fuente en la configuración de Gemini, el traductor primero transforma la entrada original y, luego, traduce la entrada mejorada con Gemini. Para ver la entrada original, haz clic en Ver entrada original.
- Resultado de la traducción: Es el resultado de la traducción. Si especificaste reglas de personalización de Gemini para el SQL de destino en la configuración de Gemini, la transformación se aplica al resultado traducido como un resultado mejorado por Gemini. Si hay un resultado mejorado con Gemini disponible, puedes hacer clic en el botón Sugerencia de Gemini para revisarlo.
Opcional: Para ver un archivo de entrada y su archivo de salida en el traductor de SQL interactivo de BigQuery, haz clic en Editar. Puedes editar los archivos y guardar el archivo de salida en Cloud Storage.
Pestaña Configuración
Puedes agregar, cambiar el nombre, ver o editar tus archivos YAML de configuración en la pestaña Configuration.El Explorador de esquemas muestra la documentación de los tipos de configuración admitidos para ayudarte a escribir tus archivos YAML de configuración. Después de editar los archivos YAML de configuración, puedes volver a ejecutar el trabajo para usar la nueva configuración.
Para acceder a la pestaña de configuración, sigue estos pasos:
En la consola de Google Cloud , ve a la página BigQuery.
En el menú de navegación, haz clic en Traducción de SQL.
En la lista de trabajos de traducción, busca el que te interese y, luego, haz clic en su nombre o en Más opciones > Mostrar detalles.
En la ventana Detalles de la traducción, haz clic en la pestaña Configuración.
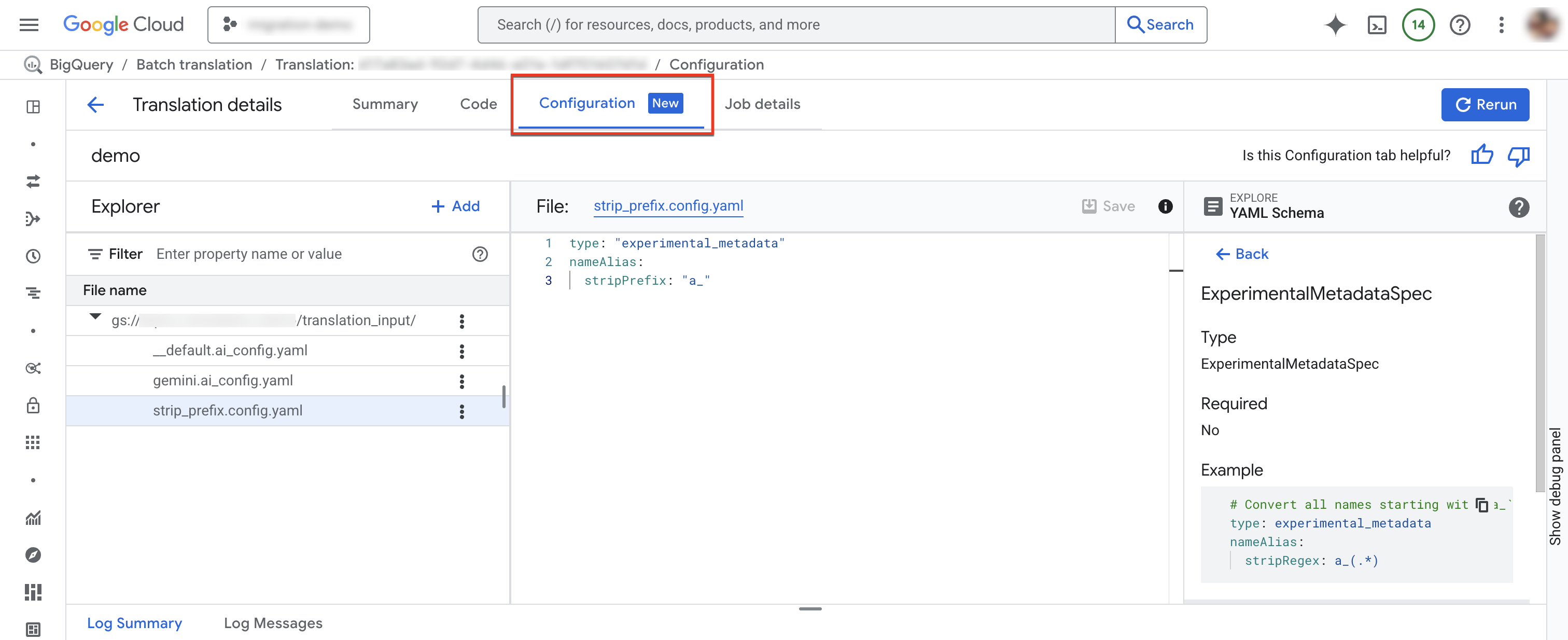
Para agregar un archivo de configuración nuevo, sigue estos pasos:
- Haz clic en more_vert Más opciones > Crear archivo YAML de configuración.
- Aparecerá un panel en el que podrás elegir el tipo, la ubicación y el nombre del nuevo archivo YAML de configuración.
- Haz clic en Crear.
Para editar un archivo de configuración existente, sigue estos pasos:
- Haz clic en el archivo YAML de configuración.
- Edita el archivo y, luego, haz clic en Guardar.
- Haz clic en Volver a ejecutar para ejecutar un nuevo trabajo de traducción que use los archivos YAML de configuración editados.
Para cambiar el nombre de un archivo de configuración existente, haz clic en more_vert Más opciones > Cambiar nombre.
Archivo de asignación de nombres de salida consumido
Este archivo JSON contiene las reglas de asignación de nombres de salida que usó el trabajo de traducción. Las reglas en este archivo pueden diferir de las reglas de asignación de nombres de salida que especificaste para el trabajo de traducción debido a conflictos en las reglas de asignación de nombres o a la falta de reglas de asignación de nombres para los objetos SQL que se identificaron durante la traducción. Revisa este archivo para determinar si las reglas de asignación de nombres necesitan corrección. Si es así, crea nuevas reglas de asignación de nombres de salida que aborden cualquier problema que identifiques y ejecuta un nuevo trabajo de traducción.
Archivos traducidos
Para cada archivo de origen, se genera el archivo de salida correspondiente en la ruta de destino. El archivo de salida contiene la consulta traducida.
Depura consultas de SQL traducidas por lotes con el traductor interactivo de SQL
Puedes usar el traductor interactivo de SQL de BigQuery para revisar o depurar una consulta en SQL con los mismos metadatos o la misma información de asignación de objetos que la base de datos de origen. Después de completar un trabajo de traducción por lotes, BigQuery genera un ID de configuración de traducción que contiene información sobre los metadatos del trabajo, la asignación de objetos o la ruta de búsqueda del esquema, según corresponda para la consulta. Usa el ID de configuración de traducción por lotes con el traductor interactivo de SQL para ejecutar consultas de SQL con la configuración especificada.
Para iniciar una traducción interactiva de SQL a través de un ID de configuración de traducción por lotes, sigue estos pasos:
En la consola de Google Cloud , ve a la página BigQuery.
En el menú de navegación, haz clic en Traducción de SQL.
En la lista de trabajos de traducción, busca el trabajo que te interesa y, luego, haz clic en Más opciones > Abrir la traducción interactiva.
El traductor interactivo de SQL de BigQuery ahora se abre con el ID de configuración de traducción por lotes correspondiente. Para ver el ID de configuración de traducción de la traducción interactiva, haz clic en Más > Configuración de traducción en el traductor de SQL interactivo.
Para depurar un archivo de traducción por lotes en el traductor interactivo de SQL, sigue estos pasos:
En la consola de Google Cloud , ve a la página BigQuery.
En el menú de navegación, haz clic en Traducción de SQL.
En la lista de trabajos de traducción, busca el que te interesa y, luego, haz clic en su nombre o en Más opciones > Mostrar detalles.
En la ventana Detalles de la traducción, haz clic en la pestaña Código.
En el explorador de archivos, haz clic en el nombre del archivo para abrirlo.
Junto al nombre del archivo de salida, haz clic en Editar para abrir los archivos en el traductor de SQL interactivo (Vista previa).
Verás los archivos de entrada y salida completados en el traductor interactivo de SQL, que ahora usa el ID de configuración de traducción por lotes correspondiente.
Para guardar el archivo de salida editado en Cloud Storage, en el traductor interactivo de SQL, haz clic en Guardar > Guardar en GCS.
Limitaciones
El traductor no puede traducir funciones definidas por el usuario (UDF) de lenguajes que no sean SQL, ya que no puede analizarlas para determinar sus tipos de datos de entrada y salida. Esto provoca que la traducción de las instrucciones de SQL que hacen referencia a estas UDF sea inexacta. Para asegurarte de que se haga referencia de forma correcta a las UDF que no son de SQL durante la traducción, usa SQL válido para crear UDF de marcador de posición con las mismas firmas.
Por ejemplo, supongamos que tienes una UDF escrita en C que calcula la suma de dos números enteros. Para asegurarte de que las instrucciones de SQL que hacen referencia a esta UDF se traduzcan de forma correcta, crea una UDF de SQL de marcador de posición que comparta la misma firma que la UDF de C, como se muestra en el siguiente ejemplo:
CREATE FUNCTION Test.MySum (a INT, b INT)
RETURNS INT
LANGUAGE SQL
RETURN a + b;
Guarda esta UDF de marcador de posición en un archivo de texto y, luego, incluye ese archivo como uno de los archivos de origen para el trabajo de traducción. Así, el traductor puede aprender la definición de la UDF y, además, identificar los tipos de datos de entrada y salida esperados.
Cuota y límites
- Se aplican las cuotas de la API de BigQuery Migration.
- Cada proyecto puede tener como máximo 10 tareas de traducción activas.
- Si bien no existe un límite estricto en la cantidad total de archivos de origen y de metadatos, recomendamos mantener la cantidad de archivos por debajo de 1,000 para obtener un mejor rendimiento.
Soluciona problemas de errores de traducción
Problemas de traducción de RelationNotFound o AttributeNotFound
La traducción funciona mejor con DDL de metadatos. Cuando no se pueden encontrar definiciones de
objetos SQL, el motor de traducción genera problemas RelationNotFound o
AttributeNotFound. Recomendamos usar el extractor de metadatos para generar paquetes de metadatos para garantizar que todas las definiciones de objetos estén presentes. Agregar metadatos es el
primer paso recomendado para resolver la mayoría de los errores de traducción, ya que a menudo puede corregir
muchos otros errores que se generan de forma indirecta por la falta de metadatos.
Si deseas obtener más información, consulta Genera metadatos para la traducción y la evaluación.
Precios
No se aplican cargos por usar el traductor de SQL por lotes. Sin embargo, se aplican las tarifas normales al almacenamiento que se usa para almacenar archivos de entrada y salida. Para obtener más información, consulta los precios de almacenamiento.
¿Qué sigue?
Obtén más información sobre los siguientes pasos en la migración de almacenes de datos:
- Descripción general de la migración
- Evaluación de la migración
- Descripción general de transferencia de datos y esquemas
- Canalizaciones de datos
- Traducción de SQL interactiva
- Seguridad y administración de los datos
- Herramienta de validación de datos